 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Using Neural Networks for Fast SAR Roughness Estimation of High Resolution Images
Sep 06, 2023
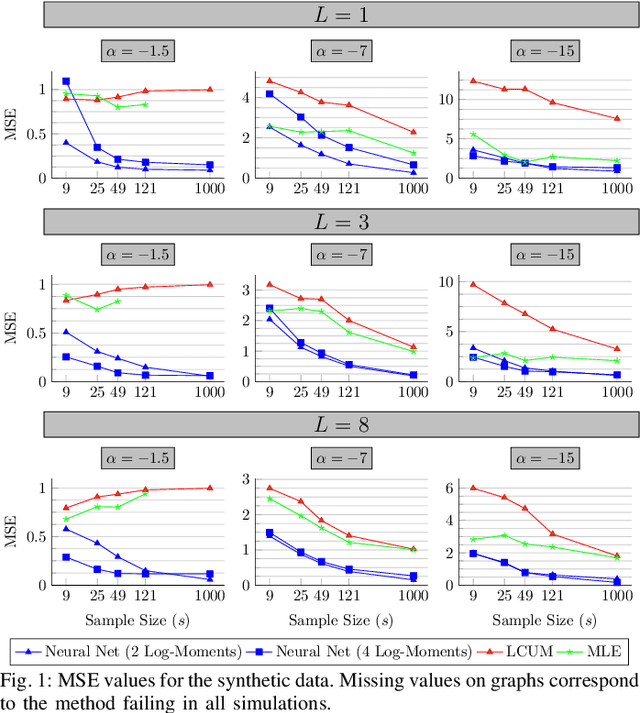


The analysis of Synthetic Aperture Radar (SAR) imagery is an important step in remote sensing applications, and it is a challenging problem due to its inherent speckle noise. One typical solution is to model the data using the $G_I^0$ distribution and extract its roughness information, which in turn can be used in posterior imaging tasks, such as segmentation, classification and interpretation. This leads to the need of quick and reliable estimation of the roughness parameter from SAR data, especially with high resolution images. Unfortunately, traditional parameter estimation procedures are slow and prone to estimation failures. In this work, we proposed a neural network-based estimation framework that first learns how to predict underlying parameters of $G_I^0$ samples and then can be used to estimate the roughness of unseen data. We show that this approach leads to an estimator that is quicker, yields less estimation error and is less prone to failures than the traditional estimation procedures for this problem, even when we use a simple network. More importantly, we show that this same methodology can be generalized to handle image inputs and, even if trained on purely synthetic data for a few seconds, is able to perform real time pixel-wise roughness estimation for high resolution real SAR imagery.
A Graph Multi-separator Problem for Image Segmentation
Jul 10, 2023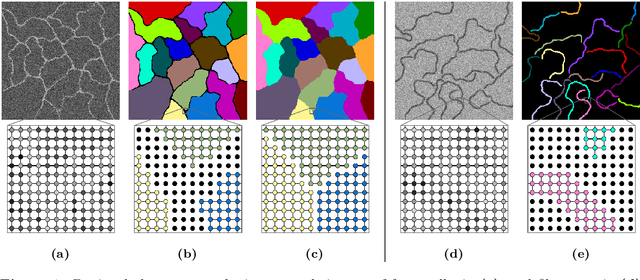
We propose a novel abstraction of the image segmentation task in the form of a combinatorial optimization problem that we call the multi-separator problem. Feasible solutions indicate for every pixel whether it belongs to a segment or a segment separator, and indicate for pairs of pixels whether or not the pixels belong to the same segment. This is in contrast to the closely related lifted multicut problem where every pixel is associated to a segment and no pixel explicitly represents a separating structure. While the multi-separator problem is NP-hard, we identify two special cases for which it can be solved efficiently. Moreover, we define two local search algorithms for the general case and demonstrate their effectiveness in segmenting simulated volume images of foam cells and filaments.
On the Cultural Gap in Text-to-Image Generation
Jul 06, 2023
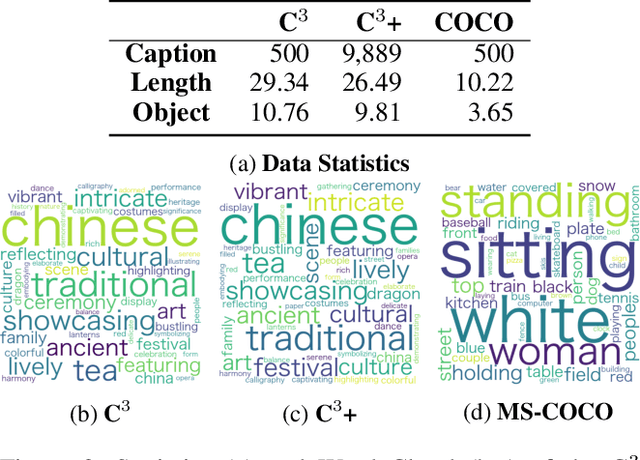
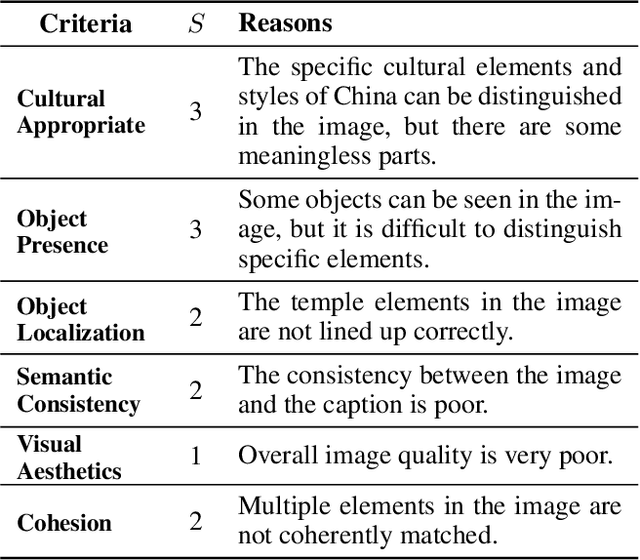
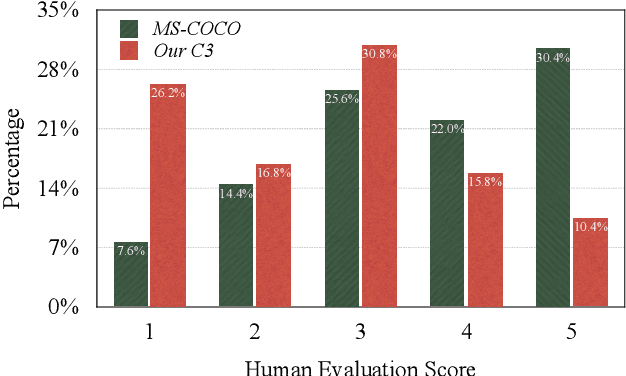
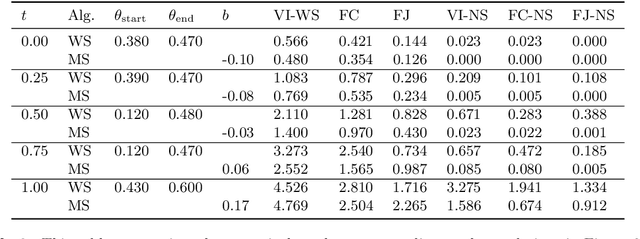
One challenge in text-to-image (T2I) generation is the inadvertent reflection of culture gaps present in the training data, which signifies the disparity in generated image quality when the cultural elements of the input text are rarely collected in the training set. Although various T2I models have shown impressive but arbitrary examples, there is no benchmark to systematically evaluate a T2I model's ability to generate cross-cultural images. To bridge the gap, we propose a Challenging Cross-Cultural (C3) benchmark with comprehensive evaluation criteria, which can assess how well-suited a model is to a target culture. By analyzing the flawed images generated by the Stable Diffusion model on the C3 benchmark, we find that the model often fails to generate certain cultural objects. Accordingly, we propose a novel multi-modal metric that considers object-text alignment to filter the fine-tuning data in the target culture, which is used to fine-tune a T2I model to improve cross-cultural generation. Experimental results show that our multi-modal metric provides stronger data selection performance on the C3 benchmark than existing metrics, in which the object-text alignment is crucial. We release the benchmark, data, code, and generated images to facilitate future research on culturally diverse T2I generation (https://github.com/longyuewangdcu/C3-Bench).
Recursive Detection and Analysis of Nanoparticles in Scanning Electron Microscopy Images
Aug 17, 2023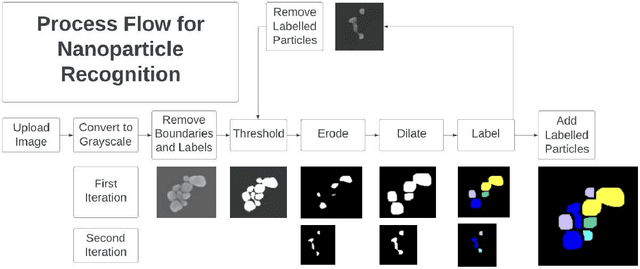
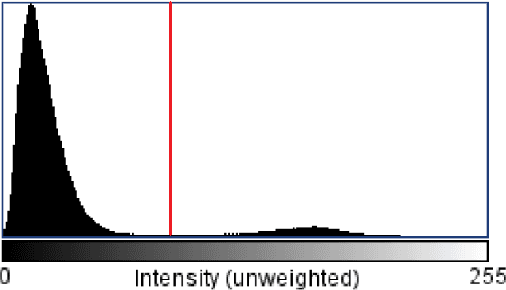


In this study, we present a computational framework tailored for the precise detection and comprehensive analysis of nanoparticles within scanning electron microscopy (SEM) images. The primary objective of this framework revolves around the accurate localization of nanoparticle coordinates, accompanied by secondary objectives encompassing the extraction of pertinent morphological attributes including area, orientation, brightness, and length. Constructed leveraging the robust image processing capabilities of Python, particularly harnessing libraries such as OpenCV, SciPy, and Scikit-Image, the framework employs an amalgamation of techniques, including thresholding, dilating, and eroding, to enhance the fidelity of image processing outcomes. The ensuing nanoparticle data is seamlessly integrated into the RStudio environment to facilitate meticulous post-processing analysis. This encompasses a comprehensive evaluation of model accuracy, discernment of feature distribution patterns, and the identification of intricate particle arrangements. The finalized framework exhibits high nanoparticle identification within the primary sample image and boasts 97\% accuracy in detecting particles across five distinct test images drawn from a SEM nanoparticle dataset. Furthermore, the framework demonstrates the capability to discern nanoparticles of faint intensity, eluding manual labeling within the control group.
Learning Descriptive Image Captioning via Semipermeable Maximum Likelihood Estimation
Jun 27, 2023Image captioning aims to describe visual content in natural language. As 'a picture is worth a thousand words', there could be various correct descriptions for an image. However, with maximum likelihood estimation as the training objective, the captioning model is penalized whenever its prediction mismatches with the label. For instance, when the model predicts a word expressing richer semantics than the label, it will be penalized and optimized to prefer more concise expressions, referred to as conciseness optimization. In contrast, predictions that are more concise than labels lead to richness optimization. Such conflicting optimization directions could eventually result in the model generating general descriptions. In this work, we introduce Semipermeable MaxImum Likelihood Estimation (SMILE), which allows richness optimization while blocking conciseness optimization, thus encouraging the model to generate longer captions with more details. Extensive experiments on two mainstream image captioning datasets MSCOCO and Flickr30K demonstrate that SMILE significantly enhances the descriptiveness of generated captions. We further provide in-depth investigations to facilitate a better understanding of how SMILE works.
CIEM: Contrastive Instruction Evaluation Method for Better Instruction Tuning
Sep 05, 2023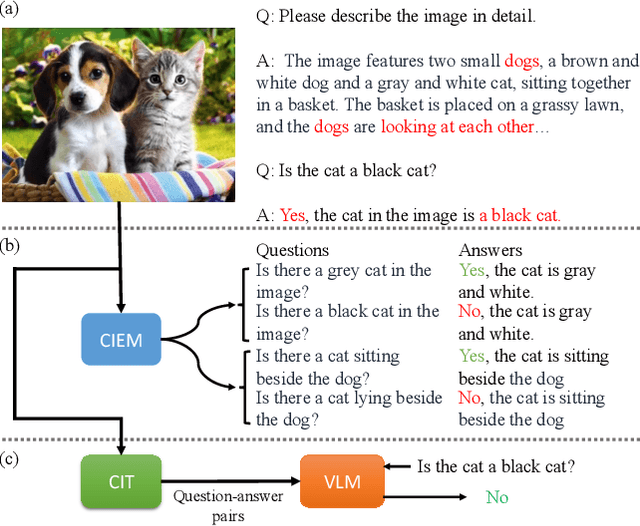

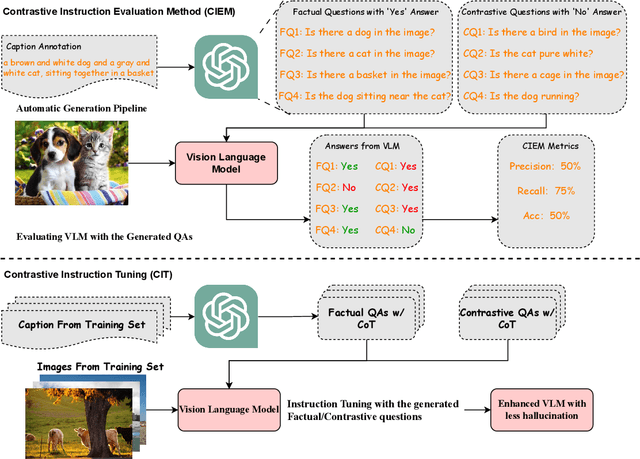

Nowadays, the research on Large Vision-Language Models (LVLMs) has been significantly promoted thanks to the success of Large Language Models (LLM). Nevertheless, these Vision-Language Models (VLMs) are suffering from the drawback of hallucination -- due to insufficient understanding of vision and language modalities, VLMs may generate incorrect perception information when doing downstream applications, for example, captioning a non-existent entity. To address the hallucination phenomenon, on the one hand, we introduce a Contrastive Instruction Evaluation Method (CIEM), which is an automatic pipeline that leverages an annotated image-text dataset coupled with an LLM to generate factual/contrastive question-answer pairs for the evaluation of the hallucination of VLMs. On the other hand, based on CIEM, we further propose a new instruction tuning method called CIT (the abbreviation of Contrastive Instruction Tuning) to alleviate the hallucination of VLMs by automatically producing high-quality factual/contrastive question-answer pairs and corresponding justifications for model tuning. Through extensive experiments on CIEM and CIT, we pinpoint the hallucination issues commonly present in existing VLMs, the disability of the current instruction-tuning dataset to handle the hallucination phenomenon and the superiority of CIT-tuned VLMs over both CIEM and public datasets.
Robustness and Generalizability of Deepfake Detection: A Study with Diffusion Models
Sep 05, 2023
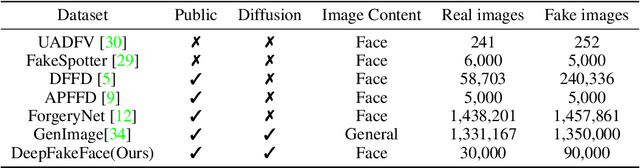
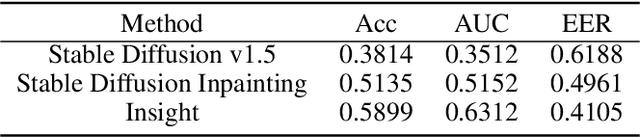

The rise of deepfake images, especially of well-known personalities, poses a serious threat to the dissemination of authentic information. To tackle this, we present a thorough investigation into how deepfakes are produced and how they can be identified. The cornerstone of our research is a rich collection of artificial celebrity faces, titled DeepFakeFace (DFF). We crafted the DFF dataset using advanced diffusion models and have shared it with the community through online platforms. This data serves as a robust foundation to train and test algorithms designed to spot deepfakes. We carried out a thorough review of the DFF dataset and suggest two evaluation methods to gauge the strength and adaptability of deepfake recognition tools. The first method tests whether an algorithm trained on one type of fake images can recognize those produced by other methods. The second evaluates the algorithm's performance with imperfect images, like those that are blurry, of low quality, or compressed. Given varied results across deepfake methods and image changes, our findings stress the need for better deepfake detectors. Our DFF dataset and tests aim to boost the development of more effective tools against deepfakes.
Debiasing Counterfactuals In the Presence of Spurious Correlations
Aug 21, 2023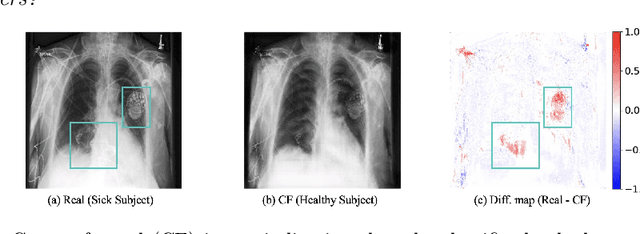

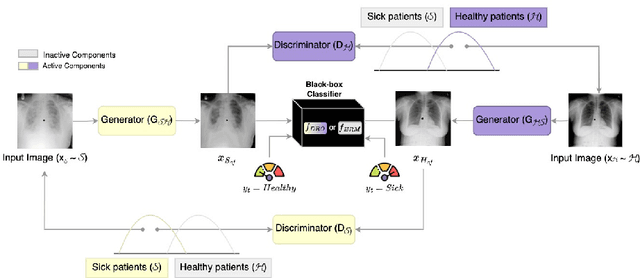
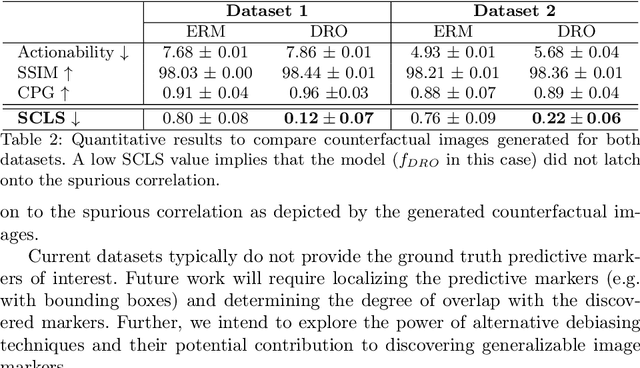
Deep learning models can perform well in complex medical imaging classification tasks, even when basing their conclusions on spurious correlations (i.e. confounders), should they be prevalent in the training dataset, rather than on the causal image markers of interest. This would thereby limit their ability to generalize across the population. Explainability based on counterfactual image generation can be used to expose the confounders but does not provide a strategy to mitigate the bias. In this work, we introduce the first end-to-end training framework that integrates both (i) popular debiasing classifiers (e.g. distributionally robust optimization (DRO)) to avoid latching onto the spurious correlations and (ii) counterfactual image generation to unveil generalizable imaging markers of relevance to the task. Additionally, we propose a novel metric, Spurious Correlation Latching Score (SCLS), to quantify the extent of the classifier reliance on the spurious correlation as exposed by the counterfactual images. Through comprehensive experiments on two public datasets (with the simulated and real visual artifacts), we demonstrate that the debiasing method: (i) learns generalizable markers across the population, and (ii) successfully ignores spurious correlations and focuses on the underlying disease pathology.
Multi-Scale and Multi-Layer Contrastive Learning for Domain Generalization
Aug 28, 2023During the past decade, deep neural networks have led to fast-paced progress and significant achievements in computer vision problems, for both academia and industry. Yet despite their success, state-of-the-art image classification approaches fail to generalize well in previously unseen visual contexts, as required by many real-world applications. In this paper, we focus on this domain generalization (DG) problem and argue that the generalization ability of deep convolutional neural networks can be improved by taking advantage of multi-layer and multi-scaled representations of the network. We introduce a framework that aims at improving domain generalization of image classifiers by combining both low-level and high-level features at multiple scales, enabling the network to implicitly disentangle representations in its latent space and learn domain-invariant attributes of the depicted objects. Additionally, to further facilitate robust representation learning, we propose a novel objective function, inspired by contrastive learning, which aims at constraining the extracted representations to remain invariant under distribution shifts. We demonstrate the effectiveness of our method by evaluating on the domain generalization datasets of PACS, VLCS, Office-Home and NICO. Through extensive experimentation, we show that our model is able to surpass the performance of previous DG methods and consistently produce competitive and state-of-the-art results in all datasets.
Attention Where It Matters: Rethinking Visual Document Understanding with Selective Region Concentration
Sep 03, 2023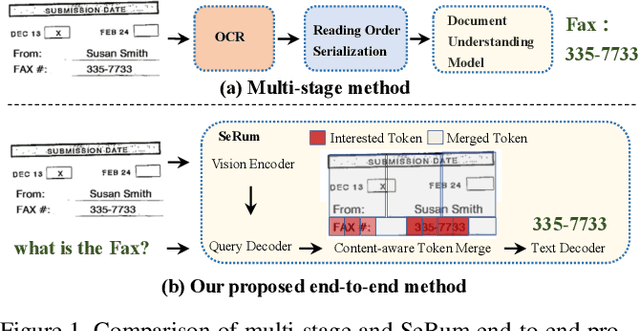
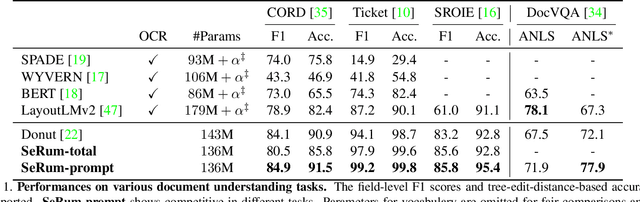
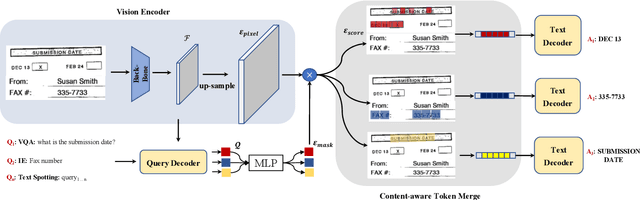

We propose a novel end-to-end document understanding model called SeRum (SElective Region Understanding Model) for extracting meaningful information from document images, including document analysis, retrieval, and office automation. Unlike state-of-the-art approaches that rely on multi-stage technical schemes and are computationally expensive, SeRum converts document image understanding and recognition tasks into a local decoding process of the visual tokens of interest, using a content-aware token merge module. This mechanism enables the model to pay more attention to regions of interest generated by the query decoder, improving the model's effectiveness and speeding up the decoding speed of the generative scheme. We also designed several pre-training tasks to enhance the understanding and local awareness of the model. Experimental results demonstrate that SeRum achieves state-of-the-art performance on document understanding tasks and competitive results on text spotting tasks. SeRum represents a substantial advancement towards enabling efficient and effective end-to-end document understanding.