 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Coarse-to-Fine Amodal Segmentation with Shape Prior
Aug 31, 2023
Amodal object segmentation is a challenging task that involves segmenting both visible and occluded parts of an object. In this paper, we propose a novel approach, called Coarse-to-Fine Segmentation (C2F-Seg), that addresses this problem by progressively modeling the amodal segmentation. C2F-Seg initially reduces the learning space from the pixel-level image space to the vector-quantized latent space. This enables us to better handle long-range dependencies and learn a coarse-grained amodal segment from visual features and visible segments. However, this latent space lacks detailed information about the object, which makes it difficult to provide a precise segmentation directly. To address this issue, we propose a convolution refine module to inject fine-grained information and provide a more precise amodal object segmentation based on visual features and coarse-predicted segmentation. To help the studies of amodal object segmentation, we create a synthetic amodal dataset, named as MOViD-Amodal (MOViD-A), which can be used for both image and video amodal object segmentation. We extensively evaluate our model on two benchmark datasets: KINS and COCO-A. Our empirical results demonstrate the superiority of C2F-Seg. Moreover, we exhibit the potential of our approach for video amodal object segmentation tasks on FISHBOWL and our proposed MOViD-A. Project page at: http://jianxgao.github.io/C2F-Seg.
From Sky to the Ground: A Large-scale Benchmark and Simple Baseline Towards Real Rain Removal
Aug 18, 2023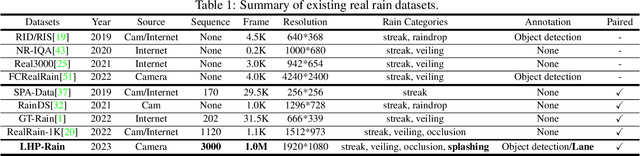
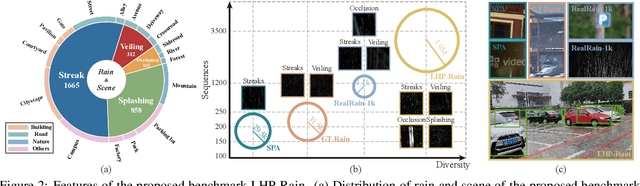
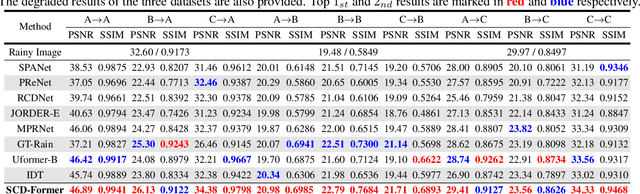

Learning-based image deraining methods have made great progress. However, the lack of large-scale high-quality paired training samples is the main bottleneck to hamper the real image deraining (RID). To address this dilemma and advance RID, we construct a Large-scale High-quality Paired real rain benchmark (LHP-Rain), including 3000 video sequences with 1 million high-resolution (1920*1080) frame pairs. The advantages of the proposed dataset over the existing ones are three-fold: rain with higher-diversity and larger-scale, image with higher-resolution and higher-quality ground-truth. Specifically, the real rains in LHP-Rain not only contain the classical rain streak/veiling/occlusion in the sky, but also the \textbf{splashing on the ground} overlooked by deraining community. Moreover, we propose a novel robust low-rank tensor recovery model to generate the GT with better separating the static background from the dynamic rain. In addition, we design a simple transformer-based single image deraining baseline, which simultaneously utilize the self-attention and cross-layer attention within the image and rain layer with discriminative feature representation. Extensive experiments verify the superiority of the proposed dataset and deraining method over state-of-the-art.
Motion Compensated Unsupervised Deep Learning for 5D MRI
Sep 08, 2023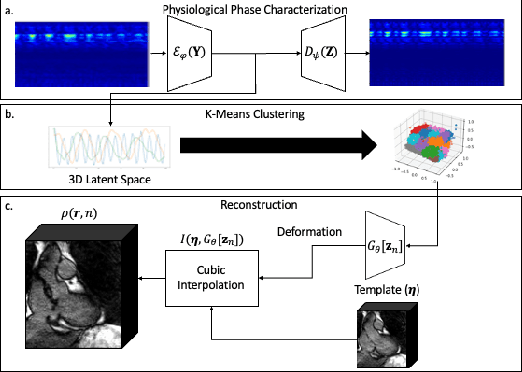
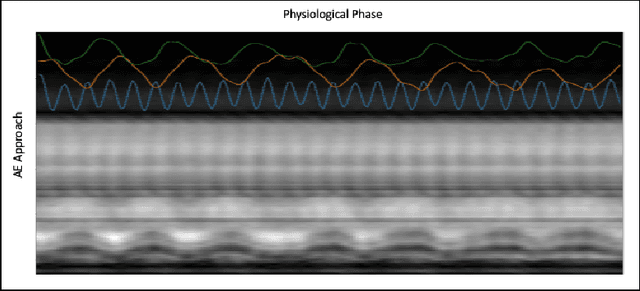
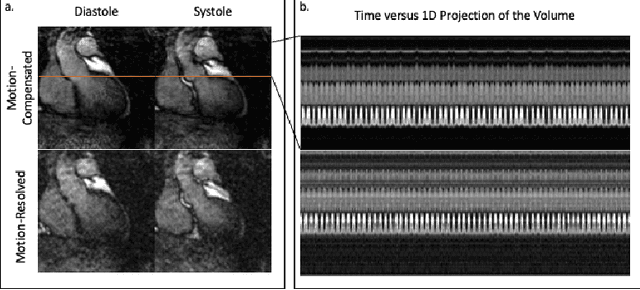
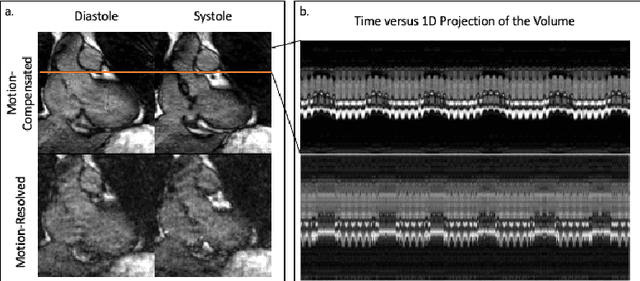
We propose an unsupervised deep learning algorithm for the motion-compensated reconstruction of 5D cardiac MRI data from 3D radial acquisitions. Ungated free-breathing 5D MRI simplifies the scan planning, improves patient comfort, and offers several clinical benefits over breath-held 2D exams, including isotropic spatial resolution and the ability to reslice the data to arbitrary views. However, the current reconstruction algorithms for 5D MRI take very long computational time, and their outcome is greatly dependent on the uniformity of the binning of the acquired data into different physiological phases. The proposed algorithm is a more data-efficient alternative to current motion-resolved reconstructions. This motion-compensated approach models the data in each cardiac/respiratory bin as Fourier samples of the deformed version of a 3D image template. The deformation maps are modeled by a convolutional neural network driven by the physiological phase information. The deformation maps and the template are then jointly estimated from the measured data. The cardiac and respiratory phases are estimated from 1D navigators using an auto-encoder. The proposed algorithm is validated on 5D bSSFP datasets acquired from two subjects.
Adaptive Growth: Real-time CNN Layer Expansion
Sep 06, 2023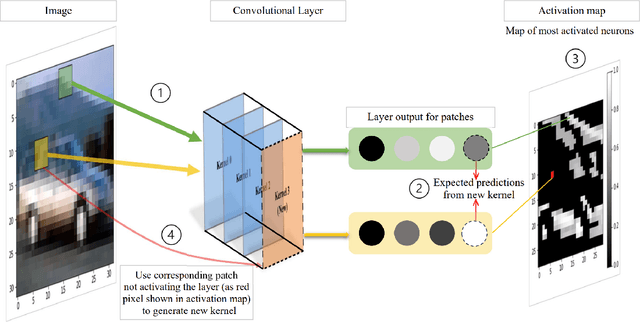
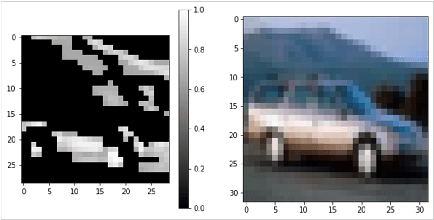
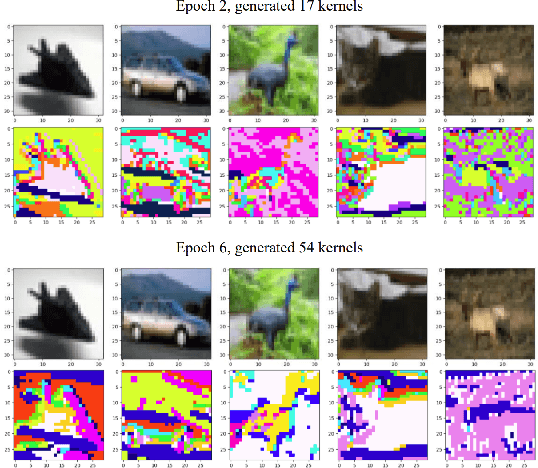
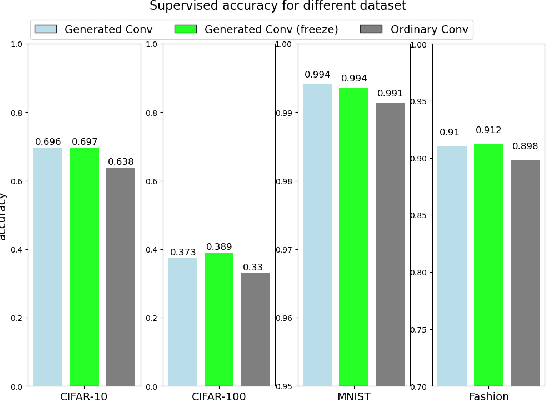
Deep Neural Networks (DNNs) have shown unparalleled achievements in numerous applications, reflecting their proficiency in managing vast data sets. Yet, their static structure limits their adaptability in ever-changing environments. This research presents a new algorithm that allows the convolutional layer of a Convolutional Neural Network (CNN) to dynamically evolve based on data input, while still being seamlessly integrated into existing DNNs. Instead of a rigid architecture, our approach iteratively introduces kernels to the convolutional layer, gauging its real-time response to varying data. This process is refined by evaluating the layer's capacity to discern image features, guiding its growth. Remarkably, our unsupervised method has outstripped its supervised counterparts across diverse datasets like MNIST, Fashion-MNIST, CIFAR-10, and CIFAR-100. It also showcases enhanced adaptability in transfer learning scenarios. By introducing a data-driven model scalability strategy, we are filling a void in deep learning, leading to more flexible and efficient DNNs suited for dynamic settings. Code:(https://github.com/YunjieZhu/Extensible-Convolutional-Layer-git-version).
An Empirical Analysis for Zero-Shot Multi-Label Classification on COVID-19 CT Scans and Uncurated Reports
Sep 06, 2023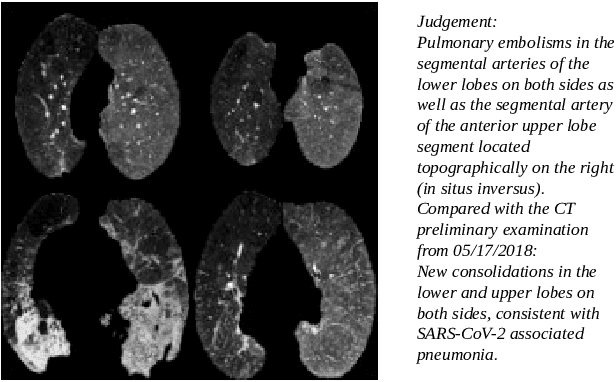

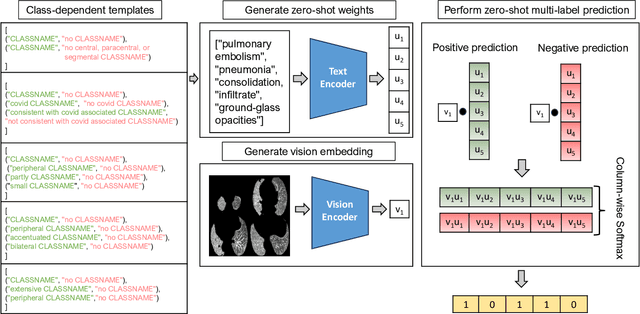
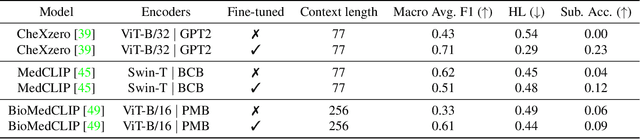
The pandemic resulted in vast repositories of unstructured data, including radiology reports, due to increased medical examinations. Previous research on automated diagnosis of COVID-19 primarily focuses on X-ray images, despite their lower precision compared to computed tomography (CT) scans. In this work, we leverage unstructured data from a hospital and harness the fine-grained details offered by CT scans to perform zero-shot multi-label classification based on contrastive visual language learning. In collaboration with human experts, we investigate the effectiveness of multiple zero-shot models that aid radiologists in detecting pulmonary embolisms and identifying intricate lung details like ground glass opacities and consolidations. Our empirical analysis provides an overview of the possible solutions to target such fine-grained tasks, so far overlooked in the medical multimodal pretraining literature. Our investigation promises future advancements in the medical image analysis community by addressing some challenges associated with unstructured data and fine-grained multi-label classification.
Frequency-Space Prediction Filtering for Phase Aberration Correction in Plane-Wave Ultrasound
Aug 22, 2023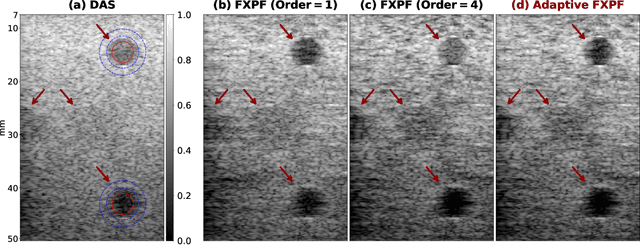
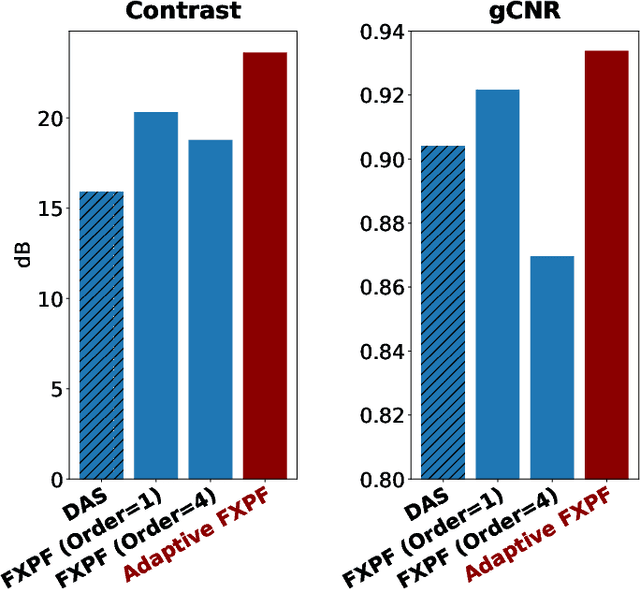
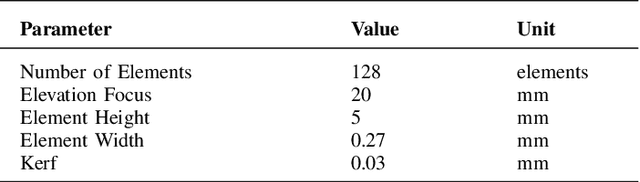
Ultrasound imaging often suffers from image degradation stemming from phase aberration, which represents a significant contributing factor to the overall image degradation in ultrasound imaging. Frequency-space prediction filtering or FXPF is a technique that has been applied within focused ultrasound imaging to alleviate the phase aberration effect. It presupposes the existence of an autoregressive (AR) model across the signals received at the transducer elements and removes any components that do not conform to the established model. In this study, we illustrate the challenge of applying this technique to plane-wave imaging, where, at shallower depths, signals from more distant elements lose relevance, and a fewer number of elements contribute to image reconstruction. While the number of contributing signals varies, adopting a fixed-order AR model across all depths, results in suboptimal performance. To address this challenge, we propose an AR model with an adaptive order and quantify its effectiveness using contrast and generalized contrast-to-noise ratio metrics.
ArtiGrasp: Physically Plausible Synthesis of Bi-Manual Dexterous Grasping and Articulation
Sep 07, 2023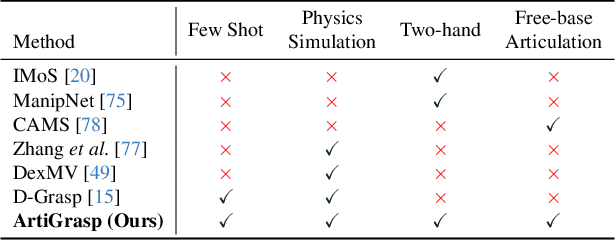
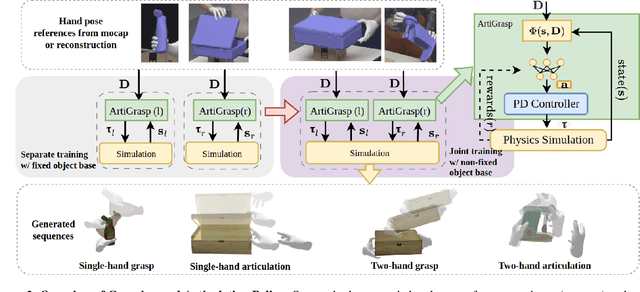
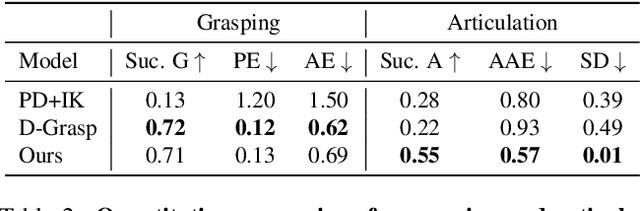
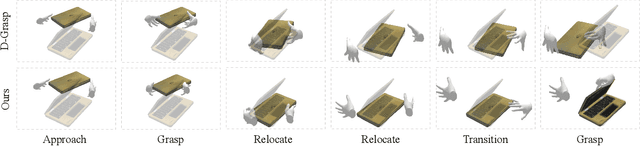
We present ArtiGrasp, a novel method to synthesize bi-manual hand-object interactions that include grasping and articulation. This task is challenging due to the diversity of the global wrist motions and the precise finger control that are necessary to articulate objects. ArtiGrasp leverages reinforcement learning and physics simulations to train a policy that controls the global and local hand pose. Our framework unifies grasping and articulation within a single policy guided by a single hand pose reference. Moreover, to facilitate the training of the precise finger control required for articulation, we present a learning curriculum with increasing difficulty. It starts with single-hand manipulation of stationary objects and continues with multi-agent training including both hands and non-stationary objects. To evaluate our method, we introduce Dynamic Object Grasping and Articulation, a task that involves bringing an object into a target articulated pose. This task requires grasping, relocation, and articulation. We show our method's efficacy towards this task. We further demonstrate that our method can generate motions with noisy hand-object pose estimates from an off-the-shelf image-based regressor.
What to Learn: Features, Image Transformations, or Both?
Jun 22, 2023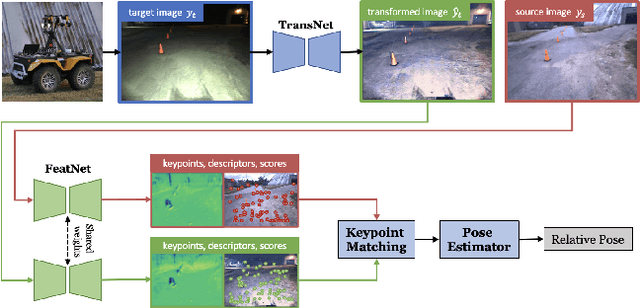
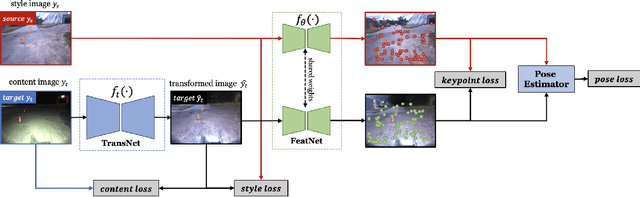

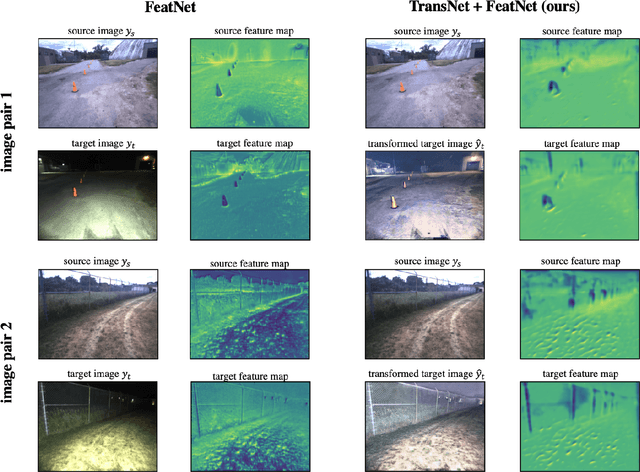
Long-term visual localization is an essential problem in robotics and computer vision, but remains challenging due to the environmental appearance changes caused by lighting and seasons. While many existing works have attempted to solve it by directly learning invariant sparse keypoints and descriptors to match scenes, these approaches still struggle with adverse appearance changes. Recent developments in image transformations such as neural style transfer have emerged as an alternative to address such appearance gaps. In this work, we propose to combine an image transformation network and a feature-learning network to improve long-term localization performance. Given night-to-day image pairs, the image transformation network transforms the night images into day-like conditions prior to feature matching; the feature network learns to detect keypoint locations with their associated descriptor values, which can be passed to a classical pose estimator to compute the relative poses. We conducted various experiments to examine the effectiveness of combining style transfer and feature learning and its training strategy, showing that such a combination greatly improves long-term localization performance.
AnoVL: Adapting Vision-Language Models for Unified Zero-shot Anomaly Localization
Aug 30, 2023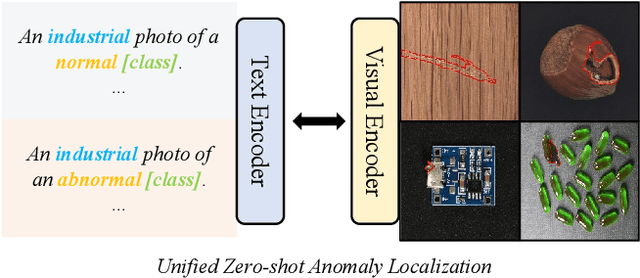
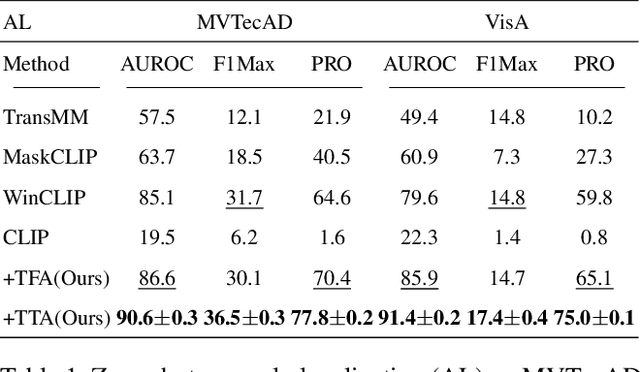
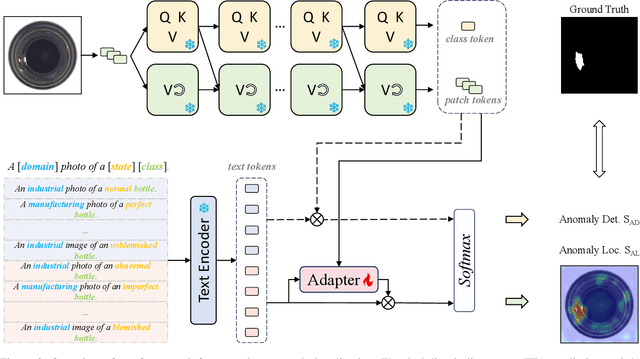
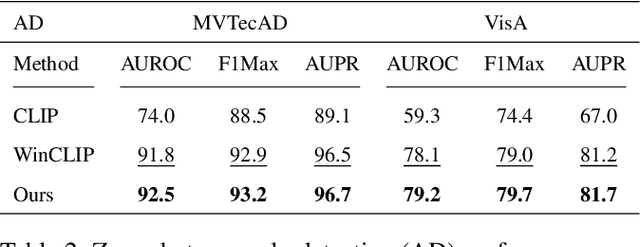
Contrastive Language-Image Pre-training (CLIP) models have shown promising performance on zero-shot visual recognition tasks by learning visual representations under natural language supervision. Recent studies attempt the use of CLIP to tackle zero-shot anomaly detection by matching images with normal and abnormal state prompts. However, since CLIP focuses on building correspondence between paired text prompts and global image-level representations, the lack of patch-level vision to text alignment limits its capability on precise visual anomaly localization. In this work, we introduce a training-free adaptation (TFA) framework of CLIP for zero-shot anomaly localization. In the visual encoder, we innovate a training-free value-wise attention mechanism to extract intrinsic local tokens of CLIP for patch-level local description. From the perspective of text supervision, we particularly design a unified domain-aware contrastive state prompting template. On top of the proposed TFA, we further introduce a test-time adaptation (TTA) mechanism to refine anomaly localization results, where a layer of trainable parameters in the adapter is optimized using TFA's pseudo-labels and synthetic noise-corrupted tokens. With both TFA and TTA adaptation, we significantly exploit the potential of CLIP for zero-shot anomaly localization and demonstrate the effectiveness of our proposed methods on various datasets.
NaturalInversion: Data-Free Image Synthesis Improving Real-World Consistency
Jun 29, 2023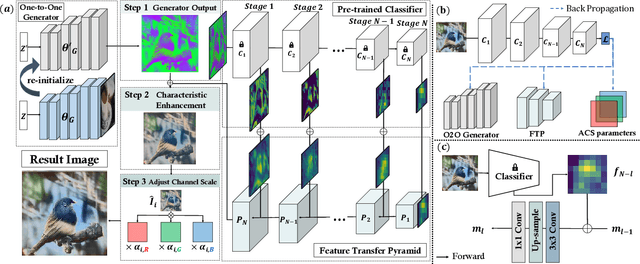
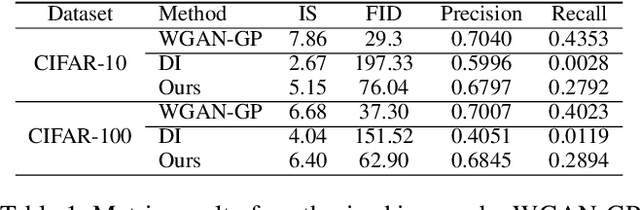

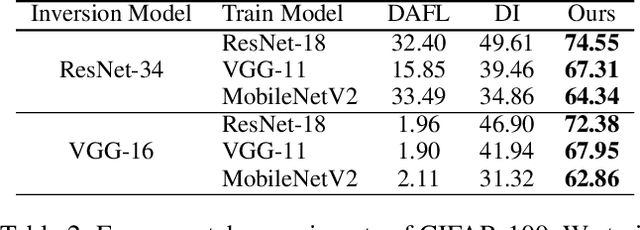
We introduce NaturalInversion, a novel model inversion-based method to synthesize images that agrees well with the original data distribution without using real data. In NaturalInversion, we propose: (1) a Feature Transfer Pyramid which uses enhanced image prior of the original data by combining the multi-scale feature maps extracted from the pre-trained classifier, (2) a one-to-one approach generative model where only one batch of images are synthesized by one generator to bring the non-linearity to optimization and to ease the overall optimizing process, (3) learnable Adaptive Channel Scaling parameters which are end-to-end trained to scale the output image channel to utilize the original image prior further. With our NaturalInversion, we synthesize images from classifiers trained on CIFAR-10/100 and show that our images are more consistent with original data distribution than prior works by visualization and additional analysis. Furthermore, our synthesized images outperform prior works on various applications such as knowledge distillation and pruning, demonstrating the effectiveness of our proposed method.
* Published at AAAI 2022