 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CLIPMasterPrints: Fooling Contrastive Language-Image Pre-training Using Latent Variable Evolution
Jul 07, 2023

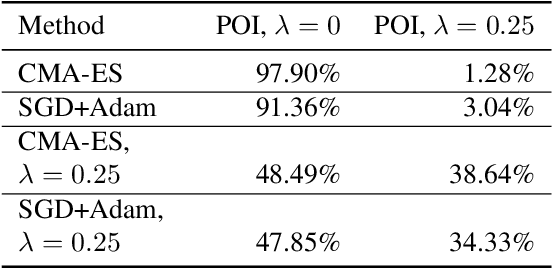
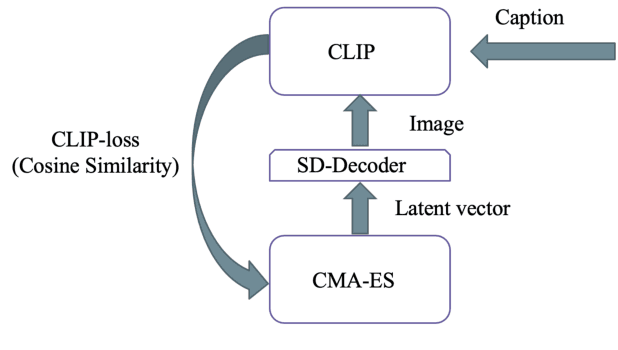
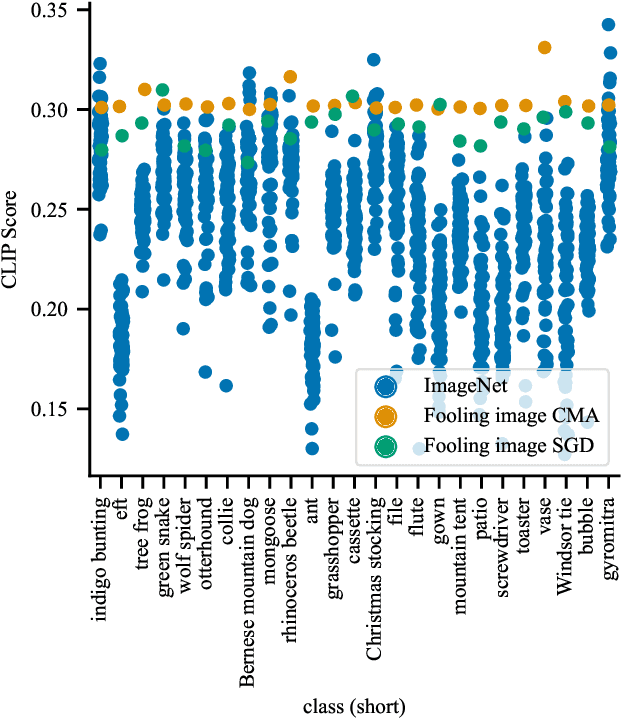
Models leveraging both visual and textual data such as Contrastive Language-Image Pre-training (CLIP), are increasingly gaining importance. In this work, we show that despite their versatility, such models are vulnerable to what we refer to as fooling master images. Fooling master images are capable of maximizing the confidence score of a CLIP model for a significant number of widely varying prompts, while being unrecognizable for humans. We demonstrate how fooling master images can be mined by searching the latent space of generative models by means of an evolution strategy or stochastic gradient descent. We investigate the properties of the mined fooling master images, and find that images trained on a small number of image captions potentially generalize to a much larger number of semantically related captions. Further, we evaluate two possible mitigation strategies and find that vulnerability to fooling master examples is closely related to a modality gap in contrastive pre-trained multi-modal networks. From the perspective of vulnerability to off-manifold attacks, we therefore argue for the mitigation of modality gaps in CLIP and related multi-modal approaches. Source code and mined CLIPMasterPrints are available at https://github.com/matfrei/CLIPMasterPrints.
Large AI Model Empowered Multimodal Semantic Communications
Sep 03, 2023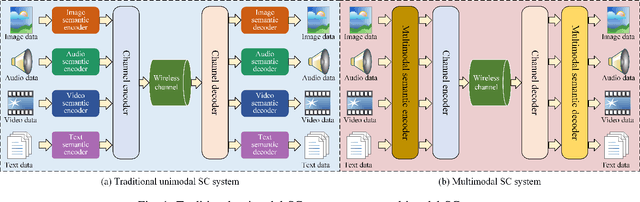
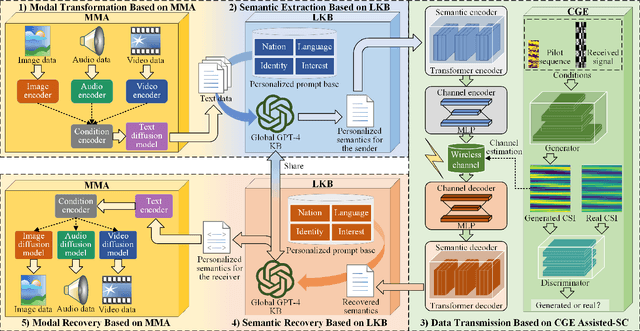
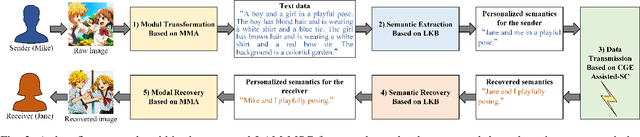
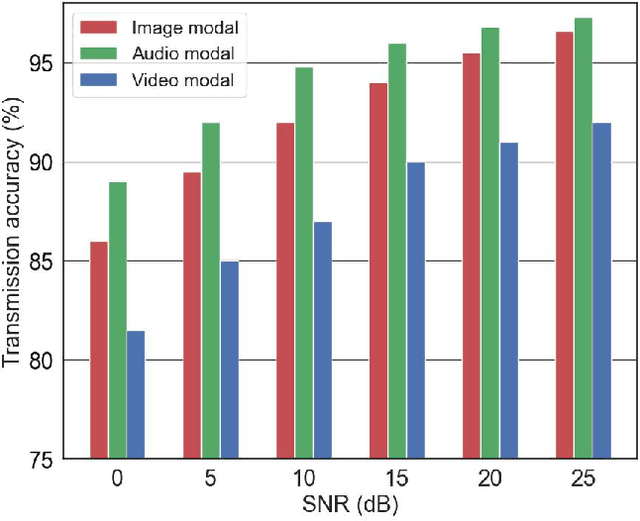
Multimodal signals, including text, audio, image and video, can be integrated into Semantic Communication (SC) for providing an immersive experience with low latency and high quality at the semantic level. However, the multimodal SC has several challenges, including data heterogeneity, semantic ambiguity, and signal fading. Recent advancements in large AI models, particularly in Multimodal Language Model (MLM) and Large Language Model (LLM), offer potential solutions for these issues. To this end, we propose a Large AI Model-based Multimodal SC (LAM-MSC) framework, in which we first present the MLM-based Multimodal Alignment (MMA) that utilizes the MLM to enable the transformation between multimodal and unimodal data while preserving semantic consistency. Then, a personalized LLM-based Knowledge Base (LKB) is proposed, which allows users to perform personalized semantic extraction or recovery through the LLM. This effectively addresses the semantic ambiguity. Finally, we apply the Conditional Generative adversarial networks-based channel Estimation (CGE) to obtain Channel State Information (CSI). This approach effectively mitigates the impact of fading channels in SC. Finally, we conduct simulations that demonstrate the superior performance of the LAM-MSC framework.
Correcting Motion Distortion for LIDAR HD-Map Localization
Aug 25, 2023Because scanning-LIDAR sensors require finite time to create a point cloud, sensor motion during a scan warps the resulting image, a phenomenon known as motion distortion or rolling shutter. Motion-distortion correction methods exist, but they rely on external measurements or Bayesian filtering over multiple LIDAR scans. In this paper we propose a novel algorithm that performs snapshot processing to obtain a motion-distortion correction. Snapshot processing, which registers a current LIDAR scan to a reference image without using external sensors or Bayesian filtering, is particularly relevant for localization to a high-definition (HD) map. Our approach, which we call Velocity-corrected Iterative Compact Ellipsoidal Transformation (VICET), extends the well-known Normal Distributions Transform (NDT) algorithm to solve jointly for both a 6 Degree-of-Freedom (DOF) rigid transform between two LIDAR scans and a set of 6DOF motion states that describe distortion within the current LIDAR scan. Using experiments, we show that VICET achieves significantly higher accuracy than NDT or Iterative Closest Point (ICP) algorithms when localizing a distorted raw LIDAR scan against an undistorted HD Map. We recommend the reader explore our open-source code and visualizations at https://github.com/mcdermatt/VICET, which supplements this manuscript.
POCO: 3D Pose and Shape Estimation with Confidence
Aug 24, 2023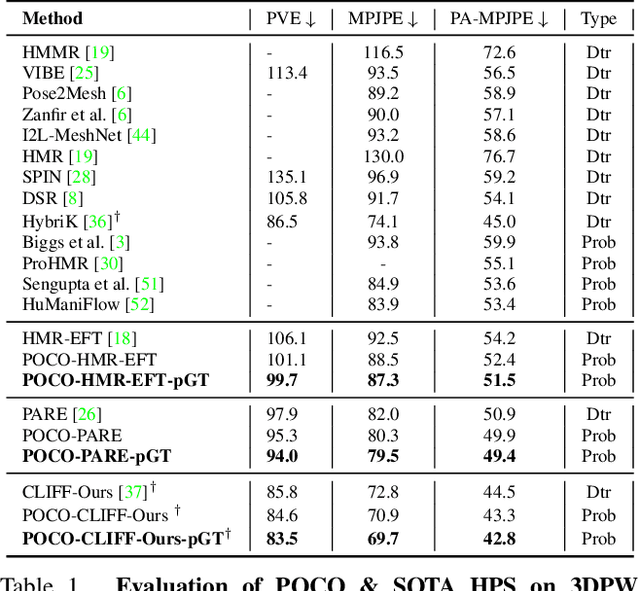
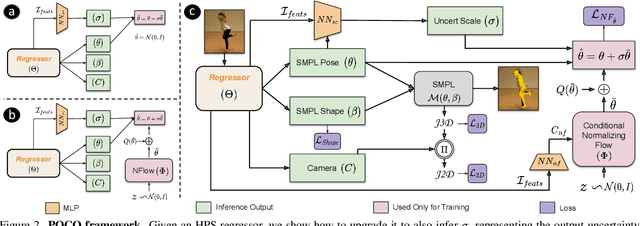
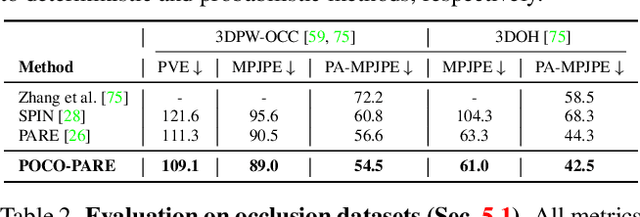
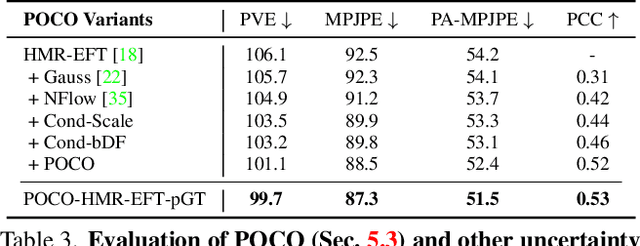
The regression of 3D Human Pose and Shape (HPS) from an image is becoming increasingly accurate. This makes the results useful for downstream tasks like human action recognition or 3D graphics. Yet, no regressor is perfect, and accuracy can be affected by ambiguous image evidence or by poses and appearance that are unseen during training. Most current HPS regressors, however, do not report the confidence of their outputs, meaning that downstream tasks cannot differentiate accurate estimates from inaccurate ones. To address this, we develop POCO, a novel framework for training HPS regressors to estimate not only a 3D human body, but also their confidence, in a single feed-forward pass. Specifically, POCO estimates both the 3D body pose and a per-sample variance. The key idea is to introduce a Dual Conditioning Strategy (DCS) for regressing uncertainty that is highly correlated to pose reconstruction quality. The POCO framework can be applied to any HPS regressor and here we evaluate it by modifying HMR, PARE, and CLIFF. In all cases, training the network to reason about uncertainty helps it learn to more accurately estimate 3D pose. While this was not our goal, the improvement is modest but consistent. Our main motivation is to provide uncertainty estimates for downstream tasks; we demonstrate this in two ways: (1) We use the confidence estimates to bootstrap HPS training. Given unlabelled image data, we take the confident estimates of a POCO-trained regressor as pseudo ground truth. Retraining with this automatically-curated data improves accuracy. (2) We exploit uncertainty in video pose estimation by automatically identifying uncertain frames (e.g. due to occlusion) and inpainting these from confident frames. Code and models will be available for research at https://poco.is.tue.mpg.de.
Dealing with Small Datasets for Deep Learning in Medical Imaging: An Evaluation of Self-Supervised Pre-Training on CT Scans Comparing Contrastive and Masked Autoencoder Methods for Convolutional Models
Aug 24, 2023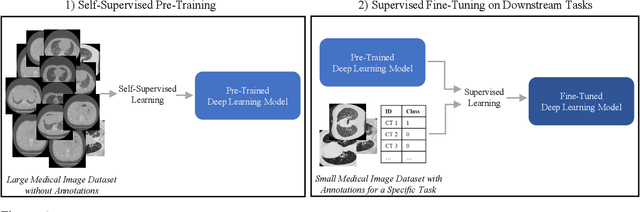
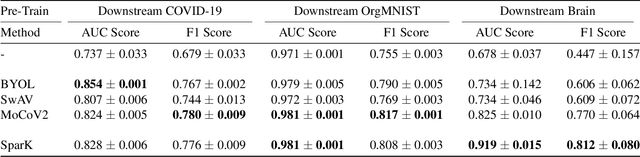
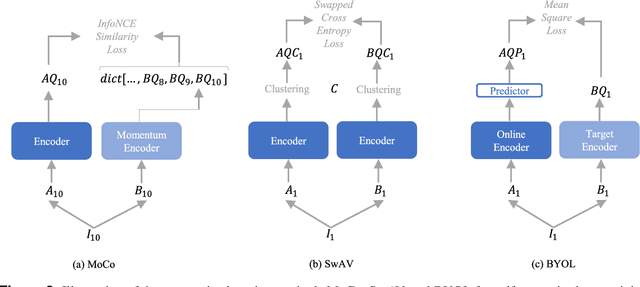
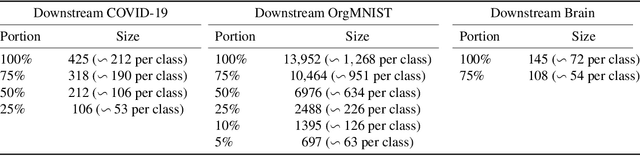
Deep learning in medical imaging has the potential to minimize the risk of diagnostic errors, reduce radiologist workload, and accelerate diagnosis. Training such deep learning models requires large and accurate datasets, with annotations for all training samples. However, in the medical imaging domain, annotated datasets for specific tasks are often small due to the high complexity of annotations, limited access, or the rarity of diseases. To address this challenge, deep learning models can be pre-trained on large image datasets without annotations using methods from the field of self-supervised learning. After pre-training, small annotated datasets are sufficient to fine-tune the models for a specific task. The most popular self-supervised pre-training approaches in medical imaging are based on contrastive learning. However, recent studies in natural image processing indicate a strong potential for masked autoencoder approaches. Our work compares state-of-the-art contrastive learning methods with the recently introduced masked autoencoder approach "SparK" for convolutional neural networks (CNNs) on medical images. Therefore we pre-train on a large unannotated CT image dataset and fine-tune on several CT classification tasks. Due to the challenge of obtaining sufficient annotated training data in medical imaging, it is of particular interest to evaluate how the self-supervised pre-training methods perform when fine-tuning on small datasets. By experimenting with gradually reducing the training dataset size for fine-tuning, we find that the reduction has different effects depending on the type of pre-training chosen. The SparK pre-training method is more robust to the training dataset size than the contrastive methods. Based on our results, we propose the SparK pre-training for medical imaging tasks with only small annotated datasets.
Hyperbolic Convolutional Neural Networks
Aug 29, 2023
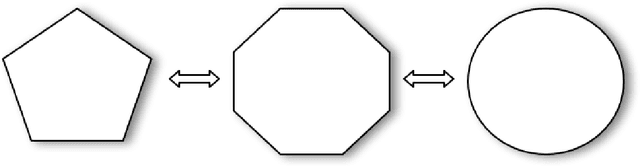
Deep Learning is mostly responsible for the surge of interest in Artificial Intelligence in the last decade. So far, deep learning researchers have been particularly successful in the domain of image processing, where Convolutional Neural Networks are used. Although excelling at image classification, Convolutional Neural Networks are quite naive in that no inductive bias is set on the embedding space for images. Similar flaws are also exhibited by another type of Convolutional Networks - Graph Convolutional Neural Networks. However, using non-Euclidean space for embedding data might result in more robust and explainable models. One example of such a non-Euclidean space is hyperbolic space. Hyperbolic spaces are particularly useful due to their ability to fit more data in a low-dimensional space and tree-likeliness properties. These attractive properties have been previously used in multiple papers which indicated that they are beneficial for building hierarchical embeddings using shallow models and, recently, using MLPs and RNNs. However, no papers have yet suggested a general approach to using Hyperbolic Convolutional Neural Networks for structured data processing, although these are the most common examples of data used. Therefore, the goal of this work is to devise a general recipe for building Hyperbolic Convolutional Neural Networks. We hypothesize that ability of hyperbolic space to capture hierarchy in the data would lead to better performance. This ability should be particularly useful in cases where data has a tree-like structure. Since this is the case for many existing datasets \citep{wordnet, imagenet, fb15k}, we argue that such a model would be advantageous both in terms of applications and future research prospects.
CGAM: Click-Guided Attention Module for Interactive Pathology Image Segmentation via Backpropagating Refinement
Jul 03, 2023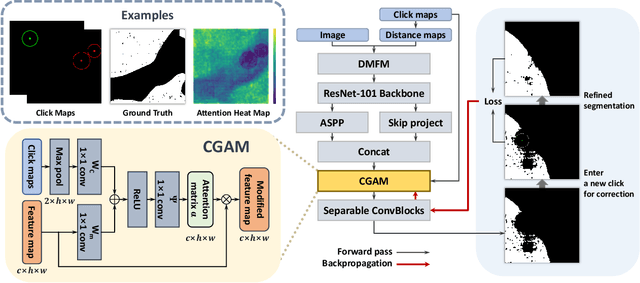

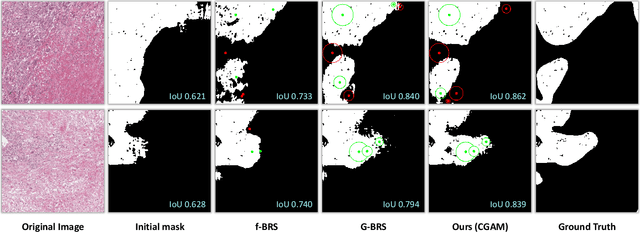
Tumor region segmentation is an essential task for the quantitative analysis of digital pathology. Recently presented deep neural networks have shown state-of-the-art performance in various image-segmentation tasks. However, because of the unclear boundary between the cancerous and normal regions in pathology images, despite using modern methods, it is difficult to produce satisfactory segmentation results in terms of the reliability and accuracy required for medical data. In this study, we propose an interactive segmentation method that allows users to refine the output of deep neural networks through click-type user interactions. The primary method is to formulate interactive segmentation as an optimization problem that leverages both user-provided click constraints and semantic information in a feature map using a click-guided attention module (CGAM). Unlike other existing methods, CGAM avoids excessive changes in segmentation results, which can lead to the overfitting of user clicks. Another advantage of CGAM is that the model size is independent of input image size. Experimental results on pathology image datasets indicated that our method performs better than existing state-of-the-art methods.
Turning a CLIP Model into a Scene Text Spotter
Aug 21, 2023
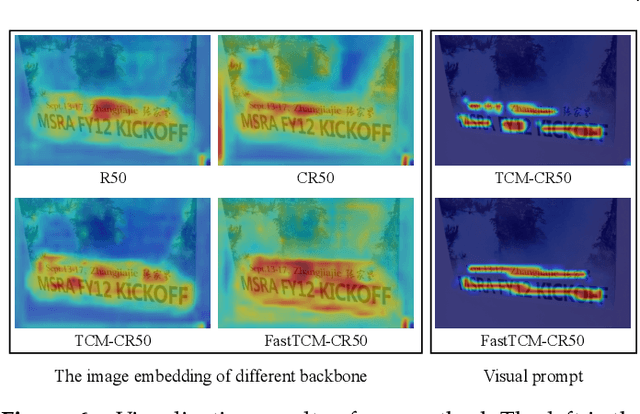
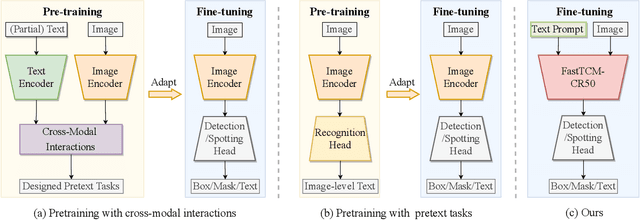
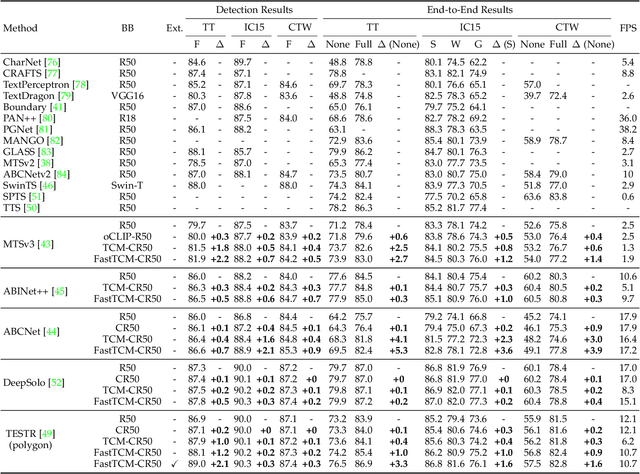
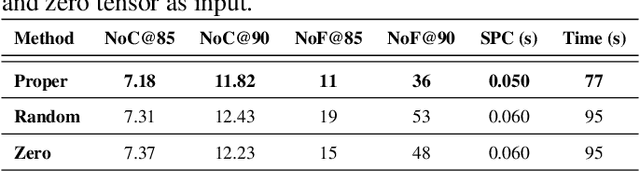
We exploit the potential of the large-scale Contrastive Language-Image Pretraining (CLIP) model to enhance scene text detection and spotting tasks, transforming it into a robust backbone, FastTCM-CR50. This backbone utilizes visual prompt learning and cross-attention in CLIP to extract image and text-based prior knowledge. Using predefined and learnable prompts, FastTCM-CR50 introduces an instance-language matching process to enhance the synergy between image and text embeddings, thereby refining text regions. Our Bimodal Similarity Matching (BSM) module facilitates dynamic language prompt generation, enabling offline computations and improving performance. FastTCM-CR50 offers several advantages: 1) It can enhance existing text detectors and spotters, improving performance by an average of 1.7% and 1.5%, respectively. 2) It outperforms the previous TCM-CR50 backbone, yielding an average improvement of 0.2% and 0.56% in text detection and spotting tasks, along with a 48.5% increase in inference speed. 3) It showcases robust few-shot training capabilities. Utilizing only 10% of the supervised data, FastTCM-CR50 improves performance by an average of 26.5% and 5.5% for text detection and spotting tasks, respectively. 4) It consistently enhances performance on out-of-distribution text detection and spotting datasets, particularly the NightTime-ArT subset from ICDAR2019-ArT and the DOTA dataset for oriented object detection. The code is available at https://github.com/wenwenyu/TCM.
Joint Hierarchical Priors and Adaptive Spatial Resolution for Efficient Neural Image Compression
Jul 05, 2023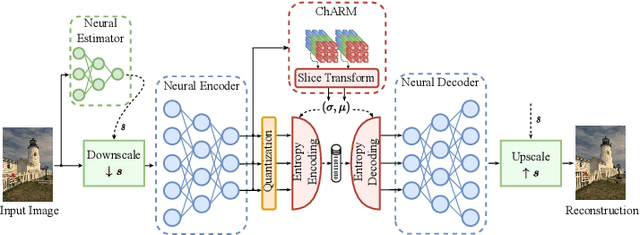
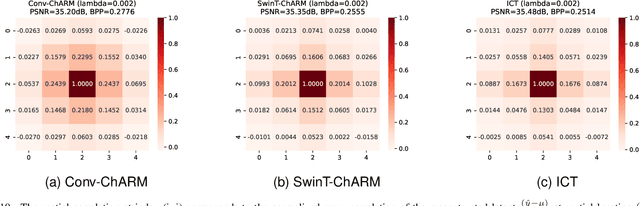

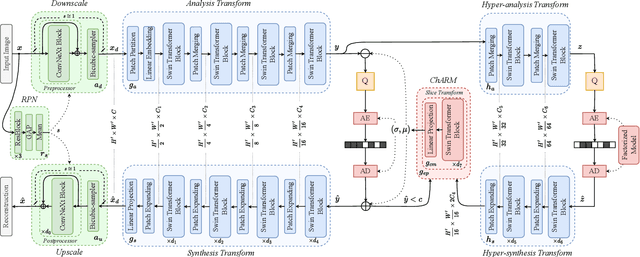
Recently, the performance of neural image compression (NIC) has steadily improved thanks to the last line of study, reaching or outperforming state-of-the-art conventional codecs. Despite significant progress, current NIC methods still rely on ConvNet-based entropy coding, limited in modeling long-range dependencies due to their local connectivity and the increasing number of architectural biases and priors, resulting in complex underperforming models with high decoding latency. Motivated by the efficiency investigation of the Tranformer-based transform coding framework, namely SwinT-ChARM, we propose to enhance the latter, as first, with a more straightforward yet effective Tranformer-based channel-wise auto-regressive prior model, resulting in an absolute image compression transformer (ICT). Through the proposed ICT, we can capture both global and local contexts from the latent representations and better parameterize the distribution of the quantized latents. Further, we leverage a learnable scaling module with a sandwich ConvNeXt-based pre-/post-processor to accurately extract more compact latent codes while reconstructing higher-quality images. Extensive experimental results on benchmark datasets showed that the proposed framework significantly improves the trade-off between coding efficiency and decoder complexity over the versatile video coding (VVC) reference encoder (VTM-18.0) and the neural codec SwinT-ChARM. Moreover, we provide model scaling studies to verify the computational efficiency of our approach and conduct several objective and subjective analyses to bring to the fore the performance gap between the adaptive image compression transformer (AICT) and the neural codec SwinT-ChARM.
SoccerNet 2023 Tracking Challenge -- 3rd place MOT4MOT Team Technical Report
Aug 31, 2023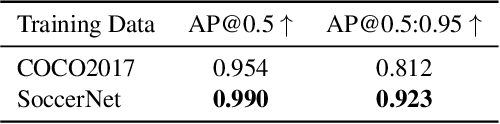
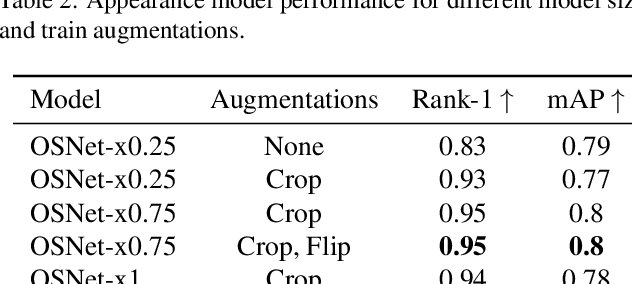
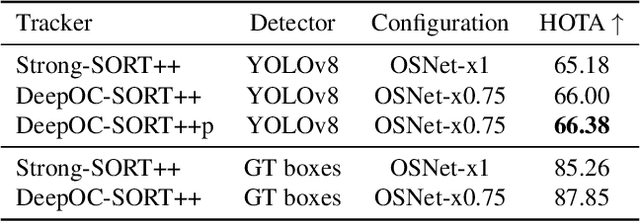
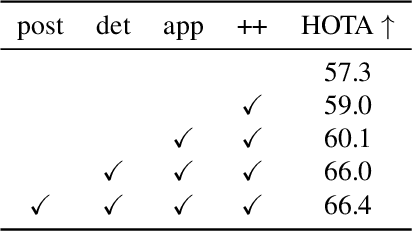
The SoccerNet 2023 tracking challenge requires the detection and tracking of soccer players and the ball. In this work, we present our approach to tackle these tasks separately. We employ a state-of-the-art online multi-object tracker and a contemporary object detector for player tracking. To overcome the limitations of our online approach, we incorporate a post-processing stage using interpolation and appearance-free track merging. Additionally, an appearance-based track merging technique is used to handle the termination and creation of tracks far from the image boundaries. Ball tracking is formulated as single object detection, and a fine-tuned YOLOv8l detector with proprietary filtering improves the detection precision. Our method achieves 3rd place on the SoccerNet 2023 tracking challenge with a HOTA score of 66.27.