 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
EdaDet: Open-Vocabulary Object Detection Using Early Dense Alignment
Sep 03, 2023
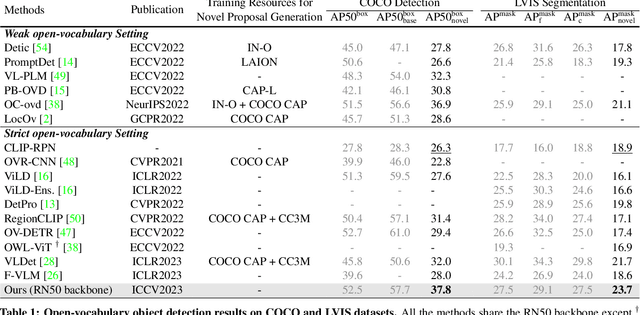

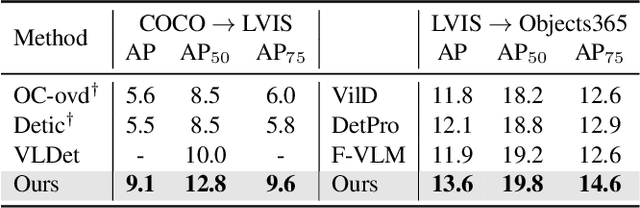
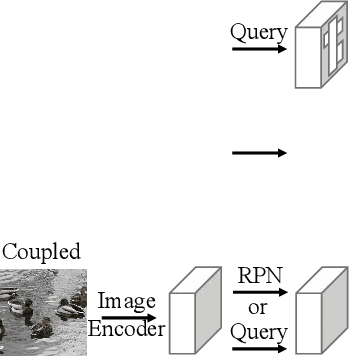
Vision-language models such as CLIP have boosted the performance of open-vocabulary object detection, where the detector is trained on base categories but required to detect novel categories. Existing methods leverage CLIP's strong zero-shot recognition ability to align object-level embeddings with textual embeddings of categories. However, we observe that using CLIP for object-level alignment results in overfitting to base categories, i.e., novel categories most similar to base categories have particularly poor performance as they are recognized as similar base categories. In this paper, we first identify that the loss of critical fine-grained local image semantics hinders existing methods from attaining strong base-to-novel generalization. Then, we propose Early Dense Alignment (EDA) to bridge the gap between generalizable local semantics and object-level prediction. In EDA, we use object-level supervision to learn the dense-level rather than object-level alignment to maintain the local fine-grained semantics. Extensive experiments demonstrate our superior performance to competing approaches under the same strict setting and without using external training resources, i.e., improving the +8.4% novel box AP50 on COCO and +3.9% rare mask AP on LVIS.
DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing
Jun 27, 2023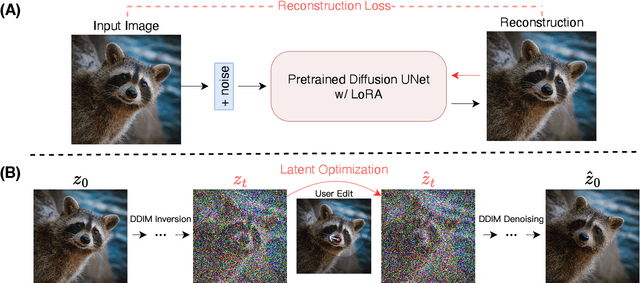


Precise and controllable image editing is a challenging task that has attracted significant attention. Recently, DragGAN enables an interactive point-based image editing framework and achieves impressive editing results with pixel-level precision. However, since this method is based on generative adversarial networks (GAN), its generality is upper-bounded by the capacity of the pre-trained GAN models. In this work, we extend such an editing framework to diffusion models and propose DragDiffusion. By leveraging large-scale pretrained diffusion models, we greatly improve the applicability of interactive point-based editing in real world scenarios. While most existing diffusion-based image editing methods work on text embeddings, DragDiffusion optimizes the diffusion latent to achieve precise spatial control. Although diffusion models generate images in an iterative manner, we empirically show that optimizing diffusion latent at one single step suffices to generate coherent results, enabling DragDiffusion to complete high-quality editing efficiently. Extensive experiments across a wide range of challenging cases (e.g., multi-objects, diverse object categories, various styles, etc.) demonstrate the versatility and generality of DragDiffusion.
CLIPMasterPrints: Fooling Contrastive Language-Image Pre-training Using Latent Variable Evolution
Jul 07, 2023
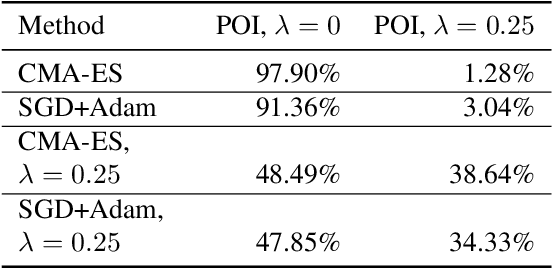
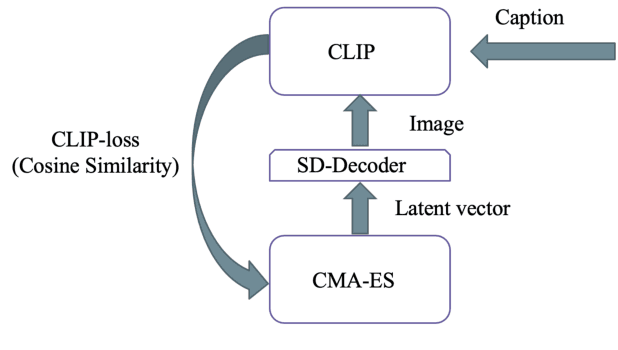
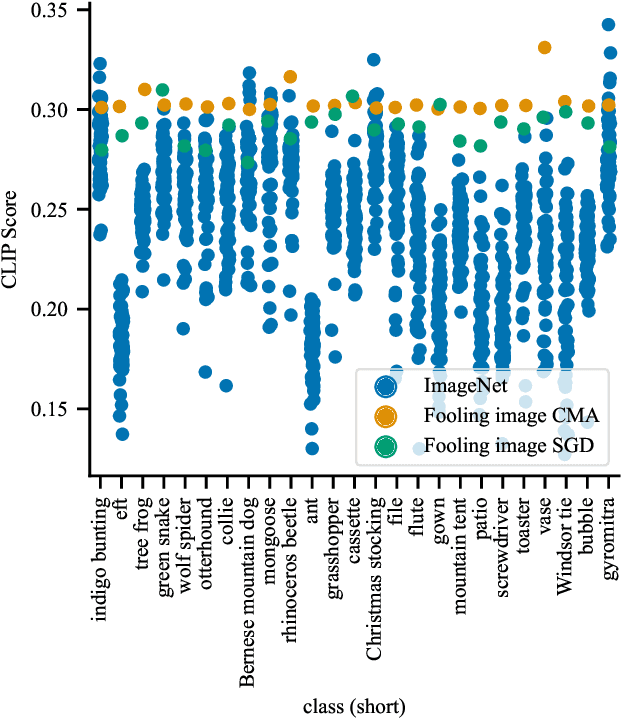
Models leveraging both visual and textual data such as Contrastive Language-Image Pre-training (CLIP), are increasingly gaining importance. In this work, we show that despite their versatility, such models are vulnerable to what we refer to as fooling master images. Fooling master images are capable of maximizing the confidence score of a CLIP model for a significant number of widely varying prompts, while being unrecognizable for humans. We demonstrate how fooling master images can be mined by searching the latent space of generative models by means of an evolution strategy or stochastic gradient descent. We investigate the properties of the mined fooling master images, and find that images trained on a small number of image captions potentially generalize to a much larger number of semantically related captions. Further, we evaluate two possible mitigation strategies and find that vulnerability to fooling master examples is closely related to a modality gap in contrastive pre-trained multi-modal networks. From the perspective of vulnerability to off-manifold attacks, we therefore argue for the mitigation of modality gaps in CLIP and related multi-modal approaches. Source code and mined CLIPMasterPrints are available at https://github.com/matfrei/CLIPMasterPrints.
Unsupervised Prototype Adapter for Vision-Language Models
Aug 25, 2023Recently, large-scale pre-trained vision-language models (e.g. CLIP and ALIGN) have demonstrated remarkable effectiveness in acquiring transferable visual representations. To leverage the valuable knowledge encoded within these models for downstream tasks, several fine-tuning approaches, including prompt tuning methods and adapter-based methods, have been developed to adapt vision-language models effectively with supervision. However, these methods rely on the availability of annotated samples, which can be labor-intensive and time-consuming to acquire, thus limiting scalability. To address this issue, in this work, we design an unsupervised fine-tuning approach for vision-language models called Unsupervised Prototype Adapter (UP-Adapter). Specifically, for the unannotated target datasets, we leverage the text-image aligning capability of CLIP to automatically select the most confident samples for each class. Utilizing these selected samples, we generate class prototypes, which serve as the initialization for the learnable prototype model. After fine-tuning, the prototype model prediction is combined with the original CLIP's prediction by a residual connection to perform downstream recognition tasks. Our extensive experimental results on image recognition and domain generalization show that the proposed unsupervised method outperforms 8-shot CoOp, 8-shot Tip-Adapter, and also the state-of-the-art UPL method by large margins.
GPU Accelerated Color Correction and Frame Warping for Real-time Video Stitching
Aug 17, 2023
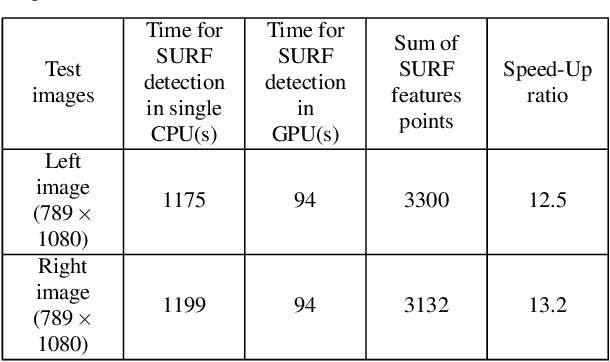
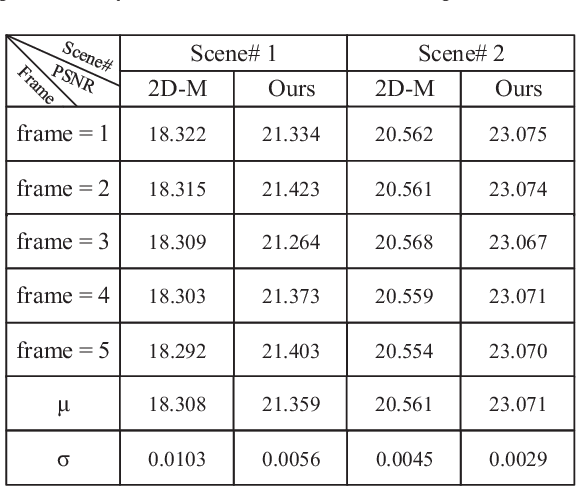
Traditional image stitching focuses on a single panorama frame without considering the spatial-temporal consistency in videos. The straightforward image stitching approach will cause temporal flicking and color inconstancy when it is applied to the video stitching task. Besides, inaccurate camera parameters will cause artifacts in the image warping. In this paper, we propose a real-time system to stitch multiple video sequences into a panoramic video, which is based on GPU accelerated color correction and frame warping without accurate camera parameters. We extend the traditional 2D-Matrix (2D-M) color correction approach and a present spatio-temporal 3D-Matrix (3D-M) color correction method for the overlap local regions with online color balancing using a piecewise function on global frames. Furthermore, we use pairwise homography matrices given by coarse camera calibration for global warping followed by accurate local warping based on the optical flow. Experimental results show that our system can generate highquality panorama videos in real time.
Learn Single-horizon Disease Evolution for Predictive Generation of Post-therapeutic Neovascular Age-related Macular Degeneration
Aug 12, 2023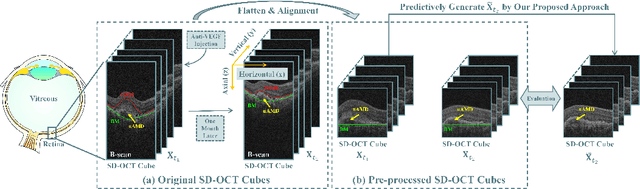

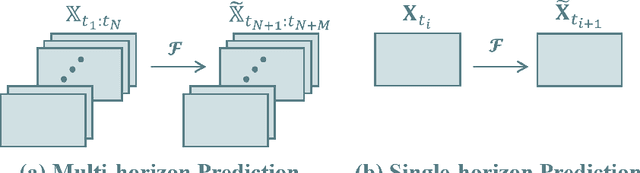
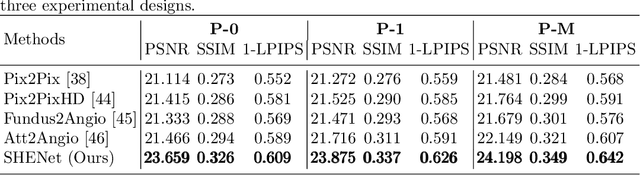
Most of the existing disease prediction methods in the field of medical image processing fall into two classes, namely image-to-category predictions and image-to-parameter predictions. Few works have focused on image-to-image predictions. Different from multi-horizon predictions in other fields, ophthalmologists prefer to show more confidence in single-horizon predictions due to the low tolerance of predictive risk. We propose a single-horizon disease evolution network (SHENet) to predictively generate post-therapeutic SD-OCT images by inputting pre-therapeutic SD-OCT images with neovascular age-related macular degeneration (nAMD). In SHENet, a feature encoder converts the input SD-OCT images to deep features, then a graph evolution module predicts the process of disease evolution in high-dimensional latent space and outputs the predicted deep features, and lastly, feature decoder recovers the predicted deep features to SD-OCT images. We further propose an evolution reinforcement module to ensure the effectiveness of disease evolution learning and obtain realistic SD-OCT images by adversarial training. SHENet is validated on 383 SD-OCT cubes of 22 nAMD patients based on three well-designed schemes based on the quantitative and qualitative evaluations. Compared with other generative methods, the generative SD-OCT images of SHENet have the highest image quality. Besides, SHENet achieves the best structure protection and content prediction. Qualitative evaluations also demonstrate that SHENet has a better visual effect than other methods. SHENet can generate post-therapeutic SD-OCT images with both high prediction performance and good image quality, which has great potential to help ophthalmologists forecast the therapeutic effect of nAMD.
Amortised Inference in Bayesian Neural Networks
Sep 06, 2023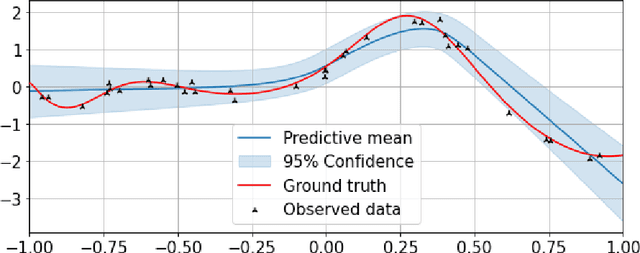

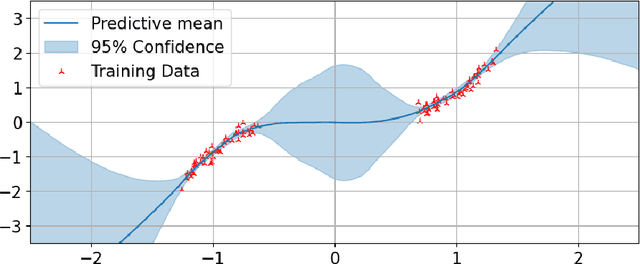
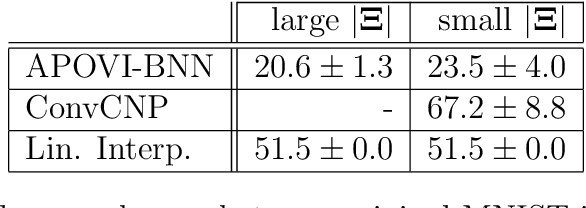
Meta-learning is a framework in which machine learning models train over a set of datasets in order to produce predictions on new datasets at test time. Probabilistic meta-learning has received an abundance of attention from the research community in recent years, but a problem shared by many existing probabilistic meta-models is that they require a very large number of datasets in order to produce high-quality predictions with well-calibrated uncertainty estimates. In many applications, however, such quantities of data are simply not available. In this dissertation we present a significantly more data-efficient approach to probabilistic meta-learning through per-datapoint amortisation of inference in Bayesian neural networks, introducing the Amortised Pseudo-Observation Variational Inference Bayesian Neural Network (APOVI-BNN). First, we show that the approximate posteriors obtained under our amortised scheme are of similar or better quality to those obtained through traditional variational inference, despite the fact that the amortised inference is performed in a single forward pass. We then discuss how the APOVI-BNN may be viewed as a new member of the neural process family, motivating the use of neural process training objectives for potentially better predictive performance on complex problems as a result. Finally, we assess the predictive performance of the APOVI-BNN against other probabilistic meta-models in both a one-dimensional regression problem and in a significantly more complex image completion setting. In both cases, when the amount of training data is limited, our model is the best in its class.
R2D2: Deep neural network series for near real-time high-dynamic range imaging in radio astronomy
Sep 06, 2023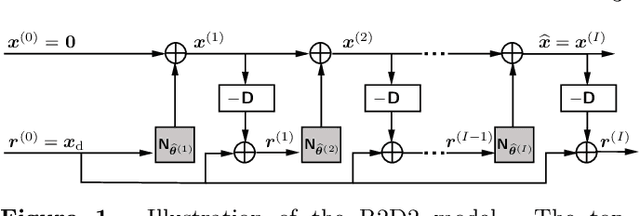
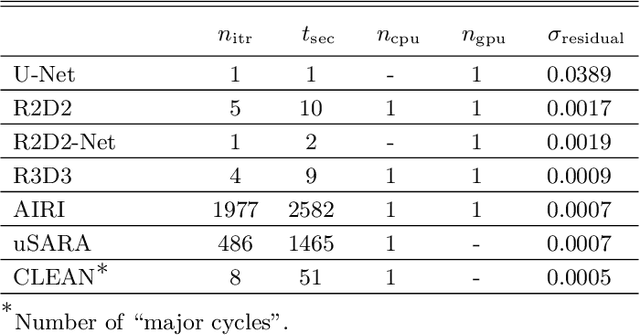

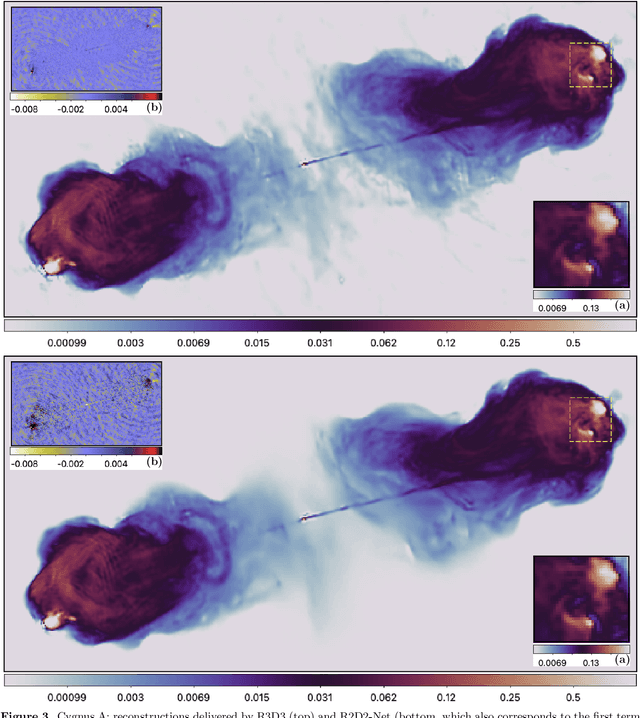
We present a novel AI approach for high-resolution high-dynamic range synthesis imaging by radio interferometry (RI) in astronomy. R2D2, standing for "{R}esidual-to-{R}esidual {D}NN series for high-{D}ynamic range imaging", is a model-based data-driven approach relying on hybrid deep neural networks (DNNs) and data-consistency updates. Its reconstruction is built as a series of residual images estimated as the outputs of DNNs, each taking the residual dirty image of the previous iteration as an input. The approach can be interpreted as a learned version of a matching pursuit approach, whereby model components are iteratively identified from residual dirty images, and of which CLEAN is a well-known example. We propose two variants of the R2D2 model, built upon two distinctive DNN architectures: a standard U-Net, and a novel unrolled architecture. We demonstrate their use for monochromatic intensity imaging on highly-sensitive observations of the radio galaxy Cygnus~A at S band, from the Very Large Array (VLA). R2D2 is validated against CLEAN and the recent RI algorithms AIRI and uSARA, which respectively inject a learned implicit regularization and an advanced handcrafted sparsity-based regularization into the RI data. With only few terms in its series, the R2D2 model is able to deliver high-precision imaging, significantly superior to CLEAN and matching the precision of AIRI and uSARA. In terms of computational efficiency, R2D2 runs at a fraction of the cost of AIRI and uSARA, and is also faster than CLEAN, opening the door to real-time precision imaging in RI.
DiffGuard: Semantic Mismatch-Guided Out-of-Distribution Detection using Pre-trained Diffusion Models
Aug 16, 2023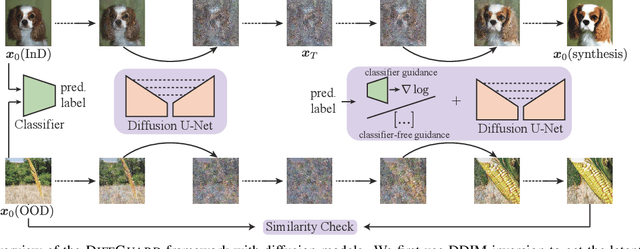
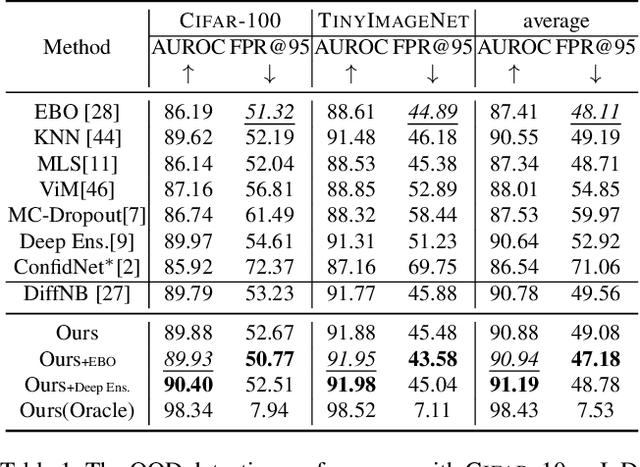

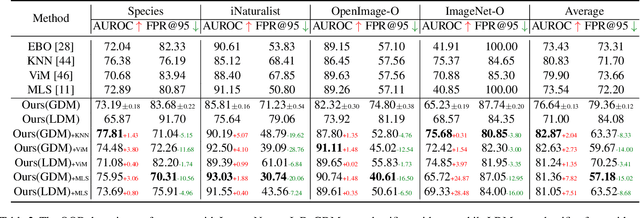
Given a classifier, the inherent property of semantic Out-of-Distribution (OOD) samples is that their contents differ from all legal classes in terms of semantics, namely semantic mismatch. There is a recent work that directly applies it to OOD detection, which employs a conditional Generative Adversarial Network (cGAN) to enlarge semantic mismatch in the image space. While achieving remarkable OOD detection performance on small datasets, it is not applicable to ImageNet-scale datasets due to the difficulty in training cGANs with both input images and labels as conditions. As diffusion models are much easier to train and amenable to various conditions compared to cGANs, in this work, we propose to directly use pre-trained diffusion models for semantic mismatch-guided OOD detection, named DiffGuard. Specifically, given an OOD input image and the predicted label from the classifier, we try to enlarge the semantic difference between the reconstructed OOD image under these conditions and the original input image. We also present several test-time techniques to further strengthen such differences. Experimental results show that DiffGuard is effective on both Cifar-10 and hard cases of the large-scale ImageNet, and it can be easily combined with existing OOD detection techniques to achieve state-of-the-art OOD detection results.
Boosting Semantic Segmentation from the Perspective of Explicit Class Embeddings
Aug 24, 2023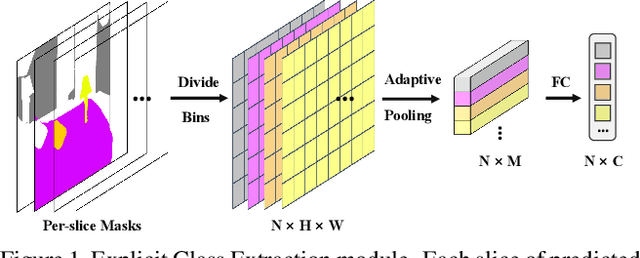
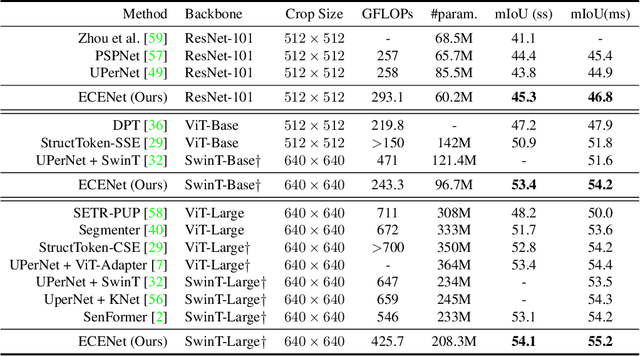
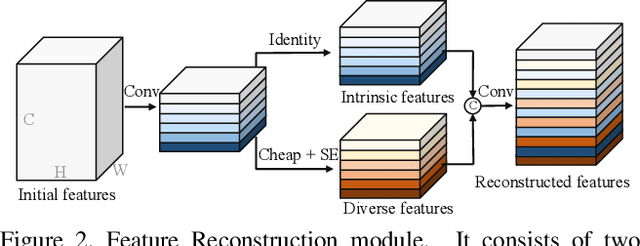
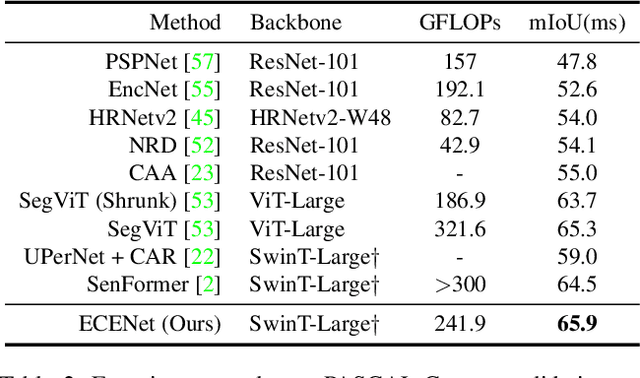
Semantic segmentation is a computer vision task that associates a label with each pixel in an image. Modern approaches tend to introduce class embeddings into semantic segmentation for deeply utilizing category semantics, and regard supervised class masks as final predictions. In this paper, we explore the mechanism of class embeddings and have an insight that more explicit and meaningful class embeddings can be generated based on class masks purposely. Following this observation, we propose ECENet, a new segmentation paradigm, in which class embeddings are obtained and enhanced explicitly during interacting with multi-stage image features. Based on this, we revisit the traditional decoding process and explore inverted information flow between segmentation masks and class embeddings. Furthermore, to ensure the discriminability and informativity of features from backbone, we propose a Feature Reconstruction module, which combines intrinsic and diverse branches together to ensure the concurrence of diversity and redundancy in features. Experiments show that our ECENet outperforms its counterparts on the ADE20K dataset with much less computational cost and achieves new state-of-the-art results on PASCAL-Context dataset. The code will be released at https://gitee.com/mindspore/models and https://github.com/Carol-lyh/ECENet.