 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HIDFlowNet: A Flow-Based Deep Network for Hyperspectral Image Denoising
Jun 20, 2023
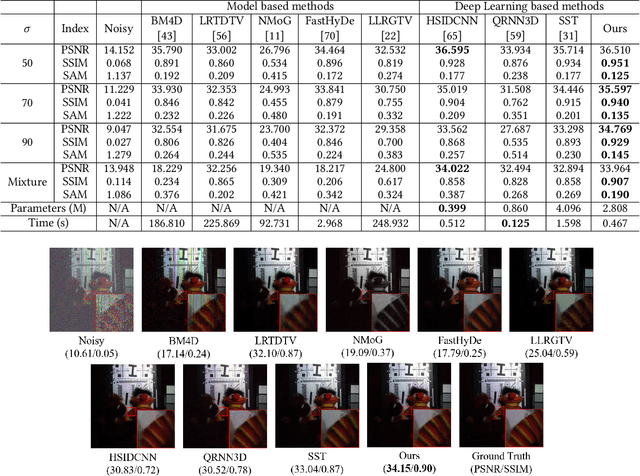
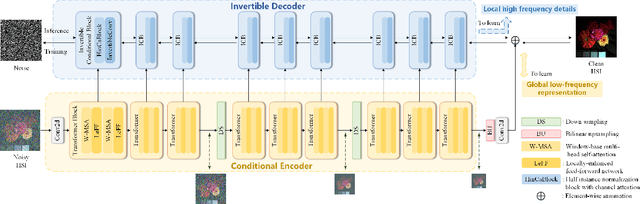
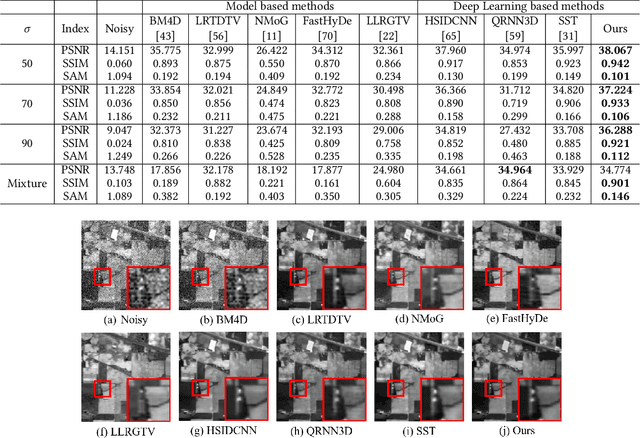
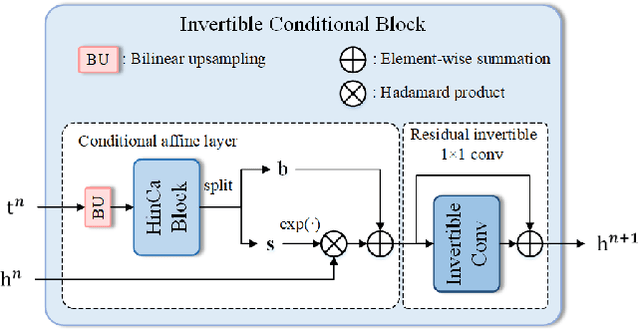
Hyperspectral image (HSI) denoising is essentially ill-posed since a noisy HSI can be degraded from multiple clean HSIs. However, current deep learning-based approaches ignore this fact and restore the clean image with deterministic mapping (i.e., the network receives a noisy HSI and outputs a clean HSI). To alleviate this issue, this paper proposes a flow-based HSI denoising network (HIDFlowNet) to directly learn the conditional distribution of the clean HSI given the noisy HSI and thus diverse clean HSIs can be sampled from the conditional distribution. Overall, our HIDFlowNet is induced from the flow methodology and contains an invertible decoder and a conditional encoder, which can fully decouple the learning of low-frequency and high-frequency information of HSI. Specifically, the invertible decoder is built by staking a succession of invertible conditional blocks (ICBs) to capture the local high-frequency details since the invertible network is information-lossless. The conditional encoder utilizes down-sampling operations to obtain low-resolution images and uses transformers to capture correlations over a long distance so that global low-frequency information can be effectively extracted. Extensive experimental results on simulated and real HSI datasets verify the superiority of our proposed HIDFlowNet compared with other state-of-the-art methods both quantitatively and visually.
Comparative Evaluation of Recent Universal Adversarial Perturbations in Image Classification
Jun 20, 2023The vulnerability of Convolutional Neural Networks (CNNs) to adversarial samples has recently garnered significant attention in the machine learning community. Furthermore, recent studies have unveiled the existence of universal adversarial perturbations (UAPs) that are image-agnostic and highly transferable across different CNN models. In this survey, our primary focus revolves around the recent advancements in UAPs specifically within the image classification task. We categorize UAPs into two distinct categories, i.e., noise-based attacks and generator-based attacks, thereby providing a comprehensive overview of representative methods within each category. By presenting the computational details of these methods, we summarize various loss functions employed for learning UAPs. Furthermore, we conduct a comprehensive evaluation of different loss functions within consistent training frameworks, including noise-based and generator-based. The evaluation covers a wide range of attack settings, including black-box and white-box attacks, targeted and untargeted attacks, as well as the examination of defense mechanisms. Our quantitative evaluation results yield several important findings pertaining to the effectiveness of different loss functions, the selection of surrogate CNN models, the impact of training data and data size, and the training frameworks involved in crafting universal attackers. Finally, to further promote future research on universal adversarial attacks, we provide some visualizations of the perturbations and discuss the potential research directions.
CMDA: Cross-Modality Domain Adaptation for Nighttime Semantic Segmentation
Jul 29, 2023
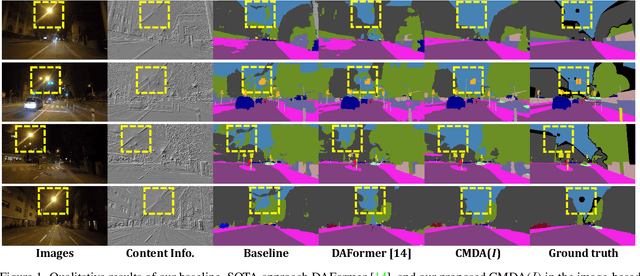
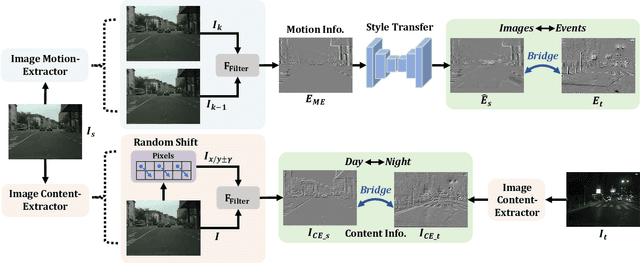
Most nighttime semantic segmentation studies are based on domain adaptation approaches and image input. However, limited by the low dynamic range of conventional cameras, images fail to capture structural details and boundary information in low-light conditions. Event cameras, as a new form of vision sensors, are complementary to conventional cameras with their high dynamic range. To this end, we propose a novel unsupervised Cross-Modality Domain Adaptation (CMDA) framework to leverage multi-modality (Images and Events) information for nighttime semantic segmentation, with only labels on daytime images. In CMDA, we design the Image Motion-Extractor to extract motion information and the Image Content-Extractor to extract content information from images, in order to bridge the gap between different modalities (Images to Events) and domains (Day to Night). Besides, we introduce the first image-event nighttime semantic segmentation dataset. Extensive experiments on both the public image dataset and the proposed image-event dataset demonstrate the effectiveness of our proposed approach. We open-source our code, models, and dataset at https://github.com/XiaRho/CMDA.
Robotic Scene Segmentation with Memory Network for Runtime Surgical Context Inference
Aug 24, 2023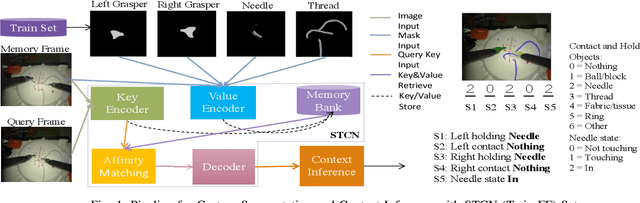
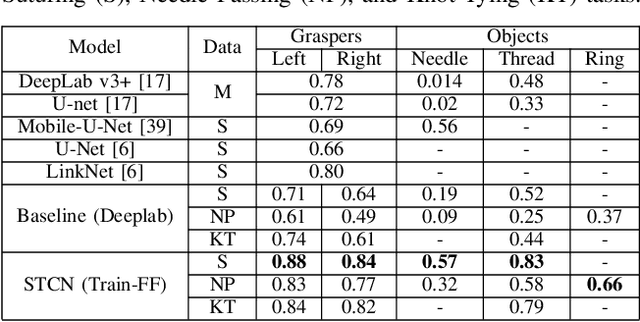
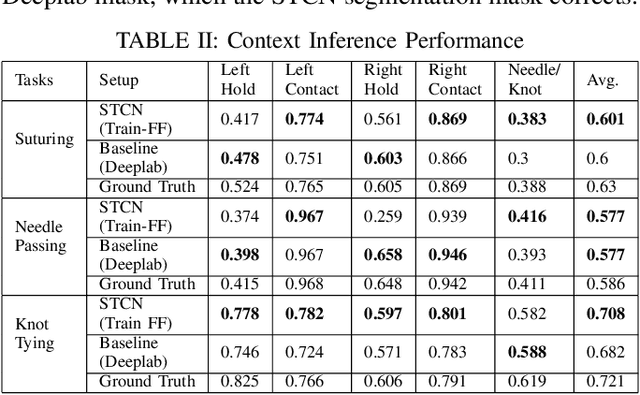

Surgical context inference has recently garnered significant attention in robot-assisted surgery as it can facilitate workflow analysis, skill assessment, and error detection. However, runtime context inference is challenging since it requires timely and accurate detection of the interactions among the tools and objects in the surgical scene based on the segmentation of video data. On the other hand, existing state-of-the-art video segmentation methods are often biased against infrequent classes and fail to provide temporal consistency for segmented masks. This can negatively impact the context inference and accurate detection of critical states. In this study, we propose a solution to these challenges using a Space Time Correspondence Network (STCN). STCN is a memory network that performs binary segmentation and minimizes the effects of class imbalance. The use of a memory bank in STCN allows for the utilization of past image and segmentation information, thereby ensuring consistency of the masks. Our experiments using the publicly available JIGSAWS dataset demonstrate that STCN achieves superior segmentation performance for objects that are difficult to segment, such as needle and thread, and improves context inference compared to the state-of-the-art. We also demonstrate that segmentation and context inference can be performed at runtime without compromising performance.
Deep learning techniques for blind image super-resolution: A high-scale multi-domain perspective evaluation
Jun 15, 2023
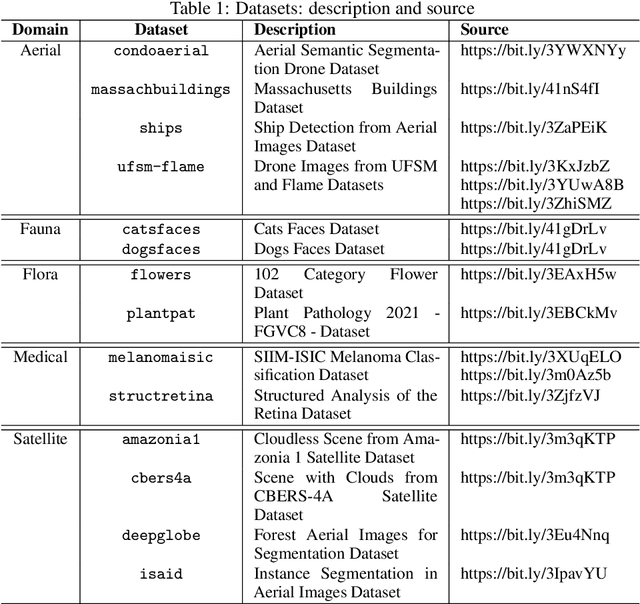
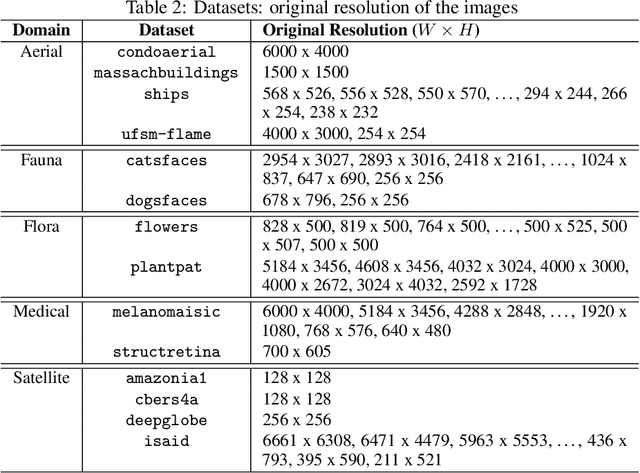

Despite several solutions and experiments have been conducted recently addressing image super-resolution (SR), boosted by deep learning (DL) techniques, they do not usually design evaluations with high scaling factors, capping it at 2x or 4x. Moreover, the datasets are generally benchmarks which do not truly encompass significant diversity of domains to proper evaluate the techniques. It is also interesting to remark that blind SR is attractive for real-world scenarios since it is based on the idea that the degradation process is unknown, and hence techniques in this context rely basically on low-resolution (LR) images. In this article, we present a high-scale (8x) controlled experiment which evaluates five recent DL techniques tailored for blind image SR: Adaptive Pseudo Augmentation (APA), Blind Image SR with Spatially Variant Degradations (BlindSR), Deep Alternating Network (DAN), FastGAN, and Mixture of Experts Super-Resolution (MoESR). We consider 14 small datasets from five different broader domains which are: aerial, fauna, flora, medical, and satellite. Another distinctive characteristic of our evaluation is that some of the DL approaches were designed for single-image SR but others not. Two no-reference metrics were selected, being the classical natural image quality evaluator (NIQE) and the recent transformer-based multi-dimension attention network for no-reference image quality assessment (MANIQA) score, to assess the techniques. Overall, MoESR can be regarded as the best solution although the perceptual quality of the created HR images of all the techniques still needs to improve. Supporting code: https://github.com/vsantjr/DL_BlindSR. Datasets: https://www.kaggle.com/datasets/valdivinosantiago/dl-blindsr-datasets.
The Five-Dollar Model: Generating Game Maps and Sprites from Sentence Embeddings
Aug 08, 2023The five-dollar model is a lightweight text-to-image generative architecture that generates low dimensional images from an encoded text prompt. This model can successfully generate accurate and aesthetically pleasing content in low dimensional domains, with limited amounts of training data. Despite the small size of both the model and datasets, the generated images are still able to maintain the encoded semantic meaning of the textual prompt. We apply this model to three small datasets: pixel art video game maps, video game sprite images, and down-scaled emoji images and apply novel augmentation strategies to improve the performance of our model on these limited datasets. We evaluate our models performance using cosine similarity score between text-image pairs generated by the CLIP VIT-B/32 model.
WS-SfMLearner: Self-supervised Monocular Depth and Ego-motion Estimation on Surgical Videos with Unknown Camera Parameters
Aug 22, 2023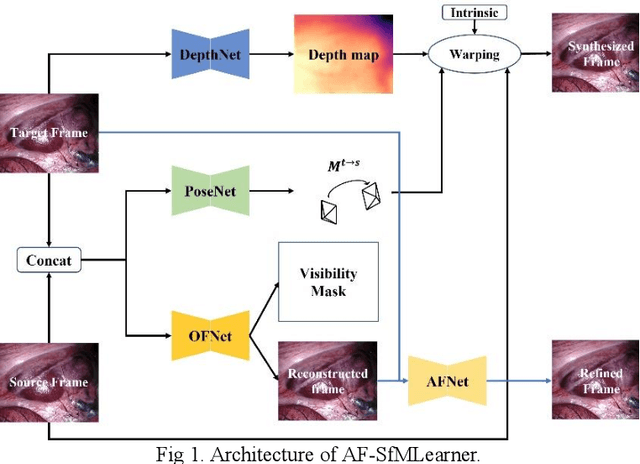
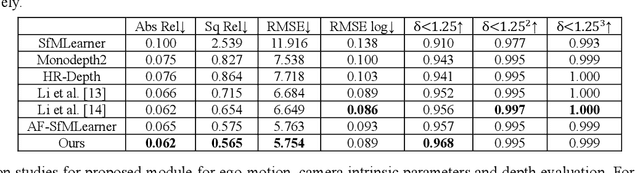
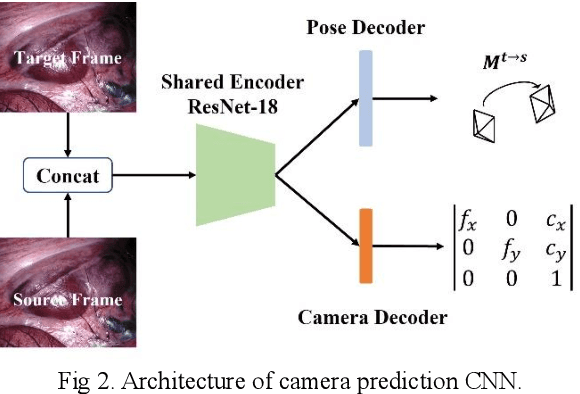
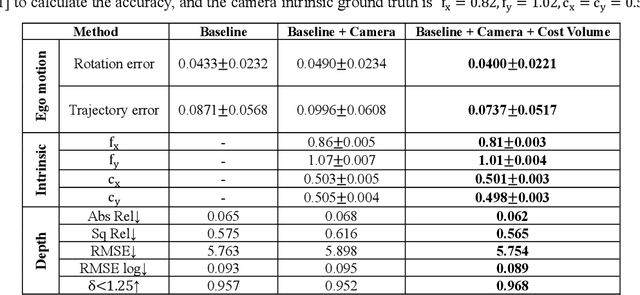
Depth estimation in surgical video plays a crucial role in many image-guided surgery procedures. However, it is difficult and time consuming to create depth map ground truth datasets in surgical videos due in part to inconsistent brightness and noise in the surgical scene. Therefore, building an accurate and robust self-supervised depth and camera ego-motion estimation system is gaining more attention from the computer vision community. Although several self-supervision methods alleviate the need for ground truth depth maps and poses, they still need known camera intrinsic parameters, which are often missing or not recorded. Moreover, the camera intrinsic prediction methods in existing works depend heavily on the quality of datasets. In this work, we aimed to build a self-supervised depth and ego-motion estimation system which can predict not only accurate depth maps and camera pose, but also camera intrinsic parameters. We proposed a cost-volume-based supervision manner to give the system auxiliary supervision for camera parameters prediction. The experimental results showed that the proposed method improved the accuracy of estimated camera parameters, ego-motion, and depth estimation.
Coarse-to-Fine Multi-Scene Pose Regression with Transformers
Aug 22, 2023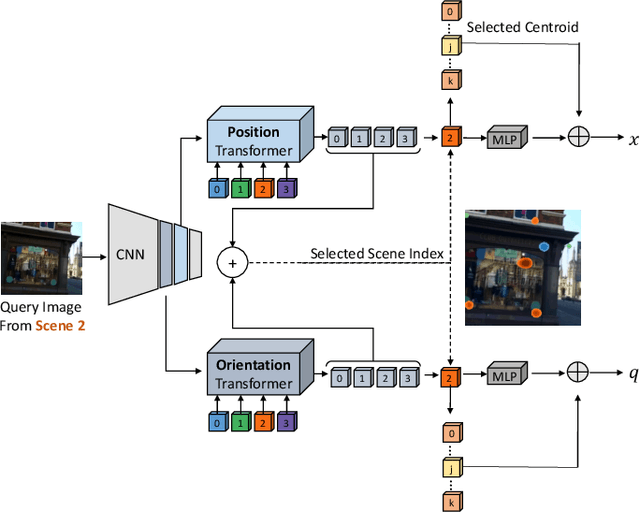
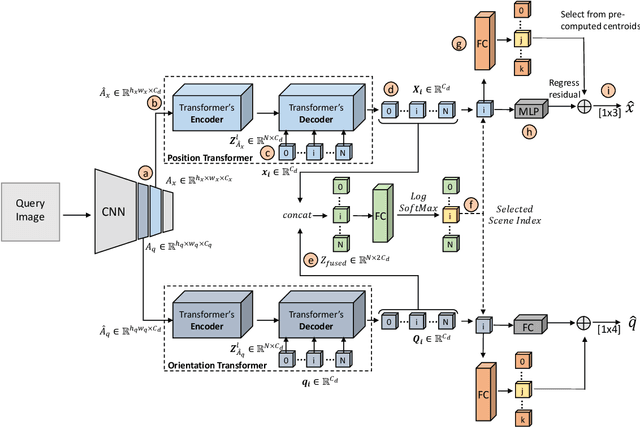


Absolute camera pose regressors estimate the position and orientation of a camera given the captured image alone. Typically, a convolutional backbone with a multi-layer perceptron (MLP) head is trained using images and pose labels to embed a single reference scene at a time. Recently, this scheme was extended to learn multiple scenes by replacing the MLP head with a set of fully connected layers. In this work, we propose to learn multi-scene absolute camera pose regression with Transformers, where encoders are used to aggregate activation maps with self-attention and decoders transform latent features and scenes encoding into pose predictions. This allows our model to focus on general features that are informative for localization, while embedding multiple scenes in parallel. We extend our previous MS-Transformer approach \cite{shavit2021learning} by introducing a mixed classification-regression architecture that improves the localization accuracy. Our method is evaluated on commonly benchmark indoor and outdoor datasets and has been shown to exceed both multi-scene and state-of-the-art single-scene absolute pose regressors.
WMFormer++: Nested Transformer for Visible Watermark Removal via Implict Joint Learning
Aug 22, 2023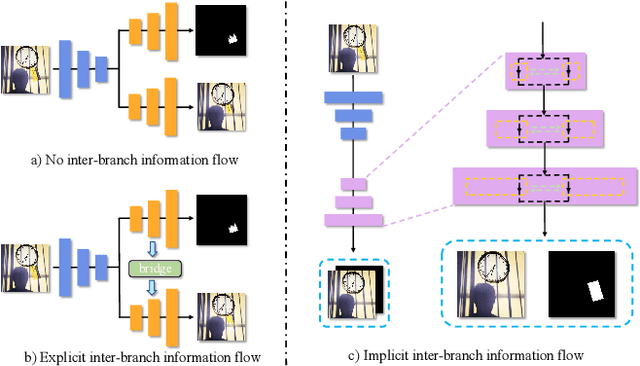
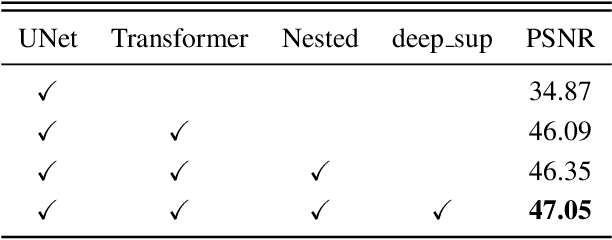

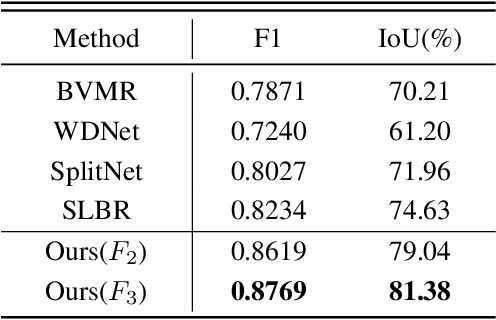
Watermarking serves as a widely adopted approach to safeguard media copyright. In parallel, the research focus has extended to watermark removal techniques, offering an adversarial means to enhance watermark robustness and foster advancements in the watermarking field. Existing watermark removal methods mainly rely on UNet with task-specific decoder branches--one for watermark localization and the other for background image restoration. However, watermark localization and background restoration are not isolated tasks; precise watermark localization inherently implies regions necessitating restoration, and the background restoration process contributes to more accurate watermark localization. To holistically integrate information from both branches, we introduce an implicit joint learning paradigm. This empowers the network to autonomously navigate the flow of information between implicit branches through a gate mechanism. Furthermore, we employ cross-channel attention to facilitate local detail restoration and holistic structural comprehension, while harnessing nested structures to integrate multi-scale information. Extensive experiments are conducted on various challenging benchmarks to validate the effectiveness of our proposed method. The results demonstrate our approach's remarkable superiority, surpassing existing state-of-the-art methods by a large margin.
Self-Supervised Learning for Endoscopic Video Analysis
Aug 23, 2023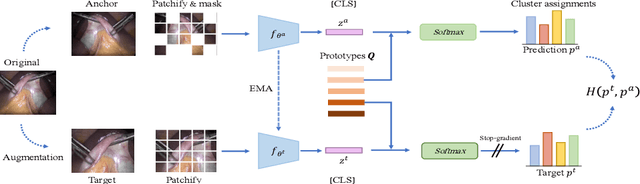
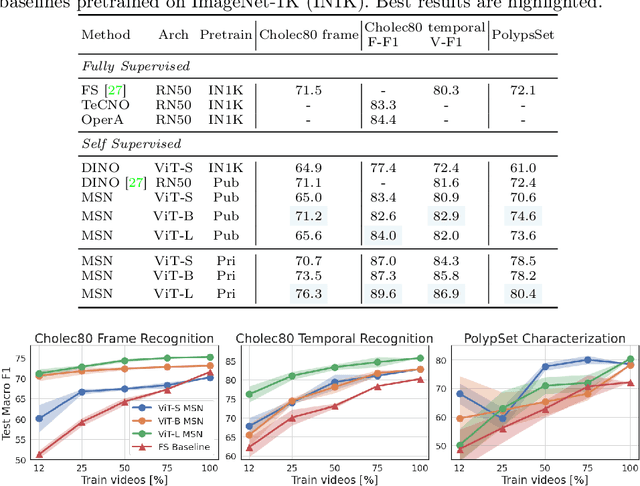
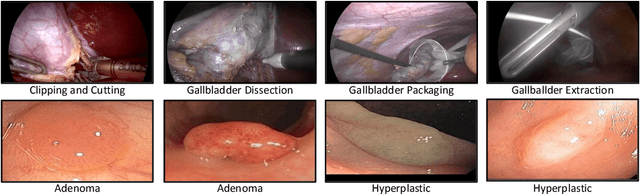
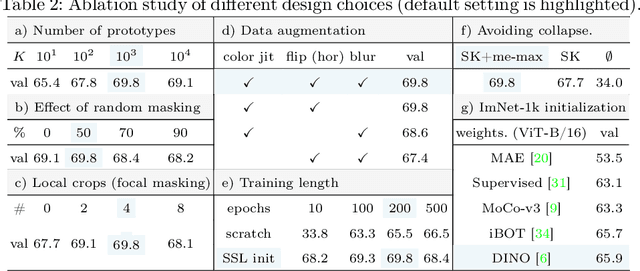
Self-supervised learning (SSL) has led to important breakthroughs in computer vision by allowing learning from large amounts of unlabeled data. As such, it might have a pivotal role to play in biomedicine where annotating data requires a highly specialized expertise. Yet, there are many healthcare domains for which SSL has not been extensively explored. One such domain is endoscopy, minimally invasive procedures which are commonly used to detect and treat infections, chronic inflammatory diseases or cancer. In this work, we study the use of a leading SSL framework, namely Masked Siamese Networks (MSNs), for endoscopic video analysis such as colonoscopy and laparoscopy. To fully exploit the power of SSL, we create sizable unlabeled endoscopic video datasets for training MSNs. These strong image representations serve as a foundation for secondary training with limited annotated datasets, resulting in state-of-the-art performance in endoscopic benchmarks like surgical phase recognition during laparoscopy and colonoscopic polyp characterization. Additionally, we achieve a 50% reduction in annotated data size without sacrificing performance. Thus, our work provides evidence that SSL can dramatically reduce the need of annotated data in endoscopy.