 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Revisiting Image Classifier Training for Improved Certified Robust Defense against Adversarial Patches
Jun 22, 2023
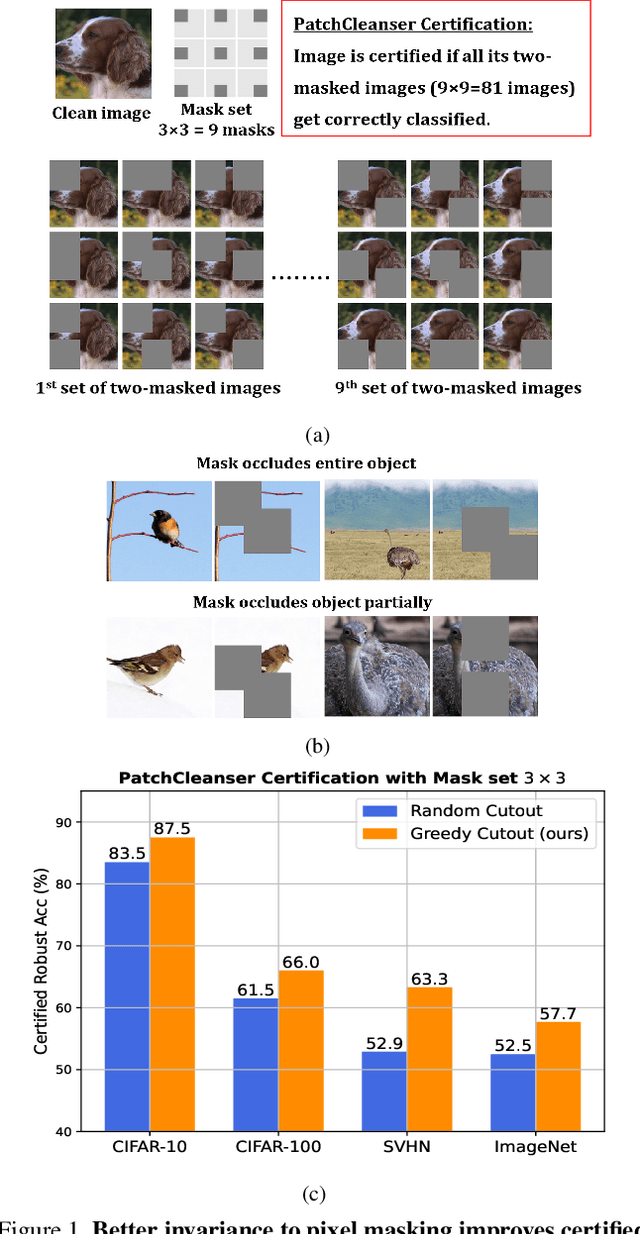

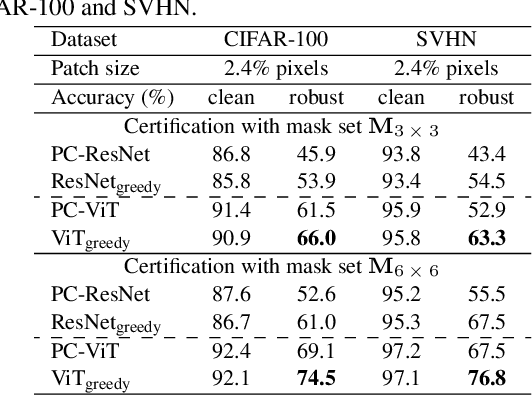
Certifiably robust defenses against adversarial patches for image classifiers ensure correct prediction against any changes to a constrained neighborhood of pixels. PatchCleanser arXiv:2108.09135 [cs.CV], the state-of-the-art certified defense, uses a double-masking strategy for robust classification. The success of this strategy relies heavily on the model's invariance to image pixel masking. In this paper, we take a closer look at model training schemes to improve this invariance. Instead of using Random Cutout arXiv:1708.04552v2 [cs.CV] augmentations like PatchCleanser, we introduce the notion of worst-case masking, i.e., selecting masked images which maximize classification loss. However, finding worst-case masks requires an exhaustive search, which might be prohibitively expensive to do on-the-fly during training. To solve this problem, we propose a two-round greedy masking strategy (Greedy Cutout) which finds an approximate worst-case mask location with much less compute. We show that the models trained with our Greedy Cutout improves certified robust accuracy over Random Cutout in PatchCleanser across a range of datasets and architectures. Certified robust accuracy on ImageNet with a ViT-B16-224 model increases from 58.1\% to 62.3\% against a 3\% square patch applied anywhere on the image.
Fixating on Attention: Integrating Human Eye Tracking into Vision Transformers
Aug 26, 2023

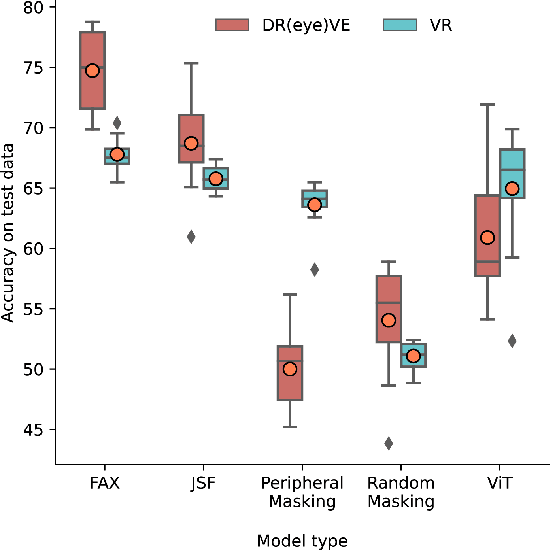
Modern transformer-based models designed for computer vision have outperformed humans across a spectrum of visual tasks. However, critical tasks, such as medical image interpretation or autonomous driving, still require reliance on human judgments. This work demonstrates how human visual input, specifically fixations collected from an eye-tracking device, can be integrated into transformer models to improve accuracy across multiple driving situations and datasets. First, we establish the significance of fixation regions in left-right driving decisions, as observed in both human subjects and a Vision Transformer (ViT). By comparing the similarity between human fixation maps and ViT attention weights, we reveal the dynamics of overlap across individual heads and layers. This overlap is exploited for model pruning without compromising accuracy. Thereafter, we incorporate information from the driving scene with fixation data, employing a "joint space-fixation" (JSF) attention setup. Lastly, we propose a "fixation-attention intersection" (FAX) loss to train the ViT model to attend to the same regions that humans fixated on. We find that the ViT performance is improved in accuracy and number of training epochs when using JSF and FAX. These results hold significant implications for human-guided artificial intelligence.
Devil is in Channels: Contrastive Single Domain Generalization for Medical Image Segmentation
Jun 24, 2023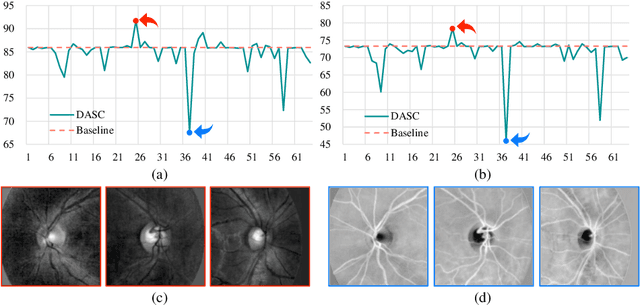
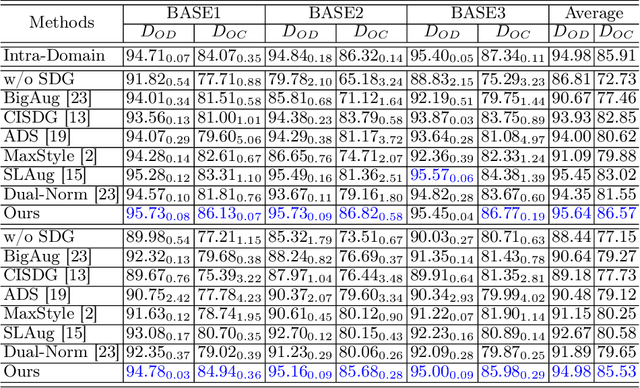
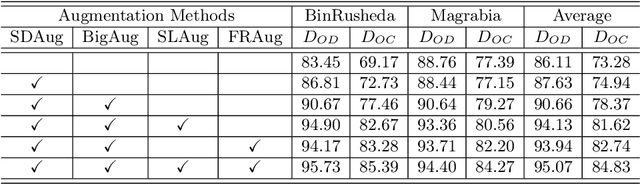
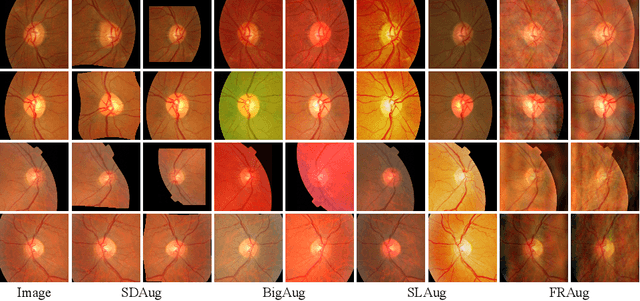
Deep learning-based medical image segmentation models suffer from performance degradation when deployed to a new healthcare center. To address this issue, unsupervised domain adaptation and multi-source domain generalization methods have been proposed, which, however, are less favorable for clinical practice due to the cost of acquiring target-domain data and the privacy concerns associated with redistributing the data from multiple source domains. In this paper, we propose a \textbf{C}hannel-level \textbf{C}ontrastive \textbf{S}ingle \textbf{D}omain \textbf{G}eneralization (\textbf{C$^2$SDG}) model for medical image segmentation. In C$^2$SDG, the shallower features of each image and its style-augmented counterpart are extracted and used for contrastive training, resulting in the disentangled style representations and structure representations. The segmentation is performed based solely on the structure representations. Our method is novel in the contrastive perspective that enables channel-wise feature disentanglement using a single source domain. We evaluated C$^2$SDG against six SDG methods on a multi-domain joint optic cup and optic disc segmentation benchmark. Our results suggest the effectiveness of each module in C$^2$SDG and also indicate that C$^2$SDG outperforms the baseline and all competing methods with a large margin. The code will be available at \url{https://github.com/ShishuaiHu/CCSDG}.
Black-box Unsupervised Domain Adaptation with Bi-directional Atkinson-Shiffrin Memory
Aug 25, 2023Black-box unsupervised domain adaptation (UDA) learns with source predictions of target data without accessing either source data or source models during training, and it has clear superiority in data privacy and flexibility in target network selection. However, the source predictions of target data are often noisy and training with them is prone to learning collapses. We propose BiMem, a bi-directional memorization mechanism that learns to remember useful and representative information to correct noisy pseudo labels on the fly, leading to robust black-box UDA that can generalize across different visual recognition tasks. BiMem constructs three types of memory, including sensory memory, short-term memory, and long-term memory, which interact in a bi-directional manner for comprehensive and robust memorization of learnt features. It includes a forward memorization flow that identifies and stores useful features and a backward calibration flow that rectifies features' pseudo labels progressively. Extensive experiments show that BiMem achieves superior domain adaptation performance consistently across various visual recognition tasks such as image classification, semantic segmentation and object detection.
Textureless Deformable Surface Reconstruction with Invisible Markers
Aug 25, 2023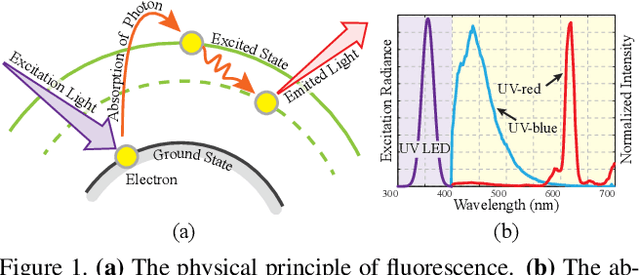

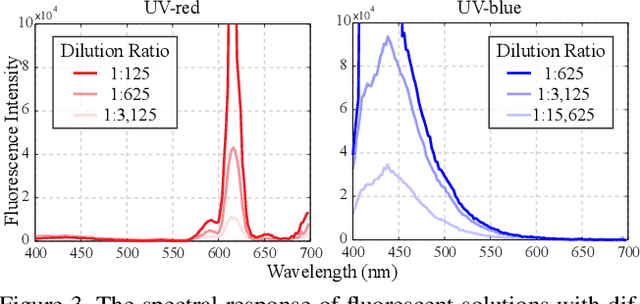
Reconstructing and tracking deformable surface with little or no texture has posed long-standing challenges. Fundamentally, the challenges stem from textureless surfaces lacking features for establishing cross-image correspondences. In this work, we present a novel type of markers to proactively enrich the object's surface features, and thereby ease the 3D surface reconstruction and correspondence tracking. Our markers are made of fluorescent dyes, visible only under the ultraviolet (UV) light and invisible under regular lighting condition. Leveraging the markers, we design a multi-camera system that captures surface deformation under the UV light and the visible light in a time multiplexing fashion. Under the UV light, markers on the object emerge to enrich its surface texture, allowing high-quality 3D shape reconstruction and tracking. Under the visible light, markers become invisible, allowing us to capture the object's original untouched appearance. We perform experiments on various challenging scenes, including hand gestures, facial expressions, waving cloth, and hand-object interaction. In all these cases, we demonstrate that our system is able to produce robust, high-quality 3D reconstruction and tracking.
E-CLIP: Towards Label-efficient Event-based Open-world Understanding by CLIP
Aug 06, 2023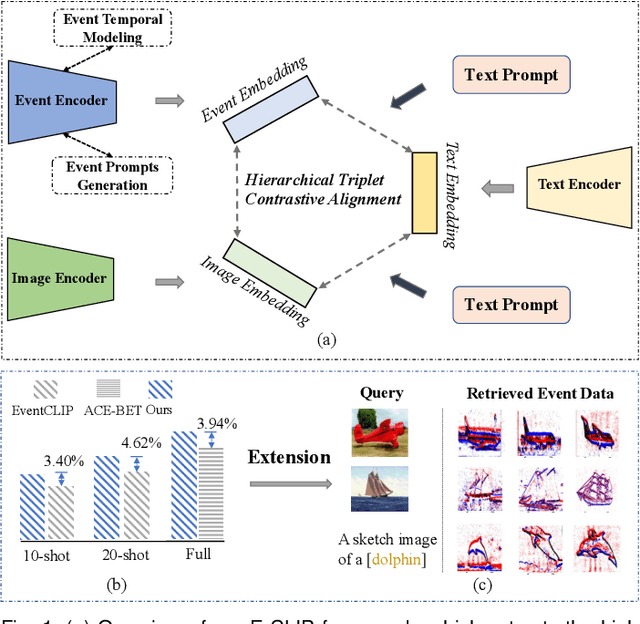
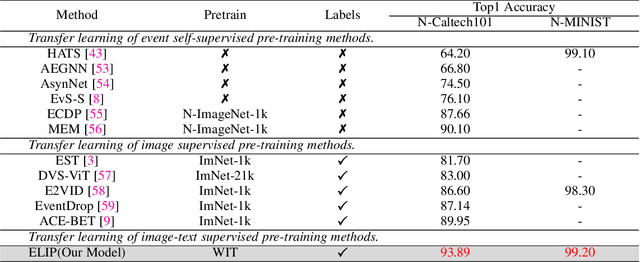
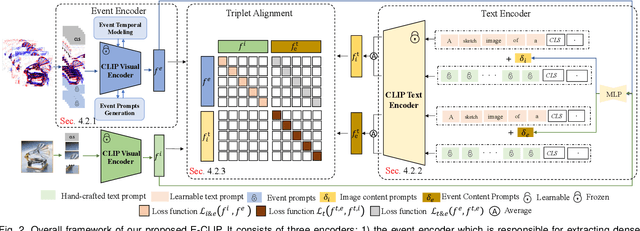
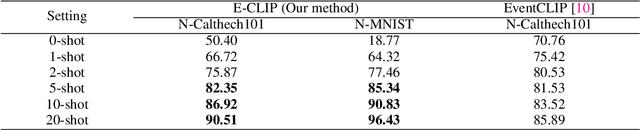
Contrasting Language-image pertaining (CLIP) has recently shown promising open-world and few-shot performance on 2D image-based recognition tasks. However, the transferred capability of CLIP to the novel event camera data still remains under-explored. In particular, due to the modality gap with the image-text data and the lack of large-scale datasets, achieving this goal is non-trivial and thus requires significant research innovation. In this paper, we propose E-CLIP, a novel and effective framework that unleashes the potential of CLIP for event-based recognition to compensate for the lack of large-scale event-based datasets. Our work addresses two crucial challenges: 1) how to generalize CLIP's visual encoder to event data while fully leveraging events' unique properties, e.g., sparsity and high temporal resolution; 2) how to effectively align the multi-modal embeddings, i.e., image, text, and events. To this end, we first introduce a novel event encoder that subtly models the temporal information from events and meanwhile generates event prompts to promote the modality bridging. We then design a text encoder that generates content prompts and utilizes hybrid text prompts to enhance the E-CLIP's generalization ability across diverse datasets. With the proposed event encoder, text encoder, and original image encoder, a novel Hierarchical Triple Contrastive Alignment (HTCA) module is introduced to jointly optimize the correlation and enable efficient knowledge transfer among the three modalities. We conduct extensive experiments on two recognition benchmarks, and the results demonstrate that our E-CLIP outperforms existing methods by a large margin of +3.94% and +4.62% on the N-Caltech dataset, respectively, in both fine-tuning and few-shot settings. Moreover, our E-CLIP can be flexibly extended to the event retrieval task using both text or image queries, showing plausible performance.
From Global to Local: Multi-scale Out-of-distribution Detection
Aug 20, 2023Out-of-distribution (OOD) detection aims to detect "unknown" data whose labels have not been seen during the in-distribution (ID) training process. Recent progress in representation learning gives rise to distance-based OOD detection that recognizes inputs as ID/OOD according to their relative distances to the training data of ID classes. Previous approaches calculate pairwise distances relying only on global image representations, which can be sub-optimal as the inevitable background clutter and intra-class variation may drive image-level representations from the same ID class far apart in a given representation space. In this work, we overcome this challenge by proposing Multi-scale OOD DEtection (MODE), a first framework leveraging both global visual information and local region details of images to maximally benefit OOD detection. Specifically, we first find that existing models pretrained by off-the-shelf cross-entropy or contrastive losses are incompetent to capture valuable local representations for MODE, due to the scale-discrepancy between the ID training and OOD detection processes. To mitigate this issue and encourage locally discriminative representations in ID training, we propose Attention-based Local PropAgation (ALPA), a trainable objective that exploits a cross-attention mechanism to align and highlight the local regions of the target objects for pairwise examples. During test-time OOD detection, a Cross-Scale Decision (CSD) function is further devised on the most discriminative multi-scale representations to distinguish ID/OOD data more faithfully. We demonstrate the effectiveness and flexibility of MODE on several benchmarks -- on average, MODE outperforms the previous state-of-the-art by up to 19.24% in FPR, 2.77% in AUROC. Code is available at https://github.com/JimZAI/MODE-OOD.
Learning Disentangled Prompts for Compositional Image Synthesis
Jun 01, 2023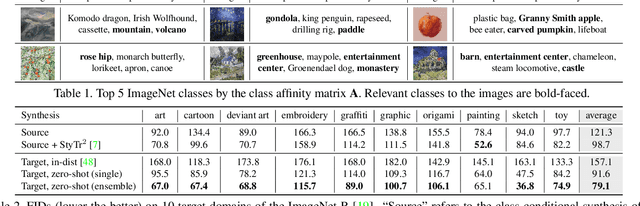
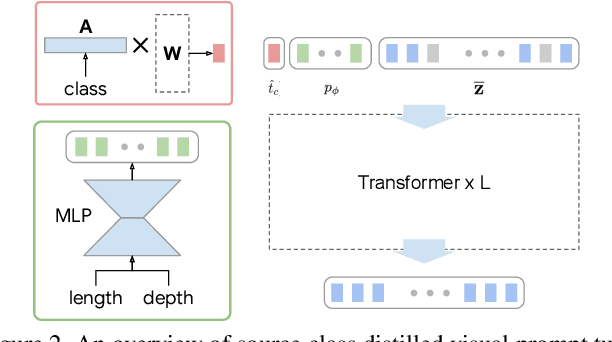


We study domain-adaptive image synthesis, the problem of teaching pretrained image generative models a new style or concept from as few as one image to synthesize novel images, to better understand the compositional image synthesis. We present a framework that leverages a pretrained class-conditional generation model and visual prompt tuning. Specifically, we propose a novel source class distilled visual prompt that learns disentangled prompts of semantic (e.g., class) and domain (e.g., style) from a few images. Learned domain prompt is then used to synthesize images of any classes in the style of target domain. We conduct studies on various target domains with the number of images ranging from one to a few to many, and show qualitative results which show the compositional generalization of our method. Moreover, we show that our method can help improve zero-shot domain adaptation classification accuracy.
MatFuse: Controllable Material Generation with Diffusion Models
Aug 22, 2023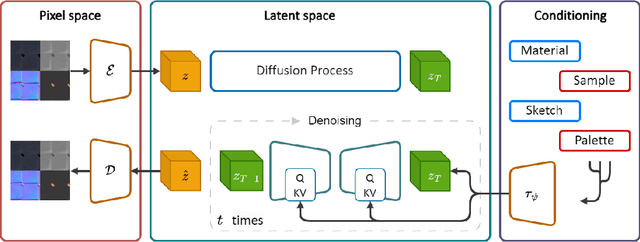
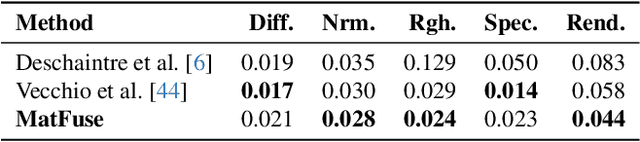
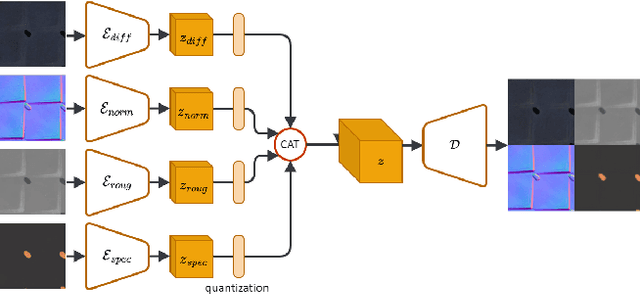
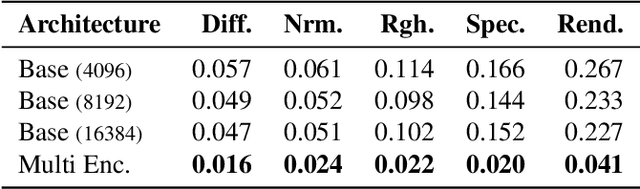
Creating high quality and realistic materials in computer graphics is a challenging and time-consuming task, which requires great expertise. In this paper, we present MatFuse, a novel unified approach that harnesses the generative power of diffusion models (DM) to simplify the creation of SVBRDF maps. Our DM-based pipeline integrates multiple sources of conditioning, such as color palettes, sketches, and pictures, enabling fine-grained control and flexibility in material synthesis. This design allows for the combination of diverse information sources (e.g., sketch + image embedding), enhancing creative possibilities in line with the principle of compositionality. We demonstrate the generative capabilities of the proposed method under various conditioning settings; on the SVBRDF estimation task, we show that our method yields performance comparable to state-of-the-art approaches, both qualitatively and quantitatively.
AdAM: Few-Shot Image Generation via Adaptation-Aware Kernel Modulation
Jul 08, 2023
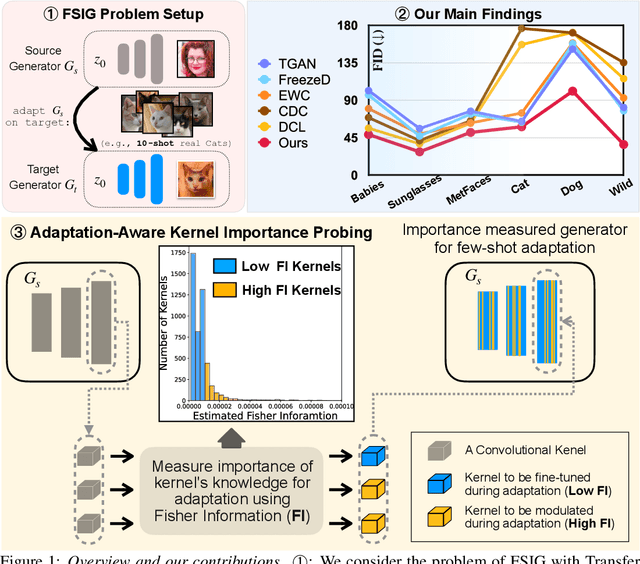
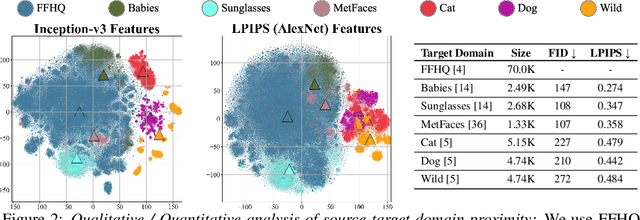
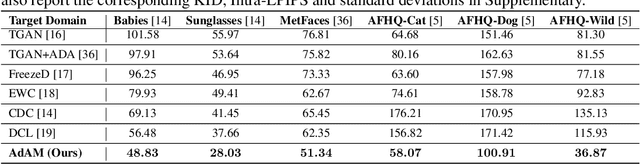
Few-shot image generation (FSIG) aims to learn to generate new and diverse images given few (e.g., 10) training samples. Recent work has addressed FSIG by leveraging a GAN pre-trained on a large-scale source domain and adapting it to the target domain with few target samples. Central to recent FSIG methods are knowledge preservation criteria, which select and preserve a subset of source knowledge to the adapted model. However, a major limitation of existing methods is that their knowledge preserving criteria consider only source domain/task and fail to consider target domain/adaptation in selecting source knowledge, casting doubt on their suitability for setups of different proximity between source and target domain. Our work makes two contributions. Firstly, we revisit recent FSIG works and their experiments. We reveal that under setups which assumption of close proximity between source and target domains is relaxed, many existing state-of-the-art (SOTA) methods which consider only source domain in knowledge preserving perform no better than a baseline method. As our second contribution, we propose Adaptation-Aware kernel Modulation (AdAM) for general FSIG of different source-target domain proximity. Extensive experiments show that AdAM consistently achieves SOTA performance in FSIG, including challenging setups where source and target domains are more apart.