 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TAI-GAN: Temporally and Anatomically Informed GAN for early-to-late frame conversion in dynamic cardiac PET motion correction
Aug 23, 2023
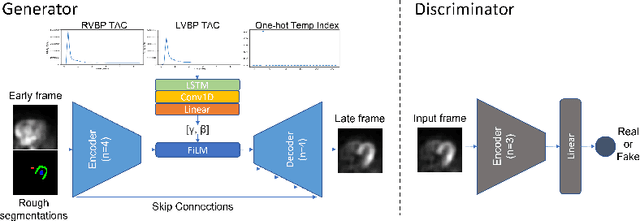
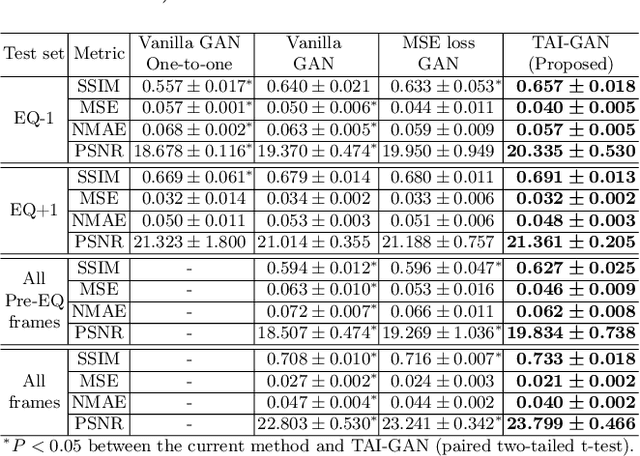
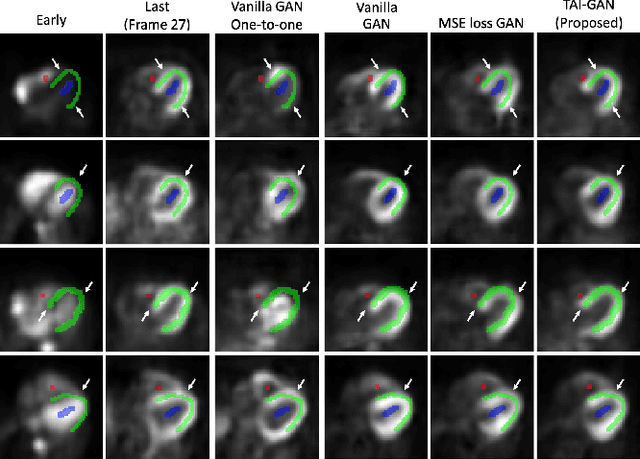
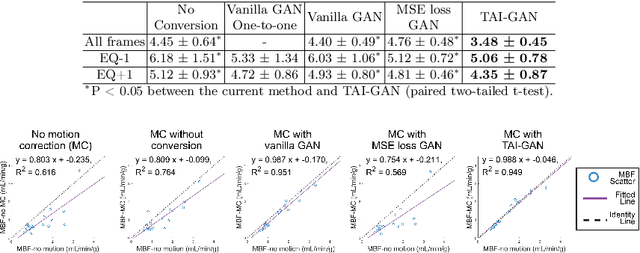
The rapid tracer kinetics of rubidium-82 ($^{82}$Rb) and high variation of cross-frame distribution in dynamic cardiac positron emission tomography (PET) raise significant challenges for inter-frame motion correction, particularly for the early frames where conventional intensity-based image registration techniques are not applicable. Alternatively, a promising approach utilizes generative methods to handle the tracer distribution changes to assist existing registration methods. To improve frame-wise registration and parametric quantification, we propose a Temporally and Anatomically Informed Generative Adversarial Network (TAI-GAN) to transform the early frames into the late reference frame using an all-to-one mapping. Specifically, a feature-wise linear modulation layer encodes channel-wise parameters generated from temporal tracer kinetics information, and rough cardiac segmentations with local shifts serve as the anatomical information. We validated our proposed method on a clinical $^{82}$Rb PET dataset and found that our TAI-GAN can produce converted early frames with high image quality, comparable to the real reference frames. After TAI-GAN conversion, motion estimation accuracy and clinical myocardial blood flow (MBF) quantification were improved compared to using the original frames. Our code is published at https://github.com/gxq1998/TAI-GAN.
Understanding Dark Scenes by Contrasting Multi-Modal Observations
Aug 23, 2023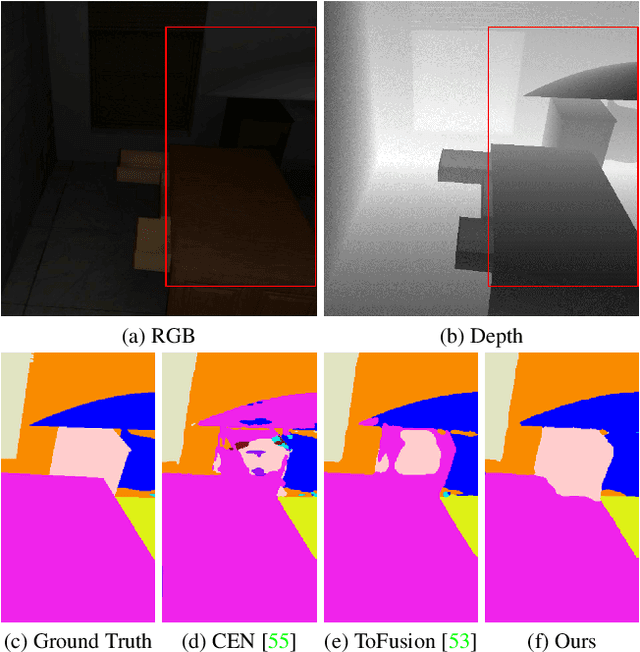

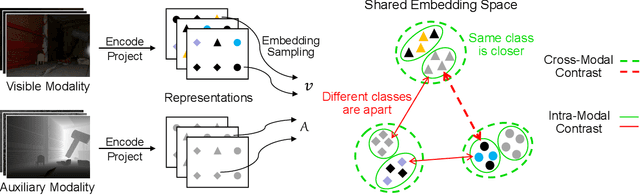
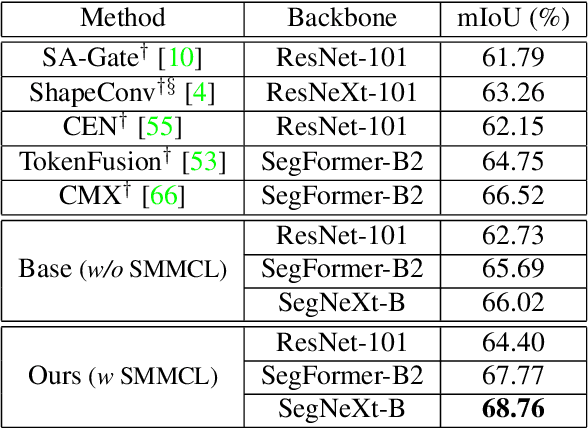
Understanding dark scenes based on multi-modal image data is challenging, as both the visible and auxiliary modalities provide limited semantic information for the task. Previous methods focus on fusing the two modalities but neglect the correlations among semantic classes when minimizing losses to align pixels with labels, resulting in inaccurate class predictions. To address these issues, we introduce a supervised multi-modal contrastive learning approach to increase the semantic discriminability of the learned multi-modal feature spaces by jointly performing cross-modal and intra-modal contrast under the supervision of the class correlations. The cross-modal contrast encourages same-class embeddings from across the two modalities to be closer and pushes different-class ones apart. The intra-modal contrast forces same-class or different-class embeddings within each modality to be together or apart. We validate our approach on a variety of tasks that cover diverse light conditions and image modalities. Experiments show that our approach can effectively enhance dark scene understanding based on multi-modal images with limited semantics by shaping semantic-discriminative feature spaces. Comparisons with previous methods demonstrate our state-of-the-art performance. Code and pretrained models are available at https://github.com/palmdong/SMMCL.
Annotation Cost Efficient Active Learning for Content Based Image Retrieval
Jun 20, 2023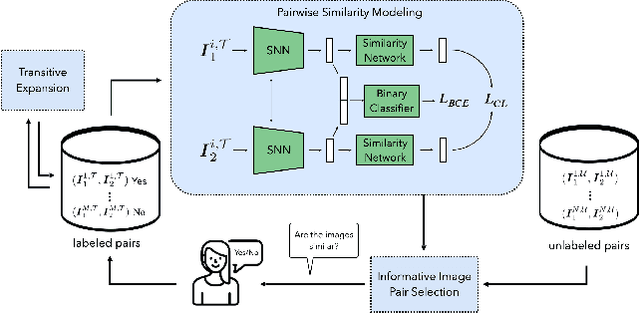
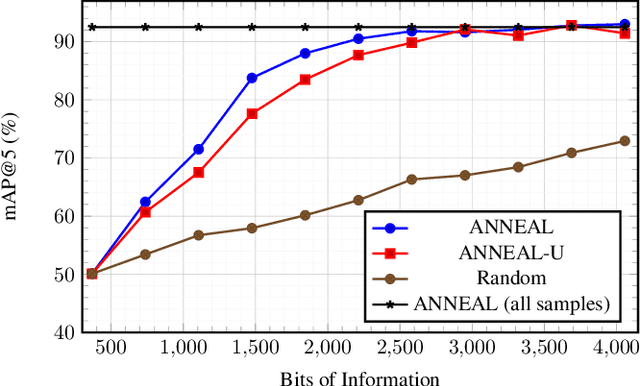
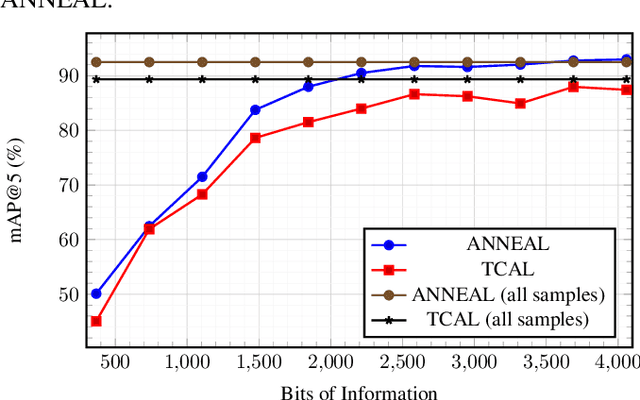
Deep metric learning (DML) based methods have been found very effective for content-based image retrieval (CBIR) in remote sensing (RS). For accurately learning the model parameters of deep neural networks, most of the DML methods require a high number of annotated training images, which can be costly to gather. To address this problem, in this paper we present an annotation cost efficient active learning (AL) method (denoted as ANNEAL). The proposed method aims to iteratively enrich the training set by annotating the most informative image pairs as similar or dissimilar, %answering a simple yes/no question, while accurately modelling a deep metric space. This is achieved by two consecutive steps. In the first step the pairwise image similarity is modelled based on the available training set. Then, in the second step the most uncertain and diverse (i.e., informative) image pairs are selected to be annotated. Unlike the existing AL methods for CBIR, at each AL iteration of ANNEAL a human expert is asked to annotate the most informative image pairs as similar/dissimilar. This significantly reduces the annotation cost compared to annotating images with land-use/land cover class labels. Experimental results show the effectiveness of our method. The code of ANNEAL is publicly available at https://git.tu-berlin.de/rsim/ANNEAL.
UnLoc: A Unified Framework for Video Localization Tasks
Aug 21, 2023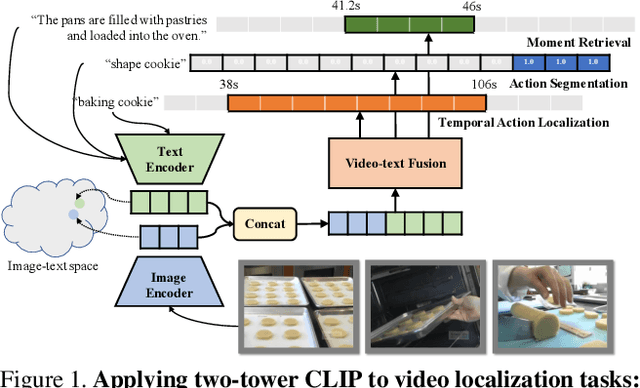

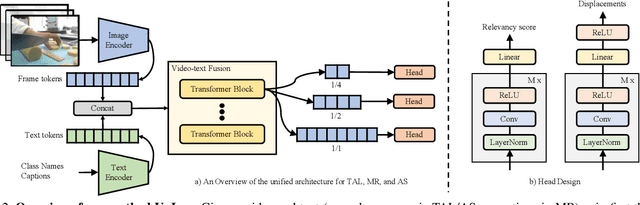
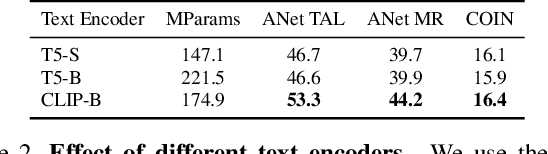
While large-scale image-text pretrained models such as CLIP have been used for multiple video-level tasks on trimmed videos, their use for temporal localization in untrimmed videos is still a relatively unexplored task. We design a new approach for this called UnLoc, which uses pretrained image and text towers, and feeds tokens to a video-text fusion model. The output of the fusion module are then used to construct a feature pyramid in which each level connects to a head to predict a per-frame relevancy score and start/end time displacements. Unlike previous works, our architecture enables Moment Retrieval, Temporal Localization, and Action Segmentation with a single stage model, without the need for action proposals, motion based pretrained features or representation masking. Unlike specialized models, we achieve state of the art results on all three different localization tasks with a unified approach. Code will be available at: \url{https://github.com/google-research/scenic}.
M3PS: End-to-End Multi-Grained Multi-Modal Attribute-Aware Product Summarization in E-commerce
Aug 22, 2023
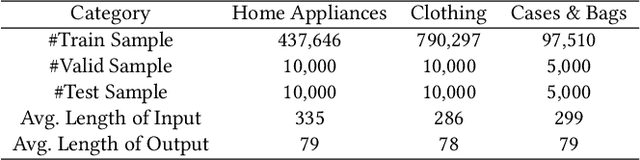
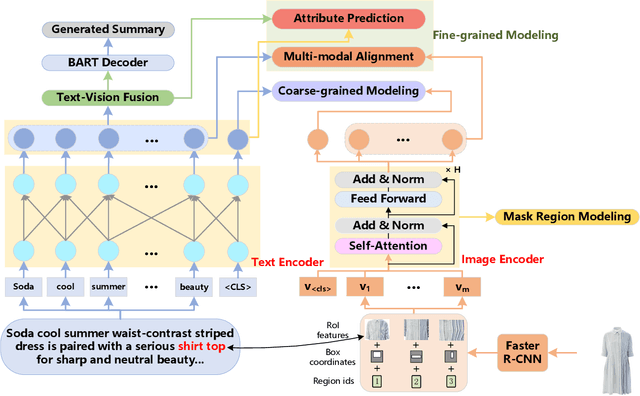

Given the long textual product information and the product image, Multi-Modal Product Summarization (MMPS) aims to attract customers' interest and increase their desire to purchase by highlighting product characteristics with a short textual summary. Existing MMPS methods have achieved promising performance. Nevertheless, there still exist several problems: 1) lack end-to-end product summarization, 2) lack multi-grained multi-modal modeling, and 3) lack multi-modal attribute modeling. To address these issues, we propose an end-to-end multi-grained multi-modal attribute-aware product summarization method (M3PS) for generating high-quality product summaries in e-commerce. M3PS jointly models product attributes and generates product summaries. Meanwhile, we design several multi-grained multi-modal tasks to better guide the multi-modal learning of M3PS. Furthermore, we model product attributes based on both text and image modalities so that multi-modal product characteristics can be manifested in the generated summaries. Extensive experiments on a real large-scale Chinese e-commence dataset demonstrate that our model outperforms state-of-the-art product summarization methods w.r.t. several summarization metrics.
MOFI: Learning Image Representations from Noisy Entity Annotated Images
Jun 13, 2023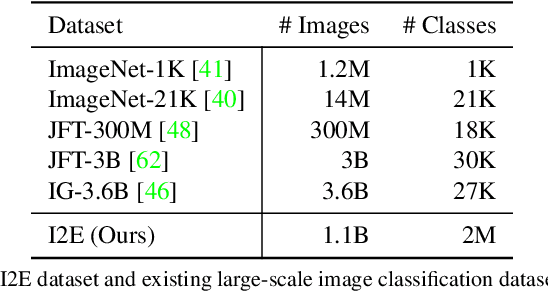

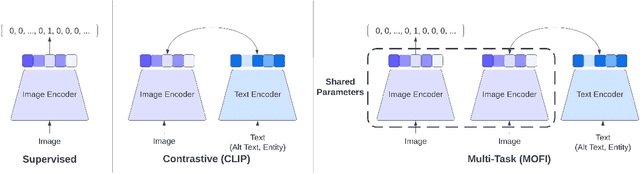
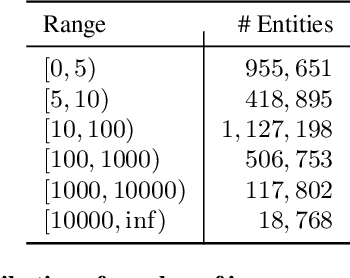
We present MOFI, a new vision foundation model designed to learn image representations from noisy entity annotated images. MOFI differs from previous work in two key aspects: ($i$) pre-training data, and ($ii$) training recipe. Regarding data, we introduce a new approach to automatically assign entity labels to images from noisy image-text pairs. Our approach involves employing a named entity recognition model to extract entities from the alt-text, and then using a CLIP model to select the correct entities as labels of the paired image. The approach is simple, does not require costly human annotation, and can be readily scaled up to billions of image-text pairs mined from the web. Through this method, we have created Image-to-Entities (I2E), a new large-scale dataset with 1 billion images and 2 million distinct entities, covering rich visual concepts in the wild. Building upon the I2E dataset, we study different training recipes, including supervised pre-training, contrastive pre-training, and multi-task learning. For constrastive pre-training, we treat entity names as free-form text, and further enrich them with entity descriptions. Experiments show that supervised pre-training with large-scale fine-grained entity labels is highly effective for image retrieval tasks, and multi-task training further improves the performance. The final MOFI model achieves 86.66% mAP on the challenging GPR1200 dataset, surpassing the previous state-of-the-art performance of 72.19% from OpenAI's CLIP model. Further experiments on zero-shot and linear probe image classification also show that MOFI outperforms a CLIP model trained on the original image-text data, demonstrating the effectiveness of the I2E dataset in learning strong image representations.
TauPETGen: Text-Conditional Tau PET Image Synthesis Based on Latent Diffusion Models
Jun 21, 2023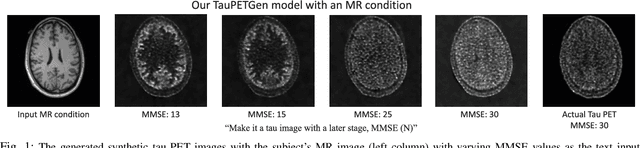
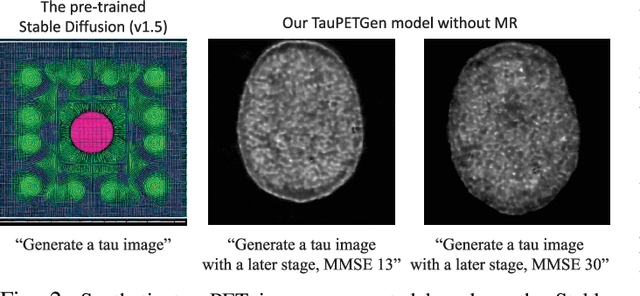
In this work, we developed a novel text-guided image synthesis technique which could generate realistic tau PET images from textual descriptions and the subject's MR image. The generated tau PET images have the potential to be used in examining relations between different measures and also increasing the public availability of tau PET datasets. The method was based on latent diffusion models. Both textual descriptions and the subject's MR prior image were utilized as conditions during image generation. The subject's MR image can provide anatomical details, while the text descriptions, such as gender, scan time, cognitive test scores, and amyloid status, can provide further guidance regarding where the tau neurofibrillary tangles might be deposited. Preliminary experimental results based on clinical [18F]MK-6240 datasets demonstrate the feasibility of the proposed method in generating realistic tau PET images at different clinical stages.
Face Image Quality Enhancement Study for Face Recognition
Jul 08, 2023
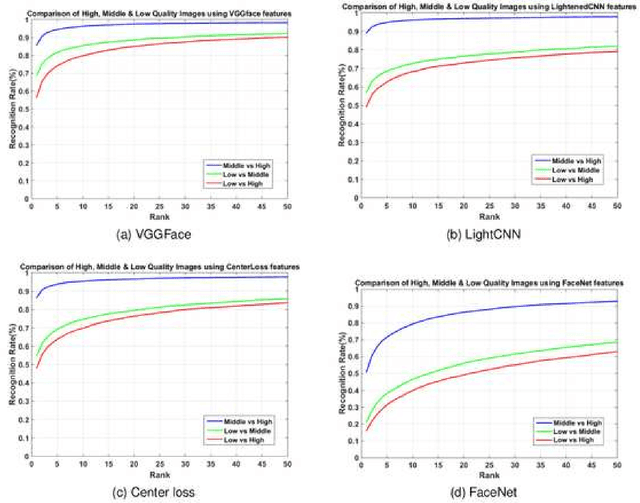
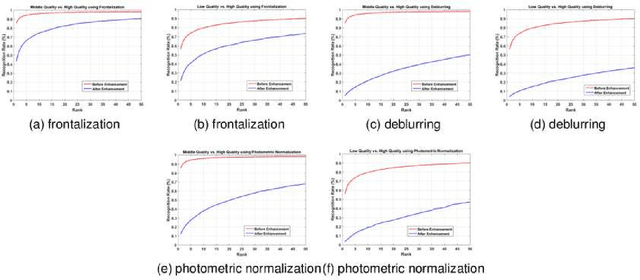
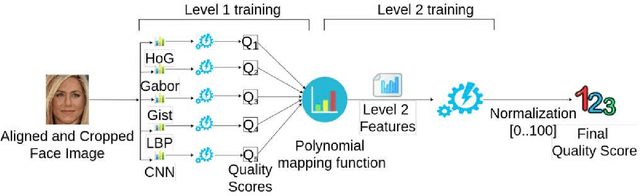
Unconstrained face recognition is an active research area among computer vision and biometric researchers for many years now. Still the problem of face recognition in low quality photos has not been well-studied so far. In this paper, we explore the face recognition performance on low quality photos, and we try to improve the accuracy in dealing with low quality face images. We assemble a large database with low quality photos, and examine the performance of face recognition algorithms for three different quality sets. Using state-of-the-art facial image enhancement approaches, we explore the face recognition performance for the enhanced face images. To perform this without experimental bias, we have developed a new protocol for recognition with low quality face photos and validate the performance experimentally. Our designed protocol for face recognition with low quality face images can be useful to other researchers. Moreover, experiment results show some of the challenging aspects of this problem.
CFI2P: Coarse-to-Fine Cross-Modal Correspondence Learning for Image-to-Point Cloud Registration
Jul 14, 2023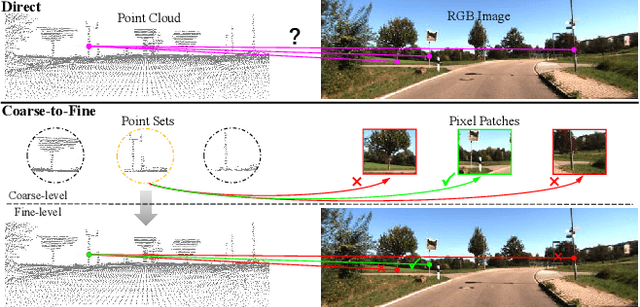

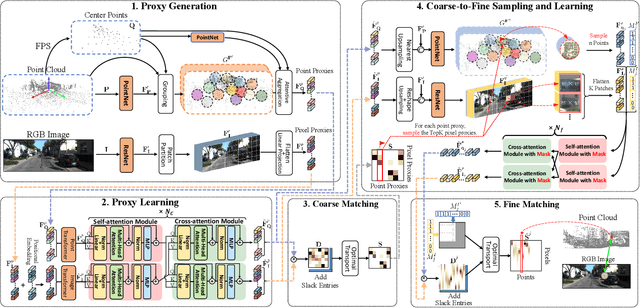
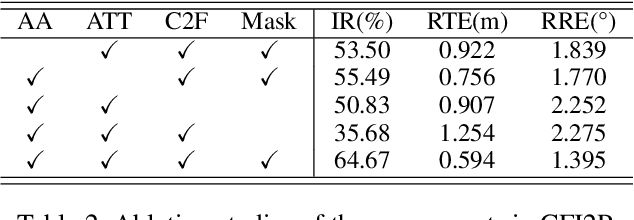
In the context of image-to-point cloud registration, acquiring point-to-pixel correspondences presents a challenging task since the similarity between individual points and pixels is ambiguous due to the visual differences in data modalities. Nevertheless, the same object present in the two data formats can be readily identified from the local perspective of point sets and pixel patches. Motivated by this intuition, we propose a coarse-to-fine framework that emphasizes the establishment of correspondences between local point sets and pixel patches, followed by the refinement of results at both the point and pixel levels. On a coarse scale, we mimic the classic Visual Transformer to translate both image and point cloud into two sequences of local representations, namely point and pixel proxies, and employ attention to capture global and cross-modal contexts. To supervise the coarse matching, we propose a novel projected point proportion loss, which guides to match point sets with pixel patches where more points can be projected into. On a finer scale, point-to-pixel correspondences are then refined from a smaller search space (i.e., the coarsely matched sets and patches) via well-designed sampling, attentional learning and fine matching, where sampling masks are embedded in the last two steps to mitigate the negative effect of sampling. With the high-quality correspondences, the registration problem is then resolved by EPnP algorithm within RANSAC. Experimental results on large-scale outdoor benchmarks demonstrate our superiority over existing methods.
Both Spatial and Frequency Cues Contribute to High-Fidelity Image Inpainting
Jul 15, 2023
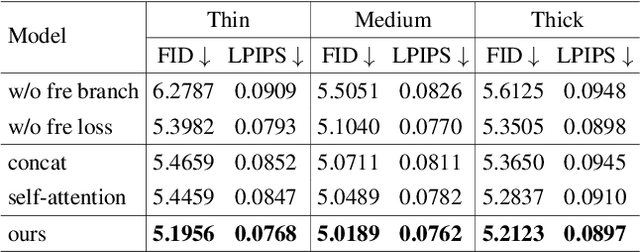
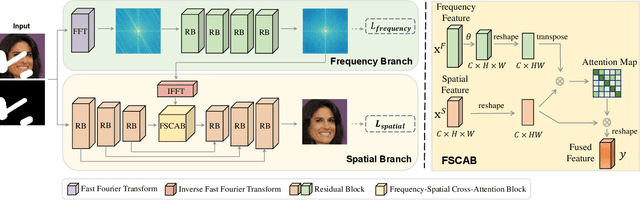
Deep generative approaches have obtained great success in image inpainting recently. However, most generative inpainting networks suffer from either over-smooth results or aliasing artifacts. The former lacks high-frequency details, while the latter lacks semantic structure. To address this issue, we propose an effective Frequency-Spatial Complementary Network (FSCN) by exploiting rich semantic information in both spatial and frequency domains. Specifically, we introduce an extra Frequency Branch and Frequency Loss on the spatial-based network to impose direct supervision on the frequency information, and propose a Frequency-Spatial Cross-Attention Block (FSCAB) to fuse multi-domain features and combine the corresponding characteristics. With our FSCAB, the inpainting network is capable of capturing frequency information and preserving visual consistency simultaneously. Extensive quantitative and qualitative experiments demonstrate that our inpainting network can effectively achieve superior results, outperforming previous state-of-the-art approaches with significantly fewer parameters and less computation cost. The code will be released soon.