 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Ensembling Uncertainty Measures to Improve Safety of Black-Box Classifiers
Aug 23, 2023
Machine Learning (ML) algorithms that perform classification may predict the wrong class, experiencing misclassifications. It is well-known that misclassifications may have cascading effects on the encompassing system, possibly resulting in critical failures. This paper proposes SPROUT, a Safety wraPper thROugh ensembles of UncertainTy measures, which suspects misclassifications by computing uncertainty measures on the inputs and outputs of a black-box classifier. If a misclassification is detected, SPROUT blocks the propagation of the output of the classifier to the encompassing system. The resulting impact on safety is that SPROUT transforms erratic outputs (misclassifications) into data omission failures, which can be easily managed at the system level. SPROUT has a broad range of applications as it fits binary and multi-class classification, comprising image and tabular datasets. We experimentally show that SPROUT always identifies a huge fraction of the misclassifications of supervised classifiers, and it is able to detect all misclassifications in specific cases. SPROUT implementation contains pre-trained wrappers, it is publicly available and ready to be deployed with minimal effort.
Language Reward Modulation for Pretraining Reinforcement Learning
Aug 23, 2023

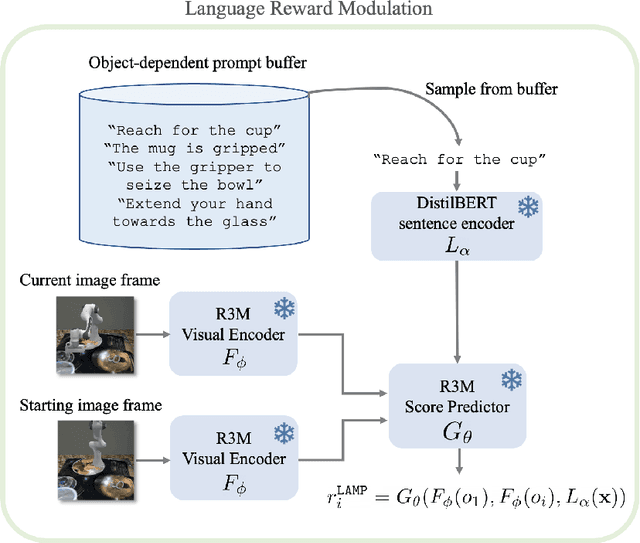

Using learned reward functions (LRFs) as a means to solve sparse-reward reinforcement learning (RL) tasks has yielded some steady progress in task-complexity through the years. In this work, we question whether today's LRFs are best-suited as a direct replacement for task rewards. Instead, we propose leveraging the capabilities of LRFs as a pretraining signal for RL. Concretely, we propose $\textbf{LA}$nguage Reward $\textbf{M}$odulated $\textbf{P}$retraining (LAMP) which leverages the zero-shot capabilities of Vision-Language Models (VLMs) as a $\textit{pretraining}$ utility for RL as opposed to a downstream task reward. LAMP uses a frozen, pretrained VLM to scalably generate noisy, albeit shaped exploration rewards by computing the contrastive alignment between a highly diverse collection of language instructions and the image observations of an agent in its pretraining environment. LAMP optimizes these rewards in conjunction with standard novelty-seeking exploration rewards with reinforcement learning to acquire a language-conditioned, pretrained policy. Our VLM pretraining approach, which is a departure from previous attempts to use LRFs, can warmstart sample-efficient learning on robot manipulation tasks in RLBench.
SAAN: Similarity-aware attention flow network for change detection with VHR remote sensing images
Aug 28, 2023

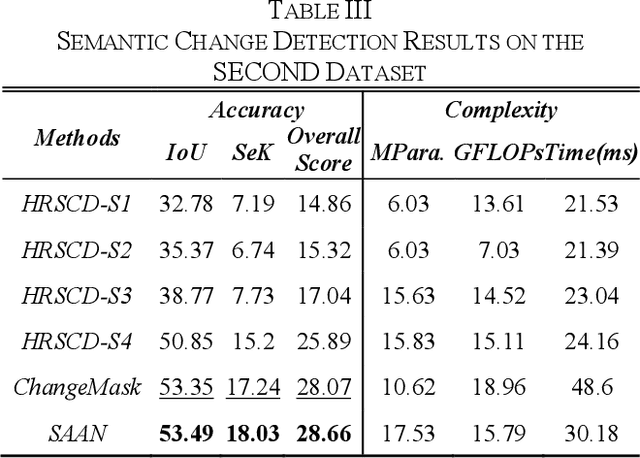
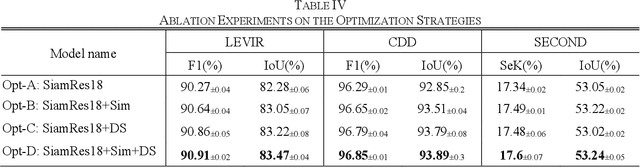
Change detection (CD) is a fundamental and important task for monitoring the land surface dynamics in the earth observation field. Existing deep learning-based CD methods typically extract bi-temporal image features using a weight-sharing Siamese encoder network and identify change regions using a decoder network. These CD methods, however, still perform far from satisfactorily as we observe that 1) deep encoder layers focus on irrelevant background regions and 2) the models' confidence in the change regions is inconsistent at different decoder stages. The first problem is because deep encoder layers cannot effectively learn from imbalanced change categories using the sole output supervision, while the second problem is attributed to the lack of explicit semantic consistency preservation. To address these issues, we design a novel similarity-aware attention flow network (SAAN). SAAN incorporates a similarity-guided attention flow module with deeply supervised similarity optimization to achieve effective change detection. Specifically, we counter the first issue by explicitly guiding deep encoder layers to discover semantic relations from bi-temporal input images using deeply supervised similarity optimization. The extracted features are optimized to be semantically similar in the unchanged regions and dissimilar in the changing regions. The second drawback can be alleviated by the proposed similarity-guided attention flow module, which incorporates similarity-guided attention modules and attention flow mechanisms to guide the model to focus on discriminative channels and regions. We evaluated the effectiveness and generalization ability of the proposed method by conducting experiments on a wide range of CD tasks. The experimental results demonstrate that our method achieves excellent performance on several CD tasks, with discriminative features and semantic consistency preserved.
Multimodal Detection of Social Spambots in Twitter using Transformers
Aug 28, 2023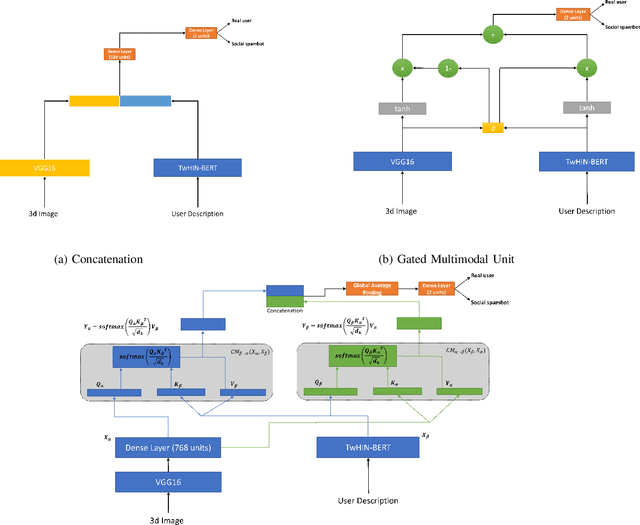
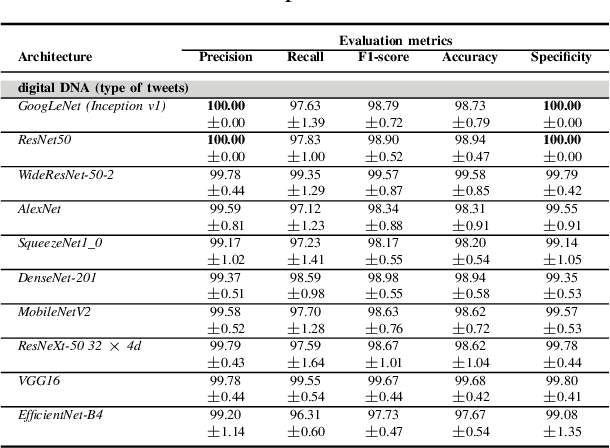
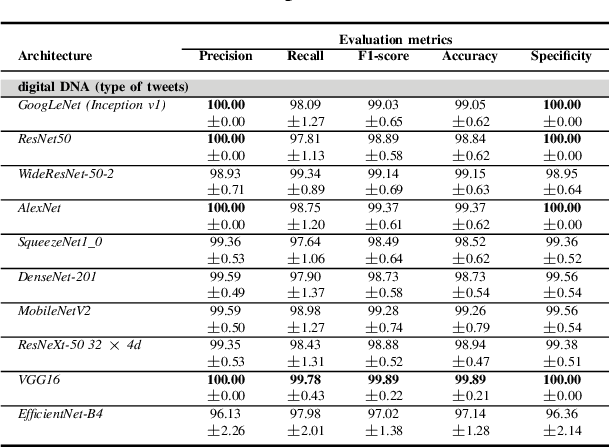
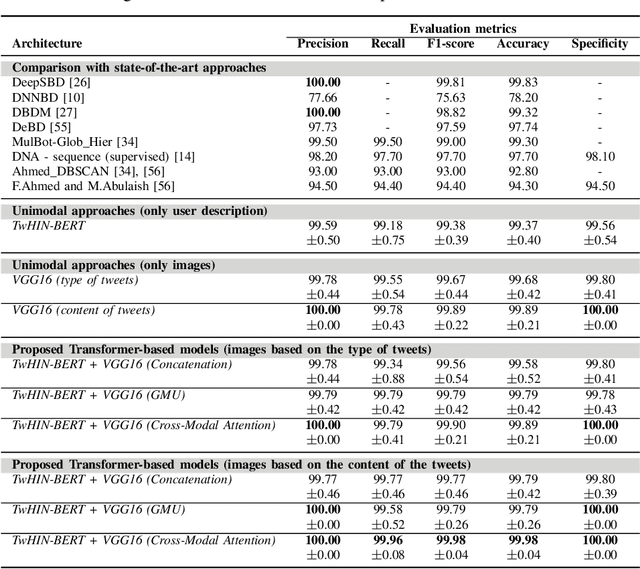
Although not all bots are malicious, the vast majority of them are responsible for spreading misinformation and manipulating the public opinion about several issues, i.e., elections and many more. Therefore, the early detection of social spambots is crucial. Although there have been proposed methods for detecting bots in social media, there are still substantial limitations. For instance, existing research initiatives still extract a large number of features and train traditional machine learning algorithms or use GloVe embeddings and train LSTMs. However, feature extraction is a tedious procedure demanding domain expertise. Also, language models based on transformers have been proved to be better than LSTMs. Other approaches create large graphs and train graph neural networks requiring in this way many hours for training and access to computational resources. To tackle these limitations, this is the first study employing only the user description field and images of three channels denoting the type and content of tweets posted by the users. Firstly, we create digital DNA sequences, transform them to 3d images, and apply pretrained models of the vision domain, including EfficientNet, AlexNet, VGG16, etc. Next, we propose a multimodal approach, where we use TwHIN-BERT for getting the textual representation of the user description field and employ VGG16 for acquiring the visual representation for the image modality. We propose three different fusion methods, namely concatenation, gated multimodal unit, and crossmodal attention, for fusing the different modalities and compare their performances. Extensive experiments conducted on the Cresci '17 dataset demonstrate valuable advantages of our introduced approaches over state-of-the-art ones reaching Accuracy up to 99.98%.
Domain Adaptation based on Human Feedback for Enhancing Generative Model Denoising Abilities
Aug 01, 2023How can we apply human feedback into generative model? As answer of this question, in this paper, we show the method applied on denoising problem and domain adaptation using human feedback. Deep generative models have demonstrated impressive results in image denoising. However, current image denoising models often produce inappropriate results when applied to domains different from the ones they were trained on. If there are `Good' and `Bad' result for unseen data, how to raise up quality of `Bad' result. Most methods use an approach based on generalization of model. However, these methods require target image for training or adapting unseen domain. In this paper, to adapting domain, we deal with non-target image for unseen domain, and improve specific failed image. To address this, we propose a method for fine-tuning inappropriate results generated in a different domain by utilizing human feedback. First, we train a generator to denoise images using only the noisy MNIST digit '0' images. The denoising generator trained on the source domain leads to unintended results when applied to target domain images. To achieve domain adaptation, we construct a noise-image denoising generated image data set and train a reward model predict human feedback. Finally, we fine-tune the generator on the different domain using the reward model with auxiliary loss function, aiming to transfer denoising capabilities to target domain. Our approach demonstrates the potential to efficiently fine-tune a generator trained on one domain using human feedback from another domain, thereby enhancing denoising abilities in different domains.
Metadata Improves Segmentation Through Multitasking Elicitation
Aug 18, 2023Metainformation is a common companion to biomedical images. However, this potentially powerful additional source of signal from image acquisition has had limited use in deep learning methods, for semantic segmentation in particular. Here, we incorporate metadata by employing a channel modulation mechanism in convolutional networks and study its effect on semantic segmentation tasks. We demonstrate that metadata as additional input to a convolutional network can improve segmentation results while being inexpensive in implementation as a nimble add-on to popular models. We hypothesize that this benefit of metadata can be attributed to facilitating multitask switching. This aspect of metadata-driven systems is explored and discussed in detail.
StyleDrop: Text-to-Image Generation in Any Style
Jun 01, 2023
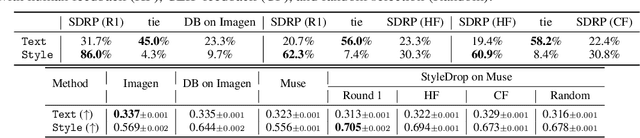


Pre-trained large text-to-image models synthesize impressive images with an appropriate use of text prompts. However, ambiguities inherent in natural language and out-of-distribution effects make it hard to synthesize image styles, that leverage a specific design pattern, texture or material. In this paper, we introduce StyleDrop, a method that enables the synthesis of images that faithfully follow a specific style using a text-to-image model. The proposed method is extremely versatile and captures nuances and details of a user-provided style, such as color schemes, shading, design patterns, and local and global effects. It efficiently learns a new style by fine-tuning very few trainable parameters (less than $1\%$ of total model parameters) and improving the quality via iterative training with either human or automated feedback. Better yet, StyleDrop is able to deliver impressive results even when the user supplies only a single image that specifies the desired style. An extensive study shows that, for the task of style tuning text-to-image models, StyleDrop implemented on Muse convincingly outperforms other methods, including DreamBooth and textual inversion on Imagen or Stable Diffusion. More results are available at our project website: https://styledrop.github.io
Improving Joint Speech-Text Representations Without Alignment
Aug 11, 2023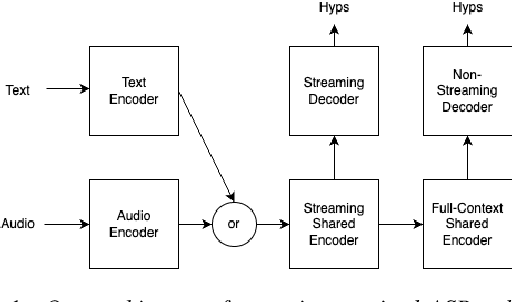
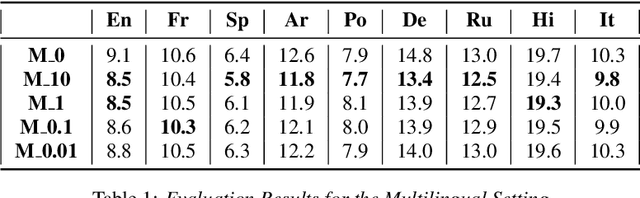
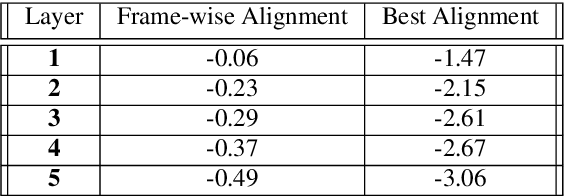
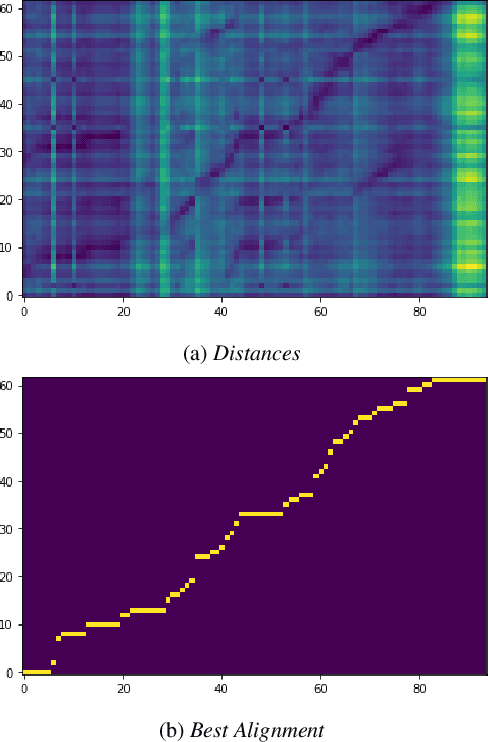
The last year has seen astonishing progress in text-prompted image generation premised on the idea of a cross-modal representation space in which the text and image domains are represented jointly. In ASR, this idea has found application as joint speech-text encoders that can scale to the capacities of very large parameter models by being trained on both unpaired speech and text. While these methods show promise, they have required special treatment of the sequence-length mismatch inherent in speech and text, either by up-sampling heuristics or an explicit alignment model. In this work, we offer evidence that joint speech-text encoders naturally achieve consistent representations across modalities by disregarding sequence length, and argue that consistency losses could forgive length differences and simply assume the best alignment. We show that such a loss improves downstream WER in both a large-parameter monolingual and multilingual system.
Exploring Better Text Image Translation with Multimodal Codebook
Jun 02, 2023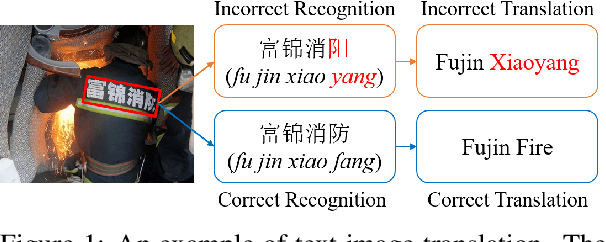
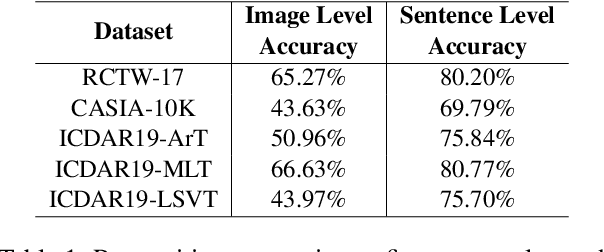
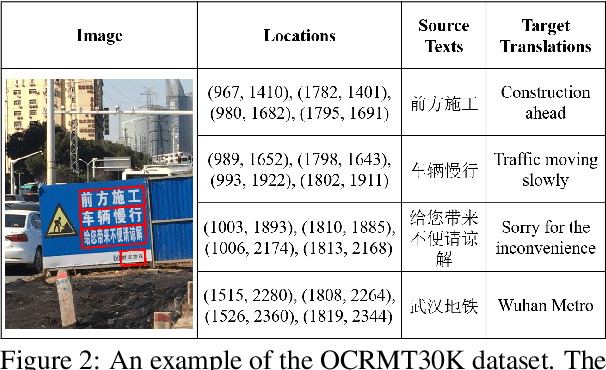
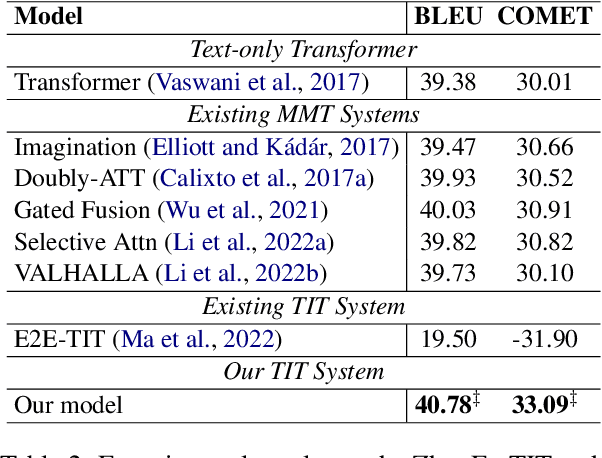
Text image translation (TIT) aims to translate the source texts embedded in the image to target translations, which has a wide range of applications and thus has important research value. However, current studies on TIT are confronted with two main bottlenecks: 1) this task lacks a publicly available TIT dataset, 2) dominant models are constructed in a cascaded manner, which tends to suffer from the error propagation of optical character recognition (OCR). In this work, we first annotate a Chinese-English TIT dataset named OCRMT30K, providing convenience for subsequent studies. Then, we propose a TIT model with a multimodal codebook, which is able to associate the image with relevant texts, providing useful supplementary information for translation. Moreover, we present a multi-stage training framework involving text machine translation, image-text alignment, and TIT tasks, which fully exploits additional bilingual texts, OCR dataset and our OCRMT30K dataset to train our model. Extensive experiments and in-depth analyses strongly demonstrate the effectiveness of our proposed model and training framework.
Conditional Diffusion Models for Weakly Supervised Medical Image Segmentation
Jun 06, 2023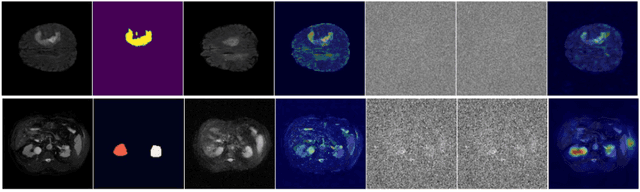
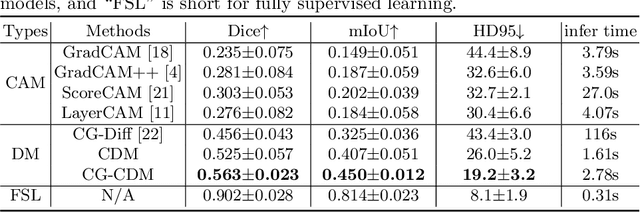
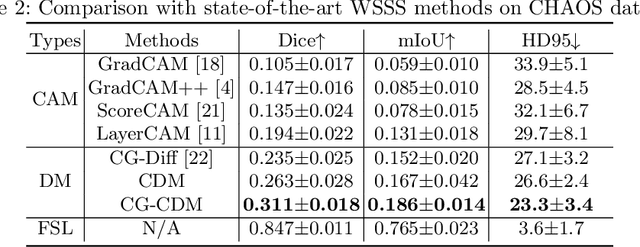

Recent advances in denoising diffusion probabilistic models have shown great success in image synthesis tasks. While there are already works exploring the potential of this powerful tool in image semantic segmentation, its application in weakly supervised semantic segmentation (WSSS) remains relatively under-explored. Observing that conditional diffusion models (CDM) is capable of generating images subject to specific distributions, in this work, we utilize category-aware semantic information underlied in CDM to get the prediction mask of the target object with only image-level annotations. More specifically, we locate the desired class by approximating the derivative of the output of CDM w.r.t the input condition. Our method is different from previous diffusion model methods with guidance from an external classifier, which accumulates noises in the background during the reconstruction process. Our method outperforms state-of-the-art CAM and diffusion model methods on two public medical image segmentation datasets, which demonstrates that CDM is a promising tool in WSSS. Also, experiment shows our method is more time-efficient than existing diffusion model methods, making it practical for wider applications.