 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hierarchical Matching and Reasoning for Multi-Query Image Retrieval
Jun 26, 2023

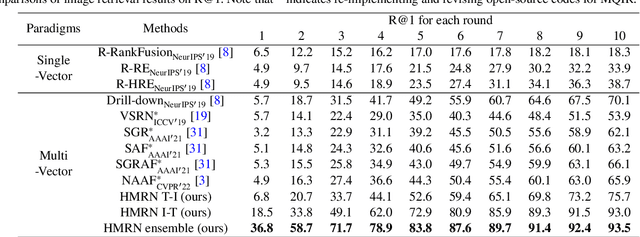
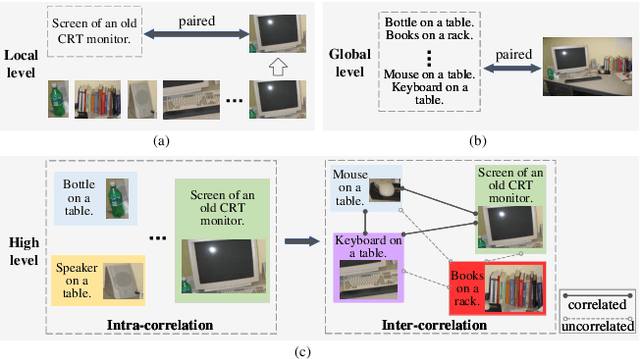
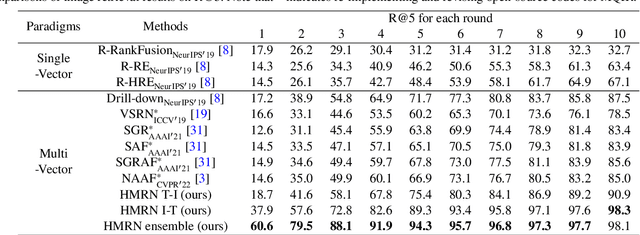
As a promising field, Multi-Query Image Retrieval (MQIR) aims at searching for the semantically relevant image given multiple region-specific text queries. Existing works mainly focus on a single-level similarity between image regions and text queries, which neglects the hierarchical guidance of multi-level similarities and results in incomplete alignments. Besides, the high-level semantic correlations that intrinsically connect different region-query pairs are rarely considered. To address above limitations, we propose a novel Hierarchical Matching and Reasoning Network (HMRN) for MQIR. It disentangles MQIR into three hierarchical semantic representations, which is responsible to capture fine-grained local details, contextual global scopes, and high-level inherent correlations. HMRN comprises two modules: Scalar-based Matching (SM) module and Vector-based Reasoning (VR) module. Specifically, the SM module characterizes the multi-level alignment similarity, which consists of a fine-grained local-level similarity and a context-aware global-level similarity. Afterwards, the VR module is developed to excavate the potential semantic correlations among multiple region-query pairs, which further explores the high-level reasoning similarity. Finally, these three-level similarities are aggregated into a joint similarity space to form the ultimate similarity. Extensive experiments on the benchmark dataset demonstrate that our HMRN substantially surpasses the current state-of-the-art methods. For instance, compared with the existing best method Drill-down, the metric R@1 in the last round is improved by 23.4%. Our source codes will be released at https://github.com/LZH-053/HMRN.
A Semi-Paired Approach For Label-to-Image Translation
Jun 23, 2023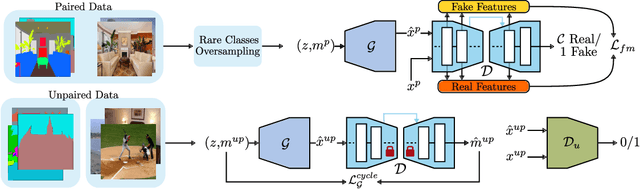
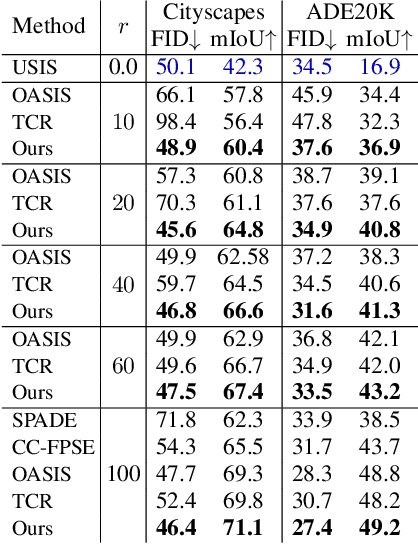

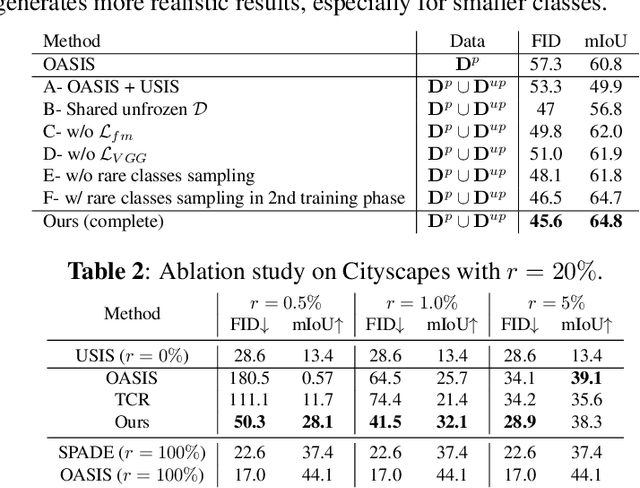
Data efficiency, or the ability to generalize from a few labeled data, remains a major challenge in deep learning. Semi-supervised learning has thrived in traditional recognition tasks alleviating the need for large amounts of labeled data, yet it remains understudied in image-to-image translation (I2I) tasks. In this work, we introduce the first semi-supervised (semi-paired) framework for label-to-image translation, a challenging subtask of I2I which generates photorealistic images from semantic label maps. In the semi-paired setting, the model has access to a small set of paired data and a larger set of unpaired images and labels. Instead of using geometrical transformations as a pretext task like previous works, we leverage an input reconstruction task by exploiting the conditional discriminator on the paired data as a reverse generator. We propose a training algorithm for this shared network, and we present a rare classes sampling algorithm to focus on under-represented classes. Experiments on 3 standard benchmarks show that the proposed model outperforms state-of-the-art unsupervised and semi-supervised approaches, as well as some fully supervised approaches while using a much smaller number of paired samples.
Ensemble of Anchor-Free Models for Robust Bangla Document Layout Segmentation
Aug 29, 2023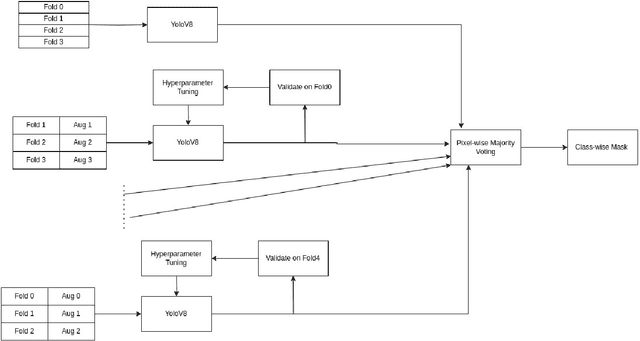
In this research paper, we introduce a novel approach designed for the purpose of segmenting the layout of Bangla documents. Our methodology involves the utilization of a sophisticated ensemble of YOLOv8 models, which were trained for the DL Sprint 2.0 - BUET CSE Fest 2023 Competition focused on Bangla document layout segmentation. Our primary emphasis lies in enhancing various aspects of the task, including techniques such as image augmentation, model architecture, and the incorporation of model ensembles. We deliberately reduce the quality of a subset of document images to enhance the resilience of model training, thereby resulting in an improvement in our cross-validation score. By employing Bayesian optimization, we determine the optimal confidence and Intersection over Union (IoU) thresholds for our model ensemble. Through our approach, we successfully demonstrate the effectiveness of anchor-free models in achieving robust layout segmentation in Bangla documents.
NeO 360: Neural Fields for Sparse View Synthesis of Outdoor Scenes
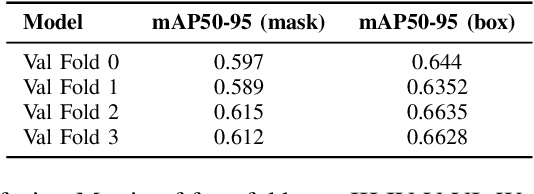
Aug 24, 2023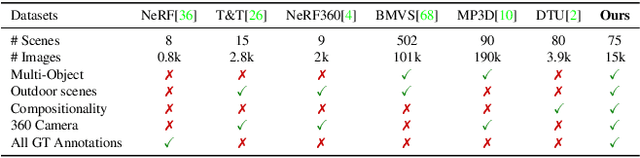

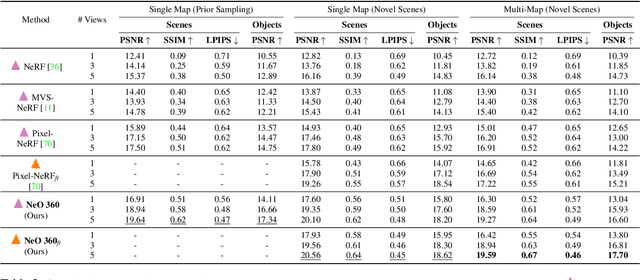
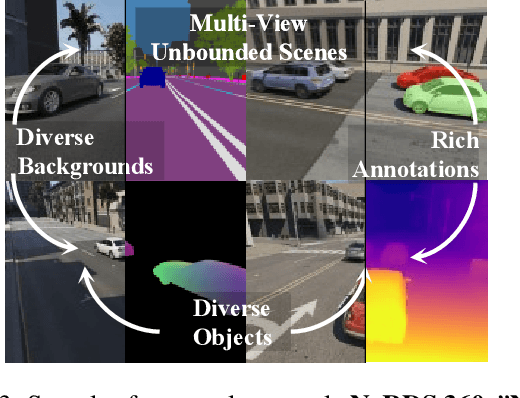
Recent implicit neural representations have shown great results for novel view synthesis. However, existing methods require expensive per-scene optimization from many views hence limiting their application to real-world unbounded urban settings where the objects of interest or backgrounds are observed from very few views. To mitigate this challenge, we introduce a new approach called NeO 360, Neural fields for sparse view synthesis of outdoor scenes. NeO 360 is a generalizable method that reconstructs 360{\deg} scenes from a single or a few posed RGB images. The essence of our approach is in capturing the distribution of complex real-world outdoor 3D scenes and using a hybrid image-conditional triplanar representation that can be queried from any world point. Our representation combines the best of both voxel-based and bird's-eye-view (BEV) representations and is more effective and expressive than each. NeO 360's representation allows us to learn from a large collection of unbounded 3D scenes while offering generalizability to new views and novel scenes from as few as a single image during inference. We demonstrate our approach on the proposed challenging 360{\deg} unbounded dataset, called NeRDS 360, and show that NeO 360 outperforms state-of-the-art generalizable methods for novel view synthesis while also offering editing and composition capabilities. Project page: https://zubair-irshad.github.io/projects/neo360.html
Generative Approach for Probabilistic Human Mesh Recovery using Diffusion Models
Aug 16, 2023
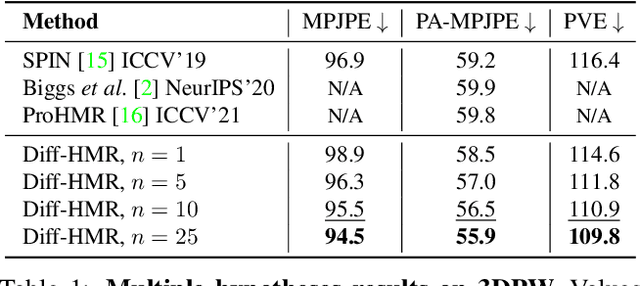
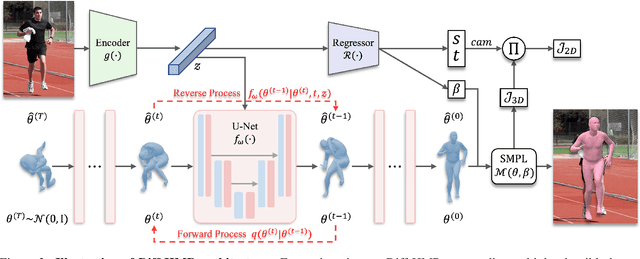

This work focuses on the problem of reconstructing a 3D human body mesh from a given 2D image. Despite the inherent ambiguity of the task of human mesh recovery, most existing works have adopted a method of regressing a single output. In contrast, we propose a generative approach framework, called "Diffusion-based Human Mesh Recovery (Diff-HMR)" that takes advantage of the denoising diffusion process to account for multiple plausible outcomes. During the training phase, the SMPL parameters are diffused from ground-truth parameters to random distribution, and Diff-HMR learns the reverse process of this diffusion. In the inference phase, the model progressively refines the given random SMPL parameters into the corresponding parameters that align with the input image. Diff-HMR, being a generative approach, is capable of generating diverse results for the same input image as the input noise varies. We conduct validation experiments, and the results demonstrate that the proposed framework effectively models the inherent ambiguity of the task of human mesh recovery in a probabilistic manner. The code is available at https://github.com/hanbyel0105/Diff-HMR
Label Denoising through Cross-Model Agreement
Sep 01, 2023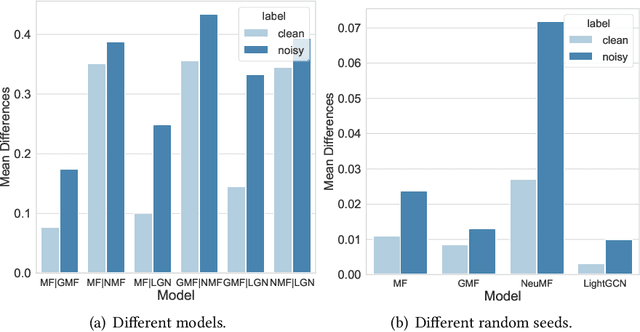
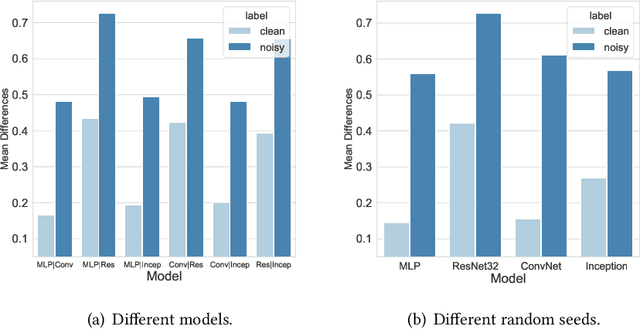
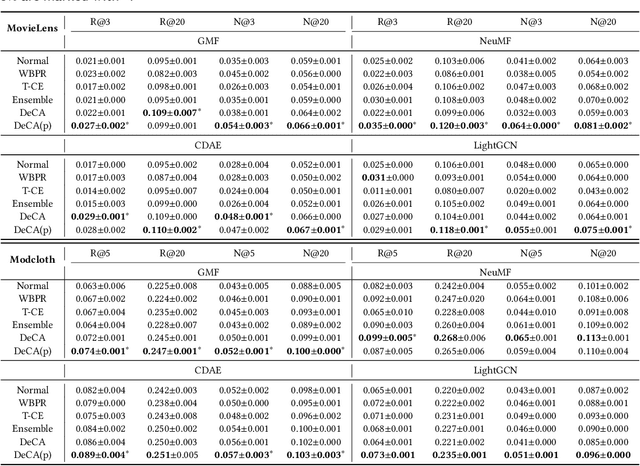
Learning from corrupted labels is very common in real-world machine-learning applications. Memorizing such noisy labels could affect the learning of the model, leading to sub-optimal performances. In this work, we propose a novel framework to learn robust machine-learning models from noisy labels. Through an empirical study, we find that different models make relatively similar predictions on clean examples, while the predictions on noisy examples vary much more across different models. Motivated by this observation, we propose \em denoising with cross-model agreement \em (DeCA) which aims to minimize the KL-divergence between the true label distributions parameterized by two machine learning models while maximizing the likelihood of data observation. We employ the proposed DeCA on both the binary label scenario and the multiple label scenario. For the binary label scenario, we select implicit feedback recommendation as the downstream task and conduct experiments with four state-of-the-art recommendation models on four datasets. For the multiple-label scenario, the downstream application is image classification on two benchmark datasets. Experimental results demonstrate that the proposed methods significantly improve the model performance compared with normal training and other denoising methods on both binary and multiple-label scenarios.
A Comprehensive Empirical Evaluation on Online Continual Learning
Sep 01, 2023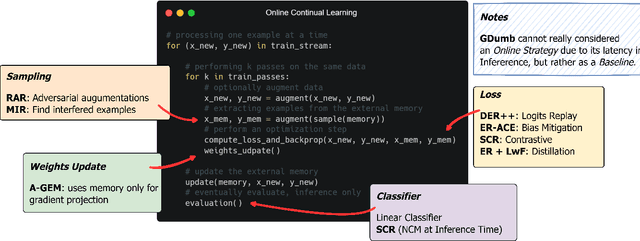
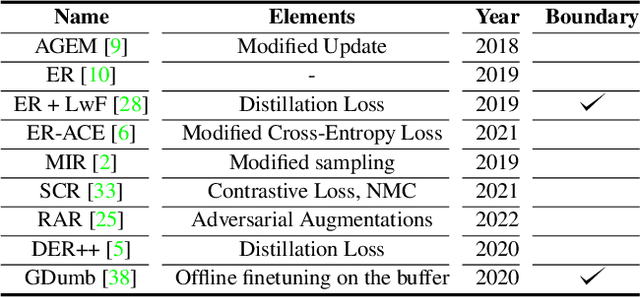
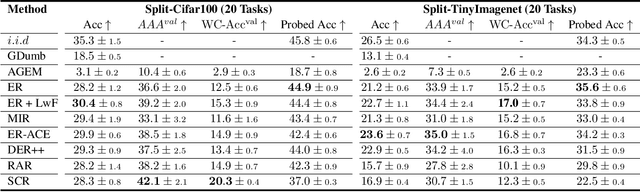
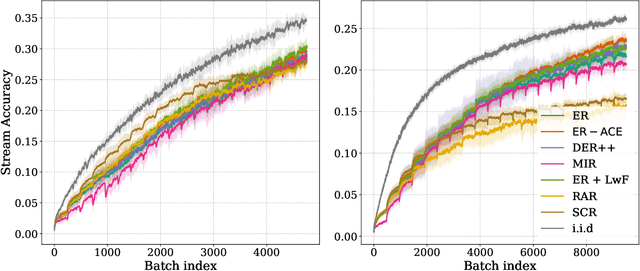
Online continual learning aims to get closer to a live learning experience by learning directly on a stream of data with temporally shifting distribution and by storing a minimum amount of data from that stream. In this empirical evaluation, we evaluate various methods from the literature that tackle online continual learning. More specifically, we focus on the class-incremental setting in the context of image classification, where the learner must learn new classes incrementally from a stream of data. We compare these methods on the Split-CIFAR100 and Split-TinyImagenet benchmarks, and measure their average accuracy, forgetting, stability, and quality of the representations, to evaluate various aspects of the algorithm at the end but also during the whole training period. We find that most methods suffer from stability and underfitting issues. However, the learned representations are comparable to i.i.d. training under the same computational budget. No clear winner emerges from the results and basic experience replay, when properly tuned and implemented, is a very strong baseline. We release our modular and extensible codebase at https://github.com/AlbinSou/ocl_survey based on the avalanche framework to reproduce our results and encourage future research.
Gap and Overlap Detection in Automated Fiber Placement
Sep 01, 2023The identification and correction of manufacturing defects, particularly gaps and overlaps, are crucial for ensuring high-quality composite parts produced through Automated Fiber Placement (AFP). These imperfections are the most commonly observed issues that can significantly impact the overall quality of the composite parts. Manual inspection is both time-consuming and labor-intensive, making it an inefficient approach. To overcome this challenge, the implementation of an automated defect detection system serves as the optimal solution. In this paper, we introduce a novel method that uses an Optical Coherence Tomography (OCT) sensor and computer vision techniques to detect and locate gaps and overlaps in composite parts. Our approach involves generating a depth map image of the composite surface that highlights the elevation of composite tapes (or tows) on the surface. By detecting the boundaries of each tow, our algorithm can compare consecutive tows and identify gaps or overlaps that may exist between them. Any gaps or overlaps exceeding a predefined tolerance threshold are considered manufacturing defects. To evaluate the performance of our approach, we compare the detected defects with the ground truth annotated by experts. The results demonstrate a high level of accuracy and efficiency in gap and overlap segmentation.
Mechanism of feature learning in convolutional neural networks
Sep 01, 2023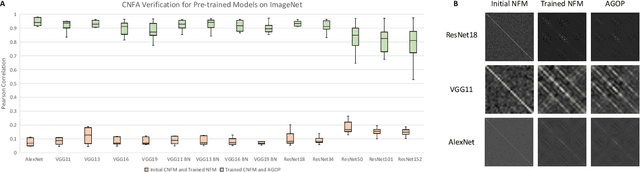



Understanding the mechanism of how convolutional neural networks learn features from image data is a fundamental problem in machine learning and computer vision. In this work, we identify such a mechanism. We posit the Convolutional Neural Feature Ansatz, which states that covariances of filters in any convolutional layer are proportional to the average gradient outer product (AGOP) taken with respect to patches of the input to that layer. We present extensive empirical evidence for our ansatz, including identifying high correlation between covariances of filters and patch-based AGOPs for convolutional layers in standard neural architectures, such as AlexNet, VGG, and ResNets pre-trained on ImageNet. We also provide supporting theoretical evidence. We then demonstrate the generality of our result by using the patch-based AGOP to enable deep feature learning in convolutional kernel machines. We refer to the resulting algorithm as (Deep) ConvRFM and show that our algorithm recovers similar features to deep convolutional networks including the notable emergence of edge detectors. Moreover, we find that Deep ConvRFM overcomes previously identified limitations of convolutional kernels, such as their inability to adapt to local signals in images and, as a result, leads to sizable performance improvement over fixed convolutional kernels.
Deep Segmented DMP Networks for Learning Discontinuous Motions
Sep 01, 2023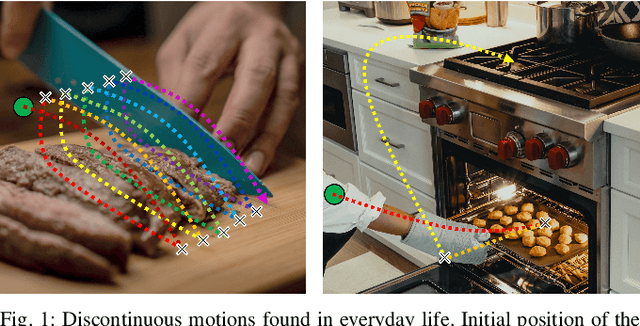
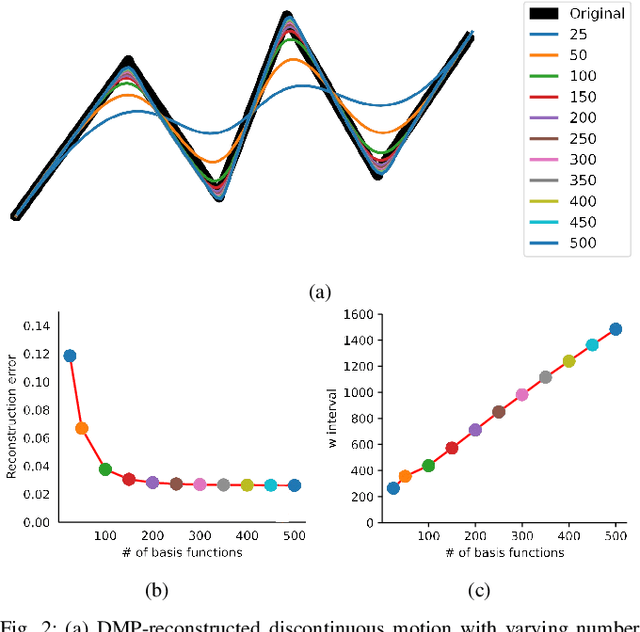
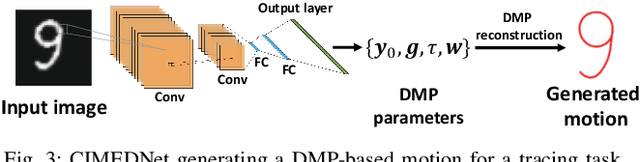
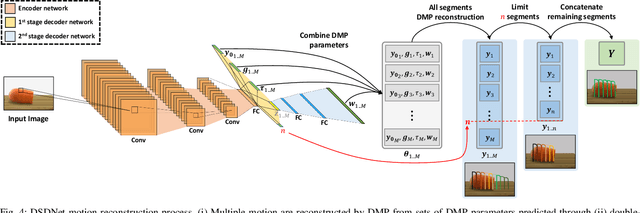
Discontinuous motion which is a motion composed of multiple continuous motions with sudden change in direction or velocity in between, can be seen in state-aware robotic tasks. Such robotic tasks are often coordinated with sensor information such as image. In recent years, Dynamic Movement Primitives (DMP) which is a method for generating motor behaviors suitable for robotics has garnered several deep learning based improvements to allow associations between sensor information and DMP parameters. While the implementation of deep learning framework does improve upon DMP's inability to directly associate to an input, we found that it has difficulty learning DMP parameters for complex motion which requires large number of basis functions to reconstruct. In this paper we propose a novel deep learning network architecture called Deep Segmented DMP Network (DSDNet) which generates variable-length segmented motion by utilizing the combination of multiple DMP parameters predicting network architecture, double-stage decoder network, and number of segments predictor. The proposed method is evaluated on both artificial data (object cutting & pick-and-place) and real data (object cutting) where our proposed method could achieve high generalization capability, task-achievement, and data-efficiency compared to previous method on generating discontinuous long-horizon motions.