 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Prompt Switch: Efficient CLIP Adaptation for Text-Video Retrieval
Aug 15, 2023
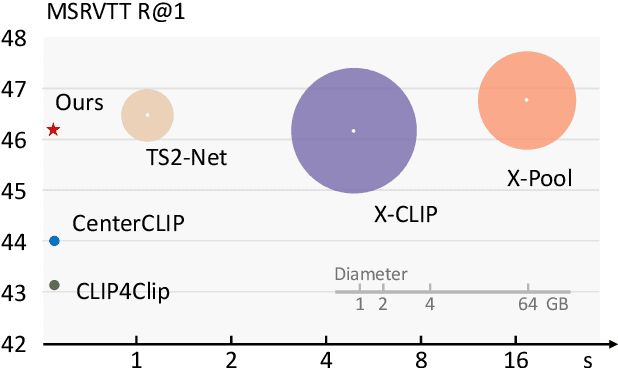
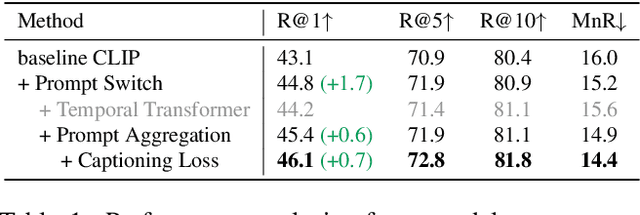
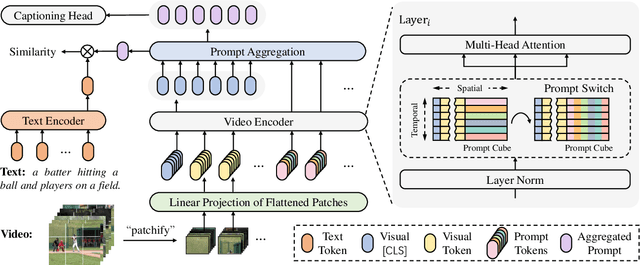
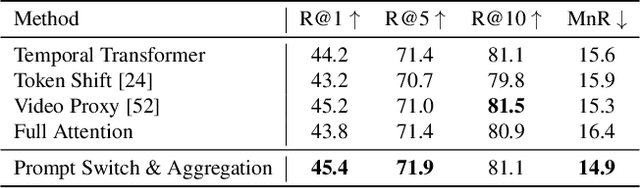
In text-video retrieval, recent works have benefited from the powerful learning capabilities of pre-trained text-image foundation models (e.g., CLIP) by adapting them to the video domain. A critical problem for them is how to effectively capture the rich semantics inside the video using the image encoder of CLIP. To tackle this, state-of-the-art methods adopt complex cross-modal modeling techniques to fuse the text information into video frame representations, which, however, incurs severe efficiency issues in large-scale retrieval systems as the video representations must be recomputed online for every text query. In this paper, we discard this problematic cross-modal fusion process and aim to learn semantically-enhanced representations purely from the video, so that the video representations can be computed offline and reused for different texts. Concretely, we first introduce a spatial-temporal "Prompt Cube" into the CLIP image encoder and iteratively switch it within the encoder layers to efficiently incorporate the global video semantics into frame representations. We then propose to apply an auxiliary video captioning objective to train the frame representations, which facilitates the learning of detailed video semantics by providing fine-grained guidance in the semantic space. With a naive temporal fusion strategy (i.e., mean-pooling) on the enhanced frame representations, we obtain state-of-the-art performances on three benchmark datasets, i.e., MSR-VTT, MSVD, and LSMDC.
Towards High-Fidelity Text-Guided 3D Face Generation and Manipulation Using only Images
Aug 31, 2023
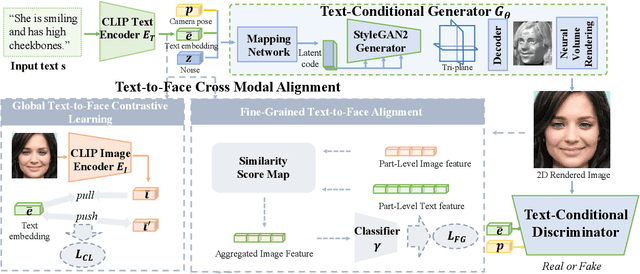
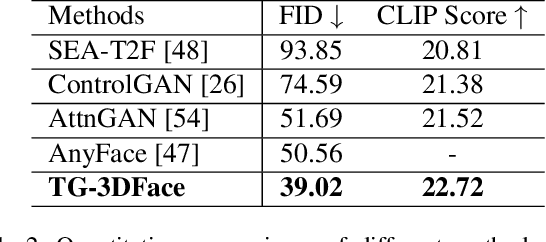
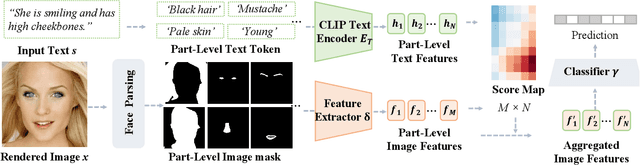
Generating 3D faces from textual descriptions has a multitude of applications, such as gaming, movie, and robotics. Recent progresses have demonstrated the success of unconditional 3D face generation and text-to-3D shape generation. However, due to the limited text-3D face data pairs, text-driven 3D face generation remains an open problem. In this paper, we propose a text-guided 3D faces generation method, refer as TG-3DFace, for generating realistic 3D faces using text guidance. Specifically, we adopt an unconditional 3D face generation framework and equip it with text conditions, which learns the text-guided 3D face generation with only text-2D face data. On top of that, we propose two text-to-face cross-modal alignment techniques, including the global contrastive learning and the fine-grained alignment module, to facilitate high semantic consistency between generated 3D faces and input texts. Besides, we present directional classifier guidance during the inference process, which encourages creativity for out-of-domain generations. Compared to the existing methods, TG-3DFace creates more realistic and aesthetically pleasing 3D faces, boosting 9% multi-view consistency (MVIC) over Latent3D. The rendered face images generated by TG-3DFace achieve higher FID and CLIP score than text-to-2D face/image generation models, demonstrating our superiority in generating realistic and semantic-consistent textures.
Expanding Frozen Vision-Language Models without Retraining: Towards Improved Robot Perception
Aug 31, 2023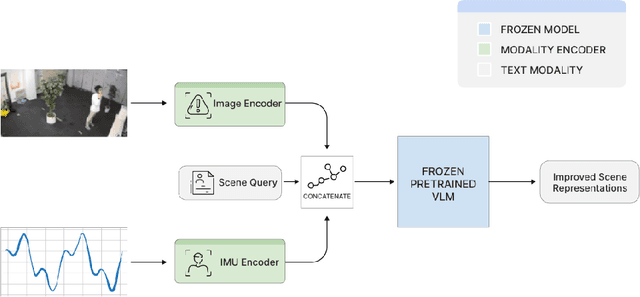
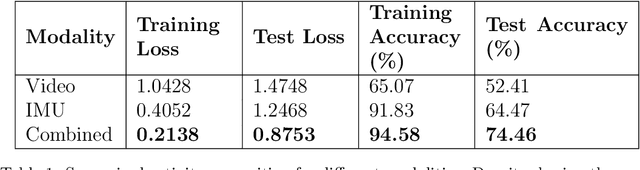
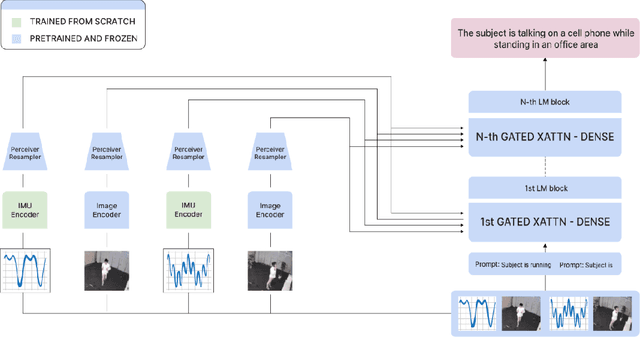
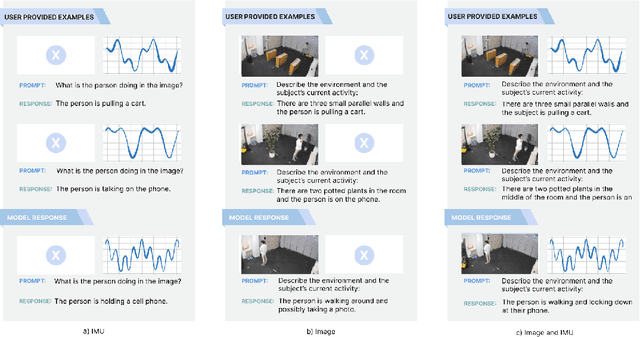
Vision-language models (VLMs) have shown powerful capabilities in visual question answering and reasoning tasks by combining visual representations with the abstract skill set large language models (LLMs) learn during pretraining. Vision, while the most popular modality to augment LLMs with, is only one representation of a scene. In human-robot interaction scenarios, robot perception requires accurate scene understanding by the robot. In this paper, we define and demonstrate a method of aligning the embedding spaces of different modalities (in this case, inertial measurement unit (IMU) data) to the vision embedding space through a combination of supervised and contrastive training, enabling the VLM to understand and reason about these additional modalities without retraining. We opt to give the model IMU embeddings directly over using a separate human activity recognition model that feeds directly into the prompt to allow for any nonlinear interactions between the query, image, and IMU signal that would be lost by mapping the IMU data to a discrete activity label. Further, we demonstrate our methodology's efficacy through experiments involving human activity recognition using IMU data and visual inputs. Our results show that using multiple modalities as input improves the VLM's scene understanding and enhances its overall performance in various tasks, thus paving the way for more versatile and capable language models in multi-modal contexts.
RePo: Resilient Model-Based Reinforcement Learning by Regularizing Posterior Predictability
Aug 31, 2023
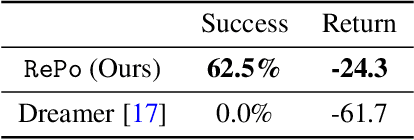
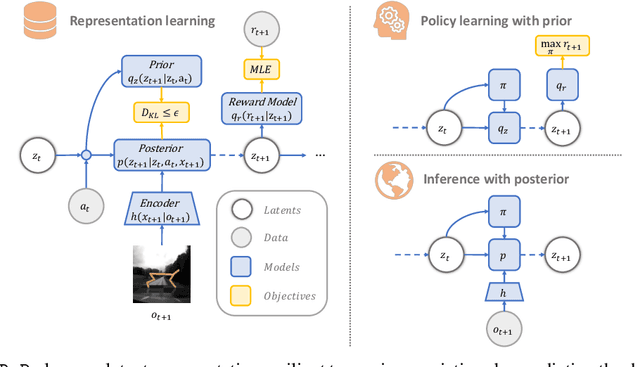
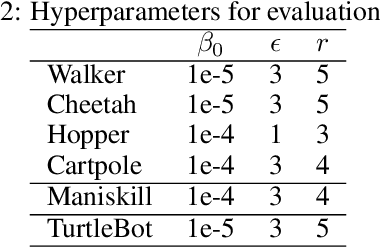
Visual model-based RL methods typically encode image observations into low-dimensional representations in a manner that does not eliminate redundant information. This leaves them susceptible to spurious variations -- changes in task-irrelevant components such as background distractors or lighting conditions. In this paper, we propose a visual model-based RL method that learns a latent representation resilient to such spurious variations. Our training objective encourages the representation to be maximally predictive of dynamics and reward, while constraining the information flow from the observation to the latent representation. We demonstrate that this objective significantly bolsters the resilience of visual model-based RL methods to visual distractors, allowing them to operate in dynamic environments. We then show that while the learned encoder is resilient to spirious variations, it is not invariant under significant distribution shift. To address this, we propose a simple reward-free alignment procedure that enables test time adaptation of the encoder. This allows for quick adaptation to widely differing environments without having to relearn the dynamics and policy. Our effort is a step towards making model-based RL a practical and useful tool for dynamic, diverse domains. We show its effectiveness in simulation benchmarks with significant spurious variations as well as a real-world egocentric navigation task with noisy TVs in the background. Videos and code at https://zchuning.github.io/repo-website/.
Not All Image Regions Matter: Masked Vector Quantization for Autoregressive Image Generation
May 23, 2023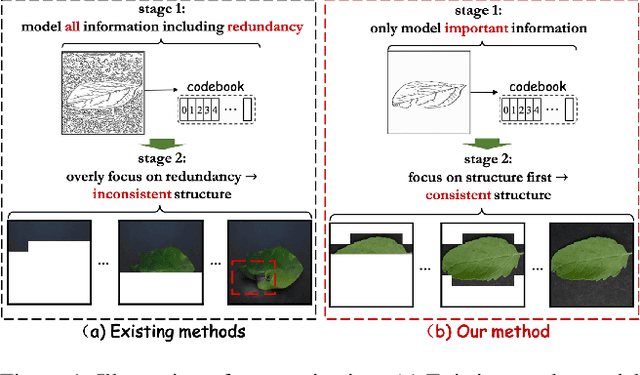
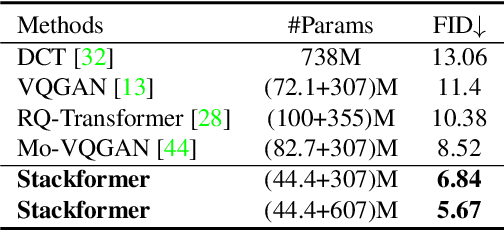
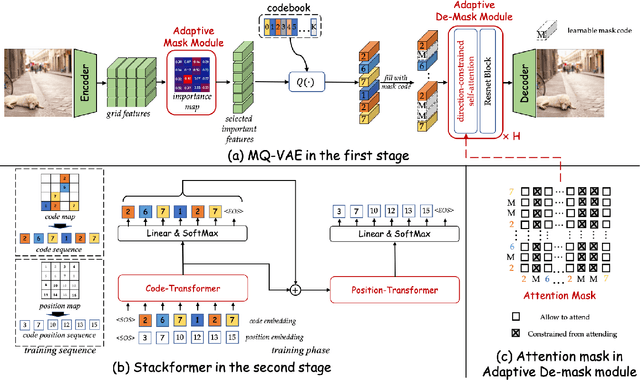
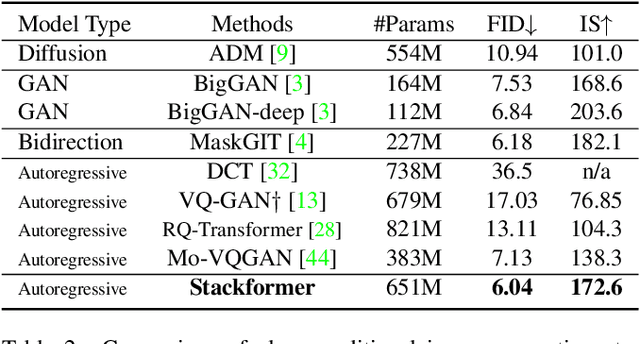
Existing autoregressive models follow the two-stage generation paradigm that first learns a codebook in the latent space for image reconstruction and then completes the image generation autoregressively based on the learned codebook. However, existing codebook learning simply models all local region information of images without distinguishing their different perceptual importance, which brings redundancy in the learned codebook that not only limits the next stage's autoregressive model's ability to model important structure but also results in high training cost and slow generation speed. In this study, we borrow the idea of importance perception from classical image coding theory and propose a novel two-stage framework, which consists of Masked Quantization VAE (MQ-VAE) and Stackformer, to relieve the model from modeling redundancy. Specifically, MQ-VAE incorporates an adaptive mask module for masking redundant region features before quantization and an adaptive de-mask module for recovering the original grid image feature map to faithfully reconstruct the original images after quantization. Then, Stackformer learns to predict the combination of the next code and its position in the feature map. Comprehensive experiments on various image generation validate our effectiveness and efficiency. Code will be released at https://github.com/CrossmodalGroup/MaskedVectorQuantization.
Post-Hoc Explainability of BI-RADS Descriptors in a Multi-task Framework for Breast Cancer Detection and Segmentation
Aug 27, 2023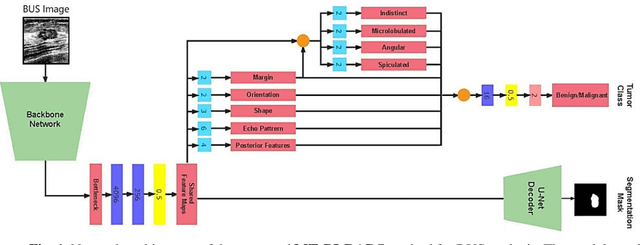



Despite recent medical advancements, breast cancer remains one of the most prevalent and deadly diseases among women. Although machine learning-based Computer-Aided Diagnosis (CAD) systems have shown potential to assist radiologists in analyzing medical images, the opaque nature of the best-performing CAD systems has raised concerns about their trustworthiness and interpretability. This paper proposes MT-BI-RADS, a novel explainable deep learning approach for tumor detection in Breast Ultrasound (BUS) images. The approach offers three levels of explanations to enable radiologists to comprehend the decision-making process in predicting tumor malignancy. Firstly, the proposed model outputs the BI-RADS categories used for BUS image analysis by radiologists. Secondly, the model employs multi-task learning to concurrently segment regions in images that correspond to tumors. Thirdly, the proposed approach outputs quantified contributions of each BI-RADS descriptor toward predicting the benign or malignant class using post-hoc explanations with Shapley Values.
Few-Shot Object Detection via Synthetic Features with Optimal Transport
Aug 30, 2023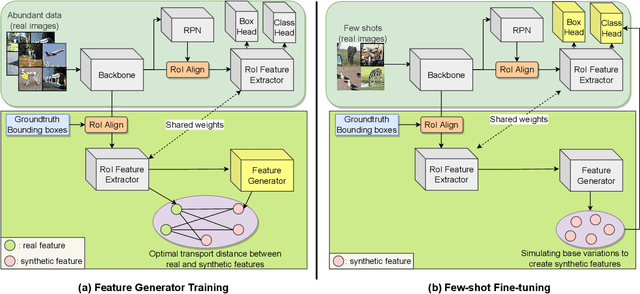
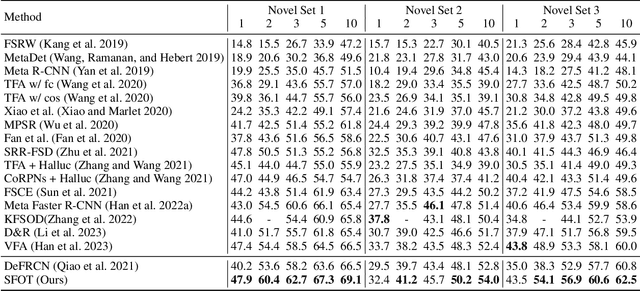
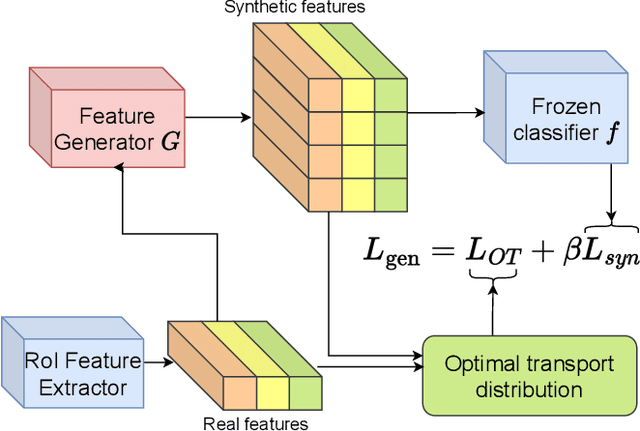
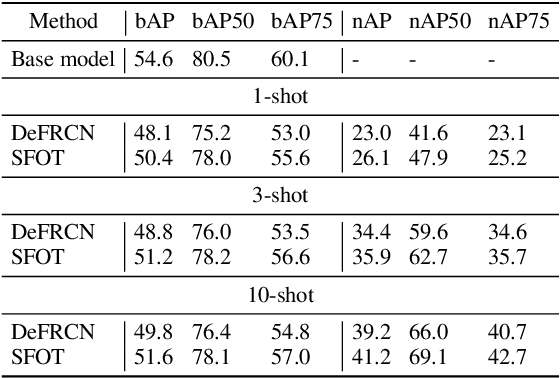
Few-shot object detection aims to simultaneously localize and classify the objects in an image with limited training samples. However, most existing few-shot object detection methods focus on extracting the features of a few samples of novel classes that lack diversity. Hence, they may not be sufficient to capture the data distribution. To address that limitation, in this paper, we propose a novel approach in which we train a generator to generate synthetic data for novel classes. Still, directly training a generator on the novel class is not effective due to the lack of novel data. To overcome that issue, we leverage the large-scale dataset of base classes. Our overarching goal is to train a generator that captures the data variations of the base dataset. We then transform the captured variations into novel classes by generating synthetic data with the trained generator. To encourage the generator to capture data variations on base classes, we propose to train the generator with an optimal transport loss that minimizes the optimal transport distance between the distributions of real and synthetic data. Extensive experiments on two benchmark datasets demonstrate that the proposed method outperforms the state of the art. Source code will be available.
AMDNet23: A combined deep Contour-based Convolutional Neural Network and Long Short Term Memory system to diagnose Age-related Macular Degeneration
Aug 30, 2023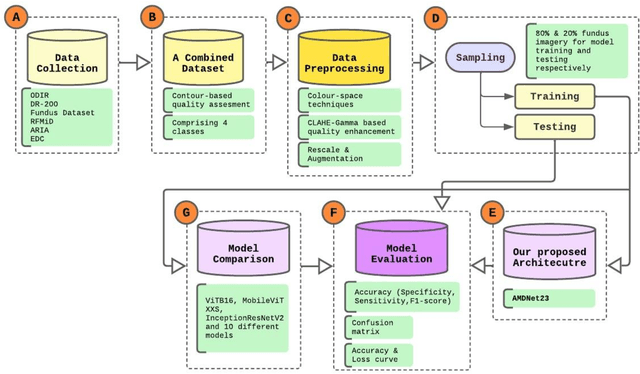
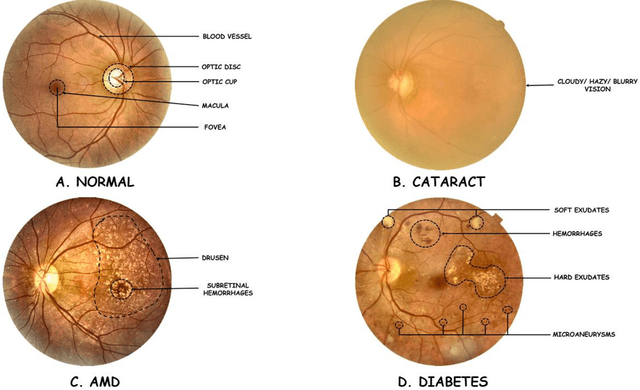
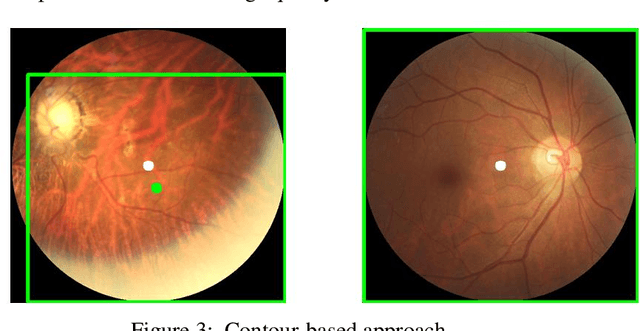
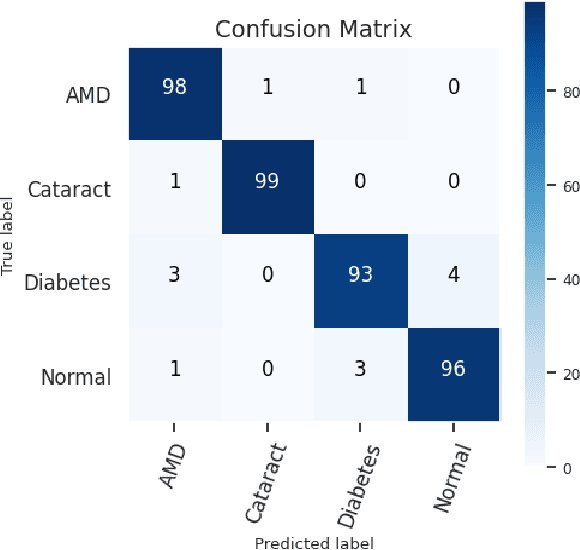
In light of the expanding population, an automated framework of disease detection can assist doctors in the diagnosis of ocular diseases, yields accurate, stable, rapid outcomes, and improves the success rate of early detection. The work initially intended the enhancing the quality of fundus images by employing an adaptive contrast enhancement algorithm (CLAHE) and Gamma correction. In the preprocessing techniques, CLAHE elevates the local contrast of the fundus image and gamma correction increases the intensity of relevant features. This study operates on a AMDNet23 system of deep learning that combined the neural networks made up of convolutions (CNN) and short-term and long-term memory (LSTM) to automatically detect aged macular degeneration (AMD) disease from fundus ophthalmology. In this mechanism, CNN is utilized for extracting features and LSTM is utilized to detect the extracted features. The dataset of this research is collected from multiple sources and afterward applied quality assessment techniques, 2000 experimental fundus images encompass four distinct classes equitably. The proposed hybrid deep AMDNet23 model demonstrates to detection of AMD ocular disease and the experimental result achieved an accuracy 96.50%, specificity 99.32%, sensitivity 96.5%, and F1-score 96.49.0%. The system achieves state-of-the-art findings on fundus imagery datasets to diagnose AMD ocular disease and findings effectively potential of our method.
ACNPU: A 4.75TOPS/W 1080P@30FPS Super Resolution Accelerator with Decoupled Asymmetric Convolution
Aug 30, 2023Deep learning-driven superresolution (SR) outperforms traditional techniques but also faces the challenge of high complexity and memory bandwidth. This challenge leads many accelerators to opt for simpler and shallow models like FSRCNN, compromising performance for real-time needs, especially for resource-limited edge devices. This paper proposes an energy-efficient SR accelerator, ACNPU, to tackle this challenge. The ACNPU enhances image quality by 0.34dB with a 27-layer model, but needs 36\% less complexity than FSRCNN, while maintaining a similar model size, with the \textit{decoupled asymmetric convolution and split-bypass structure}. The hardware-friendly 17K-parameter model enables \textit{holistic model fusion} instead of localized layer fusion to remove external DRAM access of intermediate feature maps. The on-chip memory bandwidth is further reduced with the \textit{input stationary flow} and \textit{parallel-layer execution} to reduce power consumption. Hardware is regular and easy to control to support different layers by \textit{processing elements (PEs) clusters with reconfigurable input and uniform data flow}. The implementation in the 40 nm CMOS process consumes 2333 K gate counts and 198KB SRAMs. The ACNPU achieves 31.7 FPS and 124.4 FPS for x2 and x4 scales Full-HD generation, respectively, which attains 4.75 TOPS/W energy efficiency.
Domain Agnostic Image-to-image Translation using Low-Resolution Conditioning
May 11, 2023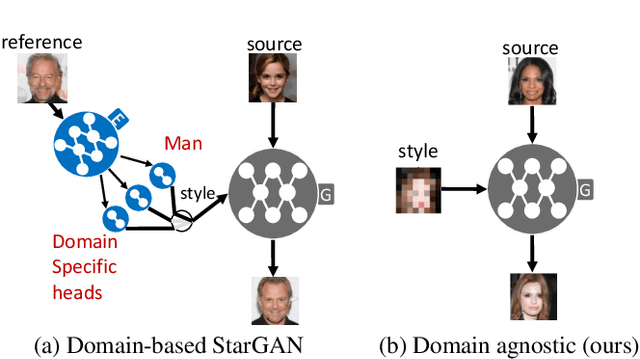
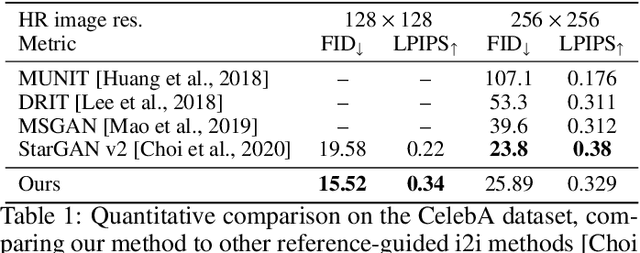
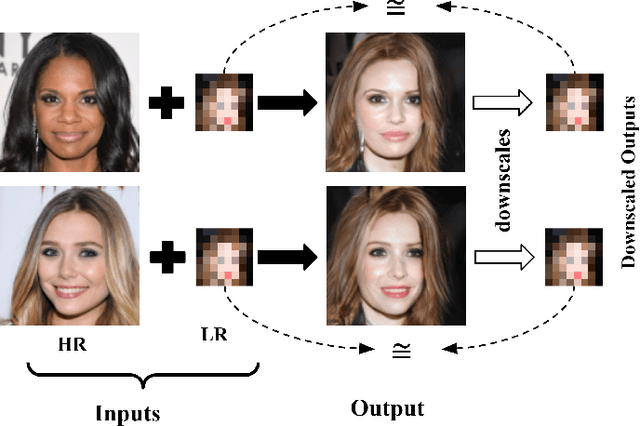
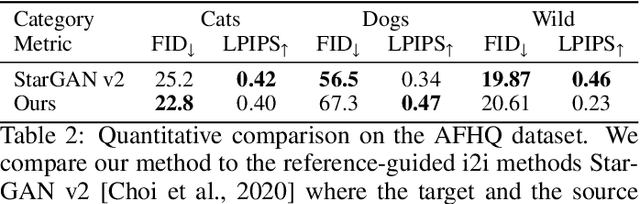
Generally, image-to-image translation (i2i) methods aim at learning mappings across domains with the assumption that the images used for translation share content (e.g., pose) but have their own domain-specific information (a.k.a. style). Conditioned on a target image, such methods extract the target style and combine it with the source image content, keeping coherence between the domains. In our proposal, we depart from this traditional view and instead consider the scenario where the target domain is represented by a very low-resolution (LR) image, proposing a domain-agnostic i2i method for fine-grained problems, where the domains are related. More specifically, our domain-agnostic approach aims at generating an image that combines visual features from the source image with low-frequency information (e.g. pose, color) of the LR target image. To do so, we present a novel approach that relies on training the generative model to produce images that both share distinctive information of the associated source image and correctly match the LR target image when downscaled. We validate our method on the CelebA-HQ and AFHQ datasets by demonstrating improvements in terms of visual quality. Qualitative and quantitative results show that when dealing with intra-domain image translation, our method generates realistic samples compared to state-of-the-art methods such as StarGAN v2. Ablation studies also reveal that our method is robust to changes in color, it can be applied to out-of-distribution images, and it allows for manual control over the final results.