 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RISCLIP: Referring Image Segmentation Framework using CLIP
Jun 14, 2023
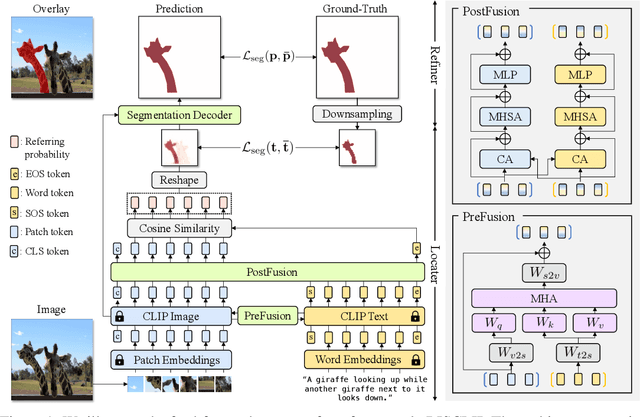
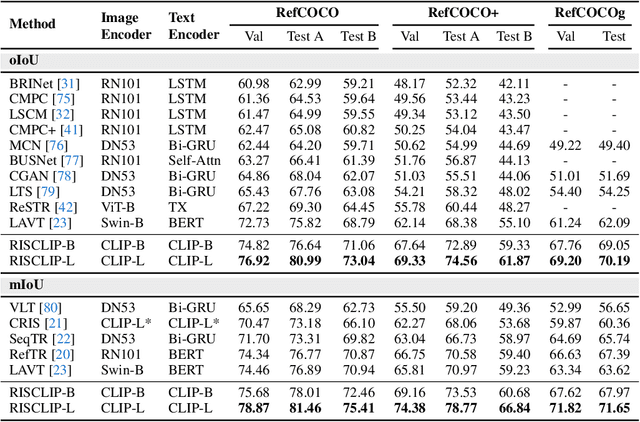
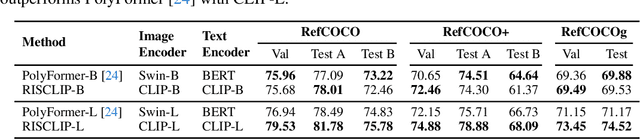

Recent advances in computer vision and natural language processing have naturally led to active research in multi-modal tasks, including Referring Image Segmentation (RIS). Recent approaches have advanced the frontier of RIS by impressive margins, but they require an additional pretraining stage on external visual grounding datasets to achieve the state-of-the-art performances. We attempt to break free from this requirement by effectively adapting Contrastive Language-Image Pretraining (CLIP) to RIS. We propose a novel framework that residually adapts frozen CLIP features to RIS with Fusion Adapters and Backbone Adapters. Freezing CLIP preserves the backbone's rich, general image-text alignment knowledge, whilst Fusion Adapters introduce multi-modal communication and Backbone Adapters inject new knowledge useful in solving RIS. Our method reaches a new state of the art on three major RIS benchmarks. We attain such performance without additional pretraining and thereby absolve the necessity of extra training and data preparation. Source code and model weights will be available upon publication.
UnLoc: A Unified Framework for Video Localization Tasks
Aug 21, 2023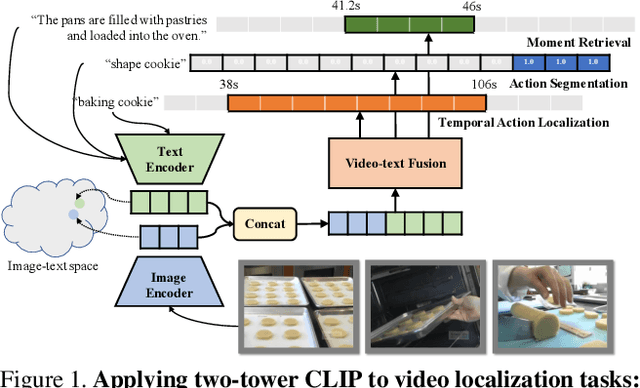

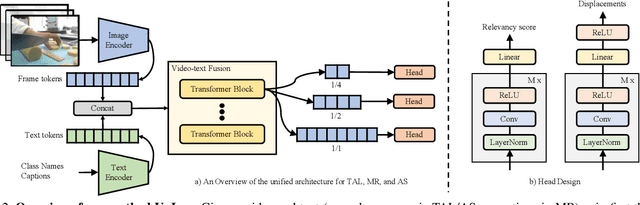
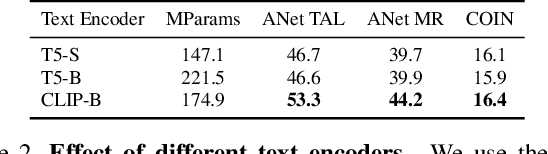
While large-scale image-text pretrained models such as CLIP have been used for multiple video-level tasks on trimmed videos, their use for temporal localization in untrimmed videos is still a relatively unexplored task. We design a new approach for this called UnLoc, which uses pretrained image and text towers, and feeds tokens to a video-text fusion model. The output of the fusion module are then used to construct a feature pyramid in which each level connects to a head to predict a per-frame relevancy score and start/end time displacements. Unlike previous works, our architecture enables Moment Retrieval, Temporal Localization, and Action Segmentation with a single stage model, without the need for action proposals, motion based pretrained features or representation masking. Unlike specialized models, we achieve state of the art results on all three different localization tasks with a unified approach. Code will be available at: \url{https://github.com/google-research/scenic}.
TAI-GAN: Temporally and Anatomically Informed GAN for early-to-late frame conversion in dynamic cardiac PET motion correction
Aug 23, 2023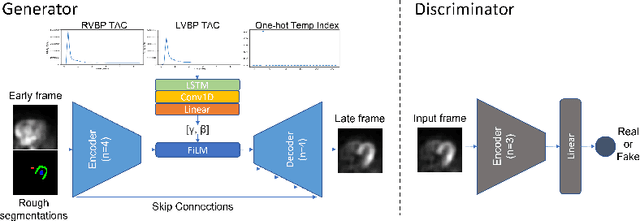
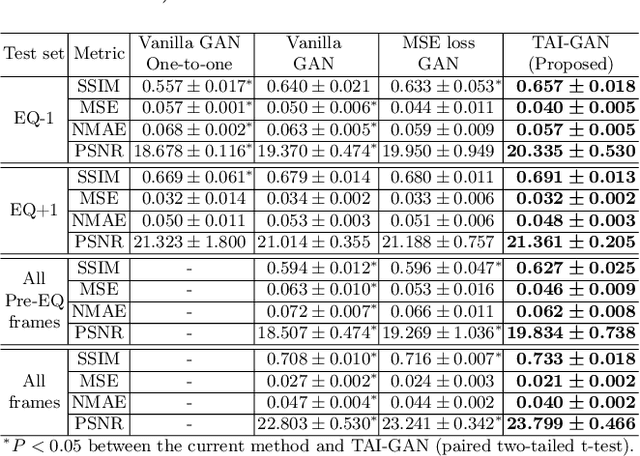
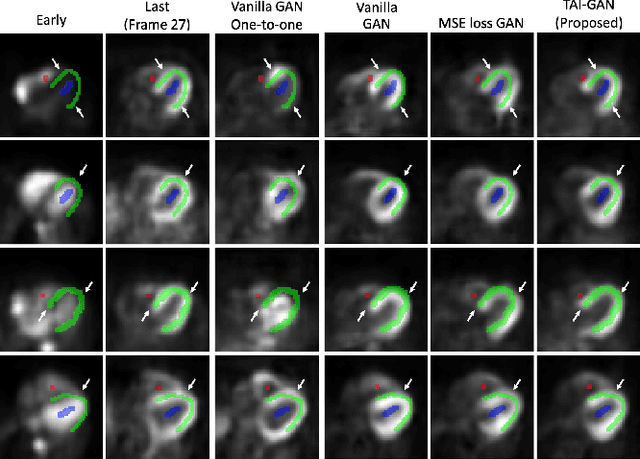
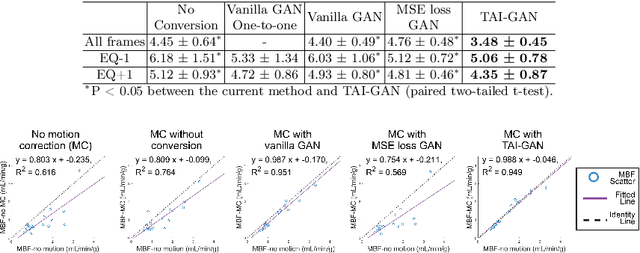
The rapid tracer kinetics of rubidium-82 ($^{82}$Rb) and high variation of cross-frame distribution in dynamic cardiac positron emission tomography (PET) raise significant challenges for inter-frame motion correction, particularly for the early frames where conventional intensity-based image registration techniques are not applicable. Alternatively, a promising approach utilizes generative methods to handle the tracer distribution changes to assist existing registration methods. To improve frame-wise registration and parametric quantification, we propose a Temporally and Anatomically Informed Generative Adversarial Network (TAI-GAN) to transform the early frames into the late reference frame using an all-to-one mapping. Specifically, a feature-wise linear modulation layer encodes channel-wise parameters generated from temporal tracer kinetics information, and rough cardiac segmentations with local shifts serve as the anatomical information. We validated our proposed method on a clinical $^{82}$Rb PET dataset and found that our TAI-GAN can produce converted early frames with high image quality, comparable to the real reference frames. After TAI-GAN conversion, motion estimation accuracy and clinical myocardial blood flow (MBF) quantification were improved compared to using the original frames. Our code is published at https://github.com/gxq1998/TAI-GAN.
Understanding Dark Scenes by Contrasting Multi-Modal Observations
Aug 23, 2023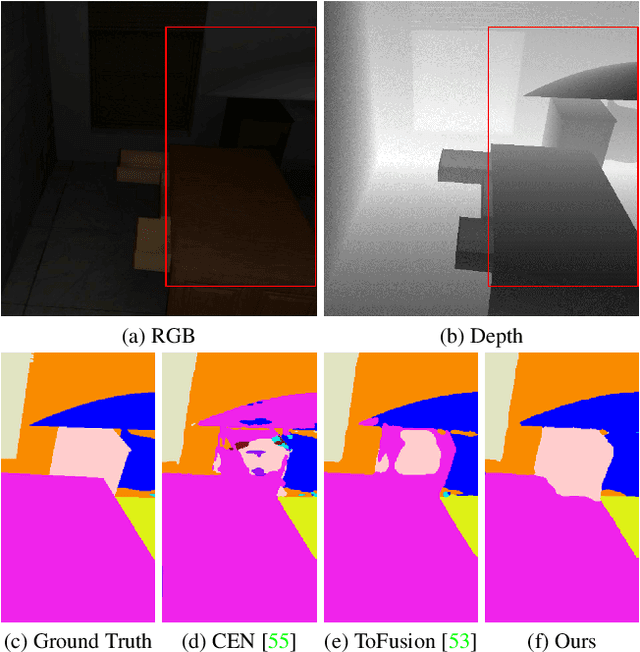

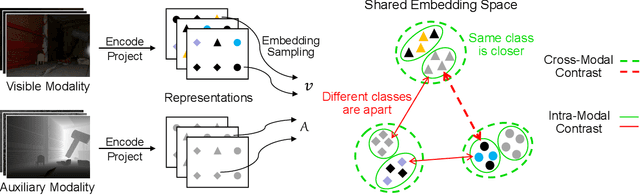
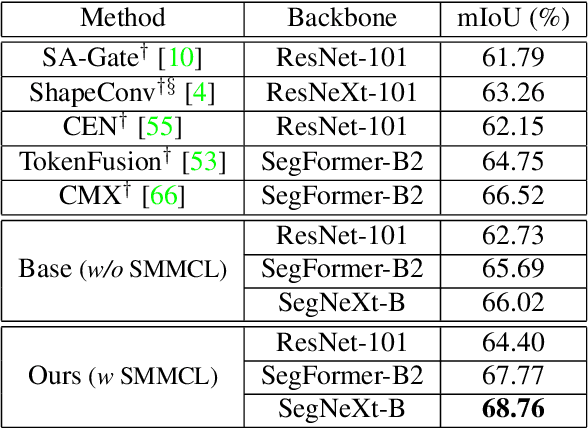
Understanding dark scenes based on multi-modal image data is challenging, as both the visible and auxiliary modalities provide limited semantic information for the task. Previous methods focus on fusing the two modalities but neglect the correlations among semantic classes when minimizing losses to align pixels with labels, resulting in inaccurate class predictions. To address these issues, we introduce a supervised multi-modal contrastive learning approach to increase the semantic discriminability of the learned multi-modal feature spaces by jointly performing cross-modal and intra-modal contrast under the supervision of the class correlations. The cross-modal contrast encourages same-class embeddings from across the two modalities to be closer and pushes different-class ones apart. The intra-modal contrast forces same-class or different-class embeddings within each modality to be together or apart. We validate our approach on a variety of tasks that cover diverse light conditions and image modalities. Experiments show that our approach can effectively enhance dark scene understanding based on multi-modal images with limited semantics by shaping semantic-discriminative feature spaces. Comparisons with previous methods demonstrate our state-of-the-art performance. Code and pretrained models are available at https://github.com/palmdong/SMMCL.
Advances in machine-learning-based sampling motivated by lattice quantum chromodynamics
Sep 03, 2023Sampling from known probability distributions is a ubiquitous task in computational science, underlying calculations in domains from linguistics to biology and physics. Generative machine-learning (ML) models have emerged as a promising tool in this space, building on the success of this approach in applications such as image, text, and audio generation. Often, however, generative tasks in scientific domains have unique structures and features -- such as complex symmetries and the requirement of exactness guarantees -- that present both challenges and opportunities for ML. This Perspective outlines the advances in ML-based sampling motivated by lattice quantum field theory, in particular for the theory of quantum chromodynamics. Enabling calculations of the structure and interactions of matter from our most fundamental understanding of particle physics, lattice quantum chromodynamics is one of the main consumers of open-science supercomputing worldwide. The design of ML algorithms for this application faces profound challenges, including the necessity of scaling custom ML architectures to the largest supercomputers, but also promises immense benefits, and is spurring a wave of development in ML-based sampling more broadly. In lattice field theory, if this approach can realize its early promise it will be a transformative step towards first-principles physics calculations in particle, nuclear and condensed matter physics that are intractable with traditional approaches.
* 11 pages, 5 figures
A Synthetic Electrocardiogram (ECG) Image Generation Toolbox to Facilitate Deep Learning-Based Scanned ECG Digitization
Jul 04, 2023

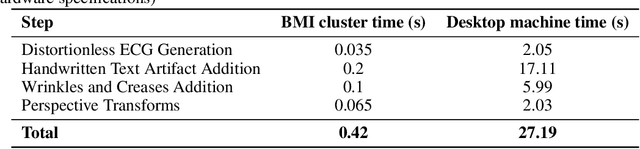
Access to medical data is often limited as it contains protected health information (PHI). There are privacy concerns regarding using records containing personally identifiable information. Recent advancements have been made in applying deep learning-based algorithms for clinical diagnosis and decision-making. However, deep learning models are data-greedy, whereas the availability of medical datasets for training and evaluating these models is relatively limited. Data augmentation with so-called \textit{digital twins} is an emerging technique to address this need. This paper presents a novel approach for generating synthetic electrocardiogram (ECG) images with realistic artifacts from time-series data for use in developing algorithms for digitization of ECG images. Synthetic data is generated in a privacy-preserving manner by generating distortionless ECG images on standard ECG paper background. Next, various distortions, including handwritten text artifacts, wrinkles, creases, and perspective transforms are applied to the ECG images. The artifacts are generated synthetically, without personally identifiable information. As a use case, we generated a large ECG image dataset of 21,801 records from the PhysioNet PTB-XL dataset, with 12 lead ECG time-series data from 18,869 patients. A deep ECG image digitization model was developed and trained on the synthetic dataset, and was employed to convert the synthetic images to time-series data for evaluation. The signal-to-noise ratio (SNR) was calculated to assess the image digitization quality vs the ground truth ECG time-series. The results show an average signal recovery SNR of 27$\pm$2.8\,dB, demonstrating the significance of the proposed synthetic ECG image dataset for training deep learning models.
M3PS: End-to-End Multi-Grained Multi-Modal Attribute-Aware Product Summarization in E-commerce
Aug 22, 2023
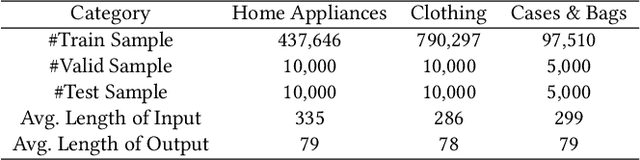
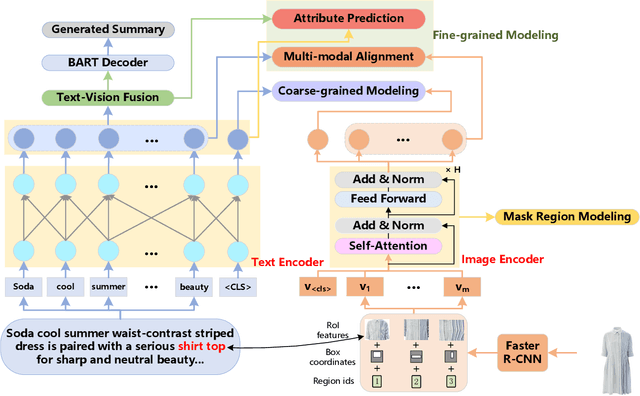

Given the long textual product information and the product image, Multi-Modal Product Summarization (MMPS) aims to attract customers' interest and increase their desire to purchase by highlighting product characteristics with a short textual summary. Existing MMPS methods have achieved promising performance. Nevertheless, there still exist several problems: 1) lack end-to-end product summarization, 2) lack multi-grained multi-modal modeling, and 3) lack multi-modal attribute modeling. To address these issues, we propose an end-to-end multi-grained multi-modal attribute-aware product summarization method (M3PS) for generating high-quality product summaries in e-commerce. M3PS jointly models product attributes and generates product summaries. Meanwhile, we design several multi-grained multi-modal tasks to better guide the multi-modal learning of M3PS. Furthermore, we model product attributes based on both text and image modalities so that multi-modal product characteristics can be manifested in the generated summaries. Extensive experiments on a real large-scale Chinese e-commence dataset demonstrate that our model outperforms state-of-the-art product summarization methods w.r.t. several summarization metrics.
Language-Conditioned Path Planning
Aug 31, 2023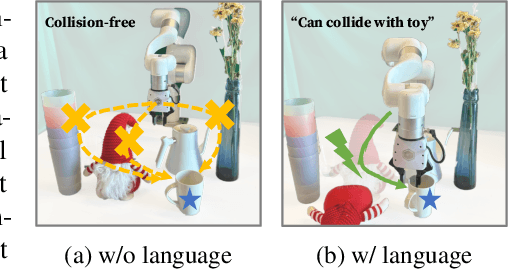
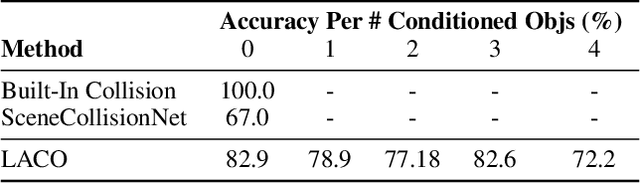
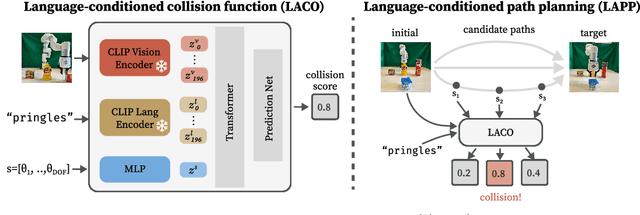

Contact is at the core of robotic manipulation. At times, it is desired (e.g. manipulation and grasping), and at times, it is harmful (e.g. when avoiding obstacles). However, traditional path planning algorithms focus solely on collision-free paths, limiting their applicability in contact-rich tasks. To address this limitation, we propose the domain of Language-Conditioned Path Planning, where contact-awareness is incorporated into the path planning problem. As a first step in this domain, we propose Language-Conditioned Collision Functions (LACO) a novel approach that learns a collision function using only a single-view image, language prompt, and robot configuration. LACO predicts collisions between the robot and the environment, enabling flexible, conditional path planning without the need for manual object annotations, point cloud data, or ground-truth object meshes. In both simulation and the real world, we demonstrate that LACO can facilitate complex, nuanced path plans that allow for interaction with objects that are safe to collide, rather than prohibiting any collision.
MMVP: Motion-Matrix-based Video Prediction
Aug 31, 2023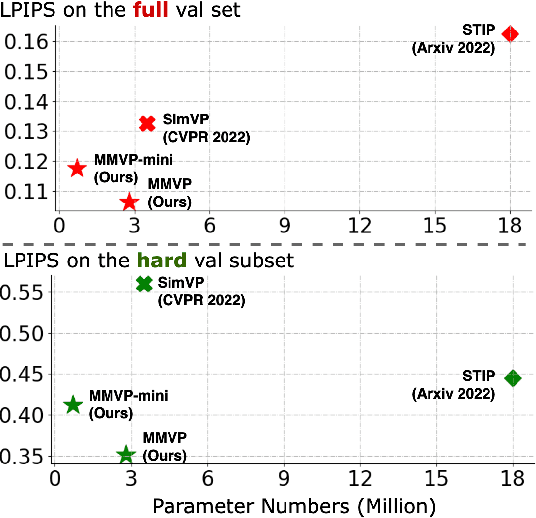

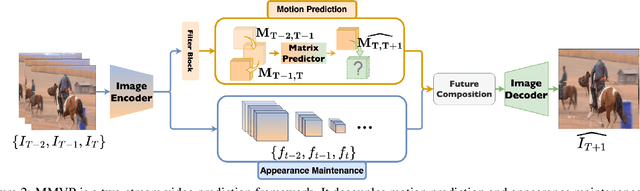
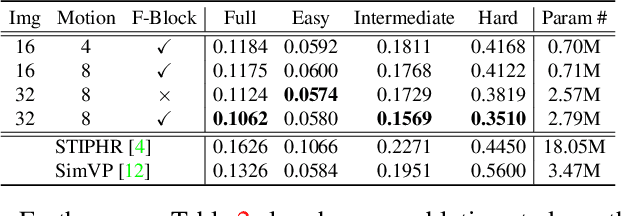
A central challenge of video prediction lies where the system has to reason the objects' future motions from image frames while simultaneously maintaining the consistency of their appearances across frames. This work introduces an end-to-end trainable two-stream video prediction framework, Motion-Matrix-based Video Prediction (MMVP), to tackle this challenge. Unlike previous methods that usually handle motion prediction and appearance maintenance within the same set of modules, MMVP decouples motion and appearance information by constructing appearance-agnostic motion matrices. The motion matrices represent the temporal similarity of each and every pair of feature patches in the input frames, and are the sole input of the motion prediction module in MMVP. This design improves video prediction in both accuracy and efficiency, and reduces the model size. Results of extensive experiments demonstrate that MMVP outperforms state-of-the-art systems on public data sets by non-negligible large margins (about 1 db in PSNR, UCF Sports) in significantly smaller model sizes (84% the size or smaller).
Gaussian Image Anomaly Detection with Greedy Eigencomponent Selection
Aug 09, 2023Anomaly detection (AD) in images, identifying significant deviations from normality, is a critical issue in computer vision. This paper introduces a novel approach to dimensionality reduction for AD using pre-trained convolutional neural network (CNN) that incorporate EfficientNet models. We investigate the importance of component selection and propose two types of tree search approaches, both employing a greedy strategy, for optimal eigencomponent selection. Our study conducts three main experiments to evaluate the effectiveness of our approach. The first experiment explores the influence of test set performance on component choice, the second experiment examines the performance when we train on one anomaly type and evaluate on all other types, and the third experiment investigates the impact of using a minimum number of images for training and selecting them based on anomaly types. Our approach aims to find the optimal subset of components that deliver the highest performance score, instead of focusing solely on the proportion of variance explained by each component and also understand the components behaviour in different settings. Our results indicate that the proposed method surpasses both Principal Component Analysis (PCA) and Negated Principal Component Analysis (NPCA) in terms of detection accuracy, even when using fewer components. Thus, our approach provides a promising alternative to conventional dimensionality reduction techniques in AD, and holds potential to enhance the efficiency and effectiveness of AD systems.