 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Uncertainty-Driven Multi-Scale Feature Fusion Network for Real-time Image Deraining
Jul 19, 2023

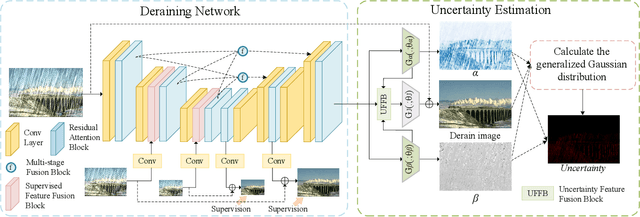
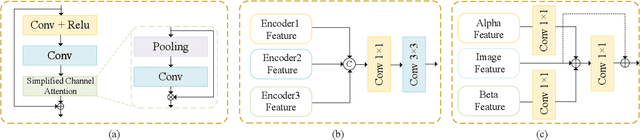
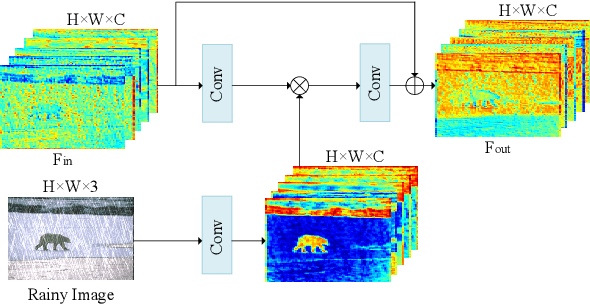
Visual-based measurement systems are frequently affected by rainy weather due to the degradation caused by rain streaks in captured images, and existing imaging devices struggle to address this issue in real-time. While most efforts leverage deep networks for image deraining and have made progress, their large parameter sizes hinder deployment on resource-constrained devices. Additionally, these data-driven models often produce deterministic results, without considering their inherent epistemic uncertainty, which can lead to undesired reconstruction errors. Well-calibrated uncertainty can help alleviate prediction errors and assist measurement devices in mitigating risks and improving usability. Therefore, we propose an Uncertainty-Driven Multi-Scale Feature Fusion Network (UMFFNet) that learns the probability mapping distribution between paired images to estimate uncertainty. Specifically, we introduce an uncertainty feature fusion block (UFFB) that utilizes uncertainty information to dynamically enhance acquired features and focus on blurry regions obscured by rain streaks, reducing prediction errors. In addition, to further boost the performance of UMFFNet, we fused feature information from multiple scales to guide the network for efficient collaborative rain removal. Extensive experiments demonstrate that UMFFNet achieves significant performance improvements with few parameters, surpassing state-of-the-art image deraining methods.
Unveiling Camouflage: A Learnable Fourier-based Augmentation for Camouflaged Object Detection and Instance Segmentation
Aug 29, 2023
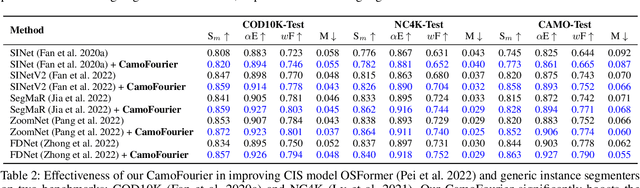
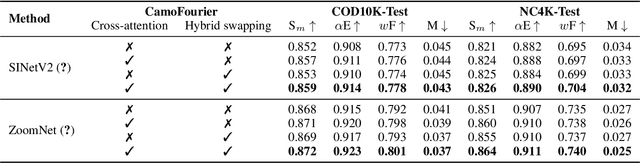

Camouflaged object detection (COD) and camouflaged instance segmentation (CIS) aim to recognize and segment objects that are blended into their surroundings, respectively. While several deep neural network models have been proposed to tackle those tasks, augmentation methods for COD and CIS have not been thoroughly explored. Augmentation strategies can help improve the performance of models by increasing the size and diversity of the training data and exposing the model to a wider range of variations in the data. Besides, we aim to automatically learn transformations that help to reveal the underlying structure of camouflaged objects and allow the model to learn to better identify and segment camouflaged objects. To achieve this, we propose a learnable augmentation method in the frequency domain for COD and CIS via Fourier transform approach, dubbed CamoFourier. Our method leverages a conditional generative adversarial network and cross-attention mechanism to generate a reference image and an adaptive hybrid swapping with parameters to mix the low-frequency component of the reference image and the high-frequency component of the input image. This approach aims to make camouflaged objects more visible for detection and segmentation models. Without bells and whistles, our proposed augmentation method boosts the performance of camouflaged object detectors and camouflaged instance segmenters by large margins.
Hierarchical Semantic Tree Concept Whitening for Interpretable Image Classification
Jul 10, 2023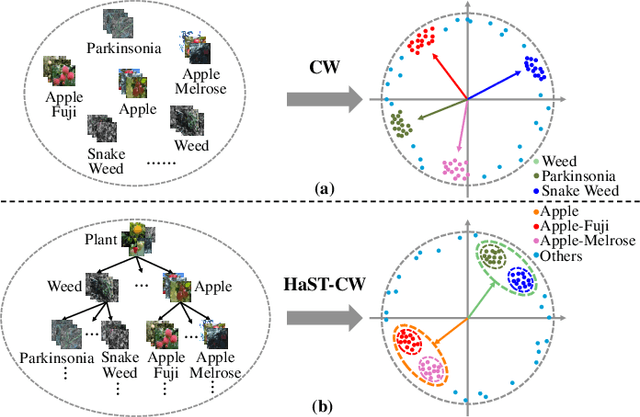
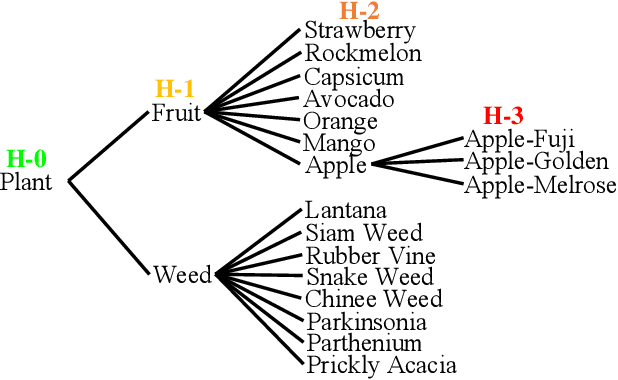
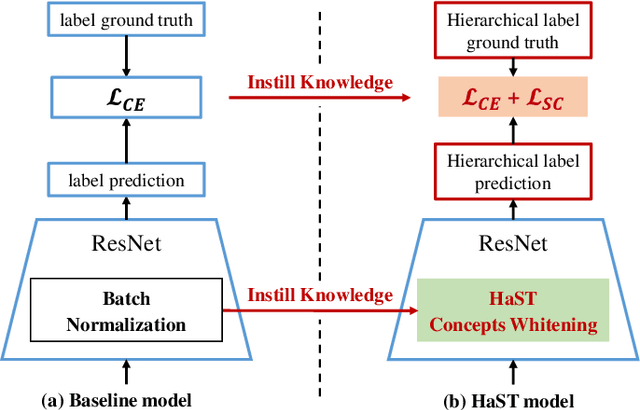
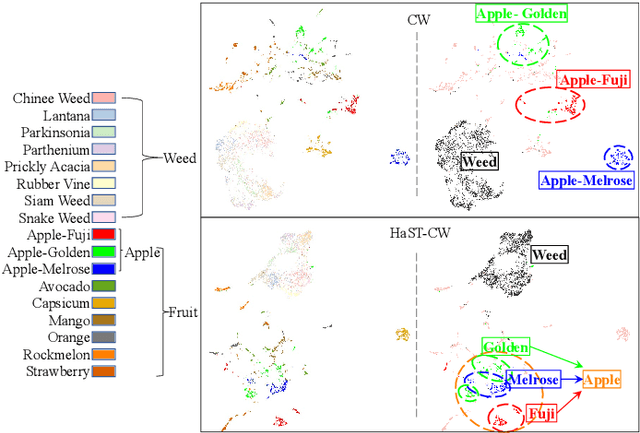
With the popularity of deep neural networks (DNNs), model interpretability is becoming a critical concern. Many approaches have been developed to tackle the problem through post-hoc analysis, such as explaining how predictions are made or understanding the meaning of neurons in middle layers. Nevertheless, these methods can only discover the patterns or rules that naturally exist in models. In this work, rather than relying on post-hoc schemes, we proactively instill knowledge to alter the representation of human-understandable concepts in hidden layers. Specifically, we use a hierarchical tree of semantic concepts to store the knowledge, which is leveraged to regularize the representations of image data instances while training deep models. The axes of the latent space are aligned with the semantic concepts, where the hierarchical relations between concepts are also preserved. Experiments on real-world image datasets show that our method improves model interpretability, showing better disentanglement of semantic concepts, without negatively affecting model classification performance.
Exchanging-based Multimodal Fusion with Transformer
Sep 05, 2023
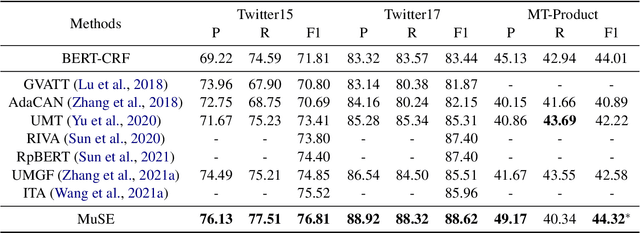
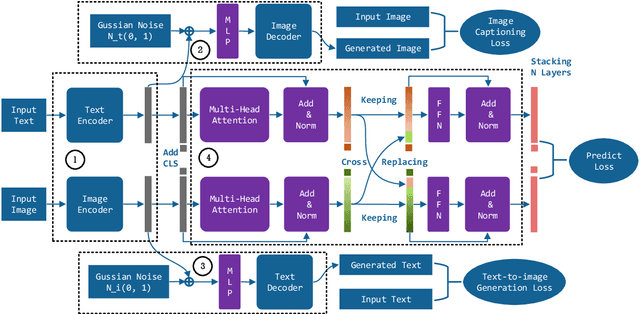
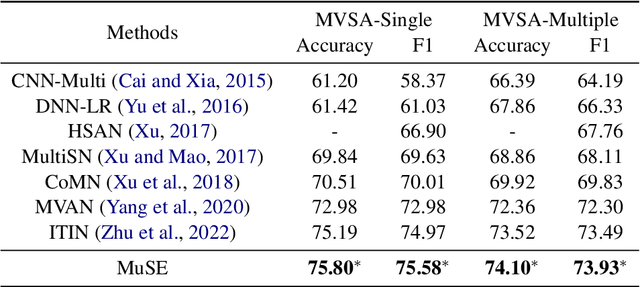
We study the problem of multimodal fusion in this paper. Recent exchanging-based methods have been proposed for vision-vision fusion, which aim to exchange embeddings learned from one modality to the other. However, most of them project inputs of multimodalities into different low-dimensional spaces and cannot be applied to the sequential input data. To solve these issues, in this paper, we propose a novel exchanging-based multimodal fusion model MuSE for text-vision fusion based on Transformer. We first use two encoders to separately map multimodal inputs into different low-dimensional spaces. Then we employ two decoders to regularize the embeddings and pull them into the same space. The two decoders capture the correlations between texts and images with the image captioning task and the text-to-image generation task, respectively. Further, based on the regularized embeddings, we present CrossTransformer, which uses two Transformer encoders with shared parameters as the backbone model to exchange knowledge between multimodalities. Specifically, CrossTransformer first learns the global contextual information of the inputs in the shallow layers. After that, it performs inter-modal exchange by selecting a proportion of tokens in one modality and replacing their embeddings with the average of embeddings in the other modality. We conduct extensive experiments to evaluate the performance of MuSE on the Multimodal Named Entity Recognition task and the Multimodal Sentiment Analysis task. Our results show the superiority of MuSE against other competitors. Our code and data are provided at https://github.com/RecklessRonan/MuSE.
Physically Grounded Vision-Language Models for Robotic Manipulation
Sep 13, 2023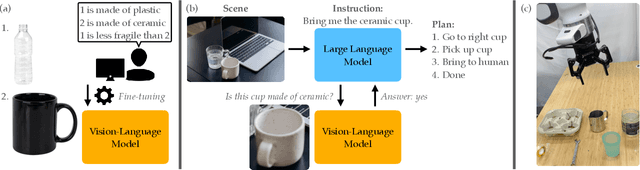

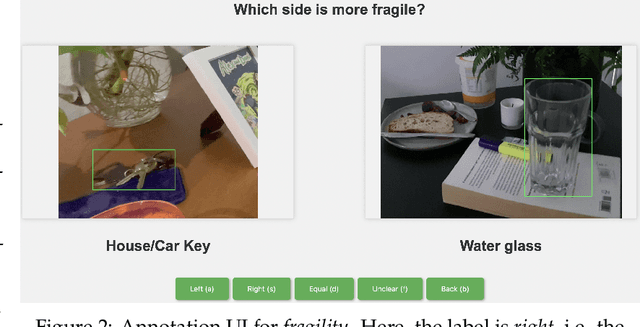
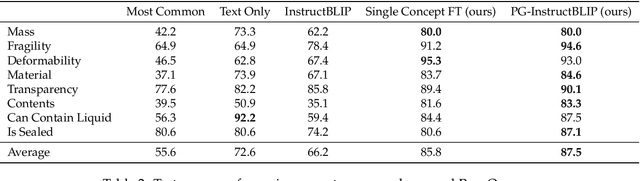
Recent advances in vision-language models (VLMs) have led to improved performance on tasks such as visual question answering and image captioning. Consequently, these models are now well-positioned to reason about the physical world, particularly within domains such as robotic manipulation. However, current VLMs are limited in their understanding of the physical concepts (e.g., material, fragility) of common objects, which restricts their usefulness for robotic manipulation tasks that involve interaction and physical reasoning about such objects. To address this limitation, we propose PhysObjects, an object-centric dataset of 39.6K crowd-sourced and 417K automated physical concept annotations of common household objects. We demonstrate that fine-tuning a VLM on PhysObjects improves its understanding of physical object concepts, including generalization to held-out concepts, by capturing human priors of these concepts from visual appearance. We incorporate this physically-grounded VLM in an interactive framework with a large language model-based robotic planner, and show improved planning performance on tasks that require reasoning about physical object concepts, compared to baselines that do not leverage physically-grounded VLMs. We additionally illustrate the benefits of our physically-grounded VLM on a real robot, where it improves task success rates. We release our dataset and provide further details and visualizations of our results at https://iliad.stanford.edu/pg-vlm/.
Contrastive Deep Encoding Enables Uncertainty-aware Machine-learning-assisted Histopathology
Sep 13, 2023Deep neural network models can learn clinically relevant features from millions of histopathology images. However generating high-quality annotations to train such models for each hospital, each cancer type, and each diagnostic task is prohibitively laborious. On the other hand, terabytes of training data -- while lacking reliable annotations -- are readily available in the public domain in some cases. In this work, we explore how these large datasets can be consciously utilized to pre-train deep networks to encode informative representations. We then fine-tune our pre-trained models on a fraction of annotated training data to perform specific downstream tasks. We show that our approach can reach the state-of-the-art (SOTA) for patch-level classification with only 1-10% randomly selected annotations compared to other SOTA approaches. Moreover, we propose an uncertainty-aware loss function, to quantify the model confidence during inference. Quantified uncertainty helps experts select the best instances to label for further training. Our uncertainty-aware labeling reaches the SOTA with significantly fewer annotations compared to random labeling. Last, we demonstrate how our pre-trained encoders can surpass current SOTA for whole-slide image classification with weak supervision. Our work lays the foundation for data and task-agnostic pre-trained deep networks with quantified uncertainty.
Polygon Intersection-over-Union Loss for Viewpoint-Agnostic Monocular 3D Vehicle Detection
Sep 13, 2023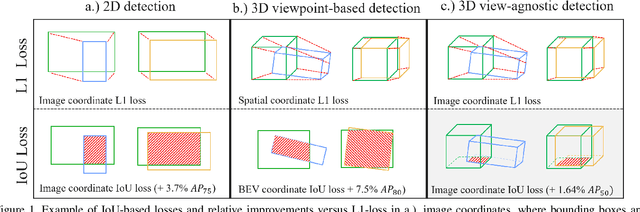
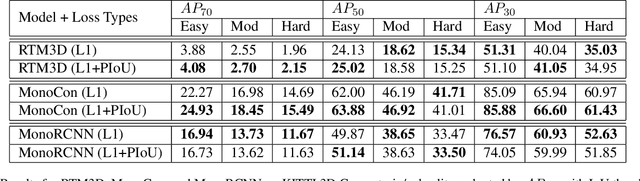
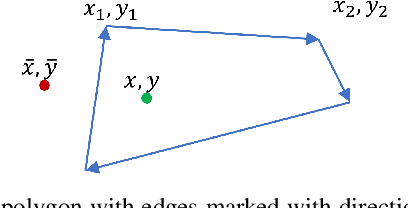
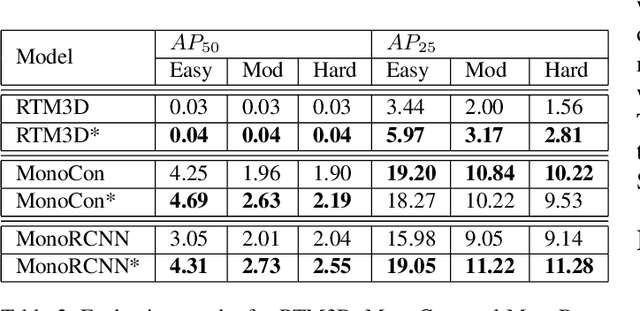
Monocular 3D object detection is a challenging task because depth information is difficult to obtain from 2D images. A subset of viewpoint-agnostic monocular 3D detection methods also do not explicitly leverage scene homography or geometry during training, meaning that a model trained thusly can detect objects in images from arbitrary viewpoints. Such works predict the projections of the 3D bounding boxes on the image plane to estimate the location of the 3D boxes, but these projections are not rectangular so the calculation of IoU between these projected polygons is not straightforward. This work proposes an efficient, fully differentiable algorithm for the calculation of IoU between two convex polygons, which can be utilized to compute the IoU between two 3D bounding box footprints viewed from an arbitrary angle. We test the performance of the proposed polygon IoU loss (PIoU loss) on three state-of-the-art viewpoint-agnostic 3D detection models. Experiments demonstrate that the proposed PIoU loss converges faster than L1 loss and that in 3D detection models, a combination of PIoU loss and L1 loss gives better results than L1 loss alone (+1.64% AP70 for MonoCon on cars, +0.18% AP70 for RTM3D on cars, and +0.83%/+2.46% AP50/AP25 for MonoRCNN on cyclists).
Dynamic Spectrum Mixer for Visual Recognition
Sep 13, 2023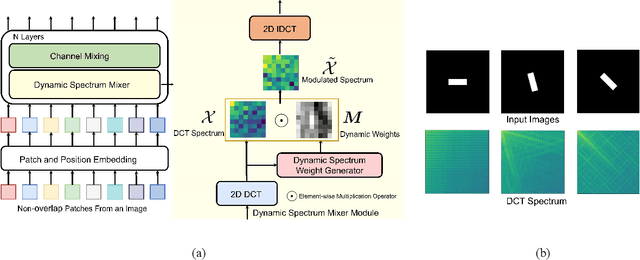
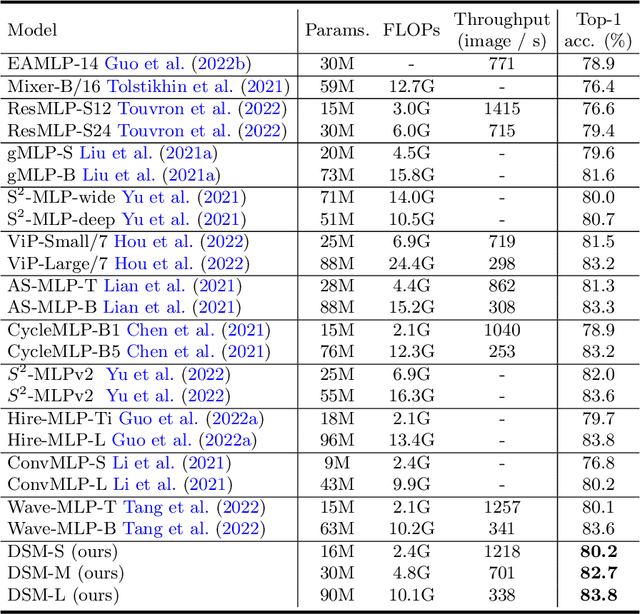
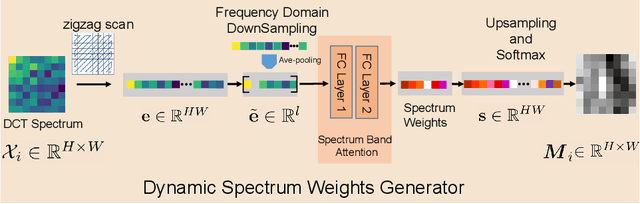
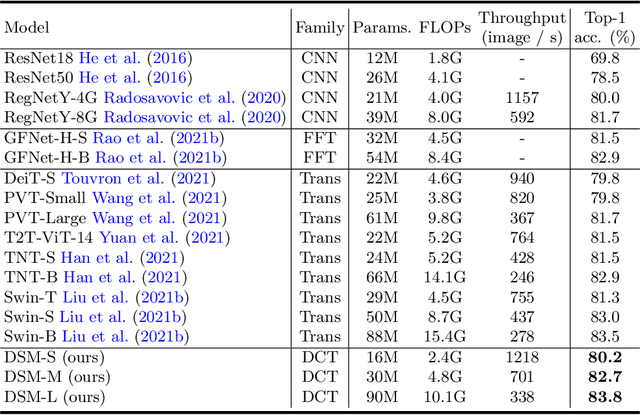
Recently, MLP-based vision backbones have achieved promising performance in several visual recognition tasks. However, the existing MLP-based methods directly aggregate tokens with static weights, leaving the adaptability to different images untouched. Moreover, Recent research demonstrates that MLP-Transformer is great at creating long-range dependencies but ineffective at catching high frequencies that primarily transmit local information, which prevents it from applying to the downstream dense prediction tasks, such as semantic segmentation. To address these challenges, we propose a content-adaptive yet computationally efficient structure, dubbed Dynamic Spectrum Mixer (DSM). The DSM represents token interactions in the frequency domain by employing the Discrete Cosine Transform, which can learn long-term spatial dependencies with log-linear complexity. Furthermore, a dynamic spectrum weight generation layer is proposed as the spectrum bands selector, which could emphasize the informative frequency bands while diminishing others. To this end, the technique can efficiently learn detailed features from visual input that contains both high- and low-frequency information. Extensive experiments show that DSM is a powerful and adaptable backbone for a range of visual recognition tasks. Particularly, DSM outperforms previous transformer-based and MLP-based models, on image classification, object detection, and semantic segmentation tasks, such as 83.8 \% top-1 accuracy on ImageNet, and 49.9 \% mIoU on ADE20K.
Utilizing Hybrid Trajectory Prediction Models to Recognize Highly Interactive Traffic Scenarios
Sep 13, 2023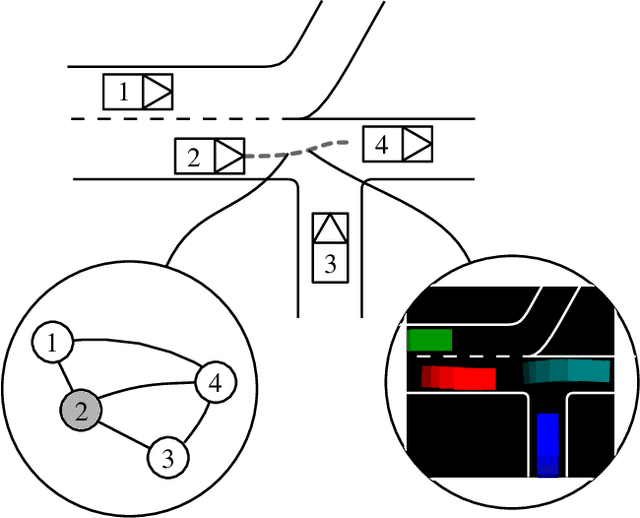
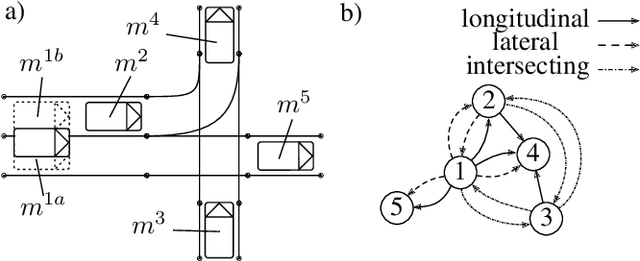
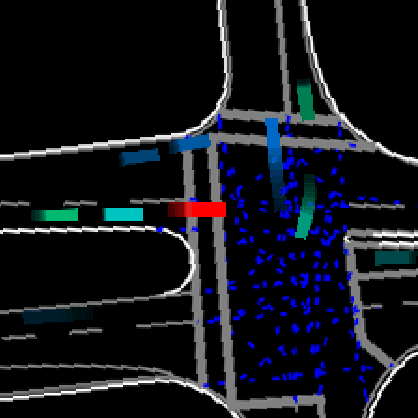
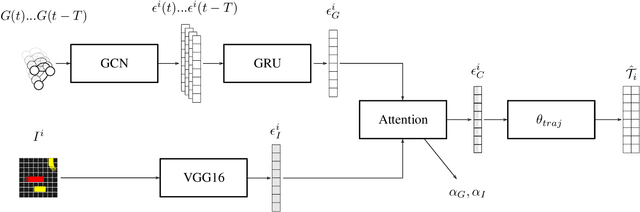
Autonomous vehicles hold great promise in improving the future of transportation. The driving models used in these vehicles are based on neural networks, which can be difficult to validate. However, ensuring the safety of these models is crucial. Traditional field tests can be costly, time-consuming, and dangerous. To address these issues, scenario-based closed-loop simulations can simulate many hours of vehicle operation in a shorter amount of time and allow for specific investigation of important situations. Nonetheless, the detection of relevant traffic scenarios that also offer substantial testing benefits remains a significant challenge. To address this need, in this paper we build an imitation learning based trajectory prediction for traffic participants. We combine an image-based (CNN) approach to represent spatial environmental factors and a graph-based (GNN) approach to specifically represent relations between traffic participants. In our understanding, traffic scenes that are highly interactive due to the network's significant utilization of the social component are more pertinent for a validation process. Therefore, we propose to use the activity of such sub networks as a measure of interactivity of a traffic scene. We evaluate our model using a motion dataset and discuss the value of the relationship information with respect to different traffic situations.
SAMedOCT: Adapting Segment Anything Model (SAM) for Retinal OCT
Aug 31, 2023The Segment Anything Model (SAM) has gained significant attention in the field of image segmentation due to its impressive capabilities and prompt-based interface. While SAM has already been extensively evaluated in various domains, its adaptation to retinal OCT scans remains unexplored. To bridge this research gap, we conduct a comprehensive evaluation of SAM and its adaptations on a large-scale public dataset of OCTs from RETOUCH challenge. Our evaluation covers diverse retinal diseases, fluid compartments, and device vendors, comparing SAM against state-of-the-art retinal fluid segmentation methods. Through our analysis, we showcase adapted SAM's efficacy as a powerful segmentation model in retinal OCT scans, although still lagging behind established methods in some circumstances. The findings highlight SAM's adaptability and robustness, showcasing its utility as a valuable tool in retinal OCT image analysis and paving the way for further advancements in this domain.