 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Few-shot Diagnosis of Chest x-rays Using an Ensemble of Random Discriminative Subspaces
Aug 31, 2023
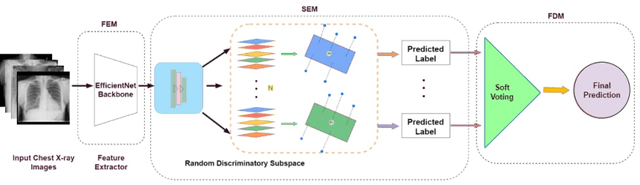
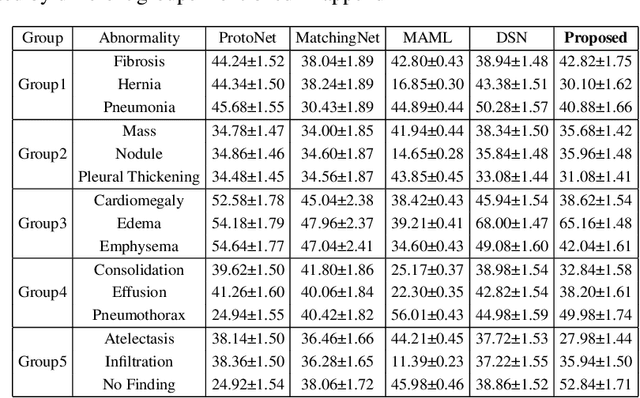
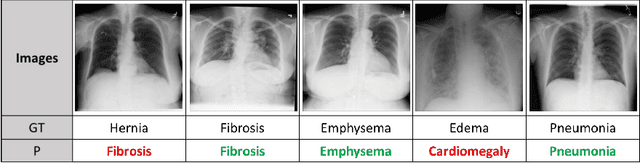

Due to the scarcity of annotated data in the medical domain, few-shot learning may be useful for medical image analysis tasks. We design a few-shot learning method using an ensemble of random subspaces for the diagnosis of chest x-rays (CXRs). Our design is computationally efficient and almost 1.8 times faster than method that uses the popular truncated singular value decomposition (t-SVD) for subspace decomposition. The proposed method is trained by minimizing a novel loss function that helps create well-separated clusters of training data in discriminative subspaces. As a result, minimizing the loss maximizes the distance between the subspaces, making them discriminative and assisting in better classification. Experiments on large-scale publicly available CXR datasets yield promising results. Code for the project will be available at https://github.com/Few-shot-Learning-on-chest-x-ray/fsl_subspace.
MVDream: Multi-view Diffusion for 3D Generation
Aug 31, 2023We propose MVDream, a multi-view diffusion model that is able to generate geometrically consistent multi-view images from a given text prompt. By leveraging image diffusion models pre-trained on large-scale web datasets and a multi-view dataset rendered from 3D assets, the resulting multi-view diffusion model can achieve both the generalizability of 2D diffusion and the consistency of 3D data. Such a model can thus be applied as a multi-view prior for 3D generation via Score Distillation Sampling, where it greatly improves the stability of existing 2D-lifting methods by solving the 3D consistency problem. Finally, we show that the multi-view diffusion model can also be fine-tuned under a few shot setting for personalized 3D generation, i.e. DreamBooth3D application, where the consistency can be maintained after learning the subject identity.
Unsupervised Prototype Adapter for Vision-Language Models
Aug 25, 2023Recently, large-scale pre-trained vision-language models (e.g. CLIP and ALIGN) have demonstrated remarkable effectiveness in acquiring transferable visual representations. To leverage the valuable knowledge encoded within these models for downstream tasks, several fine-tuning approaches, including prompt tuning methods and adapter-based methods, have been developed to adapt vision-language models effectively with supervision. However, these methods rely on the availability of annotated samples, which can be labor-intensive and time-consuming to acquire, thus limiting scalability. To address this issue, in this work, we design an unsupervised fine-tuning approach for vision-language models called Unsupervised Prototype Adapter (UP-Adapter). Specifically, for the unannotated target datasets, we leverage the text-image aligning capability of CLIP to automatically select the most confident samples for each class. Utilizing these selected samples, we generate class prototypes, which serve as the initialization for the learnable prototype model. After fine-tuning, the prototype model prediction is combined with the original CLIP's prediction by a residual connection to perform downstream recognition tasks. Our extensive experimental results on image recognition and domain generalization show that the proposed unsupervised method outperforms 8-shot CoOp, 8-shot Tip-Adapter, and also the state-of-the-art UPL method by large margins.
RRSIS: Referring Remote Sensing Image Segmentation
Jun 14, 2023
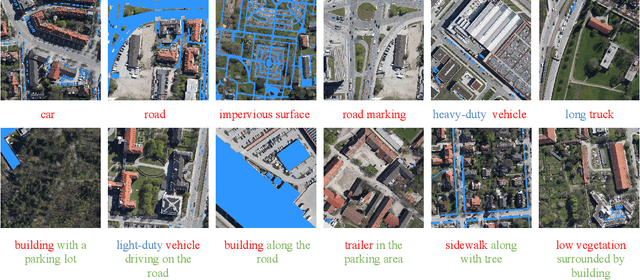

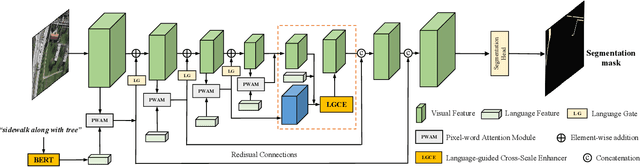
Localizing desired objects from remote sensing images is of great use in practical applications. Referring image segmentation, which aims at segmenting out the objects to which a given expression refers, has been extensively studied in natural images. However, almost no research attention is given to this task of remote sensing imagery. Considering its potential for real-world applications, in this paper, we introduce referring remote sensing image segmentation (RRSIS) to fill in this gap and make some insightful explorations. Specifically, we create a new dataset, called RefSegRS, for this task, enabling us to evaluate different methods. Afterward, we benchmark referring image segmentation methods of natural images on the RefSegRS dataset and find that these models show limited efficacy in detecting small and scattered objects. To alleviate this issue, we propose a language-guided cross-scale enhancement (LGCE) module that utilizes linguistic features to adaptively enhance multi-scale visual features by integrating both deep and shallow features. The proposed dataset, benchmarking results, and the designed LGCE module provide insights into the design of a better RRSIS model. We will make our dataset and code publicly available.
TouchStone: Evaluating Vision-Language Models by Language Models
Sep 04, 2023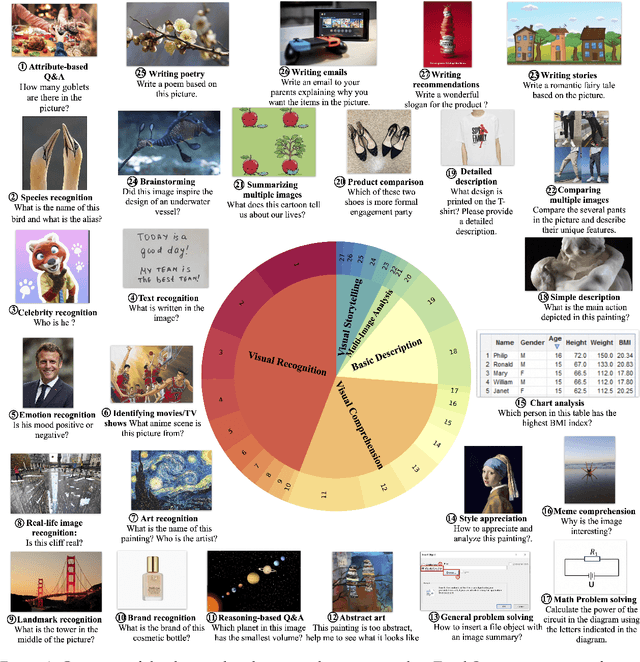


Large vision-language models (LVLMs) have recently witnessed rapid advancements, exhibiting a remarkable capacity for perceiving, understanding, and processing visual information by connecting visual receptor with large language models (LLMs). However, current assessments mainly focus on recognizing and reasoning abilities, lacking direct evaluation of conversational skills and neglecting visual storytelling abilities. In this paper, we propose an evaluation method that uses strong LLMs as judges to comprehensively evaluate the various abilities of LVLMs. Firstly, we construct a comprehensive visual dialogue dataset TouchStone, consisting of open-world images and questions, covering five major categories of abilities and 27 subtasks. This dataset not only covers fundamental recognition and comprehension but also extends to literary creation. Secondly, by integrating detailed image annotations we effectively transform the multimodal input content into a form understandable by LLMs. This enables us to employ advanced LLMs for directly evaluating the quality of the multimodal dialogue without requiring human intervention. Through validation, we demonstrate that powerful LVLMs, such as GPT-4, can effectively score dialogue quality by leveraging their textual capabilities alone, aligning with human preferences. We hope our work can serve as a touchstone for LVLMs' evaluation and pave the way for building stronger LVLMs. The evaluation code is available at https://github.com/OFA-Sys/TouchStone.
Boosting Semantic Segmentation from the Perspective of Explicit Class Embeddings
Aug 24, 2023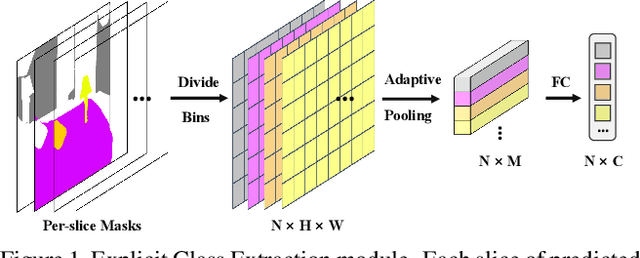
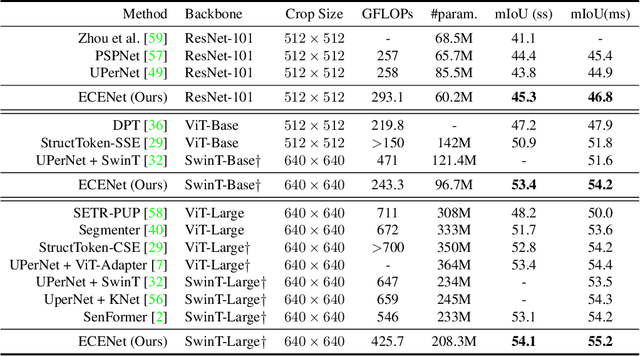
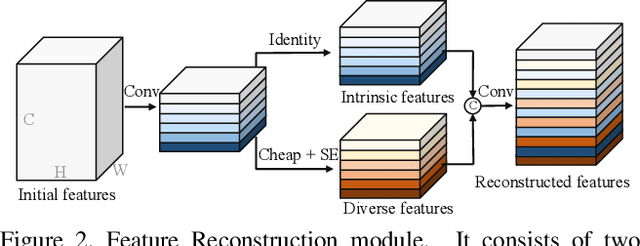
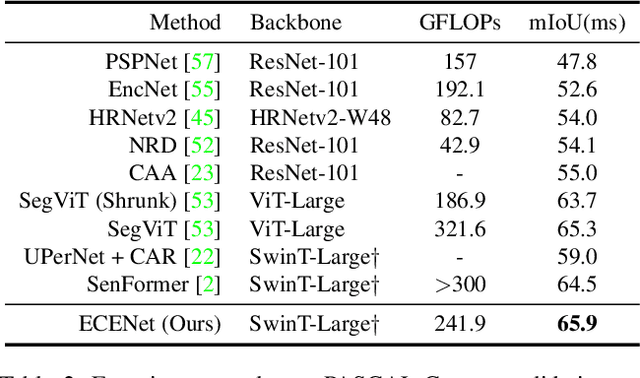
Semantic segmentation is a computer vision task that associates a label with each pixel in an image. Modern approaches tend to introduce class embeddings into semantic segmentation for deeply utilizing category semantics, and regard supervised class masks as final predictions. In this paper, we explore the mechanism of class embeddings and have an insight that more explicit and meaningful class embeddings can be generated based on class masks purposely. Following this observation, we propose ECENet, a new segmentation paradigm, in which class embeddings are obtained and enhanced explicitly during interacting with multi-stage image features. Based on this, we revisit the traditional decoding process and explore inverted information flow between segmentation masks and class embeddings. Furthermore, to ensure the discriminability and informativity of features from backbone, we propose a Feature Reconstruction module, which combines intrinsic and diverse branches together to ensure the concurrence of diversity and redundancy in features. Experiments show that our ECENet outperforms its counterparts on the ADE20K dataset with much less computational cost and achieves new state-of-the-art results on PASCAL-Context dataset. The code will be released at https://gitee.com/mindspore/models and https://github.com/Carol-lyh/ECENet.
Face Image Quality Enhancement Study for Face Recognition
Jul 08, 2023
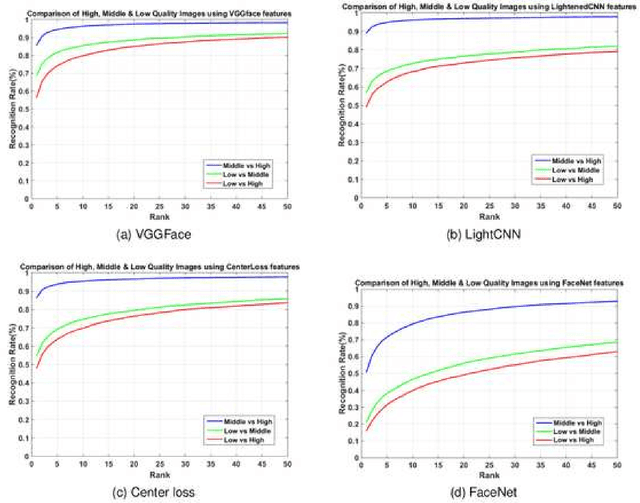
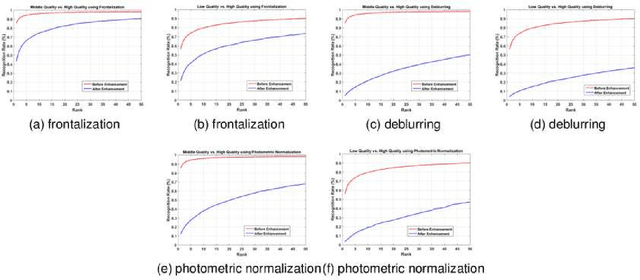
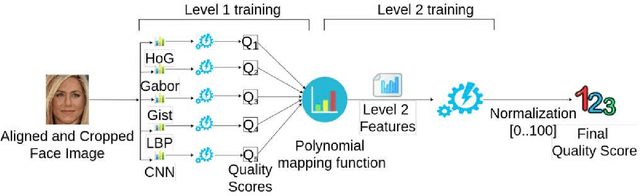
Unconstrained face recognition is an active research area among computer vision and biometric researchers for many years now. Still the problem of face recognition in low quality photos has not been well-studied so far. In this paper, we explore the face recognition performance on low quality photos, and we try to improve the accuracy in dealing with low quality face images. We assemble a large database with low quality photos, and examine the performance of face recognition algorithms for three different quality sets. Using state-of-the-art facial image enhancement approaches, we explore the face recognition performance for the enhanced face images. To perform this without experimental bias, we have developed a new protocol for recognition with low quality face photos and validate the performance experimentally. Our designed protocol for face recognition with low quality face images can be useful to other researchers. Moreover, experiment results show some of the challenging aspects of this problem.
Improving the Accuracy of Beauty Product Recommendations by Assessing Face Illumination Quality
Sep 07, 2023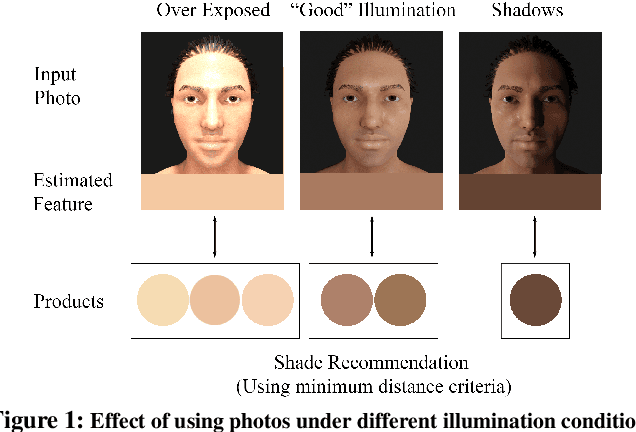
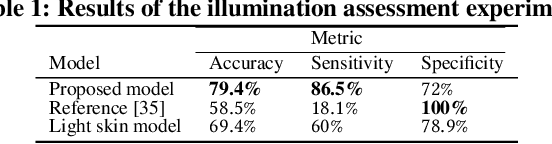
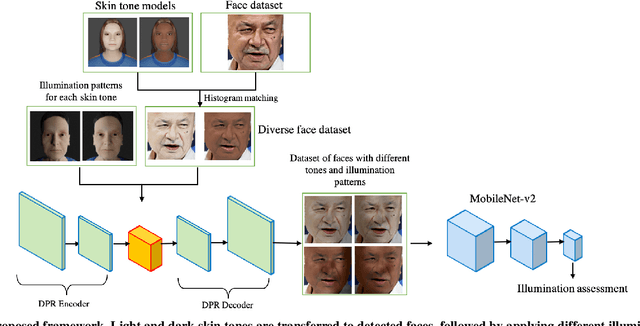
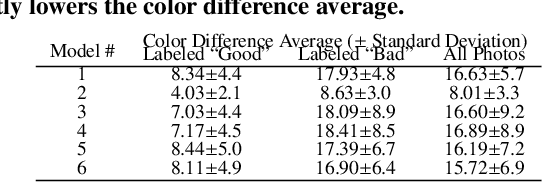
We focus on addressing the challenges in responsible beauty product recommendation, particularly when it involves comparing the product's color with a person's skin tone, such as for foundation and concealer products. To make accurate recommendations, it is crucial to infer both the product attributes and the product specific facial features such as skin conditions or tone. However, while many product photos are taken under good light conditions, face photos are taken from a wide range of conditions. The features extracted using the photos from ill-illuminated environment can be highly misleading or even be incompatible to be compared with the product attributes. Hence bad illumination condition can severely degrade quality of the recommendation. We introduce a machine learning framework for illumination assessment which classifies images into having either good or bad illumination condition. We then build an automatic user guidance tool which informs a user holding their camera if their illumination condition is good or bad. This way, the user is provided with rapid feedback and can interactively control how the photo is taken for their recommendation. Only a few studies are dedicated to this problem, mostly due to the lack of dataset that is large, labeled, and diverse both in terms of skin tones and light patterns. Lack of such dataset leads to neglecting skin tone diversity. Therefore, We begin by constructing a diverse synthetic dataset that simulates various skin tones and light patterns in addition to an existing facial image dataset. Next, we train a Convolutional Neural Network (CNN) for illumination assessment that outperforms the existing solutions using the synthetic dataset. Finally, we analyze how the our work improves the shade recommendation for various foundation products.
Orientation-Independent Chinese Text Recognition in Scene Images
Sep 03, 2023
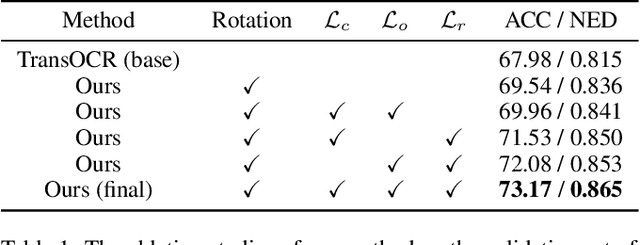
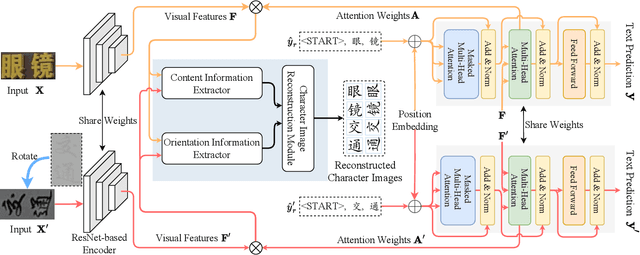
Scene text recognition (STR) has attracted much attention due to its broad applications. The previous works pay more attention to dealing with the recognition of Latin text images with complex backgrounds by introducing language models or other auxiliary networks. Different from Latin texts, many vertical Chinese texts exist in natural scenes, which brings difficulties to current state-of-the-art STR methods. In this paper, we take the first attempt to extract orientation-independent visual features by disentangling content and orientation information of text images, thus recognizing both horizontal and vertical texts robustly in natural scenes. Specifically, we introduce a Character Image Reconstruction Network (CIRN) to recover corresponding printed character images with disentangled content and orientation information. We conduct experiments on a scene dataset for benchmarking Chinese text recognition, and the results demonstrate that the proposed method can indeed improve performance through disentangling content and orientation information. To further validate the effectiveness of our method, we additionally collect a Vertical Chinese Text Recognition (VCTR) dataset. The experimental results show that the proposed method achieves 45.63% improvement on VCTR when introducing CIRN to the baseline model.
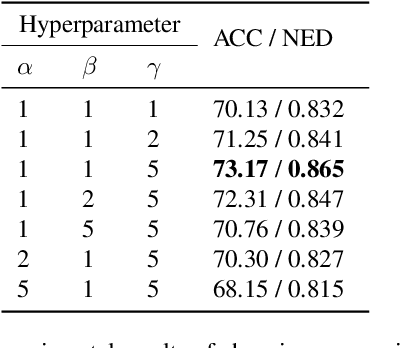
BDC-Adapter: Brownian Distance Covariance for Better Vision-Language Reasoning
Sep 03, 2023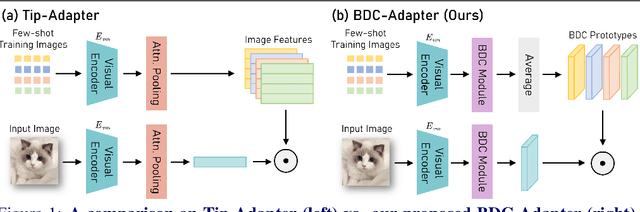
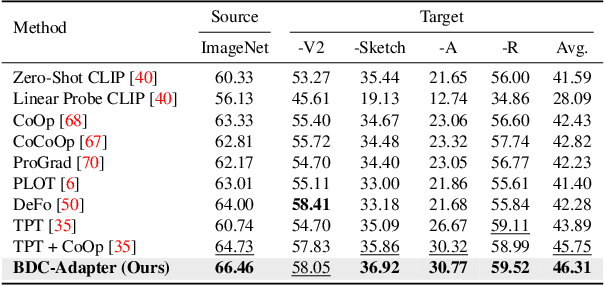
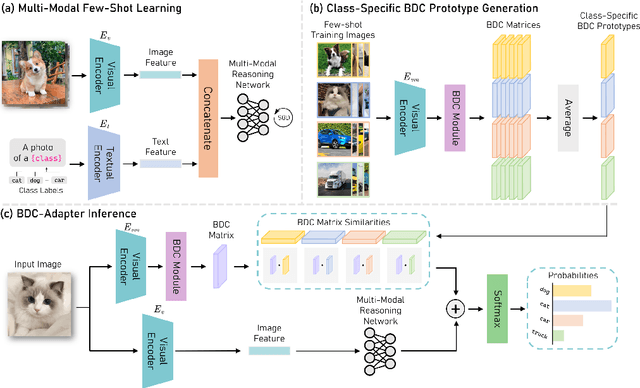
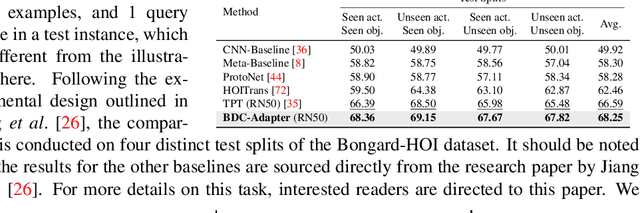
Large-scale pre-trained Vision-Language Models (VLMs), such as CLIP and ALIGN, have introduced a new paradigm for learning transferable visual representations. Recently, there has been a surge of interest among researchers in developing lightweight fine-tuning techniques to adapt these models to downstream visual tasks. We recognize that current state-of-the-art fine-tuning methods, such as Tip-Adapter, simply consider the covariance between the query image feature and features of support few-shot training samples, which only captures linear relations and potentially instigates a deceptive perception of independence. To address this issue, in this work, we innovatively introduce Brownian Distance Covariance (BDC) to the field of vision-language reasoning. The BDC metric can model all possible relations, providing a robust metric for measuring feature dependence. Based on this, we present a novel method called BDC-Adapter, which integrates BDC prototype similarity reasoning and multi-modal reasoning network prediction to perform classification tasks. Our extensive experimental results show that the proposed BDC-Adapter can freely handle non-linear relations and fully characterize independence, outperforming the current state-of-the-art methods by large margins.