 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Synthetic data generation method for hybrid image-tabular data using two generative adversarial networks
Aug 15, 2023
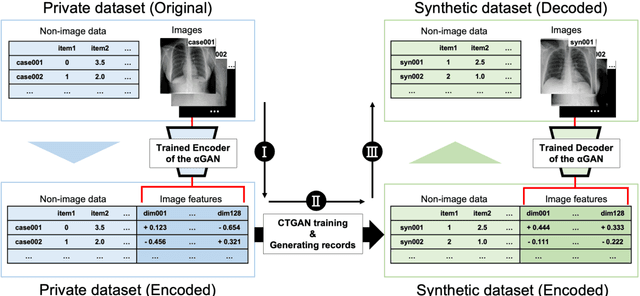

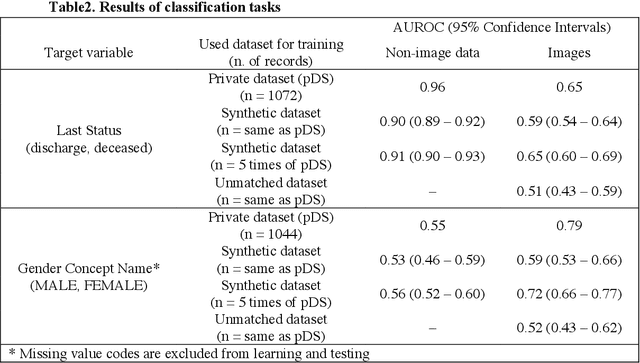
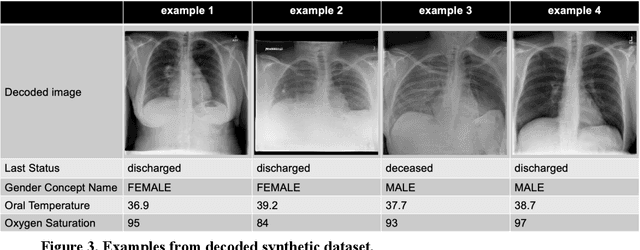
The generation of synthetic medical records using generative adversarial networks (GANs) has become increasingly important for addressing privacy concerns and promoting data sharing in the medical field. In this paper, we propose a novel method for generating synthetic hybrid medical records consisting of chest X-ray images (CXRs) and structured tabular data (including anthropometric data and laboratory tests) using an auto-encoding GAN ({\alpha}GAN) and a conditional tabular GAN (CTGAN). Our approach involves training a {\alpha}GAN model on a large public database (pDB) to reduce the dimensionality of CXRs. We then applied the trained encoder of the GAN model to the images in original database (oDB) to obtain the latent vectors. These latent vectors were combined with tabular data in oDB, and these joint data were used to train the CTGAN model. We successfully generated diverse synthetic records of hybrid CXR and tabular data, maintaining correspondence between them. We evaluated this synthetic database (sDB) through visual assessment, distribution of interrecord distances, and classification tasks. Our evaluation results showed that the sDB captured the features of the oDB while maintaining the correspondence between the images and tabular data. Although our approach relies on the availability of a large-scale pDB containing a substantial number of images with the same modality and imaging region as those in the oDB, this method has the potential for the public release of synthetic datasets without compromising the secondary use of data.
SA Unet Improved
Aug 18, 2023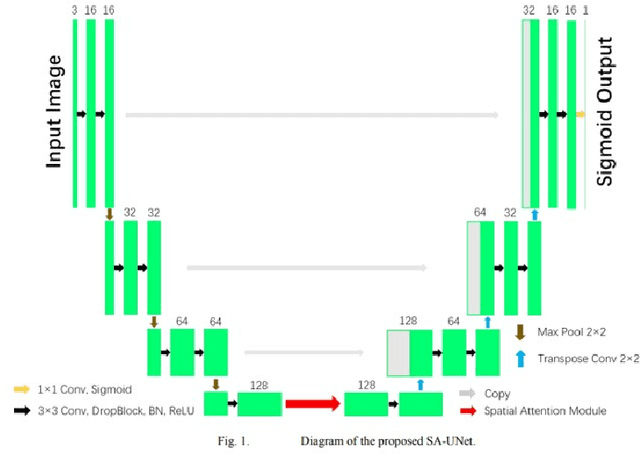
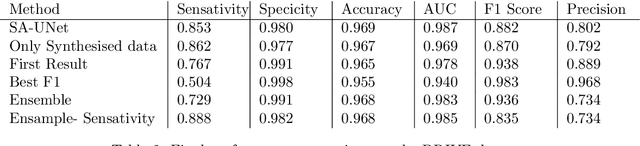
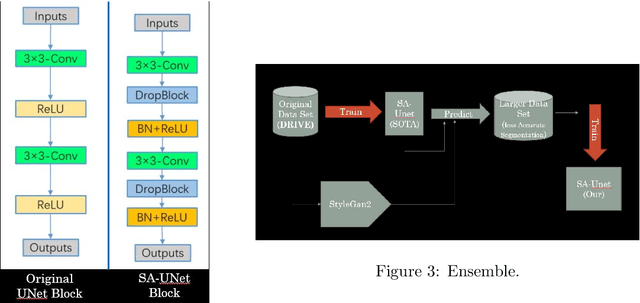
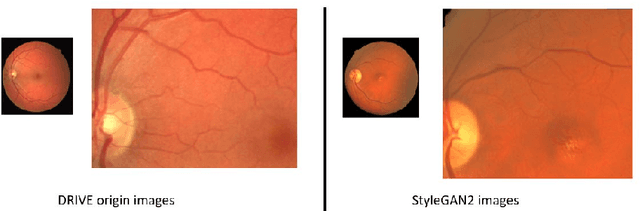
Retinal vessels segmentation is well known problem in image processing on the medical field. Good segmentation may help doctors take better decisions while diagnose eyes disuses. This paper describes our work taking up the DRIVE challenge which include segmentation on retinal vessels. We invented a new method which combine using of StyleGAN2 and SA-Unet. Our innovation can help any small data set segmentation problem.
Catalog Phrase Grounding (CPG): Grounding of Product Textual Attributes in Product Images for e-commerce Vision-Language Applications
Aug 30, 2023

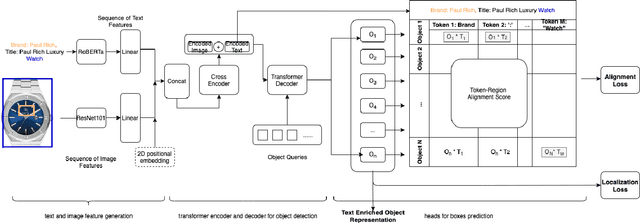
We present Catalog Phrase Grounding (CPG), a model that can associate product textual data (title, brands) into corresponding regions of product images (isolated product region, brand logo region) for e-commerce vision-language applications. We use a state-of-the-art modulated multimodal transformer encoder-decoder architecture unifying object detection and phrase-grounding. We train the model in self-supervised fashion with 2.3 million image-text pairs synthesized from an e-commerce site. The self-supervision data is annotated with high-confidence pseudo-labels generated with a combination of teacher models: a pre-trained general domain phrase grounding model (e.g. MDETR) and a specialized logo detection model. This allows CPG, as a student model, to benefit from transfer knowledge from these base models combining general-domain knowledge and specialized knowledge. Beyond immediate catalog phrase grounding tasks, we can benefit from CPG representations by incorporating them as ML features into downstream catalog applications that require deep semantic understanding of products. Our experiments on product-brand matching, a challenging e-commerce application, show that incorporating CPG representations into the existing production ensemble system leads to on average 5% recall improvement across all countries globally (with the largest lift of 11% in a single country) at fixed 95% precision, outperforming other alternatives including a logo detection teacher model and ResNet50.
DiffuVolume: Diffusion Model for Volume based Stereo Matching
Aug 30, 2023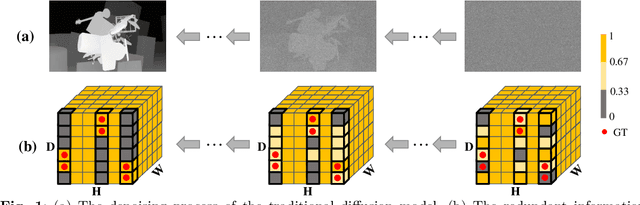

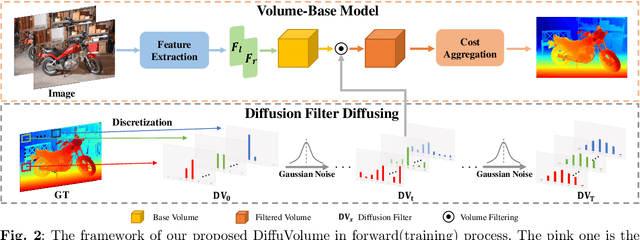
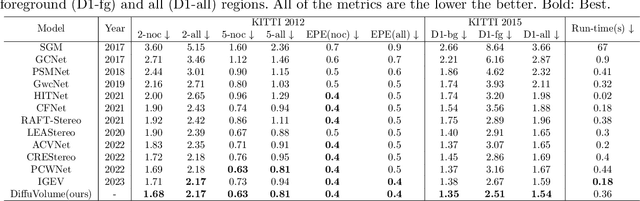
Stereo matching is a significant part in many computer vision tasks and driving-based applications. Recently cost volume-based methods have achieved great success benefiting from the rich geometry information in paired images. However, the redundancy of cost volume also interferes with the model training and limits the performance. To construct a more precise cost volume, we pioneeringly apply the diffusion model to stereo matching. Our method, termed DiffuVolume, considers the diffusion model as a cost volume filter, which will recurrently remove the redundant information from the cost volume. Two main designs make our method not trivial. Firstly, to make the diffusion model more adaptive to stereo matching, we eschew the traditional manner of directly adding noise into the image but embed the diffusion model into a task-specific module. In this way, we outperform the traditional diffusion stereo matching method by 22% EPE improvement and 240 times inference acceleration. Secondly, DiffuVolume can be easily embedded into any volume-based stereo matching network with boost performance but slight parameters rise (only 2%). By adding the DiffuVolume into well-performed methods, we outperform all the published methods on Scene Flow, KITTI2012, KITTI2015 benchmarks and zero-shot generalization setting. It is worth mentioning that the proposed model ranks 1st on KITTI 2012 leader board, 2nd on KITTI 2015 leader board since 15, July 2023.
Adaptive Multi-Modalities Fusion in Sequential Recommendation Systems
Aug 30, 2023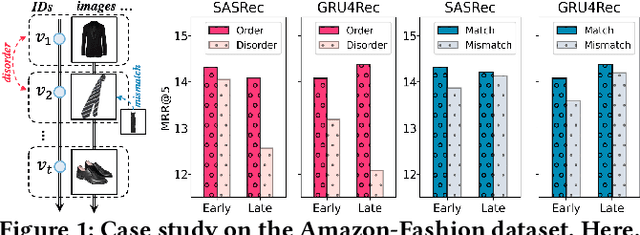
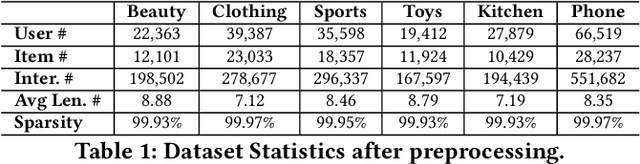
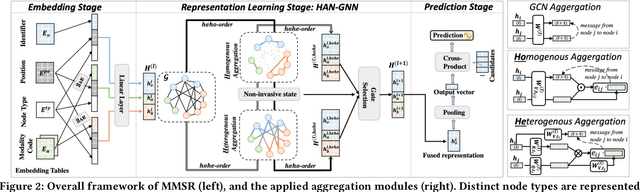
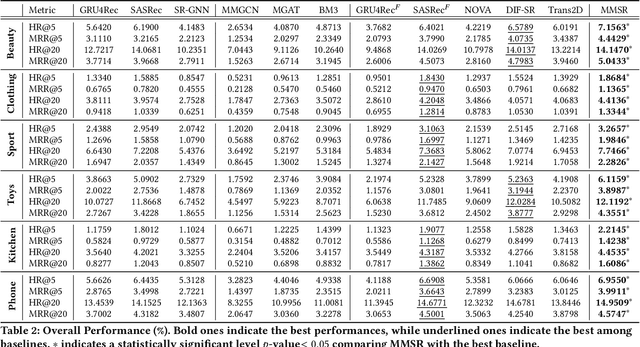
In sequential recommendation, multi-modal information (e.g., text or image) can provide a more comprehensive view of an item's profile. The optimal stage (early or late) to fuse modality features into item representations is still debated. We propose a graph-based approach (named MMSR) to fuse modality features in an adaptive order, enabling each modality to prioritize either its inherent sequential nature or its interplay with other modalities. MMSR represents each user's history as a graph, where the modality features of each item in a user's history sequence are denoted by cross-linked nodes. The edges between homogeneous nodes represent intra-modality sequential relationships, and the ones between heterogeneous nodes represent inter-modality interdependence relationships. During graph propagation, MMSR incorporates dual attention, differentiating homogeneous and heterogeneous neighbors. To adaptively assign nodes with distinct fusion orders, MMSR allows each node's representation to be asynchronously updated through an update gate. In scenarios where modalities exhibit stronger sequential relationships, the update gate prioritizes updates among homogeneous nodes. Conversely, when the interdependent relationships between modalities are more pronounced, the update gate prioritizes updates among heterogeneous nodes. Consequently, MMSR establishes a fusion order that spans a spectrum from early to late modality fusion. In experiments across six datasets, MMSR consistently outperforms state-of-the-art models, and our graph propagation methods surpass other graph neural networks. Additionally, MMSR naturally manages missing modalities.
Feature Decoupling-Recycling Network for Fast Interactive Segmentation
Aug 08, 2023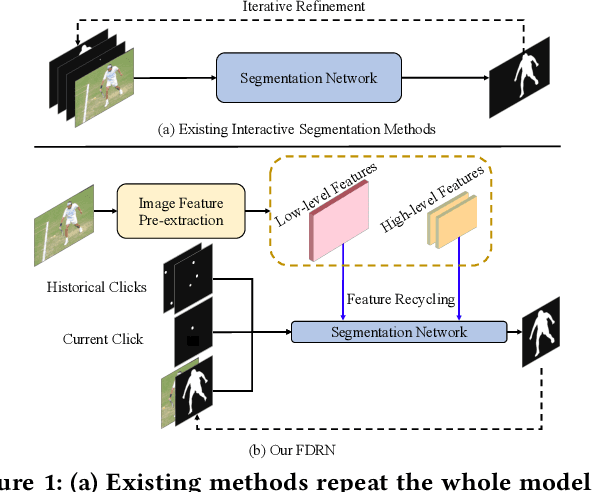
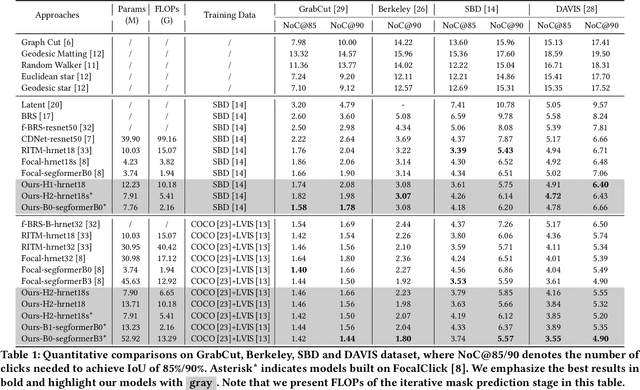
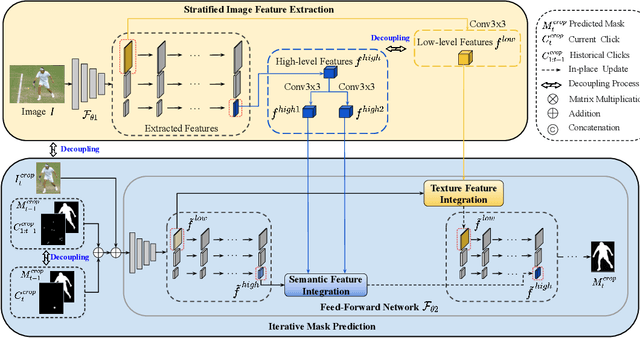
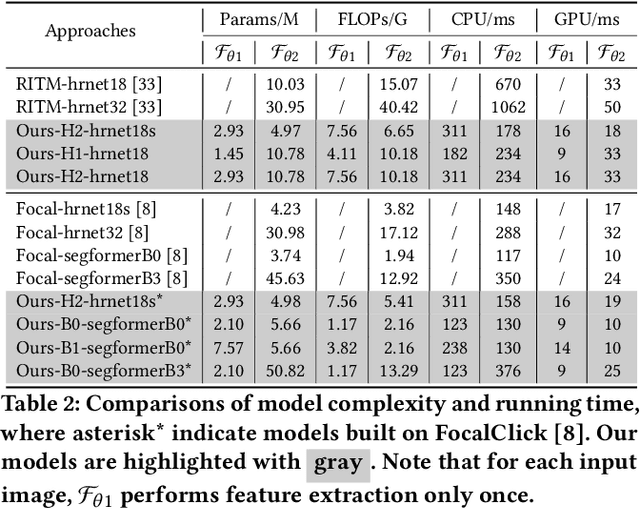
Recent interactive segmentation methods iteratively take source image, user guidance and previously predicted mask as the input without considering the invariant nature of the source image. As a result, extracting features from the source image is repeated in each interaction, resulting in substantial computational redundancy. In this work, we propose the Feature Decoupling-Recycling Network (FDRN), which decouples the modeling components based on their intrinsic discrepancies and then recycles components for each user interaction. Thus, the efficiency of the whole interactive process can be significantly improved. To be specific, we apply the Decoupling-Recycling strategy from three perspectives to address three types of discrepancies, respectively. First, our model decouples the learning of source image semantics from the encoding of user guidance to process two types of input domains separately. Second, FDRN decouples high-level and low-level features from stratified semantic representations to enhance feature learning. Third, during the encoding of user guidance, current user guidance is decoupled from historical guidance to highlight the effect of current user guidance. We conduct extensive experiments on 6 datasets from different domains and modalities, which demonstrate the following merits of our model: 1) superior efficiency than other methods, particularly advantageous in challenging scenarios requiring long-term interactions (up to 4.25x faster), while achieving favorable segmentation performance; 2) strong applicability to various methods serving as a universal enhancement technique; 3) well cross-task generalizability, e.g., to medical image segmentation, and robustness against misleading user guidance.
Grounded Text-to-Image Synthesis with Attention Refocusing
Jun 08, 2023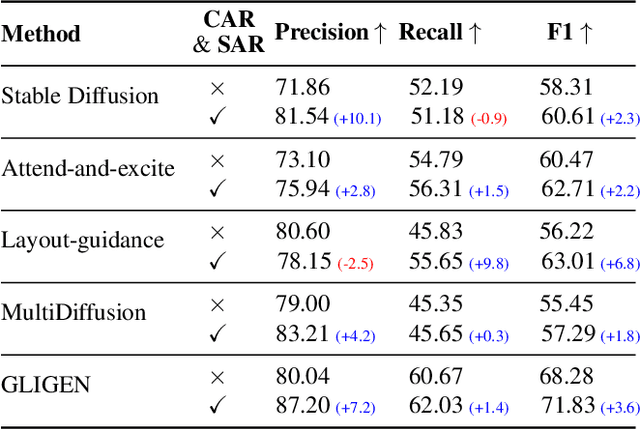
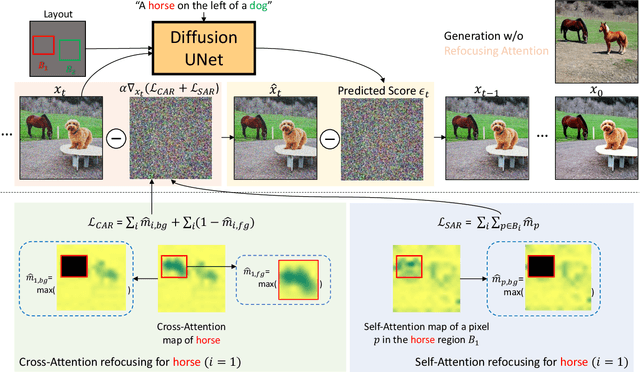
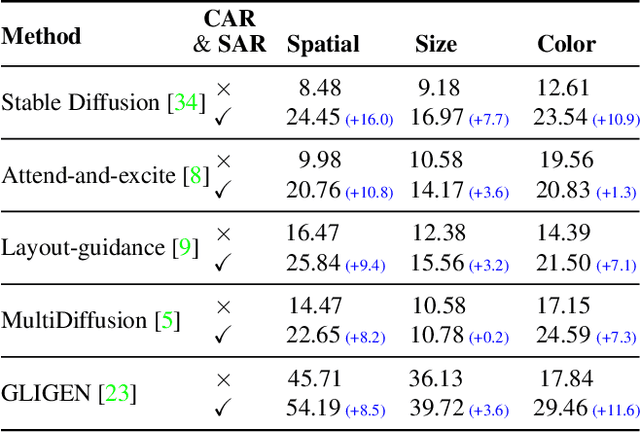
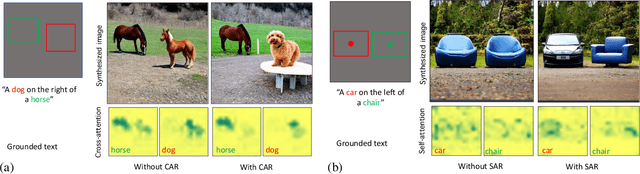
Driven by scalable diffusion models trained on large-scale paired text-image datasets, text-to-image synthesis methods have shown compelling results. However, these models still fail to precisely follow the text prompt when multiple objects, attributes, and spatial compositions are involved in the prompt. In this paper, we identify the potential reasons in both the cross-attention and self-attention layers of the diffusion model. We propose two novel losses to refocus the attention maps according to a given layout during the sampling process. We perform comprehensive experiments on the DrawBench and HRS benchmarks using layouts synthesized by Large Language Models, showing that our proposed losses can be integrated easily and effectively into existing text-to-image methods and consistently improve their alignment between the generated images and the text prompts.
ReFuSeg: Regularized Multi-Modal Fusion for Precise Brain Tumour Segmentation
Aug 26, 2023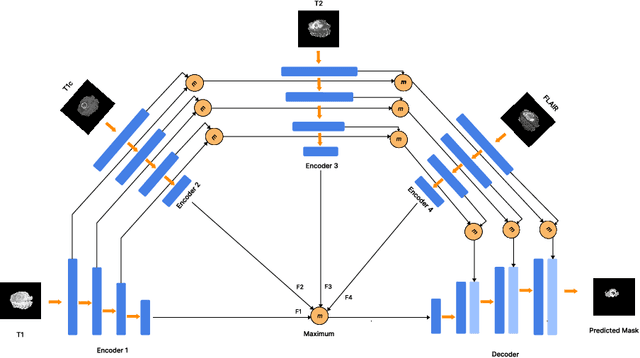
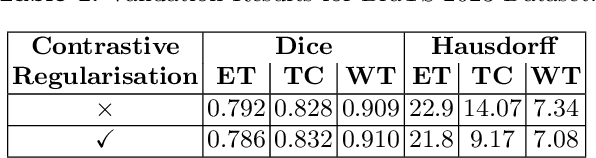
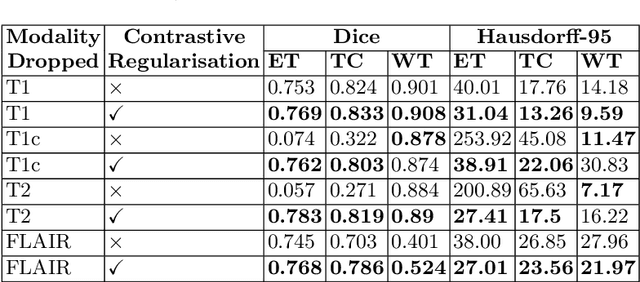
Semantic segmentation of brain tumours is a fundamental task in medical image analysis that can help clinicians in diagnosing the patient and tracking the progression of any malignant entities. Accurate segmentation of brain lesions is essential for medical diagnosis and treatment planning. However, failure to acquire specific MRI imaging modalities can prevent applications from operating in critical situations, raising concerns about their reliability and overall trustworthiness. This paper presents a novel multi-modal approach for brain lesion segmentation that leverages information from four distinct imaging modalities while being robust to real-world scenarios of missing modalities, such as T1, T1c, T2, and FLAIR MRI of brains. Our proposed method can help address the challenges posed by artifacts in medical imagery due to data acquisition errors (such as patient motion) or a reconstruction algorithm's inability to represent the anatomy while ensuring a trade-off in accuracy. Our proposed regularization module makes it robust to these scenarios and ensures the reliability of lesion segmentation.
Classification Committee for Active Deep Object Detection
Aug 22, 2023
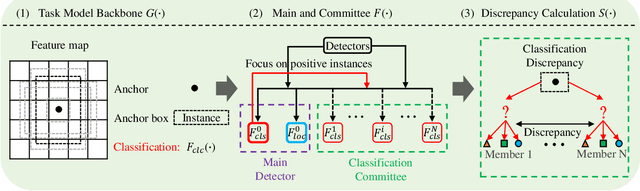
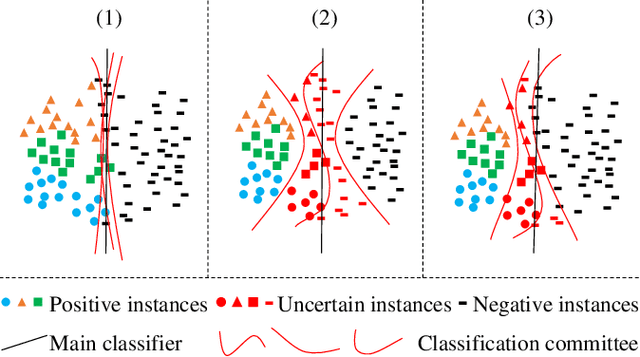
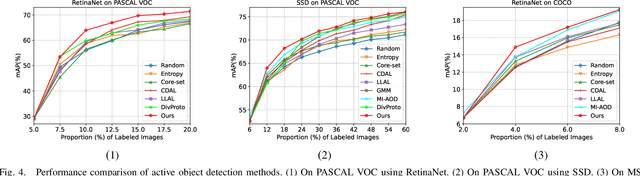
In object detection, the cost of labeling is much high because it needs not only to confirm the categories of multiple objects in an image but also to accurately determine the bounding boxes of each object. Thus, integrating active learning into object detection will raise pretty positive significance. In this paper, we propose a classification committee for active deep object detection method by introducing a discrepancy mechanism of multiple classifiers for samples' selection when training object detectors. The model contains a main detector and a classification committee. The main detector denotes the target object detector trained from a labeled pool composed of the selected informative images. The role of the classification committee is to select the most informative images according to their uncertainty values from the view of classification, which is expected to focus more on the discrepancy and representative of instances. Specifically, they compute the uncertainty for a specified instance within the image by measuring its discrepancy output by the committee pre-trained via the proposed Maximum Classifiers Discrepancy Group Loss (MCDGL). The most informative images are finally determined by selecting the ones with many high-uncertainty instances. Besides, to mitigate the impact of interference instances, we design a Focus on Positive Instances Loss (FPIL) to make the committee the ability to automatically focus on the representative instances as well as precisely encode their discrepancies for the same instance. Experiments are conducted on Pascal VOC and COCO datasets versus some popular object detectors. And results show that our method outperforms the state-of-the-art active learning methods, which verifies the effectiveness of the proposed method.
Masked Momentum Contrastive Learning for Zero-shot Semantic Understanding
Aug 22, 2023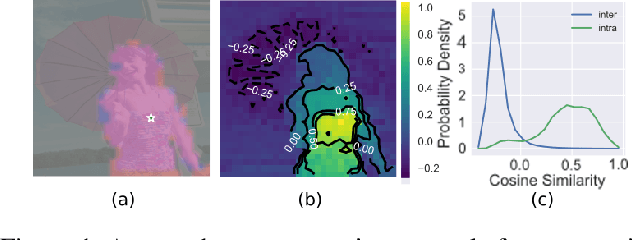
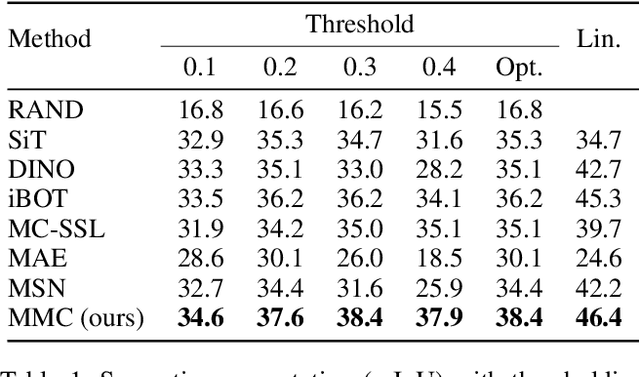
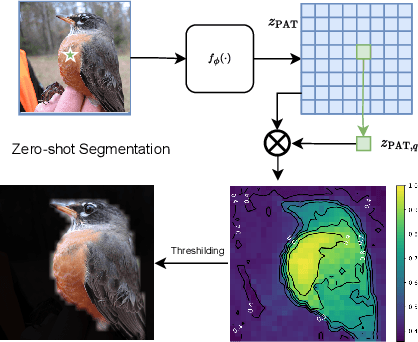
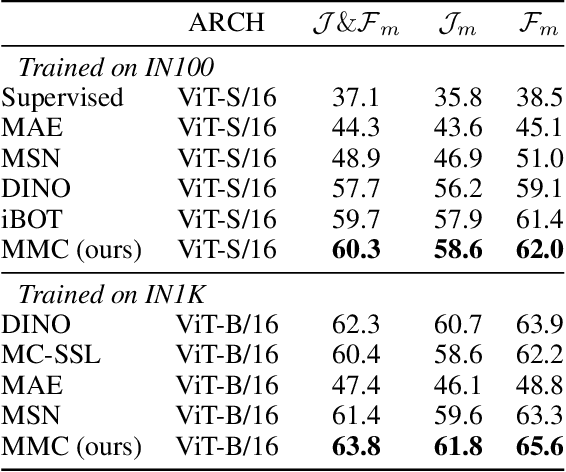
Self-supervised pretraining (SSP) has emerged as a popular technique in machine learning, enabling the extraction of meaningful feature representations without labelled data. In the realm of computer vision, pretrained vision transformers (ViTs) have played a pivotal role in advancing transfer learning. Nonetheless, the escalating cost of finetuning these large models has posed a challenge due to the explosion of model size. This study endeavours to evaluate the effectiveness of pure self-supervised learning (SSL) techniques in computer vision tasks, obviating the need for finetuning, with the intention of emulating human-like capabilities in generalisation and recognition of unseen objects. To this end, we propose an evaluation protocol for zero-shot segmentation based on a prompting patch. Given a point on the target object as a prompt, the algorithm calculates the similarity map between the selected patch and other patches, upon that, a simple thresholding is applied to segment the target. Another evaluation is intra-object and inter-object similarity to gauge discriminatory ability of SSP ViTs. Insights from zero-shot segmentation from prompting and discriminatory abilities of SSP led to the design of a simple SSP approach, termed MMC. This approaches combines Masked image modelling for encouraging similarity of local features, Momentum based self-distillation for transferring semantics from global to local features, and global Contrast for promoting semantics of global features, to enhance discriminative representations of SSP ViTs. Consequently, our proposed method significantly reduces the overlap of intra-object and inter-object similarities, thereby facilitating effective object segmentation within an image. Our experiments reveal that MMC delivers top-tier results in zero-shot semantic segmentation across various datasets.