 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Modified Step Size for Enhanced Stochastic Gradient Descent: Convergence and Experiments
Sep 03, 2023
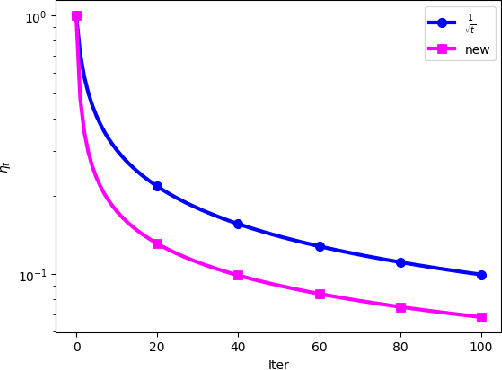
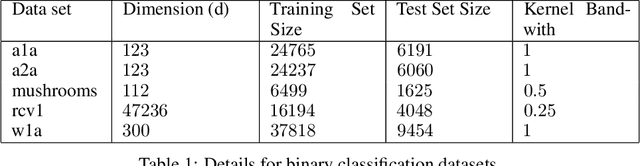
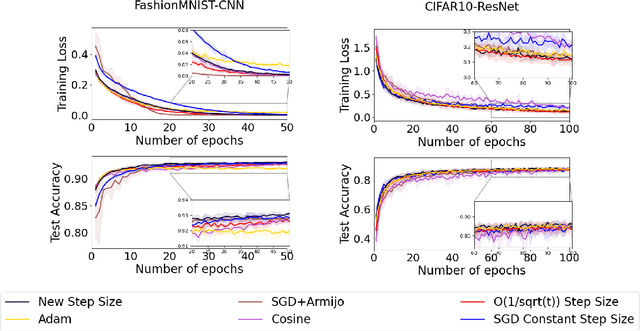

This paper introduces a novel approach to enhance the performance of the stochastic gradient descent (SGD) algorithm by incorporating a modified decay step size based on $\frac{1}{\sqrt{t}}$. The proposed step size integrates a logarithmic term, leading to the selection of smaller values in the final iterations. Our analysis establishes a convergence rate of $O(\frac{\ln T}{\sqrt{T}})$ for smooth non-convex functions without the Polyak-{\L}ojasiewicz condition. To evaluate the effectiveness of our approach, we conducted numerical experiments on image classification tasks using the FashionMNIST, and CIFAR10 datasets, and the results demonstrate significant improvements in accuracy, with enhancements of $0.5\%$ and $1.4\%$ observed, respectively, compared to the traditional $\frac{1}{\sqrt{t}}$ step size. The source code can be found at \\\url{https://github.com/Shamaeem/LNSQRTStepSize}.
Catching Image Retrieval Generalization
Jun 23, 2023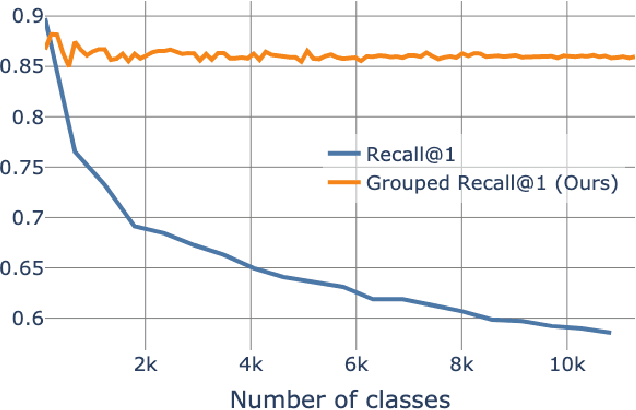

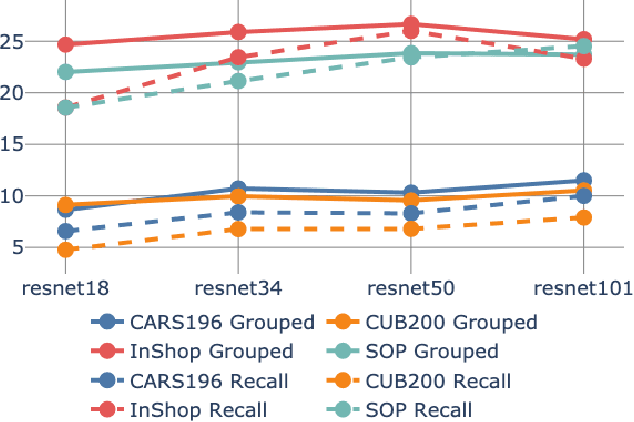

The concepts of overfitting and generalization are vital for evaluating machine learning models. In this work, we show that the popular Recall@K metric depends on the number of classes in the dataset, which limits its ability to estimate generalization. To fix this issue, we propose a new metric, which measures retrieval performance, and, unlike Recall@K, estimates generalization. We apply the proposed metric to popular image retrieval methods and provide new insights about deep metric learning generalization.
Efficient Discovery and Effective Evaluation of Visual Perceptual Similarity: A Benchmark and Beyond
Aug 28, 2023

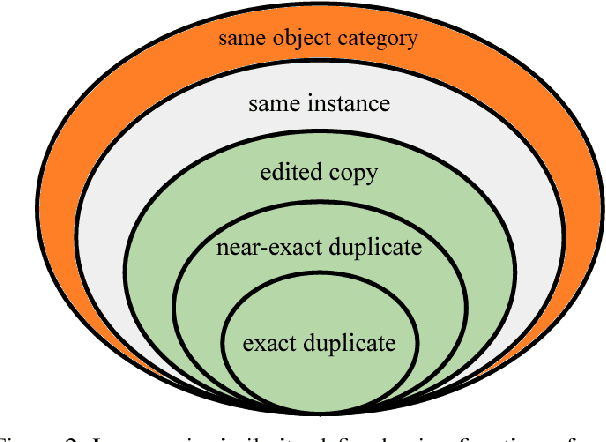
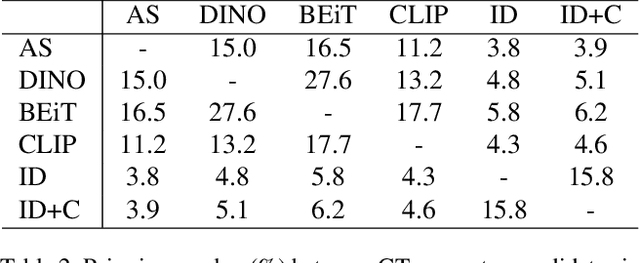
Visual similarities discovery (VSD) is an important task with broad e-commerce applications. Given an image of a certain object, the goal of VSD is to retrieve images of different objects with high perceptual visual similarity. Although being a highly addressed problem, the evaluation of proposed methods for VSD is often based on a proxy of an identification-retrieval task, evaluating the ability of a model to retrieve different images of the same object. We posit that evaluating VSD methods based on identification tasks is limited, and faithful evaluation must rely on expert annotations. In this paper, we introduce the first large-scale fashion visual similarity benchmark dataset, consisting of more than 110K expert-annotated image pairs. Besides this major contribution, we share insight from the challenges we faced while curating this dataset. Based on these insights, we propose a novel and efficient labeling procedure that can be applied to any dataset. Our analysis examines its limitations and inductive biases, and based on these findings, we propose metrics to mitigate those limitations. Though our primary focus lies on visual similarity, the methodologies we present have broader applications for discovering and evaluating perceptual similarity across various domains.
VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection
Aug 25, 2023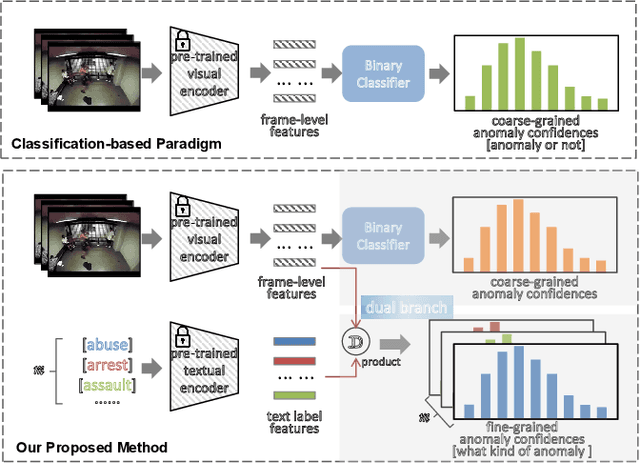
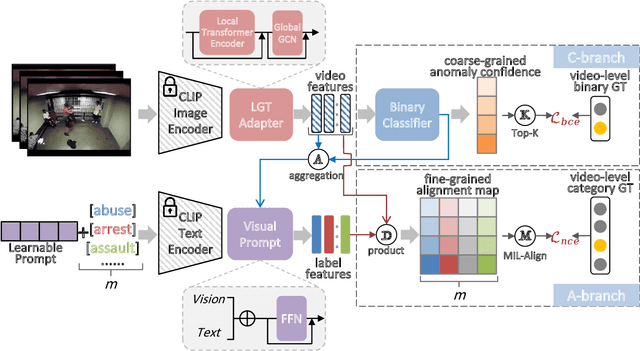

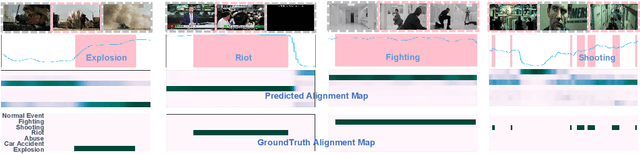
The recent contrastive language-image pre-training (CLIP) model has shown great success in a wide range of image-level tasks, revealing remarkable ability for learning powerful visual representations with rich semantics. An open and worthwhile problem is efficiently adapting such a strong model to the video domain and designing a robust video anomaly detector. In this work, we propose VadCLIP, a new paradigm for weakly supervised video anomaly detection (WSVAD) by leveraging the frozen CLIP model directly without any pre-training and fine-tuning process. Unlike current works that directly feed extracted features into the weakly supervised classifier for frame-level binary classification, VadCLIP makes full use of fine-grained associations between vision and language on the strength of CLIP and involves dual branch. One branch simply utilizes visual features for coarse-grained binary classification, while the other fully leverages the fine-grained language-image alignment. With the benefit of dual branch, VadCLIP achieves both coarse-grained and fine-grained video anomaly detection by transferring pre-trained knowledge from CLIP to WSVAD task. We conduct extensive experiments on two commonly-used benchmarks, demonstrating that VadCLIP achieves the best performance on both coarse-grained and fine-grained WSVAD, surpassing the state-of-the-art methods by a large margin. Specifically, VadCLIP achieves 84.51% AP and 88.02% AUC on XD-Violence and UCF-Crime, respectively. Code and features will be released to facilitate future VAD research.
ProRes: Exploring Degradation-aware Visual Prompt for Universal Image Restoration
Jun 23, 2023
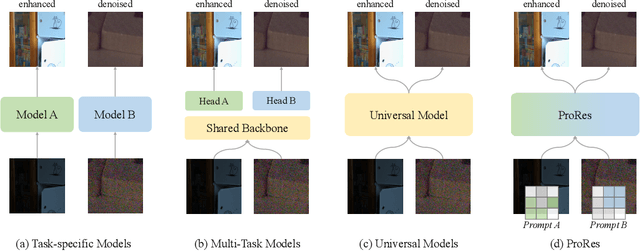
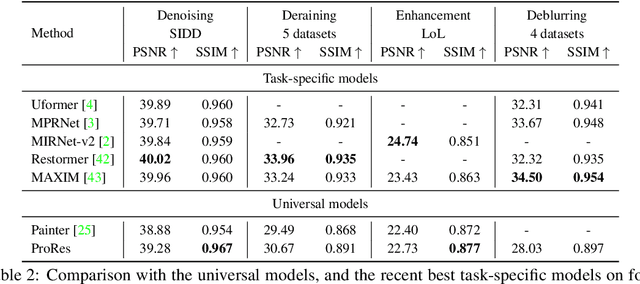
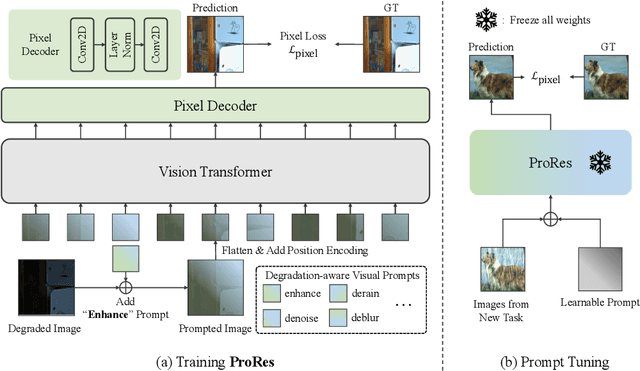
Image restoration aims to reconstruct degraded images, e.g., denoising or deblurring. Existing works focus on designing task-specific methods and there are inadequate attempts at universal methods. However, simply unifying multiple tasks into one universal architecture suffers from uncontrollable and undesired predictions. To address those issues, we explore prompt learning in universal architectures for image restoration tasks. In this paper, we present Degradation-aware Visual Prompts, which encode various types of image degradation, e.g., noise and blur, into unified visual prompts. These degradation-aware prompts provide control over image processing and allow weighted combinations for customized image restoration. We then leverage degradation-aware visual prompts to establish a controllable and universal model for image restoration, called ProRes, which is applicable to an extensive range of image restoration tasks. ProRes leverages the vanilla Vision Transformer (ViT) without any task-specific designs. Furthermore, the pre-trained ProRes can easily adapt to new tasks through efficient prompt tuning with only a few images. Without bells and whistles, ProRes achieves competitive performance compared to task-specific methods and experiments can demonstrate its ability for controllable restoration and adaptation for new tasks. The code and models will be released in \url{https://github.com/leonmakise/ProRes}.
Beyond Generic: Enhancing Image Captioning with Real-World Knowledge using Vision-Language Pre-Training Model
Aug 02, 2023


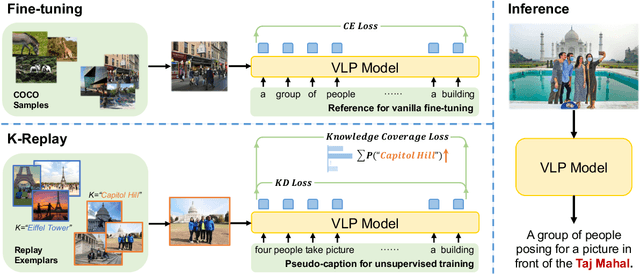
Current captioning approaches tend to generate correct but "generic" descriptions that lack real-world knowledge, e.g., named entities and contextual information. Considering that Vision-Language Pre-Training (VLP) models master massive such knowledge from large-scale web-harvested data, it is promising to utilize the generalizability of VLP models to incorporate knowledge into image descriptions. However, using VLP models faces challenges: zero-shot inference suffers from knowledge hallucination that leads to low-quality descriptions, but the generic bias in downstream task fine-tuning hinders the VLP model from expressing knowledge. To address these concerns, we propose a simple yet effective method called Knowledge-guided Replay (K-Replay), which enables the retention of pre-training knowledge during fine-tuning. Our approach consists of two parts: (1) a knowledge prediction task on automatically collected replay exemplars to continuously awaken the VLP model's memory about knowledge, thus preventing the model from collapsing into the generic pattern; (2) a knowledge distillation constraint to improve the faithfulness of generated descriptions hence alleviating the knowledge hallucination. To evaluate knowledge-enhanced descriptions, we construct a novel captioning benchmark KnowCap, containing knowledge of landmarks, famous brands, special foods and movie characters. Experimental results show that our approach effectively incorporates knowledge into descriptions, outperforming strong VLP baseline by 20.9 points (78.7->99.6) in CIDEr score and 20.5 percentage points (34.0%->54.5%) in knowledge recognition accuracy. Our code and data is available at https://github.com/njucckevin/KnowCap.
Object Detection Difficulty: Suppressing Over-aggregation for Faster and Better Video Object Detection
Aug 22, 2023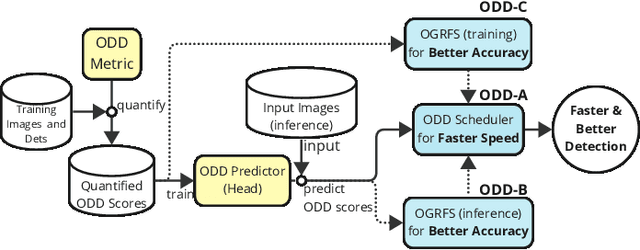
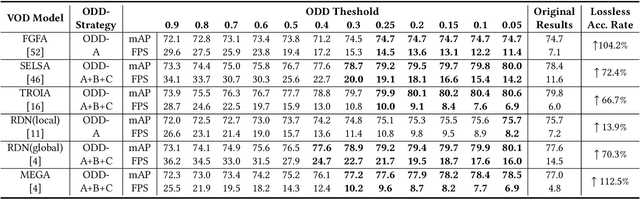

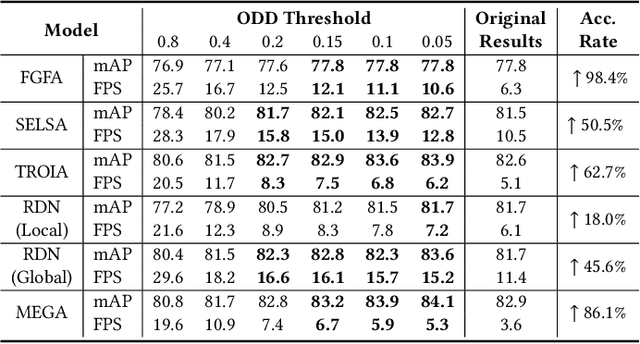
Current video object detection (VOD) models often encounter issues with over-aggregation due to redundant aggregation strategies, which perform feature aggregation on every frame. This results in suboptimal performance and increased computational complexity. In this work, we propose an image-level Object Detection Difficulty (ODD) metric to quantify the difficulty of detecting objects in a given image. The derived ODD scores can be used in the VOD process to mitigate over-aggregation. Specifically, we train an ODD predictor as an auxiliary head of a still-image object detector to compute the ODD score for each image based on the discrepancies between detection results and ground-truth bounding boxes. The ODD score enhances the VOD system in two ways: 1) it enables the VOD system to select superior global reference frames, thereby improving overall accuracy; and 2) it serves as an indicator in the newly designed ODD Scheduler to eliminate the aggregation of frames that are easy to detect, thus accelerating the VOD process. Comprehensive experiments demonstrate that, when utilized for selecting global reference frames, ODD-VOD consistently enhances the accuracy of Global-frame-based VOD models. When employed for acceleration, ODD-VOD consistently improves the frames per second (FPS) by an average of 73.3% across 8 different VOD models without sacrificing accuracy. When combined, ODD-VOD attains state-of-the-art performance when competing with many VOD methods in both accuracy and speed. Our work represents a significant advancement towards making VOD more practical for real-world applications.
SSIG: A Visually-Guided Graph Edit Distance for Floor Plan Similarity
Sep 08, 2023We propose a simple yet effective metric that measures structural similarity between visual instances of architectural floor plans, without the need for learning. Qualitatively, our experiments show that the retrieval results are similar to deeply learned methods. Effectively comparing instances of floor plan data is paramount to the success of machine understanding of floor plan data, including the assessment of floor plan generative models and floor plan recommendation systems. Comparing visual floor plan images goes beyond a sole pixel-wise visual examination and is crucially about similarities and differences in the shapes and relations between subdivisions that compose the layout. Currently, deep metric learning approaches are used to learn a pair-wise vector representation space that closely mimics the structural similarity, in which the models are trained on similarity labels that are obtained by Intersection-over-Union (IoU). To compensate for the lack of structural awareness in IoU, graph-based approaches such as Graph Matching Networks (GMNs) are used, which require pairwise inference for comparing data instances, making GMNs less practical for retrieval applications. In this paper, an effective evaluation metric for judging the structural similarity of floor plans, coined SSIG (Structural Similarity by IoU and GED), is proposed based on both image and graph distances. In addition, an efficient algorithm is developed that uses SSIG to rank a large-scale floor plan database. Code will be openly available.
Improving Lens Flare Removal with General Purpose Pipeline and Multiple Light Sources Recovery
Aug 31, 2023When taking images against strong light sources, the resulting images often contain heterogeneous flare artifacts. These artifacts can importantly affect image visual quality and downstream computer vision tasks. While collecting real data pairs of flare-corrupted/flare-free images for training flare removal models is challenging, current methods utilize the direct-add approach to synthesize data. However, these methods do not consider automatic exposure and tone mapping in image signal processing pipeline (ISP), leading to the limited generalization capability of deep models training using such data. Besides, existing methods struggle to handle multiple light sources due to the different sizes, shapes and illuminance of various light sources. In this paper, we propose a solution to improve the performance of lens flare removal by revisiting the ISP and remodeling the principle of automatic exposure in the synthesis pipeline and design a more reliable light sources recovery strategy. The new pipeline approaches realistic imaging by discriminating the local and global illumination through convex combination, avoiding global illumination shifting and local over-saturation. Our strategy for recovering multiple light sources convexly averages the input and output of the neural network based on illuminance levels, thereby avoiding the need for a hard threshold in identifying light sources. We also contribute a new flare removal testing dataset containing the flare-corrupted images captured by ten types of consumer electronics. The dataset facilitates the verification of the generalization capability of flare removal methods. Extensive experiments show that our solution can effectively improve the performance of lens flare removal and push the frontier toward more general situations.
CoDeF: Content Deformation Fields for Temporally Consistent Video Processing
Aug 15, 2023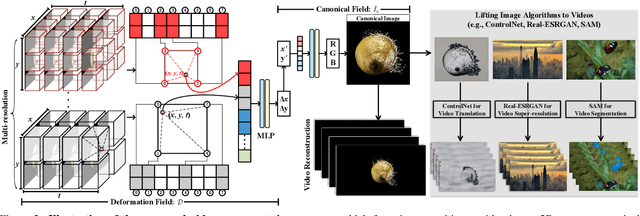



We present the content deformation field CoDeF as a new type of video representation, which consists of a canonical content field aggregating the static contents in the entire video and a temporal deformation field recording the transformations from the canonical image (i.e., rendered from the canonical content field) to each individual frame along the time axis.Given a target video, these two fields are jointly optimized to reconstruct it through a carefully tailored rendering pipeline.We advisedly introduce some regularizations into the optimization process, urging the canonical content field to inherit semantics (e.g., the object shape) from the video.With such a design, CoDeF naturally supports lifting image algorithms for video processing, in the sense that one can apply an image algorithm to the canonical image and effortlessly propagate the outcomes to the entire video with the aid of the temporal deformation field.We experimentally show that CoDeF is able to lift image-to-image translation to video-to-video translation and lift keypoint detection to keypoint tracking without any training.More importantly, thanks to our lifting strategy that deploys the algorithms on only one image, we achieve superior cross-frame consistency in processed videos compared to existing video-to-video translation approaches, and even manage to track non-rigid objects like water and smog.Project page can be found at https://qiuyu96.github.io/CoDeF/.