 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UniPT: Universal Parallel Tuning for Transfer Learning with Efficient Parameter and Memory
Aug 28, 2023
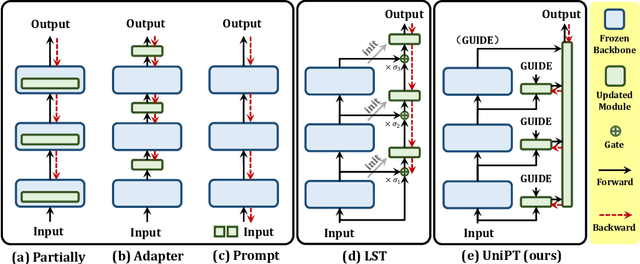
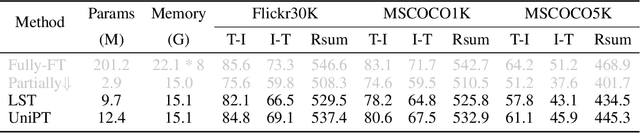
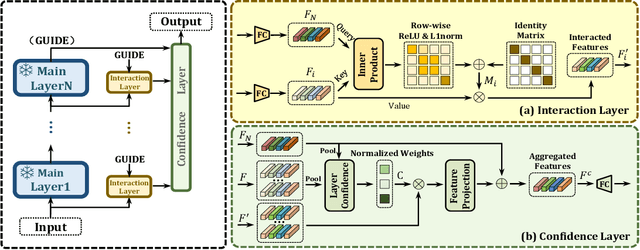
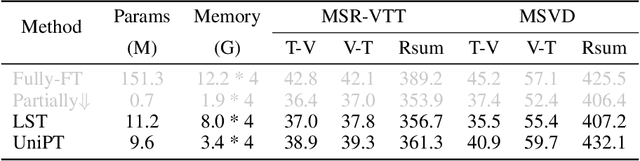
Fine-tuning pre-trained models has emerged as a powerful technique in numerous domains, owing to its ability to leverage enormous pre-existing knowledge and achieve remarkable performance on downstream tasks. However, updating the parameters of entire networks is computationally intensive. Although state-of-the-art parameter-efficient transfer learning (PETL) methods significantly reduce the trainable parameters and storage demand, almost all of them still need to back-propagate the gradients through large pre-trained networks. This memory-extensive characteristic extremely limits the applicability of PETL methods in real-world scenarios. To this end, we propose a new memory-efficient PETL strategy, dubbed Universal Parallel Tuning (UniPT). Specifically, we facilitate the transfer process via a lightweight learnable parallel network, which consists of two modules: 1) A parallel interaction module that decouples the inherently sequential connections and processes the intermediate activations detachedly of the pre-trained network. 2) A confidence aggregation module that learns optimal strategies adaptively for integrating cross-layer features. We evaluate UniPT with different backbones (e.g., VSE$\infty$, CLIP4Clip, Clip-ViL, and MDETR) on five challenging vision-and-language tasks (i.e., image-text retrieval, video-text retrieval, visual question answering, compositional question answering, and visual grounding). Extensive ablations on ten datasets have validated that our UniPT can not only dramatically reduce memory consumption and outperform the best memory-efficient competitor, but also achieve higher performance than existing PETL methods in a low-memory scenario on different architectures. Our code is publicly available at: https://github.com/Paranioar/UniPT.
RegionBLIP: A Unified Multi-modal Pre-training Framework for Holistic and Regional Comprehension
Aug 03, 2023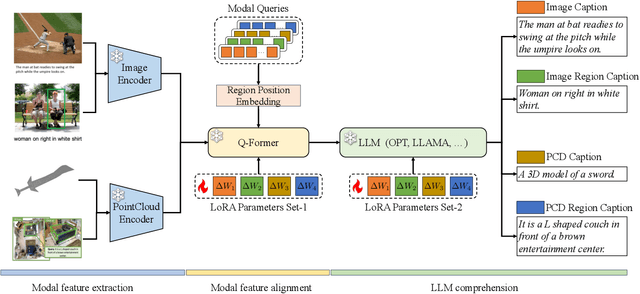
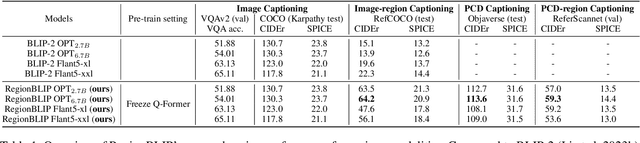


In this work, we investigate extending the comprehension of Multi-modal Large Language Models (MLLMs) to regional objects. To this end, we propose to extract features corresponding to regional objects as soft prompts for LLM, which provides a straightforward and scalable approach and eliminates the need for LLM fine-tuning. To effectively extract regional features from regular image features and irregular point cloud features, we present a novel and unified position-assisted feature extraction module. Furthermore, training an MLLM from scratch is highly time-consuming. Thus, we propose incrementally extending existing pre-trained MLLMs to comprehend more modalities and the regional objects of those modalities. Specifically, we freeze the Q-Former from BLIP-2, an impressive MLLM, and optimize the modality-specific Lora parameters in Q-Former and LLM for each newly introduced modality. The freezing of the Q-Former eliminates the need for extensive pre-training on massive image-text data. The freezed Q-Former pre-trained from massive image-text data is also beneficial for the pre-training on image-region-text data. We name our framework RegionBLIP. We pre-train RegionBLIP on image-region-text, point-cloud-text, and point-cloud-region-text data. Experimental results verify that \Ours{} can preserve the image comprehension capability of BILP-2 and further gain a comprehension of the newly introduced point cloud modality and regional objects. The Data, Code, and Pre-trained models will be available at https://github.com/mightyzau/RegionBLIP.
Real-World Image Variation by Aligning Diffusion Inversion Chain
May 30, 2023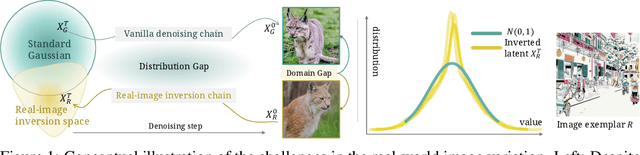
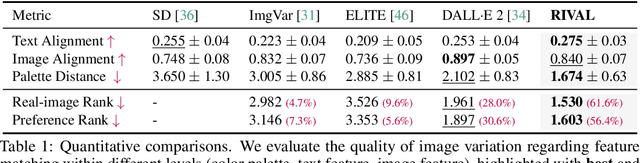
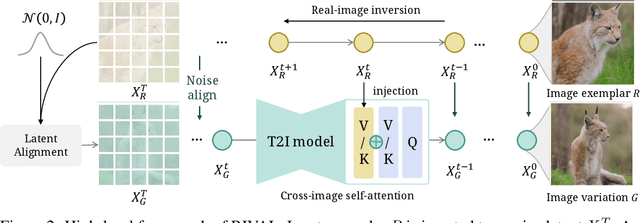

Recent diffusion model advancements have enabled high-fidelity images to be generated using text prompts. However, a domain gap exists between generated images and real-world images, which poses a challenge in generating high-quality variations of real-world images. Our investigation uncovers that this domain gap originates from a latents' distribution gap in different diffusion processes. To address this issue, we propose a novel inference pipeline called Real-world Image Variation by ALignment (RIVAL) that utilizes diffusion models to generate image variations from a single image exemplar. Our pipeline enhances the generation quality of image variations by aligning the image generation process to the source image's inversion chain. Specifically, we demonstrate that step-wise latent distribution alignment is essential for generating high-quality variations. To attain this, we design a cross-image self-attention injection for feature interaction and a step-wise distribution normalization to align the latent features. Incorporating these alignment processes into a diffusion model allows RIVAL to generate high-quality image variations without further parameter optimization. Our experimental results demonstrate that our proposed approach outperforms existing methods with respect to semantic-condition similarity and perceptual quality. Furthermore, this generalized inference pipeline can be easily applied to other diffusion-based generation tasks, such as image-conditioned text-to-image generation and example-based image inpainting.
Multi-Label Self-Supervised Learning with Scene Images
Aug 08, 2023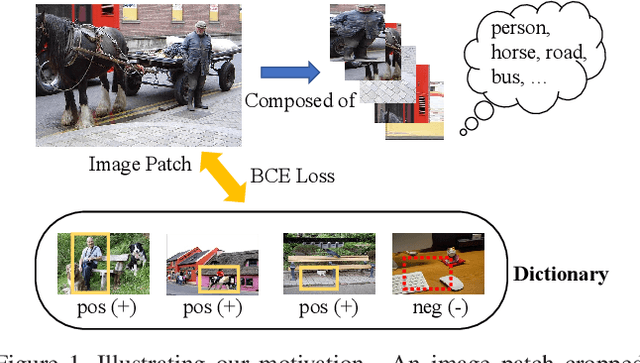
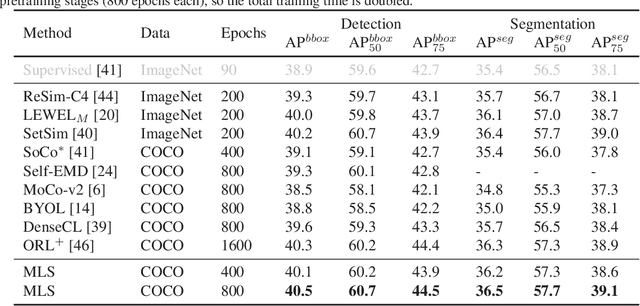
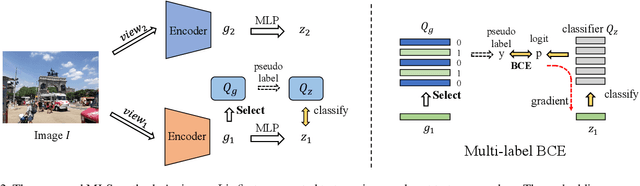
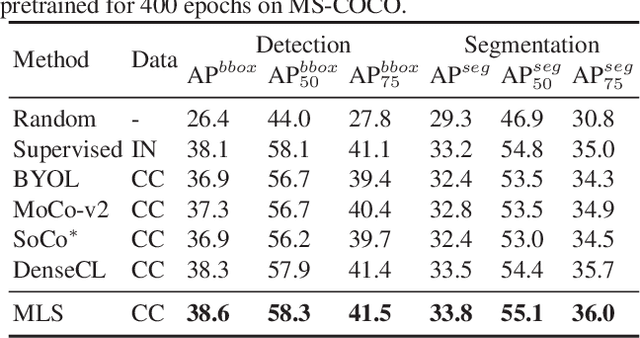
Self-supervised learning (SSL) methods targeting scene images have seen a rapid growth recently, and they mostly rely on either a dedicated dense matching mechanism or a costly unsupervised object discovery module. This paper shows that instead of hinging on these strenuous operations, quality image representations can be learned by treating scene/multi-label image SSL simply as a multi-label classification problem, which greatly simplifies the learning framework. Specifically, multiple binary pseudo-labels are assigned for each input image by comparing its embeddings with those in two dictionaries, and the network is optimized using the binary cross entropy loss. The proposed method is named Multi-Label Self-supervised learning (MLS). Visualizations qualitatively show that clearly the pseudo-labels by MLS can automatically find semantically similar pseudo-positive pairs across different images to facilitate contrastive learning. MLS learns high quality representations on MS-COCO and achieves state-of-the-art results on classification, detection and segmentation benchmarks. At the same time, MLS is much simpler than existing methods, making it easier to deploy and for further exploration.
A-STAR: Test-time Attention Segregation and Retention for Text-to-image Synthesis
Jun 26, 2023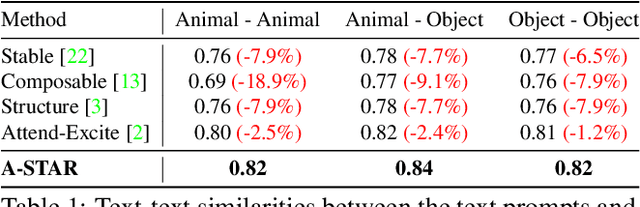
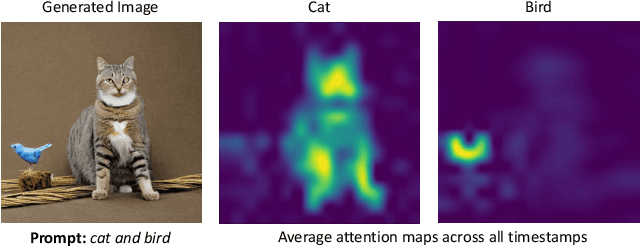
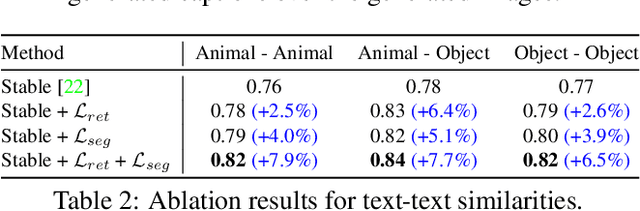

While recent developments in text-to-image generative models have led to a suite of high-performing methods capable of producing creative imagery from free-form text, there are several limitations. By analyzing the cross-attention representations of these models, we notice two key issues. First, for text prompts that contain multiple concepts, there is a significant amount of pixel-space overlap (i.e., same spatial regions) among pairs of different concepts. This eventually leads to the model being unable to distinguish between the two concepts and one of them being ignored in the final generation. Next, while these models attempt to capture all such concepts during the beginning of denoising (e.g., first few steps) as evidenced by cross-attention maps, this knowledge is not retained by the end of denoising (e.g., last few steps). Such loss of knowledge eventually leads to inaccurate generation outputs. To address these issues, our key innovations include two test-time attention-based loss functions that substantially improve the performance of pretrained baseline text-to-image diffusion models. First, our attention segregation loss reduces the cross-attention overlap between attention maps of different concepts in the text prompt, thereby reducing the confusion/conflict among various concepts and the eventual capture of all concepts in the generated output. Next, our attention retention loss explicitly forces text-to-image diffusion models to retain cross-attention information for all concepts across all denoising time steps, thereby leading to reduced information loss and the preservation of all concepts in the generated output.
DomainStudio: Fine-Tuning Diffusion Models for Domain-Driven Image Generation using Limited Data
Jun 25, 2023Denoising diffusion probabilistic models (DDPMs) have been proven capable of synthesizing high-quality images with remarkable diversity when trained on large amounts of data. Typical diffusion models and modern large-scale conditional generative models like text-to-image generative models are vulnerable to overfitting when fine-tuned on extremely limited data. Existing works have explored subject-driven generation using a reference set containing a few images. However, few prior works explore DDPM-based domain-driven generation, which aims to learn the common features of target domains while maintaining diversity. This paper proposes a novel DomainStudio approach to adapt DDPMs pre-trained on large-scale source datasets to target domains using limited data. It is designed to keep the diversity of subjects provided by source domains and get high-quality and diverse adapted samples in target domains. We propose to keep the relative distances between adapted samples to achieve considerable generation diversity. In addition, we further enhance the learning of high-frequency details for better generation quality. Our approach is compatible with both unconditional and conditional diffusion models. This work makes the first attempt to realize unconditional few-shot image generation with diffusion models, achieving better quality and greater diversity than current state-of-the-art GAN-based approaches. Moreover, this work also significantly relieves overfitting for conditional generation and realizes high-quality domain-driven generation, further expanding the applicable scenarios of modern large-scale text-to-image models.
Revealing the Underlying Patterns: Investigating Dataset Similarity, Performance, and Generalization
Aug 07, 2023Supervised deep learning models require significant amount of labelled data to achieve an acceptable performance on a specific task. However, when tested on unseen data, the models may not perform well. Therefore, the models need to be trained with additional and varying labelled data to improve the generalization. In this work, our goal is to understand the models, their performance and generalization. We establish image-image, dataset-dataset, and image-dataset distances to gain insights into the model's behavior. Our proposed distance metric when combined with model performance can help in selecting an appropriate model/architecture from a pool of candidate architectures. We have shown that the generalization of these models can be improved by only adding a small number of unseen images (say 1, 3 or 7) into the training set. Our proposed approach reduces training and annotation costs while providing an estimate of model performance on unseen data in dynamic environments.
Federated Learning for Medical Image Analysis: A Survey
Jun 09, 2023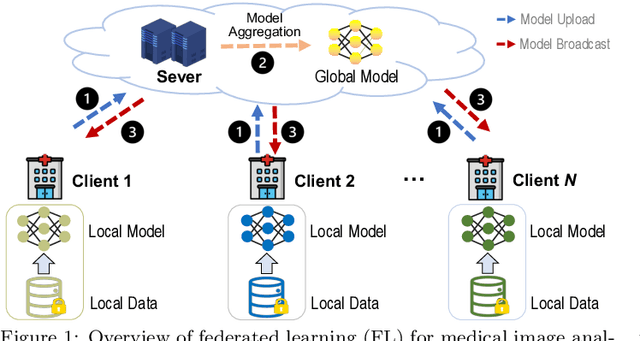
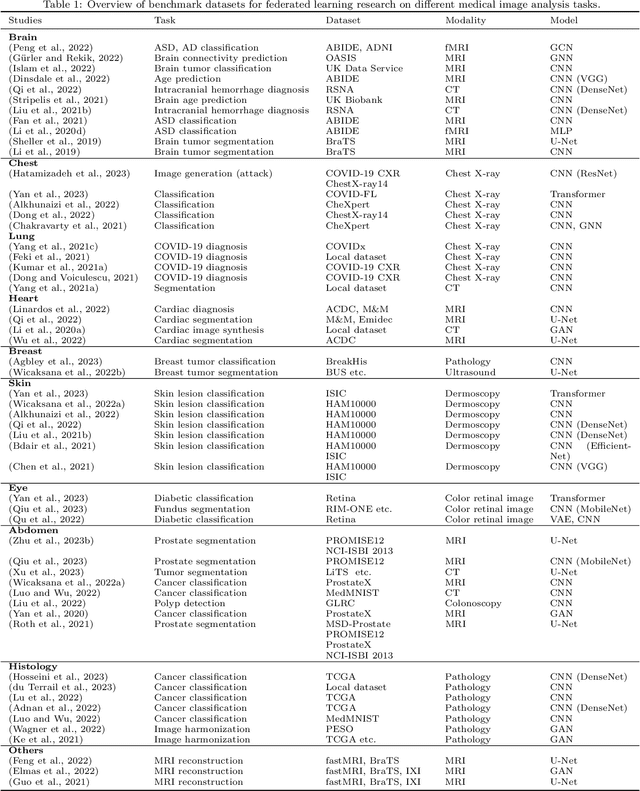
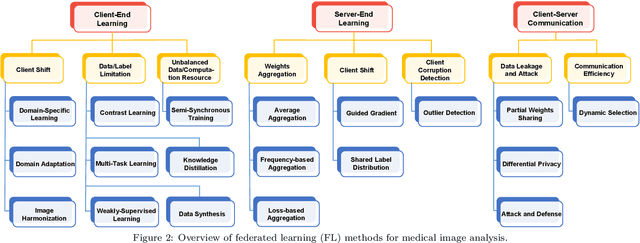
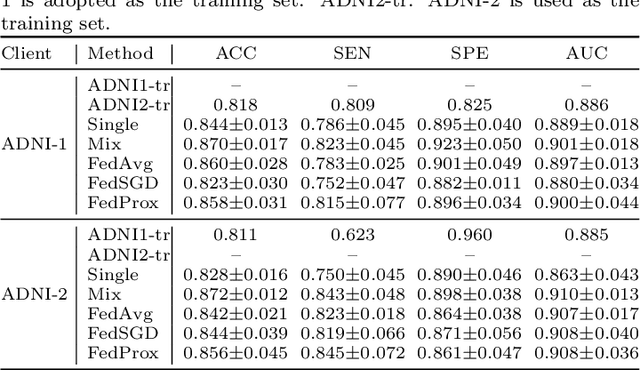
Machine learning in medical imaging often faces a fundamental dilemma, namely the small sample size problem. Many recent studies suggest using multi-domain data pooled from different acquisition sites/datasets to improve statistical power. However, medical images from different sites cannot be easily shared to build large datasets for model training due to privacy protection reasons. As a promising solution, federated learning, which enables collaborative training of machine learning models based on data from different sites without cross-site data sharing, has attracted considerable attention recently. In this paper, we conduct a comprehensive survey of the recent development of federated learning methods in medical image analysis. We first introduce the background and motivation of federated learning for dealing with privacy protection and collaborative learning issues in medical imaging. We then present a comprehensive review of recent advances in federated learning methods for medical image analysis. Specifically, existing methods are categorized based on three critical aspects of a federated learning system, including client end, server end, and communication techniques. In each category, we summarize the existing federated learning methods according to specific research problems in medical image analysis and also provide insights into the motivations of different approaches. In addition, we provide a review of existing benchmark medical imaging datasets and software platforms for current federated learning research. We also conduct an experimental study to empirically evaluate typical federated learning methods for medical image analysis. This survey can help to better understand the current research status, challenges and potential research opportunities in this promising research field.
Unsupervised Low Light Image Enhancement Using SNR-Aware Swin Transformer
Jun 03, 2023
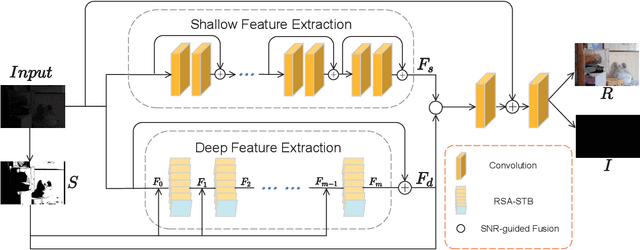
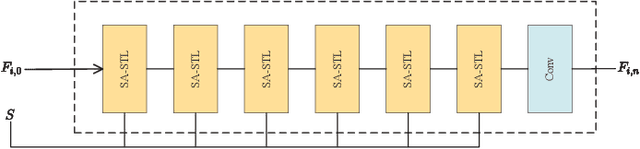
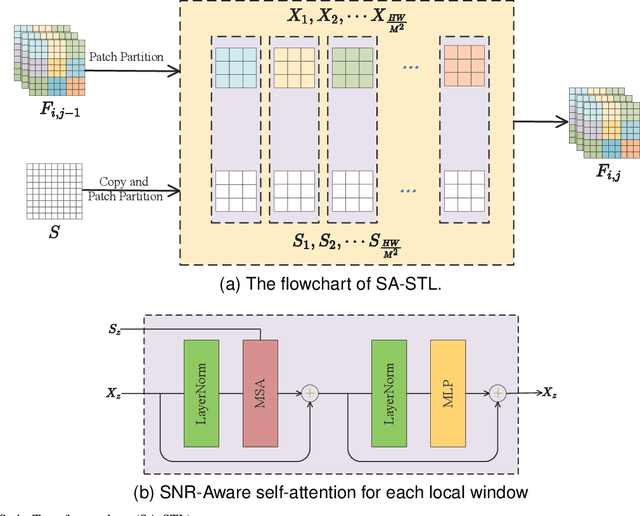
Image captured under low-light conditions presents unpleasing artifacts, which debilitate the performance of feature extraction for many upstream visual tasks. Low-light image enhancement aims at improving brightness and contrast, and further reducing noise that corrupts the visual quality. Recently, many image restoration methods based on Swin Transformer have been proposed and achieve impressive performance. However, On one hand, trivially employing Swin Transformer for low-light image enhancement would expose some artifacts, including over-exposure, brightness imbalance and noise corruption, etc. On the other hand, it is impractical to capture image pairs of low-light images and corresponding ground-truth, i.e. well-exposed image in same visual scene. In this paper, we propose a dual-branch network based on Swin Transformer, guided by a signal-to-noise ratio prior map which provides the spatial-varying information for low-light image enhancement. Moreover, we leverage unsupervised learning to construct the optimization objective based on Retinex model, to guide the training of proposed network. Experimental results demonstrate that the proposed model is competitive with the baseline models.
Can Self-Supervised Representation Learning Methods Withstand Distribution Shifts and Corruptions?
Aug 11, 2023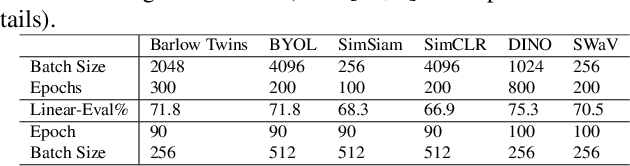
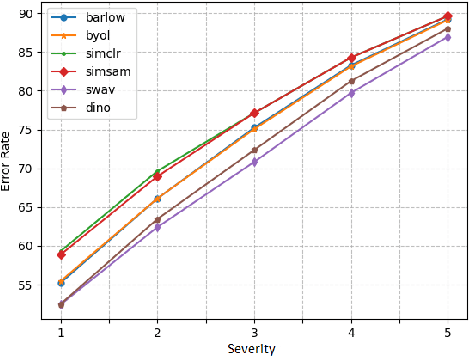
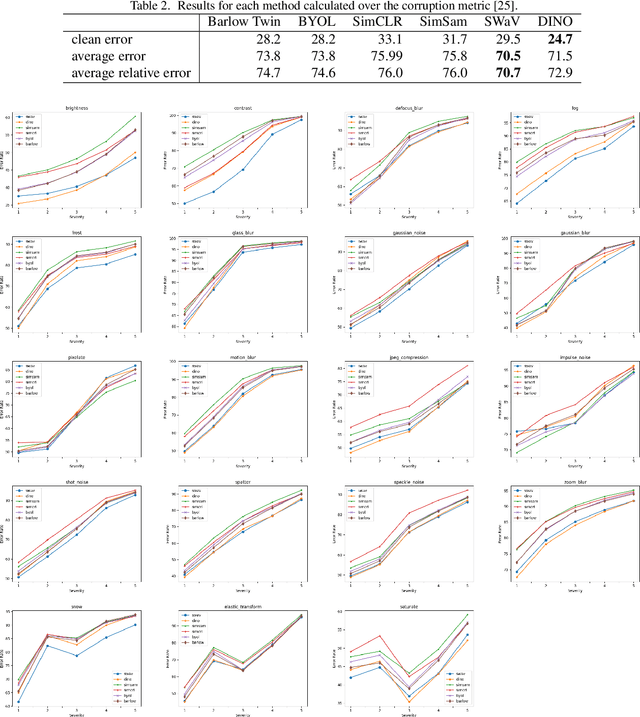

Self-supervised learning in computer vision aims to leverage the inherent structure and relationships within data to learn meaningful representations without explicit human annotation, enabling a holistic understanding of visual scenes. Robustness in vision machine learning ensures reliable and consistent performance, enhancing generalization, adaptability, and resistance to noise, variations, and adversarial attacks. Self-supervised paradigms, namely contrastive learning, knowledge distillation, mutual information maximization, and clustering, have been considered to have shown advances in invariant learning representations. This work investigates the robustness of learned representations of self-supervised learning approaches focusing on distribution shifts and image corruptions in computer vision. Detailed experiments have been conducted to study the robustness of self-supervised learning methods on distribution shifts and image corruptions. The empirical analysis demonstrates a clear relationship between the performance of learned representations within self-supervised paradigms and the severity of distribution shifts and corruptions. Notably, higher levels of shifts and corruptions are found to significantly diminish the robustness of the learned representations. These findings highlight the critical impact of distribution shifts and image corruptions on the performance and resilience of self-supervised learning methods, emphasizing the need for effective strategies to mitigate their adverse effects. The study strongly advocates for future research in the field of self-supervised representation learning to prioritize the key aspects of safety and robustness in order to ensure practical applicability. The source code and results are available on GitHub.