 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DPA-Net: Structured 3D Abstraction from Sparse Views via Differentiable Primitive Assembly
Apr 02, 2024
We present a differentiable rendering framework to learn structured 3D abstractions in the form of primitive assemblies from sparse RGB images capturing a 3D object. By leveraging differentiable volume rendering, our method does not require 3D supervision. Architecturally, our network follows the general pipeline of an image-conditioned neural radiance field (NeRF) exemplified by pixelNeRF for color prediction. As our core contribution, we introduce differential primitive assembly (DPA) into NeRF to output a 3D occupancy field in place of density prediction, where the predicted occupancies serve as opacity values for volume rendering. Our network, coined DPA-Net, produces a union of convexes, each as an intersection of convex quadric primitives, to approximate the target 3D object, subject to an abstraction loss and a masking loss, both defined in the image space upon volume rendering. With test-time adaptation and additional sampling and loss designs aimed at improving the accuracy and compactness of the obtained assemblies, our method demonstrates superior performance over state-of-the-art alternatives for 3D primitive abstraction from sparse views.
Specularity Factorization for Low-Light Enhancement
Apr 02, 2024We present a new additive image factorization technique that treats images to be composed of multiple latent specular components which can be simply estimated recursively by modulating the sparsity during decomposition. Our model-driven {\em RSFNet} estimates these factors by unrolling the optimization into network layers requiring only a few scalars to be learned. The resultant factors are interpretable by design and can be fused for different image enhancement tasks via a network or combined directly by the user in a controllable fashion. Based on RSFNet, we detail a zero-reference Low Light Enhancement (LLE) application trained without paired or unpaired supervision. Our system improves the state-of-the-art performance on standard benchmarks and achieves better generalization on multiple other datasets. We also integrate our factors with other task specific fusion networks for applications like deraining, deblurring and dehazing with negligible overhead thereby highlighting the multi-domain and multi-task generalizability of our proposed RSFNet. The code and data is released for reproducibility on the project homepage.
Event-assisted Low-Light Video Object Segmentation
Apr 02, 2024In the realm of video object segmentation (VOS), the challenge of operating under low-light conditions persists, resulting in notably degraded image quality and compromised accuracy when comparing query and memory frames for similarity computation. Event cameras, characterized by their high dynamic range and ability to capture motion information of objects, offer promise in enhancing object visibility and aiding VOS methods under such low-light conditions. This paper introduces a pioneering framework tailored for low-light VOS, leveraging event camera data to elevate segmentation accuracy. Our approach hinges on two pivotal components: the Adaptive Cross-Modal Fusion (ACMF) module, aimed at extracting pertinent features while fusing image and event modalities to mitigate noise interference, and the Event-Guided Memory Matching (EGMM) module, designed to rectify the issue of inaccurate matching prevalent in low-light settings. Additionally, we present the creation of a synthetic LLE-DAVIS dataset and the curation of a real-world LLE-VOS dataset, encompassing frames and events. Experimental evaluations corroborate the efficacy of our method across both datasets, affirming its effectiveness in low-light scenarios.
A Robust Ensemble Algorithm for Ischemic Stroke Lesion Segmentation: Generalizability and Clinical Utility Beyond the ISLES Challenge
Apr 03, 2024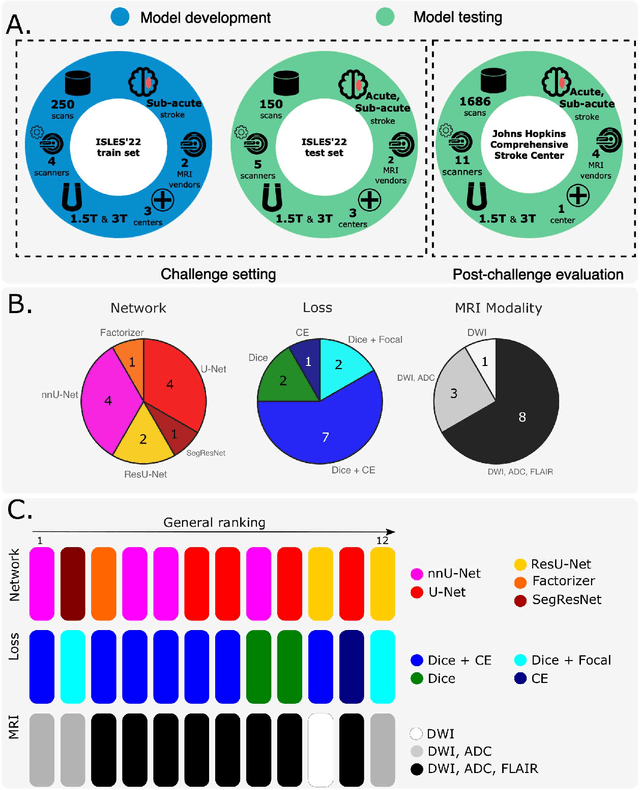
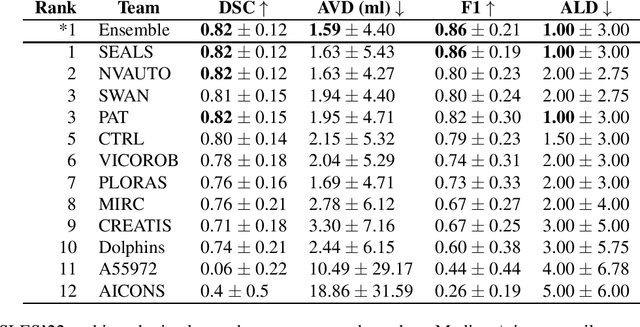
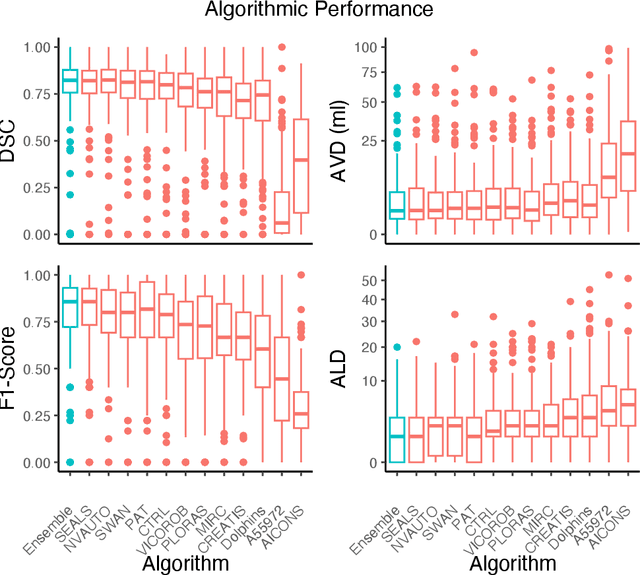
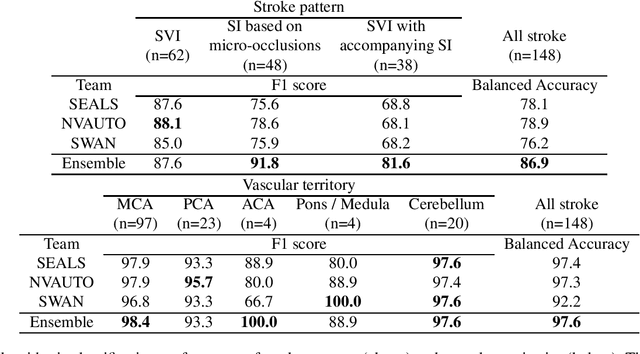
Diffusion-weighted MRI (DWI) is essential for stroke diagnosis, treatment decisions, and prognosis. However, image and disease variability hinder the development of generalizable AI algorithms with clinical value. We address this gap by presenting a novel ensemble algorithm derived from the 2022 Ischemic Stroke Lesion Segmentation (ISLES) challenge. ISLES'22 provided 400 patient scans with ischemic stroke from various medical centers, facilitating the development of a wide range of cutting-edge segmentation algorithms by the research community. Through collaboration with leading teams, we combined top-performing algorithms into an ensemble model that overcomes the limitations of individual solutions. Our ensemble model achieved superior ischemic lesion detection and segmentation accuracy on our internal test set compared to individual algorithms. This accuracy generalized well across diverse image and disease variables. Furthermore, the model excelled in extracting clinical biomarkers. Notably, in a Turing-like test, neuroradiologists consistently preferred the algorithm's segmentations over manual expert efforts, highlighting increased comprehensiveness and precision. Validation using a real-world external dataset (N=1686) confirmed the model's generalizability. The algorithm's outputs also demonstrated strong correlations with clinical scores (admission NIHSS and 90-day mRS) on par with or exceeding expert-derived results, underlining its clinical relevance. This study offers two key findings. First, we present an ensemble algorithm (https://github.com/Tabrisrei/ISLES22_Ensemble) that detects and segments ischemic stroke lesions on DWI across diverse scenarios on par with expert (neuro)radiologists. Second, we show the potential for biomedical challenge outputs to extend beyond the challenge's initial objectives, demonstrating their real-world clinical applicability.
Text-to-Image Diffusion Models are Great Sketch-Photo Matchmakers
Mar 20, 2024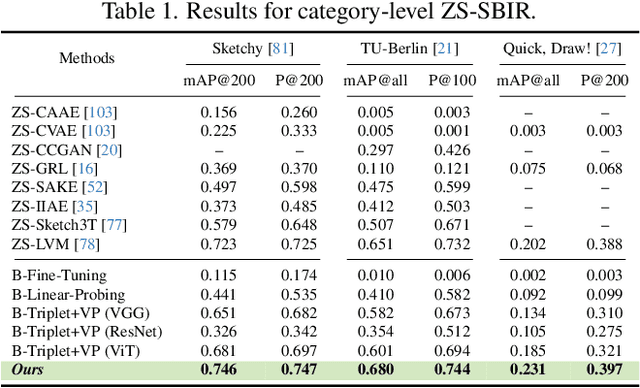
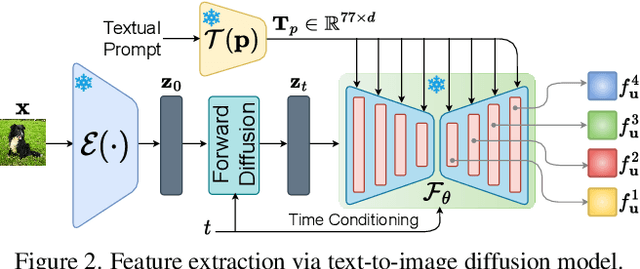


This paper, for the first time, explores text-to-image diffusion models for Zero-Shot Sketch-based Image Retrieval (ZS-SBIR). We highlight a pivotal discovery: the capacity of text-to-image diffusion models to seamlessly bridge the gap between sketches and photos. This proficiency is underpinned by their robust cross-modal capabilities and shape bias, findings that are substantiated through our pilot studies. In order to harness pre-trained diffusion models effectively, we introduce a straightforward yet powerful strategy focused on two key aspects: selecting optimal feature layers and utilising visual and textual prompts. For the former, we identify which layers are most enriched with information and are best suited for the specific retrieval requirements (category-level or fine-grained). Then we employ visual and textual prompts to guide the model's feature extraction process, enabling it to generate more discriminative and contextually relevant cross-modal representations. Extensive experiments on several benchmark datasets validate significant performance improvements.
denoiSplit: a method for joint image splitting and unsupervised denoising
Mar 18, 2024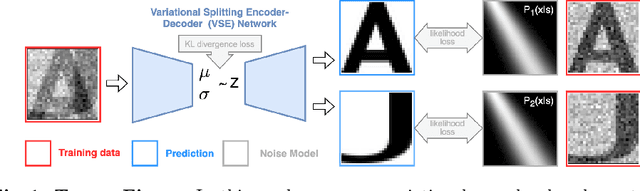
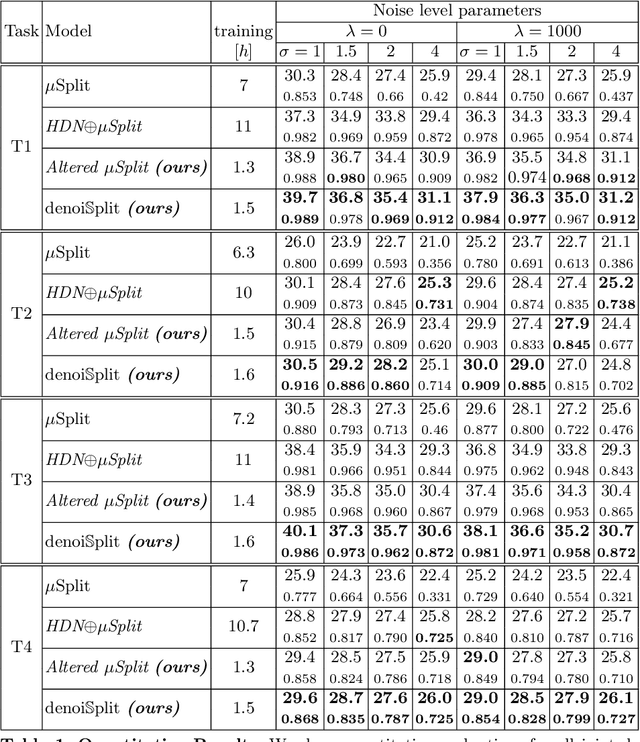
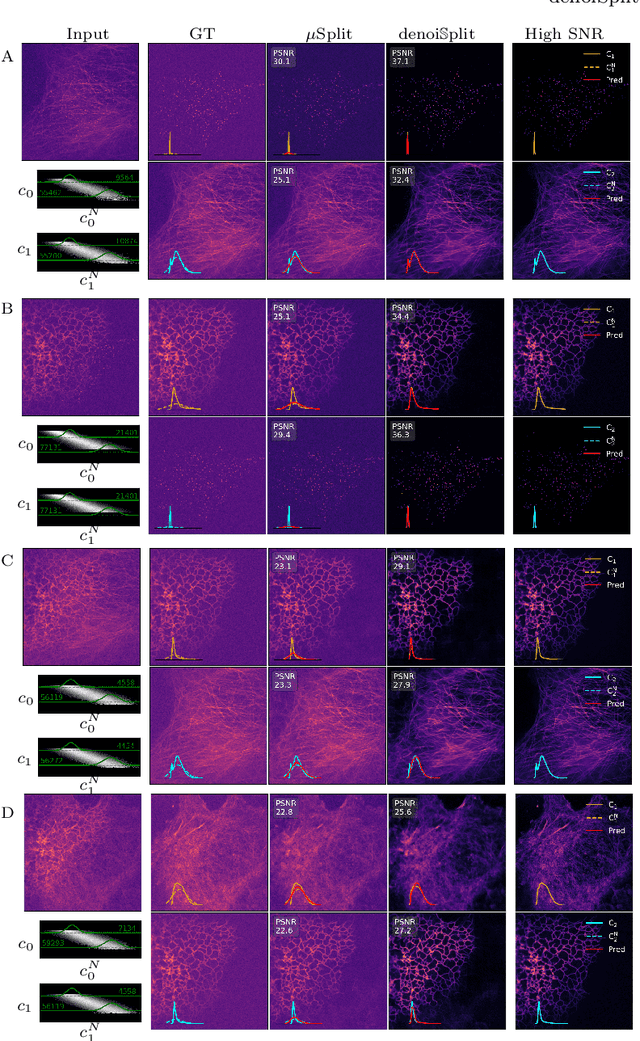
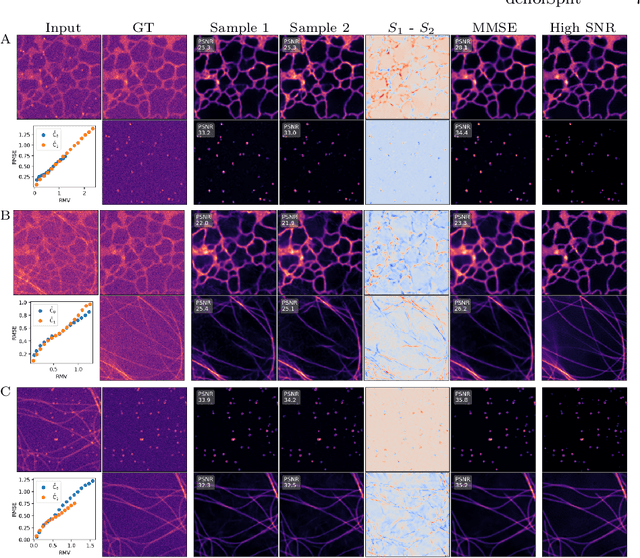
In this work we present denoiSplit, a method to tackle a new analysis task, i.e. the challenge of joint semantic image splitting and unsupervised denoising. This dual approach has important applications in fluorescence microscopy, where semantic image splitting has important applications but noise does generally hinder the downstream analysis of image content. Image splitting involves dissecting an image into its distinguishable semantic structures. We show that the current state-of-the-art method for this task struggles in the presence of image noise, inadvertently also distributing the noise across the predicted outputs. The method we present here can deal with image noise by integrating an unsupervised denoising sub-task. This integration results in improved semantic image unmixing, even in the presence of notable and realistic levels of imaging noise. A key innovation in denoiSplit is the use of specifically formulated noise models and the suitable adjustment of KL-divergence loss for the high-dimensional hierarchical latent space we are training. We showcase the performance of denoiSplit across 4 tasks on real-world microscopy images. Additionally, we perform qualitative and quantitative evaluations and compare results to existing benchmarks, demonstrating the effectiveness of using denoiSplit: a single Variational Splitting Encoder-Decoder (VSE) Network using two suitable noise models to jointly perform semantic splitting and denoising.
The More You See in 2D, the More You Perceive in 3D
Apr 04, 2024Humans can infer 3D structure from 2D images of an object based on past experience and improve their 3D understanding as they see more images. Inspired by this behavior, we introduce SAP3D, a system for 3D reconstruction and novel view synthesis from an arbitrary number of unposed images. Given a few unposed images of an object, we adapt a pre-trained view-conditioned diffusion model together with the camera poses of the images via test-time fine-tuning. The adapted diffusion model and the obtained camera poses are then utilized as instance-specific priors for 3D reconstruction and novel view synthesis. We show that as the number of input images increases, the performance of our approach improves, bridging the gap between optimization-based prior-less 3D reconstruction methods and single-image-to-3D diffusion-based methods. We demonstrate our system on real images as well as standard synthetic benchmarks. Our ablation studies confirm that this adaption behavior is key for more accurate 3D understanding.
VXP: Voxel-Cross-Pixel Large-scale Image-LiDAR Place Recognition
Mar 21, 2024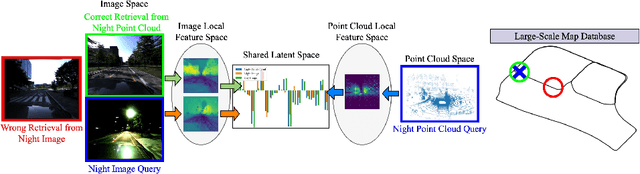

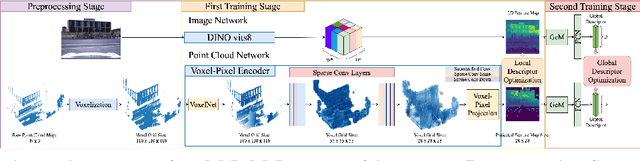
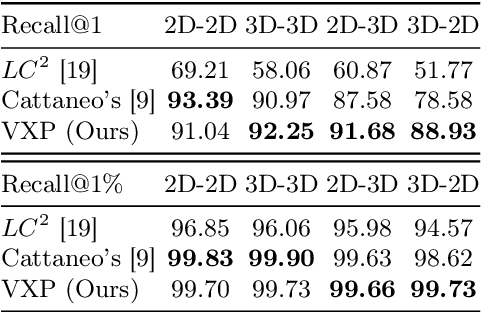
Recent works on the global place recognition treat the task as a retrieval problem, where an off-the-shelf global descriptor is commonly designed in image-based and LiDAR-based modalities. However, it is non-trivial to perform accurate image-LiDAR global place recognition since extracting consistent and robust global descriptors from different domains (2D images and 3D point clouds) is challenging. To address this issue, we propose a novel Voxel-Cross-Pixel (VXP) approach, which establishes voxel and pixel correspondences in a self-supervised manner and brings them into a shared feature space. Specifically, VXP is trained in a two-stage manner that first explicitly exploits local feature correspondences and enforces similarity of global descriptors. Extensive experiments on the three benchmarks (Oxford RobotCar, ViViD++ and KITTI) demonstrate our method surpasses the state-of-the-art cross-modal retrieval by a large margin.
Content-aware Masked Image Modeling Transformer for Stereo Image Compression
Mar 13, 2024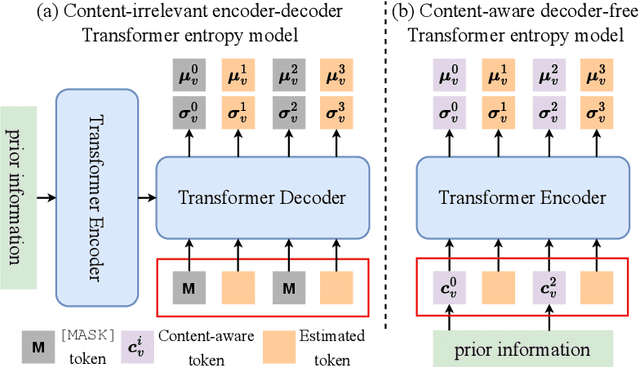
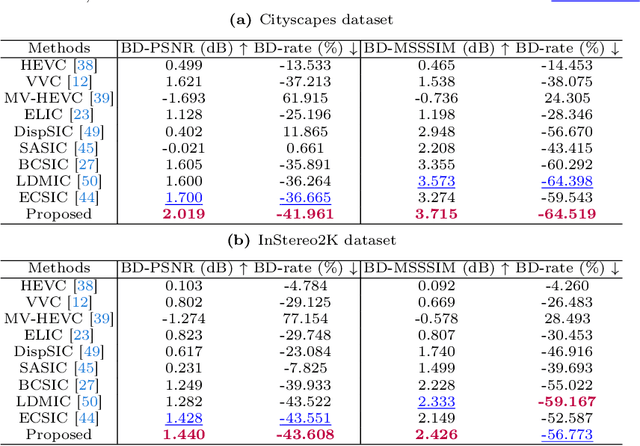
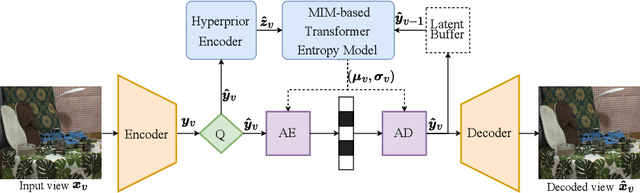
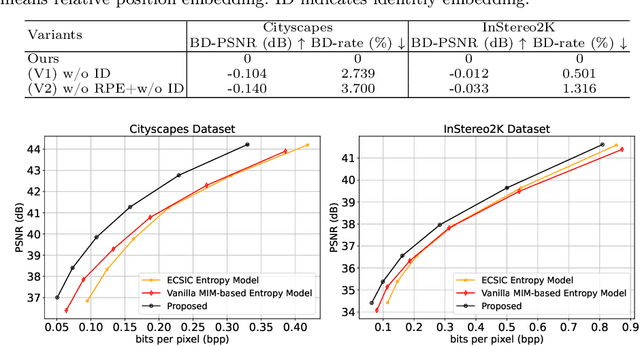
Existing learning-based stereo image codec adopt sophisticated transformation with simple entropy models derived from single image codecs to encode latent representations. However, those entropy models struggle to effectively capture the spatial-disparity characteristics inherent in stereo images, which leads to suboptimal rate-distortion results. In this paper, we propose a stereo image compression framework, named CAMSIC. CAMSIC independently transforms each image to latent representation and employs a powerful decoder-free Transformer entropy model to capture both spatial and disparity dependencies, by introducing a novel content-aware masked image modeling (MIM) technique. Our content-aware MIM facilitates efficient bidirectional interaction between prior information and estimated tokens, which naturally obviates the need for an extra Transformer decoder. Experiments show that our stereo image codec achieves state-of-the-art rate-distortion performance on two stereo image datasets Cityscapes and InStereo2K with fast encoding and decoding speed.
DPMesh: Exploiting Diffusion Prior for Occluded Human Mesh Recovery
Apr 01, 2024The recovery of occluded human meshes presents challenges for current methods due to the difficulty in extracting effective image features under severe occlusion. In this paper, we introduce DPMesh, an innovative framework for occluded human mesh recovery that capitalizes on the profound diffusion prior about object structure and spatial relationships embedded in a pre-trained text-to-image diffusion model. Unlike previous methods reliant on conventional backbones for vanilla feature extraction, DPMesh seamlessly integrates the pre-trained denoising U-Net with potent knowledge as its image backbone and performs a single-step inference to provide occlusion-aware information. To enhance the perception capability for occluded poses, DPMesh incorporates well-designed guidance via condition injection, which produces effective controls from 2D observations for the denoising U-Net. Furthermore, we explore a dedicated noisy key-point reasoning approach to mitigate disturbances arising from occlusion and crowded scenarios. This strategy fully unleashes the perceptual capability of the diffusion prior, thereby enhancing accuracy. Extensive experiments affirm the efficacy of our framework, as we outperform state-of-the-art methods on both occlusion-specific and standard datasets. The persuasive results underscore its ability to achieve precise and robust 3D human mesh recovery, particularly in challenging scenarios involving occlusion and crowded scenes.