 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CEFHRI: A Communication Efficient Federated Learning Framework for Recognizing Industrial Human-Robot Interaction
Aug 29, 2023
Human-robot interaction (HRI) is a rapidly growing field that encompasses social and industrial applications. Machine learning plays a vital role in industrial HRI by enhancing the adaptability and autonomy of robots in complex environments. However, data privacy is a crucial concern in the interaction between humans and robots, as companies need to protect sensitive data while machine learning algorithms require access to large datasets. Federated Learning (FL) offers a solution by enabling the distributed training of models without sharing raw data. Despite extensive research on Federated learning (FL) for tasks such as natural language processing (NLP) and image classification, the question of how to use FL for HRI remains an open research problem. The traditional FL approach involves transmitting large neural network parameter matrices between the server and clients, which can lead to high communication costs and often becomes a bottleneck in FL. This paper proposes a communication-efficient FL framework for human-robot interaction (CEFHRI) to address the challenges of data heterogeneity and communication costs. The framework leverages pre-trained models and introduces a trainable spatiotemporal adapter for video understanding tasks in HRI. Experimental results on three human-robot interaction benchmark datasets: HRI30, InHARD, and COIN demonstrate the superiority of CEFHRI over full fine-tuning in terms of communication costs. The proposed methodology provides a secure and efficient approach to HRI federated learning, particularly in industrial environments with data privacy concerns and limited communication bandwidth. Our code is available at https://github.com/umarkhalidAI/CEFHRI-Efficient-Federated-Learning.
Open Gaze: Open Source eye tracker for smartphone devices using Deep Learning
Aug 29, 2023Eye tracking has been a pivotal tool in diverse fields such as vision research, language analysis, and usability assessment. The majority of prior investigations, however, have concentrated on expansive desktop displays employing specialized, costly eye tracking hardware that lacks scalability. Remarkably little insight exists into ocular movement patterns on smartphones, despite their widespread adoption and significant usage. In this manuscript, we present an open-source implementation of a smartphone-based gaze tracker that emulates the methodology proposed by a GooglePaper (whose source code remains proprietary). Our focus is on attaining accuracy comparable to that attained through the GooglePaper's methodology, without the necessity for supplementary hardware. Through the integration of machine learning techniques, we unveil an accurate eye tracking solution that is native to smartphones. Our approach demonstrates precision akin to the state-of-the-art mobile eye trackers, which are characterized by a cost that is two orders of magnitude higher. Leveraging the vast MIT GazeCapture dataset, which is available through registration on the dataset's website, we successfully replicate crucial findings from previous studies concerning ocular motion behavior in oculomotor tasks and saliency analyses during natural image observation. Furthermore, we emphasize the applicability of smartphone-based gaze tracking in discerning reading comprehension challenges. Our findings exhibit the inherent potential to amplify eye movement research by significant proportions, accommodating participation from thousands of subjects with explicit consent. This scalability not only fosters advancements in vision research, but also extends its benefits to domains such as accessibility enhancement and healthcare applications.
DomainStudio: Fine-Tuning Diffusion Models for Domain-Driven Image Generation using Limited Data
Jun 25, 2023Denoising diffusion probabilistic models (DDPMs) have been proven capable of synthesizing high-quality images with remarkable diversity when trained on large amounts of data. Typical diffusion models and modern large-scale conditional generative models like text-to-image generative models are vulnerable to overfitting when fine-tuned on extremely limited data. Existing works have explored subject-driven generation using a reference set containing a few images. However, few prior works explore DDPM-based domain-driven generation, which aims to learn the common features of target domains while maintaining diversity. This paper proposes a novel DomainStudio approach to adapt DDPMs pre-trained on large-scale source datasets to target domains using limited data. It is designed to keep the diversity of subjects provided by source domains and get high-quality and diverse adapted samples in target domains. We propose to keep the relative distances between adapted samples to achieve considerable generation diversity. In addition, we further enhance the learning of high-frequency details for better generation quality. Our approach is compatible with both unconditional and conditional diffusion models. This work makes the first attempt to realize unconditional few-shot image generation with diffusion models, achieving better quality and greater diversity than current state-of-the-art GAN-based approaches. Moreover, this work also significantly relieves overfitting for conditional generation and realizes high-quality domain-driven generation, further expanding the applicable scenarios of modern large-scale text-to-image models.
Articulated 3D Head Avatar Generation using Text-to-Image Diffusion Models
Jul 10, 2023
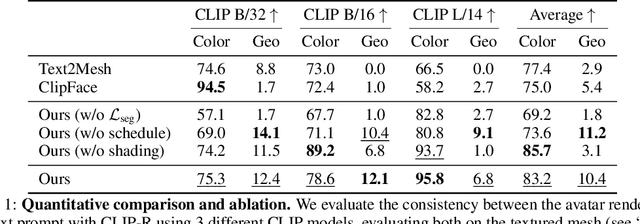

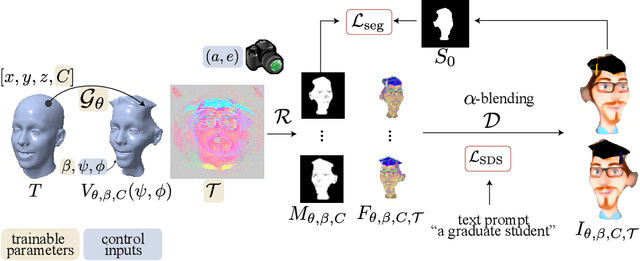
The ability to generate diverse 3D articulated head avatars is vital to a plethora of applications, including augmented reality, cinematography, and education. Recent work on text-guided 3D object generation has shown great promise in addressing these needs. These methods directly leverage pre-trained 2D text-to-image diffusion models to generate 3D-multi-view-consistent radiance fields of generic objects. However, due to the lack of geometry and texture priors, these methods have limited control over the generated 3D objects, making it difficult to operate inside a specific domain, e.g., human heads. In this work, we develop a new approach to text-guided 3D head avatar generation to address this limitation. Our framework directly operates on the geometry and texture of an articulable 3D morphable model (3DMM) of a head, and introduces novel optimization procedures to update the geometry and texture while keeping the 2D and 3D facial features aligned. The result is a 3D head avatar that is consistent with the text description and can be readily articulated using the deformation model of the 3DMM. We show that our diffusion-based articulated head avatars outperform state-of-the-art approaches for this task. The latter are typically based on CLIP, which is known to provide limited diversity of generation and accuracy for 3D object generation.
Mirror Diffusion Models
Aug 18, 2023Diffusion models have successfully been applied to generative tasks in various continuous domains. However, applying diffusion to discrete categorical data remains a non-trivial task. Moreover, generation in continuous domains often requires clipping in practice, which motivates the need for a theoretical framework for adapting diffusion to constrained domains. Inspired by the mirror Langevin algorithm for the constrained sampling problem, in this theoretical report we propose Mirror Diffusion Models (MDMs). We demonstrate MDMs in the context of simplex diffusion and propose natural extensions to popular domains such as image and text generation.
AGIQA-3K: An Open Database for AI-Generated Image Quality Assessment
Jun 12, 2023
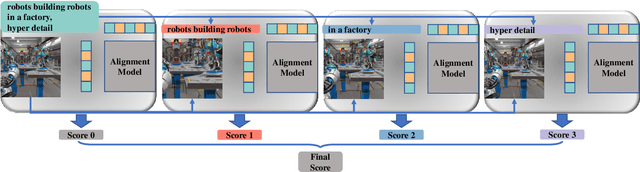
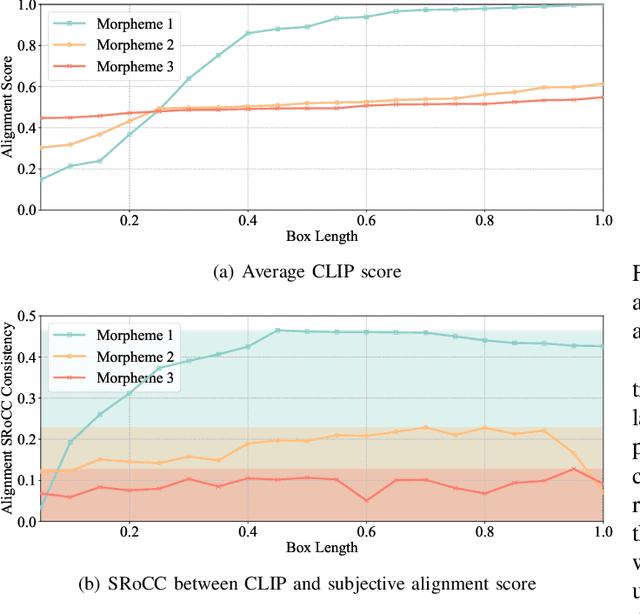

With the rapid advancements of the text-to-image generative model, AI-generated images (AGIs) have been widely applied to entertainment, education, social media, etc. However, considering the large quality variance among different AGIs, there is an urgent need for quality models that are consistent with human subjective ratings. To address this issue, we extensively consider various popular AGI models, generated AGI through different prompts and model parameters, and collected subjective scores at the perceptual quality and text-to-image alignment, thus building the most comprehensive AGI subjective quality database AGIQA-3K so far. Furthermore, we conduct a benchmark experiment on this database to evaluate the consistency between the current Image Quality Assessment (IQA) model and human perception, while proposing StairReward that significantly improves the assessment performance of subjective text-to-image alignment. We believe that the fine-grained subjective scores in AGIQA-3K will inspire subsequent AGI quality models to fit human subjective perception mechanisms at both perception and alignment levels and to optimize the generation result of future AGI models. The database is released on https://github.com/lcysyzxdxc/AGIQA-3k-Database.
DVPT: Dynamic Visual Prompt Tuning of Large Pre-trained Models for Medical Image Analysis
Jul 19, 2023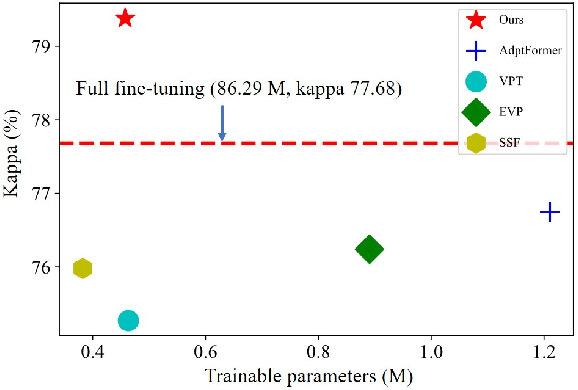
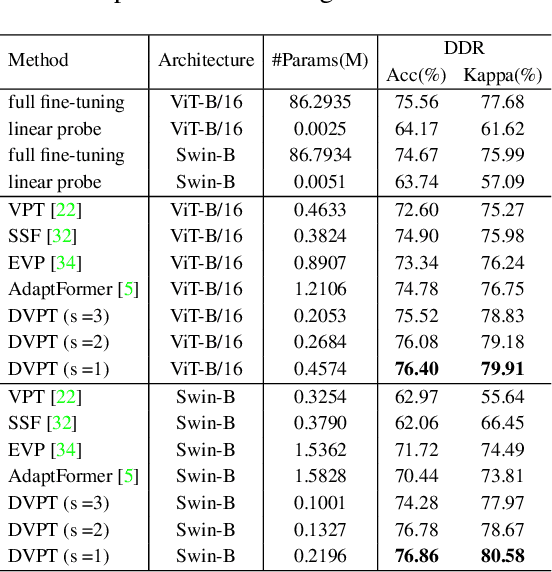
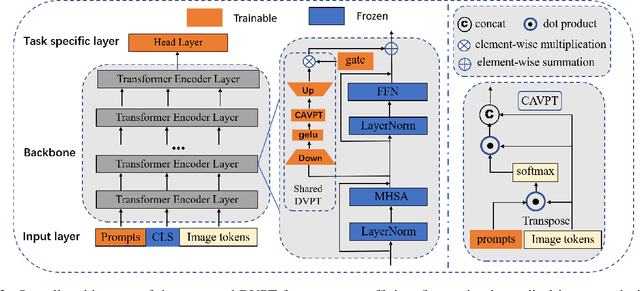
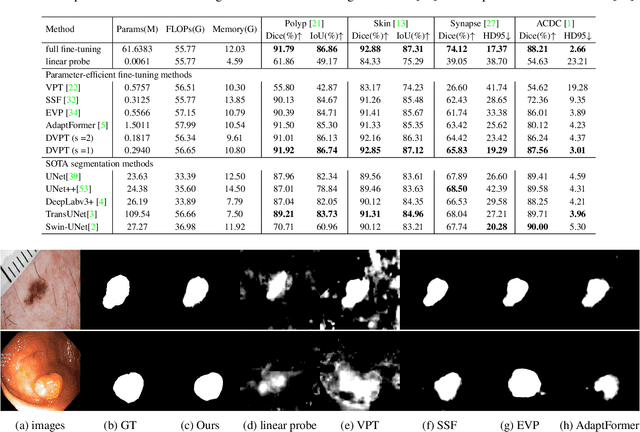
Limited labeled data makes it hard to train models from scratch in medical domain, and an important paradigm is pre-training and then fine-tuning. Large pre-trained models contain rich representations, which can be adapted to downstream medical tasks. However, existing methods either tune all the parameters or the task-specific layers of the pre-trained models, ignoring the input variations of medical images, and thus they are not efficient or effective. In this work, we aim to study parameter-efficient fine-tuning (PEFT) for medical image analysis, and propose a dynamic visual prompt tuning method, named DVPT. It can extract knowledge beneficial to downstream tasks from large models with a few trainable parameters. Firstly, the frozen features are transformed by an lightweight bottleneck layer to learn the domain-specific distribution of downstream medical tasks, and then a few learnable visual prompts are used as dynamic queries and then conduct cross-attention with the transformed features, attempting to acquire sample-specific knowledge that are suitable for each sample. Finally, the features are projected to original feature dimension and aggregated with the frozen features. This DVPT module can be shared between different Transformer layers, further reducing the trainable parameters. To validate DVPT, we conduct extensive experiments with different pre-trained models on medical classification and segmentation tasks. We find such PEFT method can not only efficiently adapt the pre-trained models to the medical domain, but also brings data efficiency with partial labeled data. For example, with 0.5\% extra trainable parameters, our method not only outperforms state-of-the-art PEFT methods, even surpasses the full fine-tuning by more than 2.20\% Kappa score on medical classification task. It can saves up to 60\% labeled data and 99\% storage cost of ViT-B/16.
Collaborative Blind Image Deblurring
May 25, 2023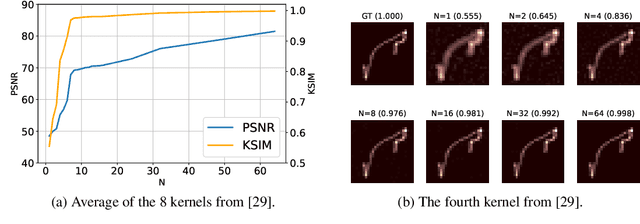
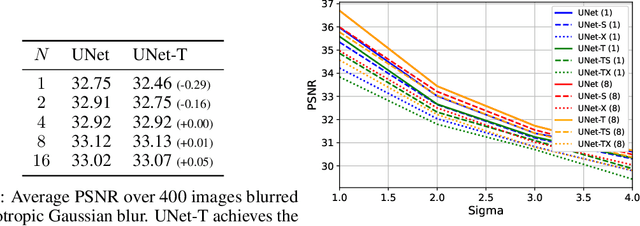

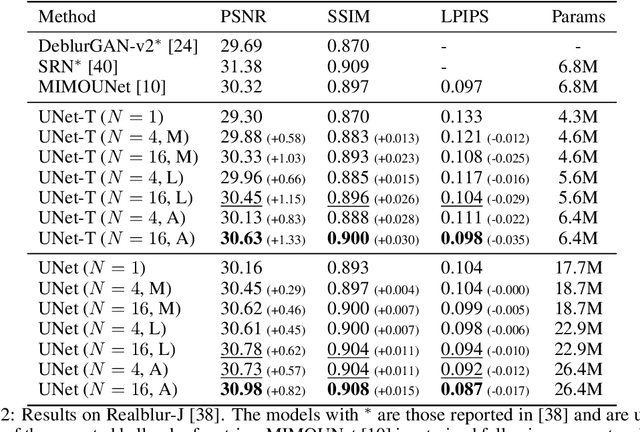
Blurry images usually exhibit similar blur at various locations across the image domain, a property barely captured in nowadays blind deblurring neural networks. We show that when extracting patches of similar underlying blur is possible, jointly processing the stack of patches yields superior accuracy than handling them separately. Our collaborative scheme is implemented in a neural architecture with a pooling layer on the stack dimension. We present three practical patch extraction strategies for image sharpening, camera shake removal and optical aberration correction, and validate the proposed approach on both synthetic and real-world benchmarks. For each blur instance, the proposed collaborative strategy yields significant quantitative and qualitative improvements.
End-to-end Remote Sensing Change Detection of Unregistered Bi-temporal Images for Natural Disasters
Aug 16, 2023
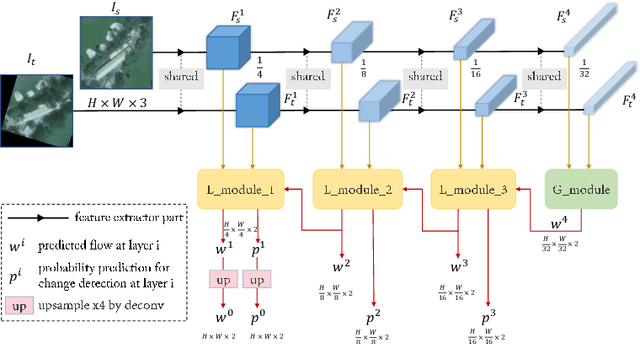
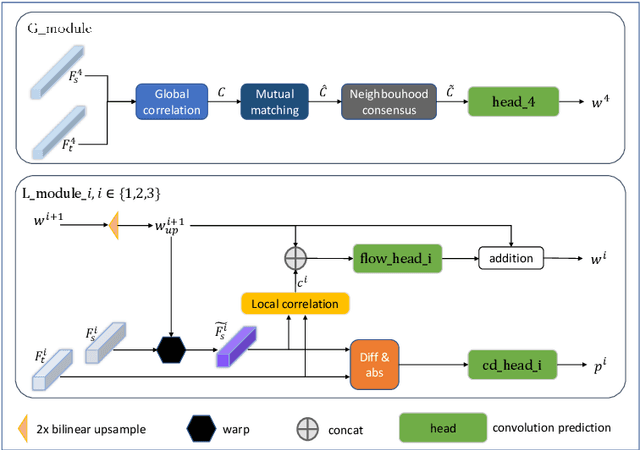

Change detection based on remote sensing images has been a prominent area of interest in the field of remote sensing. Deep networks have demonstrated significant success in detecting changes in bi-temporal remote sensing images and have found applications in various fields. Given the degradation of natural environments and the frequent occurrence of natural disasters, accurately and swiftly identifying damaged buildings in disaster-stricken areas through remote sensing images holds immense significance. This paper aims to investigate change detection specifically for natural disasters. Considering that existing public datasets used in change detection research are registered, which does not align with the practical scenario where bi-temporal images are not matched, this paper introduces an unregistered end-to-end change detection synthetic dataset called xBD-E2ECD. Furthermore, we propose an end-to-end change detection network named E2ECDNet, which takes an unregistered bi-temporal image pair as input and simultaneously generates the flow field prediction result and the change detection prediction result. It is worth noting that our E2ECDNet also supports change detection for registered image pairs, as registration can be seen as a special case of non-registration. Additionally, this paper redefines the criteria for correctly predicting a positive case and introduces neighborhood-based change detection evaluation metrics. The experimental results have demonstrated significant improvements.
DiT: Efficient Vision Transformers with Dynamic Token Routing
Aug 11, 2023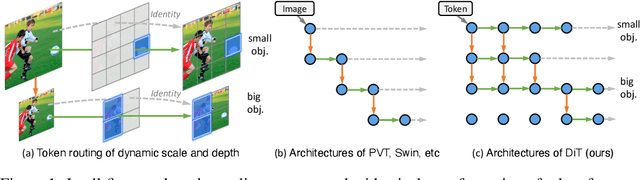
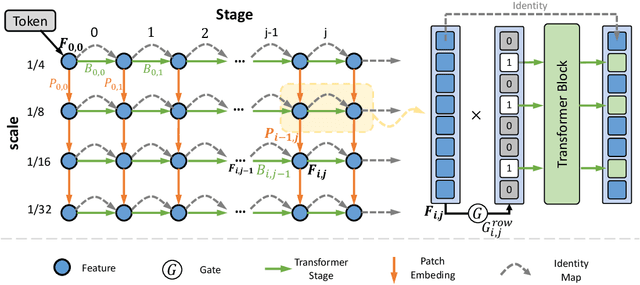
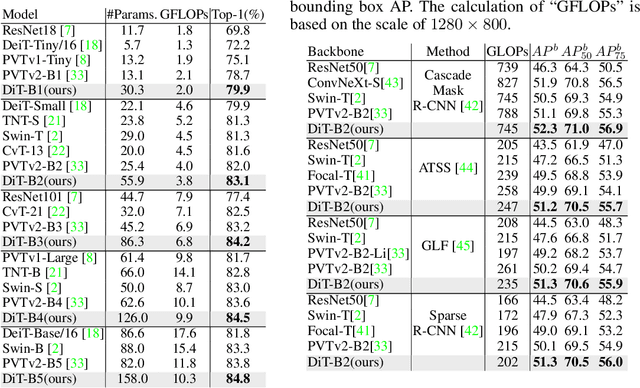
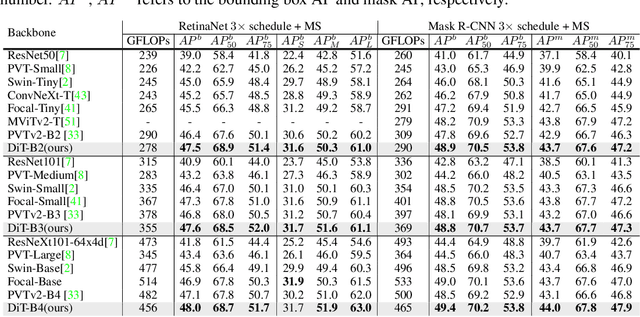
Recently, the tokens of images share the same static data flow in many dense networks. However, challenges arise from the variance among the objects in images, such as large variations in the spatial scale and difficulties of recognition for visual entities. In this paper, we propose a data-dependent token routing strategy to elaborate the routing paths of image tokens for Dynamic Vision Transformer, dubbed DiT. The proposed framework generates a data-dependent path per token, adapting to the object scales and visual discrimination of tokens. In feed-forward, the differentiable routing gates are designed to select the scaling paths and feature transformation paths for image tokens, leading to multi-path feature propagation. In this way, the impact of object scales and visual discrimination of image representation can be carefully tuned. Moreover, the computational cost can be further reduced by giving budget constraints to the routing gate and early-stopping of feature extraction. In experiments, our DiT achieves superior performance and favorable complexity/accuracy trade-offs than many SoTA methods on ImageNet classification, object detection, instance segmentation, and semantic segmentation. Particularly, the DiT-B5 obtains 84.8\% top-1 Acc on ImageNet with 10.3 GFLOPs, which is 1.0\% higher than that of the SoTA method with similar computational complexity. These extensive results demonstrate that DiT can serve as versatile backbones for various vision tasks.