 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pro-Cap: Leveraging a Frozen Vision-Language Model for Hateful Meme Detection
Aug 16, 2023
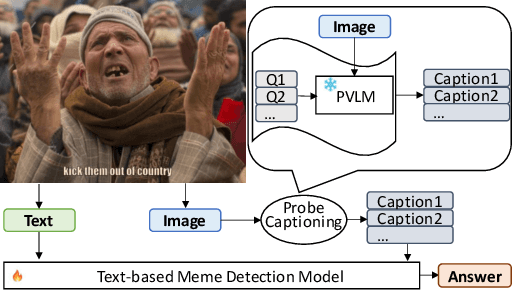
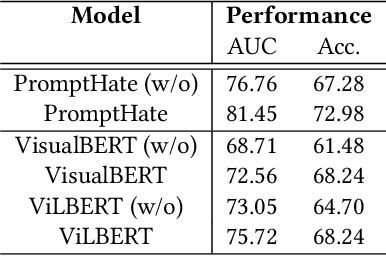

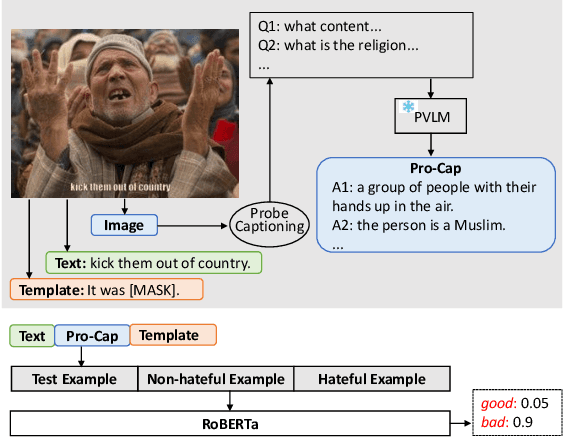
Hateful meme detection is a challenging multimodal task that requires comprehension of both vision and language, as well as cross-modal interactions. Recent studies have tried to fine-tune pre-trained vision-language models (PVLMs) for this task. However, with increasing model sizes, it becomes important to leverage powerful PVLMs more efficiently, rather than simply fine-tuning them. Recently, researchers have attempted to convert meme images into textual captions and prompt language models for predictions. This approach has shown good performance but suffers from non-informative image captions. Considering the two factors mentioned above, we propose a probing-based captioning approach to leverage PVLMs in a zero-shot visual question answering (VQA) manner. Specifically, we prompt a frozen PVLM by asking hateful content-related questions and use the answers as image captions (which we call Pro-Cap), so that the captions contain information critical for hateful content detection. The good performance of models with Pro-Cap on three benchmarks validates the effectiveness and generalization of the proposed method.
Revisiting Image Classifier Training for Improved Certified Robust Defense against Adversarial Patches
Jun 22, 2023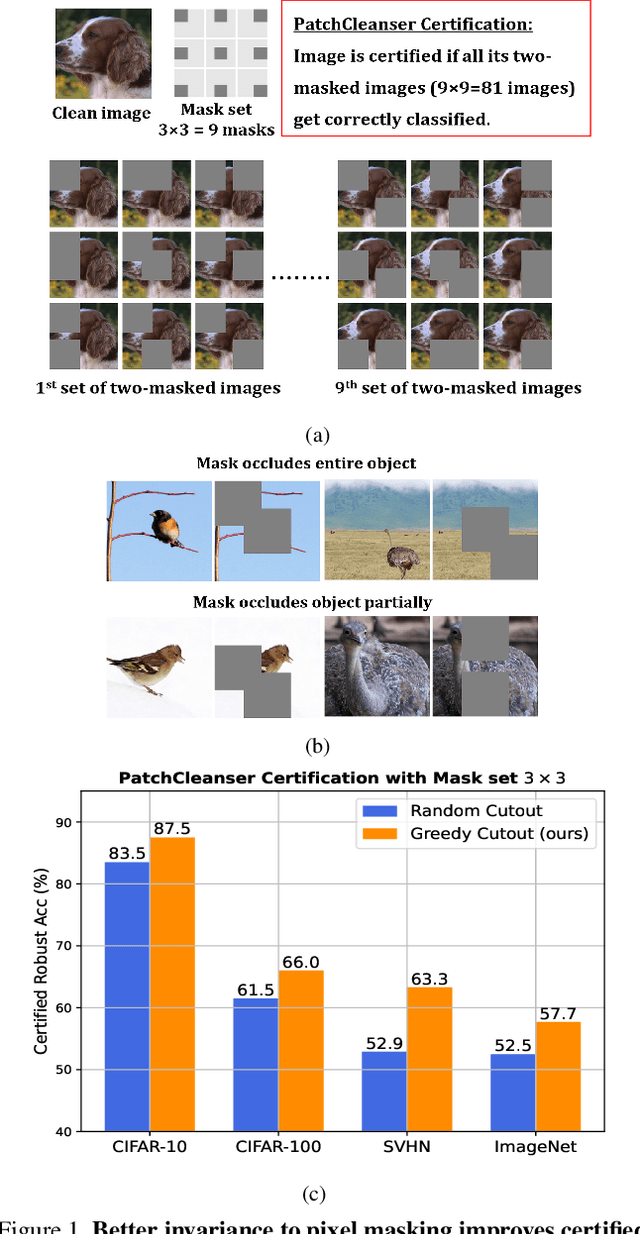
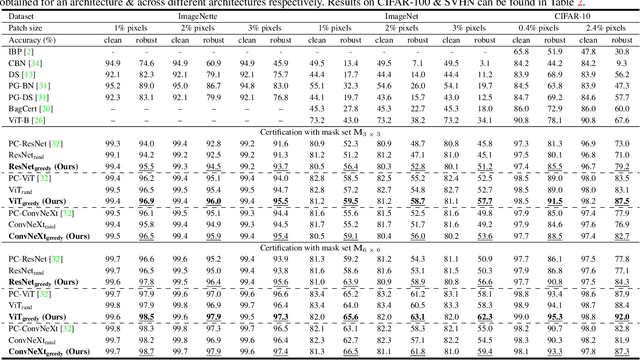

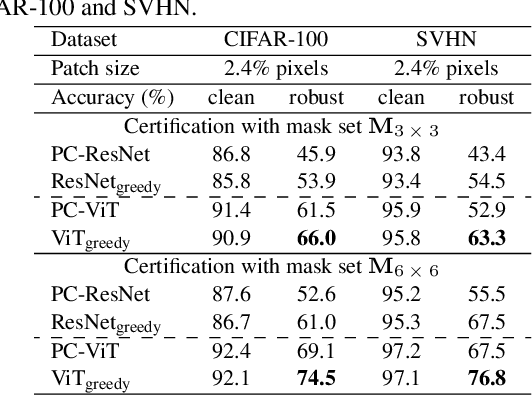
Certifiably robust defenses against adversarial patches for image classifiers ensure correct prediction against any changes to a constrained neighborhood of pixels. PatchCleanser arXiv:2108.09135 [cs.CV], the state-of-the-art certified defense, uses a double-masking strategy for robust classification. The success of this strategy relies heavily on the model's invariance to image pixel masking. In this paper, we take a closer look at model training schemes to improve this invariance. Instead of using Random Cutout arXiv:1708.04552v2 [cs.CV] augmentations like PatchCleanser, we introduce the notion of worst-case masking, i.e., selecting masked images which maximize classification loss. However, finding worst-case masks requires an exhaustive search, which might be prohibitively expensive to do on-the-fly during training. To solve this problem, we propose a two-round greedy masking strategy (Greedy Cutout) which finds an approximate worst-case mask location with much less compute. We show that the models trained with our Greedy Cutout improves certified robust accuracy over Random Cutout in PatchCleanser across a range of datasets and architectures. Certified robust accuracy on ImageNet with a ViT-B16-224 model increases from 58.1\% to 62.3\% against a 3\% square patch applied anywhere on the image.
Unsupervised Compositional Concepts Discovery with Text-to-Image Generative Models
Jun 08, 2023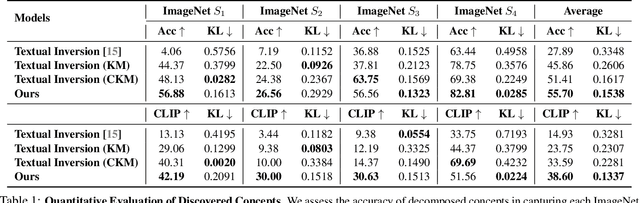
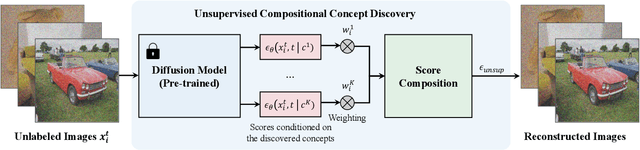


Text-to-image generative models have enabled high-resolution image synthesis across different domains, but require users to specify the content they wish to generate. In this paper, we consider the inverse problem -- given a collection of different images, can we discover the generative concepts that represent each image? We present an unsupervised approach to discover generative concepts from a collection of images, disentangling different art styles in paintings, objects, and lighting from kitchen scenes, and discovering image classes given ImageNet images. We show how such generative concepts can accurately represent the content of images, be recombined and composed to generate new artistic and hybrid images, and be further used as a representation for downstream classification tasks.
Spherical Vision Transformer for 360-degree Video Saliency Prediction
Aug 24, 2023
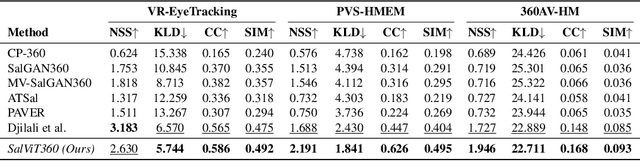
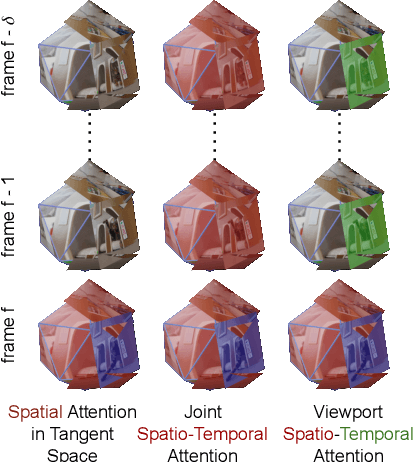
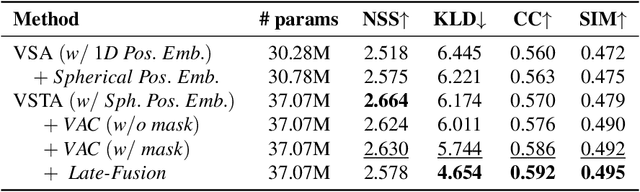
The growing interest in omnidirectional videos (ODVs) that capture the full field-of-view (FOV) has gained 360-degree saliency prediction importance in computer vision. However, predicting where humans look in 360-degree scenes presents unique challenges, including spherical distortion, high resolution, and limited labelled data. We propose a novel vision-transformer-based model for omnidirectional videos named SalViT360 that leverages tangent image representations. We introduce a spherical geometry-aware spatiotemporal self-attention mechanism that is capable of effective omnidirectional video understanding. Furthermore, we present a consistency-based unsupervised regularization term for projection-based 360-degree dense-prediction models to reduce artefacts in the predictions that occur after inverse projection. Our approach is the first to employ tangent images for omnidirectional saliency prediction, and our experimental results on three ODV saliency datasets demonstrate its effectiveness compared to the state-of-the-art.
Masked Autoencoders are Efficient Class Incremental Learners
Aug 24, 2023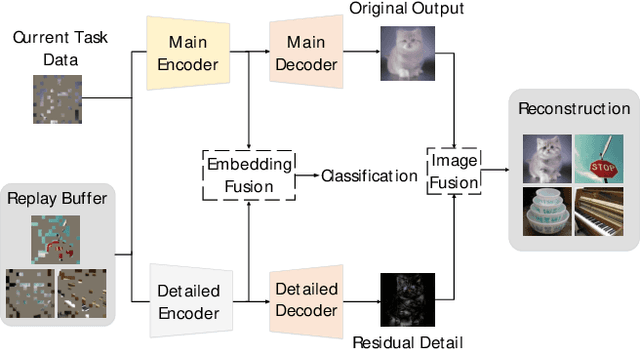
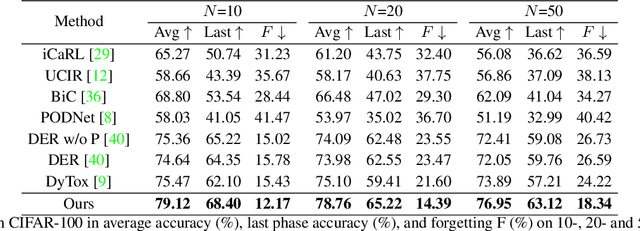
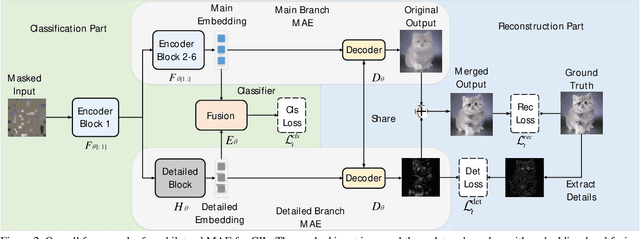
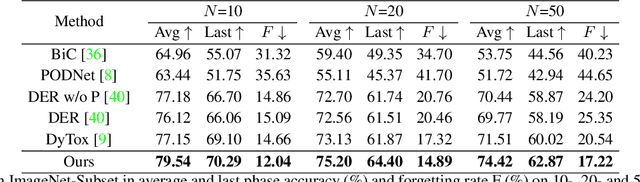
Class Incremental Learning (CIL) aims to sequentially learn new classes while avoiding catastrophic forgetting of previous knowledge. We propose to use Masked Autoencoders (MAEs) as efficient learners for CIL. MAEs were originally designed to learn useful representations through reconstructive unsupervised learning, and they can be easily integrated with a supervised loss for classification. Moreover, MAEs can reliably reconstruct original input images from randomly selected patches, which we use to store exemplars from past tasks more efficiently for CIL. We also propose a bilateral MAE framework to learn from image-level and embedding-level fusion, which produces better-quality reconstructed images and more stable representations. Our experiments confirm that our approach performs better than the state-of-the-art on CIFAR-100, ImageNet-Subset, and ImageNet-Full. The code is available at https://github.com/scok30/MAE-CIL .
DiffSketching: Sketch Control Image Synthesis with Diffusion Models
May 30, 2023
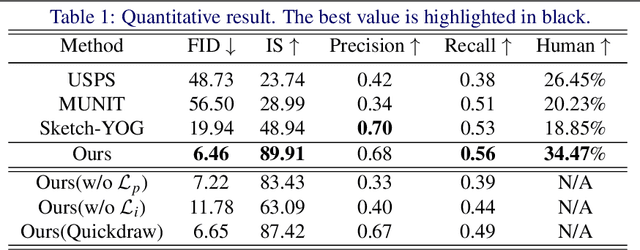
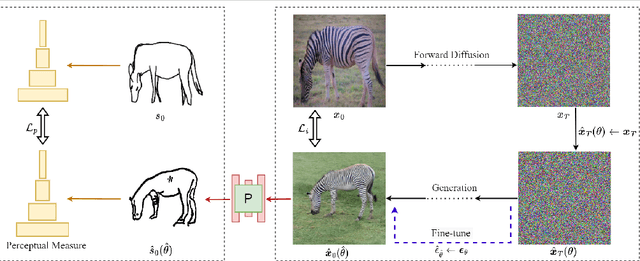

Creative sketch is a universal way of visual expression, but translating images from an abstract sketch is very challenging. Traditionally, creating a deep learning model for sketch-to-image synthesis needs to overcome the distorted input sketch without visual details, and requires to collect large-scale sketch-image datasets. We first study this task by using diffusion models. Our model matches sketches through the cross domain constraints, and uses a classifier to guide the image synthesis more accurately. Extensive experiments confirmed that our method can not only be faithful to user's input sketches, but also maintain the diversity and imagination of synthetic image results. Our model can beat GAN-based method in terms of generation quality and human evaluation, and does not rely on massive sketch-image datasets. Additionally, we present applications of our method in image editing and interpolation.
Devil is in Channels: Contrastive Single Domain Generalization for Medical Image Segmentation
Jun 24, 2023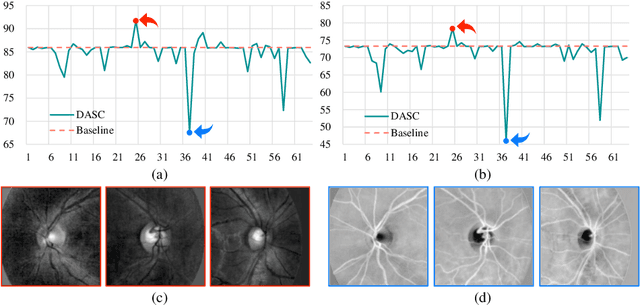
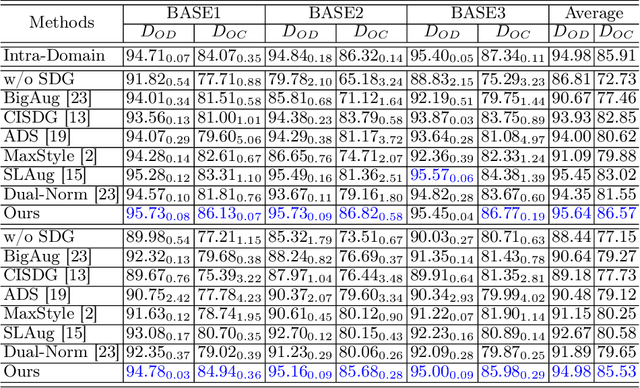
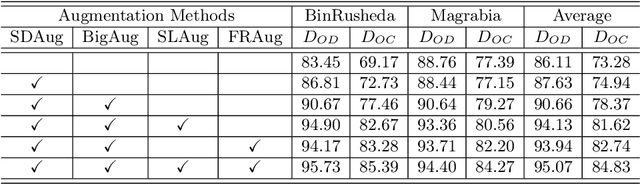
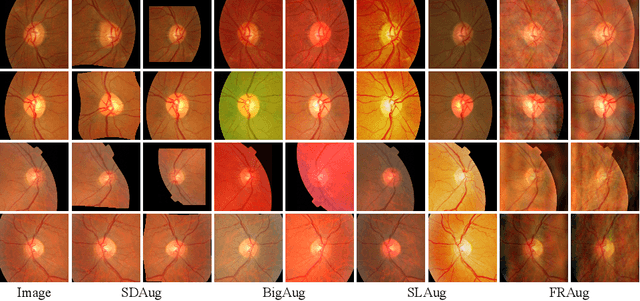
Deep learning-based medical image segmentation models suffer from performance degradation when deployed to a new healthcare center. To address this issue, unsupervised domain adaptation and multi-source domain generalization methods have been proposed, which, however, are less favorable for clinical practice due to the cost of acquiring target-domain data and the privacy concerns associated with redistributing the data from multiple source domains. In this paper, we propose a \textbf{C}hannel-level \textbf{C}ontrastive \textbf{S}ingle \textbf{D}omain \textbf{G}eneralization (\textbf{C$^2$SDG}) model for medical image segmentation. In C$^2$SDG, the shallower features of each image and its style-augmented counterpart are extracted and used for contrastive training, resulting in the disentangled style representations and structure representations. The segmentation is performed based solely on the structure representations. Our method is novel in the contrastive perspective that enables channel-wise feature disentanglement using a single source domain. We evaluated C$^2$SDG against six SDG methods on a multi-domain joint optic cup and optic disc segmentation benchmark. Our results suggest the effectiveness of each module in C$^2$SDG and also indicate that C$^2$SDG outperforms the baseline and all competing methods with a large margin. The code will be available at \url{https://github.com/ShishuaiHu/CCSDG}.
Classification robustness to common optical aberrations
Aug 29, 2023

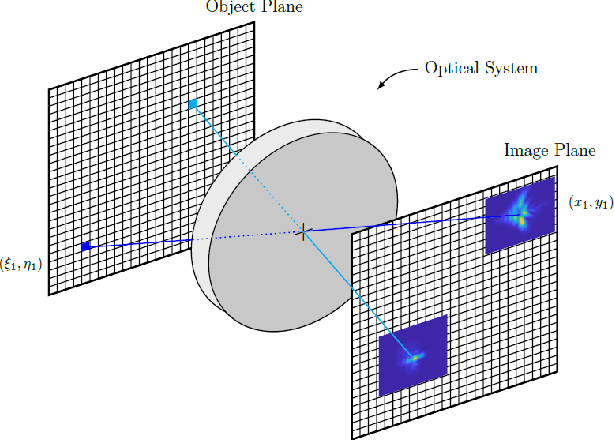
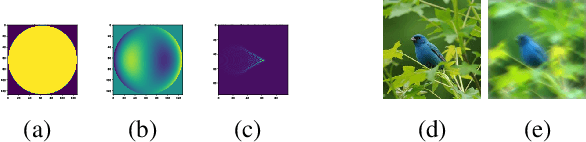
Computer vision using deep neural networks (DNNs) has brought about seminal changes in people's lives. Applications range from automotive, face recognition in the security industry, to industrial process monitoring. In some cases, DNNs infer even in safety-critical situations. Therefore, for practical applications, DNNs have to behave in a robust way to disturbances such as noise, pixelation, or blur. Blur directly impacts the performance of DNNs, which are often approximated as a disk-shaped kernel to model defocus. However, optics suggests that there are different kernel shapes depending on wavelength and location caused by optical aberrations. In practice, as the optical quality of a lens decreases, such aberrations increase. This paper proposes OpticsBench, a benchmark for investigating robustness to realistic, practically relevant optical blur effects. Each corruption represents an optical aberration (coma, astigmatism, spherical, trefoil) derived from Zernike Polynomials. Experiments on ImageNet show that for a variety of different pre-trained DNNs, the performance varies strongly compared to disk-shaped kernels, indicating the necessity of considering realistic image degradations. In addition, we show on ImageNet-100 with OpticsAugment that robustness can be increased by using optical kernels as data augmentation. Compared to a conventionally trained ResNeXt50, training with OpticsAugment achieves an average performance gain of 21.7% points on OpticsBench and 6.8% points on 2D common corruptions.
Feature Decoupling-Recycling Network for Fast Interactive Segmentation
Aug 07, 2023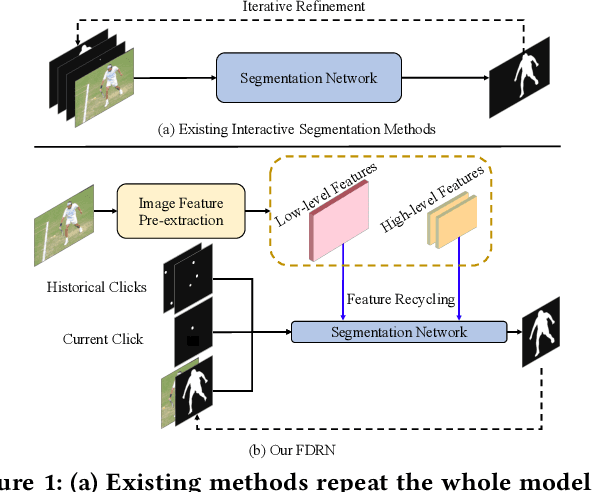
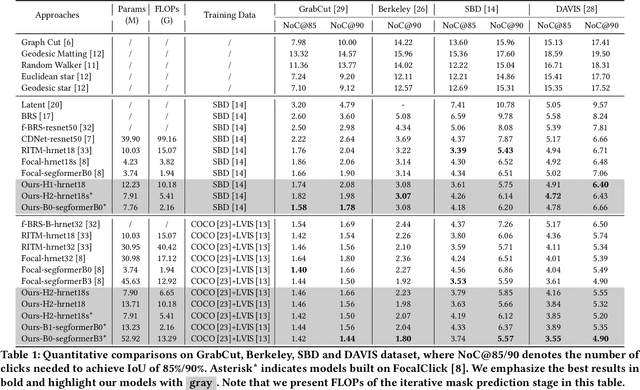
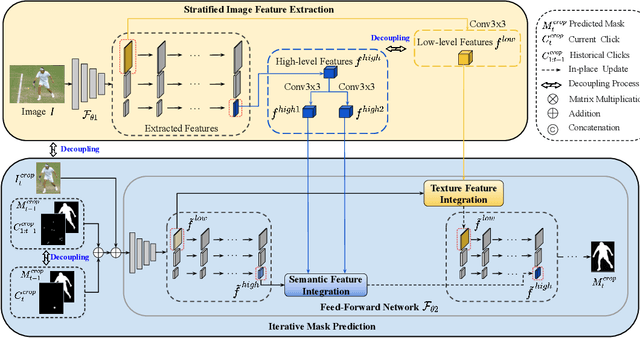
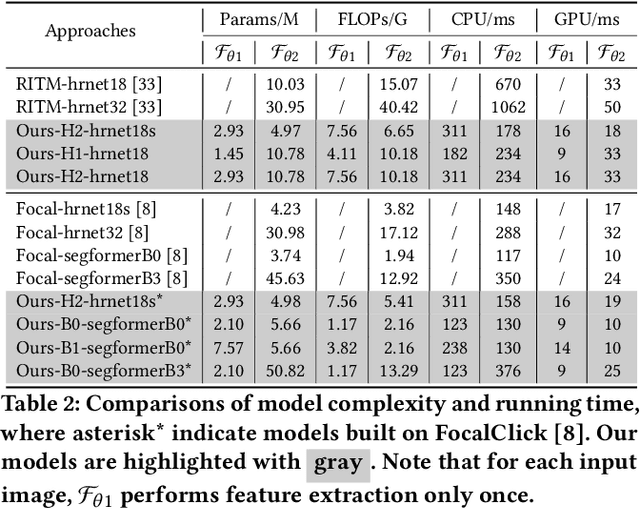
Recent interactive segmentation methods iteratively take source image, user guidance and previously predicted mask as the input without considering the invariant nature of the source image. As a result, extracting features from the source image is repeated in each interaction, resulting in substantial computational redundancy. In this work, we propose the Feature Decoupling-Recycling Network (FDRN), which decouples the modeling components based on their intrinsic discrepancies and then recycles components for each user interaction. Thus, the efficiency of the whole interactive process can be significantly improved. To be specific, we apply the Decoupling-Recycling strategy from three perspectives to address three types of discrepancies, respectively. First, our model decouples the learning of source image semantics from the encoding of user guidance to process two types of input domains separately. Second, FDRN decouples high-level and low-level features from stratified semantic representations to enhance feature learning. Third, during the encoding of user guidance, current user guidance is decoupled from historical guidance to highlight the effect of current user guidance. We conduct extensive experiments on 6 datasets from different domains and modalities, which demonstrate the following merits of our model: 1) superior efficiency than other methods, particularly advantageous in challenging scenarios requiring long-term interactions (up to 4.25x faster), while achieving favorable segmentation performance; 2) strong applicability to various methods serving as a universal enhancement technique; 3) well cross-task generalizability, e.g., to medical image segmentation, and robustness against misleading user guidance.
Efficient Learned Lossless JPEG Recompression
Aug 25, 2023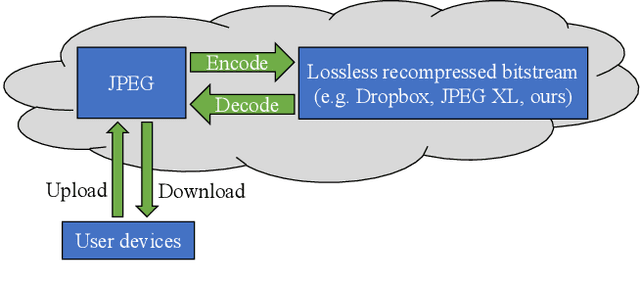

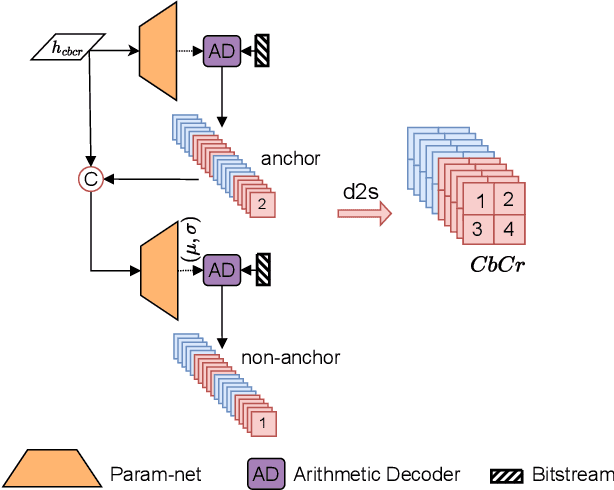
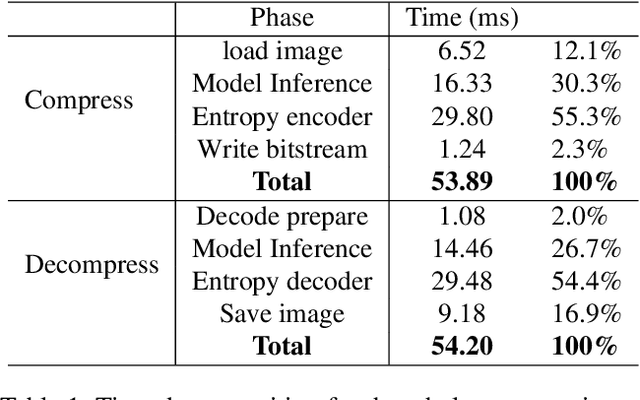
JPEG is one of the most popular image compression methods. It is beneficial to compress those existing JPEG files without introducing additional distortion. In this paper, we propose a deep learning based method to further compress JPEG images losslessly. Specifically, we propose a Multi-Level Parallel Conditional Modeling (ML-PCM) architecture, which enables parallel decoding in different granularities. First, luma and chroma are processed independently to allow parallel coding. Second, we propose pipeline parallel context model (PPCM) and compressed checkerboard context model (CCCM) for the effective conditional modeling and efficient decoding within luma and chroma components. Our method has much lower latency while achieves better compression ratio compared with previous SOTA. After proper software optimization, we can obtain a good throughput of 57 FPS for 1080P images on NVIDIA T4 GPU. Furthermore, combined with quantization, our approach can also act as a lossy JPEG codec which has obvious advantage over SOTA lossy compression methods in high bit rate (bpp$>0.9$).