 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AGIQA-3K: An Open Database for AI-Generated Image Quality Assessment
Jun 12, 2023

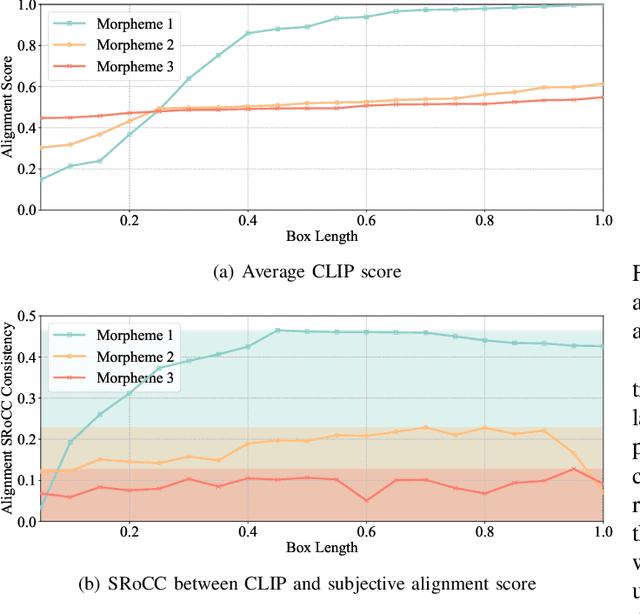

With the rapid advancements of the text-to-image generative model, AI-generated images (AGIs) have been widely applied to entertainment, education, social media, etc. However, considering the large quality variance among different AGIs, there is an urgent need for quality models that are consistent with human subjective ratings. To address this issue, we extensively consider various popular AGI models, generated AGI through different prompts and model parameters, and collected subjective scores at the perceptual quality and text-to-image alignment, thus building the most comprehensive AGI subjective quality database AGIQA-3K so far. Furthermore, we conduct a benchmark experiment on this database to evaluate the consistency between the current Image Quality Assessment (IQA) model and human perception, while proposing StairReward that significantly improves the assessment performance of subjective text-to-image alignment. We believe that the fine-grained subjective scores in AGIQA-3K will inspire subsequent AGI quality models to fit human subjective perception mechanisms at both perception and alignment levels and to optimize the generation result of future AGI models. The database is released on https://github.com/lcysyzxdxc/AGIQA-3k-Database.
X-IQE: eXplainable Image Quality Evaluation for Text-to-Image Generation with Visual Large Language Models
May 26, 2023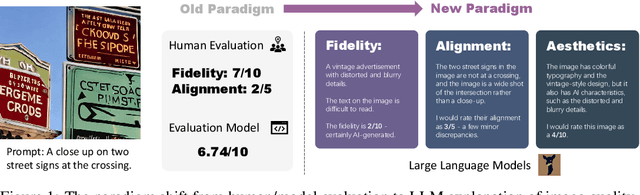
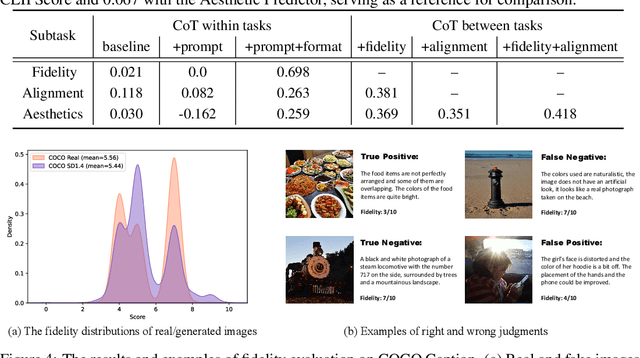
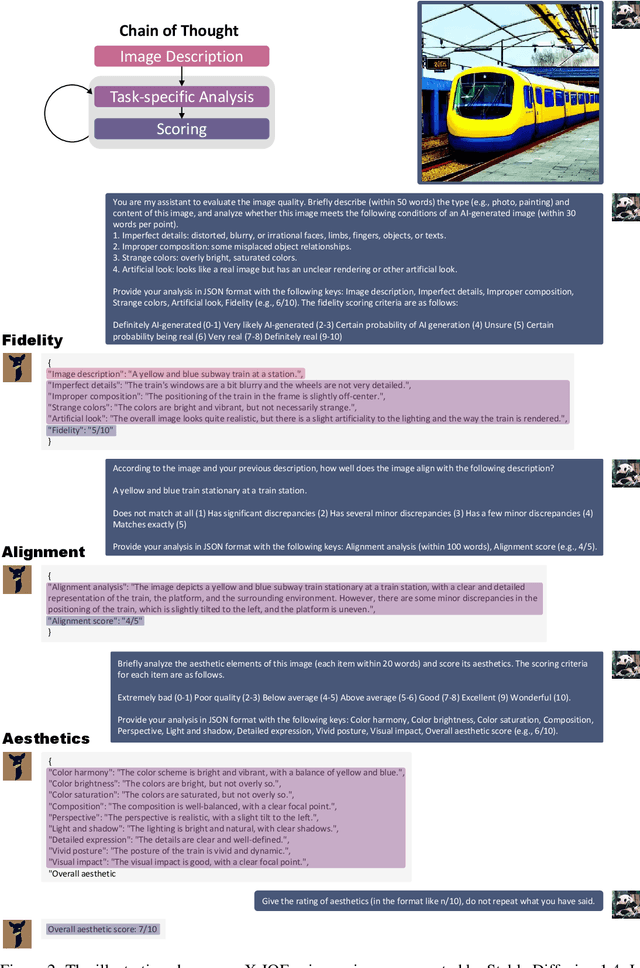
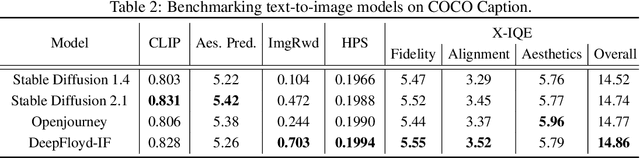
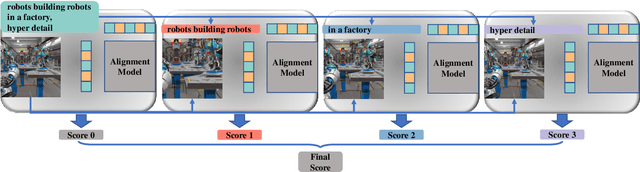
This paper introduces a novel explainable image quality evaluation approach called X-IQE, which leverages visual large language models (LLMs) to evaluate text-to-image generation methods by generating textual explanations. X-IQE utilizes a hierarchical Chain of Thought (CoT) to enable MiniGPT-4 to produce self-consistent, unbiased texts that are highly correlated with human evaluation. It offers several advantages, including the ability to distinguish between real and generated images, evaluate text-image alignment, and assess image aesthetics without requiring model training or fine-tuning. X-IQE is more cost-effective and efficient compared to human evaluation, while significantly enhancing the transparency and explainability of deep image quality evaluation models. We validate the effectiveness of our method as a benchmark using images generated by prevalent diffusion models. X-IQE demonstrates similar performance to state-of-the-art (SOTA) evaluation methods on COCO Caption, while overcoming the limitations of previous evaluation models on DrawBench, particularly in handling ambiguous generation prompts and text recognition in generated images. Project website: https://github.com/Schuture/Benchmarking-Awesome-Diffusion-Models
Adaptive Region Selection for Active Learning in Whole Slide Image Semantic Segmentation
Jul 14, 2023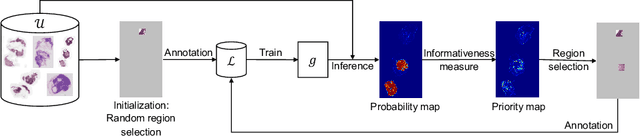
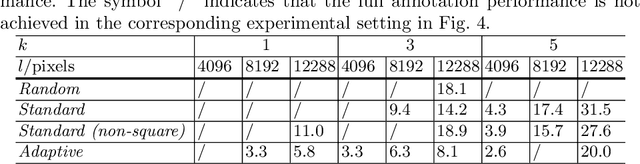
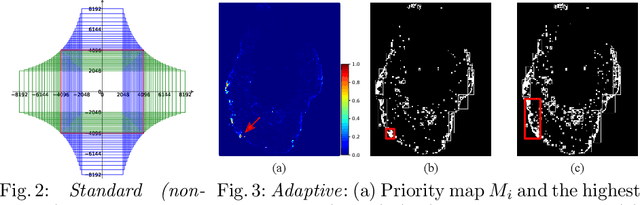
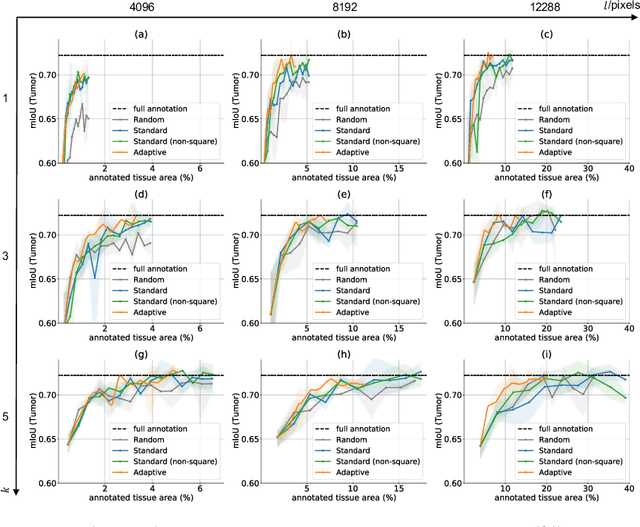
The process of annotating histological gigapixel-sized whole slide images (WSIs) at the pixel level for the purpose of training a supervised segmentation model is time-consuming. Region-based active learning (AL) involves training the model on a limited number of annotated image regions instead of requesting annotations of the entire images. These annotation regions are iteratively selected, with the goal of optimizing model performance while minimizing the annotated area. The standard method for region selection evaluates the informativeness of all square regions of a specified size and then selects a specific quantity of the most informative regions. We find that the efficiency of this method highly depends on the choice of AL step size (i.e., the combination of region size and the number of selected regions per WSI), and a suboptimal AL step size can result in redundant annotation requests or inflated computation costs. This paper introduces a novel technique for selecting annotation regions adaptively, mitigating the reliance on this AL hyperparameter. Specifically, we dynamically determine each region by first identifying an informative area and then detecting its optimal bounding box, as opposed to selecting regions of a uniform predefined shape and size as in the standard method. We evaluate our method using the task of breast cancer metastases segmentation on the public CAMELYON16 dataset and show that it consistently achieves higher sampling efficiency than the standard method across various AL step sizes. With only 2.6\% of tissue area annotated, we achieve full annotation performance and thereby substantially reduce the costs of annotating a WSI dataset. The source code is available at https://github.com/DeepMicroscopy/AdaptiveRegionSelection.
Can Self-Supervised Representation Learning Methods Withstand Distribution Shifts and Corruptions?
Aug 11, 2023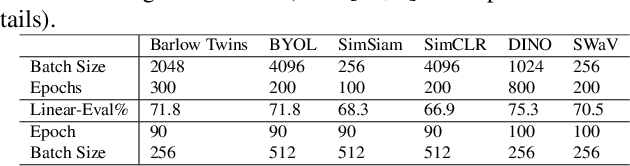
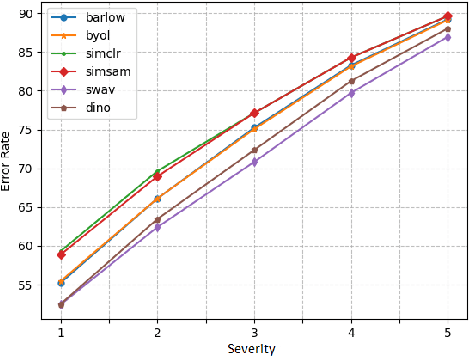
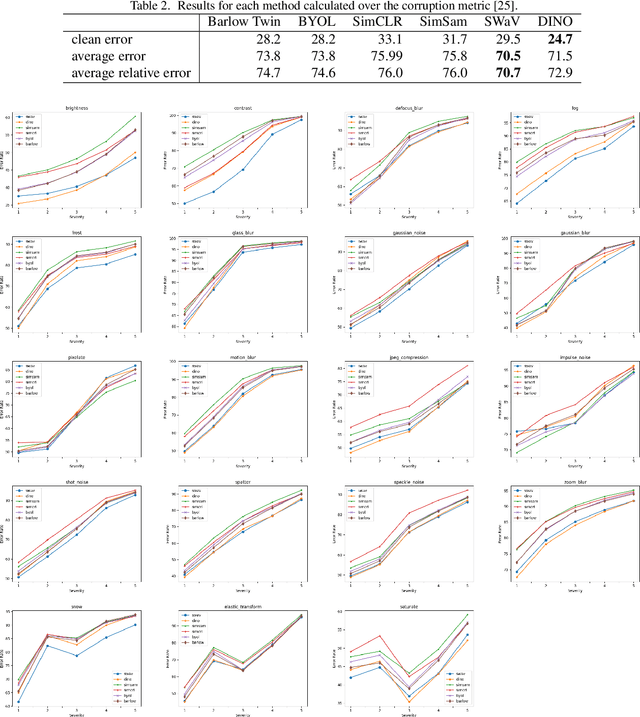

Self-supervised learning in computer vision aims to leverage the inherent structure and relationships within data to learn meaningful representations without explicit human annotation, enabling a holistic understanding of visual scenes. Robustness in vision machine learning ensures reliable and consistent performance, enhancing generalization, adaptability, and resistance to noise, variations, and adversarial attacks. Self-supervised paradigms, namely contrastive learning, knowledge distillation, mutual information maximization, and clustering, have been considered to have shown advances in invariant learning representations. This work investigates the robustness of learned representations of self-supervised learning approaches focusing on distribution shifts and image corruptions in computer vision. Detailed experiments have been conducted to study the robustness of self-supervised learning methods on distribution shifts and image corruptions. The empirical analysis demonstrates a clear relationship between the performance of learned representations within self-supervised paradigms and the severity of distribution shifts and corruptions. Notably, higher levels of shifts and corruptions are found to significantly diminish the robustness of the learned representations. These findings highlight the critical impact of distribution shifts and image corruptions on the performance and resilience of self-supervised learning methods, emphasizing the need for effective strategies to mitigate their adverse effects. The study strongly advocates for future research in the field of self-supervised representation learning to prioritize the key aspects of safety and robustness in order to ensure practical applicability. The source code and results are available on GitHub.
VERF: Runtime Monitoring of Pose Estimation with Neural Radiance Fields
Aug 11, 2023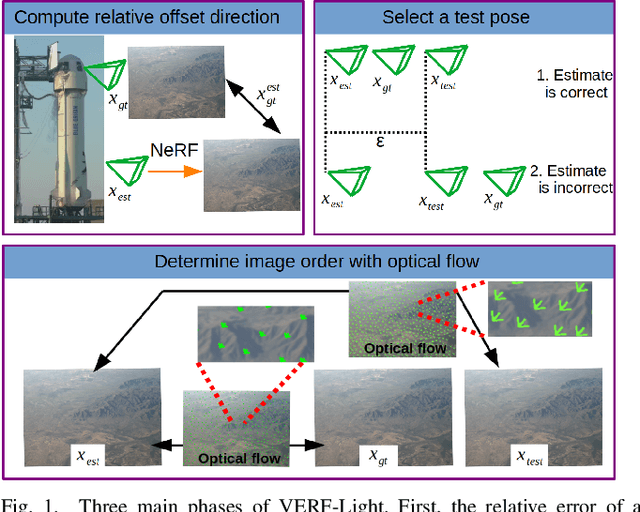
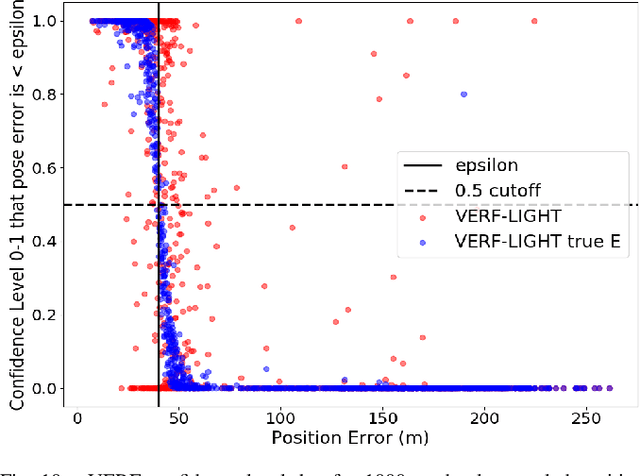
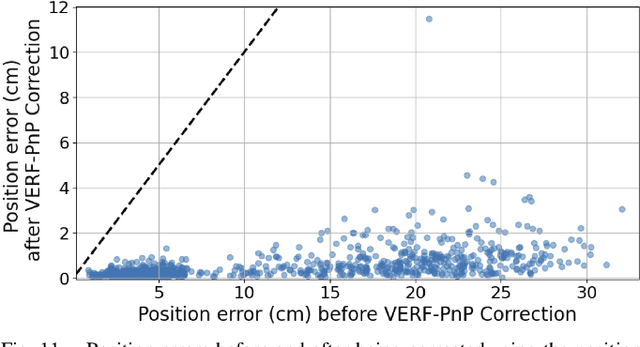
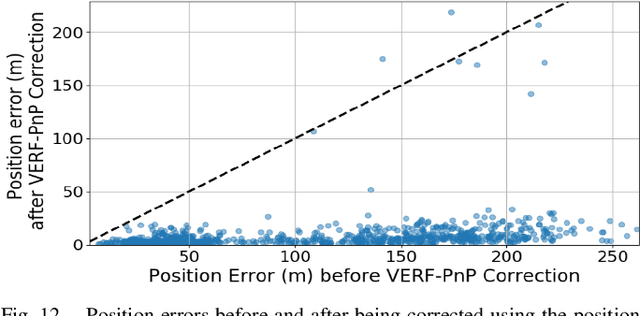
We present VERF, a collection of two methods (VERF-PnP and VERF-Light) for providing runtime assurance on the correctness of a camera pose estimate of a monocular camera without relying on direct depth measurements. We leverage the ability of NeRF (Neural Radiance Fields) to render novel RGB perspectives of a scene. We only require as input the camera image whose pose is being estimated, an estimate of the camera pose we want to monitor, and a NeRF model containing the scene pictured by the camera. We can then predict if the pose estimate is within a desired distance from the ground truth and justify our prediction with a level of confidence. VERF-Light does this by rendering a viewpoint with NeRF at the estimated pose and estimating its relative offset to the sensor image up to scale. Since scene scale is unknown, the approach renders another auxiliary image and reasons over the consistency of the optical flows across the three images. VERF-PnP takes a different approach by rendering a stereo pair of images with NeRF and utilizing the Perspective-n-Point (PnP) algorithm. We evaluate both methods on the LLFF dataset, on data from a Unitree A1 quadruped robot, and on data collected from Blue Origin's sub-orbital New Shepard rocket to demonstrate the effectiveness of the proposed pose monitoring method across a range of scene scales. We also show monitoring can be completed in under half a second on a 3090 GPU.
CATS v2: Hybrid encoders for robust medical segmentation
Aug 11, 2023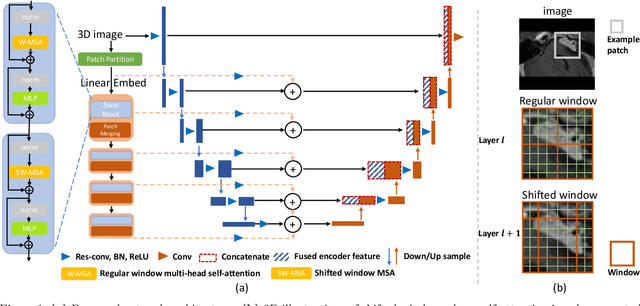
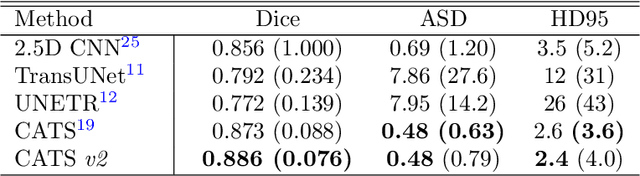
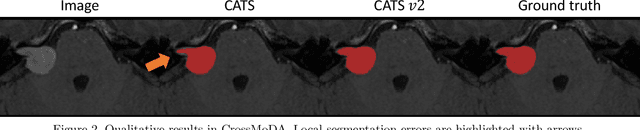
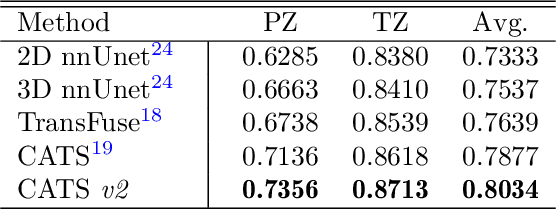
Convolutional Neural Networks (CNNs) have exhibited strong performance in medical image segmentation tasks by capturing high-level (local) information, such as edges and textures. However, due to the limited field of view of convolution kernel, it is hard for CNNs to fully represent global information. Recently, transformers have shown good performance for medical image segmentation due to their ability to better model long-range dependencies. Nevertheless, transformers struggle to capture high-level spatial features as effectively as CNNs. A good segmentation model should learn a better representation from local and global features to be both precise and semantically accurate. In our previous work, we proposed CATS, which is a U-shaped segmentation network augmented with transformer encoder. In this work, we further extend this model and propose CATS v2 with hybrid encoders. Specifically, hybrid encoders consist of a CNN-based encoder path paralleled to a transformer path with a shifted window, which better leverage both local and global information to produce robust 3D medical image segmentation. We fuse the information from the convolutional encoder and the transformer at the skip connections of different resolutions to form the final segmentation. The proposed method is evaluated on two public challenge datasets: Cross-Modality Domain Adaptation (CrossMoDA) and task 5 of Medical Segmentation Decathlon (MSD-5), to segment vestibular schwannoma (VS) and prostate, respectively. Compared with the state-of-the-art methods, our approach demonstrates superior performance in terms of higher Dice scores.
Temporally-Extended Prompts Optimization for SAM in Interactive Medical Image Segmentation
Jun 15, 2023
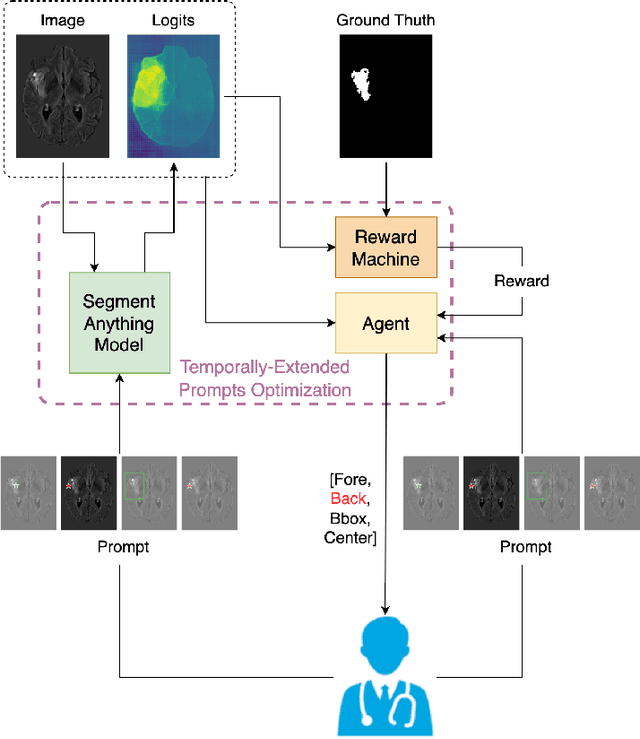
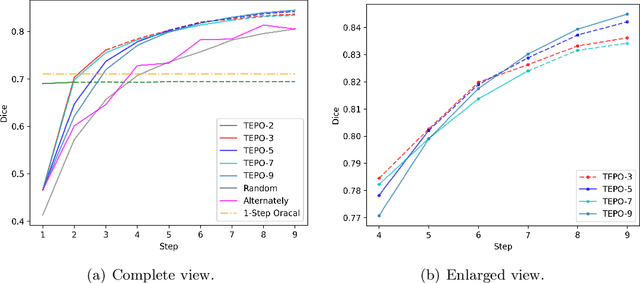

The Segmentation Anything Model (SAM) has recently emerged as a foundation model for addressing image segmentation. Owing to the intrinsic complexity of medical images and the high annotation cost, the medical image segmentation (MIS) community has been encouraged to investigate SAM's zero-shot capabilities to facilitate automatic annotation. Inspired by the extraordinary accomplishments of interactive medical image segmentation (IMIS) paradigm, this paper focuses on assessing the potential of SAM's zero-shot capabilities within the IMIS paradigm to amplify its benefits in the MIS domain. Regrettably, we observe that SAM's vulnerability to prompt forms (e.g., points, bounding boxes) becomes notably pronounced in IMIS. This leads us to develop a framework that adaptively offers suitable prompt forms for human experts. We refer to the framework above as temporally-extended prompts optimization (TEPO) and model it as a Markov decision process, solvable through reinforcement learning. Numerical experiments on the standardized benchmark BraTS2020 demonstrate that the learned TEPO agent can further enhance SAM's zero-shot capability in the MIS context.
Visually-Grounded Descriptions Improve Zero-Shot Image Classification
Jun 23, 2023
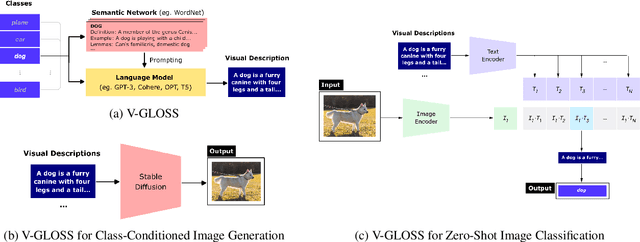

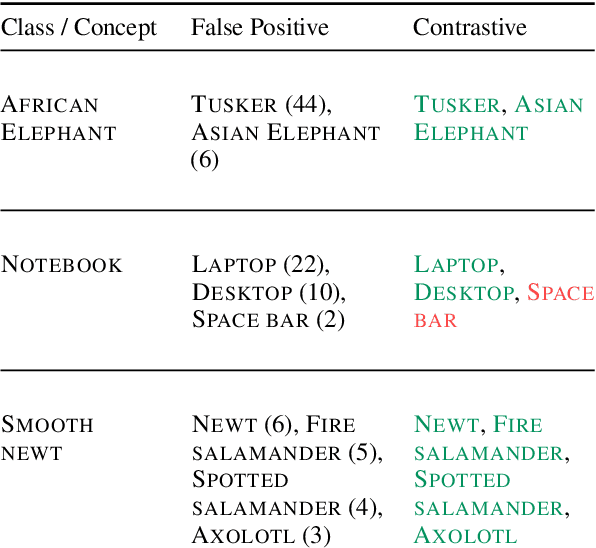
Language-vision models like CLIP have made significant progress in zero-shot vision tasks, such as zero-shot image classification (ZSIC). However, generating specific and expressive class descriptions remains a major challenge. Existing approaches suffer from granularity and label ambiguity issues. To tackle these challenges, we propose V-GLOSS: Visual Glosses, a novel method leveraging modern language models and semantic knowledge bases to produce visually-grounded class descriptions. We demonstrate V-GLOSS's effectiveness by achieving state-of-the-art results on benchmark ZSIC datasets including ImageNet and STL-10. In addition, we introduce a silver dataset with class descriptions generated by V-GLOSS, and show its usefulness for vision tasks. We make available our code and dataset.
Inter-Rater Uncertainty Quantification in Medical Image Segmentation via Rater-Specific Bayesian Neural Networks
Jun 28, 2023
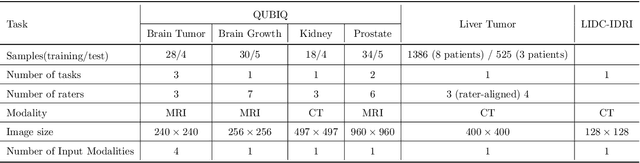

Automated medical image segmentation inherently involves a certain degree of uncertainty. One key factor contributing to this uncertainty is the ambiguity that can arise in determining the boundaries of a target region of interest, primarily due to variations in image appearance. On top of this, even among experts in the field, different opinions can emerge regarding the precise definition of specific anatomical structures. This work specifically addresses the modeling of segmentation uncertainty, known as inter-rater uncertainty. Its primary objective is to explore and analyze the variability in segmentation outcomes that can occur when multiple experts in medical imaging interpret and annotate the same images. We introduce a novel Bayesian neural network-based architecture to estimate inter-rater uncertainty in medical image segmentation. Our approach has three key advancements. Firstly, we introduce a one-encoder-multi-decoder architecture specifically tailored for uncertainty estimation, enabling us to capture the rater-specific representation of each expert involved. Secondly, we propose Bayesian modeling for the new architecture, allowing efficient capture of the inter-rater distribution, particularly in scenarios with limited annotations. Lastly, we enhance the rater-specific representation by integrating an attention module into each decoder. This module facilitates focused and refined segmentation results for each rater. We conduct extensive evaluations using synthetic and real-world datasets to validate our technical innovations rigorously. Our method surpasses existing baseline methods in five out of seven diverse tasks on the publicly available \emph{QUBIQ} dataset, considering two evaluation metrics encompassing different uncertainty aspects. Our codes, models, and the new dataset are available through our GitHub repository: https://github.com/HaoWang420/bOEMD-net .
Investigating and Improving Latent Density Segmentation Models for Aleatoric Uncertainty Quantification in Medical Imaging
Aug 15, 2023


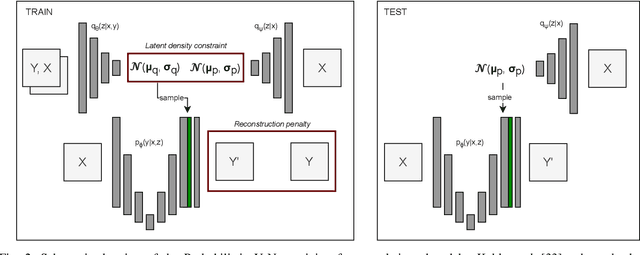
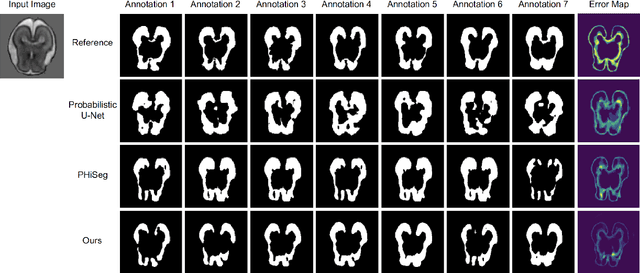
Data uncertainties, such as sensor noise or occlusions, can introduce irreducible ambiguities in images, which result in varying, yet plausible, semantic hypotheses. In Machine Learning, this ambiguity is commonly referred to as aleatoric uncertainty. Latent density models can be utilized to address this problem in image segmentation. The most popular approach is the Probabilistic U-Net (PU-Net), which uses latent Normal densities to optimize the conditional data log-likelihood Evidence Lower Bound. In this work, we demonstrate that the PU- Net latent space is severely inhomogenous. As a result, the effectiveness of gradient descent is inhibited and the model becomes extremely sensitive to the localization of the latent space samples, resulting in defective predictions. To address this, we present the Sinkhorn PU-Net (SPU-Net), which uses the Sinkhorn Divergence to promote homogeneity across all latent dimensions, effectively improving gradient-descent updates and model robustness. Our results show that by applying this on public datasets of various clinical segmentation problems, the SPU-Net receives up to 11% performance gains compared against preceding latent variable models for probabilistic segmentation on the Hungarian-Matched metric. The results indicate that by encouraging a homogeneous latent space, one can significantly improve latent density modeling for medical image segmentation.