 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image-based Regularization for Action Smoothness in Autonomous Miniature Racing Car with Deep Reinforcement Learning
Jul 17, 2023
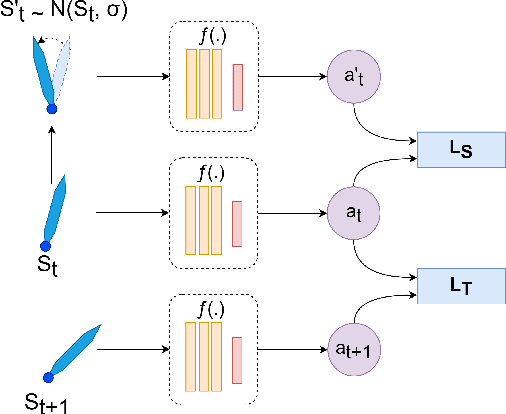
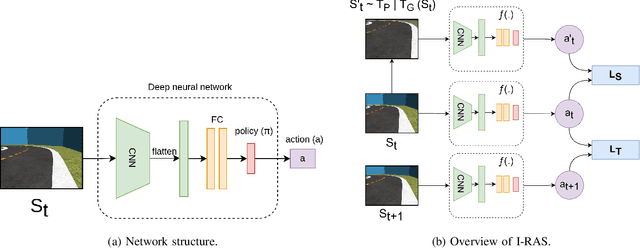

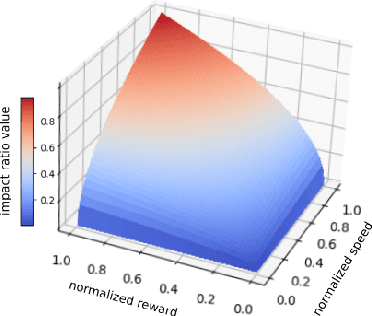
Deep reinforcement learning has achieved significant results in low-level controlling tasks. However, for some applications like autonomous driving and drone flying, it is difficult to control behavior stably since the agent may suddenly change its actions which often lowers the controlling system's efficiency, induces excessive mechanical wear, and causes uncontrollable, dangerous behavior to the vehicle. Recently, a method called conditioning for action policy smoothness (CAPS) was proposed to solve the problem of jerkiness in low-dimensional features for applications such as quadrotor drones. To cope with high-dimensional features, this paper proposes image-based regularization for action smoothness (I-RAS) for solving jerky control in autonomous miniature car racing. We also introduce a control based on impact ratio, an adaptive regularization weight to control the smoothness constraint, called IR control. In the experiment, an agent with I-RAS and IR control significantly improves the success rate from 59% to 95%. In the real-world-track experiment, the agent also outperforms other methods, namely reducing the average finish lap time, while also improving the completion rate even without real world training. This is also justified by an agent based on I-RAS winning the 2022 AWS DeepRacer Final Championship Cup.
1M parameters are enough? A lightweight CNN-based model for medical image segmentation
Jul 03, 2023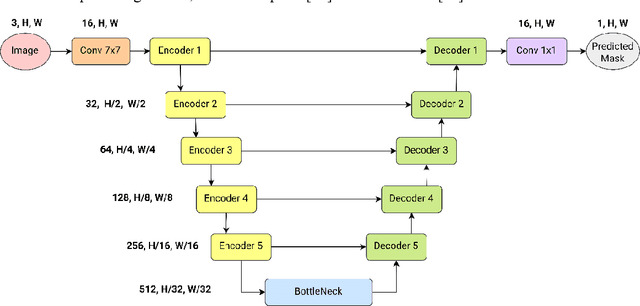
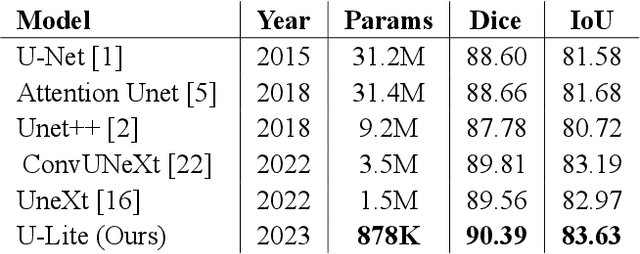
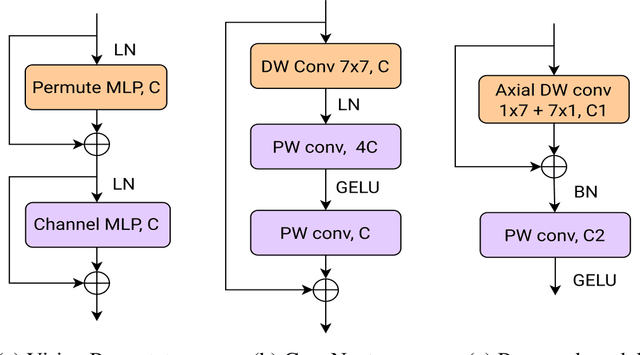
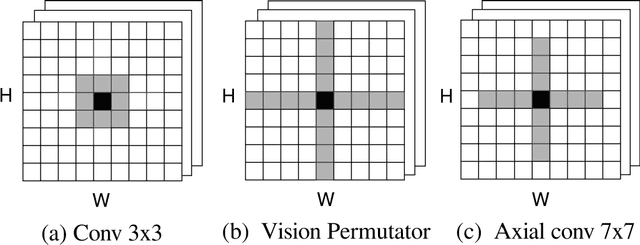
Convolutional neural networks (CNNs) and Transformer-based models are being widely applied in medical image segmentation thanks to their ability to extract high-level features and capture important aspects of the image. However, there is often a trade-off between the need for high accuracy and the desire for low computational cost. A model with higher parameters can theoretically achieve better performance but also result in more computational complexity and higher memory usage, and thus is not practical to implement. In this paper, we look for a lightweight U-Net-based model which can remain the same or even achieve better performance, namely U-Lite. We design U-Lite based on the principle of Depthwise Separable Convolution so that the model can both leverage the strength of CNNs and reduce a remarkable number of computing parameters. Specifically, we propose Axial Depthwise Convolutions with kernels 7x7 in both the encoder and decoder to enlarge the model receptive field. To further improve the performance, we use several Axial Dilated Depthwise Convolutions with filters 3x3 for the bottleneck as one of our branches. Overall, U-Lite contains only 878K parameters, 35 times less than the traditional U-Net, and much more times less than other modern Transformer-based models. The proposed model cuts down a large amount of computational complexity while attaining an impressive performance on medical segmentation tasks compared to other state-of-the-art architectures. The code will be available at: https://github.com/duong-db/U-Lite.
Improving Spherical Image Resampling through Viewport-Adaptivity
Jun 23, 2023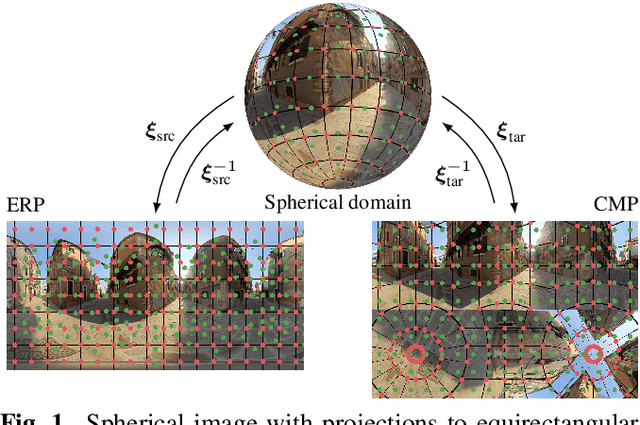
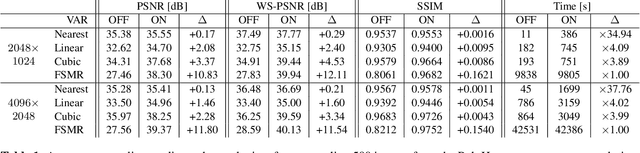
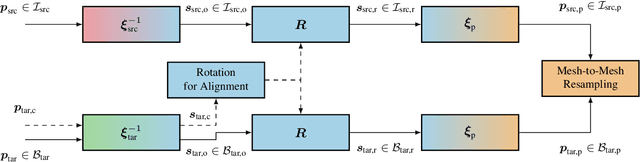
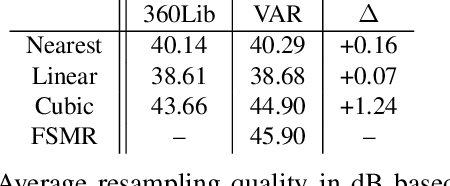
The conversion between different spherical image and video projection formats requires highly accurate resampling techniques in order to minimize the inevitable loss of information. Suitable resampling algorithms such as nearest neighbor, linear or cubic resampling are readily available. However, no generally applicable resampling technique exploits the special properties of spherical images so far. Thus, we propose a novel viewport-adaptive resampling (VAR) technique that takes the spherical characteristics of the underlying resampling problem into account. VAR can be applied to any mesh-to-mesh capable resampling algorithm and shows significant gains across all tested techniques. In combination with frequency-selective resampling, VAR outperforms conventional cubic resampling by more than 2 dB in terms of WS-PSNR. A visual inspection and the evaluation of further metrics such as PSNR and SSIM support the positive results.
Confidence Contours: Uncertainty-Aware Annotation for Medical Semantic Segmentation
Aug 15, 2023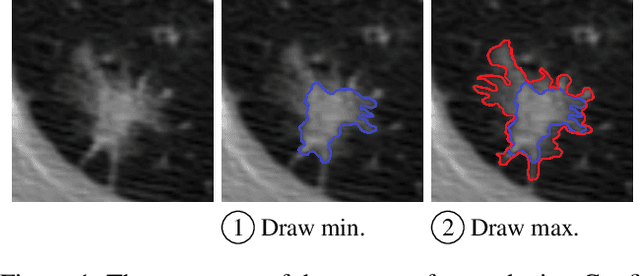
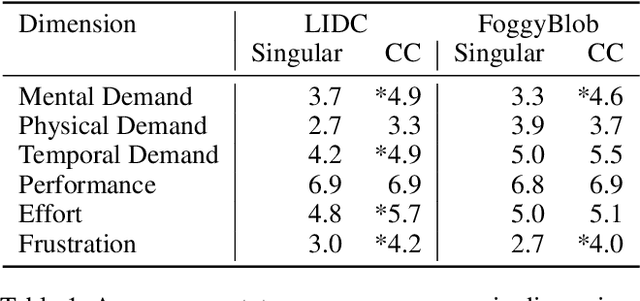
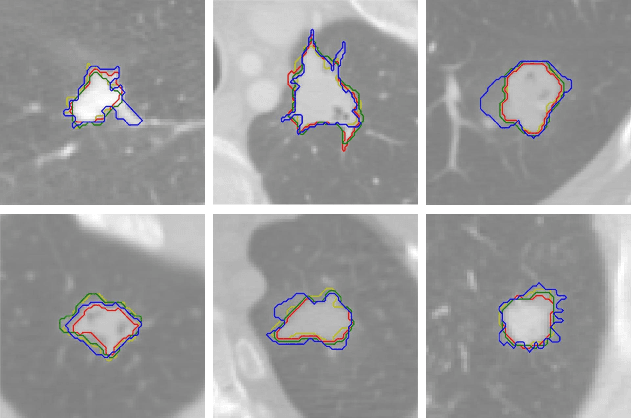
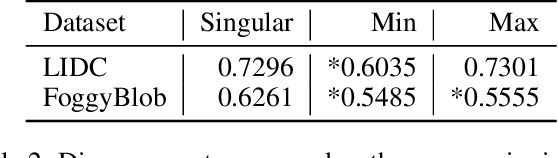
Medical image segmentation modeling is a high-stakes task where understanding of uncertainty is crucial for addressing visual ambiguity. Prior work has developed segmentation models utilizing probabilistic or generative mechanisms to infer uncertainty from labels where annotators draw a singular boundary. However, as these annotations cannot represent an individual annotator's uncertainty, models trained on them produce uncertainty maps that are difficult to interpret. We propose a novel segmentation representation, Confidence Contours, which uses high- and low-confidence ``contours'' to capture uncertainty directly, and develop a novel annotation system for collecting contours. We conduct an evaluation on the Lung Image Dataset Consortium (LIDC) and a synthetic dataset. From an annotation study with 30 participants, results show that Confidence Contours provide high representative capacity without considerably higher annotator effort. We also find that general-purpose segmentation models can learn Confidence Contours at the same performance level as standard singular annotations. Finally, from interviews with 5 medical experts, we find that Confidence Contour maps are more interpretable than Bayesian maps due to representation of structural uncertainty.
Fair GANs through model rebalancing with synthetic data
Aug 16, 2023
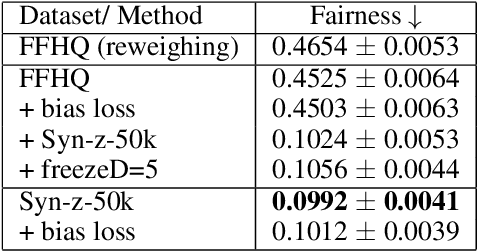
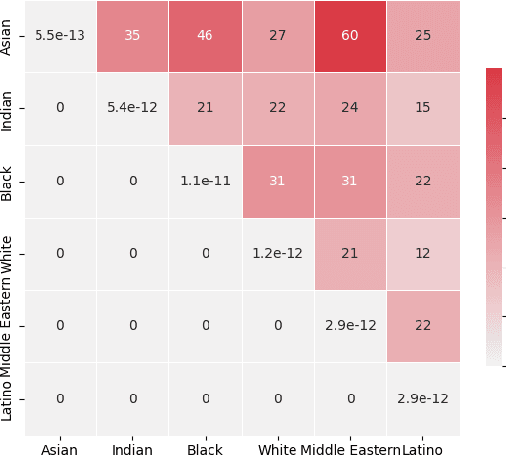
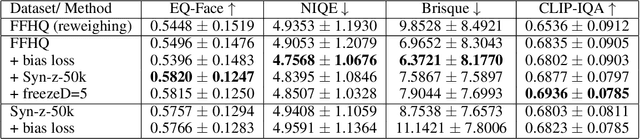
Deep generative models require large amounts of training data. This often poses a problem as the collection of datasets can be expensive and difficult, in particular datasets that are representative of the appropriate underlying distribution (e.g. demographic). This introduces biases in datasets which are further propagated in the models. We present an approach to mitigate biases in an existing generative adversarial network by rebalancing the model distribution. We do so by generating balanced data from an existing unbalanced deep generative model using latent space exploration and using this data to train a balanced generative model. Further, we propose a bias mitigation loss function that shows improvements in the fairness metric even when trained with unbalanced datasets. We show results for the Stylegan2 models while training on the FFHQ dataset for racial fairness and see that the proposed approach improves on the fairness metric by almost 5 times, whilst maintaining image quality. We further validate our approach by applying it to an imbalanced Cifar-10 dataset. Lastly, we argue that the traditionally used image quality metrics such as Frechet inception distance (FID) are unsuitable for bias mitigation problems.
SYENet: A Simple Yet Effective Network for Multiple Low-Level Vision Tasks with Real-time Performance on Mobile Device
Aug 16, 2023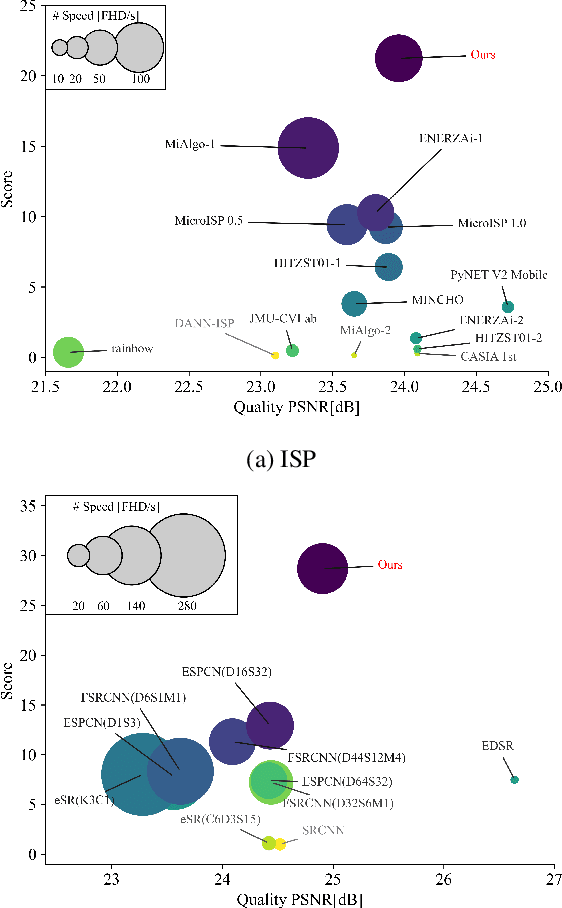
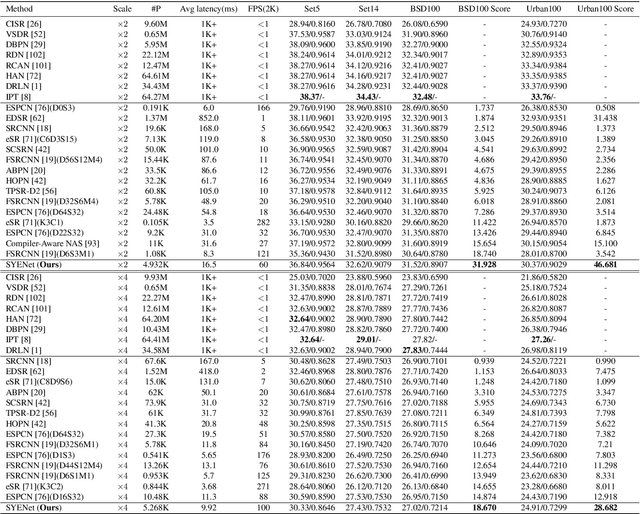
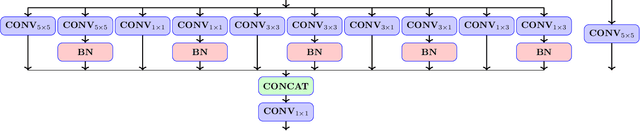
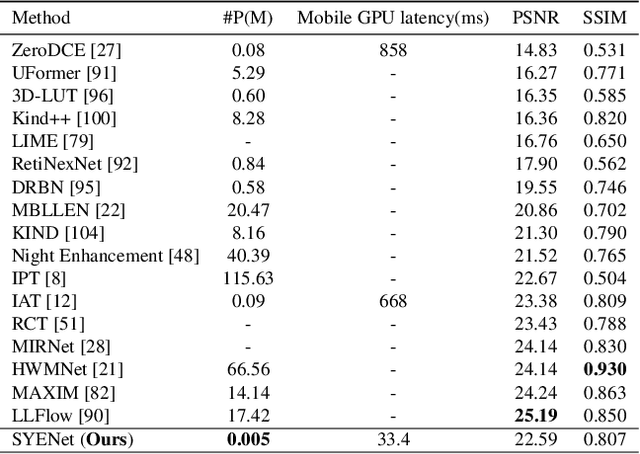
With the rapid development of AI hardware accelerators, applying deep learning-based algorithms to solve various low-level vision tasks on mobile devices has gradually become possible. However, two main problems still need to be solved: task-specific algorithms make it difficult to integrate them into a single neural network architecture, and large amounts of parameters make it difficult to achieve real-time inference. To tackle these problems, we propose a novel network, SYENet, with only $~$6K parameters, to handle multiple low-level vision tasks on mobile devices in a real-time manner. The SYENet consists of two asymmetrical branches with simple building blocks. To effectively connect the results by asymmetrical branches, a Quadratic Connection Unit(QCU) is proposed. Furthermore, to improve performance, a new Outlier-Aware Loss is proposed to process the image. The proposed method proves its superior performance with the best PSNR as compared with other networks in real-time applications such as Image Signal Processing(ISP), Low-Light Enhancement(LLE), and Super-Resolution(SR) with 2K60FPS throughput on Qualcomm 8 Gen 1 mobile SoC(System-on-Chip). Particularly, for ISP task, SYENet got the highest score in MAI 2022 Learned Smartphone ISP challenge.
High-Fidelity Lake Extraction via Two-Stage Prompt Enhancement: Establishing a Novel Baseline and Benchmark
Aug 16, 2023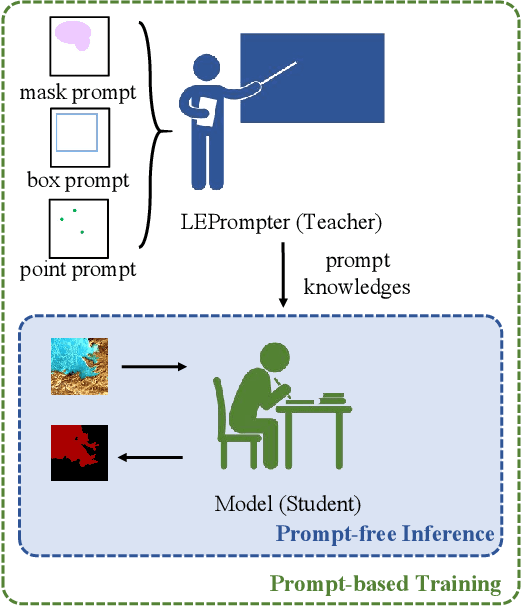
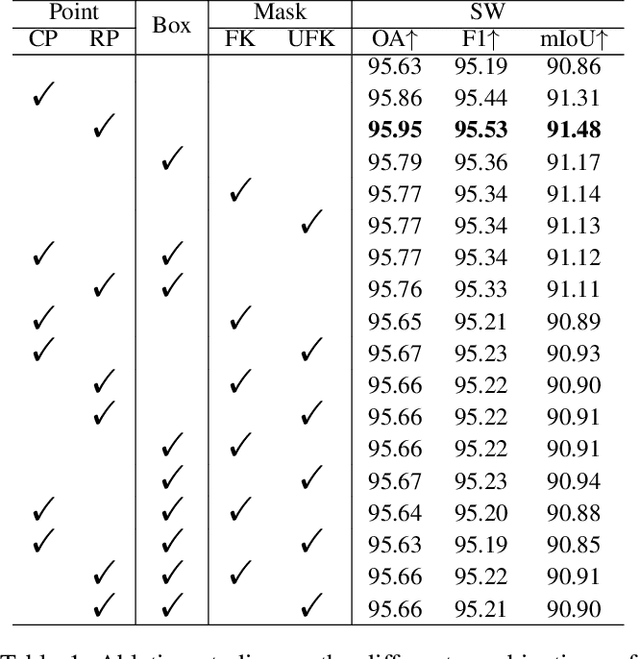
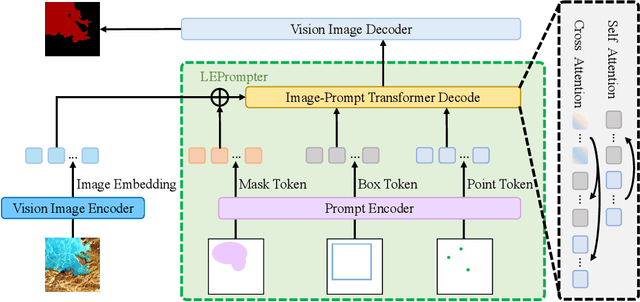
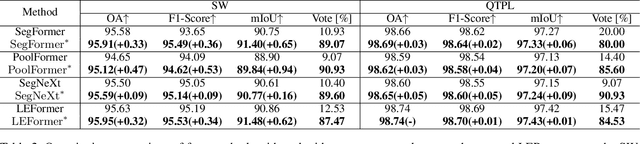
The extraction of lakes from remote sensing images is a complex challenge due to the varied lake shapes and data noise. Current methods rely on multispectral image datasets, making it challenging to learn lake features accurately from pixel arrangements. This, in turn, affects model learning and the creation of accurate segmentation masks. This paper introduces a unified prompt-based dataset construction approach that provides approximate lake locations using point, box, and mask prompts. We also propose a two-stage prompt enhancement framework, LEPrompter, which involves prompt-based and prompt-free stages during training. The prompt-based stage employs a prompt encoder to extract prior information, integrating prompt tokens and image embeddings through self- and cross-attention in the prompt decoder. Prompts are deactivated once the model is trained to ensure independence during inference, enabling automated lake extraction. Evaluations on Surface Water and Qinghai-Tibet Plateau Lake datasets show consistent performance improvements compared to the previous state-of-the-art method. LEPrompter achieves mIoU scores of 91.48% and 97.43% on the respective datasets without introducing additional parameters or GFLOPs. Supplementary materials provide the source code, pre-trained models, and detailed user studies.
MSFlow: Multi-Scale Flow-based Framework for Unsupervised Anomaly Detection
Aug 29, 2023
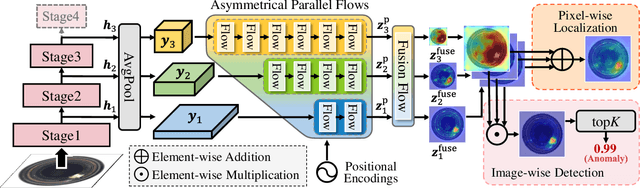
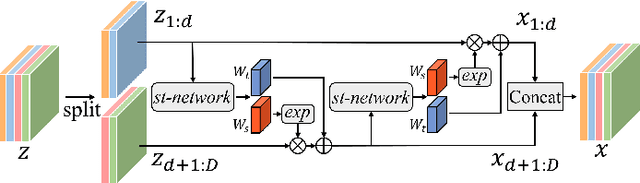
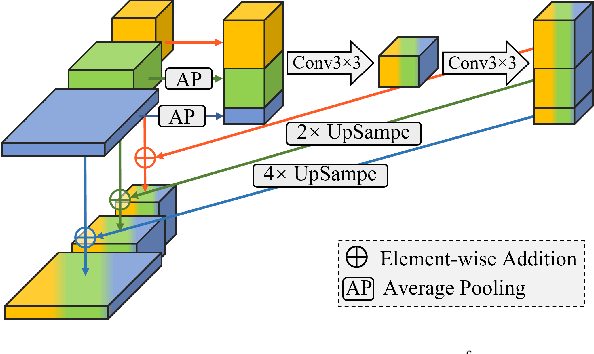
Unsupervised anomaly detection (UAD) attracts a lot of research interest and drives widespread applications, where only anomaly-free samples are available for training. Some UAD applications intend to further locate the anomalous regions without any anomaly information. Although the absence of anomalous samples and annotations deteriorates the UAD performance, an inconspicuous yet powerful statistics model, the normalizing flows, is appropriate for anomaly detection and localization in an unsupervised fashion. The flow-based probabilistic models, only trained on anomaly-free data, can efficiently distinguish unpredictable anomalies by assigning them much lower likelihoods than normal data. Nevertheless, the size variation of unpredictable anomalies introduces another inconvenience to the flow-based methods for high-precision anomaly detection and localization. To generalize the anomaly size variation, we propose a novel Multi-Scale Flow-based framework dubbed MSFlow composed of asymmetrical parallel flows followed by a fusion flow to exchange multi-scale perceptions. Moreover, different multi-scale aggregation strategies are adopted for image-wise anomaly detection and pixel-wise anomaly localization according to the discrepancy between them. The proposed MSFlow is evaluated on three anomaly detection datasets, significantly outperforming existing methods. Notably, on the challenging MVTec AD benchmark, our MSFlow achieves a new state-of-the-art with a detection AUORC score of up to 99.7%, localization AUCROC score of 98.8%, and PRO score of 97.1%. The reproducible code is available at https://github.com/cool-xuan/msflow.
CLIPTrans: Transferring Visual Knowledge with Pre-trained Models for Multimodal Machine Translation
Aug 29, 2023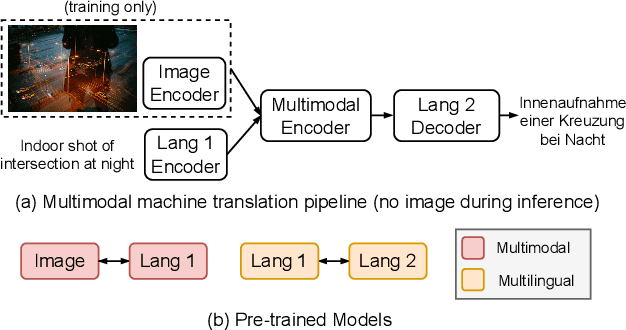
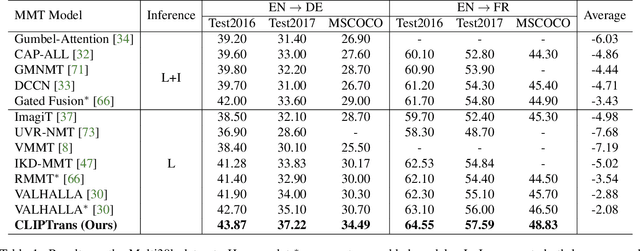
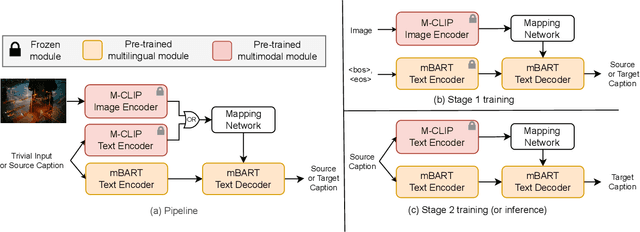

There has been a growing interest in developing multimodal machine translation (MMT) systems that enhance neural machine translation (NMT) with visual knowledge. This problem setup involves using images as auxiliary information during training, and more recently, eliminating their use during inference. Towards this end, previous works face a challenge in training powerful MMT models from scratch due to the scarcity of annotated multilingual vision-language data, especially for low-resource languages. Simultaneously, there has been an influx of multilingual pre-trained models for NMT and multimodal pre-trained models for vision-language tasks, primarily in English, which have shown exceptional generalisation ability. However, these are not directly applicable to MMT since they do not provide aligned multimodal multilingual features for generative tasks. To alleviate this issue, instead of designing complex modules for MMT, we propose CLIPTrans, which simply adapts the independently pre-trained multimodal M-CLIP and the multilingual mBART. In order to align their embedding spaces, mBART is conditioned on the M-CLIP features by a prefix sequence generated through a lightweight mapping network. We train this in a two-stage pipeline which warms up the model with image captioning before the actual translation task. Through experiments, we demonstrate the merits of this framework and consequently push forward the state-of-the-art across standard benchmarks by an average of +2.67 BLEU. The code can be found at www.github.com/devaansh100/CLIPTrans.
Pose-Free Neural Radiance Fields via Implicit Pose Regularization
Aug 29, 2023
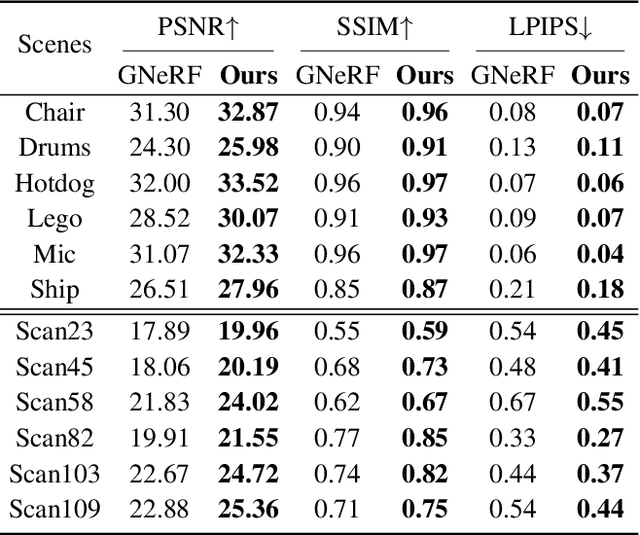
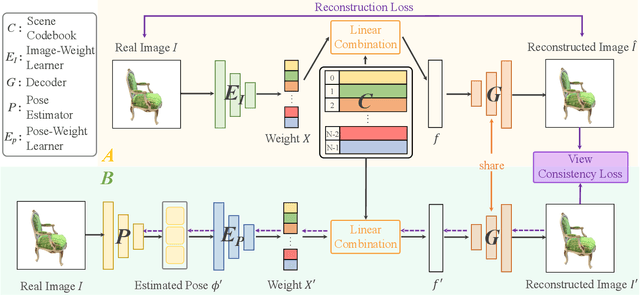
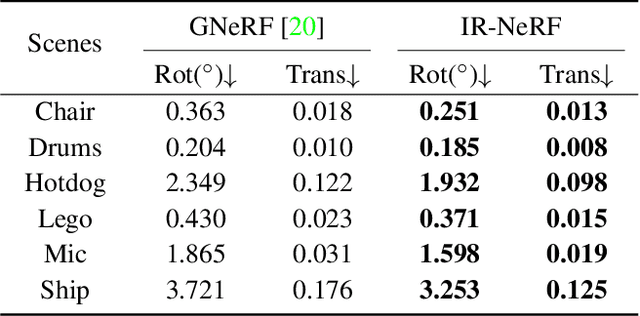
Pose-free neural radiance fields (NeRF) aim to train NeRF with unposed multi-view images and it has achieved very impressive success in recent years. Most existing works share the pipeline of training a coarse pose estimator with rendered images at first, followed by a joint optimization of estimated poses and neural radiance field. However, as the pose estimator is trained with only rendered images, the pose estimation is usually biased or inaccurate for real images due to the domain gap between real images and rendered images, leading to poor robustness for the pose estimation of real images and further local minima in joint optimization. We design IR-NeRF, an innovative pose-free NeRF that introduces implicit pose regularization to refine pose estimator with unposed real images and improve the robustness of the pose estimation for real images. With a collection of 2D images of a specific scene, IR-NeRF constructs a scene codebook that stores scene features and captures the scene-specific pose distribution implicitly as priors. Thus, the robustness of pose estimation can be promoted with the scene priors according to the rationale that a 2D real image can be well reconstructed from the scene codebook only when its estimated pose lies within the pose distribution. Extensive experiments show that IR-NeRF achieves superior novel view synthesis and outperforms the state-of-the-art consistently across multiple synthetic and real datasets.