 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Fast Minimization Algorithm for the Euler Elastica Model Based on a Bilinear Decomposition
Aug 25, 2023

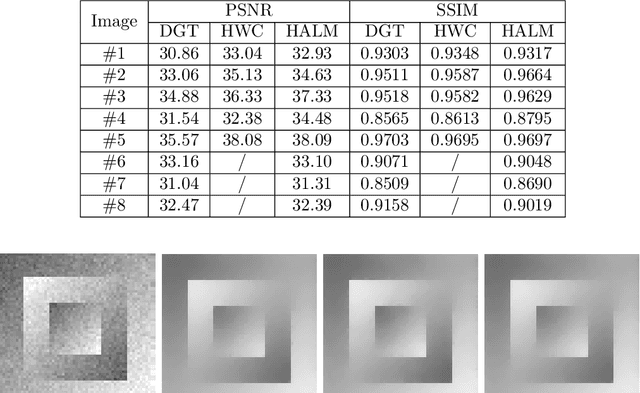

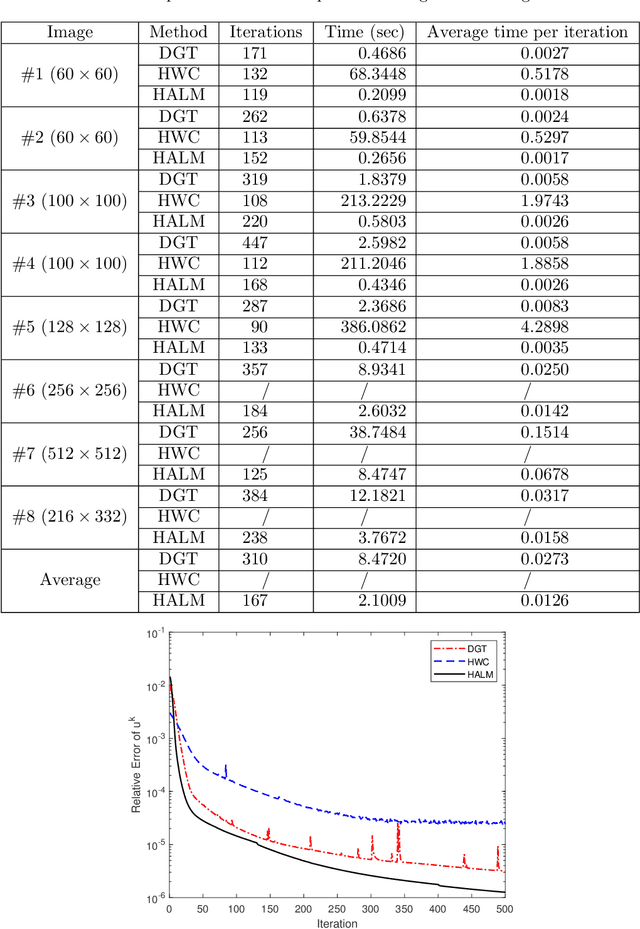
The Euler Elastica (EE) model with surface curvature can generate artifact-free results compared with the traditional total variation regularization model in image processing. However, strong nonlinearity and singularity due to the curvature term in the EE model pose a great challenge for one to design fast and stable algorithms for the EE model. In this paper, we propose a new, fast, hybrid alternating minimization (HALM) algorithm for the EE model based on a bilinear decomposition of the gradient of the underlying image and prove the global convergence of the minimizing sequence generated by the algorithm under mild conditions. The HALM algorithm comprises three sub-minimization problems and each is either solved in the closed form or approximated by fast solvers making the new algorithm highly accurate and efficient. We also discuss the extension of the HALM strategy to deal with general curvature-based variational models, especially with a Lipschitz smooth functional of the curvature. A host of numerical experiments are conducted to show that the new algorithm produces good results with much-improved efficiency compared to other state-of-the-art algorithms for the EE model. As one of the benchmarks, we show that the average running time of the HALM algorithm is at most one-quarter of that of the fast operator-splitting-based Deng-Glowinski-Tai algorithm.
3D Model-free Visual Localization System from Essential Matrix under Local Planar Motion
Sep 04, 2023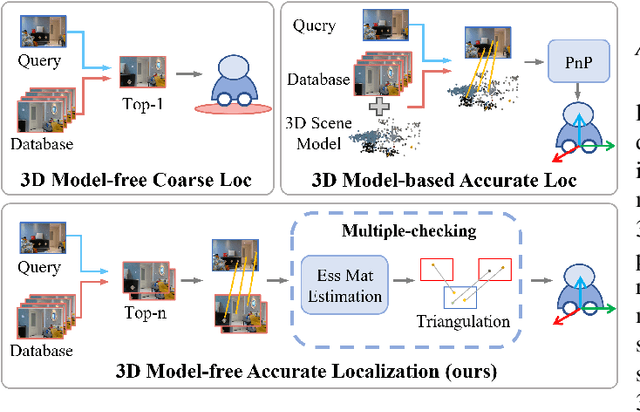


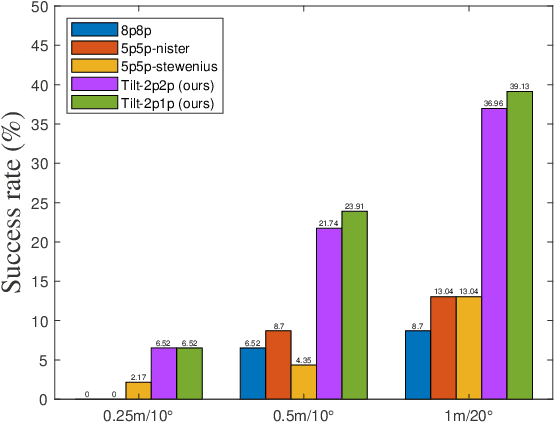
Visual localization plays a critical role in the functionality of low-cost autonomous mobile robots. Current state-of-the-art approaches for achieving accurate visual localization are 3D scene-specific, requiring additional computational and storage resources to construct a 3D scene model when facing a new environment. An alternative approach of directly using a database of 2D images for visual localization offers more flexibility. However, such methods currently suffer from limited localization accuracy. In this paper, we propose an accurate and robust multiple checking-based 3D model-free visual localization system to address the aforementioned issues. To ensure high accuracy, our focus is on estimating the pose of a query image relative to the retrieved database images using 2D-2D feature matches. Theoretically, by incorporating the local planar motion constraint into both the estimation of the essential matrix and the triangulation stages, we reduce the minimum required feature matches for absolute pose estimation, thereby enhancing the robustness of outlier rejection. Additionally, we introduce a multiple-checking mechanism to ensure the correctness of the solution throughout the solving process. For validation, qualitative and quantitative experiments are performed on both simulation and two real-world datasets and the experimental results demonstrate a significant enhancement in both accuracy and robustness afforded by the proposed 3D model-free visual localization system.
Effects of Material Mapping Agnostic Partial Volume Correction for Subject Specific Finite Elements Simulations
Sep 04, 2023
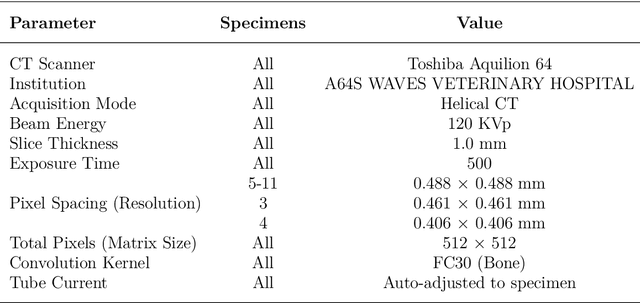
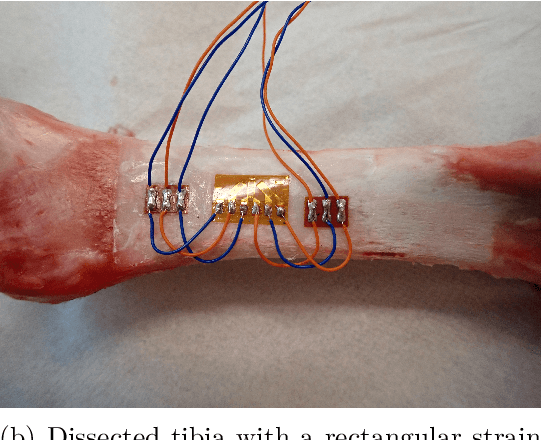
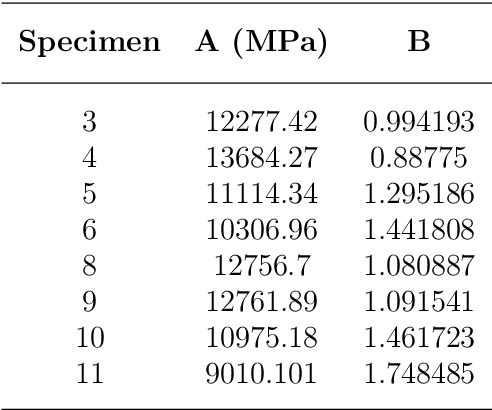
Partial Volume effects are present at the boundary between any two types of material in a CT image due to the scanner's Point Spread Function, finite voxel resolution, and importantly, the discrepancy in radiodensity between the two materials. In this study a new algorithm is developed and validated that builds on previously published work to enable the correction of partial volume effects at cortical bone boundaries. Unlike past methods, this algorithm does not require pre-processing or user input to achieve the correction, and the correction is applied directly onto a set of CT images, which enables it to be used in existing computational modelling workflows. The algorithm was validated by performing experimental three point bending tests on porcine fibulae specimen and comparing the experimental results to finite element results for models created using either the original, uncorrected CT images or the partial volume corrected images. Results demonstrated that the models created using the partial volume corrected images did improved the accuracy of the surface strain predictions. Given this initial validation, this algorithm is a viable method for overcoming the challenge of partial volume effects in CT images. Thus, future work should be undertaken to further validate the algorithm with human tissues and through coupling it with a range of different finite element creation workflows to verify that it is robust and agnostic to the chosen material mapping strategy.
SATAY: A Streaming Architecture Toolflow for Accelerating YOLO Models on FPGA Devices
Sep 04, 2023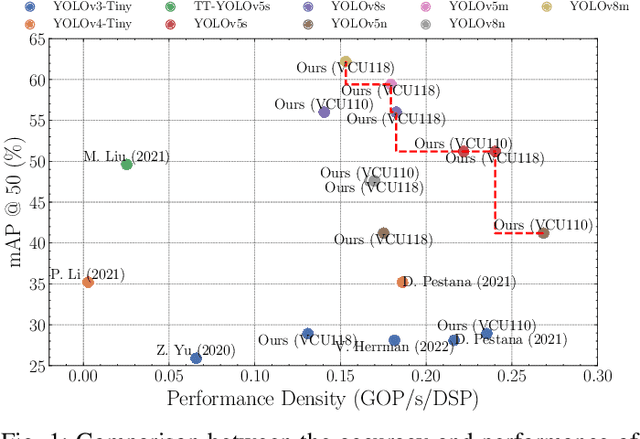
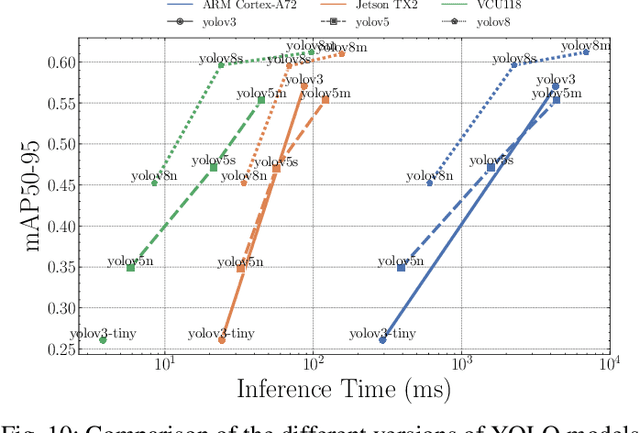
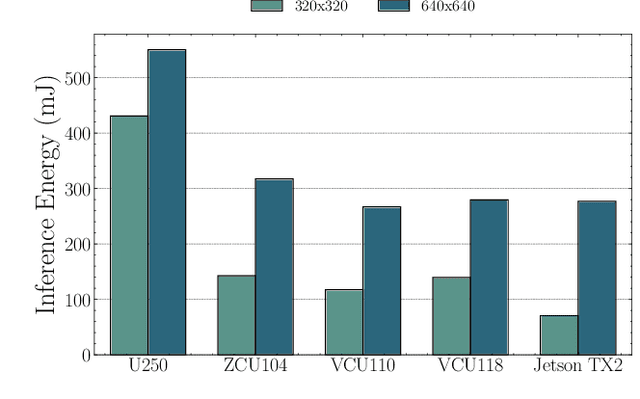
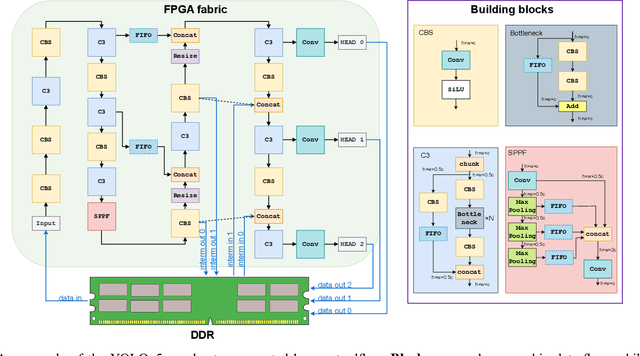
AI has led to significant advancements in computer vision and image processing tasks, enabling a wide range of applications in real-life scenarios, from autonomous vehicles to medical imaging. Many of those applications require efficient object detection algorithms and complementary real-time, low latency hardware to perform inference of these algorithms. The YOLO family of models is considered the most efficient for object detection, having only a single model pass. Despite this, the complexity and size of YOLO models can be too computationally demanding for current edge-based platforms. To address this, we present SATAY: a Streaming Architecture Toolflow for Accelerating YOLO. This work tackles the challenges of deploying stateof-the-art object detection models onto FPGA devices for ultralow latency applications, enabling real-time, edge-based object detection. We employ a streaming architecture design for our YOLO accelerators, implementing the complete model on-chip in a deeply pipelined fashion. These accelerators are generated using an automated toolflow, and can target a range of suitable FPGA devices. We introduce novel hardware components to support the operations of YOLO models in a dataflow manner, and off-chip memory buffering to address the limited on-chip memory resources. Our toolflow is able to generate accelerator designs which demonstrate competitive performance and energy characteristics to GPU devices, and which outperform current state-of-the-art FPGA accelerators.
SSVOD: Semi-Supervised Video Object Detection with Sparse Annotations
Sep 04, 2023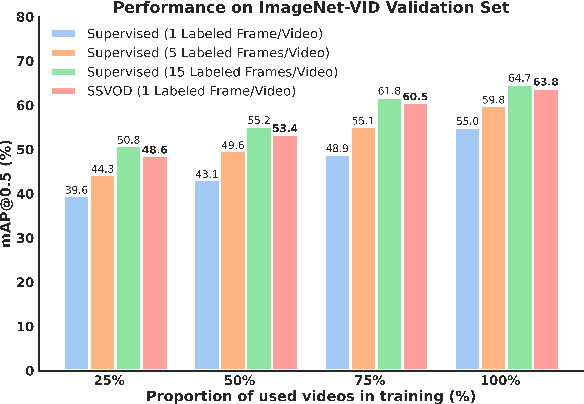
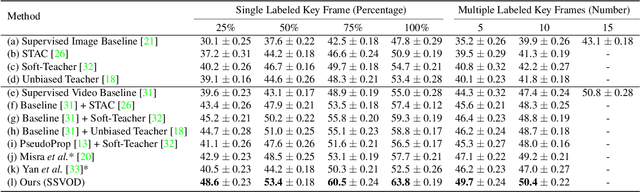
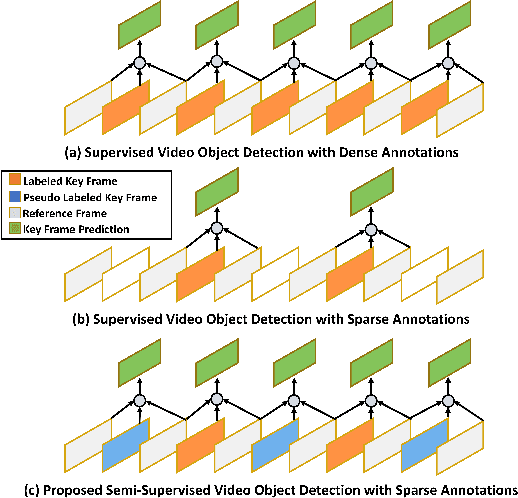
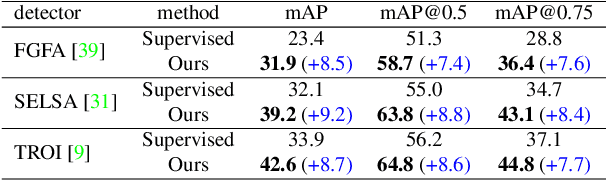
Despite significant progress in semi-supervised learning for image object detection, several key issues are yet to be addressed for video object detection: (1) Achieving good performance for supervised video object detection greatly depends on the availability of annotated frames. (2) Despite having large inter-frame correlations in a video, collecting annotations for a large number of frames per video is expensive, time-consuming, and often redundant. (3) Existing semi-supervised techniques on static images can hardly exploit the temporal motion dynamics inherently present in videos. In this paper, we introduce SSVOD, an end-to-end semi-supervised video object detection framework that exploits motion dynamics of videos to utilize large-scale unlabeled frames with sparse annotations. To selectively assemble robust pseudo-labels across groups of frames, we introduce \textit{flow-warped predictions} from nearby frames for temporal-consistency estimation. In particular, we introduce cross-IoU and cross-divergence based selection methods over a set of estimated predictions to include robust pseudo-labels for bounding boxes and class labels, respectively. To strike a balance between confirmation bias and uncertainty noise in pseudo-labels, we propose confidence threshold based combination of hard and soft pseudo-labels. Our method achieves significant performance improvements over existing methods on ImageNet-VID, Epic-KITCHENS, and YouTube-VIS datasets. Code and pre-trained models will be released.
ExMobileViT: Lightweight Classifier Extension for Mobile Vision Transformer
Sep 04, 2023The paper proposes an efficient structure for enhancing the performance of mobile-friendly vision transformer with small computational overhead. The vision transformer (ViT) is very attractive in that it reaches outperforming results in image classification, compared to conventional convolutional neural networks (CNNs). Due to its need of high computational resources, MobileNet-based ViT models such as MobileViT-S have been developed. However, their performance cannot reach the original ViT model. The proposed structure relieves the above weakness by storing the information from early attention stages and reusing it in the final classifier. This paper is motivated by the idea that the data itself from early attention stages can have important meaning for the final classification. In order to reuse the early information in attention stages, the average pooling results of various scaled features from early attention stages are used to expand channels in the fully-connected layer of the final classifier. It is expected that the inductive bias introduced by the averaged features can enhance the final performance. Because the proposed structure only needs the average pooling of features from the attention stages and channel expansions in the final classifier, its computational and storage overheads are very small, keeping the benefits of low-cost MobileNet-based ViT (MobileViT). Compared with the original MobileViTs on the ImageNet dataset, the proposed ExMobileViT has noticeable accuracy enhancements, having only about 5% additional parameters.
A Synthetic Electrocardiogram (ECG) Image Generation Toolbox to Facilitate Deep Learning-Based Scanned ECG Digitization
Jul 04, 2023

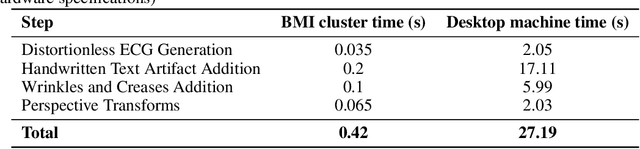
Access to medical data is often limited as it contains protected health information (PHI). There are privacy concerns regarding using records containing personally identifiable information. Recent advancements have been made in applying deep learning-based algorithms for clinical diagnosis and decision-making. However, deep learning models are data-greedy, whereas the availability of medical datasets for training and evaluating these models is relatively limited. Data augmentation with so-called \textit{digital twins} is an emerging technique to address this need. This paper presents a novel approach for generating synthetic electrocardiogram (ECG) images with realistic artifacts from time-series data for use in developing algorithms for digitization of ECG images. Synthetic data is generated in a privacy-preserving manner by generating distortionless ECG images on standard ECG paper background. Next, various distortions, including handwritten text artifacts, wrinkles, creases, and perspective transforms are applied to the ECG images. The artifacts are generated synthetically, without personally identifiable information. As a use case, we generated a large ECG image dataset of 21,801 records from the PhysioNet PTB-XL dataset, with 12 lead ECG time-series data from 18,869 patients. A deep ECG image digitization model was developed and trained on the synthetic dataset, and was employed to convert the synthetic images to time-series data for evaluation. The signal-to-noise ratio (SNR) was calculated to assess the image digitization quality vs the ground truth ECG time-series. The results show an average signal recovery SNR of 27$\pm$2.8\,dB, demonstrating the significance of the proposed synthetic ECG image dataset for training deep learning models.
Improving Lesion Volume Measurements on Digital Mammograms
Aug 28, 2023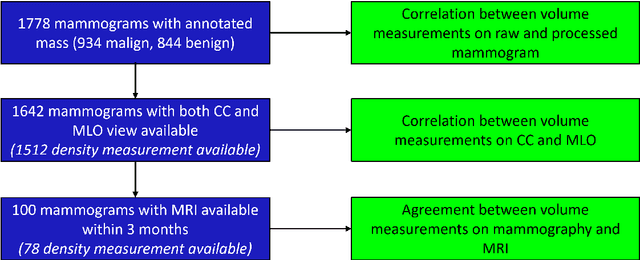
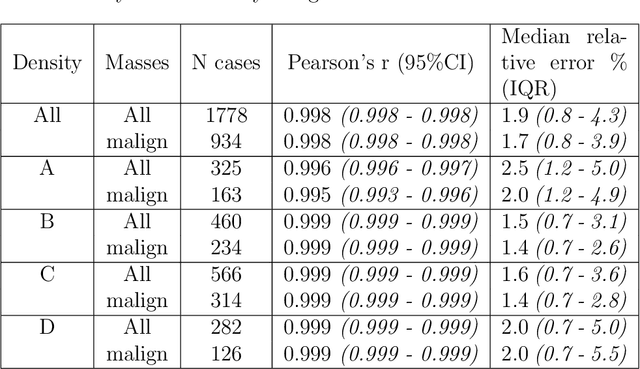
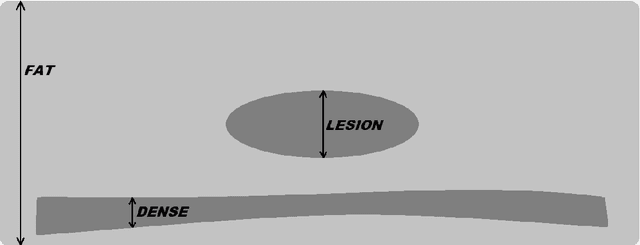
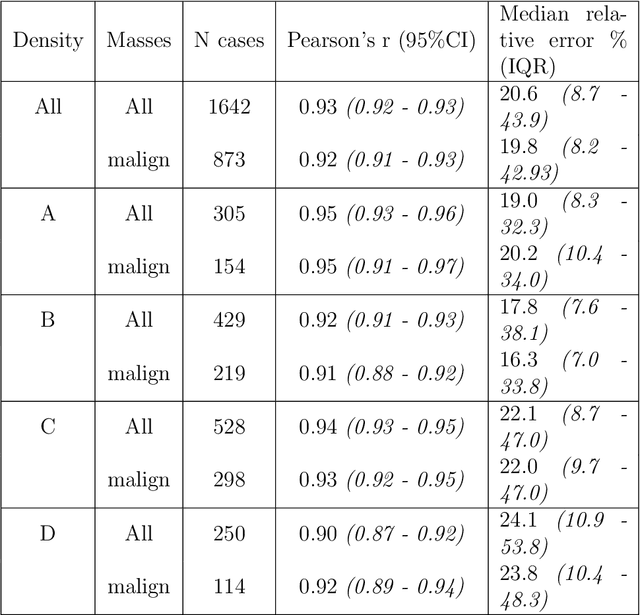
Lesion volume is an important predictor for prognosis in breast cancer. We make a step towards a more accurate lesion volume measurement on digital mammograms by developing a model that allows to estimate lesion volumes on processed mammograms, which are the images routinely used by radiologists in clinical practice as well as in breast cancer screening and are available in medical centers. Processed mammograms are obtained from raw mammograms, which are the X-ray data coming directly from the scanner, by applying certain vendor-specific non-linear transformations. At the core of our volume estimation method is a physics-based algorithm for measuring lesion volumes on raw mammograms. We subsequently extend this algorithm to processed mammograms via a deep learning image-to-image translation model that produces synthetic raw mammograms from processed mammograms in a multi-vendor setting. We assess the reliability and validity of our method using a dataset of 1778 mammograms with an annotated mass. Firstly, we investigate the correlations between lesion volumes computed from mediolateral oblique and craniocaudal views, with a resulting Pearson correlation of 0.93 [95% confidence interval (CI) 0.92 - 0.93]. Secondly, we compare the resulting lesion volumes from true and synthetic raw data, with a resulting Pearson correlation of 0.998 [95% CI 0.998 - 0.998] . Finally, for a subset of 100 mammograms with a malign mass and concurrent MRI examination available, we analyze the agreement between lesion volume on mammography and MRI, resulting in an intraclass correlation coefficient of 0.81 [95% CI 0.73 - 0.87] for consistency and 0.78 [95% CI 0.66 - 0.86] for absolute agreement. In conclusion, we developed an algorithm to measure mammographic lesion volume that reached excellent reliability and good validity, when using MRI as ground truth.
Enhancing Perception and Immersion in Pre-Captured Environments through Learning-Based Eye Height Adaptation
Aug 24, 2023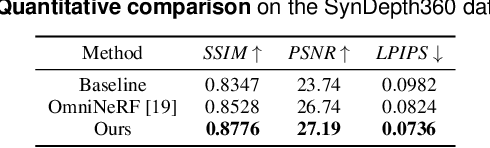
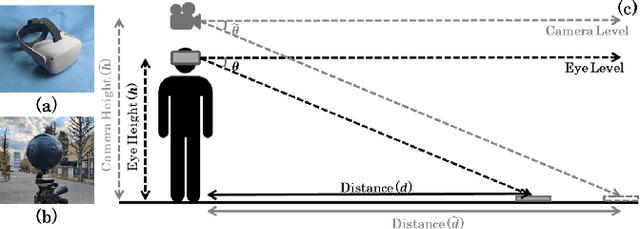


Pre-captured immersive environments using omnidirectional cameras provide a wide range of virtual reality applications. Previous research has shown that manipulating the eye height in egocentric virtual environments can significantly affect distance perception and immersion. However, the influence of eye height in pre-captured real environments has received less attention due to the difficulty of altering the perspective after finishing the capture process. To explore this influence, we first propose a pilot study that captures real environments with multiple eye heights and asks participants to judge the egocentric distances and immersion. If a significant influence is confirmed, an effective image-based approach to adapt pre-captured real-world environments to the user's eye height would be desirable. Motivated by the study, we propose a learning-based approach for synthesizing novel views for omnidirectional images with altered eye heights. This approach employs a multitask architecture that learns depth and semantic segmentation in two formats, and generates high-quality depth and semantic segmentation to facilitate the inpainting stage. With the improved omnidirectional-aware layered depth image, our approach synthesizes natural and realistic visuals for eye height adaptation. Quantitative and qualitative evaluation shows favorable results against state-of-the-art methods, and an extensive user study verifies improved perception and immersion for pre-captured real-world environments.
Motion-Guided Masking for Spatiotemporal Representation Learning
Aug 24, 2023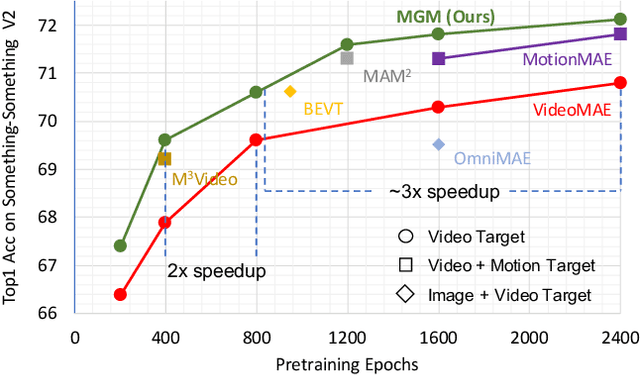
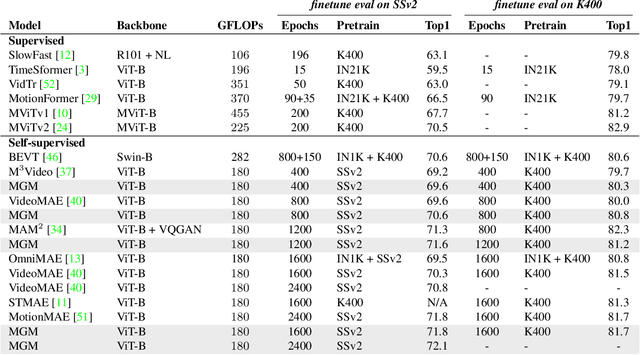
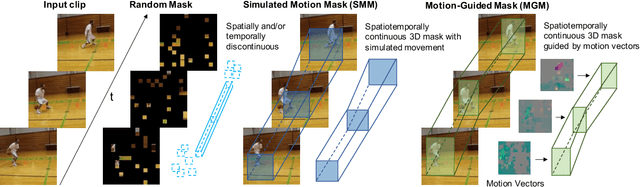
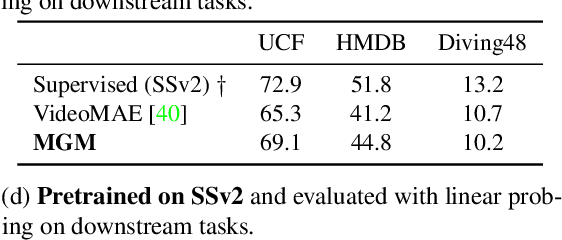
Several recent works have directly extended the image masked autoencoder (MAE) with random masking into video domain, achieving promising results. However, unlike images, both spatial and temporal information are important for video understanding. This suggests that the random masking strategy that is inherited from the image MAE is less effective for video MAE. This motivates the design of a novel masking algorithm that can more efficiently make use of video saliency. Specifically, we propose a motion-guided masking algorithm (MGM) which leverages motion vectors to guide the position of each mask over time. Crucially, these motion-based correspondences can be directly obtained from information stored in the compressed format of the video, which makes our method efficient and scalable. On two challenging large-scale video benchmarks (Kinetics-400 and Something-Something V2), we equip video MAE with our MGM and achieve up to +$1.3\%$ improvement compared to previous state-of-the-art methods. Additionally, our MGM achieves equivalent performance to previous video MAE using up to $66\%$ fewer training epochs. Lastly, we show that MGM generalizes better to downstream transfer learning and domain adaptation tasks on the UCF101, HMDB51, and Diving48 datasets, achieving up to +$4.9\%$ improvement compared to baseline methods.