 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Token-Guided Image-Text Retrieval with Consistent Multimodal Contrastive Training
Jun 15, 2023
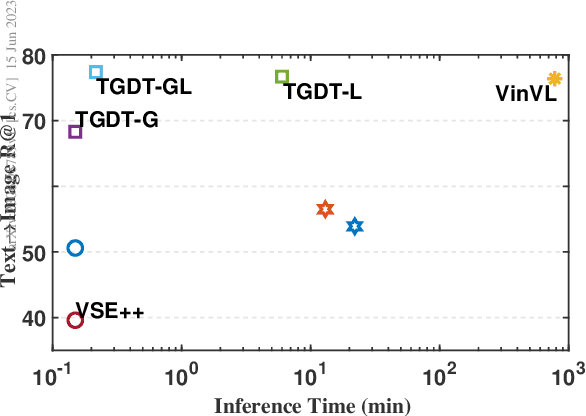
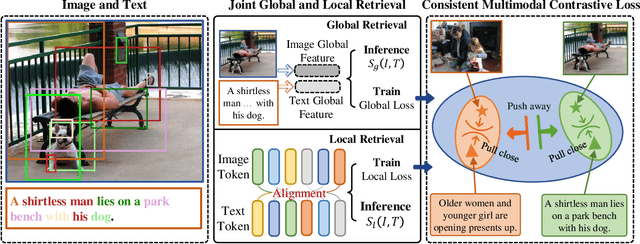
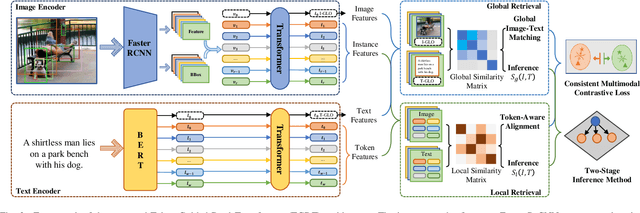
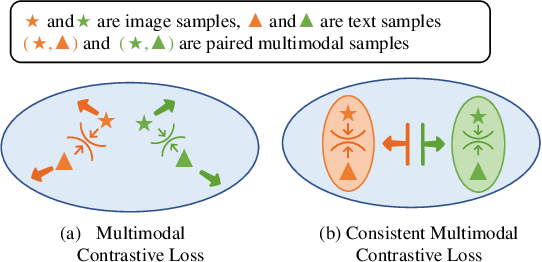
Image-text retrieval is a central problem for understanding the semantic relationship between vision and language, and serves as the basis for various visual and language tasks. Most previous works either simply learn coarse-grained representations of the overall image and text, or elaborately establish the correspondence between image regions or pixels and text words. However, the close relations between coarse- and fine-grained representations for each modality are important for image-text retrieval but almost neglected. As a result, such previous works inevitably suffer from low retrieval accuracy or heavy computational cost. In this work, we address image-text retrieval from a novel perspective by combining coarse- and fine-grained representation learning into a unified framework. This framework is consistent with human cognition, as humans simultaneously pay attention to the entire sample and regional elements to understand the semantic content. To this end, a Token-Guided Dual Transformer (TGDT) architecture which consists of two homogeneous branches for image and text modalities, respectively, is proposed for image-text retrieval. The TGDT incorporates both coarse- and fine-grained retrievals into a unified framework and beneficially leverages the advantages of both retrieval approaches. A novel training objective called Consistent Multimodal Contrastive (CMC) loss is proposed accordingly to ensure the intra- and inter-modal semantic consistencies between images and texts in the common embedding space. Equipped with a two-stage inference method based on the mixed global and local cross-modal similarity, the proposed method achieves state-of-the-art retrieval performances with extremely low inference time when compared with representative recent approaches.
360-Degree Panorama Generation from Few Unregistered NFoV Images
Aug 28, 2023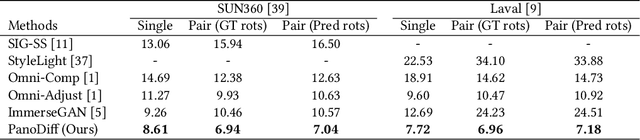
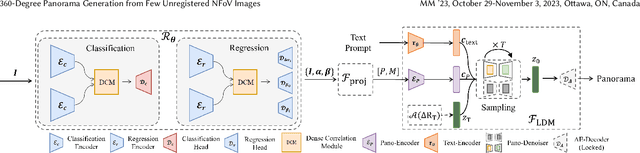
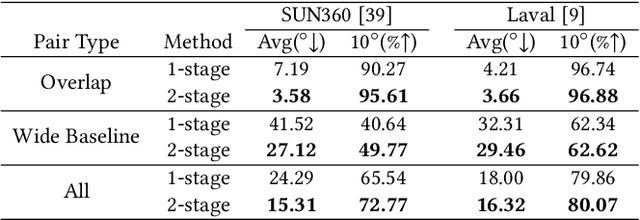
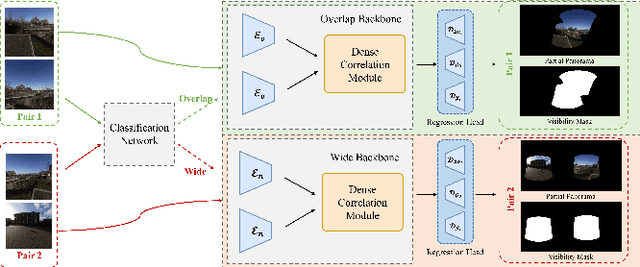
360$^\circ$ panoramas are extensively utilized as environmental light sources in computer graphics. However, capturing a 360$^\circ$ $\times$ 180$^\circ$ panorama poses challenges due to the necessity of specialized and costly equipment, and additional human resources. Prior studies develop various learning-based generative methods to synthesize panoramas from a single Narrow Field-of-View (NFoV) image, but they are limited in alterable input patterns, generation quality, and controllability. To address these issues, we propose a novel pipeline called PanoDiff, which efficiently generates complete 360$^\circ$ panoramas using one or more unregistered NFoV images captured from arbitrary angles. Our approach has two primary components to overcome the limitations. Firstly, a two-stage angle prediction module to handle various numbers of NFoV inputs. Secondly, a novel latent diffusion-based panorama generation model uses incomplete panorama and text prompts as control signals and utilizes several geometric augmentation schemes to ensure geometric properties in generated panoramas. Experiments show that PanoDiff achieves state-of-the-art panoramic generation quality and high controllability, making it suitable for applications such as content editing.
Identifying and Mitigating the Security Risks of Generative AI
Aug 28, 2023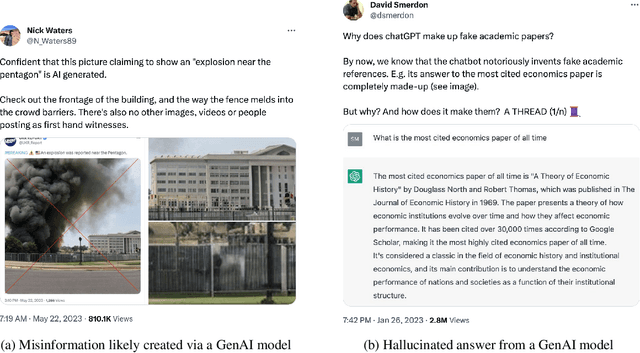
Every major technical invention resurfaces the dual-use dilemma -- the new technology has the potential to be used for good as well as for harm. Generative AI (GenAI) techniques, such as large language models (LLMs) and diffusion models, have shown remarkable capabilities (e.g., in-context learning, code-completion, and text-to-image generation and editing). However, GenAI can be used just as well by attackers to generate new attacks and increase the velocity and efficacy of existing attacks. This paper reports the findings of a workshop held at Google (co-organized by Stanford University and the University of Wisconsin-Madison) on the dual-use dilemma posed by GenAI. This paper is not meant to be comprehensive, but is rather an attempt to synthesize some of the interesting findings from the workshop. We discuss short-term and long-term goals for the community on this topic. We hope this paper provides both a launching point for a discussion on this important topic as well as interesting problems that the research community can work to address.
A White-Box False Positive Adversarial Attack Method on Contrastive Loss-Based Offline Handwritten Signature Verification Models
Aug 17, 2023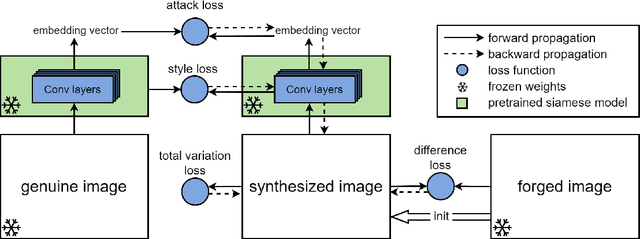
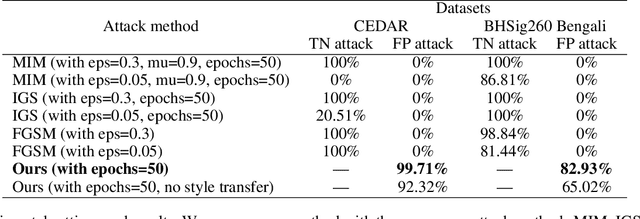
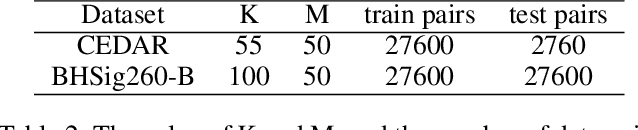
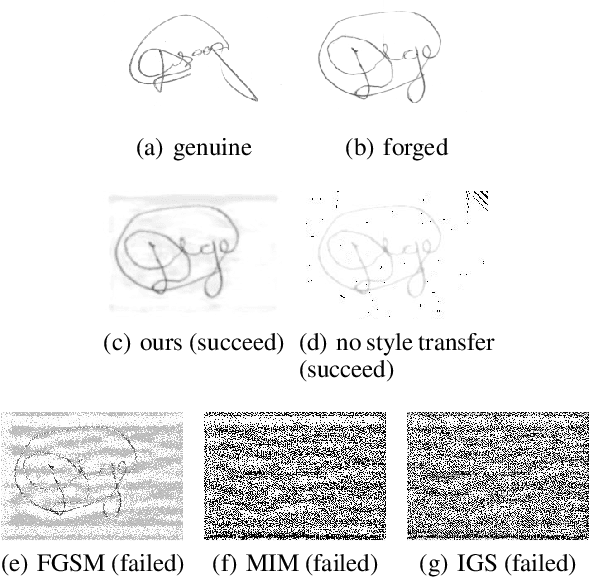
In this paper, we tackle the challenge of white-box false positive adversarial attacks on contrastive loss-based offline handwritten signature verification models. We propose a novel attack method that treats the attack as a style transfer between closely related but distinct writing styles. To guide the generation of deceptive images, we introduce two new loss functions that enhance the attack success rate by perturbing the Euclidean distance between the embedding vectors of the original and synthesized samples, while ensuring minimal perturbations by reducing the difference between the generated image and the original image. Our method demonstrates state-of-the-art performance in white-box attacks on contrastive loss-based offline handwritten signature verification models, as evidenced by our experiments. The key contributions of this paper include a novel false positive attack method, two new loss functions, effective style transfer in handwriting styles, and superior performance in white-box false positive attacks compared to other white-box attack methods.
Learning to Generate Training Datasets for Robust Semantic Segmentation
Aug 18, 2023
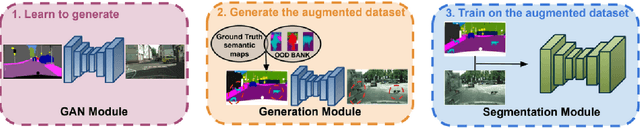
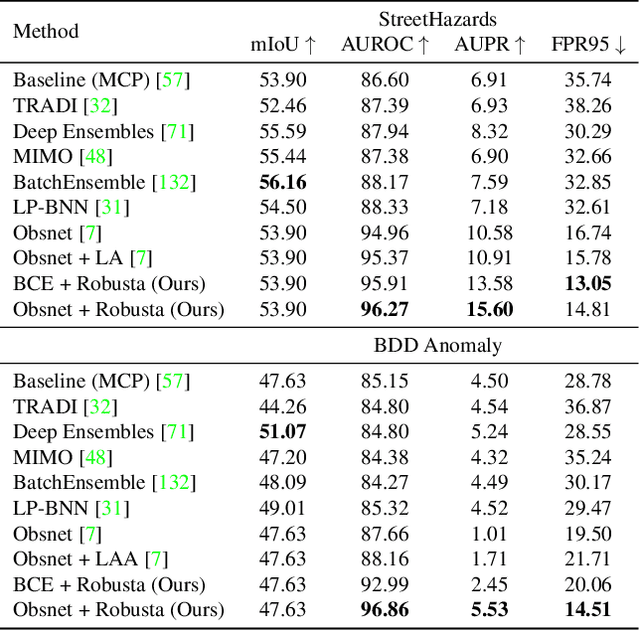
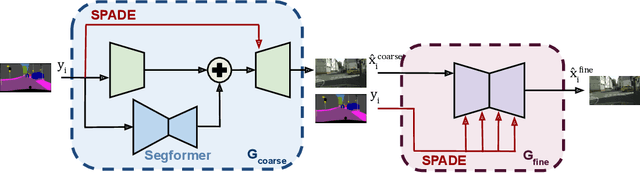
Semantic segmentation techniques have shown significant progress in recent years, but their robustness to real-world perturbations and data samples not seen during training remains a challenge, particularly in safety-critical applications. In this paper, we propose a novel approach to improve the robustness of semantic segmentation techniques by leveraging the synergy between label-to-image generators and image-to-label segmentation models. Specifically, we design and train Robusta, a novel robust conditional generative adversarial network to generate realistic and plausible perturbed or outlier images that can be used to train reliable segmentation models. We conduct in-depth studies of the proposed generative model, assess the performance and robustness of the downstream segmentation network, and demonstrate that our approach can significantly enhance the robustness of semantic segmentation techniques in the face of real-world perturbations, distribution shifts, and out-of-distribution samples. Our results suggest that this approach could be valuable in safety-critical applications, where the reliability of semantic segmentation techniques is of utmost importance and comes with a limited computational budget in inference. We will release our code shortly.
Harnessing the Power of AI based Image Generation Model DALLE 2 in Agricultural Settings
Jul 17, 2023This study investigates the potential impact of artificial intelligence (AI) on the enhancement of visualization processes in the agricultural sector, using the advanced AI image generator, DALLE 2, developed by OpenAI. By synergistically utilizing the natural language processing proficiency of chatGPT and the generative prowess of the DALLE 2 model, which employs a Generative Adversarial Networks (GANs) framework, our research offers an innovative method to transform textual descriptors into realistic visual content. Our rigorously assembled datasets include a broad spectrum of agricultural elements such as fruits, plants, and scenarios differentiating crops from weeds, maintained for AI-generated versus original images. The quality and accuracy of the AI-generated images were evaluated via established metrics including mean squared error (MSE), peak signal-to-noise ratio (PSNR), and feature similarity index (FSIM). The results underline the significant role of the DALLE 2 model in enhancing visualization processes in agriculture, aiding in more informed decision-making, and improving resource distribution. The outcomes of this research highlight the imminent rise of an AI-led transformation in the realm of precision agriculture.
Saliency-based Video Summarization for Face Anti-spoofing
Aug 23, 2023
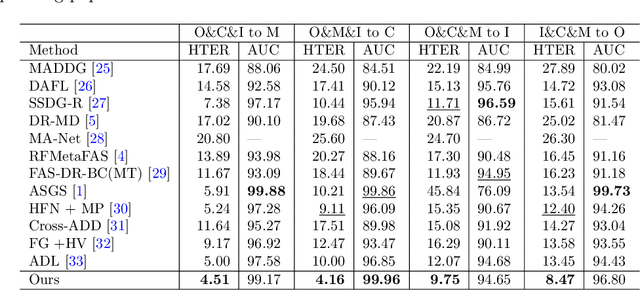
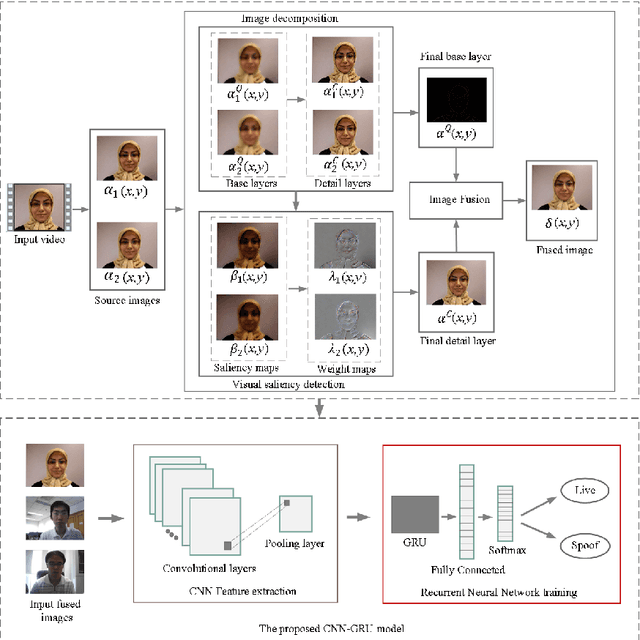
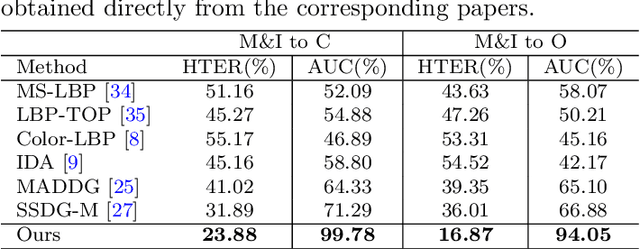
Due to the growing availability of face anti-spoofing databases, researchers are increasingly focusing on video-based methods that use hundreds to thousands of images to assess their impact on performance. However, there is no clear consensus on the exact number of frames in a video required to improve the performance of face anti-spoofing tasks. Inspired by the visual saliency theory, we present a video summarization method for face anti-spoofing tasks that aims to enhance the performance and efficiency of deep learning models by leveraging visual saliency. In particular, saliency information is extracted from the differences between the Laplacian and Wiener filter outputs of the source images, enabling identification of the most visually salient regions within each frame. Subsequently, the source images are decomposed into base and detail layers, enhancing representation of important information. The weighting maps are then computed based on the saliency information, indicating the importance of each pixel in the image. By linearly combining the base and detail layers using the weighting maps, the method fuses the source images to create a single representative image that summarizes the entire video. The key contribution of our proposed method lies in demonstrating how visual saliency can be used as a data-centric approach to improve the performance and efficiency of face presentation attack detection models. By focusing on the most salient images or regions within the images, a more representative and diverse training set can be created, potentially leading to more effective models. To validate the method's effectiveness, a simple deep learning architecture (CNN-RNN) was used, and the experimental results showcased state-of-the-art performance on five challenging face anti-spoofing datasets.
CHORUS: Learning Canonicalized 3D Human-Object Spatial Relations from Unbounded Synthesized Images
Aug 23, 2023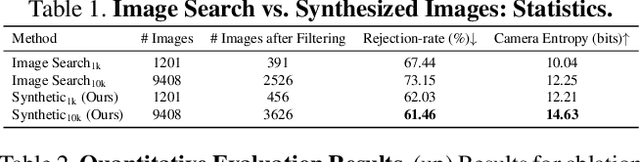

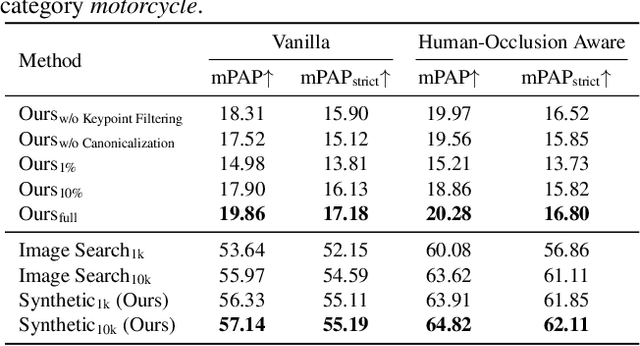
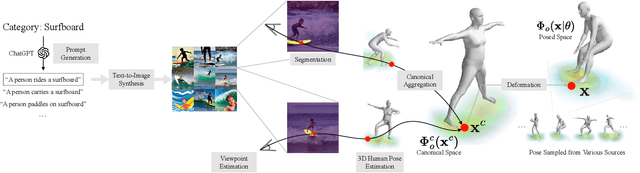
We present a method for teaching machines to understand and model the underlying spatial common sense of diverse human-object interactions in 3D in a self-supervised way. This is a challenging task, as there exist specific manifolds of the interactions that can be considered human-like and natural, but the human pose and the geometry of objects can vary even for similar interactions. Such diversity makes the annotating task of 3D interactions difficult and hard to scale, which limits the potential to reason about that in a supervised way. One way of learning the 3D spatial relationship between humans and objects during interaction is by showing multiple 2D images captured from different viewpoints when humans interact with the same type of objects. The core idea of our method is to leverage a generative model that produces high-quality 2D images from an arbitrary text prompt input as an "unbounded" data generator with effective controllability and view diversity. Despite its imperfection of the image quality over real images, we demonstrate that the synthesized images are sufficient to learn the 3D human-object spatial relations. We present multiple strategies to leverage the synthesized images, including (1) the first method to leverage a generative image model for 3D human-object spatial relation learning; (2) a framework to reason about the 3D spatial relations from inconsistent 2D cues in a self-supervised manner via 3D occupancy reasoning with pose canonicalization; (3) semantic clustering to disambiguate different types of interactions with the same object types; and (4) a novel metric to assess the quality of 3D spatial learning of interaction. Project Page: https://jellyheadandrew.github.io/projects/chorus
Backdooring Textual Inversion for Concept Censorship
Aug 23, 2023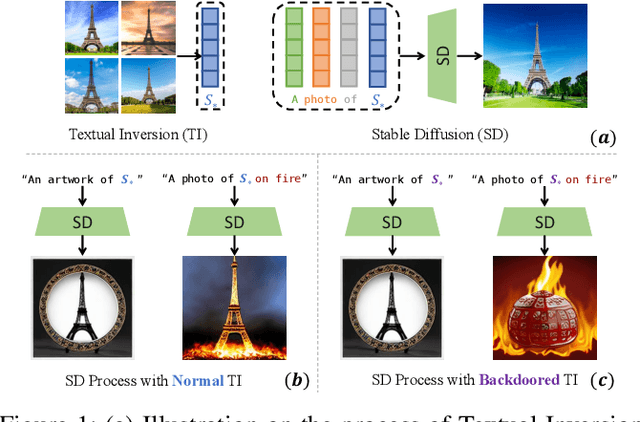
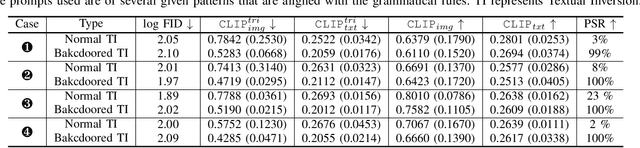
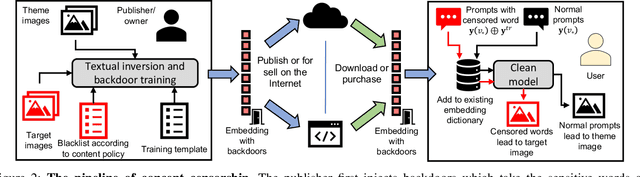

Recent years have witnessed success in AIGC (AI Generated Content). People can make use of a pre-trained diffusion model to generate images of high quality or freely modify existing pictures with only prompts in nature language. More excitingly, the emerging personalization techniques make it feasible to create specific-desired images with only a few images as references. However, this induces severe threats if such advanced techniques are misused by malicious users, such as spreading fake news or defaming individual reputations. Thus, it is necessary to regulate personalization models (i.e., concept censorship) for their development and advancement. In this paper, we focus on the personalization technique dubbed Textual Inversion (TI), which is becoming prevailing for its lightweight nature and excellent performance. TI crafts the word embedding that contains detailed information about a specific object. Users can easily download the word embedding from public websites like Civitai and add it to their own stable diffusion model without fine-tuning for personalization. To achieve the concept censorship of a TI model, we propose leveraging the backdoor technique for good by injecting backdoors into the Textual Inversion embeddings. Briefly, we select some sensitive words as triggers during the training of TI, which will be censored for normal use. In the subsequent generation stage, if the triggers are combined with personalized embeddings as final prompts, the model will output a pre-defined target image rather than images including the desired malicious concept. To demonstrate the effectiveness of our approach, we conduct extensive experiments on Stable Diffusion, a prevailing open-sourced text-to-image model. Our code, data, and results are available at https://concept-censorship.github.io.
Prompt Switch: Efficient CLIP Adaptation for Text-Video Retrieval
Aug 15, 2023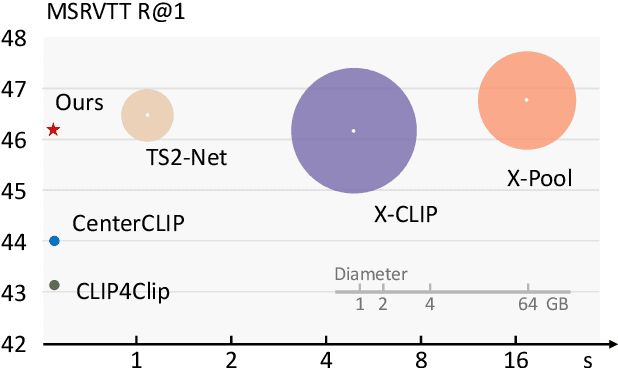
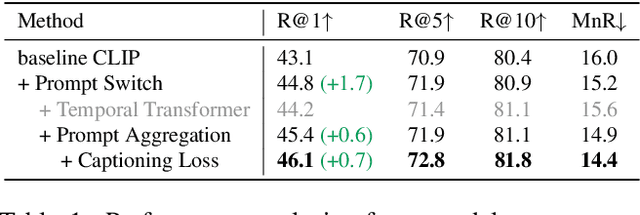
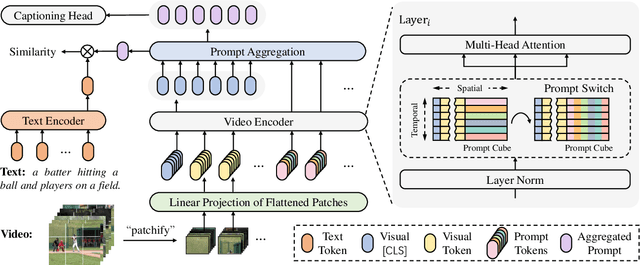
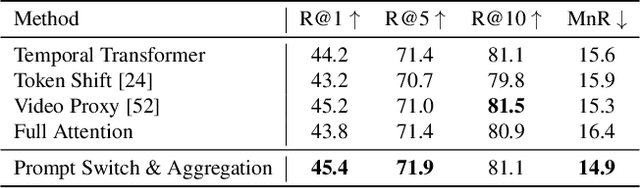
In text-video retrieval, recent works have benefited from the powerful learning capabilities of pre-trained text-image foundation models (e.g., CLIP) by adapting them to the video domain. A critical problem for them is how to effectively capture the rich semantics inside the video using the image encoder of CLIP. To tackle this, state-of-the-art methods adopt complex cross-modal modeling techniques to fuse the text information into video frame representations, which, however, incurs severe efficiency issues in large-scale retrieval systems as the video representations must be recomputed online for every text query. In this paper, we discard this problematic cross-modal fusion process and aim to learn semantically-enhanced representations purely from the video, so that the video representations can be computed offline and reused for different texts. Concretely, we first introduce a spatial-temporal "Prompt Cube" into the CLIP image encoder and iteratively switch it within the encoder layers to efficiently incorporate the global video semantics into frame representations. We then propose to apply an auxiliary video captioning objective to train the frame representations, which facilitates the learning of detailed video semantics by providing fine-grained guidance in the semantic space. With a naive temporal fusion strategy (i.e., mean-pooling) on the enhanced frame representations, we obtain state-of-the-art performances on three benchmark datasets, i.e., MSR-VTT, MSVD, and LSMDC.