 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TouchStone: Evaluating Vision-Language Models by Language Models
Sep 04, 2023
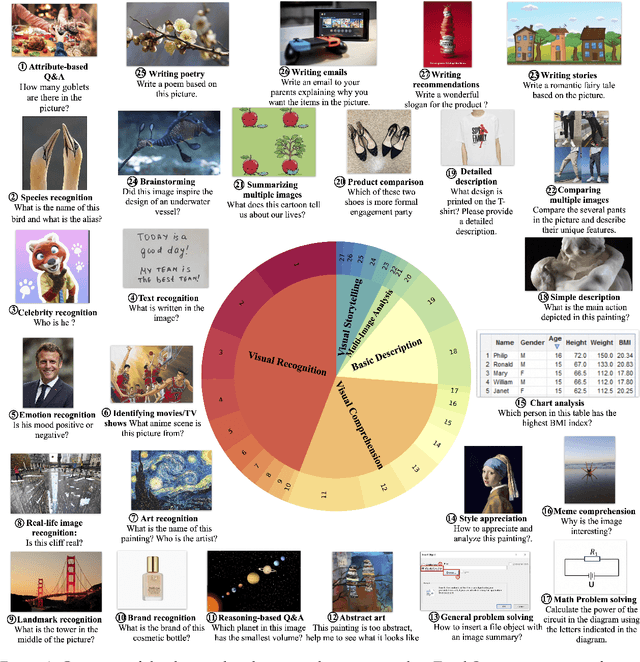
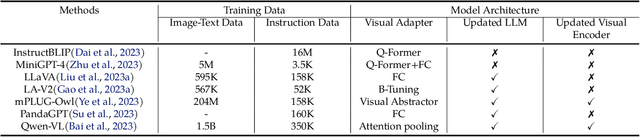


Large vision-language models (LVLMs) have recently witnessed rapid advancements, exhibiting a remarkable capacity for perceiving, understanding, and processing visual information by connecting visual receptor with large language models (LLMs). However, current assessments mainly focus on recognizing and reasoning abilities, lacking direct evaluation of conversational skills and neglecting visual storytelling abilities. In this paper, we propose an evaluation method that uses strong LLMs as judges to comprehensively evaluate the various abilities of LVLMs. Firstly, we construct a comprehensive visual dialogue dataset TouchStone, consisting of open-world images and questions, covering five major categories of abilities and 27 subtasks. This dataset not only covers fundamental recognition and comprehension but also extends to literary creation. Secondly, by integrating detailed image annotations we effectively transform the multimodal input content into a form understandable by LLMs. This enables us to employ advanced LLMs for directly evaluating the quality of the multimodal dialogue without requiring human intervention. Through validation, we demonstrate that powerful LVLMs, such as GPT-4, can effectively score dialogue quality by leveraging their textual capabilities alone, aligning with human preferences. We hope our work can serve as a touchstone for LVLMs' evaluation and pave the way for building stronger LVLMs. The evaluation code is available at https://github.com/OFA-Sys/TouchStone.
Few-shot Diagnosis of Chest x-rays Using an Ensemble of Random Discriminative Subspaces
Aug 31, 2023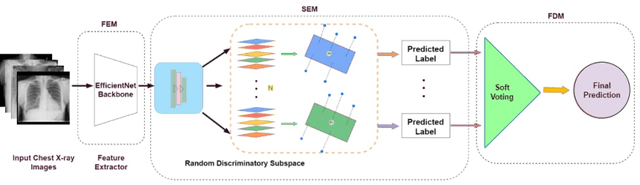
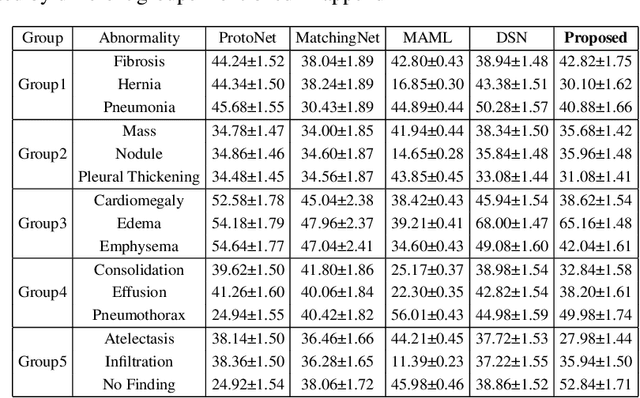
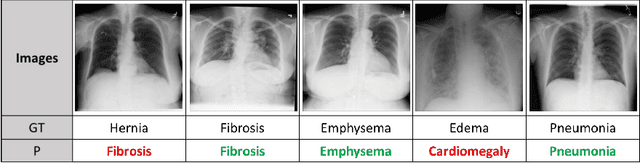

Due to the scarcity of annotated data in the medical domain, few-shot learning may be useful for medical image analysis tasks. We design a few-shot learning method using an ensemble of random subspaces for the diagnosis of chest x-rays (CXRs). Our design is computationally efficient and almost 1.8 times faster than method that uses the popular truncated singular value decomposition (t-SVD) for subspace decomposition. The proposed method is trained by minimizing a novel loss function that helps create well-separated clusters of training data in discriminative subspaces. As a result, minimizing the loss maximizes the distance between the subspaces, making them discriminative and assisting in better classification. Experiments on large-scale publicly available CXR datasets yield promising results. Code for the project will be available at https://github.com/Few-shot-Learning-on-chest-x-ray/fsl_subspace.
MVDream: Multi-view Diffusion for 3D Generation
Aug 31, 2023We propose MVDream, a multi-view diffusion model that is able to generate geometrically consistent multi-view images from a given text prompt. By leveraging image diffusion models pre-trained on large-scale web datasets and a multi-view dataset rendered from 3D assets, the resulting multi-view diffusion model can achieve both the generalizability of 2D diffusion and the consistency of 3D data. Such a model can thus be applied as a multi-view prior for 3D generation via Score Distillation Sampling, where it greatly improves the stability of existing 2D-lifting methods by solving the 3D consistency problem. Finally, we show that the multi-view diffusion model can also be fine-tuned under a few shot setting for personalized 3D generation, i.e. DreamBooth3D application, where the consistency can be maintained after learning the subject identity.
Michelangelo: Conditional 3D Shape Generation based on Shape-Image-Text Aligned Latent Representation
Jun 29, 2023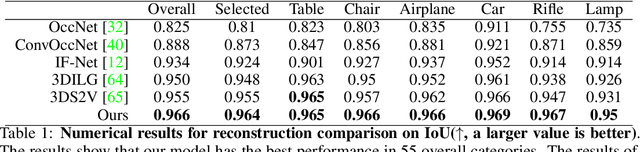
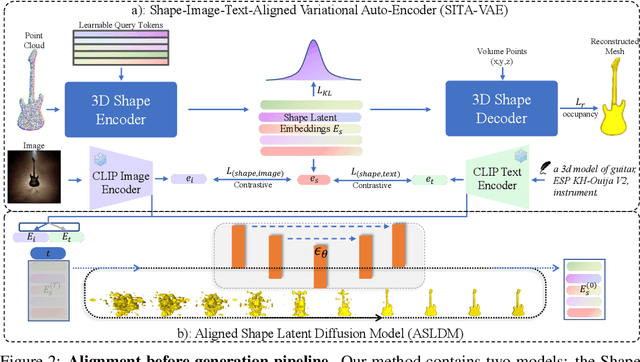
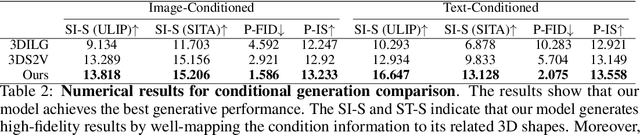

We present a novel alignment-before-generation approach to tackle the challenging task of generating general 3D shapes based on 2D images or texts. Directly learning a conditional generative model from images or texts to 3D shapes is prone to producing inconsistent results with the conditions because 3D shapes have an additional dimension whose distribution significantly differs from that of 2D images and texts. To bridge the domain gap among the three modalities and facilitate multi-modal-conditioned 3D shape generation, we explore representing 3D shapes in a shape-image-text-aligned space. Our framework comprises two models: a Shape-Image-Text-Aligned Variational Auto-Encoder (SITA-VAE) and a conditional Aligned Shape Latent Diffusion Model (ASLDM). The former model encodes the 3D shapes into the shape latent space aligned to the image and text and reconstructs the fine-grained 3D neural fields corresponding to given shape embeddings via the transformer-based decoder. The latter model learns a probabilistic mapping function from the image or text space to the latent shape space. Our extensive experiments demonstrate that our proposed approach can generate higher-quality and more diverse 3D shapes that better semantically conform to the visual or textural conditional inputs, validating the effectiveness of the shape-image-text-aligned space for cross-modality 3D shape generation.
Large-scale gradient-based training of Mixtures of Factor Analyzers
Aug 26, 2023Gaussian Mixture Models (GMMs) are a standard tool in data analysis. However, they face problems when applied to high-dimensional data (e.g., images) due to the size of the required full covariance matrices (CMs), whereas the use of diagonal or spherical CMs often imposes restrictions that are too severe. The Mixture of Factor analyzers (MFA) model is an important extension of GMMs, which allows to smoothly interpolate between diagonal and full CMs based on the number of \textit{factor loadings} $l$. MFA has successfully been applied for modeling high-dimensional image data. This article contributes both a theoretical analysis as well as a new method for efficient high-dimensional MFA training by stochastic gradient descent, starting from random centroid initializations. This greatly simplifies the training and initialization process, and avoids problems of batch-type algorithms such Expectation-Maximization (EM) when training with huge amounts of data. In addition, by exploiting the properties of the matrix determinant lemma, we prove that MFA training and inference/sampling can be performed based on precision matrices, which does not require matrix inversions after training is completed. At training time, the methods requires the inversion of $l\times l$ matrices only. Besides the theoretical analysis and proofs, we apply MFA to typical image datasets such as SVHN and MNIST, and demonstrate the ability to perform sample generation and outlier detection.
Orientation-Independent Chinese Text Recognition in Scene Images
Sep 03, 2023
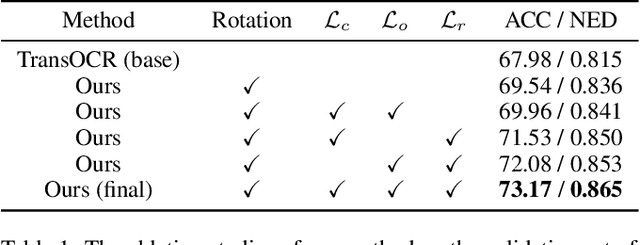
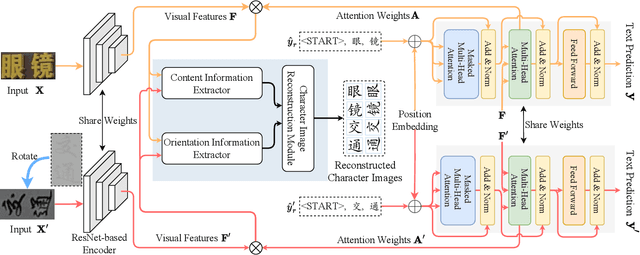
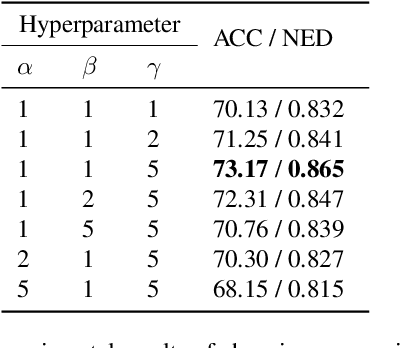
Scene text recognition (STR) has attracted much attention due to its broad applications. The previous works pay more attention to dealing with the recognition of Latin text images with complex backgrounds by introducing language models or other auxiliary networks. Different from Latin texts, many vertical Chinese texts exist in natural scenes, which brings difficulties to current state-of-the-art STR methods. In this paper, we take the first attempt to extract orientation-independent visual features by disentangling content and orientation information of text images, thus recognizing both horizontal and vertical texts robustly in natural scenes. Specifically, we introduce a Character Image Reconstruction Network (CIRN) to recover corresponding printed character images with disentangled content and orientation information. We conduct experiments on a scene dataset for benchmarking Chinese text recognition, and the results demonstrate that the proposed method can indeed improve performance through disentangling content and orientation information. To further validate the effectiveness of our method, we additionally collect a Vertical Chinese Text Recognition (VCTR) dataset. The experimental results show that the proposed method achieves 45.63% improvement on VCTR when introducing CIRN to the baseline model.
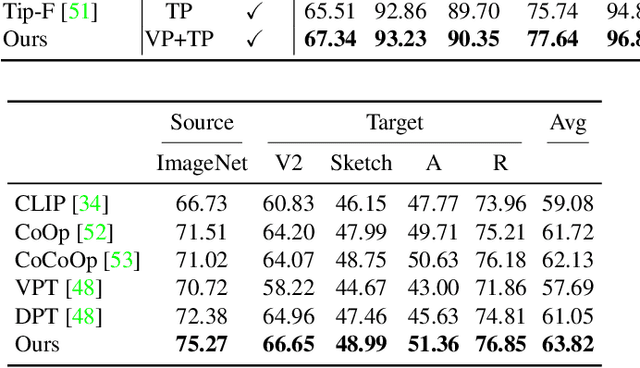
BDC-Adapter: Brownian Distance Covariance for Better Vision-Language Reasoning
Sep 03, 2023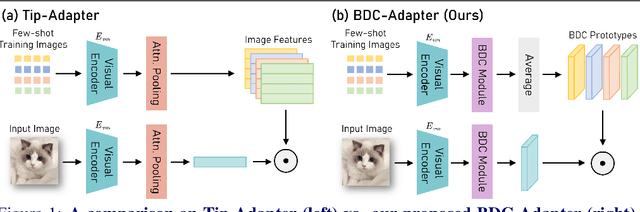
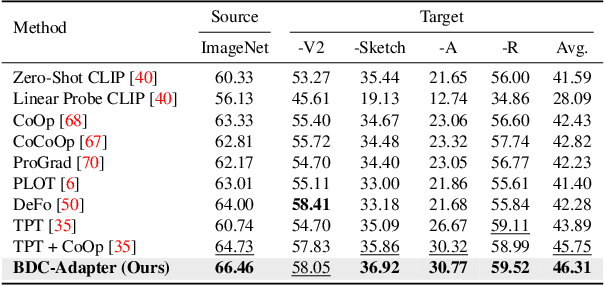
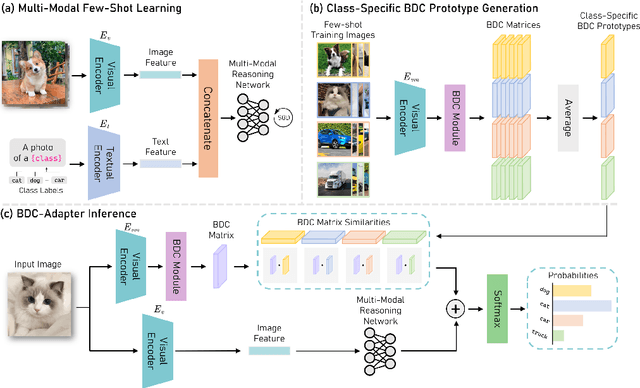
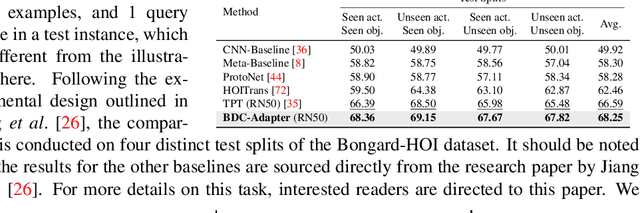
Large-scale pre-trained Vision-Language Models (VLMs), such as CLIP and ALIGN, have introduced a new paradigm for learning transferable visual representations. Recently, there has been a surge of interest among researchers in developing lightweight fine-tuning techniques to adapt these models to downstream visual tasks. We recognize that current state-of-the-art fine-tuning methods, such as Tip-Adapter, simply consider the covariance between the query image feature and features of support few-shot training samples, which only captures linear relations and potentially instigates a deceptive perception of independence. To address this issue, in this work, we innovatively introduce Brownian Distance Covariance (BDC) to the field of vision-language reasoning. The BDC metric can model all possible relations, providing a robust metric for measuring feature dependence. Based on this, we present a novel method called BDC-Adapter, which integrates BDC prototype similarity reasoning and multi-modal reasoning network prediction to perform classification tasks. Our extensive experimental results show that the proposed BDC-Adapter can freely handle non-linear relations and fully characterize independence, outperforming the current state-of-the-art methods by large margins.
CoTDet: Affordance Knowledge Prompting for Task Driven Object Detection
Sep 03, 2023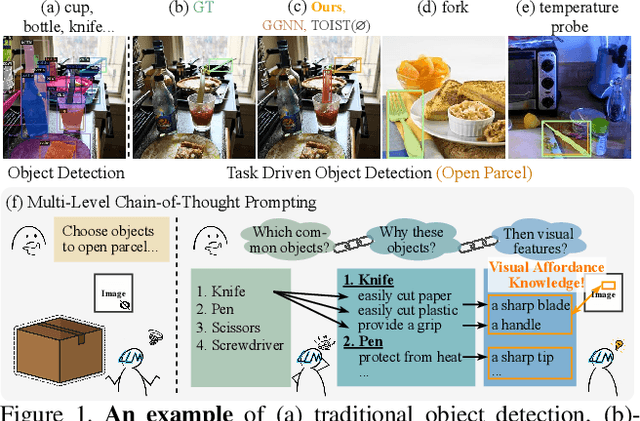
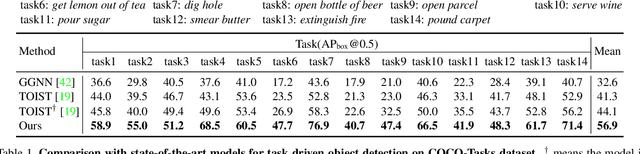
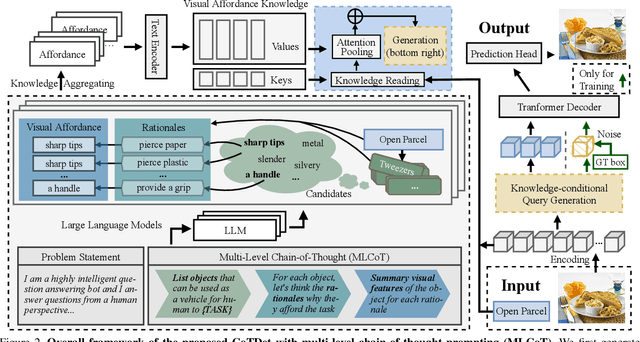

Task driven object detection aims to detect object instances suitable for affording a task in an image. Its challenge lies in object categories available for the task being too diverse to be limited to a closed set of object vocabulary for traditional object detection. Simply mapping categories and visual features of common objects to the task cannot address the challenge. In this paper, we propose to explore fundamental affordances rather than object categories, i.e., common attributes that enable different objects to accomplish the same task. Moreover, we propose a novel multi-level chain-of-thought prompting (MLCoT) to extract the affordance knowledge from large language models, which contains multi-level reasoning steps from task to object examples to essential visual attributes with rationales. Furthermore, to fully exploit knowledge to benefit object recognition and localization, we propose a knowledge-conditional detection framework, namely CoTDet. It conditions the detector from the knowledge to generate object queries and regress boxes. Experimental results demonstrate that our CoTDet outperforms state-of-the-art methods consistently and significantly (+15.6 box AP and +14.8 mask AP) and can generate rationales for why objects are detected to afford the task.
ArSDM: Colonoscopy Images Synthesis with Adaptive Refinement Semantic Diffusion Models
Sep 03, 2023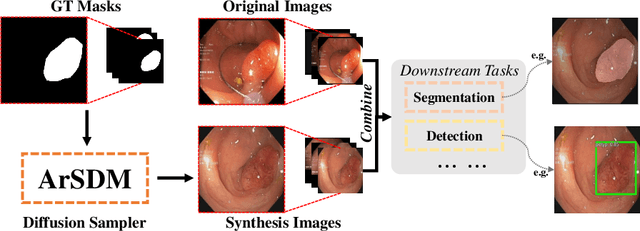
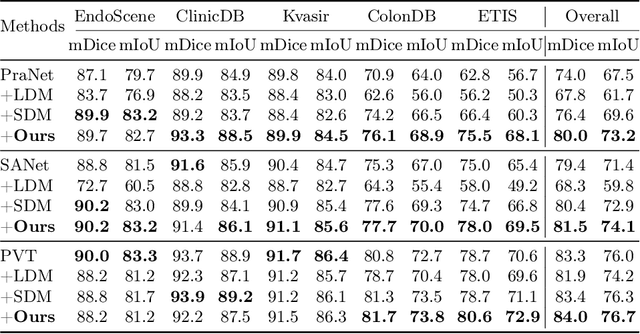
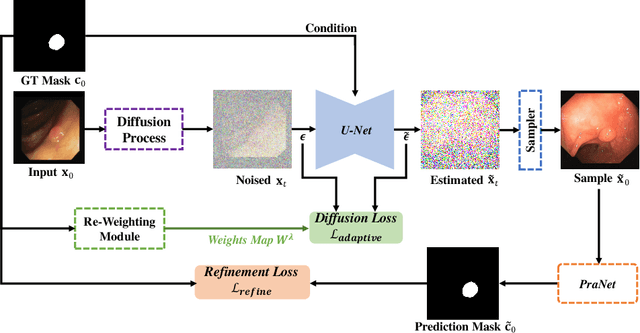
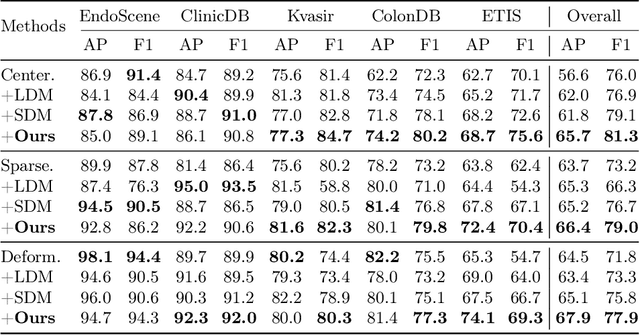
Colonoscopy analysis, particularly automatic polyp segmentation and detection, is essential for assisting clinical diagnosis and treatment. However, as medical image annotation is labour- and resource-intensive, the scarcity of annotated data limits the effectiveness and generalization of existing methods. Although recent research has focused on data generation and augmentation to address this issue, the quality of the generated data remains a challenge, which limits the contribution to the performance of subsequent tasks. Inspired by the superiority of diffusion models in fitting data distributions and generating high-quality data, in this paper, we propose an Adaptive Refinement Semantic Diffusion Model (ArSDM) to generate colonoscopy images that benefit the downstream tasks. Specifically, ArSDM utilizes the ground-truth segmentation mask as a prior condition during training and adjusts the diffusion loss for each input according to the polyp/background size ratio. Furthermore, ArSDM incorporates a pre-trained segmentation model to refine the training process by reducing the difference between the ground-truth mask and the prediction mask. Extensive experiments on segmentation and detection tasks demonstrate the generated data by ArSDM could significantly boost the performance of baseline methods.
LoGoPrompt: Synthetic Text Images Can Be Good Visual Prompts for Vision-Language Models
Sep 03, 2023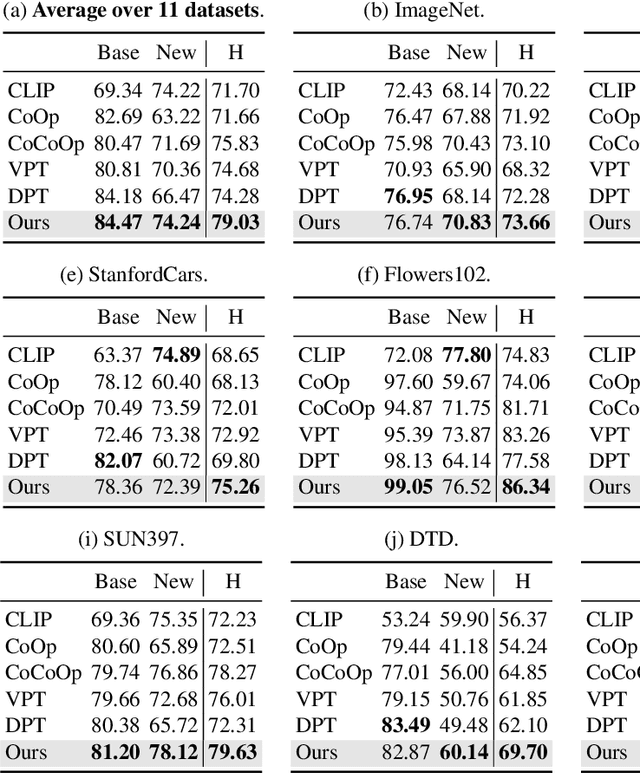

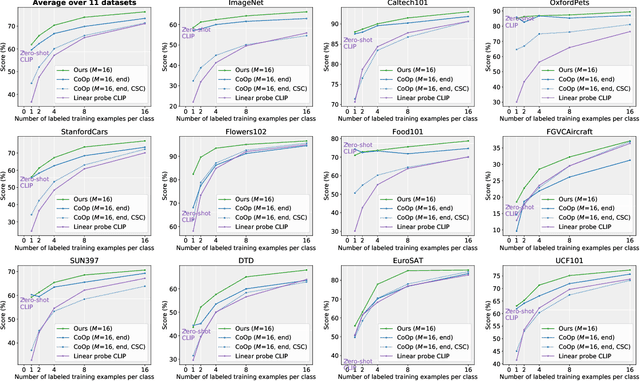
Prompt engineering is a powerful tool used to enhance the performance of pre-trained models on downstream tasks. For example, providing the prompt ``Let's think step by step" improved GPT-3's reasoning accuracy to 63% on MutiArith while prompting ``a photo of" filled with a class name enables CLIP to achieve $80$\% zero-shot accuracy on ImageNet. While previous research has explored prompt learning for the visual modality, analyzing what constitutes a good visual prompt specifically for image recognition is limited. In addition, existing visual prompt tuning methods' generalization ability is worse than text-only prompting tuning. This paper explores our key insight: synthetic text images are good visual prompts for vision-language models! To achieve that, we propose our LoGoPrompt, which reformulates the classification objective to the visual prompt selection and addresses the chicken-and-egg challenge of first adding synthetic text images as class-wise visual prompts or predicting the class first. Without any trainable visual prompt parameters, experimental results on 16 datasets demonstrate that our method consistently outperforms state-of-the-art methods in few-shot learning, base-to-new generalization, and domain generalization.