 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Let Segment Anything Help Image Dehaze
Jun 28, 2023
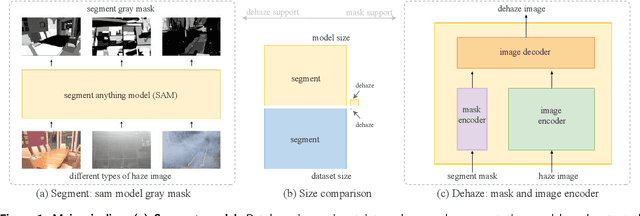

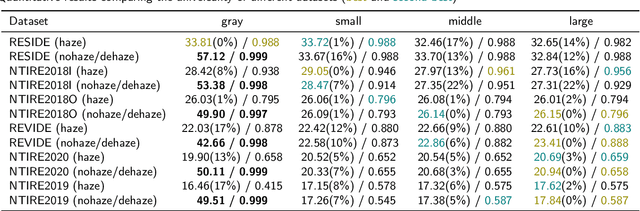
The large language model and high-level vision model have achieved impressive performance improvements with large datasets and model sizes. However, low-level computer vision tasks, such as image dehaze and blur removal, still rely on a small number of datasets and small-sized models, which generally leads to overfitting and local optima. Therefore, we propose a framework to integrate large-model prior into low-level computer vision tasks. Just as with the task of image segmentation, the degradation of haze is also texture-related. So we propose to detect gray-scale coding, network channel expansion, and pre-dehaze structures to integrate large-model prior knowledge into any low-level dehazing network. We demonstrate the effectiveness and applicability of large models in guiding low-level visual tasks through different datasets and algorithms comparison experiments. Finally, we demonstrate the effect of grayscale coding, network channel expansion, and recurrent network structures through ablation experiments. Under the conditions where additional data and training resources are not required, we successfully prove that the integration of large-model prior knowledge will improve the dehaze performance and save training time for low-level visual tasks.
Counting Guidance for High Fidelity Text-to-Image Synthesis
Jun 30, 2023

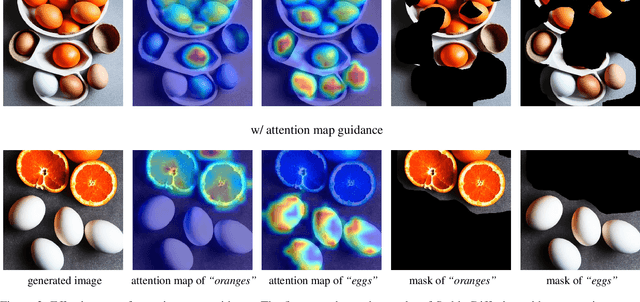

Recently, the quality and performance of text-to-image generation significantly advanced due to the impressive results of diffusion models. However, text-to-image diffusion models still fail to generate high fidelity content with respect to the input prompt. One problem where text-to-diffusion models struggle is generating the exact number of objects specified in the text prompt. E.g. given a prompt "five apples and ten lemons on a table", diffusion-generated images usually contain the wrong number of objects. In this paper, we propose a method to improve diffusion models to focus on producing the correct object count given the input prompt. We adopt a counting network that performs reference-less class-agnostic counting for any given image. We calculate the gradients of the counting network and refine the predicted noise for each step. To handle multiple types of objects in the prompt, we use novel attention map guidance to obtain high-fidelity masks for each object. Finally, we guide the denoising process by the calculated gradients for each object. Through extensive experiments and evaluation, we demonstrate that our proposed guidance method greatly improves the fidelity of diffusion models to object count.
Improving Lens Flare Removal with General Purpose Pipeline and Multiple Light Sources Recovery
Aug 31, 2023When taking images against strong light sources, the resulting images often contain heterogeneous flare artifacts. These artifacts can importantly affect image visual quality and downstream computer vision tasks. While collecting real data pairs of flare-corrupted/flare-free images for training flare removal models is challenging, current methods utilize the direct-add approach to synthesize data. However, these methods do not consider automatic exposure and tone mapping in image signal processing pipeline (ISP), leading to the limited generalization capability of deep models training using such data. Besides, existing methods struggle to handle multiple light sources due to the different sizes, shapes and illuminance of various light sources. In this paper, we propose a solution to improve the performance of lens flare removal by revisiting the ISP and remodeling the principle of automatic exposure in the synthesis pipeline and design a more reliable light sources recovery strategy. The new pipeline approaches realistic imaging by discriminating the local and global illumination through convex combination, avoiding global illumination shifting and local over-saturation. Our strategy for recovering multiple light sources convexly averages the input and output of the neural network based on illuminance levels, thereby avoiding the need for a hard threshold in identifying light sources. We also contribute a new flare removal testing dataset containing the flare-corrupted images captured by ten types of consumer electronics. The dataset facilitates the verification of the generalization capability of flare removal methods. Extensive experiments show that our solution can effectively improve the performance of lens flare removal and push the frontier toward more general situations.
SSIG: A Visually-Guided Graph Edit Distance for Floor Plan Similarity
Sep 08, 2023We propose a simple yet effective metric that measures structural similarity between visual instances of architectural floor plans, without the need for learning. Qualitatively, our experiments show that the retrieval results are similar to deeply learned methods. Effectively comparing instances of floor plan data is paramount to the success of machine understanding of floor plan data, including the assessment of floor plan generative models and floor plan recommendation systems. Comparing visual floor plan images goes beyond a sole pixel-wise visual examination and is crucially about similarities and differences in the shapes and relations between subdivisions that compose the layout. Currently, deep metric learning approaches are used to learn a pair-wise vector representation space that closely mimics the structural similarity, in which the models are trained on similarity labels that are obtained by Intersection-over-Union (IoU). To compensate for the lack of structural awareness in IoU, graph-based approaches such as Graph Matching Networks (GMNs) are used, which require pairwise inference for comparing data instances, making GMNs less practical for retrieval applications. In this paper, an effective evaluation metric for judging the structural similarity of floor plans, coined SSIG (Structural Similarity by IoU and GED), is proposed based on both image and graph distances. In addition, an efficient algorithm is developed that uses SSIG to rank a large-scale floor plan database. Code will be openly available.
What to Learn: Features, Image Transformations, or Both?
Jun 22, 2023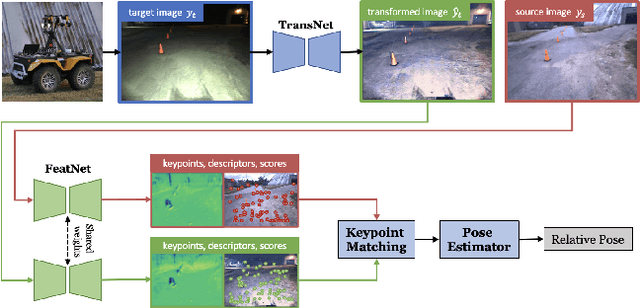
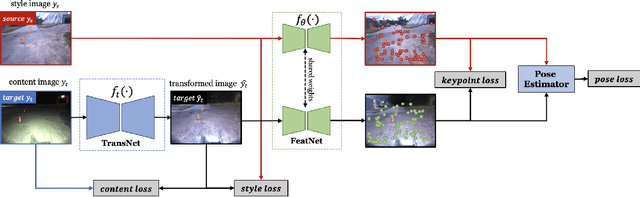

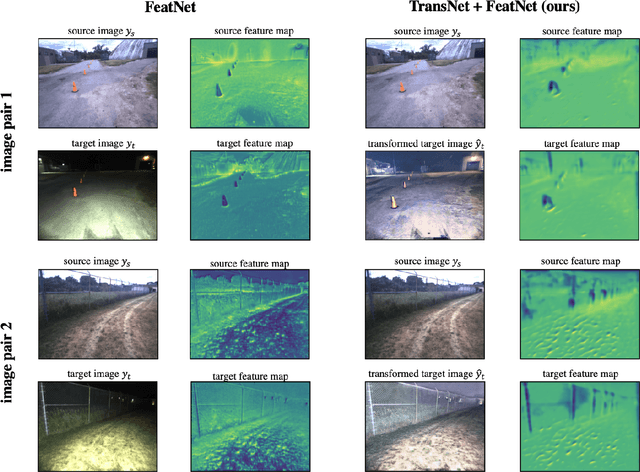
Long-term visual localization is an essential problem in robotics and computer vision, but remains challenging due to the environmental appearance changes caused by lighting and seasons. While many existing works have attempted to solve it by directly learning invariant sparse keypoints and descriptors to match scenes, these approaches still struggle with adverse appearance changes. Recent developments in image transformations such as neural style transfer have emerged as an alternative to address such appearance gaps. In this work, we propose to combine an image transformation network and a feature-learning network to improve long-term localization performance. Given night-to-day image pairs, the image transformation network transforms the night images into day-like conditions prior to feature matching; the feature network learns to detect keypoint locations with their associated descriptor values, which can be passed to a classical pose estimator to compute the relative poses. We conducted various experiments to examine the effectiveness of combining style transfer and feature learning and its training strategy, showing that such a combination greatly improves long-term localization performance.
Segmentação e contagem de troncos de madeira utilizando deep learning e processamento de imagens
Aug 31, 2023Counting objects in images is a pattern recognition problem that focuses on identifying an element to determine its incidence and is approached in the literature as Visual Object Counting (VOC). In this work, we propose a methodology to count wood logs. First, wood logs are segmented from the image background. This first segmentation step is obtained using the Pix2Pix framework that implements Conditional Generative Adversarial Networks (CGANs). Second, the clusters are counted using Connected Components. The average accuracy of the segmentation exceeds 89% while the average amount of wood logs identified based on total accounted is over 97%.
Image Transformation Sequence Retrieval with General Reinforcement Learning
Jul 13, 2023
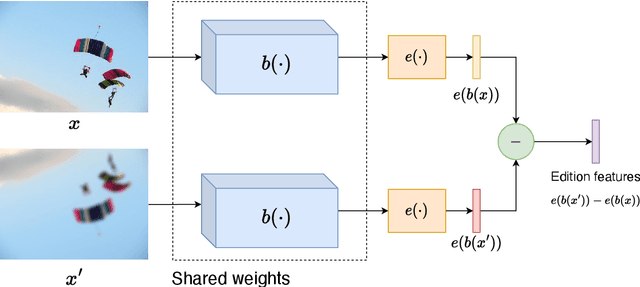
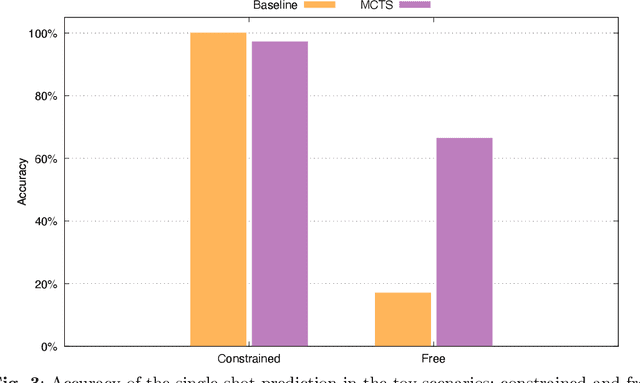
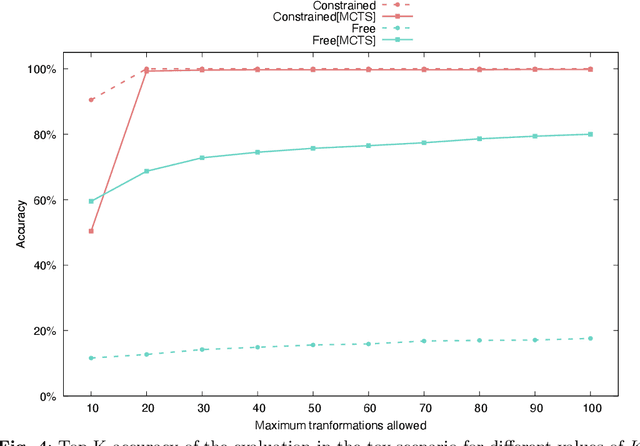
In this work, the novel Image Transformation Sequence Retrieval (ITSR) task is presented, in which a model must retrieve the sequence of transformations between two given images that act as source and target, respectively. Given certain characteristics of the challenge such as the multiplicity of a correct sequence or the correlation between consecutive steps of the process, we propose a solution to ITSR using a general model-based Reinforcement Learning such as Monte Carlo Tree Search (MCTS), which is combined with a deep neural network. Our experiments provide a benchmark in both synthetic and real domains, where the proposed approach is compared with supervised training. The results report that a model trained with MCTS is able to outperform its supervised counterpart in both the simplest and the most complex cases. Our work draws interesting conclusions about the nature of ITSR and its associated challenges.
Annotation Cost Efficient Active Learning for Content Based Image Retrieval
Jun 26, 2023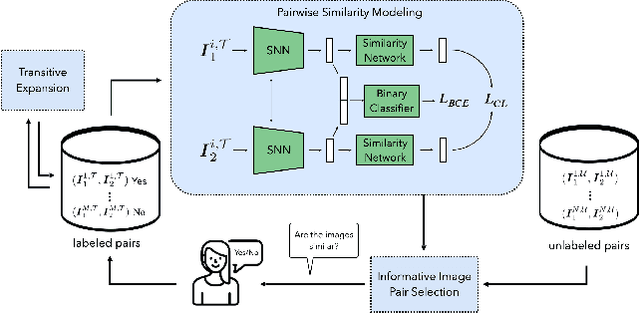
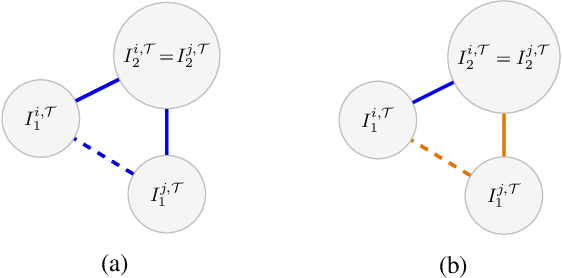
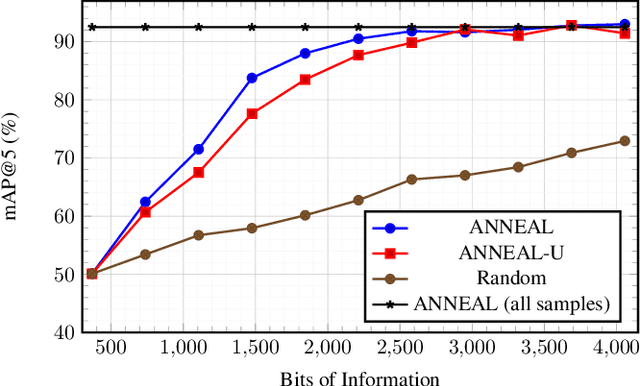
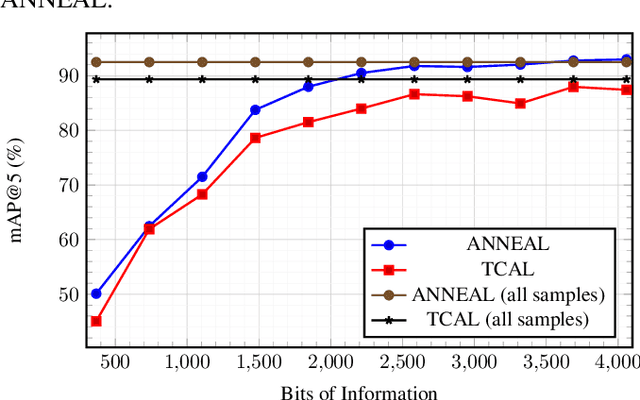
Deep metric learning (DML) based methods have been found very effective for content-based image retrieval (CBIR) in remote sensing (RS). For accurately learning the model parameters of deep neural networks, most of the DML methods require a high number of annotated training images, which can be costly to gather. To address this problem, in this paper we present an annotation cost efficient active learning (AL) method (denoted as ANNEAL). The proposed method aims to iteratively enrich the training set by annotating the most informative image pairs as similar or dissimilar, while accurately modelling a deep metric space. This is achieved by two consecutive steps. In the first step the pairwise image similarity is modelled based on the available training set. Then, in the second step the most uncertain and diverse (i.e., informative) image pairs are selected to be annotated. Unlike the existing AL methods for CBIR, at each AL iteration of ANNEAL a human expert is asked to annotate the most informative image pairs as similar/dissimilar. This significantly reduces the annotation cost compared to annotating images with land-use/land cover class labels. Experimental results show the effectiveness of our method. The code of ANNEAL is publicly available at https://git.tu-berlin.de/rsim/ANNEAL.
DreamEdit: Subject-driven Image Editing
Jun 22, 2023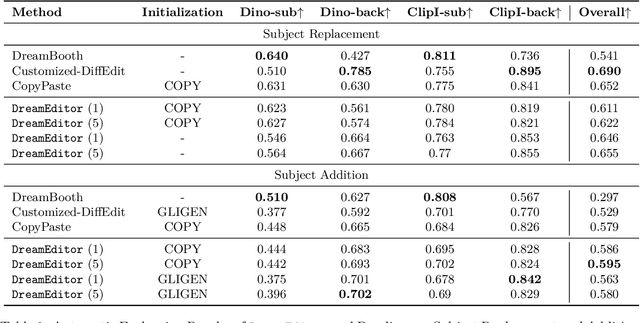

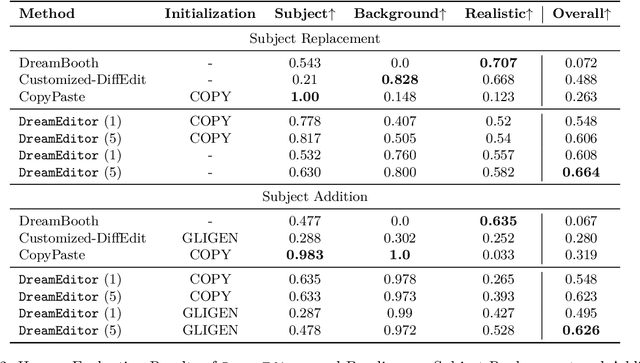
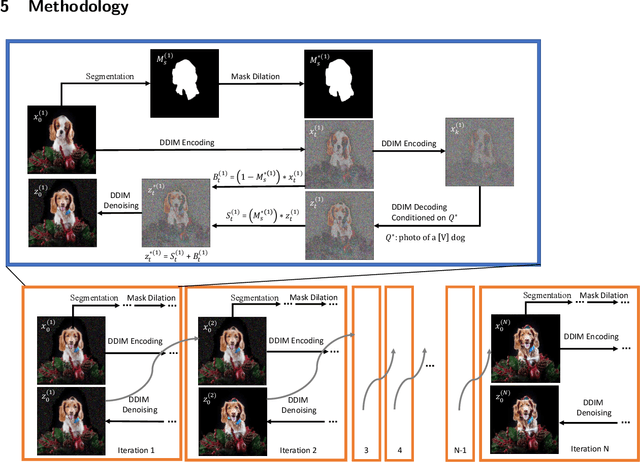
Subject-driven image generation aims at generating images containing customized subjects, which has recently drawn enormous attention from the research community. However, the previous works cannot precisely control the background and position of the target subject. In this work, we aspire to fill the void and propose two novel subject-driven sub-tasks, i.e., Subject Replacement and Subject Addition. The new tasks are challenging in multiple aspects: replacing a subject with a customized one can change its shape, texture, and color, while adding a target subject to a designated position in a provided scene necessitates a context-aware posture. To conquer these two novel tasks, we first manually curate a new dataset DreamEditBench containing 22 different types of subjects, and 440 source images with different difficulty levels. We plan to host DreamEditBench as a platform and hire trained evaluators for standard human evaluation. We also devise an innovative method DreamEditor to resolve these tasks by performing iterative generation, which enables a smooth adaptation to the customized subject. In this project, we conduct automatic and human evaluations to understand the performance of DreamEditor and baselines on DreamEditBench. For Subject Replacement, we found that the existing models are sensitive to the shape and color of the original subject. The model failure rate will dramatically increase when the source and target subjects are highly different. For Subject Addition, we found that the existing models cannot easily blend the customized subjects into the background smoothly, leading to noticeable artifacts in the generated image. We hope DreamEditBench can become a standard platform to enable future investigations toward building more controllable subject-driven image editing. Our project homepage is https://dreameditbenchteam.github.io/.
Michelangelo: Conditional 3D Shape Generation based on Shape-Image-Text Aligned Latent Representation
Jul 03, 2023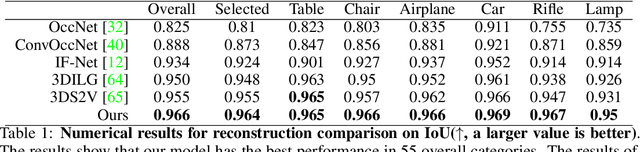
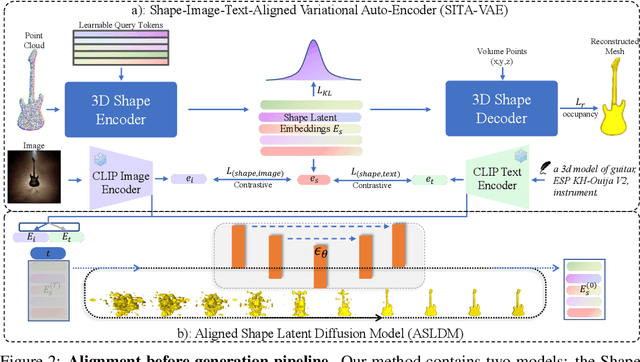
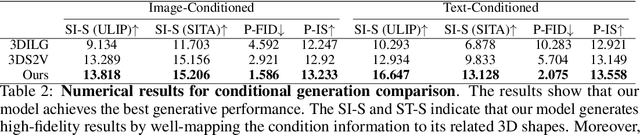

We present a novel alignment-before-generation approach to tackle the challenging task of generating general 3D shapes based on 2D images or texts. Directly learning a conditional generative model from images or texts to 3D shapes is prone to producing inconsistent results with the conditions because 3D shapes have an additional dimension whose distribution significantly differs from that of 2D images and texts. To bridge the domain gap among the three modalities and facilitate multi-modal-conditioned 3D shape generation, we explore representing 3D shapes in a shape-image-text-aligned space. Our framework comprises two models: a Shape-Image-Text-Aligned Variational Auto-Encoder (SITA-VAE) and a conditional Aligned Shape Latent Diffusion Model (ASLDM). The former model encodes the 3D shapes into the shape latent space aligned to the image and text and reconstructs the fine-grained 3D neural fields corresponding to given shape embeddings via the transformer-based decoder. The latter model learns a probabilistic mapping function from the image or text space to the latent shape space. Our extensive experiments demonstrate that our proposed approach can generate higher-quality and more diverse 3D shapes that better semantically conform to the visual or textural conditional inputs, validating the effectiveness of the shape-image-text-aligned space for cross-modality 3D shape generation.