 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Progressive Attention Guidance for Whole Slide Vulvovaginal Candidiasis Screening
Sep 06, 2023
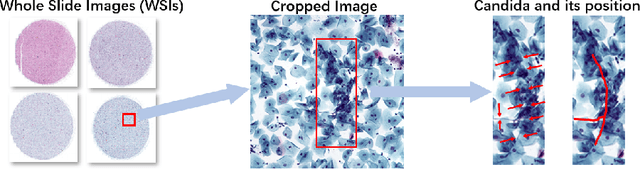
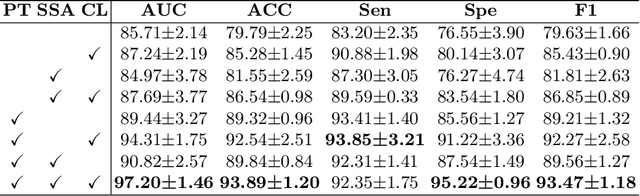
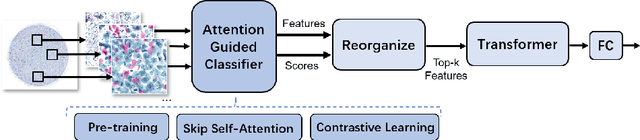
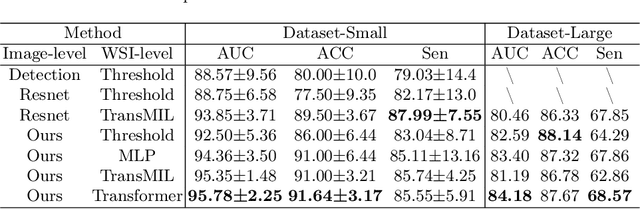
Vulvovaginal candidiasis (VVC) is the most prevalent human candidal infection, estimated to afflict approximately 75% of all women at least once in their lifetime. It will lead to several symptoms including pruritus, vaginal soreness, and so on. Automatic whole slide image (WSI) classification is highly demanded, for the huge burden of disease control and prevention. However, the WSI-based computer-aided VCC screening method is still vacant due to the scarce labeled data and unique properties of candida. Candida in WSI is challenging to be captured by conventional classification models due to its distinctive elongated shape, the small proportion of their spatial distribution, and the style gap from WSIs. To make the model focus on the candida easier, we propose an attention-guided method, which can obtain a robust diagnosis classification model. Specifically, we first use a pre-trained detection model as prior instruction to initialize the classification model. Then we design a Skip Self-Attention module to refine the attention onto the fined-grained features of candida. Finally, we use a contrastive learning method to alleviate the overfitting caused by the style gap of WSIs and suppress the attention to false positive regions. Our experimental results demonstrate that our framework achieves state-of-the-art performance. Code and example data are available at https://github.com/cjdbehumble/MICCAI2023-VVC-Screening.
* Accepted in the main conference MICCAI 2023
Multiclass Alignment of Confidence and Certainty for Network Calibration
Sep 06, 2023Deep neural networks (DNNs) have made great strides in pushing the state-of-the-art in several challenging domains. Recent studies reveal that they are prone to making overconfident predictions. This greatly reduces the overall trust in model predictions, especially in safety-critical applications. Early work in improving model calibration employs post-processing techniques which rely on limited parameters and require a hold-out set. Some recent train-time calibration methods, which involve all model parameters, can outperform the postprocessing methods. To this end, we propose a new train-time calibration method, which features a simple, plug-and-play auxiliary loss known as multi-class alignment of predictive mean confidence and predictive certainty (MACC). It is based on the observation that a model miscalibration is directly related to its predictive certainty, so a higher gap between the mean confidence and certainty amounts to a poor calibration both for in-distribution and out-of-distribution predictions. Armed with this insight, our proposed loss explicitly encourages a confident (or underconfident) model to also provide a low (or high) spread in the presoftmax distribution. Extensive experiments on ten challenging datasets, covering in-domain, out-domain, non-visual recognition and medical image classification scenarios, show that our method achieves state-of-the-art calibration performance for both in-domain and out-domain predictions. Our code and models will be publicly released.
End-to-end Alternating Optimization for Real-World Blind Super Resolution
Aug 17, 2023Blind Super-Resolution (SR) usually involves two sub-problems: 1) estimating the degradation of the given low-resolution (LR) image; 2) super-resolving the LR image to its high-resolution (HR) counterpart. Both problems are ill-posed due to the information loss in the degrading process. Most previous methods try to solve the two problems independently, but often fall into a dilemma: a good super-resolved HR result requires an accurate degradation estimation, which however, is difficult to be obtained without the help of original HR information. To address this issue, instead of considering these two problems independently, we adopt an alternating optimization algorithm, which can estimate the degradation and restore the SR image in a single model. Specifically, we design two convolutional neural modules, namely \textit{Restorer} and \textit{Estimator}. \textit{Restorer} restores the SR image based on the estimated degradation, and \textit{Estimator} estimates the degradation with the help of the restored SR image. We alternate these two modules repeatedly and unfold this process to form an end-to-end trainable network. In this way, both \textit{Restorer} and \textit{Estimator} could get benefited from the intermediate results of each other, and make each sub-problem easier. Moreover, \textit{Restorer} and \textit{Estimator} are optimized in an end-to-end manner, thus they could get more tolerant of the estimation deviations of each other and cooperate better to achieve more robust and accurate final results. Extensive experiments on both synthetic datasets and real-world images show that the proposed method can largely outperform state-of-the-art methods and produce more visually favorable results. The codes are rleased at \url{https://github.com/greatlog/RealDAN.git}.
* Extension of our previous NeurIPS paper. Accepted to IJCV
CGAM: Click-Guided Attention Module for Interactive Pathology Image Segmentation via Backpropagating Refinement
Jul 03, 2023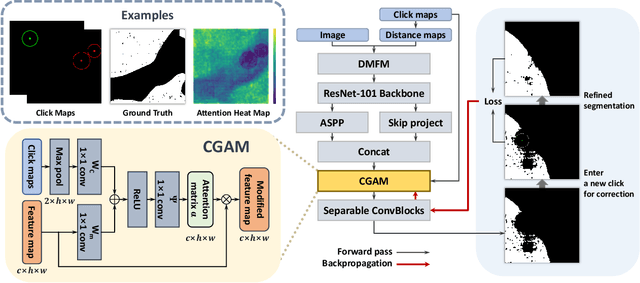

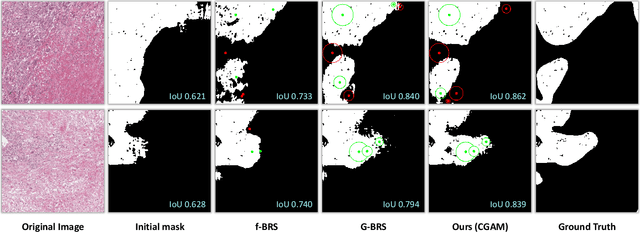
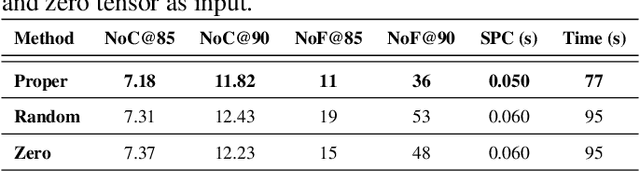
Tumor region segmentation is an essential task for the quantitative analysis of digital pathology. Recently presented deep neural networks have shown state-of-the-art performance in various image-segmentation tasks. However, because of the unclear boundary between the cancerous and normal regions in pathology images, despite using modern methods, it is difficult to produce satisfactory segmentation results in terms of the reliability and accuracy required for medical data. In this study, we propose an interactive segmentation method that allows users to refine the output of deep neural networks through click-type user interactions. The primary method is to formulate interactive segmentation as an optimization problem that leverages both user-provided click constraints and semantic information in a feature map using a click-guided attention module (CGAM). Unlike other existing methods, CGAM avoids excessive changes in segmentation results, which can lead to the overfitting of user clicks. Another advantage of CGAM is that the model size is independent of input image size. Experimental results on pathology image datasets indicated that our method performs better than existing state-of-the-art methods.
A Unified Transformer-based Network for multimodal Emotion Recognition
Aug 27, 2023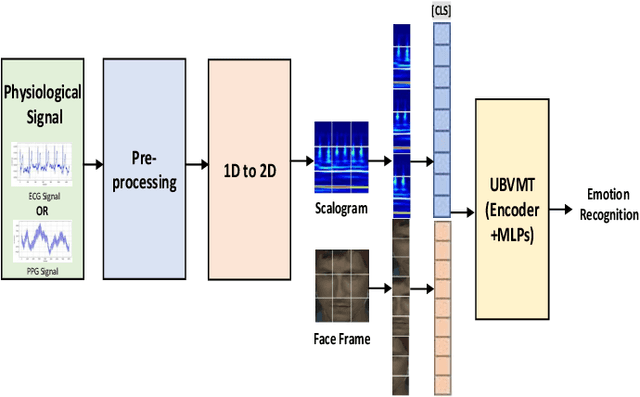

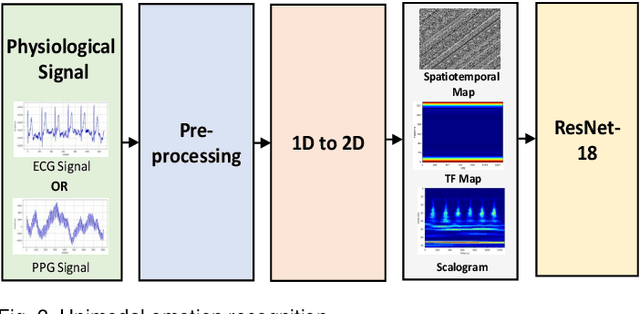
The development of transformer-based models has resulted in significant advances in addressing various vision and NLP-based research challenges. However, the progress made in transformer-based methods has not been effectively applied to biosensing research. This paper presents a novel Unified Biosensor-Vision Multi-modal Transformer-based (UBVMT) method to classify emotions in an arousal-valence space by combining a 2D representation of an ECG/PPG signal with the face information. To achieve this goal, we first investigate and compare the unimodal emotion recognition performance of three image-based representations of the ECG/PPG signal. We then present our UBVMT network which is trained to perform emotion recognition by combining the 2D image-based representation of the ECG/PPG signal and the facial expression features. Our unified transformer model consists of homogeneous transformer blocks that take as an input the 2D representation of the ECG/PPG signal and the corresponding face frame for emotion representation learning with minimal modality-specific design. Our UBVMT model is trained by reconstructing masked patches of video frames and 2D images of ECG/PPG signals, and contrastive modeling to align face and ECG/PPG data. Extensive experiments on the MAHNOB-HCI and DEAP datasets show that our Unified UBVMT-based model produces comparable results to the state-of-the-art techniques.
Joint Hierarchical Priors and Adaptive Spatial Resolution for Efficient Neural Image Compression
Jul 05, 2023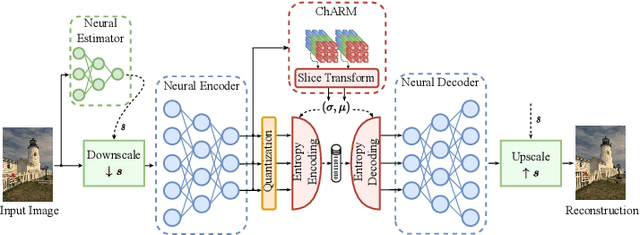
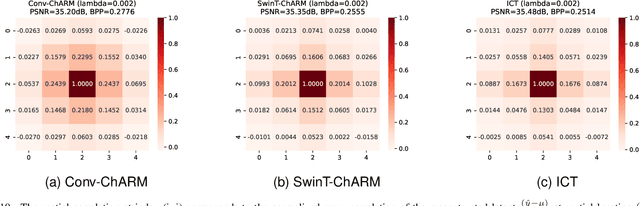

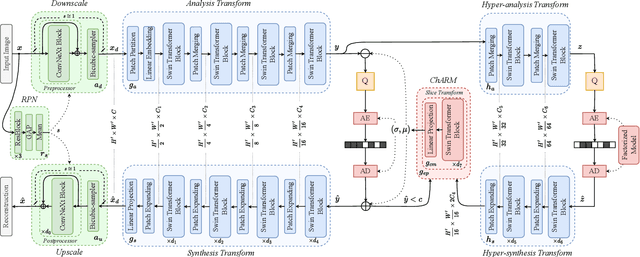
Recently, the performance of neural image compression (NIC) has steadily improved thanks to the last line of study, reaching or outperforming state-of-the-art conventional codecs. Despite significant progress, current NIC methods still rely on ConvNet-based entropy coding, limited in modeling long-range dependencies due to their local connectivity and the increasing number of architectural biases and priors, resulting in complex underperforming models with high decoding latency. Motivated by the efficiency investigation of the Tranformer-based transform coding framework, namely SwinT-ChARM, we propose to enhance the latter, as first, with a more straightforward yet effective Tranformer-based channel-wise auto-regressive prior model, resulting in an absolute image compression transformer (ICT). Through the proposed ICT, we can capture both global and local contexts from the latent representations and better parameterize the distribution of the quantized latents. Further, we leverage a learnable scaling module with a sandwich ConvNeXt-based pre-/post-processor to accurately extract more compact latent codes while reconstructing higher-quality images. Extensive experimental results on benchmark datasets showed that the proposed framework significantly improves the trade-off between coding efficiency and decoder complexity over the versatile video coding (VVC) reference encoder (VTM-18.0) and the neural codec SwinT-ChARM. Moreover, we provide model scaling studies to verify the computational efficiency of our approach and conduct several objective and subjective analyses to bring to the fore the performance gap between the adaptive image compression transformer (AICT) and the neural codec SwinT-ChARM.
Point-Bind & Point-LLM: Aligning Point Cloud with Multi-modality for 3D Understanding, Generation, and Instruction Following
Sep 01, 2023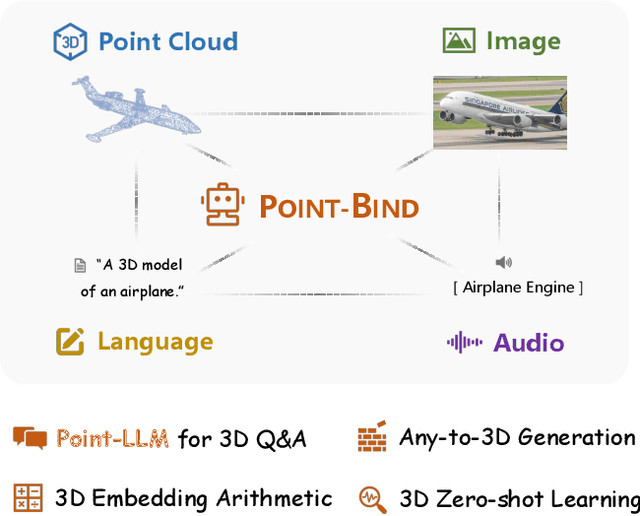
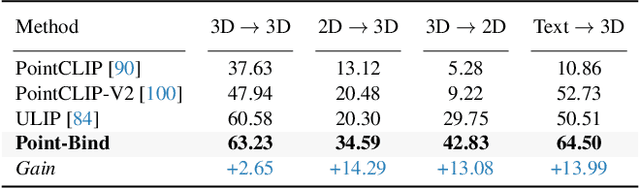
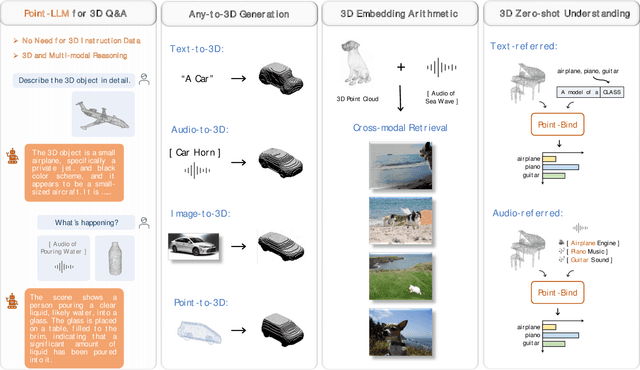
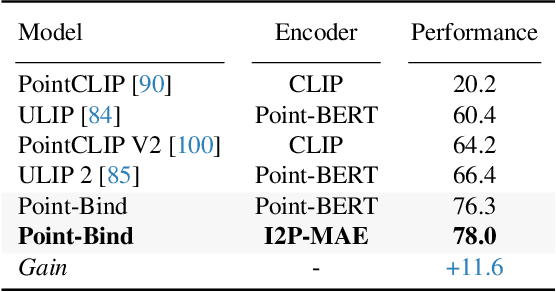
We introduce Point-Bind, a 3D multi-modality model aligning point clouds with 2D image, language, audio, and video. Guided by ImageBind, we construct a joint embedding space between 3D and multi-modalities, enabling many promising applications, e.g., any-to-3D generation, 3D embedding arithmetic, and 3D open-world understanding. On top of this, we further present Point-LLM, the first 3D large language model (LLM) following 3D multi-modal instructions. By parameter-efficient fine-tuning techniques, Point-LLM injects the semantics of Point-Bind into pre-trained LLMs, e.g., LLaMA, which requires no 3D instruction data, but exhibits superior 3D and multi-modal question-answering capacity. We hope our work may cast a light on the community for extending 3D point clouds to multi-modality applications. Code is available at https://github.com/ZiyuGuo99/Point-Bind_Point-LLM.
VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection
Aug 22, 2023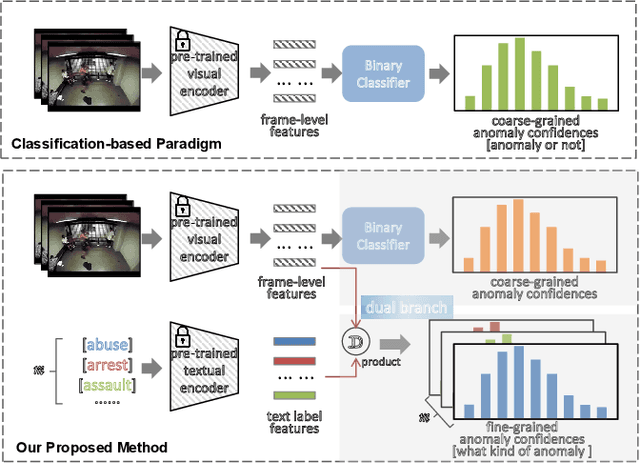
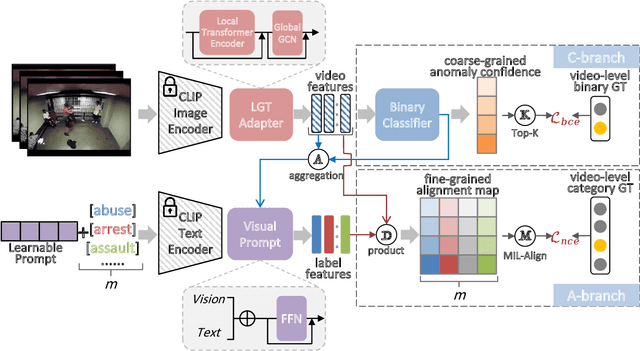

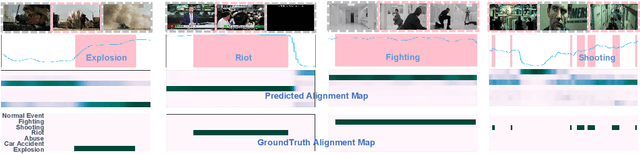
The recent contrastive language-image pre-training (CLIP) model has shown great success in a wide range of image-level tasks, revealing remarkable ability for learning powerful visual representations with rich semantics. An open and worthwhile problem is efficiently adapting such a strong model to the video domain and designing a robust video anomaly detector. In this work, we propose VadCLIP, a new paradigm for weakly supervised video anomaly detection (WSVAD) by leveraging the frozen CLIP model directly without any pre-training and fine-tuning process. Unlike current works that directly feed extracted features into the weakly supervised classifier for frame-level binary classification, VadCLIP makes full use of fine-grained associations between vision and language on the strength of CLIP and involves dual branch. One branch simply utilizes visual features for coarse-grained binary classification, while the other fully leverages the fine-grained language-image alignment. With the benefit of dual branch, VadCLIP achieves both coarse-grained and fine-grained video anomaly detection by transferring pre-trained knowledge from CLIP to WSVAD task. We conduct extensive experiments on two commonly-used benchmarks, demonstrating that VadCLIP achieves the best performance on both coarse-grained and fine-grained WSVAD, surpassing the state-of-the-art methods by a large margin. Specifically, VadCLIP achieves 84.51% AP and 88.02% AUC on XD-Violence and UCF-Crime, respectively. Code and features will be released to facilitate future VAD research.
Physically Grounded Vision-Language Models for Robotic Manipulation
Sep 05, 2023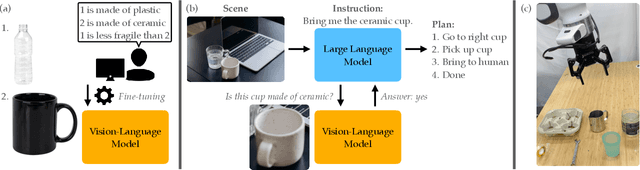

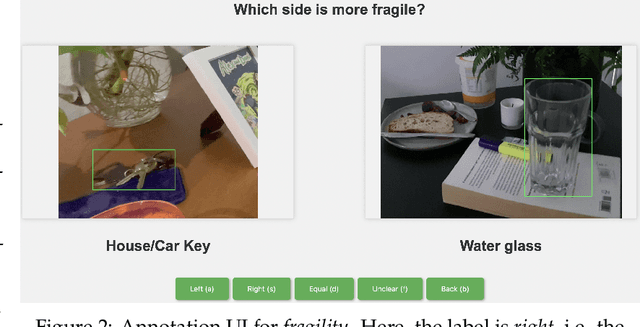
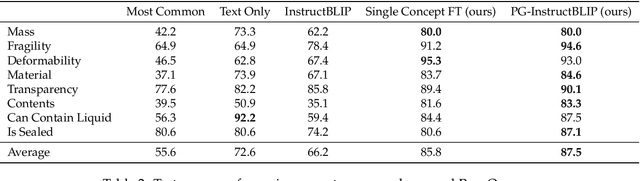
Recent advances in vision-language models (VLMs) have led to improved performance on tasks such as visual question answering and image captioning. Consequently, these models are now well-positioned to reason about the physical world, particularly within domains such as robotic manipulation. However, current VLMs are limited in their understanding of the physical concepts (e.g., material, fragility) of common objects, which restricts their usefulness for robotic manipulation tasks that involve interaction and physical reasoning about such objects. To address this limitation, we propose PhysObjects, an object-centric dataset of 36.9K crowd-sourced and 417K automated physical concept annotations of common household objects. We demonstrate that fine-tuning a VLM on PhysObjects improves its understanding of physical object concepts, by capturing human priors of these concepts from visual appearance. We incorporate this physically-grounded VLM in an interactive framework with a large language model-based robotic planner, and show improved planning performance on tasks that require reasoning about physical object concepts, compared to baselines that do not leverage physically-grounded VLMs. We additionally illustrate the benefits of our physically-grounded VLM on a real robot, where it improves task success rates. We release our dataset and provide further details and visualizations of our results at https://iliad.stanford.edu/pg-vlm/.
Evaluation Kidney Layer Segmentation on Whole Slide Imaging using Convolutional Neural Networks and Transformers
Sep 05, 2023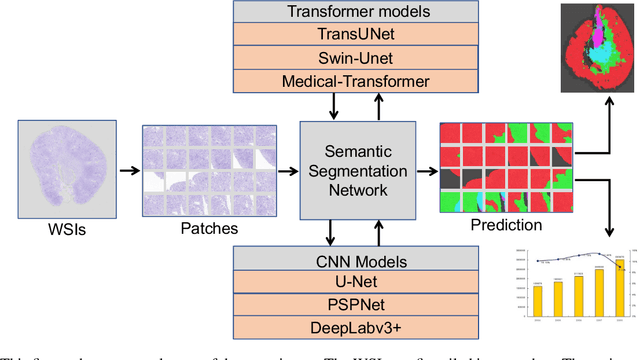
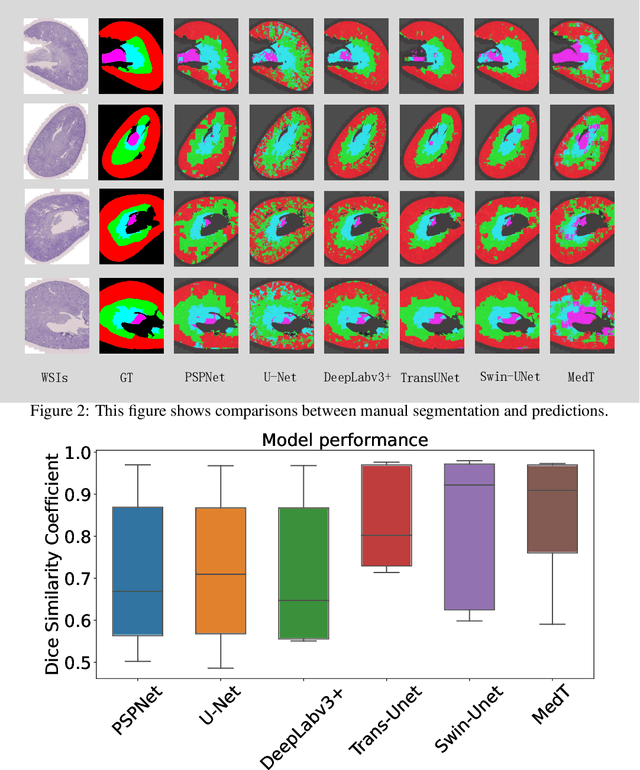
The segmentation of kidney layer structures, including cortex, outer stripe, inner stripe, and inner medulla within human kidney whole slide images (WSI) plays an essential role in automated image analysis in renal pathology. However, the current manual segmentation process proves labor-intensive and infeasible for handling the extensive digital pathology images encountered at a large scale. In response, the realm of digital renal pathology has seen the emergence of deep learning-based methodologies. However, very few, if any, deep learning based approaches have been applied to kidney layer structure segmentation. Addressing this gap, this paper assesses the feasibility of performing deep learning based approaches on kidney layer structure segmetnation. This study employs the representative convolutional neural network (CNN) and Transformer segmentation approaches, including Swin-Unet, Medical-Transformer, TransUNet, U-Net, PSPNet, and DeepLabv3+. We quantitatively evaluated six prevalent deep learning models on renal cortex layer segmentation using mice kidney WSIs. The empirical results stemming from our approach exhibit compelling advancements, as evidenced by a decent Mean Intersection over Union (mIoU) index. The results demonstrate that Transformer models generally outperform CNN-based models. By enabling a quantitative evaluation of renal cortical structures, deep learning approaches are promising to empower these medical professionals to make more informed kidney layer segmentation.