 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An inexact proximal majorization-minimization Algorithm for remote sensing image stripe noise removal
Aug 17, 2023
The stripe noise existing in remote sensing images badly degrades the visual quality and restricts the precision of data analysis. Therefore, many destriping models have been proposed in recent years. In contrast to these existing models, in this paper, we propose a nonconvex model with a DC function (i.e., the difference of convex functions) structure to remove the strip noise. To solve this model, we make use of the DC structure and apply an inexact proximal majorization-minimization algorithm with each inner subproblem solved by the alternating direction method of multipliers. It deserves mentioning that we design an implementable stopping criterion for the inner subproblem, while the convergence can still be guaranteed. Numerical experiments demonstrate the superiority of the proposed model and algorithm.
Towards Interactive Image Inpainting via Sketch Refinement
Jun 14, 2023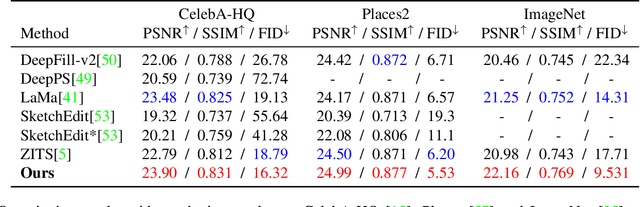
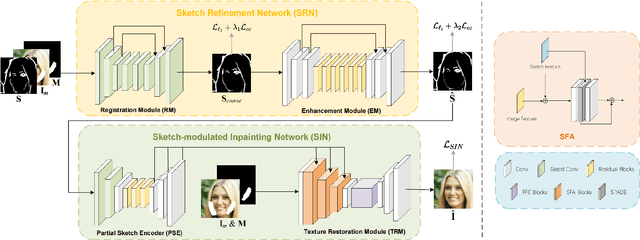
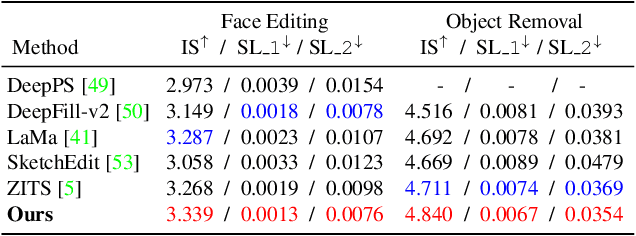

One tough problem of image inpainting is to restore complex structures in the corrupted regions. It motivates interactive image inpainting which leverages additional hints, e.g., sketches, to assist the inpainting process. Sketch is simple and intuitive to end users, but meanwhile has free forms with much randomness. Such randomness may confuse the inpainting models, and incur severe artifacts in completed images. To address this problem, we propose a two-stage image inpainting method termed SketchRefiner. In the first stage, we propose using a cross-correlation loss function to robustly calibrate and refine the user-provided sketches in a coarse-to-fine fashion. In the second stage, we learn to extract informative features from the abstracted sketches in the feature space and modulate the inpainting process. We also propose an algorithm to simulate real sketches automatically and build a test protocol with different applications. Experimental results on public datasets demonstrate that SketchRefiner effectively utilizes sketch information and eliminates the artifacts due to the free-form sketches. Our method consistently outperforms the state-of-the-art ones both qualitatively and quantitatively, meanwhile revealing great potential in real-world applications. Our code and dataset are available.
SAM-IQA: Can Segment Anything Boost Image Quality Assessment?
Jul 10, 2023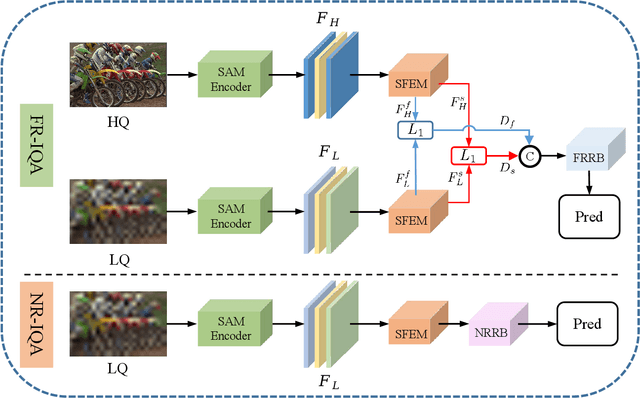
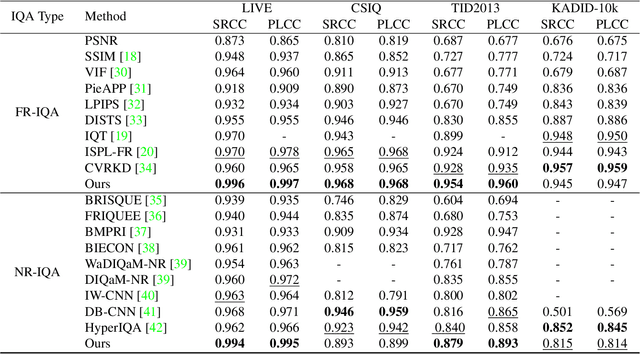
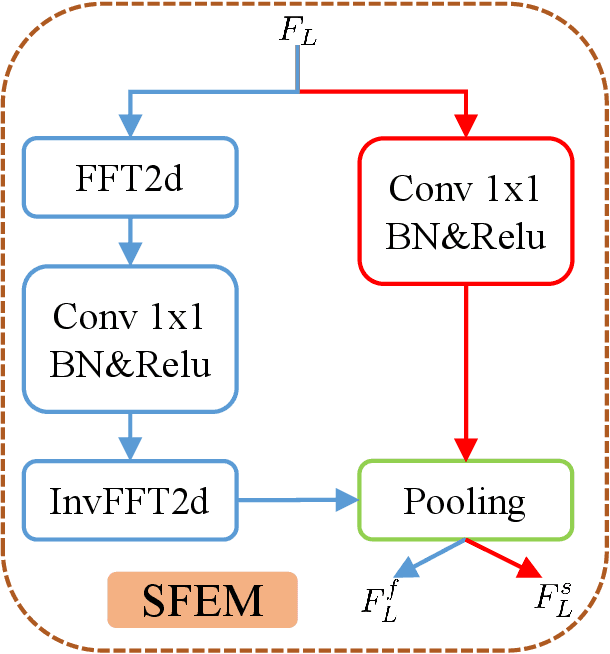
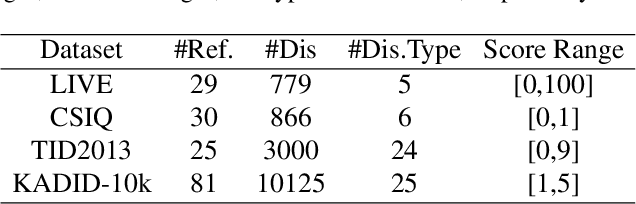
Image Quality Assessment (IQA) is a challenging task that requires training on massive datasets to achieve accurate predictions. However, due to the lack of IQA data, deep learning-based IQA methods typically rely on pre-trained networks trained on massive datasets as feature extractors to enhance their generalization ability, such as the ResNet network trained on ImageNet. In this paper, we utilize the encoder of Segment Anything, a recently proposed segmentation model trained on a massive dataset, for high-level semantic feature extraction. Most IQA methods are limited to extracting spatial-domain features, while frequency-domain features have been shown to better represent noise and blur. Therefore, we leverage both spatial-domain and frequency-domain features by applying Fourier and standard convolutions on the extracted features, respectively. Extensive experiments are conducted to demonstrate the effectiveness of all the proposed components, and results show that our approach outperforms the state-of-the-art (SOTA) in four representative datasets, both qualitatively and quantitatively. Our experiments confirm the powerful feature extraction capabilities of Segment Anything and highlight the value of combining spatial-domain and frequency-domain features in IQA tasks. Code: https://github.com/Hedlen/SAM-IQA
MILA: Memory-Based Instance-Level Adaptation for Cross-Domain Object Detection
Sep 03, 2023
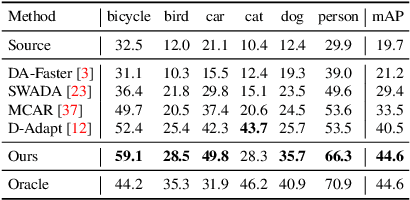
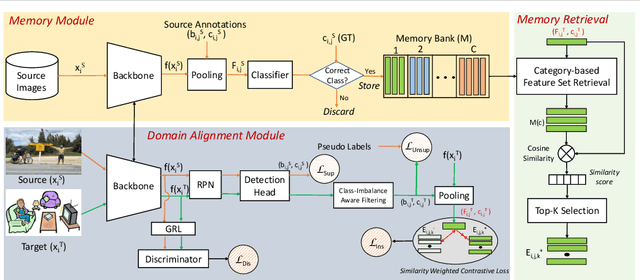
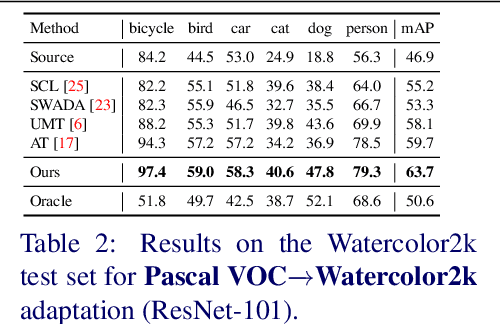
Cross-domain object detection is challenging, and it involves aligning labeled source and unlabeled target domains. Previous approaches have used adversarial training to align features at both image-level and instance-level. At the instance level, finding a suitable source sample that aligns with a target sample is crucial. A source sample is considered suitable if it differs from the target sample only in domain, without differences in unimportant characteristics such as orientation and color, which can hinder the model's focus on aligning the domain difference. However, existing instance-level feature alignment methods struggle to find suitable source instances because their search scope is limited to mini-batches. Mini-batches are often so small in size that they do not always contain suitable source instances. The insufficient diversity of mini-batches becomes problematic particularly when the target instances have high intra-class variance. To address this issue, we propose a memory-based instance-level domain adaptation framework. Our method aligns a target instance with the most similar source instance of the same category retrieved from a memory storage. Specifically, we introduce a memory module that dynamically stores the pooled features of all labeled source instances, categorized by their labels. Additionally, we introduce a simple yet effective memory retrieval module that retrieves a set of matching memory slots for target instances. Our experiments on various domain shift scenarios demonstrate that our approach outperforms existing non-memory-based methods significantly.
Zero-shot Text-driven Physically Interpretable Face Editing
Aug 11, 2023



This paper proposes a novel and physically interpretable method for face editing based on arbitrary text prompts. Different from previous GAN-inversion-based face editing methods that manipulate the latent space of GANs, or diffusion-based methods that model image manipulation as a reverse diffusion process, we regard the face editing process as imposing vector flow fields on face images, representing the offset of spatial coordinates and color for each image pixel. Under the above-proposed paradigm, we represent the vector flow field in two ways: 1) explicitly represent the flow vectors with rasterized tensors, and 2) implicitly parameterize the flow vectors as continuous, smooth, and resolution-agnostic neural fields, by leveraging the recent advances of implicit neural representations. The flow vectors are iteratively optimized under the guidance of the pre-trained Contrastive Language-Image Pretraining~(CLIP) model by maximizing the correlation between the edited image and the text prompt. We also propose a learning-based one-shot face editing framework, which is fast and adaptable to any text prompt input. Our method can also be flexibly extended to real-time video face editing. Compared with state-of-the-art text-driven face editing methods, our method can generate physically interpretable face editing results with high identity consistency and image quality. Our code will be made publicly available.
CIParsing: Unifying Causality Properties into Multiple Human Parsing
Aug 23, 2023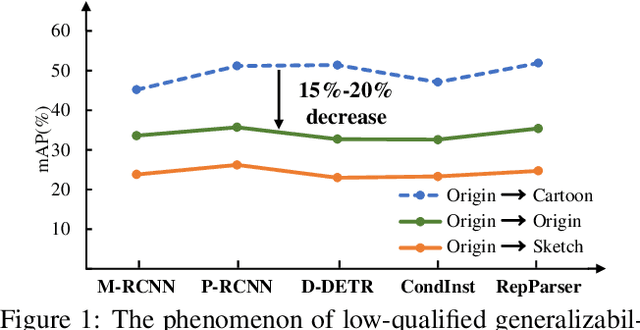
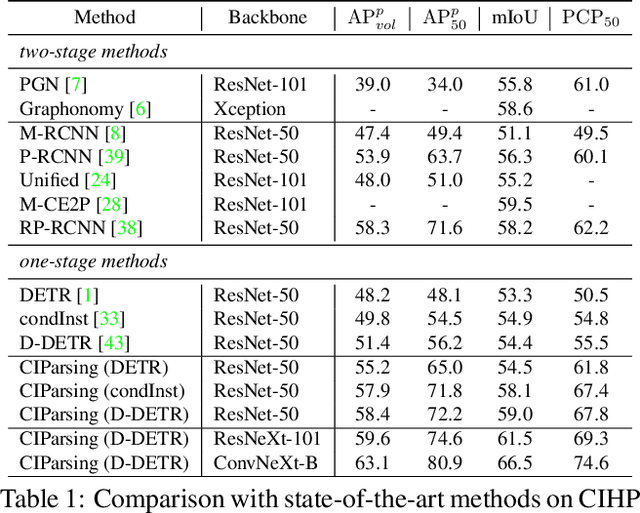
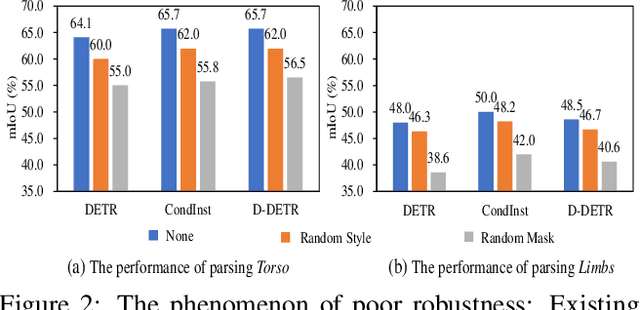
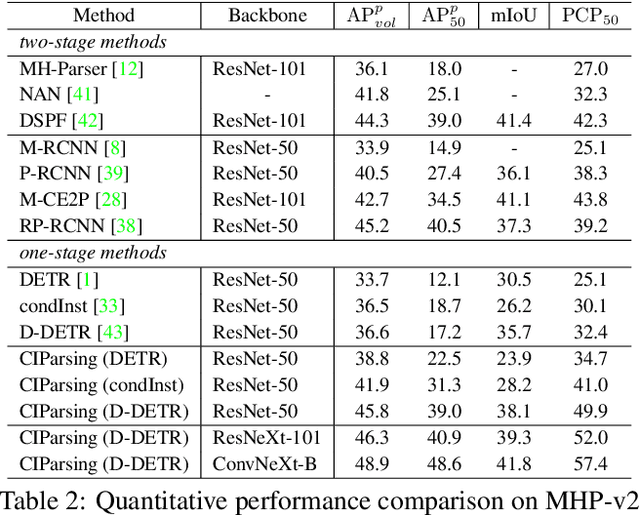
Existing methods of multiple human parsing (MHP) apply statistical models to acquire underlying associations between images and labeled body parts. However, acquired associations often contain many spurious correlations that degrade model generalization, leading statistical models to be vulnerable to visually contextual variations in images (e.g., unseen image styles/external interventions). To tackle this, we present a causality inspired parsing paradigm termed CIParsing, which follows fundamental causal principles involving two causal properties for human parsing (i.e., the causal diversity and the causal invariance). Specifically, we assume that an input image is constructed by a mix of causal factors (the characteristics of body parts) and non-causal factors (external contexts), where only the former ones cause the generation process of human parsing.Since causal/non-causal factors are unobservable, a human parser in proposed CIParsing is required to construct latent representations of causal factors and learns to enforce representations to satisfy the causal properties. In this way, the human parser is able to rely on causal factors w.r.t relevant evidence rather than non-causal factors w.r.t spurious correlations, thus alleviating model degradation and yielding improved parsing ability. Notably, the CIParsing is designed in a plug-and-play fashion and can be integrated into any existing MHP models. Extensive experiments conducted on two widely used benchmarks demonstrate the effectiveness and generalizability of our method.
AspectMMKG: A Multi-modal Knowledge Graph with Aspect-aware Entities
Aug 09, 2023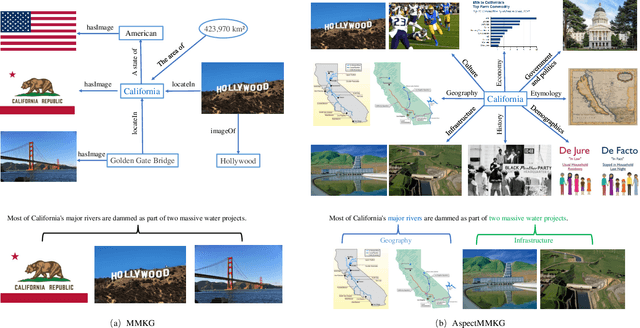
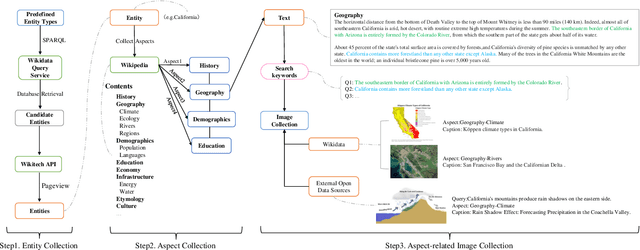
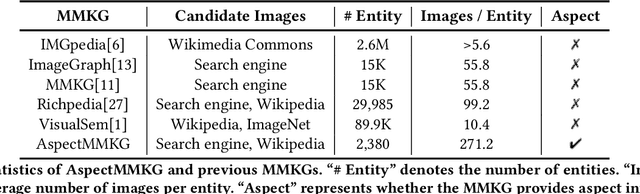
Multi-modal knowledge graphs (MMKGs) combine different modal data (e.g., text and image) for a comprehensive understanding of entities. Despite the recent progress of large-scale MMKGs, existing MMKGs neglect the multi-aspect nature of entities, limiting the ability to comprehend entities from various perspectives. In this paper, we construct AspectMMKG, the first MMKG with aspect-related images by matching images to different entity aspects. Specifically, we collect aspect-related images from a knowledge base, and further extract aspect-related sentences from the knowledge base as queries to retrieve a large number of aspect-related images via an online image search engine. Finally, AspectMMKG contains 2,380 entities, 18,139 entity aspects, and 645,383 aspect-related images. We demonstrate the usability of AspectMMKG in entity aspect linking (EAL) downstream task and show that previous EAL models achieve a new state-of-the-art performance with the help of AspectMMKG. To facilitate the research on aspect-related MMKG, we further propose an aspect-related image retrieval (AIR) model, that aims to correct and expand aspect-related images in AspectMMKG. We train an AIR model to learn the relationship between entity image and entity aspect-related images by incorporating entity image, aspect, and aspect image information. Experimental results indicate that the AIR model could retrieve suitable images for a given entity w.r.t different aspects.
Federated Learning for Medical Image Analysis: A Survey
Jun 16, 2023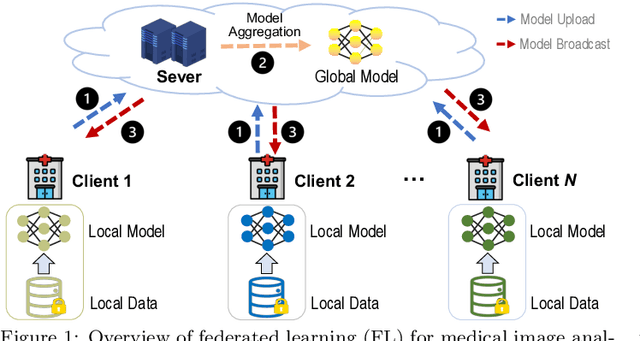
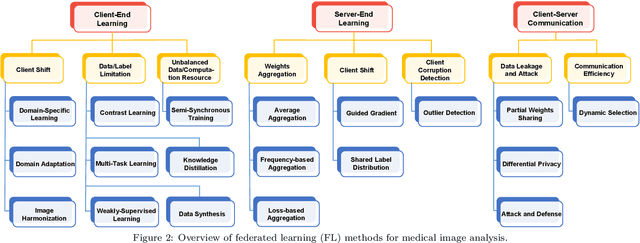
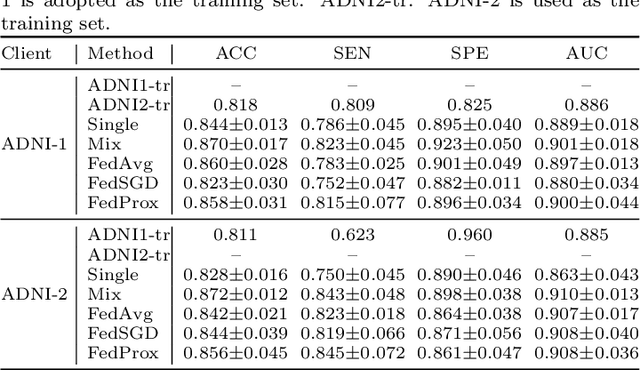
Machine learning in medical imaging often faces a fundamental dilemma, namely the small sample size problem. Many recent studies suggest using multi-domain data pooled from different acquisition sites/datasets to improve statistical power. However, medical images from different sites cannot be easily shared to build large datasets for model training due to privacy protection reasons. As a promising solution, federated learning, which enables collaborative training of machine learning models based on data from different sites without cross-site data sharing, has attracted considerable attention recently. In this paper, we conduct a comprehensive survey of the recent development of federated learning methods in medical image analysis. We first introduce the background and motivation of federated learning for dealing with privacy protection and collaborative learning issues in medical imaging. We then present a comprehensive review of recent advances in federated learning methods for medical image analysis. Specifically, existing methods are categorized based on three critical aspects of a federated learning system, including client end, server end, and communication techniques. In each category, we summarize the existing federated learning methods according to specific research problems in medical image analysis and also provide insights into the motivations of different approaches. In addition, we provide a review of existing benchmark medical imaging datasets and software platforms for current federated learning research. We also conduct an experimental study to empirically evaluate typical federated learning methods for medical image analysis. This survey can help to better understand the current research status, challenges and potential research opportunities in this promising research field.
GenImage: A Million-Scale Benchmark for Detecting AI-Generated Image
Jun 14, 2023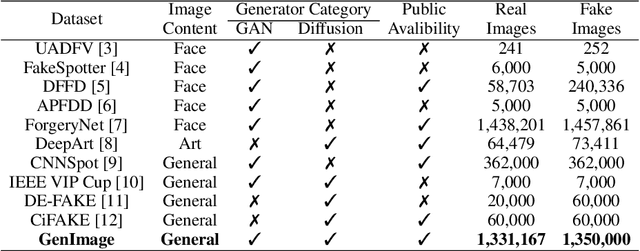

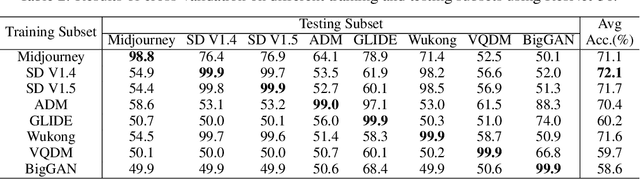
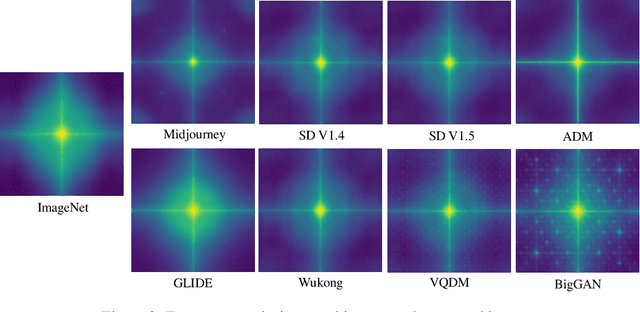
The extraordinary ability of generative models to generate photographic images has intensified concerns about the spread of disinformation, thereby leading to the demand for detectors capable of distinguishing between AI-generated fake images and real images. However, the lack of large datasets containing images from the most advanced image generators poses an obstacle to the development of such detectors. In this paper, we introduce the GenImage dataset, which has the following advantages: 1) Plenty of Images, including over one million pairs of AI-generated fake images and collected real images. 2) Rich Image Content, encompassing a broad range of image classes. 3) State-of-the-art Generators, synthesizing images with advanced diffusion models and GANs. The aforementioned advantages allow the detectors trained on GenImage to undergo a thorough evaluation and demonstrate strong applicability to diverse images. We conduct a comprehensive analysis of the dataset and propose two tasks for evaluating the detection method in resembling real-world scenarios. The cross-generator image classification task measures the performance of a detector trained on one generator when tested on the others. The degraded image classification task assesses the capability of the detectors in handling degraded images such as low-resolution, blurred, and compressed images. With the GenImage dataset, researchers can effectively expedite the development and evaluation of superior AI-generated image detectors in comparison to prevailing methodologies.
Recognize Anything: A Strong Image Tagging Model
Jun 09, 2023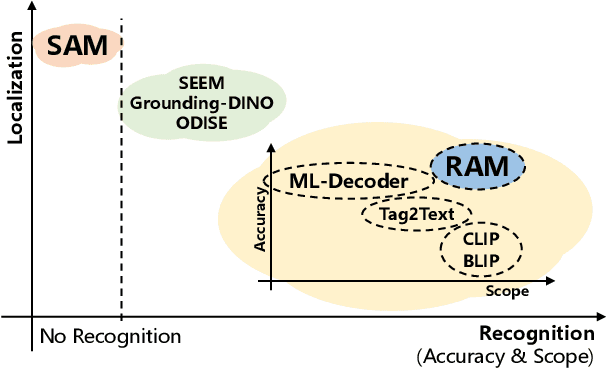
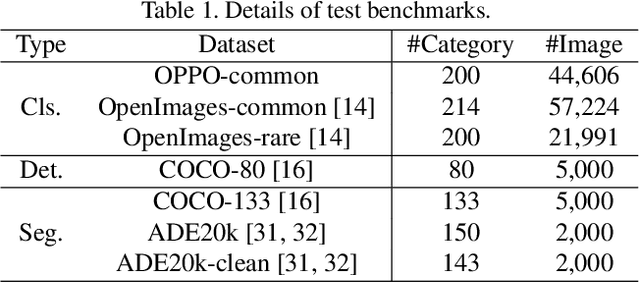

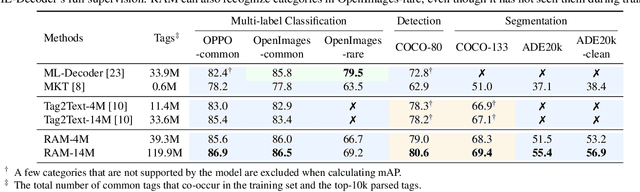
We present the Recognize Anything Model (RAM): a strong foundation model for image tagging. RAM makes a substantial step for large models in computer vision, demonstrating the zero-shot ability to recognize any common category with high accuracy. RAM introduces a new paradigm for image tagging, leveraging large-scale image-text pairs for training instead of manual annotations. The development of RAM comprises four key steps. Firstly, annotation-free image tags are obtained at scale through automatic text semantic parsing. Subsequently, a preliminary model is trained for automatic annotation by unifying the caption and tagging tasks, supervised by the original texts and parsed tags, respectively. Thirdly, a data engine is employed to generate additional annotations and clean incorrect ones. Lastly, the model is retrained with the processed data and fine-tuned using a smaller but higher-quality dataset. We evaluate the tagging capabilities of RAM on numerous benchmarks and observe impressive zero-shot performance, significantly outperforming CLIP and BLIP. Remarkably, RAM even surpasses the fully supervised manners and exhibits competitive performance with the Google tagging API. We are releasing the RAM at \url{https://recognize-anything.github.io/} to foster the advancements of large models in computer vision.