 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Large AI Model Empowered Multimodal Semantic Communications
Sep 03, 2023
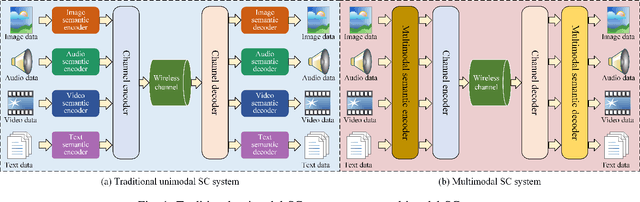
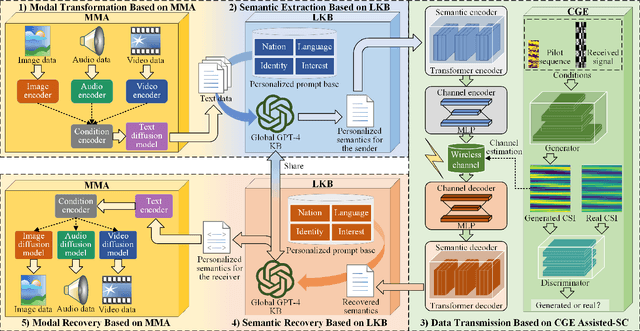
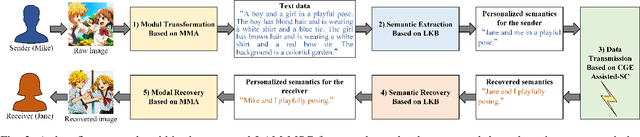
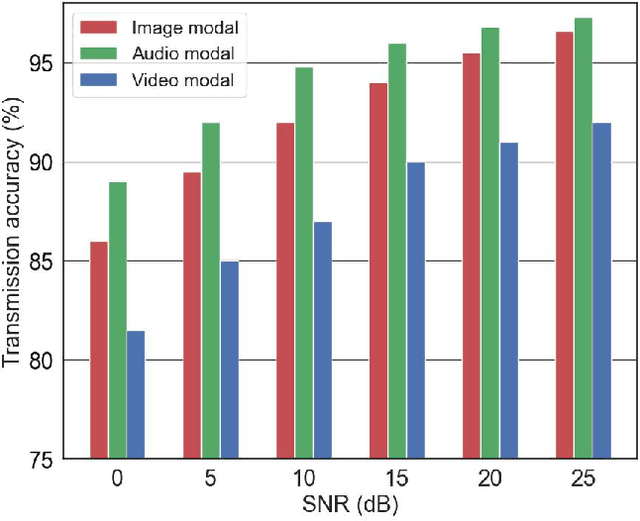
Multimodal signals, including text, audio, image and video, can be integrated into Semantic Communication (SC) for providing an immersive experience with low latency and high quality at the semantic level. However, the multimodal SC has several challenges, including data heterogeneity, semantic ambiguity, and signal fading. Recent advancements in large AI models, particularly in Multimodal Language Model (MLM) and Large Language Model (LLM), offer potential solutions for these issues. To this end, we propose a Large AI Model-based Multimodal SC (LAM-MSC) framework, in which we first present the MLM-based Multimodal Alignment (MMA) that utilizes the MLM to enable the transformation between multimodal and unimodal data while preserving semantic consistency. Then, a personalized LLM-based Knowledge Base (LKB) is proposed, which allows users to perform personalized semantic extraction or recovery through the LLM. This effectively addresses the semantic ambiguity. Finally, we apply the Conditional Generative adversarial networks-based channel Estimation (CGE) to obtain Channel State Information (CSI). This approach effectively mitigates the impact of fading channels in SC. Finally, we conduct simulations that demonstrate the superior performance of the LAM-MSC framework.
Hyperbolic Convolutional Neural Networks
Aug 29, 2023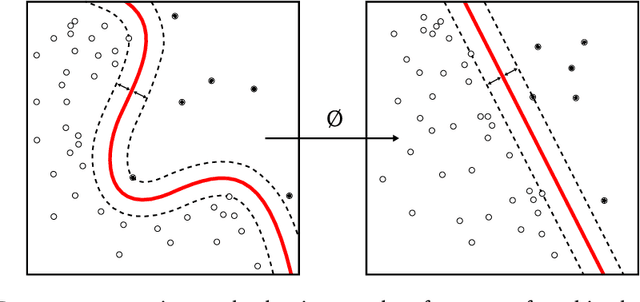
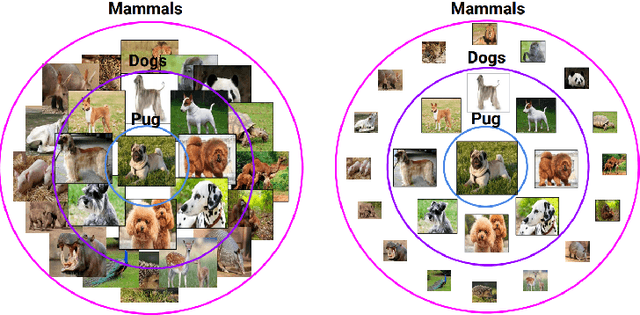
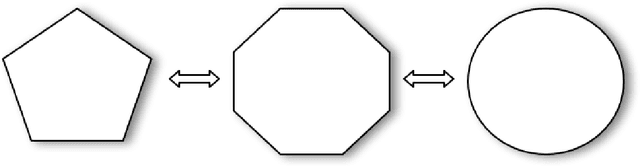
Deep Learning is mostly responsible for the surge of interest in Artificial Intelligence in the last decade. So far, deep learning researchers have been particularly successful in the domain of image processing, where Convolutional Neural Networks are used. Although excelling at image classification, Convolutional Neural Networks are quite naive in that no inductive bias is set on the embedding space for images. Similar flaws are also exhibited by another type of Convolutional Networks - Graph Convolutional Neural Networks. However, using non-Euclidean space for embedding data might result in more robust and explainable models. One example of such a non-Euclidean space is hyperbolic space. Hyperbolic spaces are particularly useful due to their ability to fit more data in a low-dimensional space and tree-likeliness properties. These attractive properties have been previously used in multiple papers which indicated that they are beneficial for building hierarchical embeddings using shallow models and, recently, using MLPs and RNNs. However, no papers have yet suggested a general approach to using Hyperbolic Convolutional Neural Networks for structured data processing, although these are the most common examples of data used. Therefore, the goal of this work is to devise a general recipe for building Hyperbolic Convolutional Neural Networks. We hypothesize that ability of hyperbolic space to capture hierarchy in the data would lead to better performance. This ability should be particularly useful in cases where data has a tree-like structure. Since this is the case for many existing datasets \citep{wordnet, imagenet, fb15k}, we argue that such a model would be advantageous both in terms of applications and future research prospects.
Turning a CLIP Model into a Scene Text Spotter
Aug 21, 2023
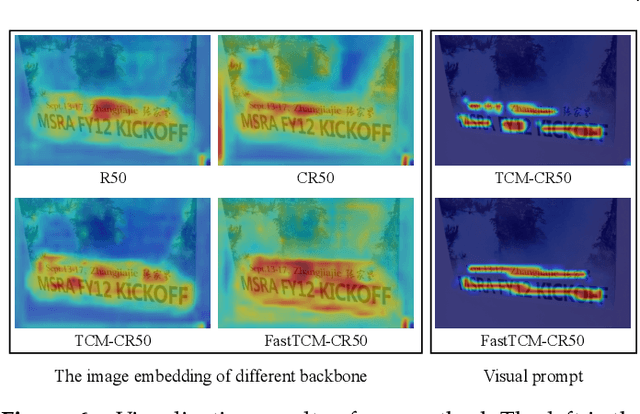
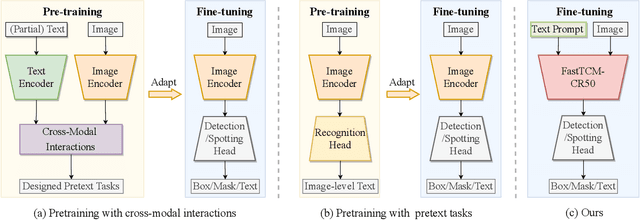
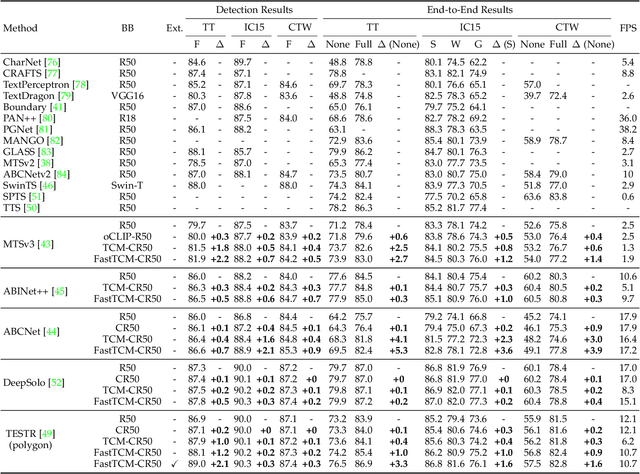
We exploit the potential of the large-scale Contrastive Language-Image Pretraining (CLIP) model to enhance scene text detection and spotting tasks, transforming it into a robust backbone, FastTCM-CR50. This backbone utilizes visual prompt learning and cross-attention in CLIP to extract image and text-based prior knowledge. Using predefined and learnable prompts, FastTCM-CR50 introduces an instance-language matching process to enhance the synergy between image and text embeddings, thereby refining text regions. Our Bimodal Similarity Matching (BSM) module facilitates dynamic language prompt generation, enabling offline computations and improving performance. FastTCM-CR50 offers several advantages: 1) It can enhance existing text detectors and spotters, improving performance by an average of 1.7% and 1.5%, respectively. 2) It outperforms the previous TCM-CR50 backbone, yielding an average improvement of 0.2% and 0.56% in text detection and spotting tasks, along with a 48.5% increase in inference speed. 3) It showcases robust few-shot training capabilities. Utilizing only 10% of the supervised data, FastTCM-CR50 improves performance by an average of 26.5% and 5.5% for text detection and spotting tasks, respectively. 4) It consistently enhances performance on out-of-distribution text detection and spotting datasets, particularly the NightTime-ArT subset from ICDAR2019-ArT and the DOTA dataset for oriented object detection. The code is available at https://github.com/wenwenyu/TCM.
SoccerNet 2023 Tracking Challenge -- 3rd place MOT4MOT Team Technical Report
Aug 31, 2023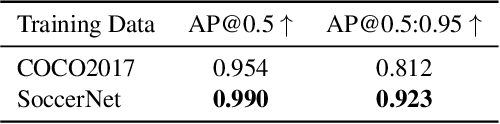
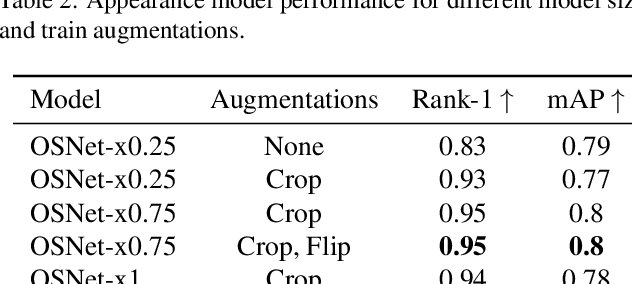
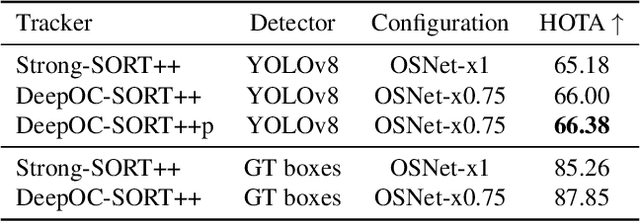
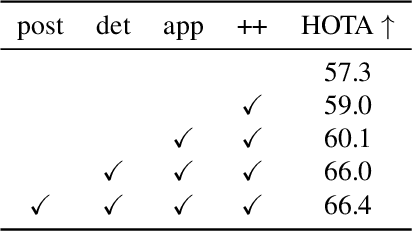
The SoccerNet 2023 tracking challenge requires the detection and tracking of soccer players and the ball. In this work, we present our approach to tackle these tasks separately. We employ a state-of-the-art online multi-object tracker and a contemporary object detector for player tracking. To overcome the limitations of our online approach, we incorporate a post-processing stage using interpolation and appearance-free track merging. Additionally, an appearance-based track merging technique is used to handle the termination and creation of tracks far from the image boundaries. Ball tracking is formulated as single object detection, and a fine-tuned YOLOv8l detector with proprietary filtering improves the detection precision. Our method achieves 3rd place on the SoccerNet 2023 tracking challenge with a HOTA score of 66.27.
Unpaired Image-to-Image Translation via Neural Schrödinger Bridge
May 24, 2023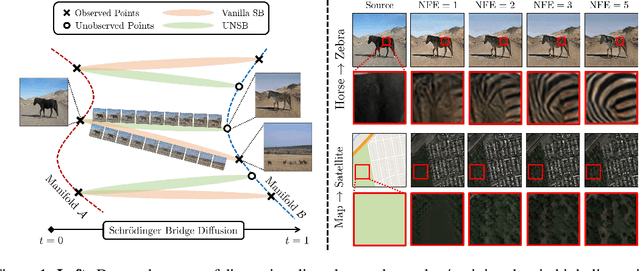
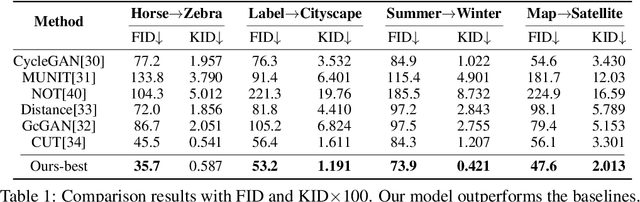
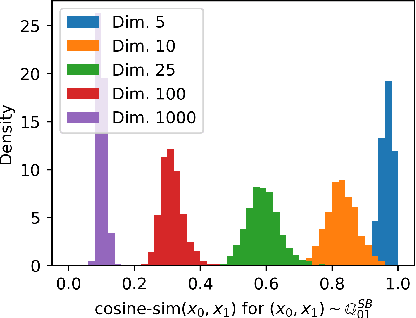
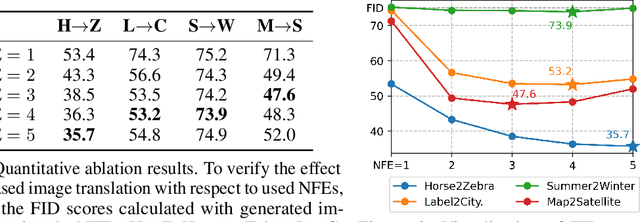
Diffusion models are a powerful class of generative models which simulate stochastic differential equations (SDEs) to generate data from noise. Although diffusion models have achieved remarkable progress in recent years, they have limitations in the unpaired image-to-image translation tasks due to the Gaussian prior assumption. Schr\"odinger Bridge (SB), which learns an SDE to translate between two arbitrary distributions, have risen as an attractive solution to this problem. However, none of SB models so far have been successful at unpaired translation between high-resolution images. In this work, we propose the Unpaired Neural Schr\"odinger Bridge (UNSB), which combines SB with adversarial training and regularization to learn a SB between unpaired data. We demonstrate that UNSB is scalable, and that it successfully solves various unpaired image-to-image translation tasks. Code: \url{https://github.com/cyclomon/UNSB}
Robustified ANNs Reveal Wormholes Between Human Category Percepts
Aug 14, 2023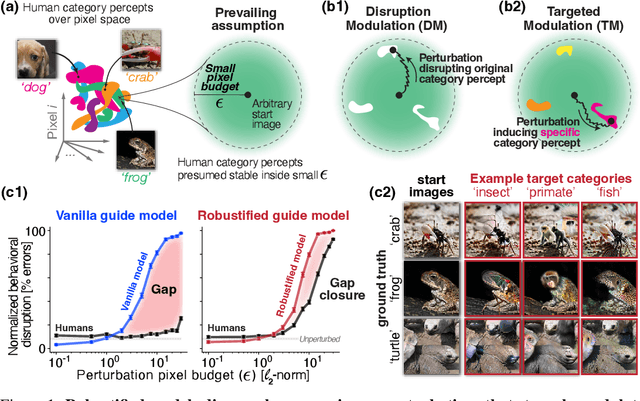
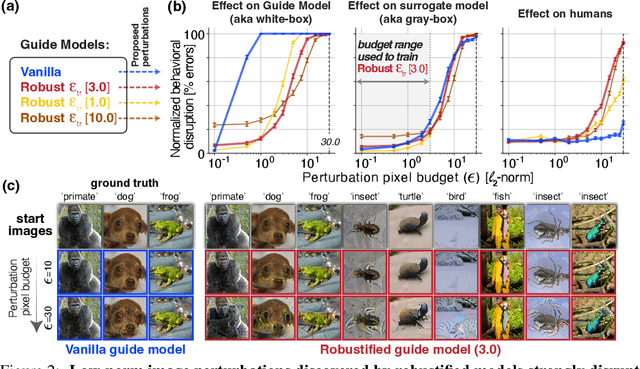
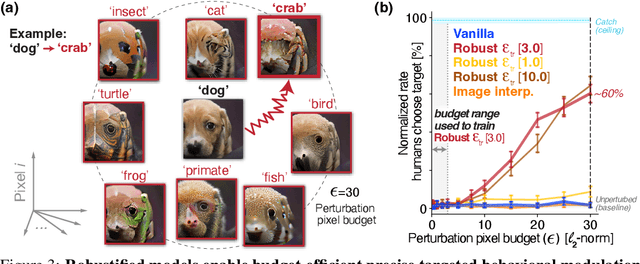
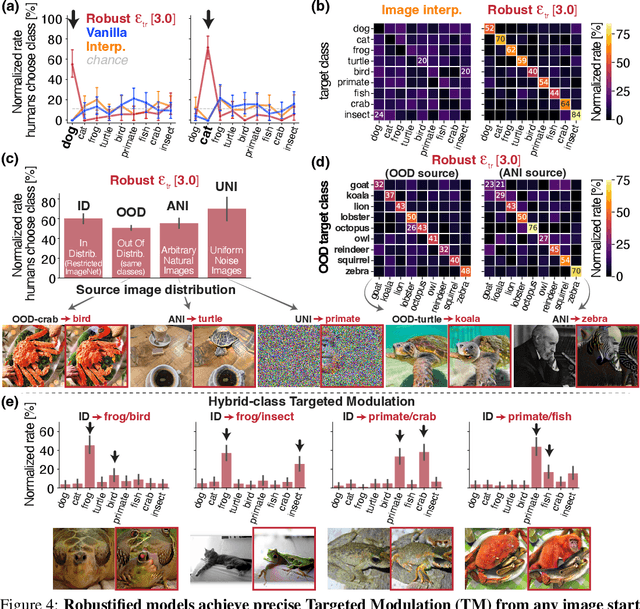
The visual object category reports of artificial neural networks (ANNs) are notoriously sensitive to tiny, adversarial image perturbations. Because human category reports (aka human percepts) are thought to be insensitive to those same small-norm perturbations -- and locally stable in general -- this argues that ANNs are incomplete scientific models of human visual perception. Consistent with this, we show that when small-norm image perturbations are generated by standard ANN models, human object category percepts are indeed highly stable. However, in this very same "human-presumed-stable" regime, we find that robustified ANNs reliably discover low-norm image perturbations that strongly disrupt human percepts. These previously undetectable human perceptual disruptions are massive in amplitude, approaching the same level of sensitivity seen in robustified ANNs. Further, we show that robustified ANNs support precise perceptual state interventions: they guide the construction of low-norm image perturbations that strongly alter human category percepts toward specific prescribed percepts. These observations suggest that for arbitrary starting points in image space, there exists a set of nearby "wormholes", each leading the subject from their current category perceptual state into a semantically very different state. Moreover, contemporary ANN models of biological visual processing are now accurate enough to consistently guide us to those portals.
Improved Flood Insights: Diffusion-Based SAR to EO Image Translation
Jul 14, 2023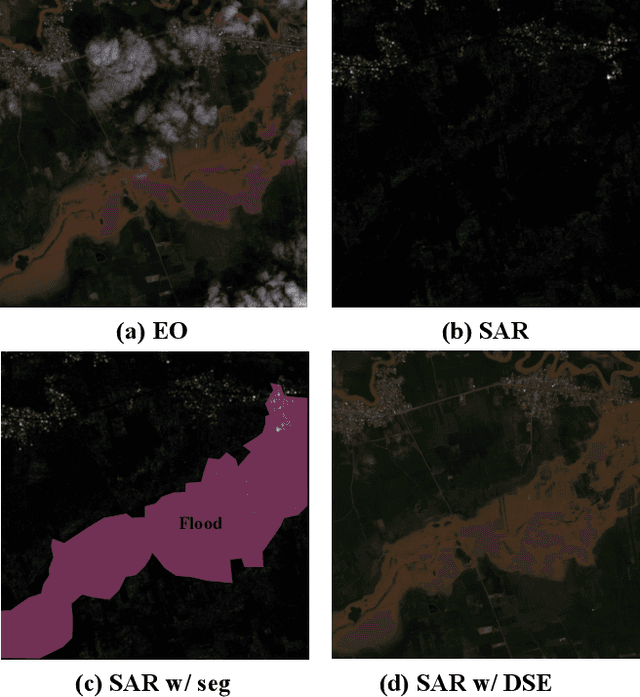
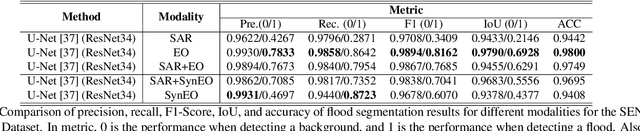
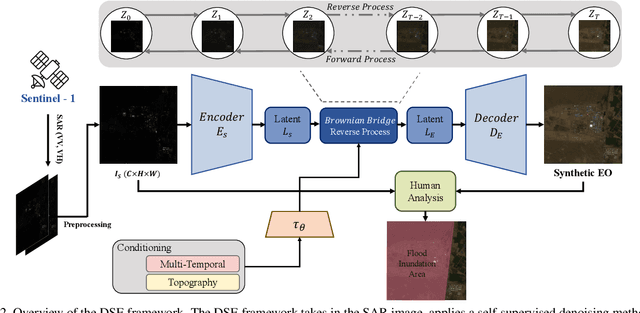
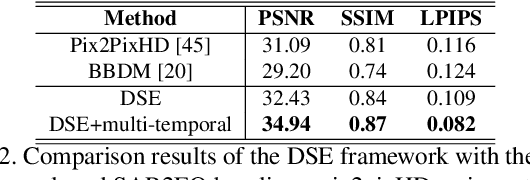
Driven by rapid climate change, the frequency and intensity of flood events are increasing. Electro-Optical (EO) satellite imagery is commonly utilized for rapid response. However, its utilities in flood situations are hampered by issues such as cloud cover and limitations during nighttime, making accurate assessment of damage challenging. Several alternative flood detection techniques utilizing Synthetic Aperture Radar (SAR) data have been proposed. Despite the advantages of SAR over EO in the aforementioned situations, SAR presents a distinct drawback: human analysts often struggle with data interpretation. To tackle this issue, this paper introduces a novel framework, Diffusion-Based SAR to EO Image Translation (DSE). The DSE framework converts SAR images into EO images, thereby enhancing the interpretability of flood insights for humans. Experimental results on the Sen1Floods11 and SEN12-FLOOD datasets confirm that the DSE framework not only delivers enhanced visual information but also improves performance across all tested flood segmentation baselines.
Probabilistic and Semantic Descriptions of Image Manifolds and Their Applications
Jul 10, 2023

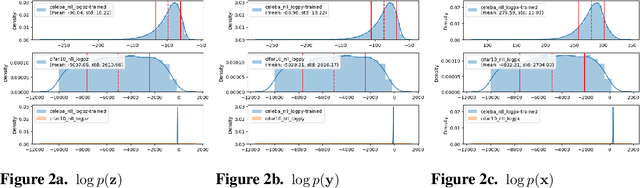

This paper begins with a description of methods for estimating probability density functions for images that reflects the observation that such data is usually constrained to lie in restricted regions of the high-dimensional image space - not every pattern of pixels is an image. It is common to say that images lie on a lower-dimensional manifold in the high-dimensional space. However, although images may lie on such lower-dimensional manifolds, it is not the case that all points on the manifold have an equal probability of being images. Images are unevenly distributed on the manifold, and our task is to devise ways to model this distribution as a probability distribution. In pursuing this goal, we consider generative models that are popular in AI and computer vision community. For our purposes, generative/probabilistic models should have the properties of 1) sample generation: it should be possible to sample from this distribution according to the modelled density function, and 2) probability computation: given a previously unseen sample from the dataset of interest, one should be able to compute the probability of the sample, at least up to a normalising constant. To this end, we investigate the use of methods such as normalising flow and diffusion models. We then show that such probabilistic descriptions can be used to construct defences against adversarial attacks. In addition to describing the manifold in terms of density, we also consider how semantic interpretations can be used to describe points on the manifold. To this end, we consider an emergent language framework which makes use of variational encoders to produce a disentangled representation of points that reside on a given manifold. Trajectories between points on a manifold can then be described in terms of evolving semantic descriptions.
Deep image prior inpainting of ancient frescoes in the Mediterranean Alpine arc
Jun 25, 2023

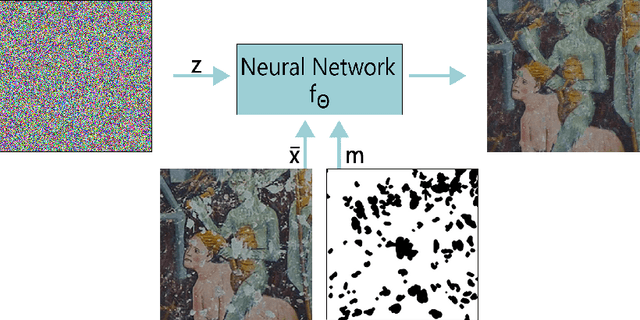
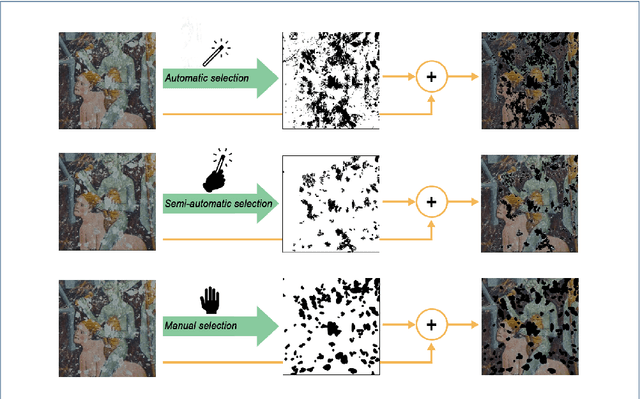
The unprecedented success of image reconstruction approaches based on deep neural networks has revolutionised both the processing and the analysis paradigms in several applied disciplines. In the field of digital humanities, the task of digital reconstruction of ancient frescoes is particularly challenging due to the scarce amount of available training data caused by ageing, wear, tear and retouching over time. To overcome these difficulties, we consider the Deep Image Prior (DIP) inpainting approach which computes appropriate reconstructions by relying on the progressive updating of an untrained convolutional neural network so as to match the reliable piece of information in the image at hand while promoting regularisation elsewhere. In comparison with state-of-the-art approaches (based on variational/PDEs and patch-based methods), DIP-based inpainting reduces artefacts and better adapts to contextual/non-local information, thus providing a valuable and effective tool for art historians. As a case study, we apply such approach to reconstruct missing image contents in a dataset of highly damaged digital images of medieval paintings located into several chapels in the Mediterranean Alpine Arc and provide a detailed description on how visible and invisible (e.g., infrared) information can be integrated for identifying and reconstructing damaged image regions.
Spatiotemporal Modeling Encounters 3D Medical Image Analysis: Slice-Shift UNet with Multi-View Fusion
Jul 24, 2023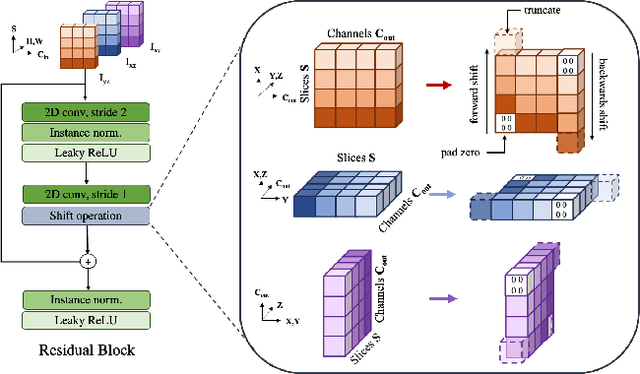

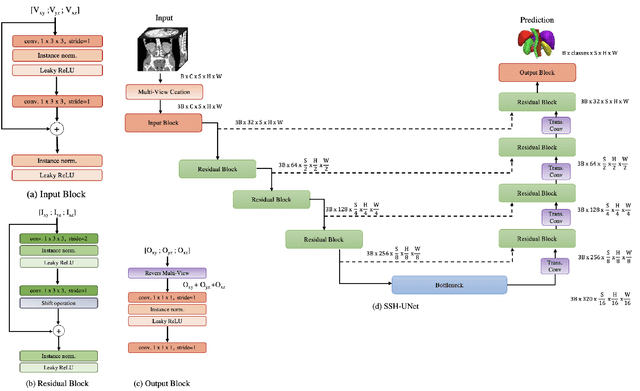

As a fundamental part of computational healthcare, Computer Tomography (CT) and Magnetic Resonance Imaging (MRI) provide volumetric data, making the development of algorithms for 3D image analysis a necessity. Despite being computationally cheap, 2D Convolutional Neural Networks can only extract spatial information. In contrast, 3D CNNs can extract three-dimensional features, but they have higher computational costs and latency, which is a limitation for clinical practice that requires fast and efficient models. Inspired by the field of video action recognition we propose a new 2D-based model dubbed Slice SHift UNet (SSH-UNet) which encodes three-dimensional features at 2D CNN's complexity. More precisely multi-view features are collaboratively learned by performing 2D convolutions along the three orthogonal planes of a volume and imposing a weights-sharing mechanism. The third dimension, which is neglected by the 2D convolution, is reincorporated by shifting a portion of the feature maps along the slices' axis. The effectiveness of our approach is validated in Multi-Modality Abdominal Multi-Organ Segmentation (AMOS) and Multi-Atlas Labeling Beyond the Cranial Vault (BTCV) datasets, showing that SSH-UNet is more efficient while on par in performance with state-of-the-art architectures.