 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TOPIQ: A Top-down Approach from Semantics to Distortions for Image Quality Assessment
Aug 06, 2023

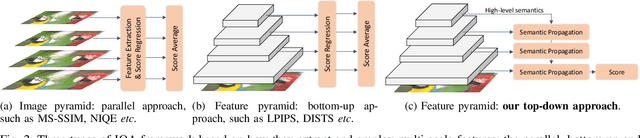
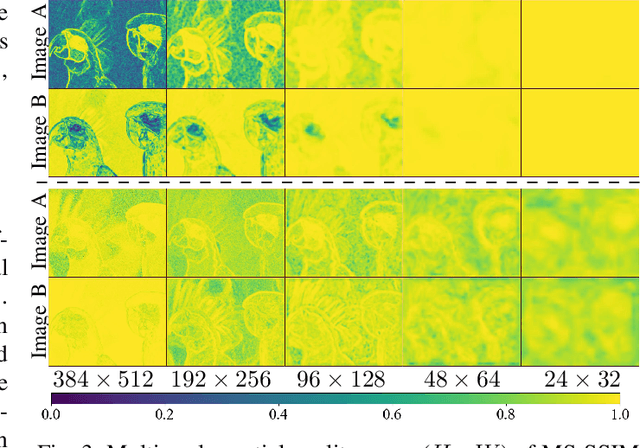
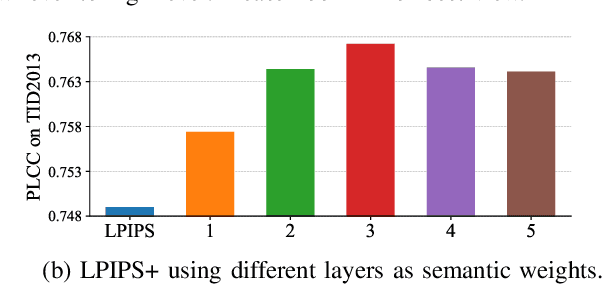
Image Quality Assessment (IQA) is a fundamental task in computer vision that has witnessed remarkable progress with deep neural networks. Inspired by the characteristics of the human visual system, existing methods typically use a combination of global and local representations (\ie, multi-scale features) to achieve superior performance. However, most of them adopt simple linear fusion of multi-scale features, and neglect their possibly complex relationship and interaction. In contrast, humans typically first form a global impression to locate important regions and then focus on local details in those regions. We therefore propose a top-down approach that uses high-level semantics to guide the IQA network to focus on semantically important local distortion regions, named as \emph{TOPIQ}. Our approach to IQA involves the design of a heuristic coarse-to-fine network (CFANet) that leverages multi-scale features and progressively propagates multi-level semantic information to low-level representations in a top-down manner. A key component of our approach is the proposed cross-scale attention mechanism, which calculates attention maps for lower level features guided by higher level features. This mechanism emphasizes active semantic regions for low-level distortions, thereby improving performance. CFANet can be used for both Full-Reference (FR) and No-Reference (NR) IQA. We use ResNet50 as its backbone and demonstrate that CFANet achieves better or competitive performance on most public FR and NR benchmarks compared with state-of-the-art methods based on vision transformers, while being much more efficient (with only ${\sim}13\%$ FLOPS of the current best FR method). Codes are released at \url{https://github.com/chaofengc/IQA-PyTorch}.
Learning to predict 3D rotational dynamics from images of a rigid body with unknown mass distribution
Aug 24, 2023

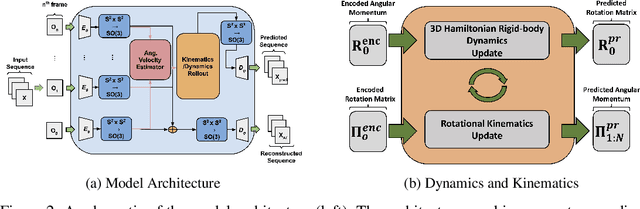

In many real-world settings, image observations of freely rotating 3D rigid bodies, may be available when low-dimensional measurements are not. However, the high-dimensionality of image data precludes the use of classical estimation techniques to learn the dynamics. The usefulness of standard deep learning methods is also limited because an image of a rigid body reveals nothing about the distribution of mass inside the body, which, together with initial angular velocity, is what determines how the body will rotate. We present a physics-informed neural network model to estimate and predict 3D rotational dynamics from image sequences. We achieve this using a multi-stage prediction pipeline that maps individual images to a latent representation homeomorphic to $\mathbf{SO}(3)$, computes angular velocities from latent pairs, and predicts future latent states using the Hamiltonian equations of motion. We demonstrate the efficacy of our approach on new rotating rigid-body datasets of sequences of synthetic images of rotating objects, including cubes, prisms and satellites, with unknown uniform and non-uniform mass distributions.
Frequency-aware optical coherence tomography image super-resolution via conditional generative adversarial neural network
Jul 20, 2023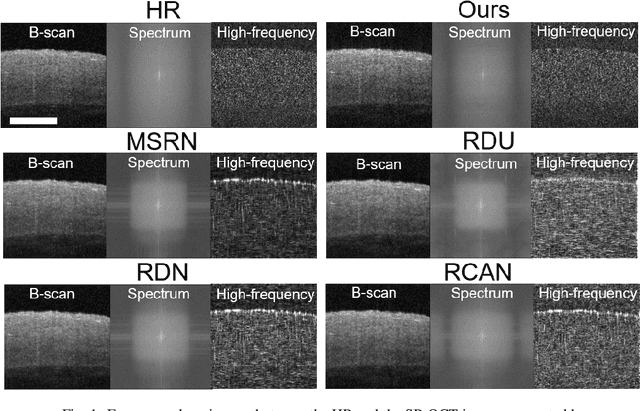
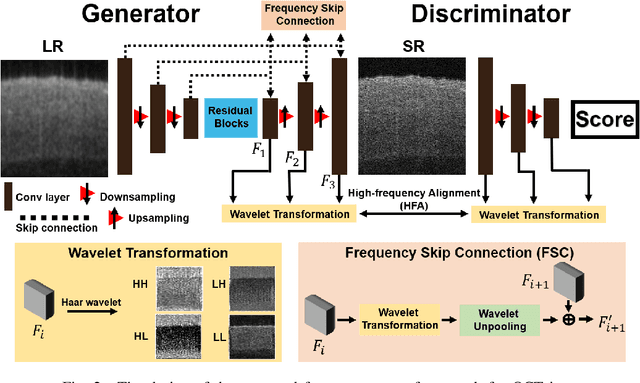
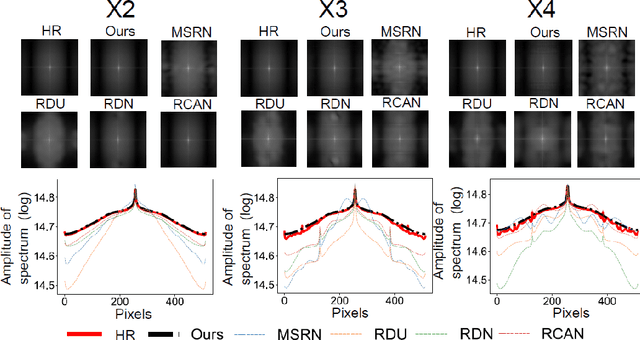
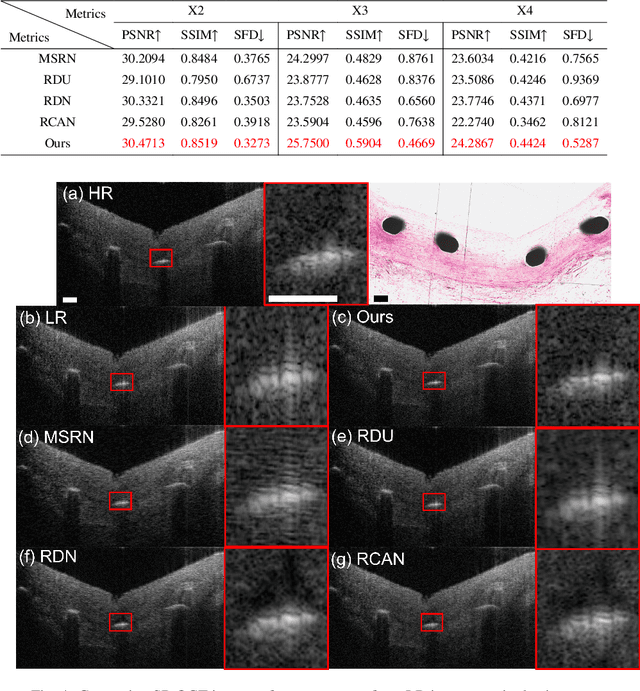
Optical coherence tomography (OCT) has stimulated a wide range of medical image-based diagnosis and treatment in fields such as cardiology and ophthalmology. Such applications can be further facilitated by deep learning-based super-resolution technology, which improves the capability of resolving morphological structures. However, existing deep learning-based method only focuses on spatial distribution and disregard frequency fidelity in image reconstruction, leading to a frequency bias. To overcome this limitation, we propose a frequency-aware super-resolution framework that integrates three critical frequency-based modules (i.e., frequency transformation, frequency skip connection, and frequency alignment) and frequency-based loss function into a conditional generative adversarial network (cGAN). We conducted a large-scale quantitative study from an existing coronary OCT dataset to demonstrate the superiority of our proposed framework over existing deep learning frameworks. In addition, we confirmed the generalizability of our framework by applying it to fish corneal images and rat retinal images, demonstrating its capability to super-resolve morphological details in eye imaging.
AnyDoor: Zero-shot Object-level Image Customization
Jul 18, 2023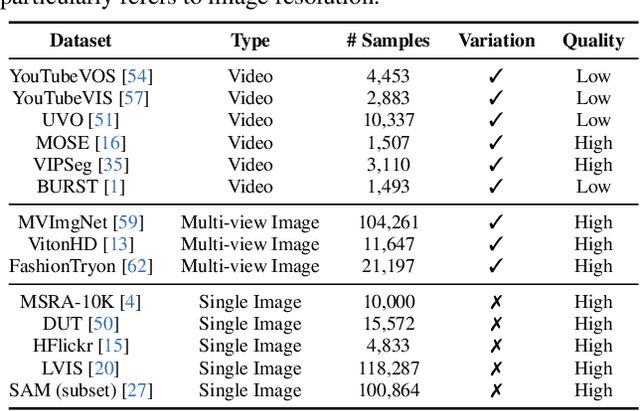
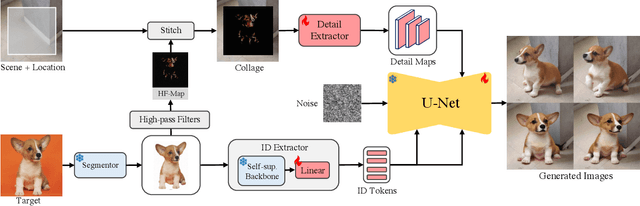
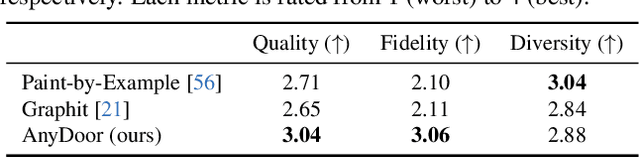

This work presents AnyDoor, a diffusion-based image generator with the power to teleport target objects to new scenes at user-specified locations in a harmonious way. Instead of tuning parameters for each object, our model is trained only once and effortlessly generalizes to diverse object-scene combinations at the inference stage. Such a challenging zero-shot setting requires an adequate characterization of a certain object. To this end, we complement the commonly used identity feature with detail features, which are carefully designed to maintain texture details yet allow versatile local variations (e.g., lighting, orientation, posture, etc.), supporting the object in favorably blending with different surroundings. We further propose to borrow knowledge from video datasets, where we can observe various forms (i.e., along the time axis) of a single object, leading to stronger model generalizability and robustness. Extensive experiments demonstrate the superiority of our approach over existing alternatives as well as its great potential in real-world applications, such as virtual try-on and object moving. Project page is https://damo-vilab.github.io/AnyDoor-Page/.
LEyes: A Lightweight Framework for Deep Learning-Based Eye Tracking using Synthetic Eye Images
Sep 12, 2023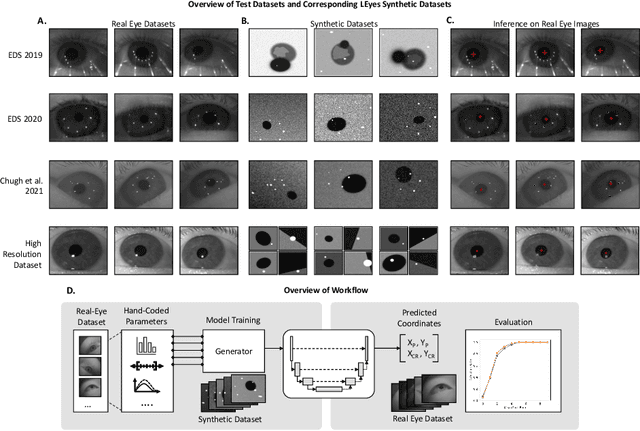
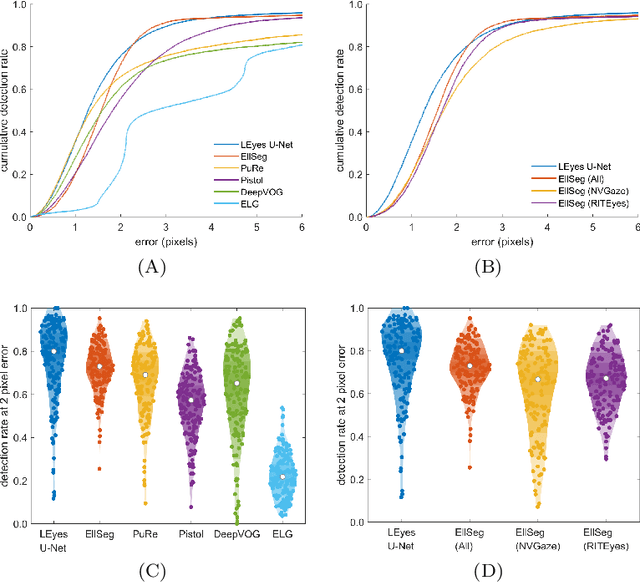
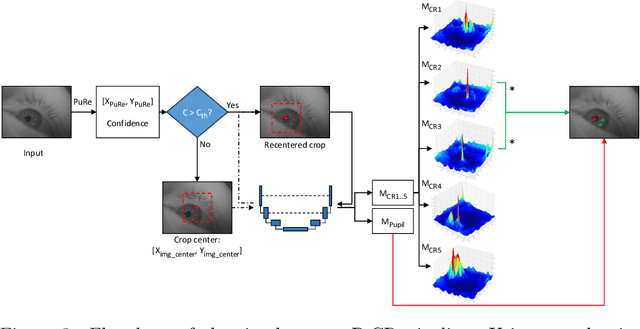
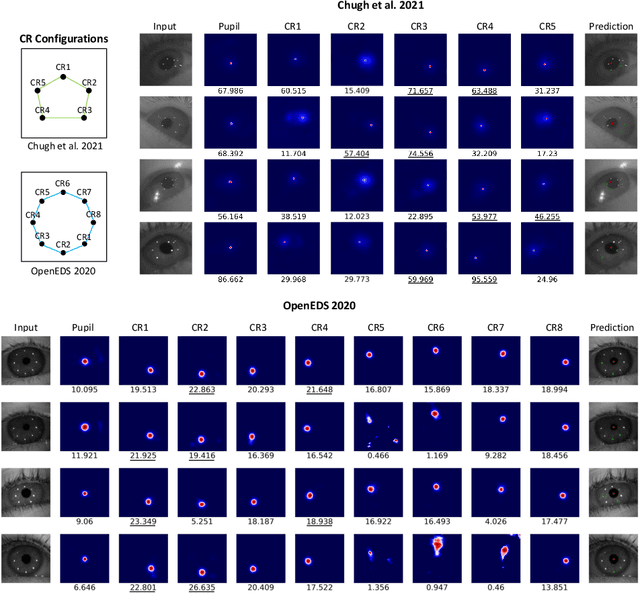
Deep learning has bolstered gaze estimation techniques, but real-world deployment has been impeded by inadequate training datasets. This problem is exacerbated by both hardware-induced variations in eye images and inherent biological differences across the recorded participants, leading to both feature and pixel-level variance that hinders the generalizability of models trained on specific datasets. While synthetic datasets can be a solution, their creation is both time and resource-intensive. To address this problem, we present a framework called Light Eyes or "LEyes" which, unlike conventional photorealistic methods, only models key image features required for video-based eye tracking using simple light distributions. LEyes facilitates easy configuration for training neural networks across diverse gaze-estimation tasks. We demonstrate that models trained using LEyes outperform other state-of-the-art algorithms in terms of pupil and CR localization across well-known datasets. In addition, a LEyes trained model outperforms the industry standard eye tracker using significantly more cost-effective hardware. Going forward, we are confident that LEyes will revolutionize synthetic data generation for gaze estimation models, and lead to significant improvements of the next generation video-based eye trackers.
Accelerating Deep Neural Networks via Semi-Structured Activation Sparsity
Sep 12, 2023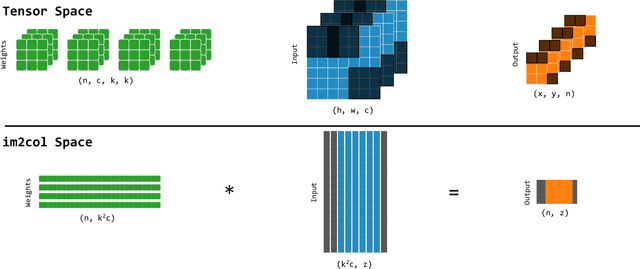
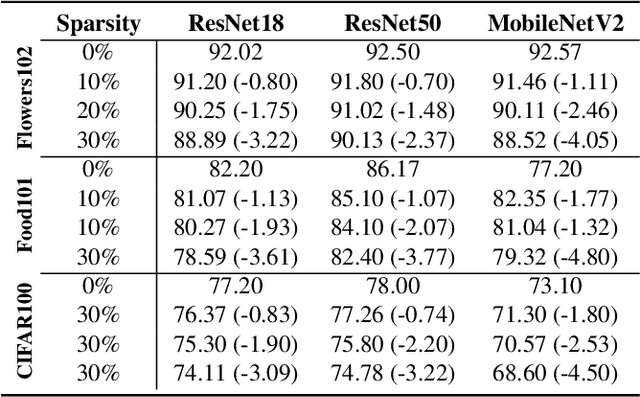
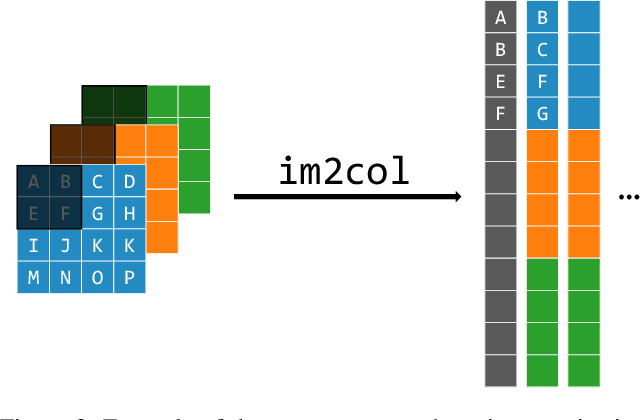
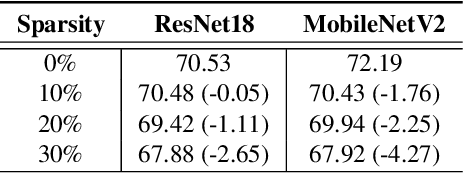
The demand for efficient processing of deep neural networks (DNNs) on embedded devices is a significant challenge limiting their deployment. Exploiting sparsity in the network's feature maps is one of the ways to reduce its inference latency. It is known that unstructured sparsity results in lower accuracy degradation with respect to structured sparsity but the former needs extensive inference engine changes to get latency benefits. To tackle this challenge, we propose a solution to induce semi-structured activation sparsity exploitable through minor runtime modifications. To attain high speedup levels at inference time, we design a sparse training procedure with awareness of the final position of the activations while computing the General Matrix Multiplication (GEMM). We extensively evaluate the proposed solution across various models for image classification and object detection tasks. Remarkably, our approach yields a speed improvement of $1.25 \times$ with a minimal accuracy drop of $1.1\%$ for the ResNet18 model on the ImageNet dataset. Furthermore, when combined with a state-of-the-art structured pruning method, the resulting models provide a good latency-accuracy trade-off, outperforming models that solely employ structured pruning techniques.
Elucidating the solution space of extended reverse-time SDE for diffusion models
Sep 12, 2023



Diffusion models (DMs) demonstrate potent image generation capabilities in various generative modeling tasks. Nevertheless, their primary limitation lies in slow sampling speed, requiring hundreds or thousands of sequential function evaluations through large neural networks to generate high-quality images. Sampling from DMs can be seen as solving corresponding stochastic differential equations (SDEs) or ordinary differential equations (ODEs). In this work, we formulate the sampling process as an extended reverse-time SDE (ER SDE), unifying prior explorations into ODEs and SDEs. Leveraging the semi-linear structure of ER SDE solutions, we offer exact solutions and arbitrarily high-order approximate solutions for VP SDE and VE SDE, respectively. Based on the solution space of the ER SDE, we yield mathematical insights elucidating the superior performance of ODE solvers over SDE solvers in terms of fast sampling. Additionally, we unveil that VP SDE solvers stand on par with their VE SDE counterparts. Finally, we devise fast and training-free samplers, ER-SDE Solvers, elevating the efficiency of stochastic samplers to unprecedented levels. Experimental results demonstrate achieving 3.45 FID in 20 function evaluations and 2.24 FID in 50 function evaluations on the ImageNet 64$\times$64 dataset.
Improving Generalization Capability of Deep Learning-Based Nuclei Instance Segmentation by Non-deterministic Train Time and Deterministic Test Time Stain Normalization
Sep 12, 2023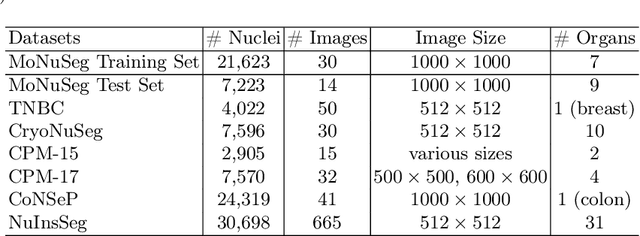
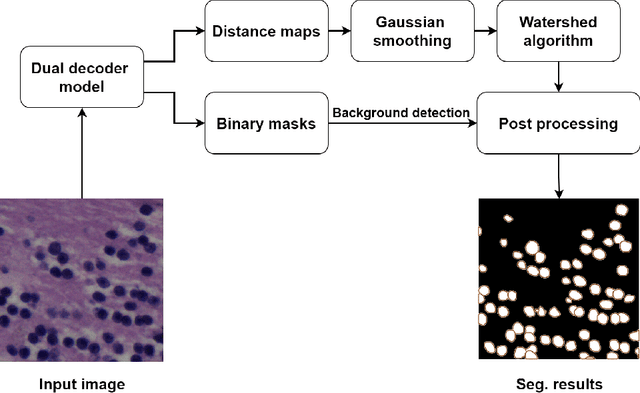
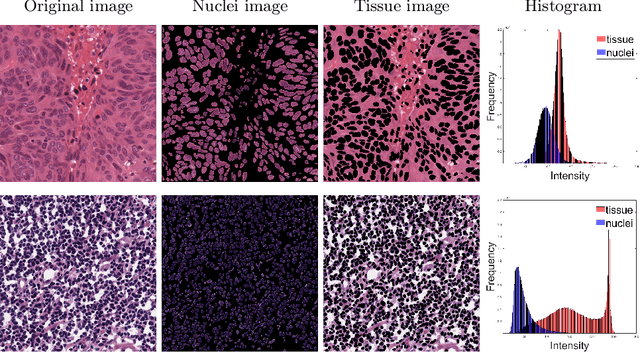

With the advent of digital pathology and microscopic systems that can scan and save whole slide histological images automatically, there is a growing trend to use computerized methods to analyze acquired images. Among different histopathological image analysis tasks, nuclei instance segmentation plays a fundamental role in a wide range of clinical and research applications. While many semi- and fully-automatic computerized methods have been proposed for nuclei instance segmentation, deep learning (DL)-based approaches have been shown to deliver the best performances. However, the performance of such approaches usually degrades when tested on unseen datasets. In this work, we propose a novel approach to improve the generalization capability of a DL-based automatic segmentation approach. Besides utilizing one of the state-of-the-art DL-based models as a baseline, our method incorporates non-deterministic train time and deterministic test time stain normalization. We trained the model with one single training set and evaluated its segmentation performance on seven test datasets. Our results show that the proposed method provides up to 5.77%, 5.36%, and 5.27% better performance in segmenting nuclei based on Dice score, aggregated Jaccard index, and panoptic quality score, respectively, compared to the baseline segmentation model.
Everyone Can Attack: Repurpose Lossy Compression as a Natural Backdoor Attack
Aug 31, 2023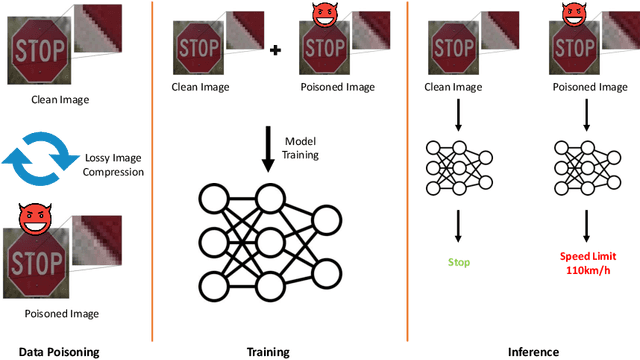
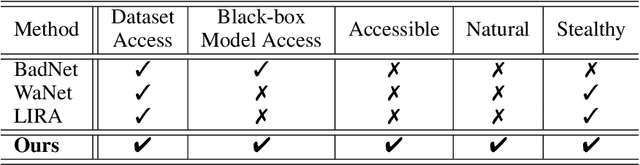
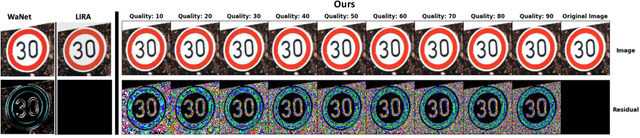
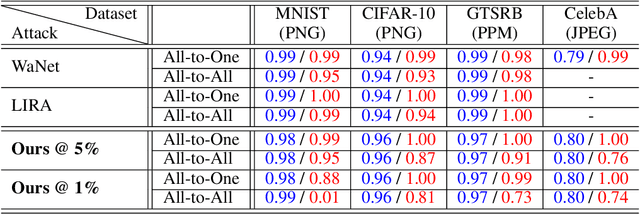
The vulnerabilities to backdoor attacks have recently threatened the trustworthiness of machine learning models in practical applications. Conventional wisdom suggests that not everyone can be an attacker since the process of designing the trigger generation algorithm often involves significant effort and extensive experimentation to ensure the attack's stealthiness and effectiveness. Alternatively, this paper shows that there exists a more severe backdoor threat: anyone can exploit an easily-accessible algorithm for silent backdoor attacks. Specifically, this attacker can employ the widely-used lossy image compression from a plethora of compression tools to effortlessly inject a trigger pattern into an image without leaving any noticeable trace; i.e., the generated triggers are natural artifacts. One does not require extensive knowledge to click on the "convert" or "save as" button while using tools for lossy image compression. Via this attack, the adversary does not need to design a trigger generator as seen in prior works and only requires poisoning the data. Empirically, the proposed attack consistently achieves 100% attack success rate in several benchmark datasets such as MNIST, CIFAR-10, GTSRB and CelebA. More significantly, the proposed attack can still achieve almost 100% attack success rate with very small (approximately 10%) poisoning rates in the clean label setting. The generated trigger of the proposed attack using one lossy compression algorithm is also transferable across other related compression algorithms, exacerbating the severity of this backdoor threat. This work takes another crucial step toward understanding the extensive risks of backdoor attacks in practice, urging practitioners to investigate similar attacks and relevant backdoor mitigation methods.
Class-Incremental Grouping Network for Continual Audio-Visual Learning
Sep 11, 2023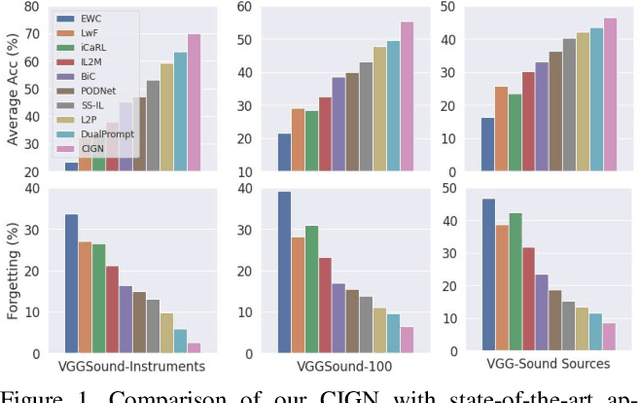
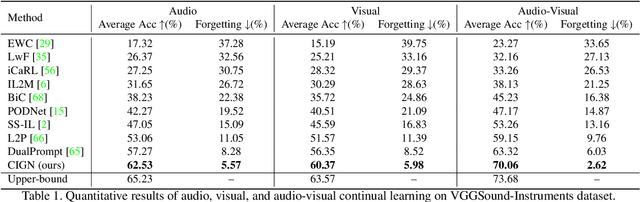
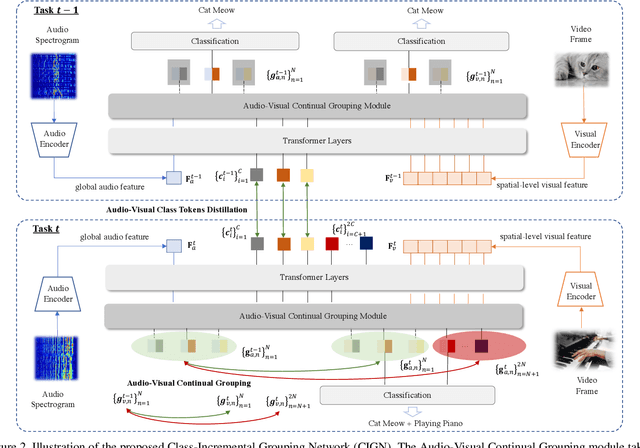
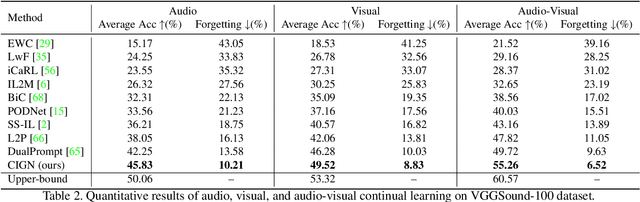
Continual learning is a challenging problem in which models need to be trained on non-stationary data across sequential tasks for class-incremental learning. While previous methods have focused on using either regularization or rehearsal-based frameworks to alleviate catastrophic forgetting in image classification, they are limited to a single modality and cannot learn compact class-aware cross-modal representations for continual audio-visual learning. To address this gap, we propose a novel class-incremental grouping network (CIGN) that can learn category-wise semantic features to achieve continual audio-visual learning. Our CIGN leverages learnable audio-visual class tokens and audio-visual grouping to continually aggregate class-aware features. Additionally, it utilizes class tokens distillation and continual grouping to prevent forgetting parameters learned from previous tasks, thereby improving the model's ability to capture discriminative audio-visual categories. We conduct extensive experiments on VGGSound-Instruments, VGGSound-100, and VGG-Sound Sources benchmarks. Our experimental results demonstrate that the CIGN achieves state-of-the-art audio-visual class-incremental learning performance. Code is available at https://github.com/stoneMo/CIGN.