 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Joint Gaze-Location and Gaze-Object Detection
Aug 26, 2023
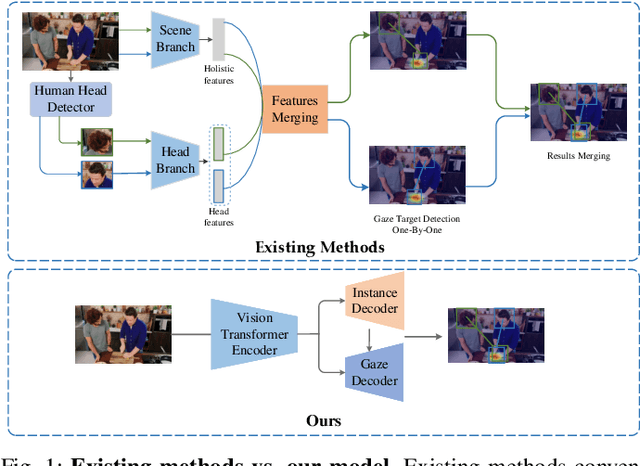
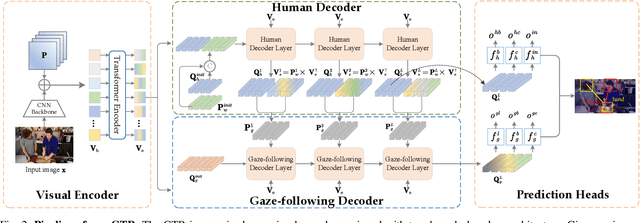
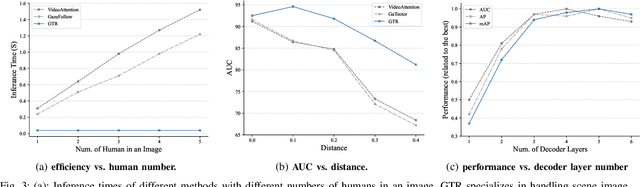
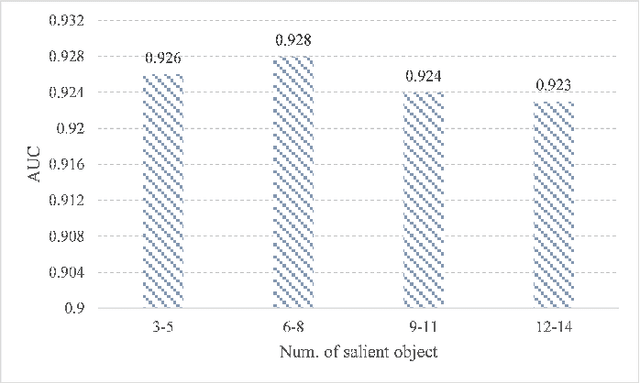
This paper proposes an efficient and effective method for joint gaze location detection (GL-D) and gaze object detection (GO-D), \emph{i.e.}, gaze following detection. Current approaches frame GL-D and GO-D as two separate tasks, employing a multi-stage framework where human head crops must first be detected and then be fed into a subsequent GL-D sub-network, which is further followed by an additional object detector for GO-D. In contrast, we reframe the gaze following detection task as detecting human head locations and their gaze followings simultaneously, aiming at jointly detect human gaze location and gaze object in a unified and single-stage pipeline. To this end, we propose GTR, short for \underline{G}aze following detection \underline{TR}ansformer, streamlining the gaze following detection pipeline by eliminating all additional components, leading to the first unified paradigm that unites GL-D and GO-D in a fully end-to-end manner. GTR enables an iterative interaction between holistic semantics and human head features through a hierarchical structure, inferring the relations of salient objects and human gaze from the global image context and resulting in an impressive accuracy. Concretely, GTR achieves a 12.1 mAP gain ($\mathbf{25.1}\%$) on GazeFollowing and a 18.2 mAP gain ($\mathbf{43.3\%}$) on VideoAttentionTarget for GL-D, as well as a 19 mAP improvement ($\mathbf{45.2\%}$) on GOO-Real for GO-D. Meanwhile, unlike existing systems detecting gaze following sequentially due to the need for a human head as input, GTR has the flexibility to comprehend any number of people's gaze followings simultaneously, resulting in high efficiency. Specifically, GTR introduces over a $\times 9$ improvement in FPS and the relative gap becomes more pronounced as the human number grows.
Dental CLAIRES: Contrastive LAnguage Image REtrieval Search for Dental Research
Jun 27, 2023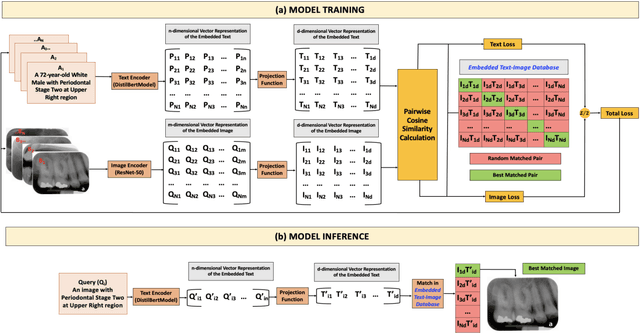

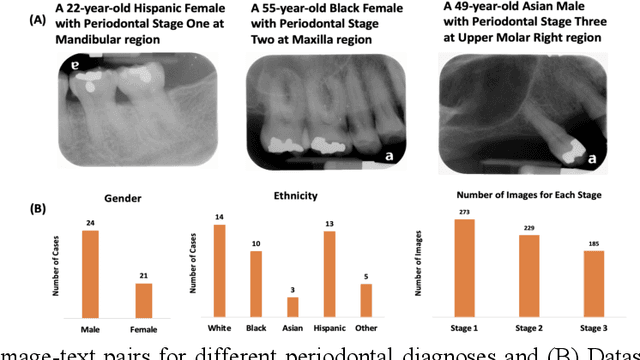
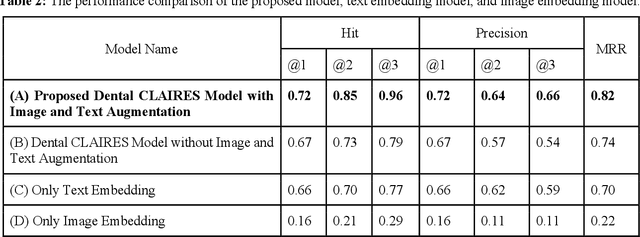
Learning about diagnostic features and related clinical information from dental radiographs is important for dental research. However, the lack of expert-annotated data and convenient search tools poses challenges. Our primary objective is to design a search tool that uses a user's query for oral-related research. The proposed framework, Contrastive LAnguage Image REtrieval Search for dental research, Dental CLAIRES, utilizes periapical radiographs and associated clinical details such as periodontal diagnosis, demographic information to retrieve the best-matched images based on the text query. We applied a contrastive representation learning method to find images described by the user's text by maximizing the similarity score of positive pairs (true pairs) and minimizing the score of negative pairs (random pairs). Our model achieved a hit@3 ratio of 96% and a Mean Reciprocal Rank (MRR) of 0.82. We also designed a graphical user interface that allows researchers to verify the model's performance with interactions.
* 10 pages, 7 figures, 4 tables
SaaFormer: Spectral-spatial Axial Aggregation Transformer for Hyperspectral Image Classification
Jul 04, 2023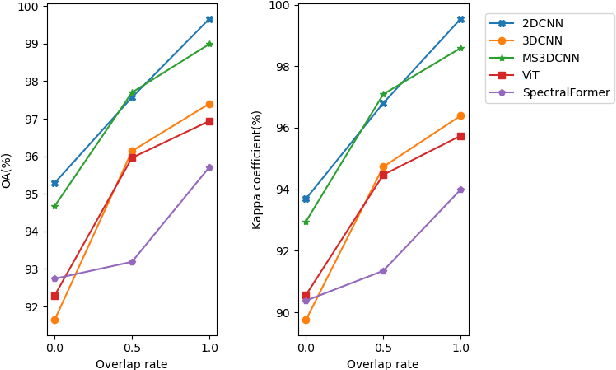
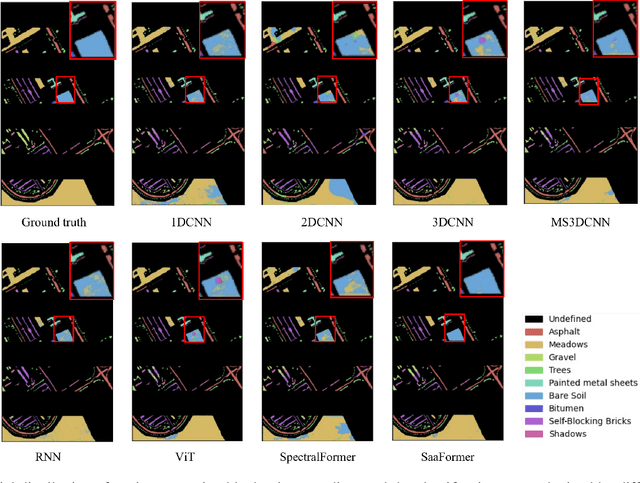
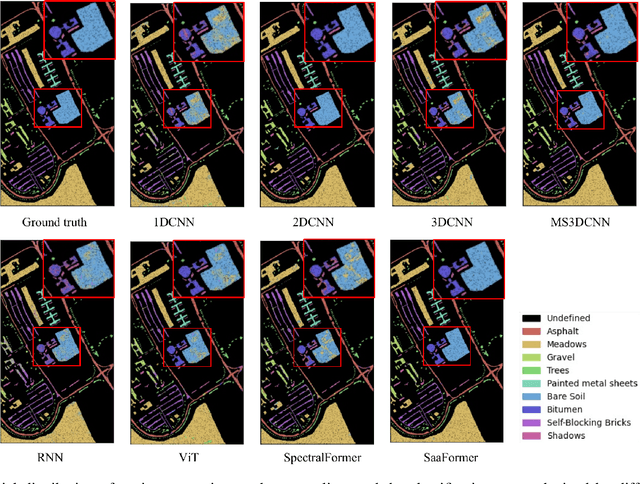
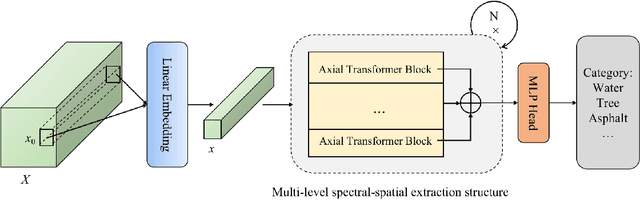
Hyperspectral images (HSI) captured from earth observing satellites and aircraft is becoming increasingly important for applications in agriculture, environmental monitoring, mining, etc. Due to the limited available hyperspectral datasets, the pixel-wise random sampling is the most commonly used training-test dataset partition approach, which has significant overlap between samples in training and test datasets. Furthermore, our experimental observations indicates that regions with larger overlap often exhibit higher classification accuracy. Consequently, the pixel-wise random sampling approach poses a risk of data leakage. Thus, we propose a block-wise sampling method to minimize the potential for data leakage. Our experimental findings also confirm the presence of data leakage in models such as 2DCNN. Further, We propose a spectral-spatial axial aggregation transformer model, namely SaaFormer, to address the challenges associated with hyperspectral image classifier that considers HSI as long sequential three-dimensional images. The model comprises two primary components: axial aggregation attention and multi-level spectral-spatial extraction. The axial aggregation attention mechanism effectively exploits the continuity and correlation among spectral bands at each pixel position in hyperspectral images, while aggregating spatial dimension features. This enables SaaFormer to maintain high precision even under block-wise sampling. The multi-level spectral-spatial extraction structure is designed to capture the sensitivity of different material components to specific spectral bands, allowing the model to focus on a broader range of spectral details. The results on six publicly available datasets demonstrate that our model exhibits comparable performance when using random sampling, while significantly outperforming other methods when employing block-wise sampling partition.
Scale Guided Hypernetwork for Blind Super-Resolution Image Quality Assessment
Jun 04, 2023
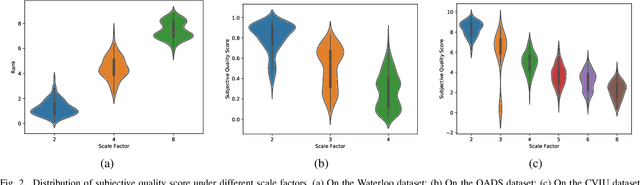
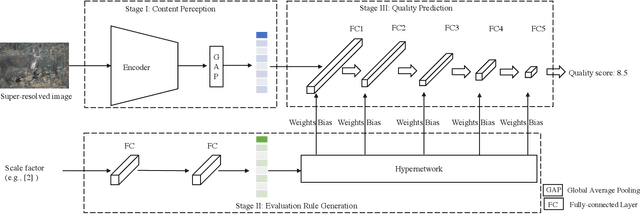
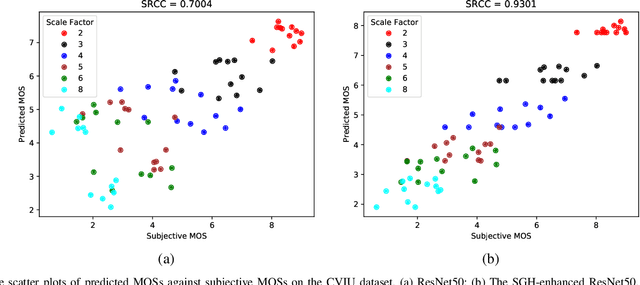
With the emergence of image super-resolution (SR) algorithm, how to blindly evaluate the quality of super-resolution images has become an urgent task. However, existing blind SR image quality assessment (IQA) metrics merely focus on visual characteristics of super-resolution images, ignoring the available scale information. In this paper, we reveal that the scale factor has a statistically significant impact on subjective quality scores of SR images, indicating that the scale information can be used to guide the task of blind SR IQA. Motivated by this, we propose a scale guided hypernetwork framework that evaluates SR image quality in a scale-adaptive manner. Specifically, the blind SR IQA procedure is divided into three stages, i.e., content perception, evaluation rule generation, and quality prediction. After content perception, a hypernetwork generates the evaluation rule used in quality prediction based on the scale factor of the SR image. We apply the proposed scale guided hypernetwork framework to existing representative blind IQA metrics, and experimental results show that the proposed framework not only boosts the performance of these IQA metrics but also enhances their generalization abilities. Source code will be available at https://github.com/JunFu1995/SGH.
GeneCIS: A Benchmark for General Conditional Image Similarity
Jun 13, 2023
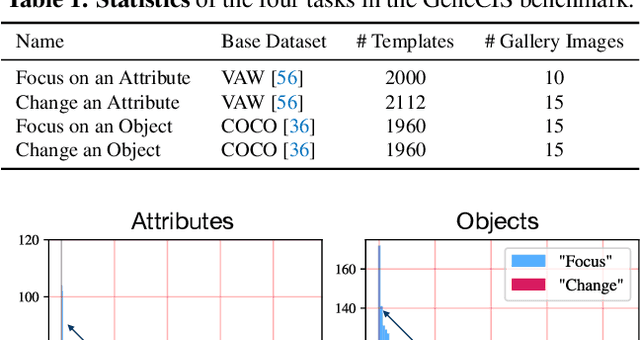

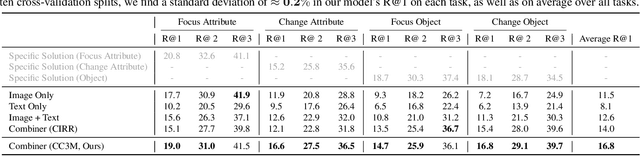
We argue that there are many notions of 'similarity' and that models, like humans, should be able to adapt to these dynamically. This contrasts with most representation learning methods, supervised or self-supervised, which learn a fixed embedding function and hence implicitly assume a single notion of similarity. For instance, models trained on ImageNet are biased towards object categories, while a user might prefer the model to focus on colors, textures or specific elements in the scene. In this paper, we propose the GeneCIS ('genesis') benchmark, which measures models' ability to adapt to a range of similarity conditions. Extending prior work, our benchmark is designed for zero-shot evaluation only, and hence considers an open-set of similarity conditions. We find that baselines from powerful CLIP models struggle on GeneCIS and that performance on the benchmark is only weakly correlated with ImageNet accuracy, suggesting that simply scaling existing methods is not fruitful. We further propose a simple, scalable solution based on automatically mining information from existing image-caption datasets. We find our method offers a substantial boost over the baselines on GeneCIS, and further improves zero-shot performance on related image retrieval benchmarks. In fact, though evaluated zero-shot, our model surpasses state-of-the-art supervised models on MIT-States. Project page at https://sgvaze.github.io/genecis/.
A Local Iterative Approach for the Extraction of 2D Manifolds from Strongly Curved and Folded Thin-Layer Structures
Aug 14, 2023Ridge surfaces represent important features for the analysis of 3-dimensional (3D) datasets in diverse applications and are often derived from varying underlying data including flow fields, geological fault data, and point data, but they can also be present in the original scalar images acquired using a plethora of imaging techniques. Our work is motivated by the analysis of image data acquired using micro-computed tomography (Micro-CT) of ancient, rolled and folded thin-layer structures such as papyrus, parchment, and paper as well as silver and lead sheets. From these documents we know that they are 2-dimensional (2D) in nature. Hence, we are particularly interested in reconstructing 2D manifolds that approximate the document's structure. The image data from which we want to reconstruct the 2D manifolds are often very noisy and represent folded, densely-layered structures with many artifacts, such as ruptures or layer splitting and merging. Previous ridge-surface extraction methods fail to extract the desired 2D manifold for such challenging data. We have therefore developed a novel method to extract 2D manifolds. The proposed method uses a local fast marching scheme in combination with a separation of the region covered by fast marching into two sub-regions. The 2D manifold of interest is then extracted as the surface separating the two sub-regions. The local scheme can be applied for both automatic propagation as well as interactive analysis. We demonstrate the applicability and robustness of our method on both artificial data as well as real-world data including folded silver and papyrus sheets.
Orthogonal Temporal Interpolation for Zero-Shot Video Recognition
Aug 14, 2023
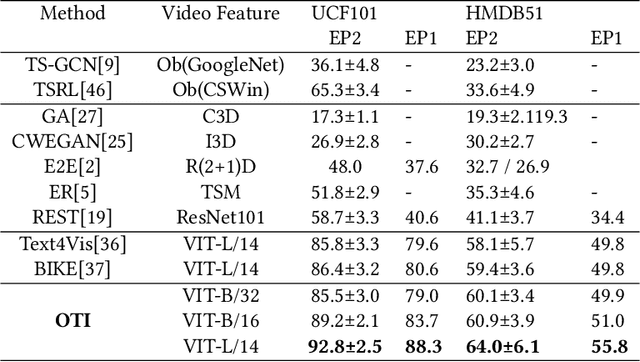
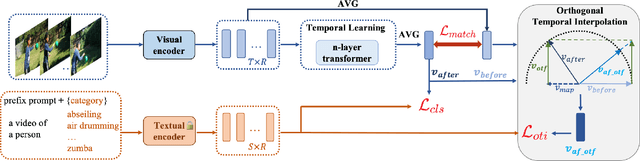
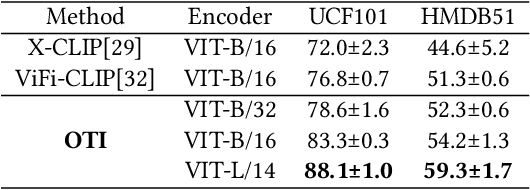
Zero-shot video recognition (ZSVR) is a task that aims to recognize video categories that have not been seen during the model training process. Recently, vision-language models (VLMs) pre-trained on large-scale image-text pairs have demonstrated impressive transferability for ZSVR. To make VLMs applicable to the video domain, existing methods often use an additional temporal learning module after the image-level encoder to learn the temporal relationships among video frames. Unfortunately, for video from unseen categories, we observe an abnormal phenomenon where the model that uses spatial-temporal feature performs much worse than the model that removes temporal learning module and uses only spatial feature. We conjecture that improper temporal modeling on video disrupts the spatial feature of the video. To verify our hypothesis, we propose Feature Factorization to retain the orthogonal temporal feature of the video and use interpolation to construct refined spatial-temporal feature. The model using appropriately refined spatial-temporal feature performs better than the one using only spatial feature, which verifies the effectiveness of the orthogonal temporal feature for the ZSVR task. Therefore, an Orthogonal Temporal Interpolation module is designed to learn a better refined spatial-temporal video feature during training. Additionally, a Matching Loss is introduced to improve the quality of the orthogonal temporal feature. We propose a model called OTI for ZSVR by employing orthogonal temporal interpolation and the matching loss based on VLMs. The ZSVR accuracies on popular video datasets (i.e., Kinetics-600, UCF101 and HMDB51) show that OTI outperforms the previous state-of-the-art method by a clear margin.
Phase Aberration Correction: A Deep Learning-Based Aberration to Aberration Approach
Aug 22, 2023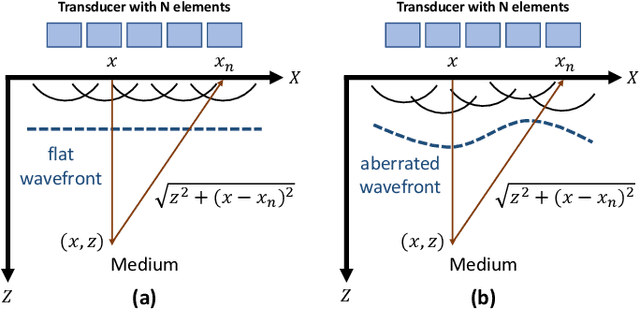

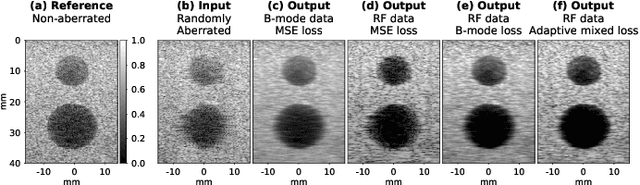
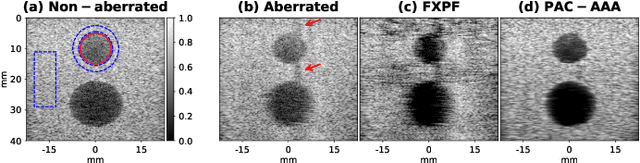
One of the primary sources of suboptimal image quality in ultrasound imaging is phase aberration. It is caused by spatial changes in sound speed over a heterogeneous medium, which disturbs the transmitted waves and prevents coherent summation of echo signals. Obtaining non-aberrated ground truths in real-world scenarios can be extremely challenging, if not impossible. This challenge hinders training of deep learning-based techniques' performance due to the presence of domain shift between simulated and experimental data. Here, for the first time, we propose a deep learning-based method that does not require ground truth to correct the phase aberration problem, and as such, can be directly trained on real data. We train a network wherein both the input and target output are randomly aberrated radio frequency (RF) data. Moreover, we demonstrate that a conventional loss function such as mean square error is inadequate for training such a network to achieve optimal performance. Instead, we propose an adaptive mixed loss function that employs both B-mode and RF data, resulting in more efficient convergence and enhanced performance. Finally, we publicly release our dataset, including 161,701 single plane-wave images (RF data). This dataset serves to mitigate the data scarcity problem in the development of deep learning-based techniques for phase aberration correction.
Knowledge-Aware Prompt Tuning for Generalizable Vision-Language Models
Aug 22, 2023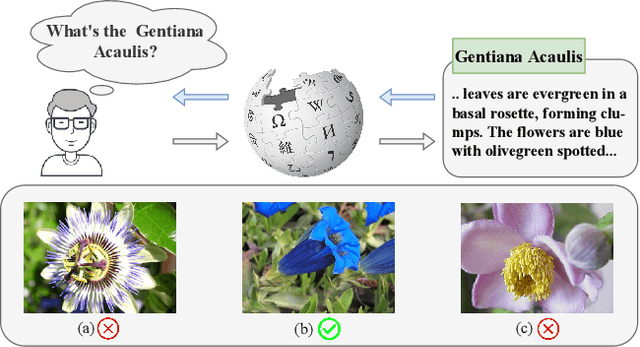
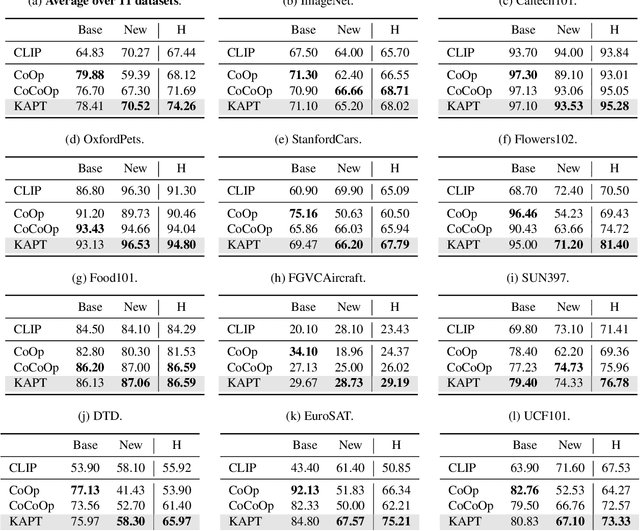
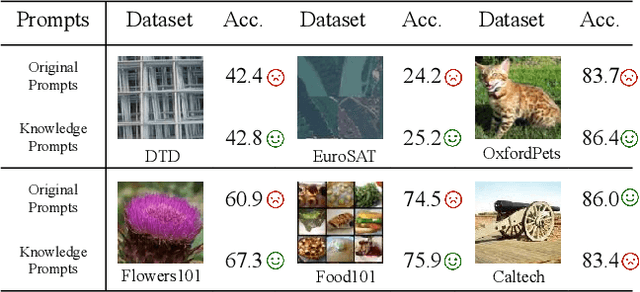

Pre-trained vision-language models, e.g., CLIP, working with manually designed prompts have demonstrated great capacity of transfer learning. Recently, learnable prompts achieve state-of-the-art performance, which however are prone to overfit to seen classes, failing to generalize to unseen classes. In this paper, we propose a Knowledge-Aware Prompt Tuning (KAPT) framework for vision-language models. Our approach takes inspiration from human intelligence in which external knowledge is usually incorporated into recognizing novel categories of objects. Specifically, we design two complementary types of knowledge-aware prompts for the text encoder to leverage the distinctive characteristics of category-related external knowledge. The discrete prompt extracts the key information from descriptions of an object category, and the learned continuous prompt captures overall contexts. We further design an adaptation head for the visual encoder to aggregate salient attentive visual cues, which establishes discriminative and task-aware visual representations. We conduct extensive experiments on 11 widely-used benchmark datasets and the results verify the effectiveness in few-shot image classification, especially in generalizing to unseen categories. Compared with the state-of-the-art CoCoOp method, KAPT exhibits favorable performance and achieves an absolute gain of 3.22% on new classes and 2.57% in terms of harmonic mean.
Delving into Motion-Aware Matching for Monocular 3D Object Tracking
Aug 22, 2023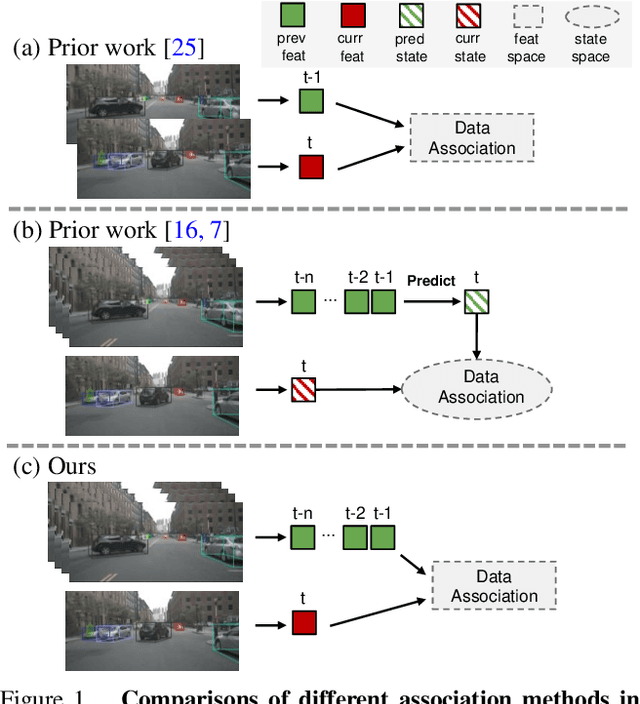
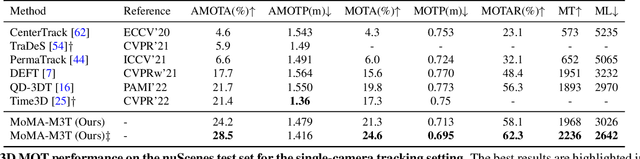
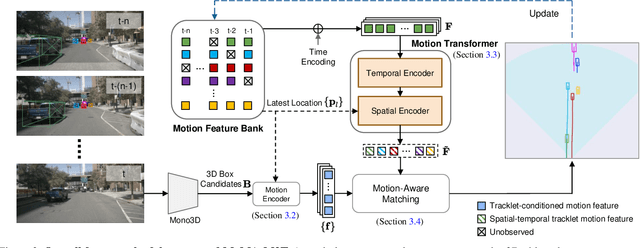

Recent advances of monocular 3D object detection facilitate the 3D multi-object tracking task based on low-cost camera sensors. In this paper, we find that the motion cue of objects along different time frames is critical in 3D multi-object tracking, which is less explored in existing monocular-based approaches. In this paper, we propose a motion-aware framework for monocular 3D MOT. To this end, we propose MoMA-M3T, a framework that mainly consists of three motion-aware components. First, we represent the possible movement of an object related to all object tracklets in the feature space as its motion features. Then, we further model the historical object tracklet along the time frame in a spatial-temporal perspective via a motion transformer. Finally, we propose a motion-aware matching module to associate historical object tracklets and current observations as final tracking results. We conduct extensive experiments on the nuScenes and KITTI datasets to demonstrate that our MoMA-M3T achieves competitive performance against state-of-the-art methods. Moreover, the proposed tracker is flexible and can be easily plugged into existing image-based 3D object detectors without re-training. Code and models are available at https://github.com/kuanchihhuang/MoMA-M3T.