 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Supervised Deep Learning for Content-Aware Image Retargeting with Fourier Convolutions
Jun 12, 2023
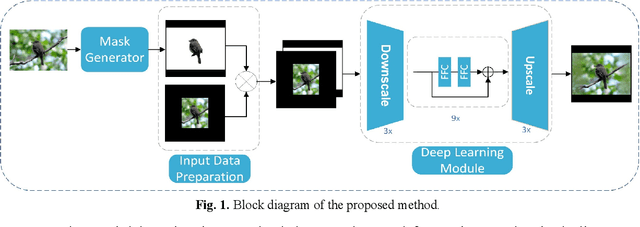


Image retargeting aims to alter the size of the image with attention to the contents. One of the main obstacles to training deep learning models for image retargeting is the need for a vast labeled dataset. Labeled datasets are unavailable for training deep learning models in the image retargeting tasks. As a result, we present a new supervised approach for training deep learning models. We use the original images as ground truth and create inputs for the model by resizing and cropping the original images. A second challenge is generating different image sizes in inference time. However, regular convolutional neural networks cannot generate images of different sizes than the input image. To address this issue, we introduced a new method for supervised learning. In our approach, a mask is generated to show the desired size and location of the object. Then the mask and the input image are fed to the network. Comparing image retargeting methods and our proposed method demonstrates the model's ability to produce high-quality retargeted images. Afterward, we compute the image quality assessment score for each output image based on different techniques and illustrate the effectiveness of our approach.
NeO 360: Neural Fields for Sparse View Synthesis of Outdoor Scenes
Aug 24, 2023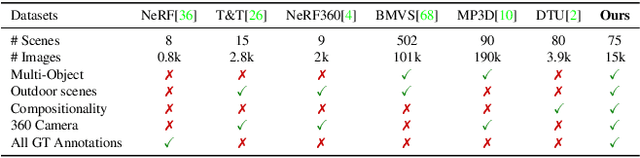

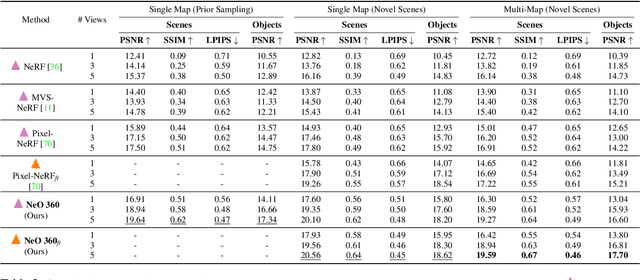
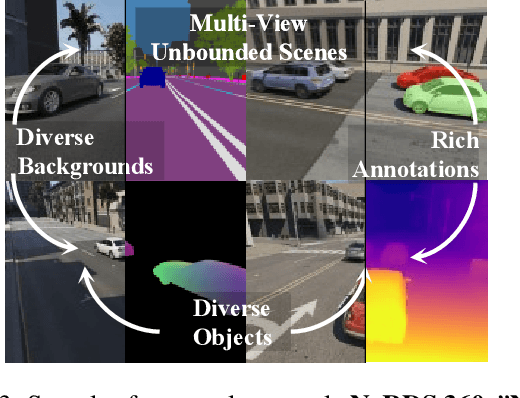
Recent implicit neural representations have shown great results for novel view synthesis. However, existing methods require expensive per-scene optimization from many views hence limiting their application to real-world unbounded urban settings where the objects of interest or backgrounds are observed from very few views. To mitigate this challenge, we introduce a new approach called NeO 360, Neural fields for sparse view synthesis of outdoor scenes. NeO 360 is a generalizable method that reconstructs 360{\deg} scenes from a single or a few posed RGB images. The essence of our approach is in capturing the distribution of complex real-world outdoor 3D scenes and using a hybrid image-conditional triplanar representation that can be queried from any world point. Our representation combines the best of both voxel-based and bird's-eye-view (BEV) representations and is more effective and expressive than each. NeO 360's representation allows us to learn from a large collection of unbounded 3D scenes while offering generalizability to new views and novel scenes from as few as a single image during inference. We demonstrate our approach on the proposed challenging 360{\deg} unbounded dataset, called NeRDS 360, and show that NeO 360 outperforms state-of-the-art generalizable methods for novel view synthesis while also offering editing and composition capabilities. Project page: https://zubair-irshad.github.io/projects/neo360.html
Diffusion Models with Deterministic Normalizing Flow Priors
Sep 03, 2023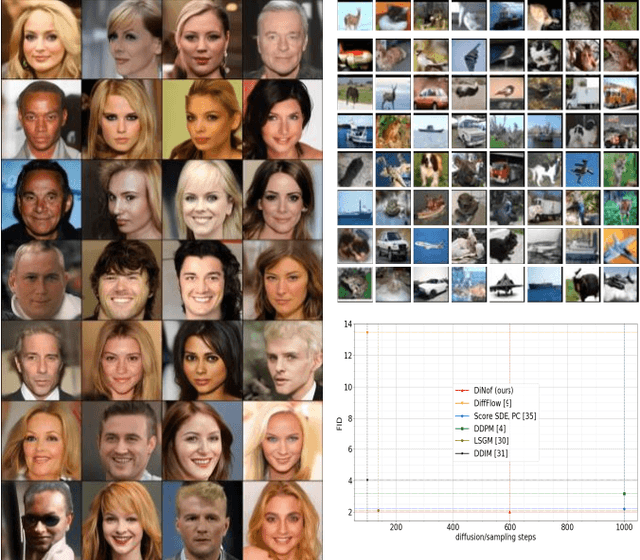
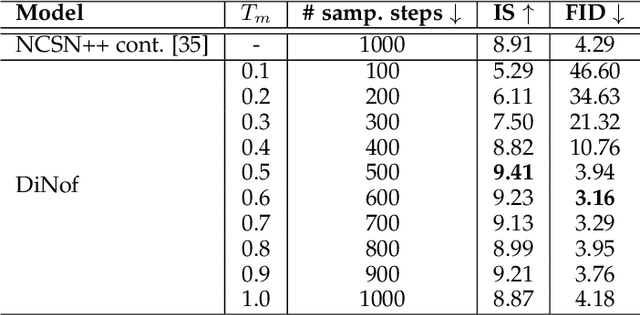
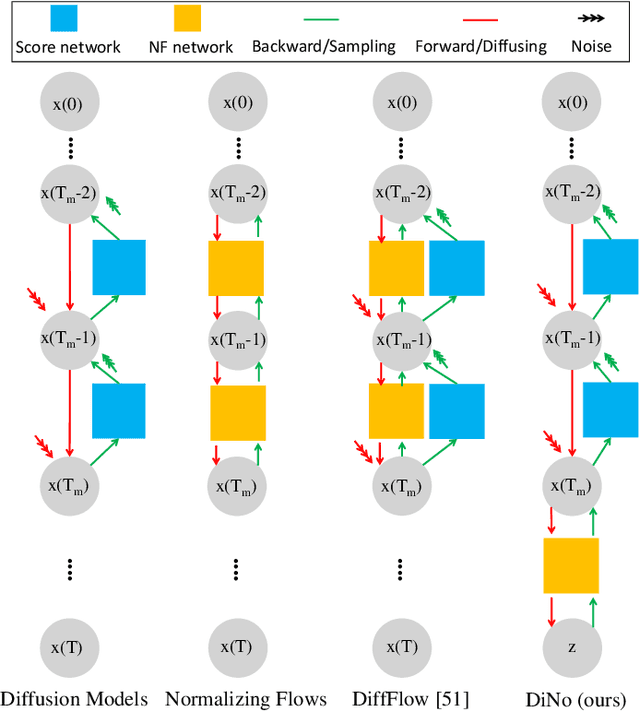
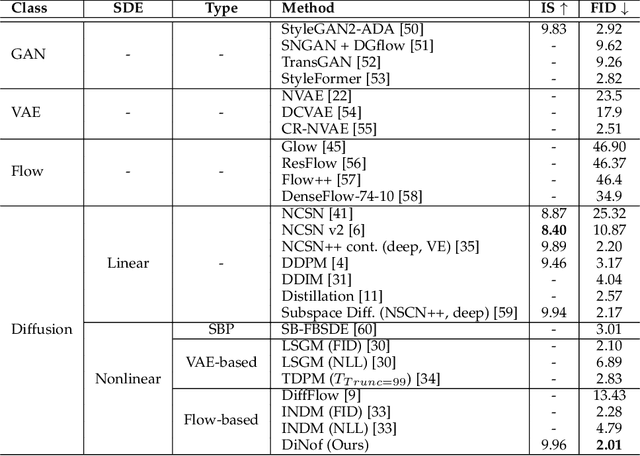
For faster sampling and higher sample quality, we propose DiNof ($\textbf{Di}$ffusion with $\textbf{No}$rmalizing $\textbf{f}$low priors), a technique that makes use of normalizing flows and diffusion models. We use normalizing flows to parameterize the noisy data at any arbitrary step of the diffusion process and utilize it as the prior in the reverse diffusion process. More specifically, the forward noising process turns a data distribution into partially noisy data, which are subsequently transformed into a Gaussian distribution by a nonlinear process. The backward denoising procedure begins with a prior created by sampling from the Gaussian distribution and applying the invertible normalizing flow transformations deterministically. To generate the data distribution, the prior then undergoes the remaining diffusion stochastic denoising procedure. Through the reduction of the number of total diffusion steps, we are able to speed up both the forward and backward processes. More importantly, we improve the expressive power of diffusion models by employing both deterministic and stochastic mappings. Experiments on standard image generation datasets demonstrate the advantage of the proposed method over existing approaches. On the unconditional CIFAR10 dataset, for example, we achieve an FID of 2.01 and an Inception score of 9.96. Our method also demonstrates competitive performance on CelebA-HQ-256 dataset as it obtains an FID score of 7.11. Code is available at https://github.com/MohsenZand/DiNof.
Traveling Waves Encode the Recent Past and Enhance Sequence Learning
Sep 03, 2023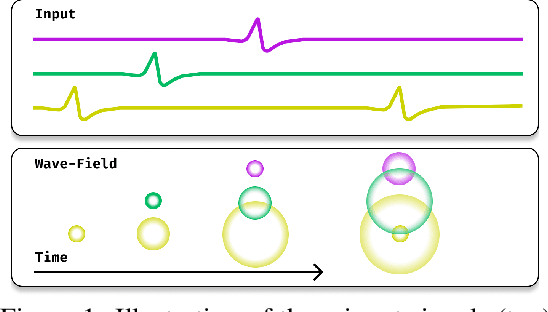

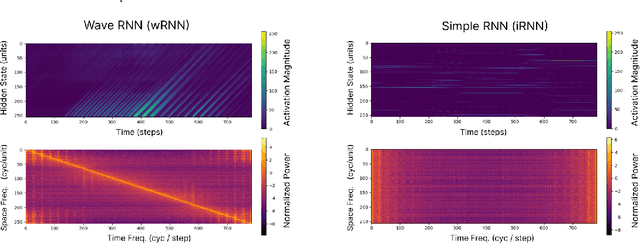
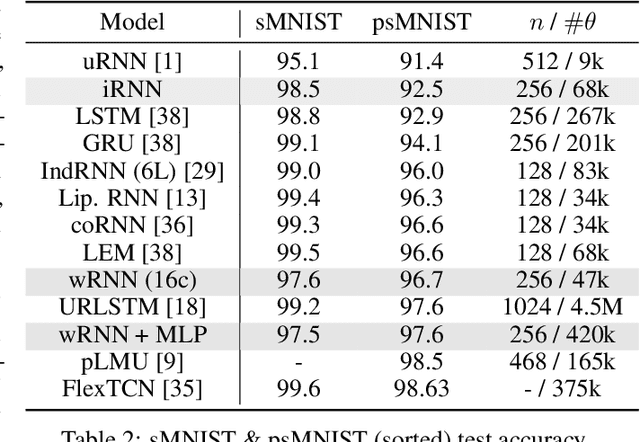
Traveling waves of neural activity have been observed throughout the brain at a diversity of regions and scales; however, their precise computational role is still debated. One physically grounded hypothesis suggests that the cortical sheet may act like a wave-field capable of storing a short-term memory of sequential stimuli through induced waves traveling across the cortical surface. To date, however, the computational implications of this idea have remained hypothetical due to the lack of a simple recurrent neural network architecture capable of exhibiting such waves. In this work, we introduce a model to fill this gap, which we denote the Wave-RNN (wRNN), and demonstrate how both connectivity constraints and initialization play a crucial role in the emergence of wave-like dynamics. We then empirically show how such an architecture indeed efficiently encodes the recent past through a suite of synthetic memory tasks where wRNNs learn faster and perform significantly better than wave-free counterparts. Finally, we explore the implications of this memory storage system on more complex sequence modeling tasks such as sequential image classification and find that wave-based models not only again outperform comparable wave-free RNNs while using significantly fewer parameters, but additionally perform comparably to more complex gated architectures such as LSTMs and GRUs. We conclude with a discussion of the implications of these results for both neuroscience and machine learning.
TeCH: Text-guided Reconstruction of Lifelike Clothed Humans
Aug 19, 2023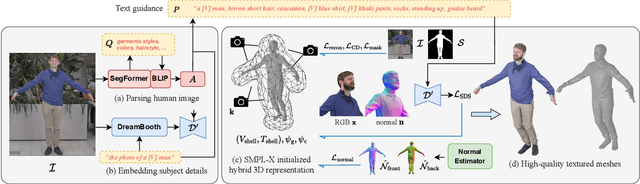

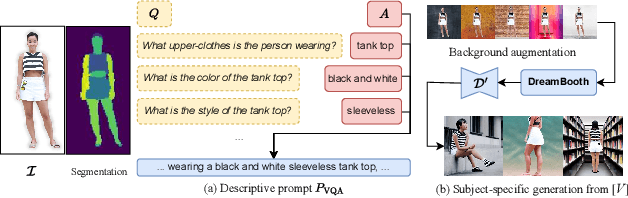
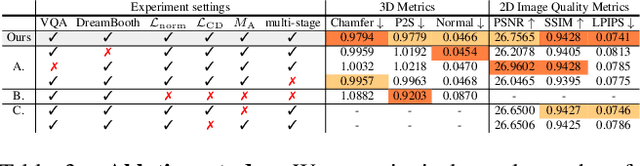
Despite recent research advancements in reconstructing clothed humans from a single image, accurately restoring the "unseen regions" with high-level details remains an unsolved challenge that lacks attention. Existing methods often generate overly smooth back-side surfaces with a blurry texture. But how to effectively capture all visual attributes of an individual from a single image, which are sufficient to reconstruct unseen areas (e.g., the back view)? Motivated by the power of foundation models, TeCH reconstructs the 3D human by leveraging 1) descriptive text prompts (e.g., garments, colors, hairstyles) which are automatically generated via a garment parsing model and Visual Question Answering (VQA), 2) a personalized fine-tuned Text-to-Image diffusion model (T2I) which learns the "indescribable" appearance. To represent high-resolution 3D clothed humans at an affordable cost, we propose a hybrid 3D representation based on DMTet, which consists of an explicit body shape grid and an implicit distance field. Guided by the descriptive prompts + personalized T2I diffusion model, the geometry and texture of the 3D humans are optimized through multi-view Score Distillation Sampling (SDS) and reconstruction losses based on the original observation. TeCH produces high-fidelity 3D clothed humans with consistent & delicate texture, and detailed full-body geometry. Quantitative and qualitative experiments demonstrate that TeCH outperforms the state-of-the-art methods in terms of reconstruction accuracy and rendering quality. The code will be publicly available for research purposes at https://huangyangyi.github.io/TeCH
Learning to Distill Global Representation for Sparse-View CT
Aug 19, 2023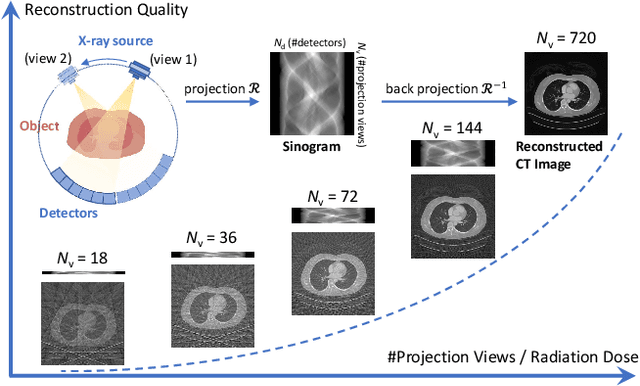
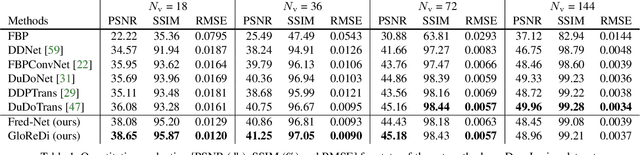
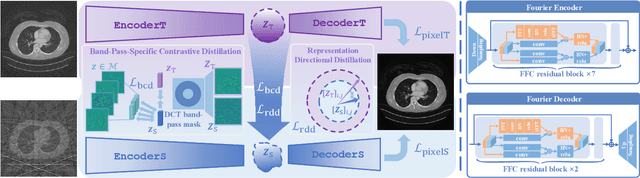
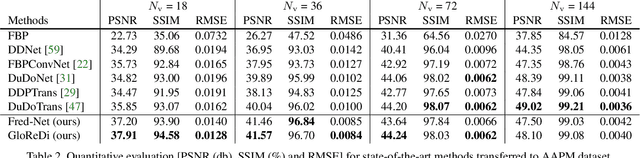
Sparse-view computed tomography (CT) -- using a small number of projections for tomographic reconstruction -- enables much lower radiation dose to patients and accelerated data acquisition. The reconstructed images, however, suffer from strong artifacts, greatly limiting their diagnostic value. Current trends for sparse-view CT turn to the raw data for better information recovery. The resultant dual-domain methods, nonetheless, suffer from secondary artifacts, especially in ultra-sparse view scenarios, and their generalization to other scanners/protocols is greatly limited. A crucial question arises: have the image post-processing methods reached the limit? Our answer is not yet. In this paper, we stick to image post-processing methods due to great flexibility and propose global representation (GloRe) distillation framework for sparse-view CT, termed GloReDi. First, we propose to learn GloRe with Fourier convolution, so each element in GloRe has an image-wide receptive field. Second, unlike methods that only use the full-view images for supervision, we propose to distill GloRe from intermediate-view reconstructed images that are readily available but not explored in previous literature. The success of GloRe distillation is attributed to two key components: representation directional distillation to align the GloRe directions, and band-pass-specific contrastive distillation to gain clinically important details. Extensive experiments demonstrate the superiority of the proposed GloReDi over the state-of-the-art methods, including dual-domain ones. The source code is available at https://github.com/longzilicart/GloReDi.
Ensemble of Anchor-Free Models for Robust Bangla Document Layout Segmentation
Aug 29, 2023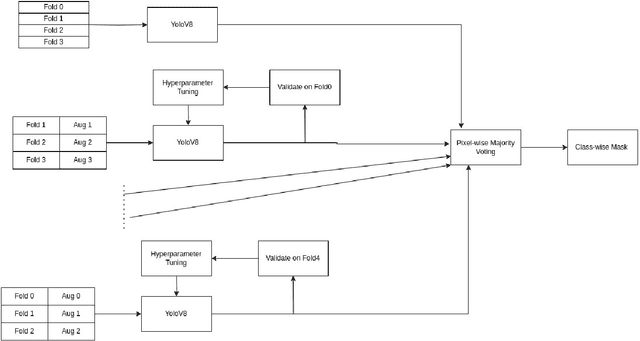
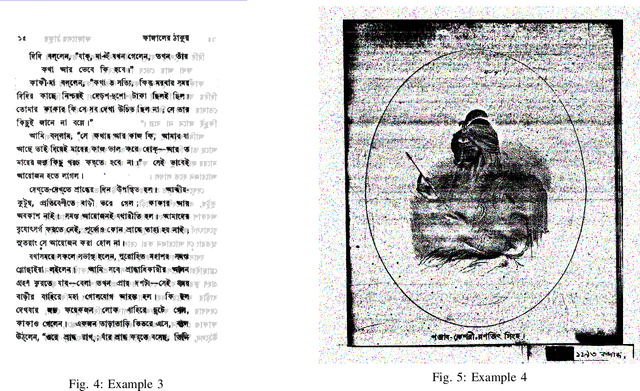
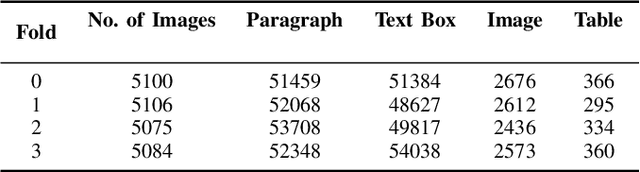
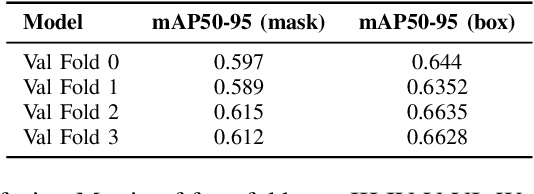
In this research paper, we introduce a novel approach designed for the purpose of segmenting the layout of Bangla documents. Our methodology involves the utilization of a sophisticated ensemble of YOLOv8 models, which were trained for the DL Sprint 2.0 - BUET CSE Fest 2023 Competition focused on Bangla document layout segmentation. Our primary emphasis lies in enhancing various aspects of the task, including techniques such as image augmentation, model architecture, and the incorporation of model ensembles. We deliberately reduce the quality of a subset of document images to enhance the resilience of model training, thereby resulting in an improvement in our cross-validation score. By employing Bayesian optimization, we determine the optimal confidence and Intersection over Union (IoU) thresholds for our model ensemble. Through our approach, we successfully demonstrate the effectiveness of anchor-free models in achieving robust layout segmentation in Bangla documents.
Partition-and-Debias: Agnostic Biases Mitigation via A Mixture of Biases-Specific Experts
Aug 19, 2023Bias mitigation in image classification has been widely researched, and existing methods have yielded notable results. However, most of these methods implicitly assume that a given image contains only one type of known or unknown bias, failing to consider the complexities of real-world biases. We introduce a more challenging scenario, agnostic biases mitigation, aiming at bias removal regardless of whether the type of bias or the number of types is unknown in the datasets. To address this difficult task, we present the Partition-and-Debias (PnD) method that uses a mixture of biases-specific experts to implicitly divide the bias space into multiple subspaces and a gating module to find a consensus among experts to achieve debiased classification. Experiments on both public and constructed benchmarks demonstrated the efficacy of the PnD. Code is available at: https://github.com/Jiaxuan-Li/PnD.
Minimum Description Length Clustering to Measure Meaningful Image Complexity
Jun 26, 2023Existing image complexity metrics cannot distinguish meaningful content from noise. This means that white noise images, which contain no meaningful information, are judged as highly complex. We present a new image complexity metric through hierarchical clustering of patches. We use the minimum description length principle to determine the number of clusters and designate certain points as outliers and, hence, correctly assign white noise a low score. The presented method has similarities to theoretical ideas for measuring meaningful complexity. We conduct experiments on seven different sets of images, which show that our method assigns the most accurate scores to all images considered. Additionally, comparing the different levels of the hierarchy of clusters can reveal how complexity manifests at different scales, from local detail to global structure. We then present ablation studies showing the contribution of the components of our method, and that it continues to assign reasonable scores when the inputs are modified in certain ways, including the addition of Gaussian noise and the lowering of the resolution.
A Study on the Impact of Face Image Quality on Face Recognition in the Wild
Jul 05, 2023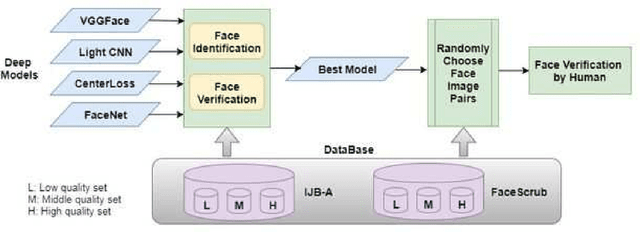



Deep learning has received increasing interests in face recognition recently. Large quantities of deep learning methods have been proposed to handle various problems appeared in face recognition. Quite a lot deep methods claimed that they have gained or even surpassed human-level face verification performance in certain databases. As we know, face image quality poses a great challenge to traditional face recognition methods, e.g. model-driven methods with hand-crafted features. However, a little research focus on the impact of face image quality on deep learning methods, and even human performance. Therefore, we raise a question: Is face image quality still one of the challenges for deep learning based face recognition, especially in unconstrained condition. Based on this, we further investigate this problem on human level. In this paper, we partition face images into three different quality sets to evaluate the performance of deep learning methods on cross-quality face images in the wild, and then design a human face verification experiment on these cross-quality data. The result indicates that quality issue still needs to be studied thoroughly in deep learning, human own better capability in building the relations between different face images with large quality gaps, and saying deep learning method surpasses human-level is too optimistic.