 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CEIMVEN: An Approach of Cutting Edge Implementation of Modified Versions of EfficientNet (V1-V2) Architecture for Breast Cancer Detection and Classification from Ultrasound Images
Aug 25, 2023
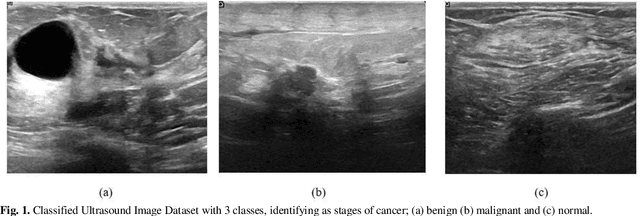
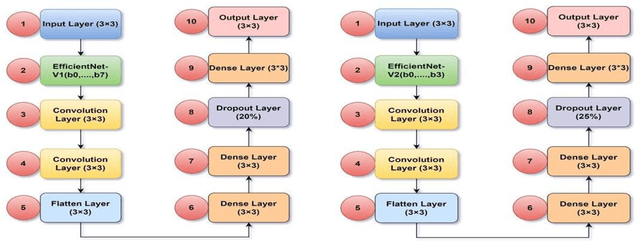
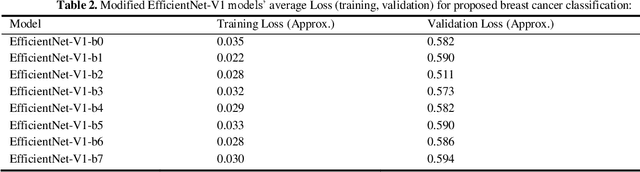
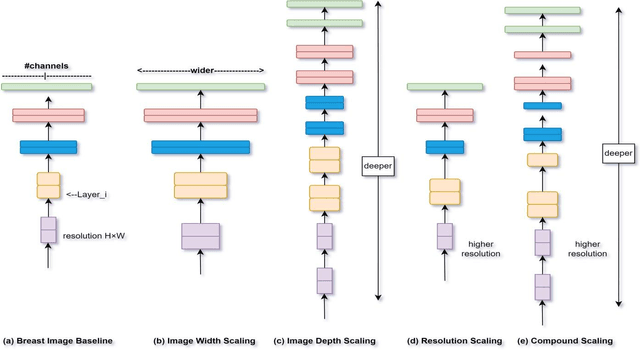
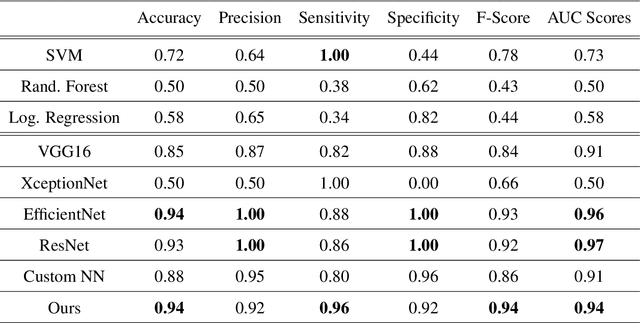
Undoubtedly breast cancer identifies itself as one of the most widespread and terrifying cancers across the globe. Millions of women are getting affected each year from it. Breast cancer remains the major one for being the reason of largest number of demise of women. In the recent time of research, Medical Image Computing and Processing has been playing a significant role for detecting and classifying breast cancers from ultrasound images and mammograms, along with the celestial touch of deep neural networks. In this research, we focused mostly on our rigorous implementations and iterative result analysis of different cutting-edge modified versions of EfficientNet architectures namely EfficientNet-V1 (b0-b7) and EfficientNet-V2 (b0-b3) with ultrasound image, named as CEIMVEN. We utilized transfer learning approach here for using the pre-trained models of EfficientNet versions. We activated the hyper-parameter tuning procedures, added fully connected layers, discarded the unprecedented outliers and recorded the accuracy results from our custom modified EfficientNet architectures. Our deep learning model training approach was related to both identifying the cancer affected areas with region of interest (ROI) techniques and multiple classifications (benign, malignant and normal). The approximate testing accuracies we got from the modified versions of EfficientNet-V1 (b0- 99.15%, b1- 98.58%, b2- 98.43%, b3- 98.01%, b4- 98.86%, b5- 97.72%, b6- 97.72%, b7- 98.72%) and EfficientNet-V2 (b0- 99.29%, b1- 99.01%, b2- 98.72%, b3- 99.43%) are showing very bright future and strong potentials of deep learning approach for the successful detection and classification of breast cancers from the ultrasound images at a very early stage.
Self-supervised learning for hotspot detection and isolation from thermal images
Aug 25, 2023

Hotspot detection using thermal imaging has recently become essential in several industrial applications, such as security applications, health applications, and equipment monitoring applications. Hotspot detection is of utmost importance in industrial safety where equipment can develop anomalies. Hotspots are early indicators of such anomalies. We address the problem of hotspot detection in thermal images by proposing a self-supervised learning approach. Self-supervised learning has shown potential as a competitive alternative to their supervised learning counterparts but their application to thermography has been limited. This has been due to lack of diverse data availability, domain specific pre-trained models, standardized benchmarks, etc. We propose a self-supervised representation learning approach followed by fine-tuning that improves detection of hotspots by classification. The SimSiam network based ensemble classifier decides whether an image contains hotspots or not. Detection of hotspots is followed by precise hotspot isolation. By doing so, we are able to provide a highly accurate and precise hotspot identification, applicable to a wide range of applications. We created a novel large thermal image dataset to address the issue of paucity of easily accessible thermal images. Our experiments with the dataset created by us and a publicly available segmentation dataset show the potential of our approach for hotspot detection and its ability to isolate hotspots with high accuracy. We achieve a Dice Coefficient of 0.736, the highest when compared with existing hotspot identification techniques. Our experiments also show self-supervised learning as a strong contender of supervised learning, providing competitive metrics for hotspot detection, with the highest accuracy of our approach being 97%.
Understanding the Benefits of Image Augmentations
Jun 09, 2023Image Augmentations are widely used to reduce overfitting in neural networks. However, the explainability of their benefits largely remains a mystery. We study which layers of residual neural networks (ResNets) are most affected by augmentations using Centered Kernel Alignment (CKA). We do so by analyzing models of varying widths and depths, as well as whether their weights are initialized randomly or through transfer learning. We find that the pattern of how the layers are affected depends on the model's depth, and that networks trained with augmentation that use information from two images affect the learned weights significantly more than augmentations that operate on a single image. Deeper layers of ResNets initialized with ImageNet-1K weights and fine-tuned receive more impact from the augmentations than early layers. Understanding the effects of image augmentations on CNNs will have a variety of applications, such as determining how far back one needs to fine-tune a network and which layers should be frozen when implementing layer freezing algorithms.
IndGIC: Supervised Action Recognition under Low Illumination
Aug 29, 2023
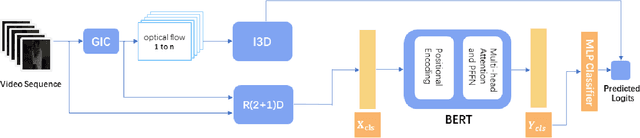
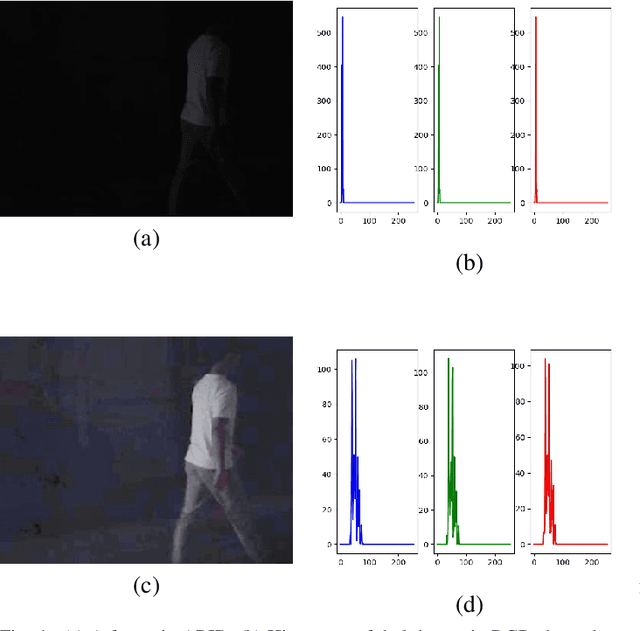
Technologies of human action recognition in the dark are gaining more and more attention as huge demand in surveillance, motion control and human-computer interaction. However, because of limitation in image enhancement method and low-lighting video datasets, e.g. labeling cost, existing methods meet some problems. Some video-based approached are effect and efficient in specific datasets but cannot generalize to most cases while others methods using multiple sensors rely heavily to prior knowledge to deal with noisy nature from video stream. In this paper, we proposes action recognition method using deep multi-input network. Furthermore, we proposed a Independent Gamma Intensity Corretion (Ind-GIC) to enhance poor-illumination video, generating one gamma for one frame to increase enhancement performance. To prove our method is effective, there is some evaluation and comparison between our method and existing methods. Experimental results show that our model achieves high accuracy in on ARID dataset.
Canonical Factors for Hybrid Neural Fields
Aug 29, 2023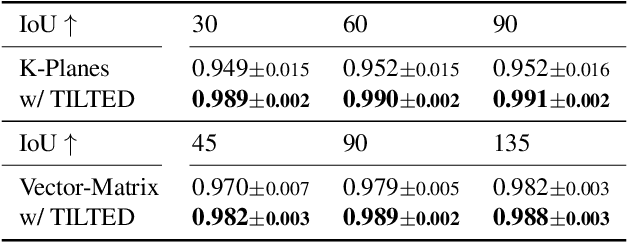
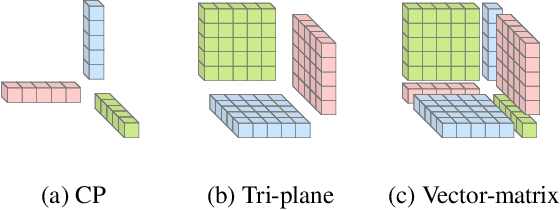

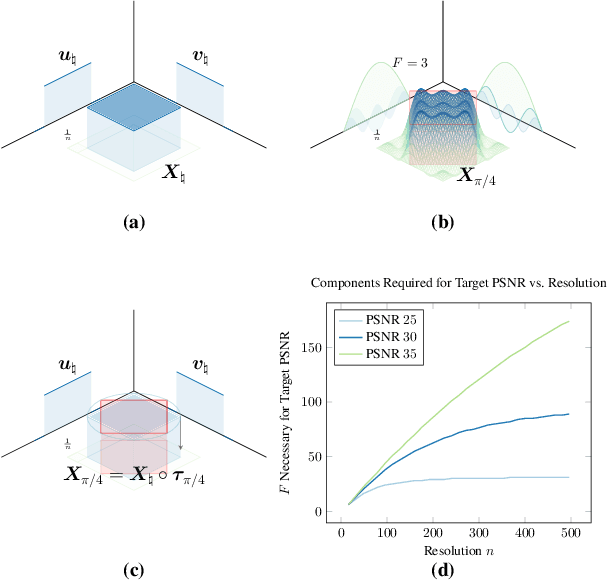
Factored feature volumes offer a simple way to build more compact, efficient, and intepretable neural fields, but also introduce biases that are not necessarily beneficial for real-world data. In this work, we (1) characterize the undesirable biases that these architectures have for axis-aligned signals -- they can lead to radiance field reconstruction differences of as high as 2 PSNR -- and (2) explore how learning a set of canonicalizing transformations can improve representations by removing these biases. We prove in a two-dimensional model problem that simultaneously learning these transformations together with scene appearance succeeds with drastically improved efficiency. We validate the resulting architectures, which we call TILTED, using image, signed distance, and radiance field reconstruction tasks, where we observe improvements across quality, robustness, compactness, and runtime. Results demonstrate that TILTED can enable capabilities comparable to baselines that are 2x larger, while highlighting weaknesses of neural field evaluation procedures.
Zero shot framework for satellite image restoration
Jun 05, 2023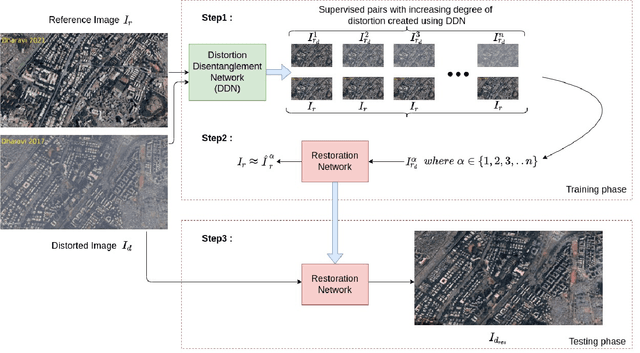


Satellite images are typically subject to multiple distortions. Different factors affect the quality of satellite images, including changes in atmosphere, surface reflectance, sun illumination, viewing geometries etc., limiting its application to downstream tasks. In supervised networks, the availability of paired datasets is a strong assumption. Consequently, many unsupervised algorithms have been proposed to address this problem. These methods synthetically generate a large dataset of degraded images using image formation models. A neural network is then trained with an adversarial loss to discriminate between images from distorted and clean domains. However, these methods yield suboptimal performance when tested on real images that do not necessarily conform to the generation mechanism. Also, they require a large amount of training data and are rendered unsuitable when only a few images are available. We propose a distortion disentanglement and knowledge distillation framework for satellite image restoration to address these important issues. Our algorithm requires only two images: the distorted satellite image to be restored and a reference image with similar semantics. Specifically, we first propose a mechanism to disentangle distortion. This enables us to generate images with varying degrees of distortion using the disentangled distortion and the reference image. We then propose the use of knowledge distillation to train a restoration network using the generated image pairs. As a final step, the distorted image is passed through the restoration network to get the final output. Ablation studies show that our proposed mechanism successfully disentangles distortion.
Prototype-Driven and Multi-Expert Integrated Multi-Modal MR Brain Tumor Image Segmentation
Jul 22, 2023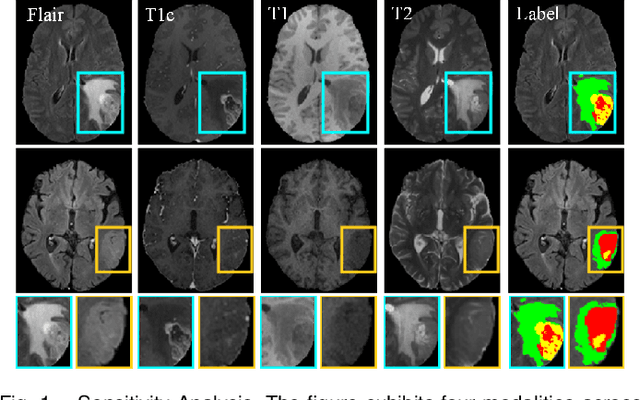
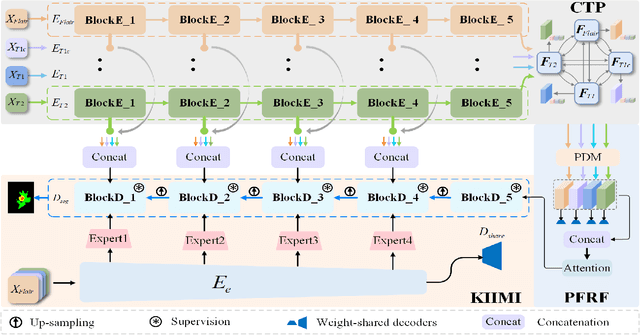
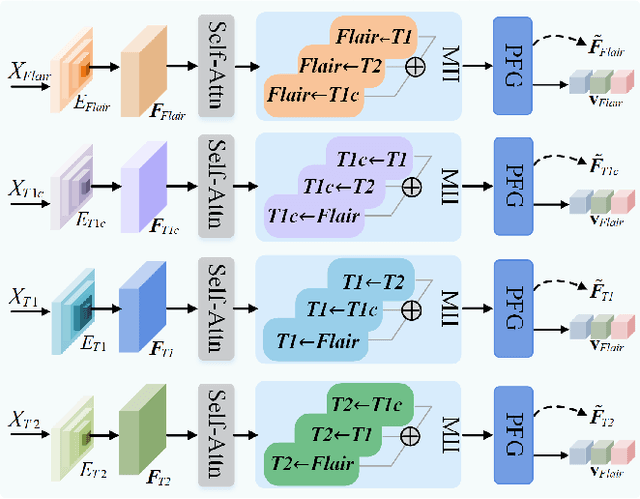
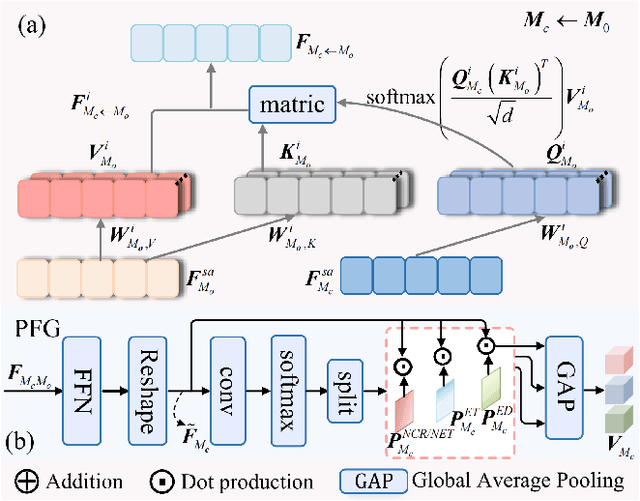
For multi-modal magnetic resonance (MR) brain tumor image segmentation, current methods usually directly extract the discriminative features from input images for tumor sub-region category determination and localization. However, the impact of information aliasing caused by the mutual inclusion of tumor sub-regions is often ignored. Moreover, existing methods usually do not take tailored efforts to highlight the single tumor sub-region features. To this end, a multi-modal MR brain tumor segmentation method with tumor prototype-driven and multi-expert integration is proposed. It could highlight the features of each tumor sub-region under the guidance of tumor prototypes. Specifically, to obtain the prototypes with complete information, we propose a mutual transmission mechanism to transfer different modal features to each other to address the issues raised by insufficient information on single-modal features. Furthermore, we devise a prototype-driven feature representation and fusion method with the learned prototypes, which implants the prototypes into tumor features and generates corresponding activation maps. With the activation maps, the sub-region features consistent with the prototype category can be highlighted. A key information enhancement and fusion strategy with multi-expert integration is designed to further improve the segmentation performance. The strategy can integrate the features from different layers of the extra feature extraction network and the features highlighted by the prototypes. Experimental results on three competition brain tumor segmentation datasets prove the superiority of the proposed method.
Interferometric lensless imaging: rank-one projections of image frequencies with speckle illuminations
Jun 22, 2023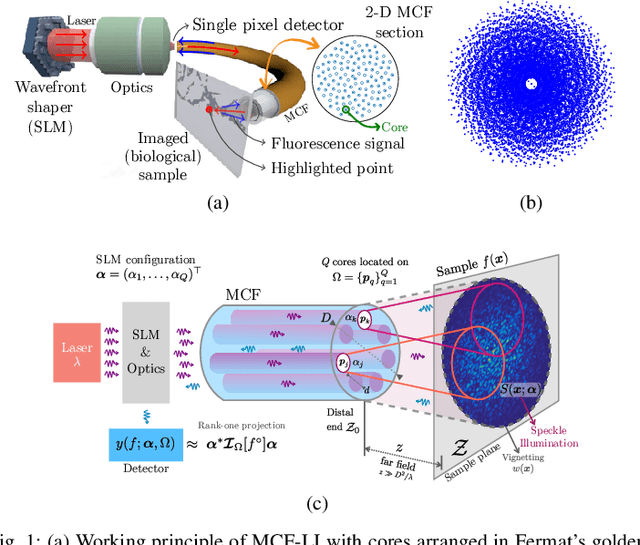
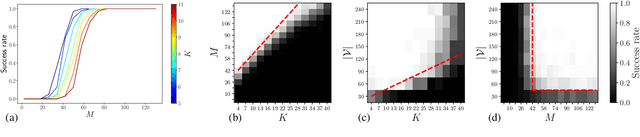

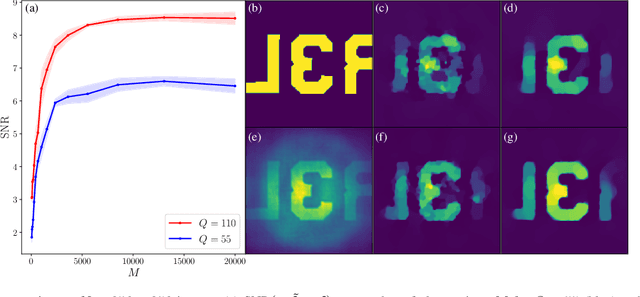
Lensless illumination single-pixel imaging with a multicore fiber (MCF) is a computational imaging technique that enables potential endoscopic observations of biological samples at cellular scale. In this work, we show that this technique is tantamount to collecting multiple symmetric rank-one projections (SROP) of an interferometric matrix--a matrix encoding the spectral content of the sample image. In this model, each SROP is induced by the complex sketching vector shaping the incident light wavefront with a spatial light modulator (SLM), while the projected interferometric matrix collects up to $O(Q^2)$ image frequencies for a $Q$-core MCF. While this scheme subsumes previous sensing modalities, such as raster scanning (RS) imaging with beamformed illumination, we demonstrate that collecting the measurements of $M$ random SLM configurations--and thus acquiring $M$ SROPs--allows us to estimate an image of interest if $M$ and $Q$ scale log-linearly with the image sparsity level This demonstration is achieved both theoretically, with a specific restricted isometry analysis of the sensing scheme, and with extensive Monte Carlo experiments. On a practical side, we perform a single calibration of the sensing system robust to certain deviations to the theoretical model and independent of the sketching vectors used during the imaging phase. Experimental results made on an actual MCF system demonstrate the effectiveness of this imaging procedure on a benchmark image.
Reconstructed Convolution Module Based Look-Up Tables for Efficient Image Super-Resolution
Jul 17, 2023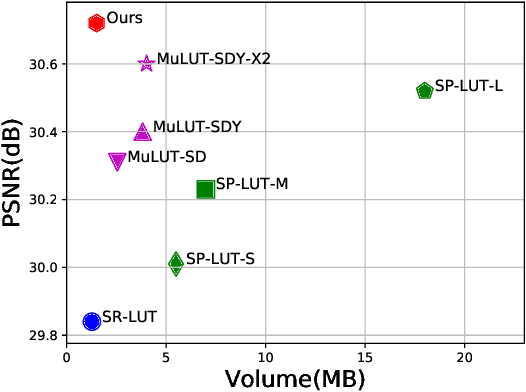
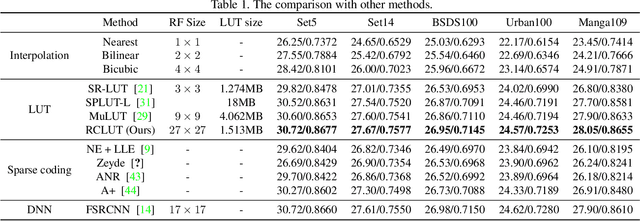
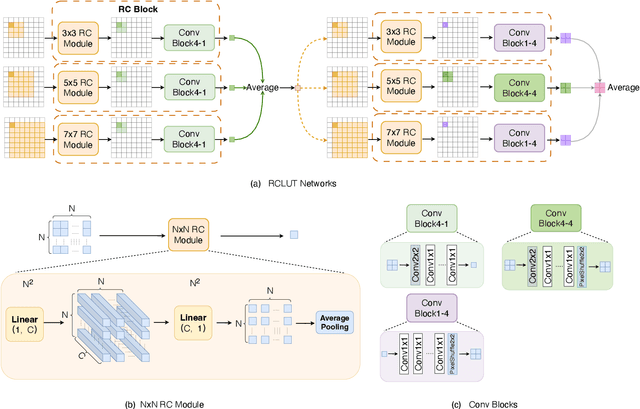

Look-up table(LUT)-based methods have shown the great efficacy in single image super-resolution (SR) task. However, previous methods ignore the essential reason of restricted receptive field (RF) size in LUT, which is caused by the interaction of space and channel features in vanilla convolution. They can only increase the RF at the cost of linearly increasing LUT size. To enlarge RF with contained LUT sizes, we propose a novel Reconstructed Convolution(RC) module, which decouples channel-wise and spatial calculation. It can be formulated as $n^2$ 1D LUTs to maintain $n\times n$ receptive field, which is obviously smaller than $n\times n$D LUT formulated before. The LUT generated by our RC module reaches less than 1/10000 storage compared with SR-LUT baseline. The proposed Reconstructed Convolution module based LUT method, termed as RCLUT, can enlarge the RF size by 9 times than the state-of-the-art LUT-based SR method and achieve superior performance on five popular benchmark dataset. Moreover, the efficient and robust RC module can be used as a plugin to improve other LUT-based SR methods. The code is available at https://github.com/liuguandu/RC-LUT.
Uniformly Distributed Category Prototype-Guided Vision-Language Framework for Long-Tail Recognition
Aug 24, 2023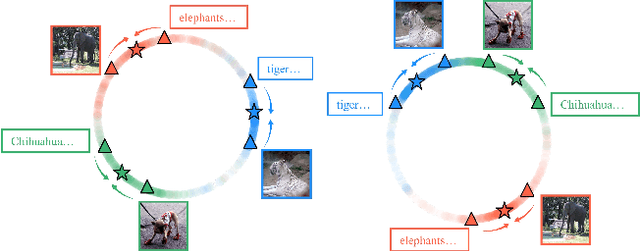
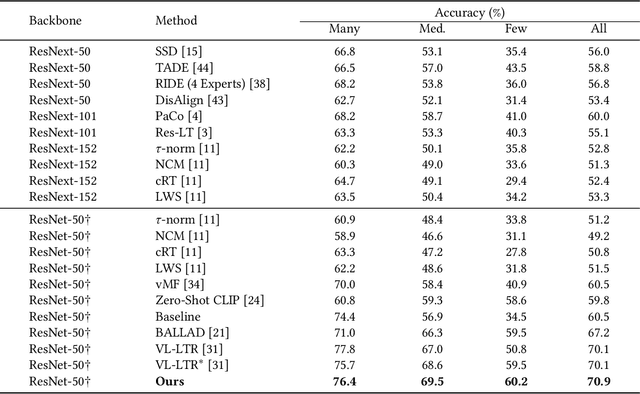
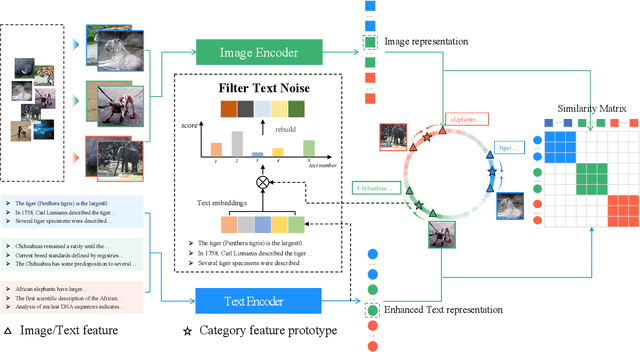
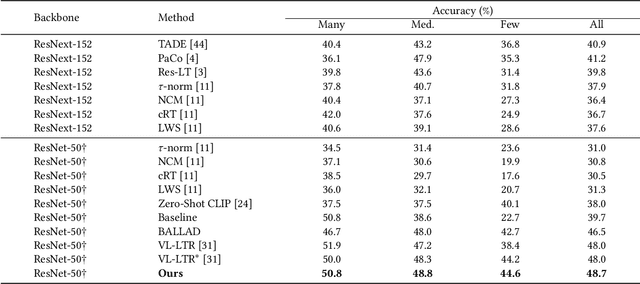
Recently, large-scale pre-trained vision-language models have presented benefits for alleviating class imbalance in long-tailed recognition. However, the long-tailed data distribution can corrupt the representation space, where the distance between head and tail categories is much larger than the distance between two tail categories. This uneven feature space distribution causes the model to exhibit unclear and inseparable decision boundaries on the uniformly distributed test set, which lowers its performance. To address these challenges, we propose the uniformly category prototype-guided vision-language framework to effectively mitigate feature space bias caused by data imbalance. Especially, we generate a set of category prototypes uniformly distributed on a hypersphere. Category prototype-guided mechanism for image-text matching makes the features of different classes converge to these distinct and uniformly distributed category prototypes, which maintain a uniform distribution in the feature space, and improve class boundaries. Additionally, our proposed irrelevant text filtering and attribute enhancement module allows the model to ignore irrelevant noisy text and focus more on key attribute information, thereby enhancing the robustness of our framework. In the image recognition fine-tuning stage, to address the positive bias problem of the learnable classifier, we design the class feature prototype-guided classifier, which compensates for the performance of tail classes while maintaining the performance of head classes. Our method outperforms previous vision-language methods for long-tailed learning work by a large margin and achieves state-of-the-art performance.