 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FG-Net: Facial Action Unit Detection with Generalizable Pyramidal Features
Aug 23, 2023
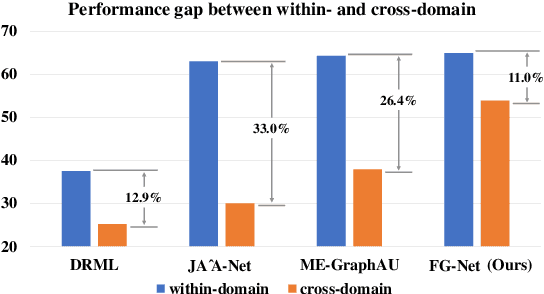
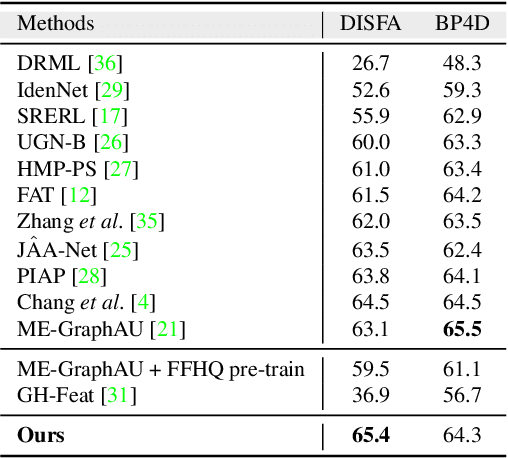
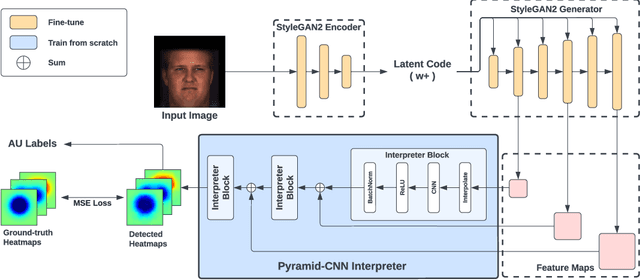
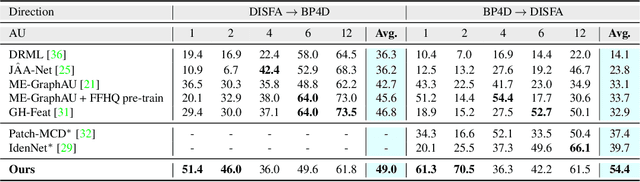
Automatic detection of facial Action Units (AUs) allows for objective facial expression analysis. Due to the high cost of AU labeling and the limited size of existing benchmarks, previous AU detection methods tend to overfit the dataset, resulting in a significant performance loss when evaluated across corpora. To address this problem, we propose FG-Net for generalizable facial action unit detection. Specifically, FG-Net extracts feature maps from a StyleGAN2 model pre-trained on a large and diverse face image dataset. Then, these features are used to detect AUs with a Pyramid CNN Interpreter, making the training efficient and capturing essential local features. The proposed FG-Net achieves a strong generalization ability for heatmap-based AU detection thanks to the generalizable and semantic-rich features extracted from the pre-trained generative model. Extensive experiments are conducted to evaluate within- and cross-corpus AU detection with the widely-used DISFA and BP4D datasets. Compared with the state-of-the-art, the proposed method achieves superior cross-domain performance while maintaining competitive within-domain performance. In addition, FG-Net is data-efficient and achieves competitive performance even when trained on 1000 samples. Our code will be released at \url{https://github.com/ihp-lab/FG-Net}
ARF-Plus: Controlling Perceptual Factors in Artistic Radiance Fields for 3D Scene Stylization
Aug 23, 2023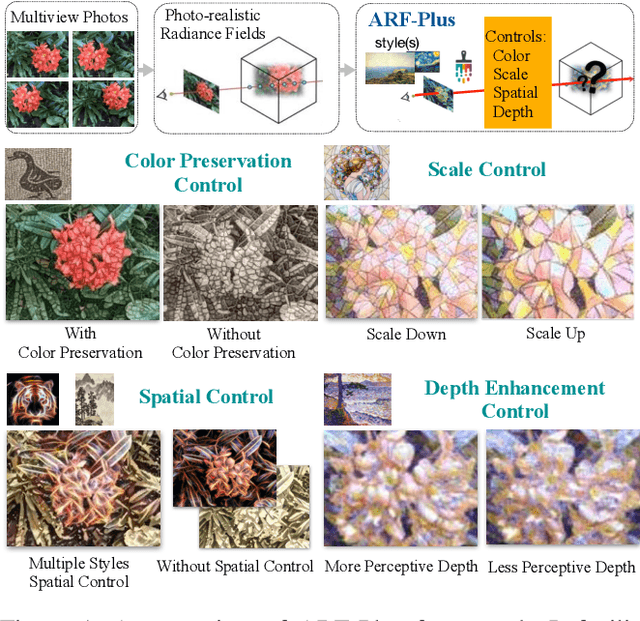
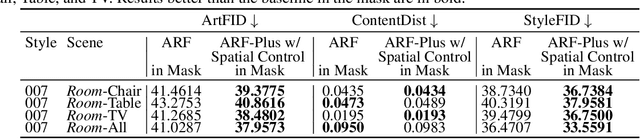

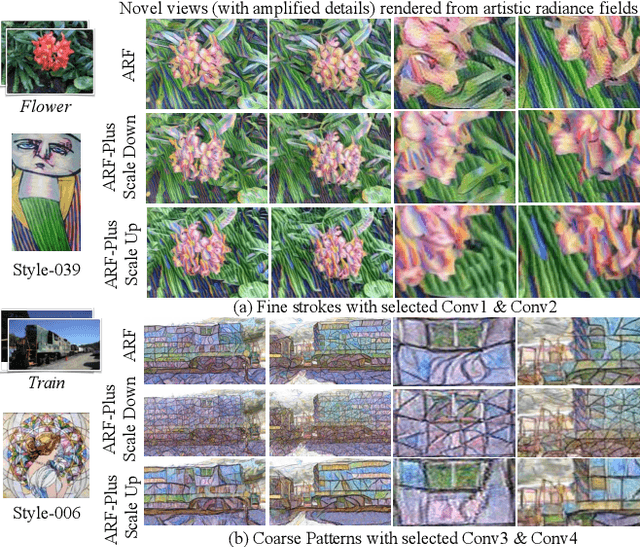
The radiance fields style transfer is an emerging field that has recently gained popularity as a means of 3D scene stylization, thanks to the outstanding performance of neural radiance fields in 3D reconstruction and view synthesis. We highlight a research gap in radiance fields style transfer, the lack of sufficient perceptual controllability, motivated by the existing concept in the 2D image style transfer. In this paper, we present ARF-Plus, a 3D neural style transfer framework offering manageable control over perceptual factors, to systematically explore the perceptual controllability in 3D scene stylization. Four distinct types of controls - color preservation control, (style pattern) scale control, spatial (selective stylization area) control, and depth enhancement control - are proposed and integrated into this framework. Results from real-world datasets, both quantitative and qualitative, show that the four types of controls in our ARF-Plus framework successfully accomplish their corresponding perceptual controls when stylizing 3D scenes. These techniques work well for individual style inputs as well as for the simultaneous application of multiple styles within a scene. This unlocks a realm of limitless possibilities, allowing customized modifications of stylization effects and flexible merging of the strengths of different styles, ultimately enabling the creation of novel and eye-catching stylistic effects on 3D scenes.
Classification Committee for Active Deep Object Detection
Aug 16, 2023
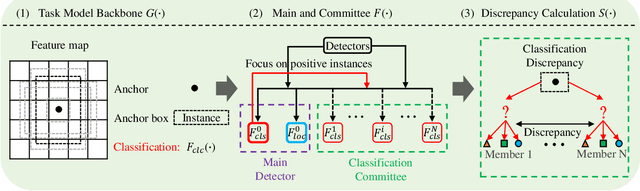
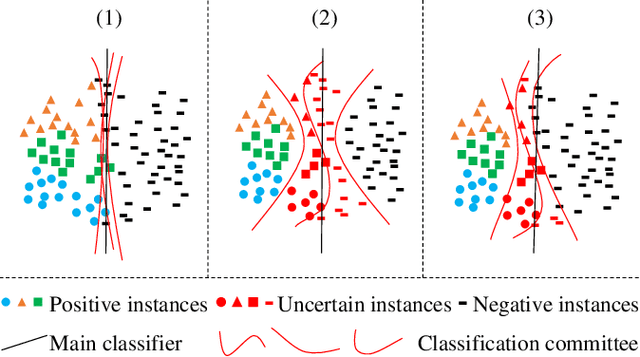
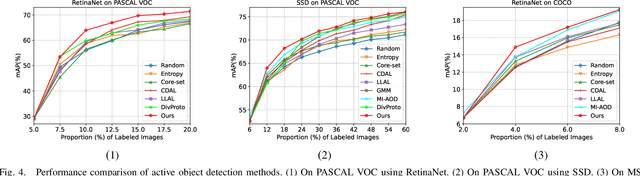
In object detection, the cost of labeling is much high because it needs not only to confirm the categories of multiple objects in an image but also to accurately determine the bounding boxes of each object. Thus, integrating active learning into object detection will raise pretty positive significance. In this paper, we propose a classification committee for active deep object detection method by introducing a discrepancy mechanism of multiple classifiers for samples' selection when training object detectors. The model contains a main detector and a classification committee. The main detector denotes the target object detector trained from a labeled pool composed of the selected informative images. The role of the classification committee is to select the most informative images according to their uncertainty values from the view of classification, which is expected to focus more on the discrepancy and representative of instances. Specifically, they compute the uncertainty for a specified instance within the image by measuring its discrepancy output by the committee pre-trained via the proposed Maximum Classifiers Discrepancy Group Loss (MCDGL). The most informative images are finally determined by selecting the ones with many high-uncertainty instances. Besides, to mitigate the impact of interference instances, we design a Focus on Positive Instances Loss (FPIL) to make the committee the ability to automatically focus on the representative instances as well as precisely encode their discrepancies for the same instance. Experiments are conducted on Pascal VOC and COCO datasets versus some popular object detectors. And results show that our method outperforms the state-of-the-art active learning methods, which verifies the effectiveness of the proposed method.
A free from local minima algorithm for training regressive MLP neural networks
Aug 22, 2023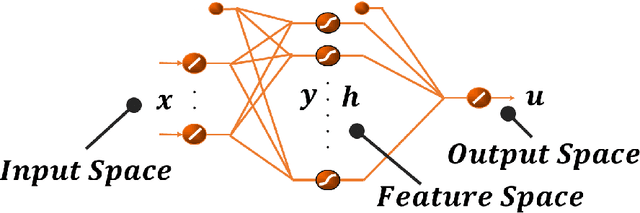
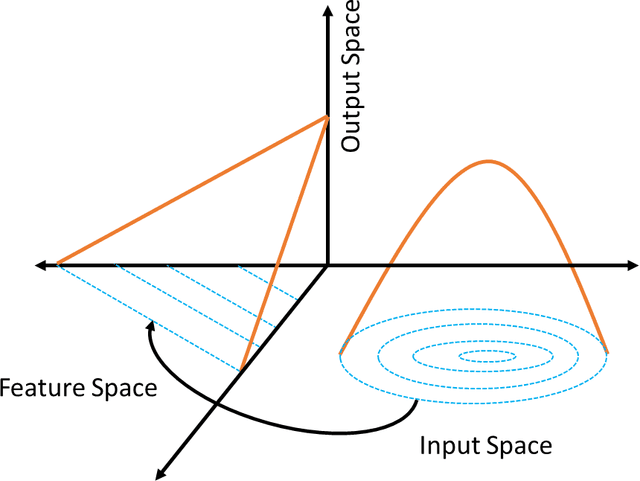
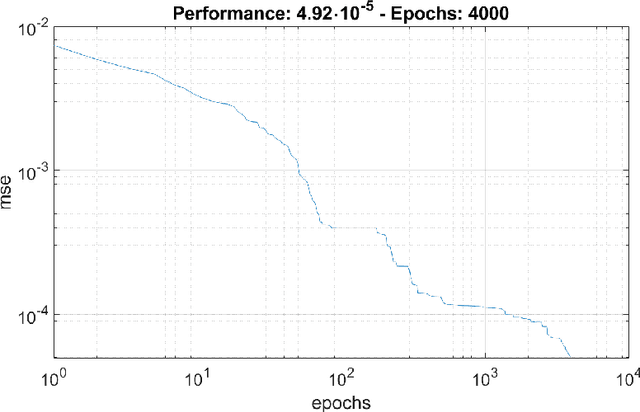
In this article an innovative method for training regressive MLP networks is presented, which is not subject to local minima. The Error-Back-Propagation algorithm, proposed by William-Hinton-Rummelhart, has had the merit of favouring the development of machine learning techniques, which has permeated every branch of research and technology since the mid-1980s. This extraordinary success is largely due to the black-box approach, but this same factor was also seen as a limitation, as soon more challenging problems were approached. One of the most critical aspects of the training algorithms was that of local minima of the loss function, typically the mean squared error of the output on the training set. In fact, as the most popular training algorithms are driven by the derivatives of the loss function, there is no possibility to evaluate if a reached minimum is local or global. The algorithm presented in this paper avoids the problem of local minima, as the training is based on the properties of the distribution of the training set, or better on its image internal to the neural network. The performance of the algorithm is shown for a well-known benchmark.
Beyond Discriminative Regions: Saliency Maps as Alternatives to CAMs for Weakly Supervised Semantic Segmentation
Aug 21, 2023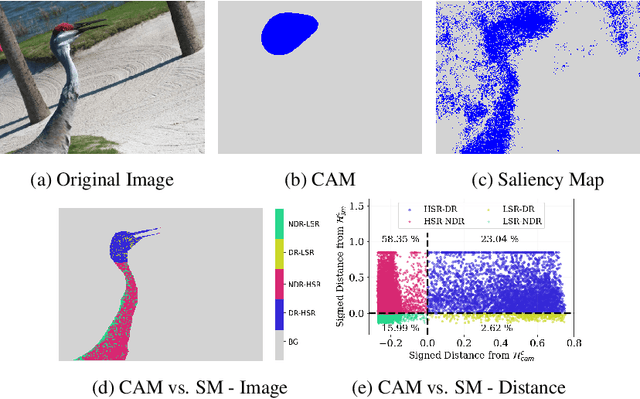
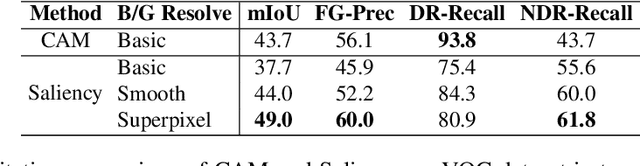
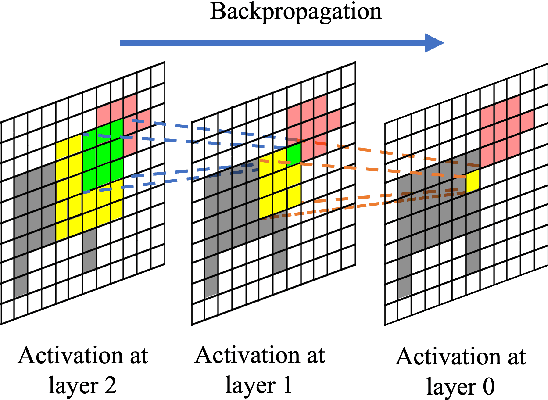
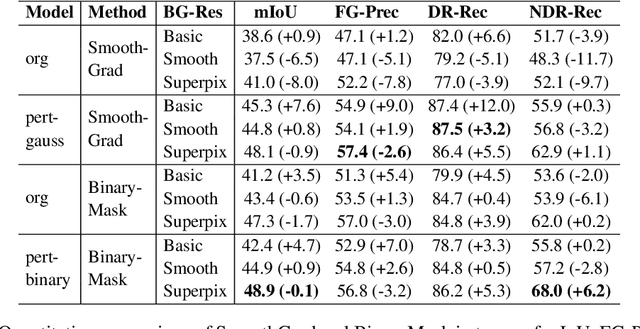
In recent years, several Weakly Supervised Semantic Segmentation (WS3) methods have been proposed that use class activation maps (CAMs) generated by a classifier to produce pseudo-ground truths for training segmentation models. While CAMs are good at highlighting discriminative regions (DR) of an image, they are known to disregard regions of the object that do not contribute to the classifier's prediction, termed non-discriminative regions (NDR). In contrast, attribution methods such as saliency maps provide an alternative approach for assigning a score to every pixel based on its contribution to the classification prediction. This paper provides a comprehensive comparison between saliencies and CAMs for WS3. Our study includes multiple perspectives on understanding their similarities and dissimilarities. Moreover, we provide new evaluation metrics that perform a comprehensive assessment of WS3 performance of alternative methods w.r.t. CAMs. We demonstrate the effectiveness of saliencies in addressing the limitation of CAMs through our empirical studies on benchmark datasets. Furthermore, we propose random cropping as a stochastic aggregation technique that improves the performance of saliency, making it a strong alternative to CAM for WS3.
Exploring Resolution Fields for Scalable Image Compression with Uncertainty Guidance
Jun 15, 2023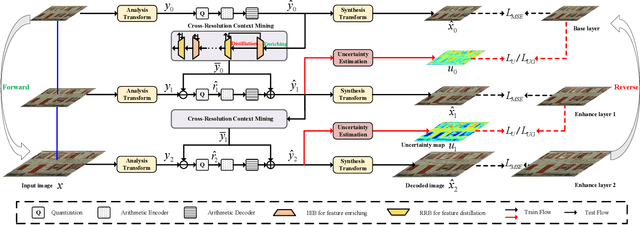

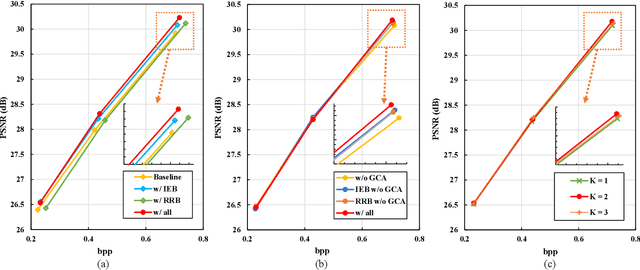

Recently, there are significant advancements in learning-based image compression methods surpassing traditional coding standards. Most of them prioritize achieving the best rate-distortion performance for a particular compression rate, which limits their flexibility and adaptability in various applications with complex and varying constraints. In this work, we explore the potential of resolution fields in scalable image compression and propose the reciprocal pyramid network (RPN) that fulfills the need for more adaptable and versatile compression. Specifically, RPN first builds a compression pyramid and generates the resolution fields at different levels in a top-down manner. The key design lies in the cross-resolution context mining module between adjacent levels, which performs feature enriching and distillation to mine meaningful contextualized information and remove unnecessary redundancy, producing informative resolution fields as residual priors. The scalability is achieved by progressive bitstream reusing and resolution field incorporation varying at different levels. Furthermore, between adjacent compression levels, we explicitly quantify the aleatoric uncertainty from the bottom decoded representations and develop an uncertainty-guided loss to update the upper-level compression parameters, forming a reverse pyramid process that enforces the network to focus on the textured pixels with high variance for more reliable and accurate reconstruction. Combining resolution field exploration and uncertainty guidance in a pyramid manner, RPN can effectively achieve spatial and quality scalable image compression. Experiments show the superiority of RPN against existing classical and deep learning-based scalable codecs. Code will be available at https://github.com/JGIroro/RPNSIC.
Norm-guided latent space exploration for text-to-image generation
Jun 14, 2023
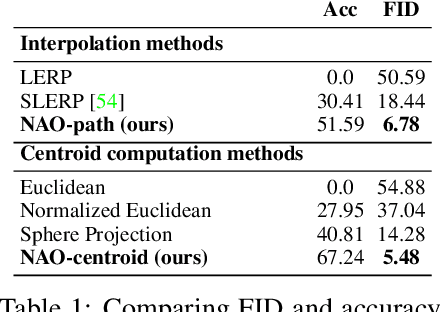
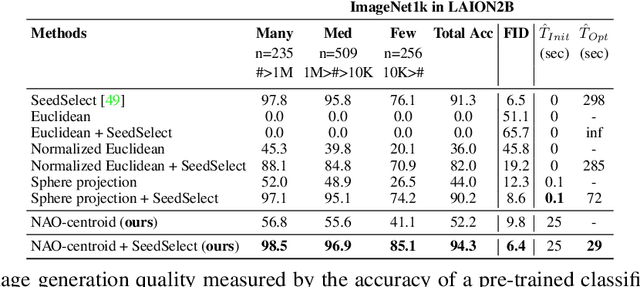

Text-to-image diffusion models show great potential in synthesizing a large variety of concepts in new compositions and scenarios. However, their latent seed space is still not well understood and has been shown to have an impact in generating new and rare concepts. Specifically, simple operations like interpolation and centroid finding work poorly with the standard Euclidean and spherical metrics in the latent space. This paper makes the observation that current training procedures make diffusion models biased toward inputs with a narrow range of norm values. This has strong implications for methods that rely on seed manipulation for image generation that can be further applied to few-shot and long-tail learning tasks. To address this issue, we propose a novel method for interpolating between two seeds and demonstrate that it defines a new non-Euclidean metric that takes into account a norm-based prior on seeds. We describe a simple yet efficient algorithm for approximating this metric and use it to further define centroids in the latent seed space. We show that our new interpolation and centroid evaluation techniques significantly enhance the generation of rare concept images. This further leads to state-of-the-art performance on few-shot and long-tail benchmarks, improving prior approach in terms of generation speed, image quality, and semantic content.
Exploring the Impact of Image Resolution on Chest X-ray Classification Performance
Jun 09, 2023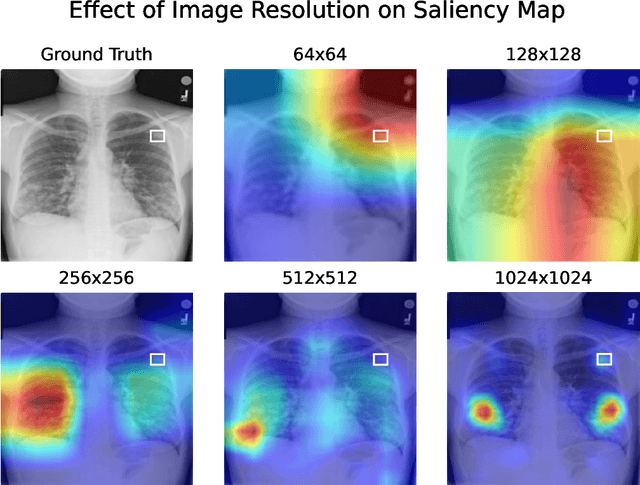
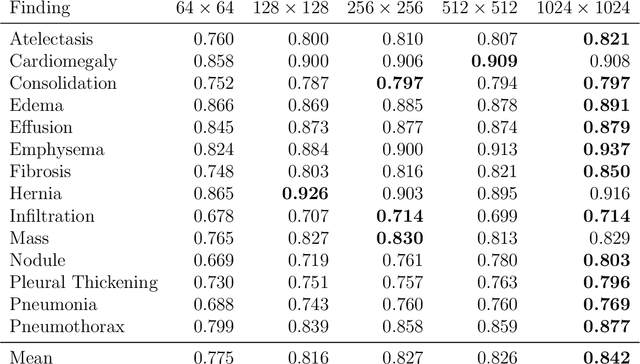
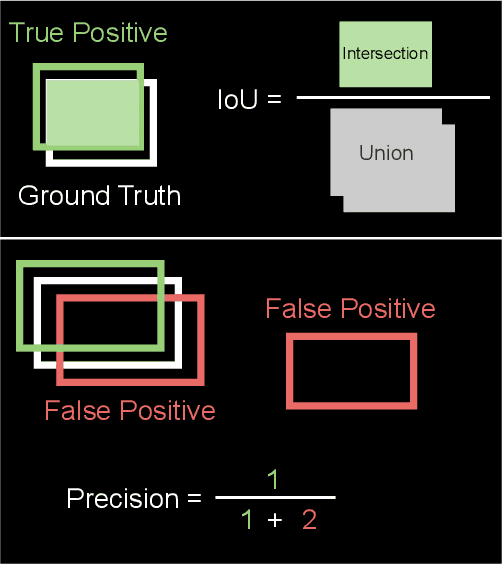
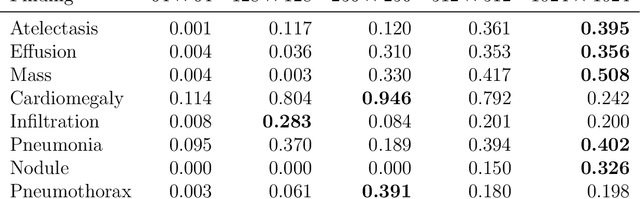
Deep learning models for image classification have often used a resolution of $224\times224$ pixels for computational reasons. This study investigates the effect of image resolution on chest X-ray classification performance, using the ChestX-ray14 dataset. The results show that a higher image resolution, specifically $1024\times1024$ pixels, has the best overall classification performance, with a slight decline in performance between $256\times256$ to $512\times512$ pixels for most of the pathological classes. Comparison of saliency map-generated bounding boxes revealed that commonly used resolutions are insufficient for finding most pathologies.
Generative Approach for Probabilistic Human Mesh Recovery using Diffusion Models
Aug 05, 2023
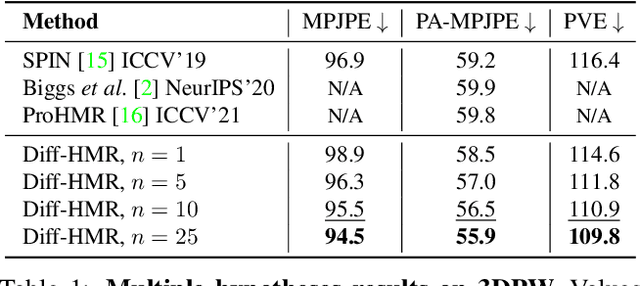
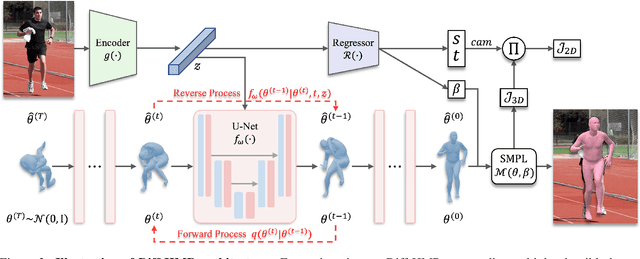

This work focuses on the problem of reconstructing a 3D human body mesh from a given 2D image. Despite the inherent ambiguity of the task of human mesh recovery, most existing works have adopted a method of regressing a single output. In contrast, we propose a generative approach framework, called "Diffusion-based Human Mesh Recovery (Diff-HMR)" that takes advantage of the denoising diffusion process to account for multiple plausible outcomes. During the training phase, the SMPL parameters are diffused from ground-truth parameters to random distribution, and Diff-HMR learns the reverse process of this diffusion. In the inference phase, the model progressively refines the given random SMPL parameters into the corresponding parameters that align with the input image. Diff-HMR, being a generative approach, is capable of generating diverse results for the same input image as the input noise varies. We conduct validation experiments, and the results demonstrate that the proposed framework effectively models the inherent ambiguity of the task of human mesh recovery in a probabilistic manner. The code is available at https://github.com/hanbyel0105/Diff-HMR
HIDFlowNet: A Flow-Based Deep Network for Hyperspectral Image Denoising
Jun 20, 2023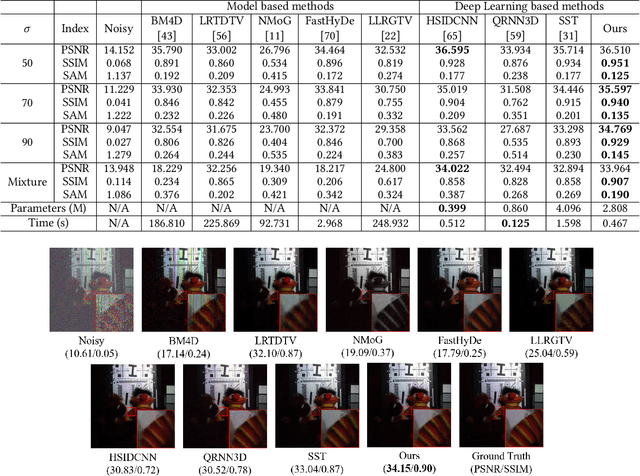
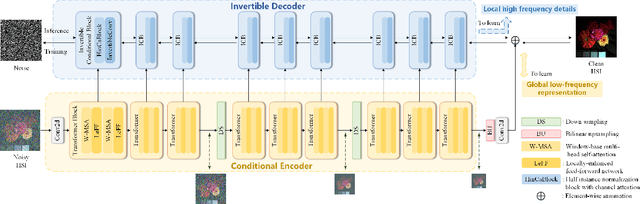
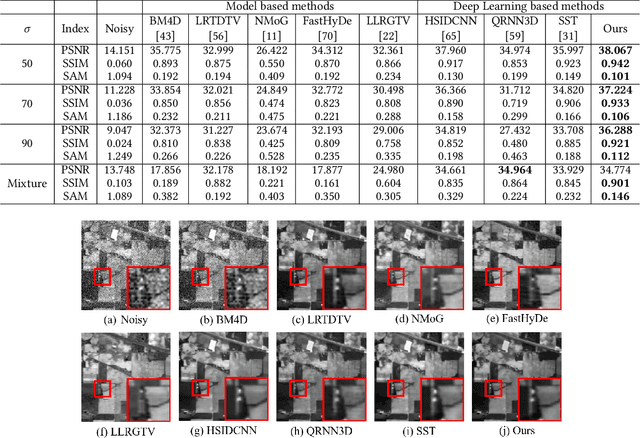
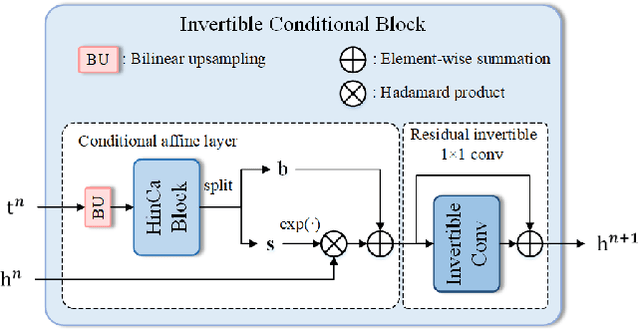
Hyperspectral image (HSI) denoising is essentially ill-posed since a noisy HSI can be degraded from multiple clean HSIs. However, current deep learning-based approaches ignore this fact and restore the clean image with deterministic mapping (i.e., the network receives a noisy HSI and outputs a clean HSI). To alleviate this issue, this paper proposes a flow-based HSI denoising network (HIDFlowNet) to directly learn the conditional distribution of the clean HSI given the noisy HSI and thus diverse clean HSIs can be sampled from the conditional distribution. Overall, our HIDFlowNet is induced from the flow methodology and contains an invertible decoder and a conditional encoder, which can fully decouple the learning of low-frequency and high-frequency information of HSI. Specifically, the invertible decoder is built by staking a succession of invertible conditional blocks (ICBs) to capture the local high-frequency details since the invertible network is information-lossless. The conditional encoder utilizes down-sampling operations to obtain low-resolution images and uses transformers to capture correlations over a long distance so that global low-frequency information can be effectively extracted. Extensive experimental results on simulated and real HSI datasets verify the superiority of our proposed HIDFlowNet compared with other state-of-the-art methods both quantitatively and visually.