 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Metrics to Quantify Global Consistency in Synthetic Medical Images
Aug 01, 2023
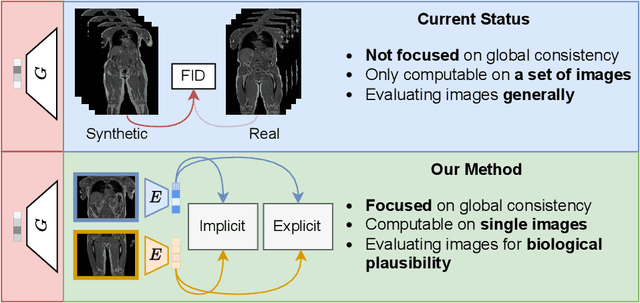
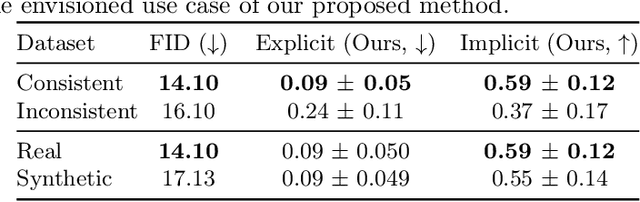
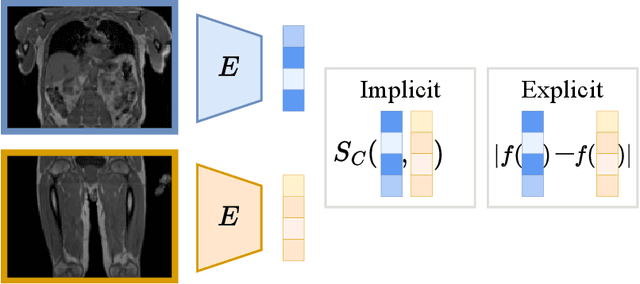
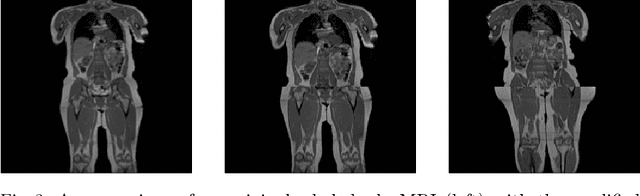
Image synthesis is increasingly being adopted in medical image processing, for example for data augmentation or inter-modality image translation. In these critical applications, the generated images must fulfill a high standard of biological correctness. A particular requirement for these images is global consistency, i.e an image being overall coherent and structured so that all parts of the image fit together in a realistic and meaningful way. Yet, established image quality metrics do not explicitly quantify this property of synthetic images. In this work, we introduce two metrics that can measure the global consistency of synthetic images on a per-image basis. To measure the global consistency, we presume that a realistic image exhibits consistent properties, e.g., a person's body fat in a whole-body MRI, throughout the depicted object or scene. Hence, we quantify global consistency by predicting and comparing explicit attributes of images on patches using supervised trained neural networks. Next, we adapt this strategy to an unlabeled setting by measuring the similarity of implicit image features predicted by a self-supervised trained network. Our results demonstrate that predicting explicit attributes of synthetic images on patches can distinguish globally consistent from inconsistent images. Implicit representations of images are less sensitive to assess global consistency but are still serviceable when labeled data is unavailable. Compared to established metrics, such as the FID, our method can explicitly measure global consistency on a per-image basis, enabling a dedicated analysis of the biological plausibility of single synthetic images.
Story Visualization by Online Text Augmentation with Context Memory
Aug 15, 2023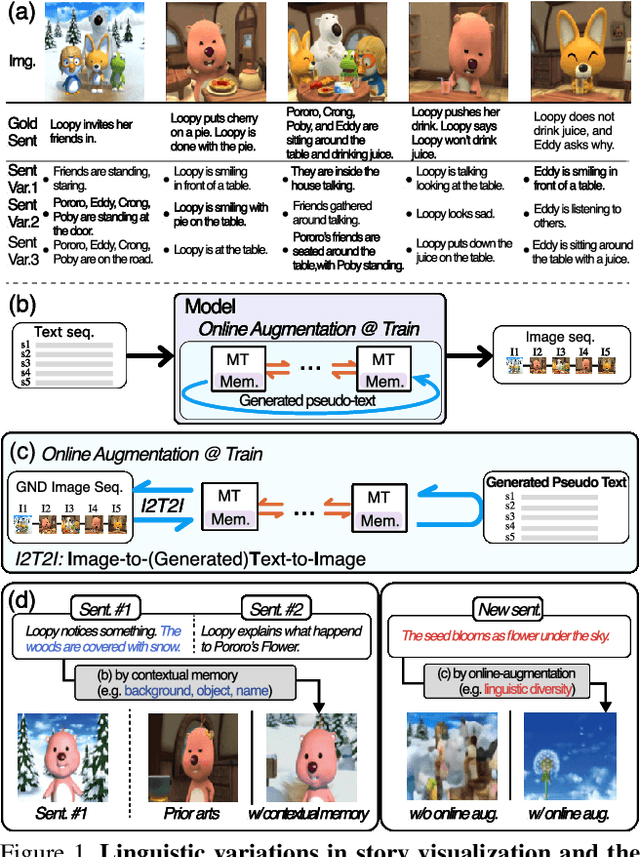
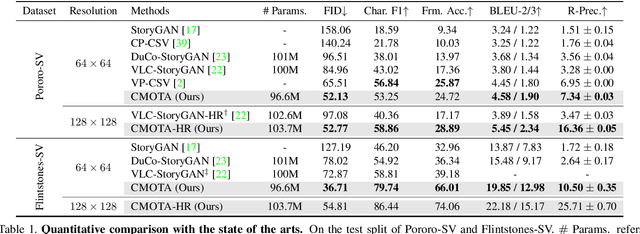
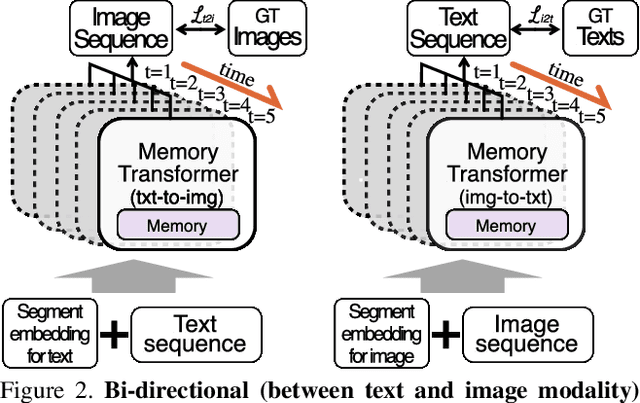
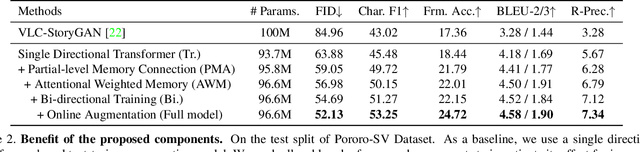
Story visualization (SV) is a challenging text-to-image generation task for the difficulty of not only rendering visual details from the text descriptions but also encoding a long-term context across multiple sentences. While prior efforts mostly focus on generating a semantically relevant image for each sentence, encoding a context spread across the given paragraph to generate contextually convincing images (e.g., with a correct character or with a proper background of the scene) remains a challenge. To this end, we propose a novel memory architecture for the Bi-directional Transformers with an online text augmentation that generates multiple pseudo-descriptions as supplementary supervision during training, for better generalization to the language variation at inference. In extensive experiments on the two popular SV benchmarks, i.e., the Pororo-SV and Flintstones-SV, the proposed method significantly outperforms the state of the arts in various evaluation metrics including FID, character F1, frame accuracy, BLEU-2/3, and R-precision with similar or less computational complexity.
Text-Only Training for Visual Storytelling
Aug 17, 2023
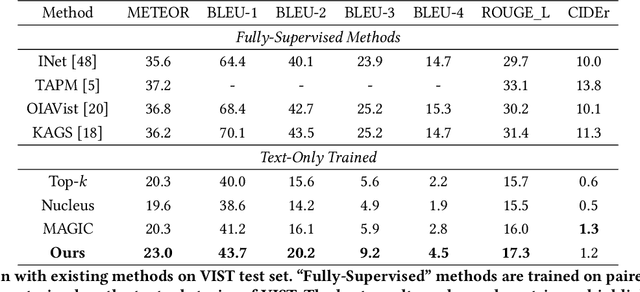
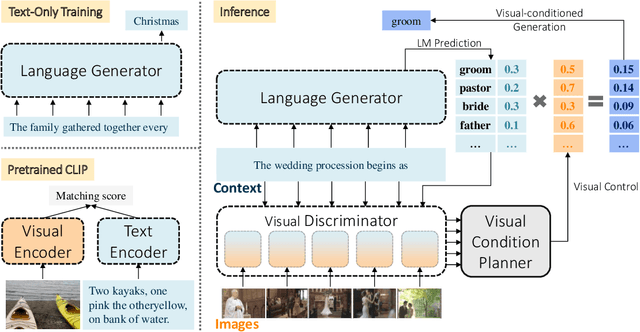
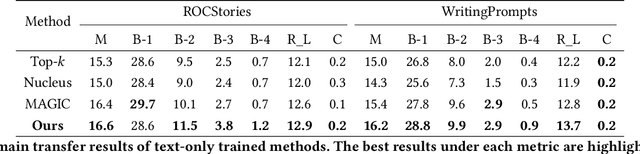
Visual storytelling aims to generate a narrative based on a sequence of images, necessitating both vision-language alignment and coherent story generation. Most existing solutions predominantly depend on paired image-text training data, which can be costly to collect and challenging to scale. To address this, we formulate visual storytelling as a visual-conditioned story generation problem and propose a text-only training method that separates the learning of cross-modality alignment and story generation. Our approach specifically leverages the cross-modality pre-trained CLIP model to integrate visual control into a story generator, trained exclusively on text data. Moreover, we devise a training-free visual condition planner that accounts for the temporal structure of the input image sequence while balancing global and local visual content. The distinctive advantage of requiring only text data for training enables our method to learn from external text story data, enhancing the generalization capability of visual storytelling. We conduct extensive experiments on the VIST benchmark, showcasing the effectiveness of our approach in both in-domain and cross-domain settings. Further evaluations on expression diversity and human assessment underscore the superiority of our method in terms of informativeness and robustness.
Stable and Causal Inference for Discriminative Self-supervised Deep Visual Representations
Aug 16, 2023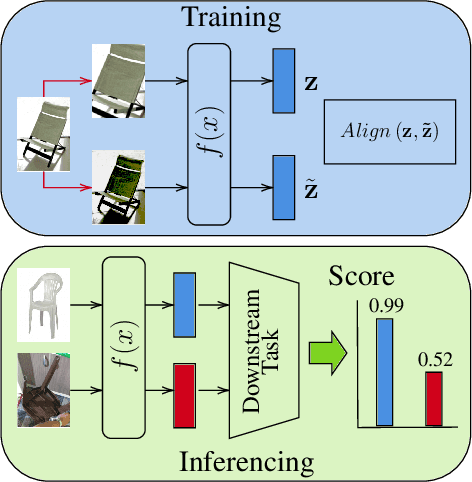
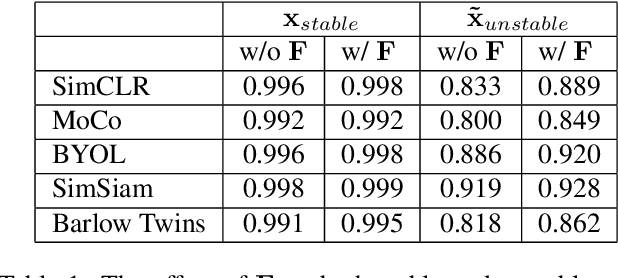
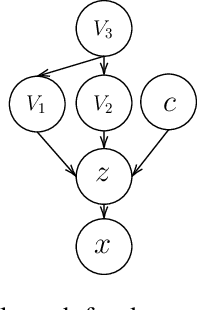
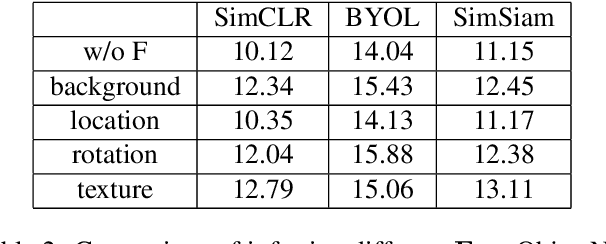
In recent years, discriminative self-supervised methods have made significant strides in advancing various visual tasks. The central idea of learning a data encoder that is robust to data distortions/augmentations is straightforward yet highly effective. Although many studies have demonstrated the empirical success of various learning methods, the resulting learned representations can exhibit instability and hinder downstream performance. In this study, we analyze discriminative self-supervised methods from a causal perspective to explain these unstable behaviors and propose solutions to overcome them. Our approach draws inspiration from prior works that empirically demonstrate the ability of discriminative self-supervised methods to demix ground truth causal sources to some extent. Unlike previous work on causality-empowered representation learning, we do not apply our solutions during the training process but rather during the inference process to improve time efficiency. Through experiments on both controlled image datasets and realistic image datasets, we show that our proposed solutions, which involve tempering a linear transformation with controlled synthetic data, are effective in addressing these issues.
Pro-Cap: Leveraging a Frozen Vision-Language Model for Hateful Meme Detection
Aug 16, 2023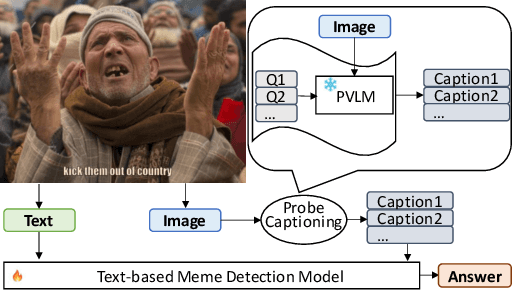
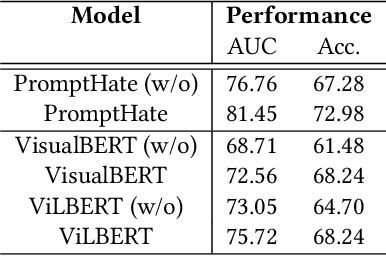

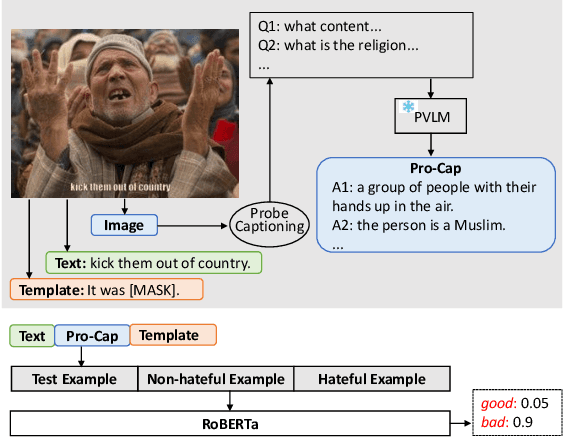
Hateful meme detection is a challenging multimodal task that requires comprehension of both vision and language, as well as cross-modal interactions. Recent studies have tried to fine-tune pre-trained vision-language models (PVLMs) for this task. However, with increasing model sizes, it becomes important to leverage powerful PVLMs more efficiently, rather than simply fine-tuning them. Recently, researchers have attempted to convert meme images into textual captions and prompt language models for predictions. This approach has shown good performance but suffers from non-informative image captions. Considering the two factors mentioned above, we propose a probing-based captioning approach to leverage PVLMs in a zero-shot visual question answering (VQA) manner. Specifically, we prompt a frozen PVLM by asking hateful content-related questions and use the answers as image captions (which we call Pro-Cap), so that the captions contain information critical for hateful content detection. The good performance of models with Pro-Cap on three benchmarks validates the effectiveness and generalization of the proposed method.
Robust Image Ordinal Regression with Controllable Image Generation
May 10, 2023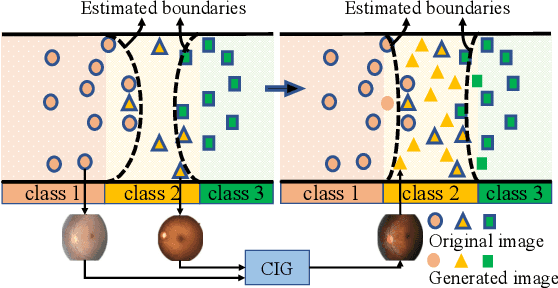
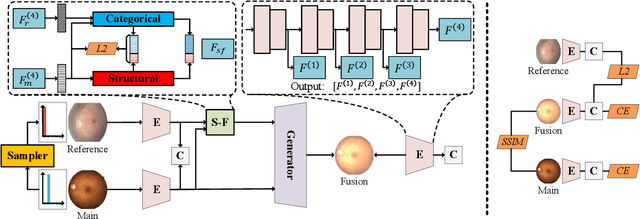
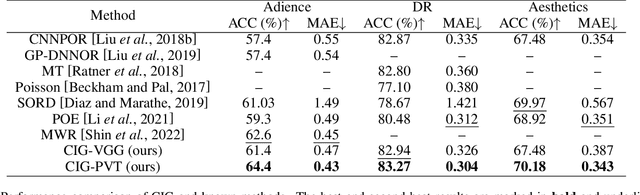
Image ordinal regression has been mainly studied along the line of exploiting the order of categories. However, the issues of class imbalance and category overlap that are very common in ordinal regression were largely overlooked. As a result, the performance on minority categories is often unsatisfactory. In this paper, we propose a novel framework called CIG based on controllable image generation to directly tackle these two issues. Our main idea is to generate extra training samples with specific labels near category boundaries, and the sample generation is biased toward the less-represented categories. To achieve controllable image generation, we seek to separate structural and categorical information of images based on structural similarity, categorical similarity, and reconstruction constraints. We evaluate the effectiveness of our new CIG approach in three different image ordinal regression scenarios. The results demonstrate that CIG can be flexibly integrated with off-the-shelf image encoders or ordinal regression models to achieve improvement, and further, the improvement is more significant for minority categories.
Energy-Based Cross Attention for Bayesian Context Update in Text-to-Image Diffusion Models
Jun 16, 2023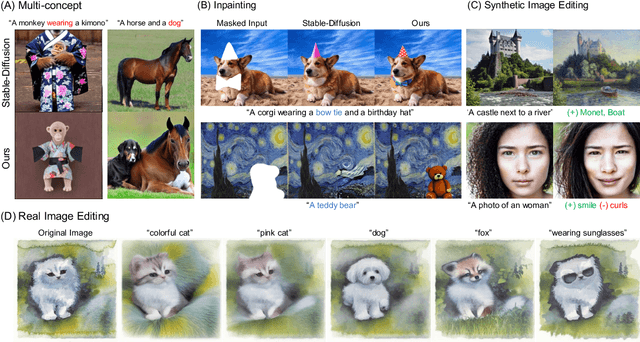
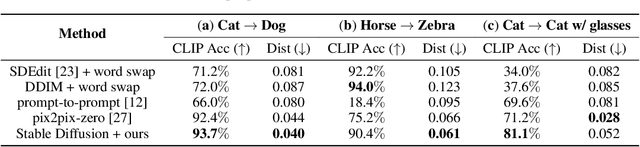
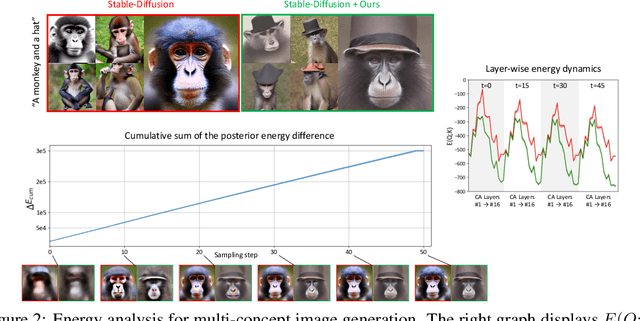

Despite the remarkable performance of text-to-image diffusion models in image generation tasks, recent studies have raised the issue that generated images sometimes cannot capture the intended semantic contents of the text prompts, which phenomenon is often called semantic misalignment. To address this, here we present a novel energy-based model (EBM) framework. Specifically, we first formulate EBMs of latent image representations and text embeddings in each cross-attention layer of the denoising autoencoder. Then, we obtain the gradient of the log posterior of context vectors, which can be updated and transferred to the subsequent cross-attention layer, thereby implicitly minimizing a nested hierarchy of energy functions. Our latent EBMs further allow zero-shot compositional generation as a linear combination of cross-attention outputs from different contexts. Using extensive experiments, we demonstrate that the proposed method is highly effective in handling various image generation tasks, including multi-concept generation, text-guided image inpainting, and real and synthetic image editing.
CodeMark: Imperceptible Watermarking for Code Datasets against Neural Code Completion Models
Aug 28, 2023
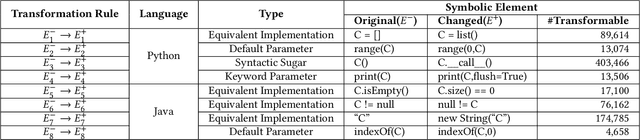
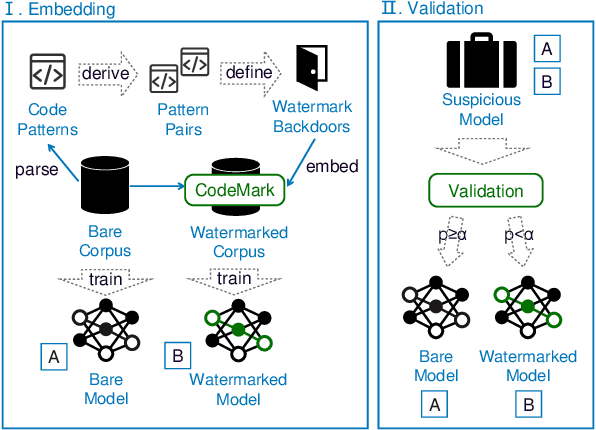
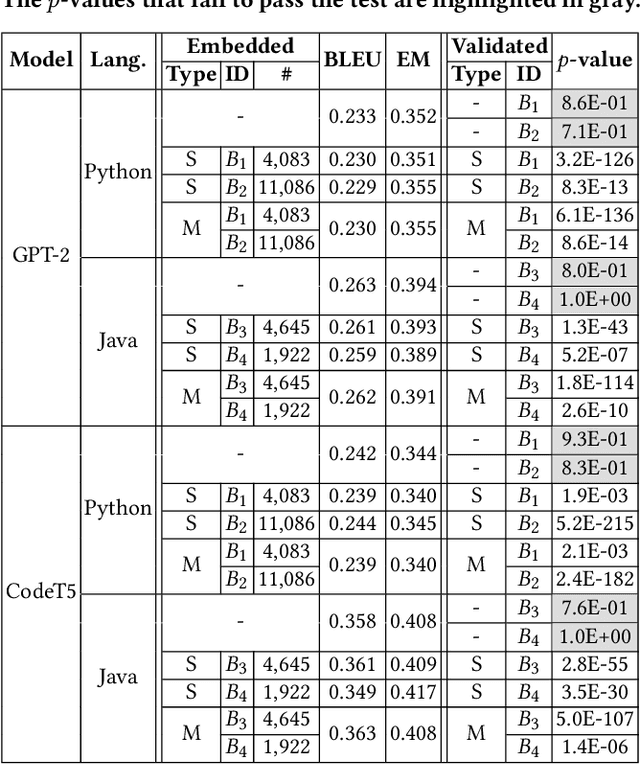
Code datasets are of immense value for training neural-network-based code completion models, where companies or organizations have made substantial investments to establish and process these datasets. Unluckily, these datasets, either built for proprietary or public usage, face the high risk of unauthorized exploits, resulting from data leakages, license violations, etc. Even worse, the ``black-box'' nature of neural models sets a high barrier for externals to audit their training datasets, which further connives these unauthorized usages. Currently, watermarking methods have been proposed to prohibit inappropriate usage of image and natural language datasets. However, due to domain specificity, they are not directly applicable to code datasets, leaving the copyright protection of this emerging and important field of code data still exposed to threats. To fill this gap, we propose a method, named CodeMark, to embed user-defined imperceptible watermarks into code datasets to trace their usage in training neural code completion models. CodeMark is based on adaptive semantic-preserving transformations, which preserve the exact functionality of the code data and keep the changes covert against rule-breakers. We implement CodeMark in a toolkit and conduct an extensive evaluation of code completion models. CodeMark is validated to fulfill all desired properties of practical watermarks, including harmlessness to model accuracy, verifiability, robustness, and imperceptibility.
HoloFusion: Towards Photo-realistic 3D Generative Modeling
Aug 28, 2023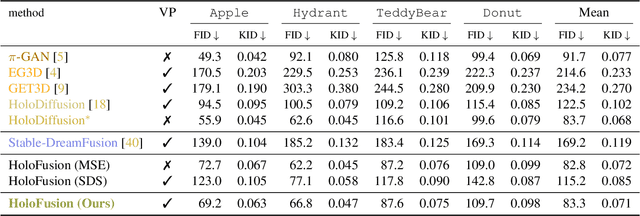
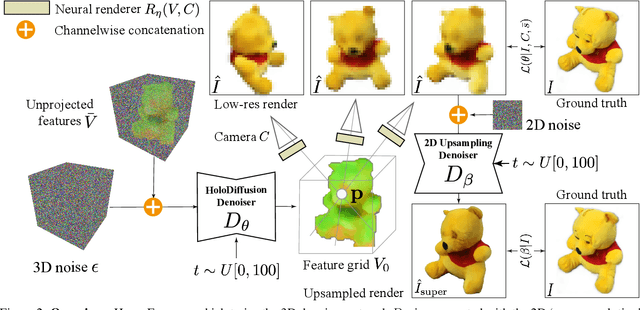
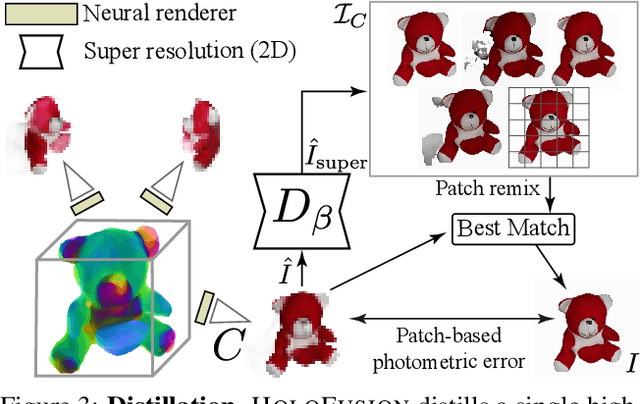

Diffusion-based image generators can now produce high-quality and diverse samples, but their success has yet to fully translate to 3D generation: existing diffusion methods can either generate low-resolution but 3D consistent outputs, or detailed 2D views of 3D objects but with potential structural defects and lacking view consistency or realism. We present HoloFusion, a method that combines the best of these approaches to produce high-fidelity, plausible, and diverse 3D samples while learning from a collection of multi-view 2D images only. The method first generates coarse 3D samples using a variant of the recently proposed HoloDiffusion generator. Then, it independently renders and upsamples a large number of views of the coarse 3D model, super-resolves them to add detail, and distills those into a single, high-fidelity implicit 3D representation, which also ensures view consistency of the final renders. The super-resolution network is trained as an integral part of HoloFusion, end-to-end, and the final distillation uses a new sampling scheme to capture the space of super-resolved signals. We compare our method against existing baselines, including DreamFusion, Get3D, EG3D, and HoloDiffusion, and achieve, to the best of our knowledge, the most realistic results on the challenging CO3Dv2 dataset.
NimbRo wins ANA Avatar XPRIZE Immersive Telepresence Competition: Human-Centric Evaluation and Lessons Learned
Aug 28, 2023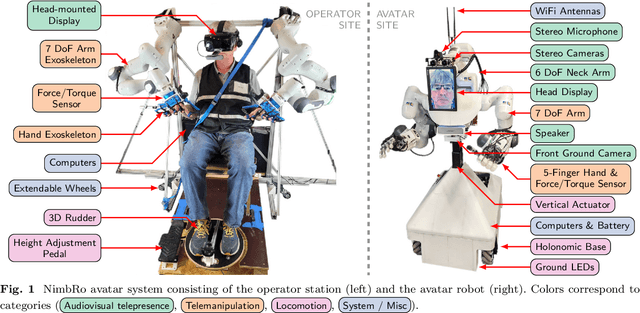


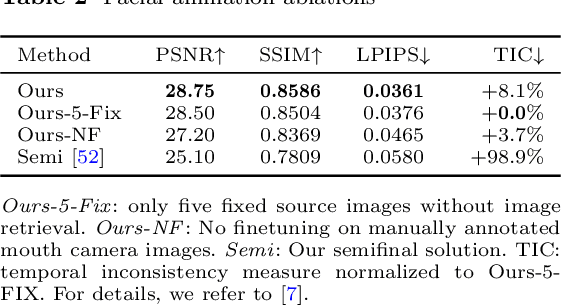
Robotic avatar systems can enable immersive telepresence with locomotion, manipulation, and communication capabilities. We present such an avatar system, based on the key components of immersive 3D visualization and transparent force-feedback telemanipulation. Our avatar robot features an anthropomorphic upper body with dexterous hands. The remote human operator drives the arms and fingers through an exoskeleton-based operator station, which provides force feedback both at the wrist and for each finger. The robot torso is mounted on a holonomic base, providing omnidirectional locomotion on flat floors, controlled using a 3D rudder device. Finally, the robot features a 6D movable head with stereo cameras, which stream images to a VR display worn by the operator. Movement latency is hidden using spherical rendering. The head also carries a telepresence screen displaying an animated image of the operator's face, enabling direct interaction with remote persons. Our system won the \$10M ANA Avatar XPRIZE competition, which challenged teams to develop intuitive and immersive avatar systems that could be operated by briefly trained judges. We analyze our successful participation in the semifinals and finals and provide insight into our operator training and lessons learned. In addition, we evaluate our system in a user study that demonstrates its intuitive and easy usability.