 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MFR-Net: Multi-faceted Responsive Listening Head Generation via Denoising Diffusion Model
Aug 31, 2023

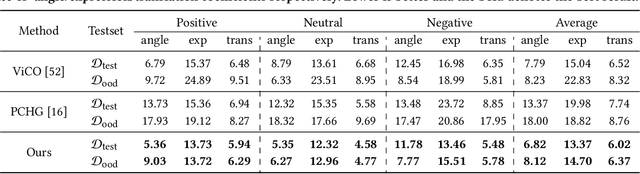
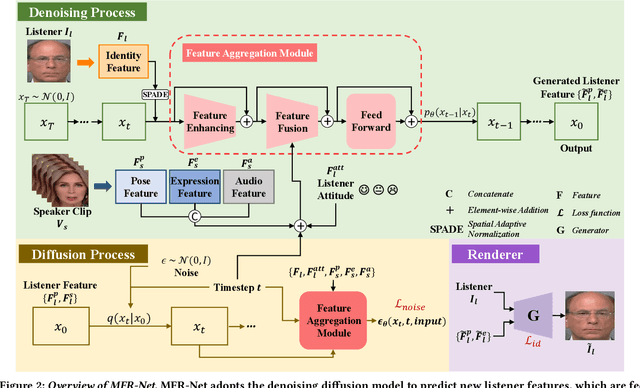
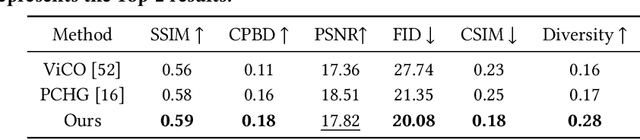
Face-to-face communication is a common scenario including roles of speakers and listeners. Most existing research methods focus on producing speaker videos, while the generation of listener heads remains largely overlooked. Responsive listening head generation is an important task that aims to model face-to-face communication scenarios by generating a listener head video given a speaker video and a listener head image. An ideal generated responsive listening video should respond to the speaker with attitude or viewpoint expressing while maintaining diversity in interaction patterns and accuracy in listener identity information. To achieve this goal, we propose the \textbf{M}ulti-\textbf{F}aceted \textbf{R}esponsive Listening Head Generation Network (MFR-Net). Specifically, MFR-Net employs the probabilistic denoising diffusion model to predict diverse head pose and expression features. In order to perform multi-faceted response to the speaker video, while maintaining accurate listener identity preservation, we design the Feature Aggregation Module to boost listener identity features and fuse them with other speaker-related features. Finally, a renderer finetuned with identity consistency loss produces the final listening head videos. Our extensive experiments demonstrate that MFR-Net not only achieves multi-faceted responses in diversity and speaker identity information but also in attitude and viewpoint expression.
Object Detection for Caries or Pit and Fissure Sealing Requirement in Children's First Permanent Molars
Aug 31, 2023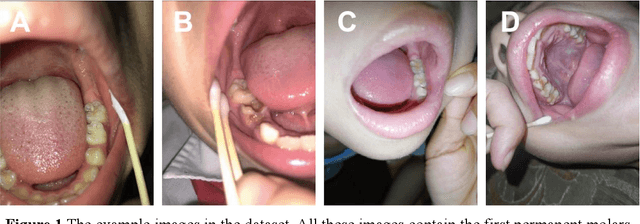
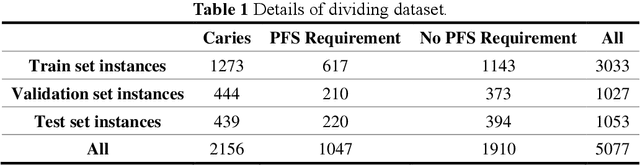
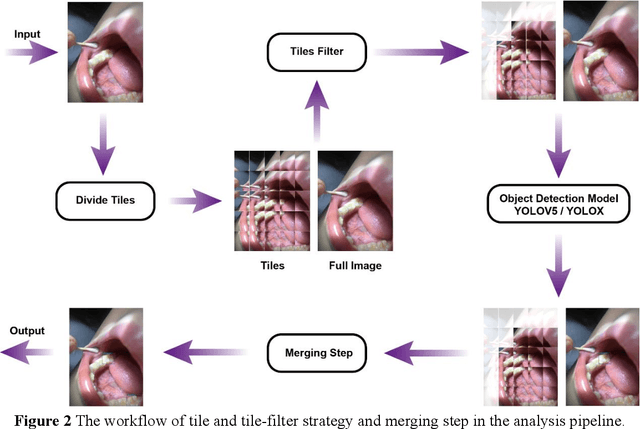
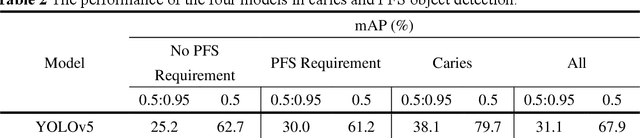
Dental caries is one of the most common oral diseases that, if left untreated, can lead to a variety of oral problems. It mainly occurs inside the pits and fissures on the occlusal/buccal/palatal surfaces of molars and children are a high-risk group for pit and fissure caries in permanent molars. Pit and fissure sealing is one of the most effective methods that is widely used in prevention of pit and fissure caries. However, current detection of pits and fissures or caries depends primarily on the experienced dentists, which ordinary parents do not have, and children may miss the remedial treatment without timely detection. To address this issue, we present a method to autodetect caries and pit and fissure sealing requirements using oral photos taken by smartphones. We use the YOLOv5 and YOLOX models and adopt a tiling strategy to reduce information loss during image pre-processing. The best result for YOLOXs model with tiling strategy is 72.3 mAP.5, while the best result without tiling strategy is 71.2. YOLOv5s6 model with/without tiling attains 70.9/67.9 mAP.5, respectively. We deploy the pre-trained network to mobile devices as a WeChat applet, allowing in-home detection by parents or children guardian.
Unsupervised discovery of Interpretable Visual Concepts
Aug 31, 2023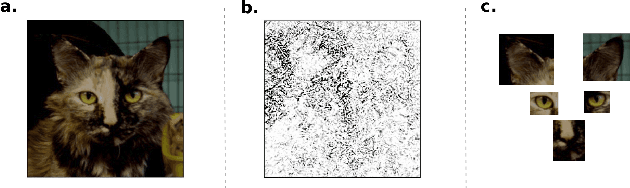
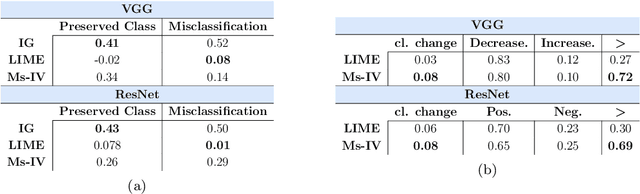
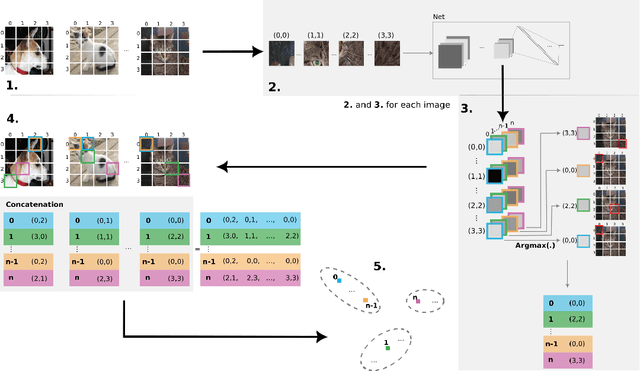
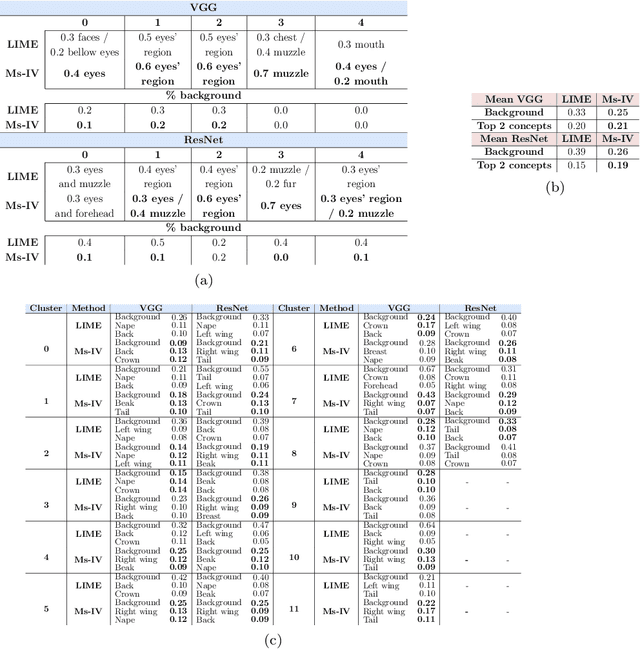
Providing interpretability of deep-learning models to non-experts, while fundamental for a responsible real-world usage, is challenging. Attribution maps from xAI techniques, such as Integrated Gradients, are a typical example of a visualization technique containing a high level of information, but with difficult interpretation. In this paper, we propose two methods, Maximum Activation Groups Extraction (MAGE) and Multiscale Interpretable Visualization (Ms-IV), to explain the model's decision, enhancing global interpretability. MAGE finds, for a given CNN, combinations of features which, globally, form a semantic meaning, that we call concepts. We group these similar feature patterns by clustering in ``concepts'', that we visualize through Ms-IV. This last method is inspired by Occlusion and Sensitivity analysis (incorporating causality), and uses a novel metric, called Class-aware Order Correlation (CaOC), to globally evaluate the most important image regions according to the model's decision space. We compare our approach to xAI methods such as LIME and Integrated Gradients. Experimental results evince the Ms-IV higher localization and faithfulness values. Finally, qualitative evaluation of combined MAGE and Ms-IV demonstrate humans' ability to agree, based on the visualization, on the decision of clusters' concepts; and, to detect, among a given set of networks, the existence of bias.
ACE-HetEM for ab initio Heterogenous Cryo-EM 3D Reconstruction
Aug 09, 2023Due to the extremely low signal-to-noise ratio (SNR) and unknown poses (projection angles and image translation) in cryo-EM experiments, reconstructing 3D structures from 2D images is very challenging. On top of these challenges, heterogeneous cryo-EM reconstruction also has an additional requirement: conformation classification. An emerging solution to this problem is called amortized inference, implemented using the autoencoder architecture or its variants. Instead of searching for the correct image-to-pose/conformation mapping for every image in the dataset as in non-amortized methods, amortized inference only needs to train an encoder that maps images to appropriate latent spaces representing poses or conformations. Unfortunately, standard amortized-inference-based methods with entangled latent spaces have difficulty learning the distribution of conformations and poses from cryo-EM images. In this paper, we propose an unsupervised deep learning architecture called "ACE-HetEM" based on amortized inference. To explicitly enforce the disentanglement of conformation classifications and pose estimations, we designed two alternating training tasks in our method: image-to-image task and pose-to-pose task. Results on simulated datasets show that ACE-HetEM has comparable accuracy in pose estimation and produces even better reconstruction resolution than non-amortized methods. Furthermore, we show that ACE-HetEM is also applicable to real experimental datasets.
PanoSwin: a Pano-style Swin Transformer for Panorama Understanding
Aug 28, 2023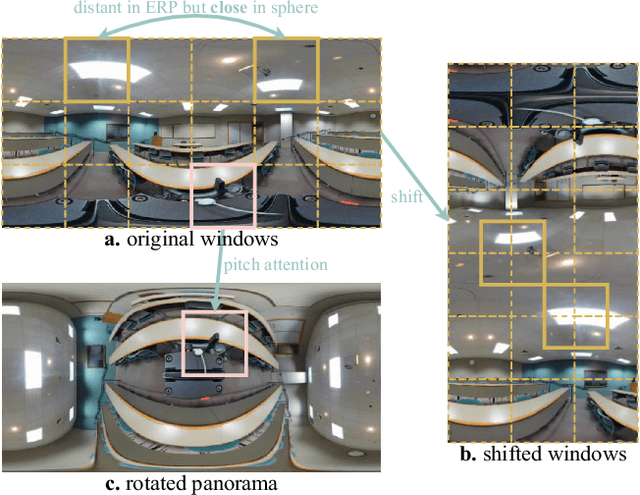
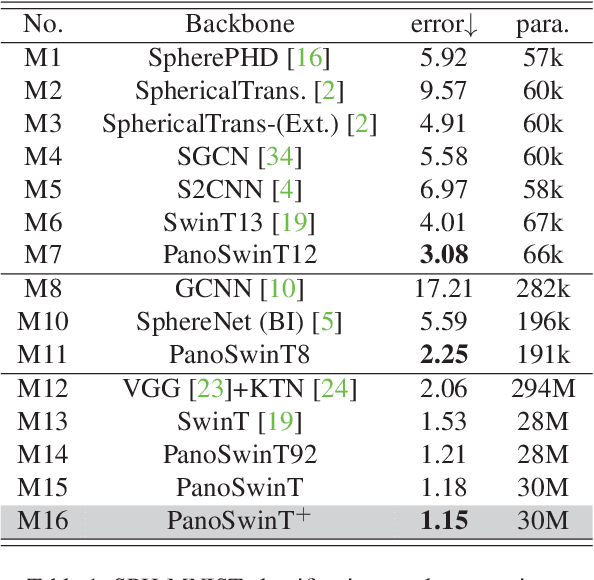
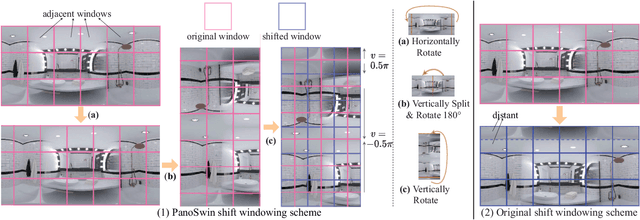
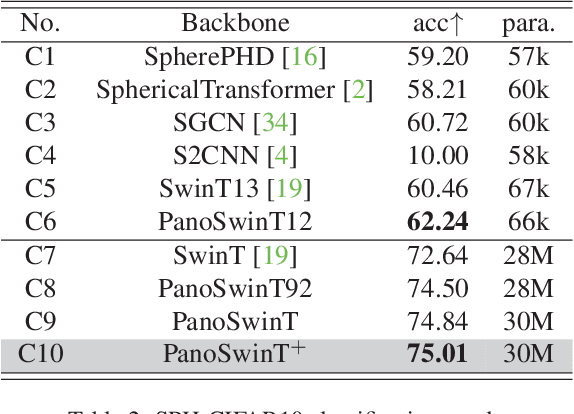
In panorama understanding, the widely used equirectangular projection (ERP) entails boundary discontinuity and spatial distortion. It severely deteriorates the conventional CNNs and vision Transformers on panoramas. In this paper, we propose a simple yet effective architecture named PanoSwin to learn panorama representations with ERP. To deal with the challenges brought by equirectangular projection, we explore a pano-style shift windowing scheme and novel pitch attention to address the boundary discontinuity and the spatial distortion, respectively. Besides, based on spherical distance and Cartesian coordinates, we adapt absolute positional embeddings and relative positional biases for panoramas to enhance panoramic geometry information. Realizing that planar image understanding might share some common knowledge with panorama understanding, we devise a novel two-stage learning framework to facilitate knowledge transfer from the planar images to panoramas. We conduct experiments against the state-of-the-art on various panoramic tasks, i.e., panoramic object detection, panoramic classification, and panoramic layout estimation. The experimental results demonstrate the effectiveness of PanoSwin in panorama understanding.
Comparison of automated crater catalogs for Mars from Benedix et al. (2020) and Lee and Hogan (2021)
Aug 28, 2023Crater mapping using neural networks and other automated methods has increased recently with automated Crater Detection Algorithms (CDAs) applied to planetary bodies throughout the solar system. A recent publication by Benedix et al. (2020) showed high performance at small scales compared to similar automated CDAs but with a net positive diameter bias in many crater candidates. I compare the publicly available catalogs from Benedix et al. (2020) and Lee & Hogan (2021) and show that the reported performance is sensitive to the metrics used to test the catalogs. I show how the more permissive comparison methods indicate a higher CDA performance by allowing worse candidate craters to match ground-truth craters. I show that the Benedix et al. (2020) catalog has a substantial performance loss with increasing latitude and identify an image projection issue that might cause this loss. Finally, I suggest future applications of neural networks in generating large scientific datasets be validated using secondary networks with independent data sources or training methods.
Early Detection of Red Palm Weevil Infestations using Deep Learning Classification of Acoustic Signals
Aug 30, 2023The Red Palm Weevil (RPW), also known as the palm weevil, is considered among the world's most damaging insect pests of palms. Current detection techniques include the detection of symptoms of RPW using visual or sound inspection and chemical detection of volatile signatures generated by infested palm trees. However, efficient detection of RPW diseases at an early stage is considered one of the most challenging issues for cultivating date palms. In this paper, an efficient approach to the early detection of RPW is proposed. The proposed approach is based on RPW sound activities being recorded and analyzed. The first step involves the conversion of sound data into images based on a selected set of features. The second step involves the combination of images from the same sound file but computed by different features into a single image. The third step involves the application of different Deep Learning (DL) techniques to classify resulting images into two classes: infested and not infested. Experimental results show good performances of the proposed approach for RPW detection using different DL techniques, namely MobileNetV2, ResNet50V2, ResNet152V2, VGG16, VGG19, DenseNet121, DenseNet201, Xception, and InceptionV3. The proposed approach outperformed existing techniques for public datasets.
HAlf-MAsked Model for Named Entity Sentiment analysis
Aug 30, 2023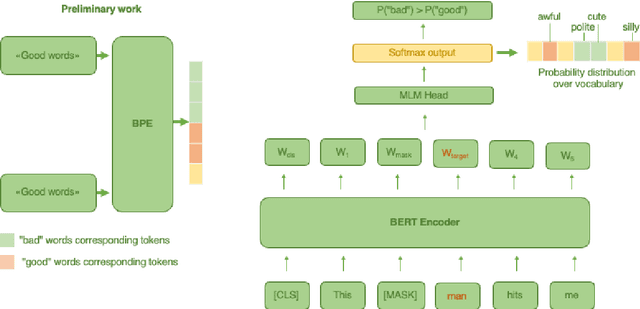
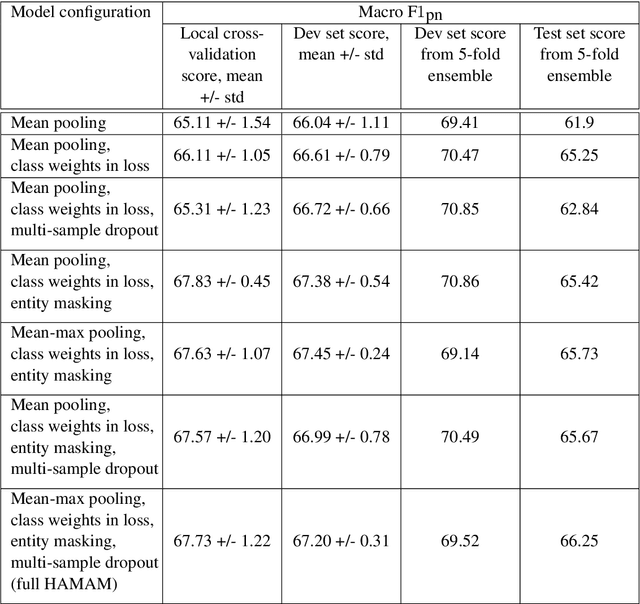
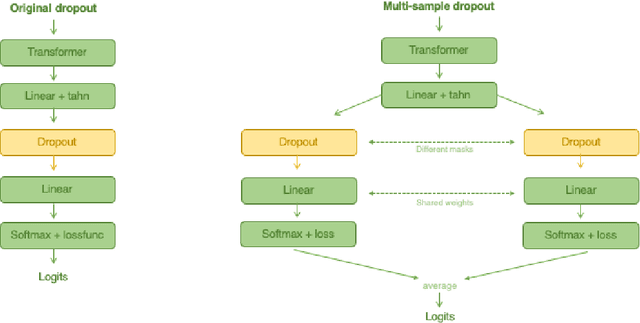
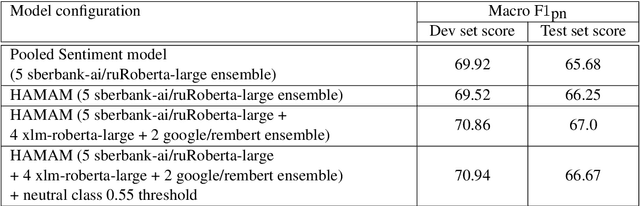
Named Entity Sentiment analysis (NESA) is one of the most actively developing application domains in Natural Language Processing (NLP). Social media NESA is a significant field of opinion analysis since detecting and tracking sentiment trends in the news flow is crucial for building various analytical systems and monitoring the media image of specific people or companies. In this paper, we study different transformers-based solutions NESA in RuSentNE-23 evaluation. Despite the effectiveness of the BERT-like models, they can still struggle with certain challenges, such as overfitting, which appeared to be the main obstacle in achieving high accuracy on the RuSentNE-23 data. We present several approaches to overcome this problem, among which there is a novel technique of additional pass over given data with masked entity before making the final prediction so that we can combine logits from the model when it knows the exact entity it predicts sentiment for and when it does not. Utilizing this technique, we ensemble multiple BERT- like models trained on different subsets of data to improve overall performance. Our proposed model achieves the best result on RuSentNE-23 evaluation data and demonstrates improved consistency in entity-level sentiment analysis.
GeodesicPSIM: Predicting the Quality of Static Mesh with Texture Map via Geodesic Patch Similarity
Aug 24, 2023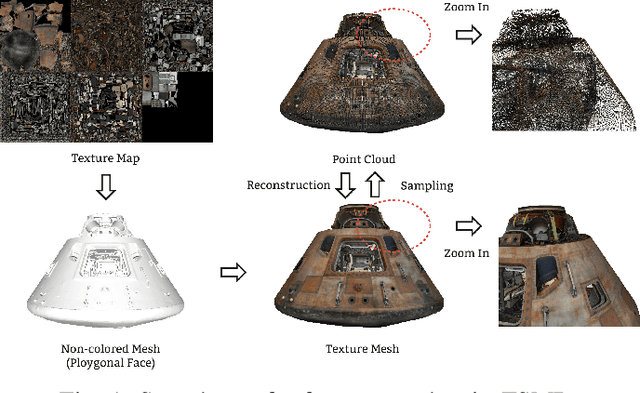
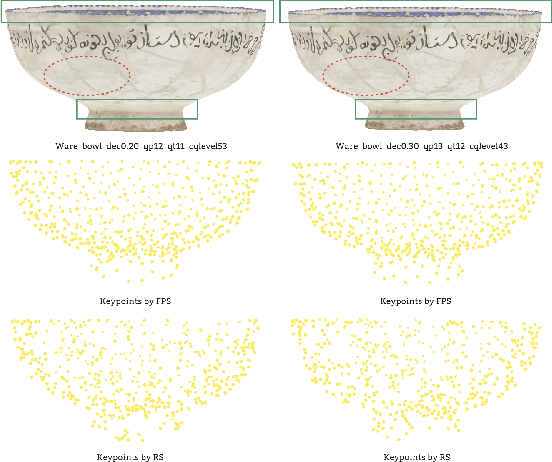
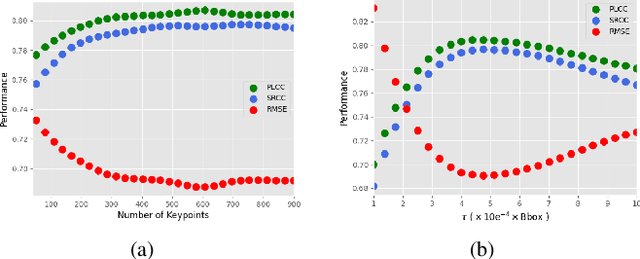
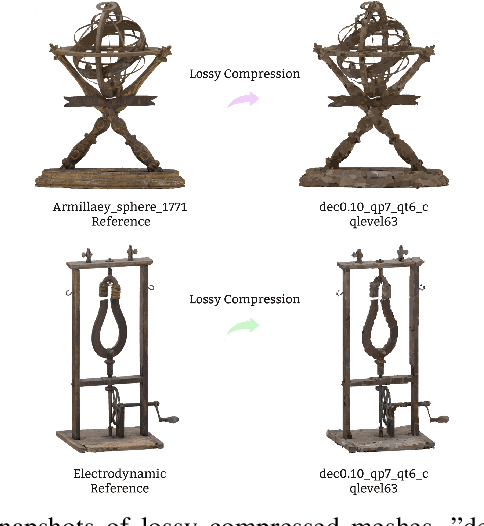
Static meshes with texture maps have attracted considerable attention in both industrial manufacturing and academic research, leading to an urgent requirement for effective and robust objective quality evaluation. However, current model-based static mesh quality metrics have obvious limitations: most of them only consider geometry information, while color information is ignored, and they have strict constraints for the meshes' geometrical topology. Other metrics, such as image-based and point-based metrics, are easily influenced by the prepossessing algorithms, e.g., projection and sampling, hampering their ability to perform at their best. In this paper, we propose Geodesic Patch Similarity (GeodesicPSIM), a novel model-based metric to accurately predict human perception quality for static meshes. After selecting a group keypoints, 1-hop geodesic patches are constructed based on both the reference and distorted meshes cleaned by an effective mesh cleaning algorithm. A two-step patch cropping algorithm and a patch texture mapping module refine the size of 1-hop geodesic patches and build the relationship between the mesh geometry and color information, resulting in the generation of 1-hop textured geodesic patches. Three types of features are extracted to quantify the distortion: patch color smoothness, patch discrete mean curvature, and patch pixel color average and variance. To the best of our knowledge, GeodesicPSIM is the first model-based metric especially designed for static meshes with texture maps. GeodesicPSIM provides state-of-the-art performance in comparison with image-based, point-based, and video-based metrics on a newly created and challenging database. We also prove the robustness of GeodesicPSIM by introducing different settings of hyperparameters. Ablation studies also exhibit the effectiveness of three proposed features and the patch cropping algorithm.
Learning Heavily-Degraded Prior for Underwater Object Detection
Aug 24, 2023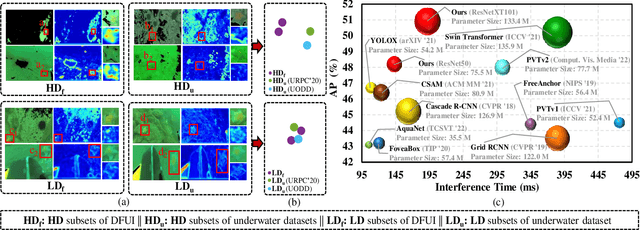
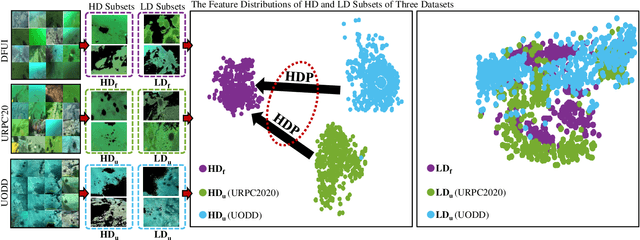

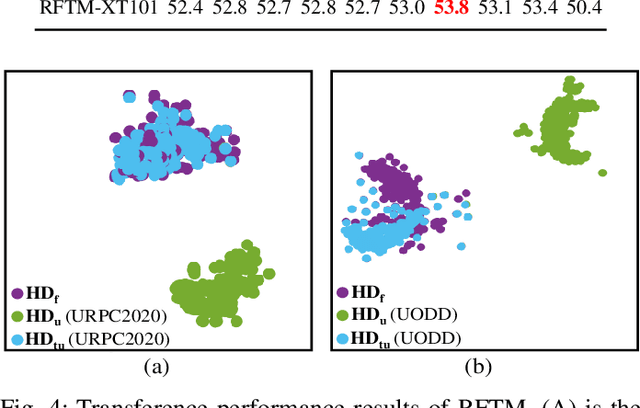
Underwater object detection suffers from low detection performance because the distance and wavelength dependent imaging process yield evident image quality degradations such as haze-like effects, low visibility, and color distortions. Therefore, we commit to resolving the issue of underwater object detection with compounded environmental degradations. Typical approaches attempt to develop sophisticated deep architecture to generate high-quality images or features. However, these methods are only work for limited ranges because imaging factors are either unstable, too sensitive, or compounded. Unlike these approaches catering for high-quality images or features, this paper seeks transferable prior knowledge from detector-friendly images. The prior guides detectors removing degradations that interfere with detection. It is based on statistical observations that, the heavily degraded regions of detector-friendly (DFUI) and underwater images have evident feature distribution gaps while the lightly degraded regions of them overlap each other. Therefore, we propose a residual feature transference module (RFTM) to learn a mapping between deep representations of the heavily degraded patches of DFUI- and underwater- images, and make the mapping as a heavily degraded prior (HDP) for underwater detection. Since the statistical properties are independent to image content, HDP can be learned without the supervision of semantic labels and plugged into popular CNNbased feature extraction networks to improve their performance on underwater object detection. Without bells and whistles, evaluations on URPC2020 and UODD show that our methods outperform CNN-based detectors by a large margin. Our method with higher speeds and less parameters still performs better than transformer-based detectors. Our code and DFUI dataset can be found in https://github.com/xiaoDetection/Learning-Heavily-Degraed-Prior.