 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Non-Invasive Interpretable NAFLD Diagnostic Method Combining TCM Tongue Features
Sep 06, 2023

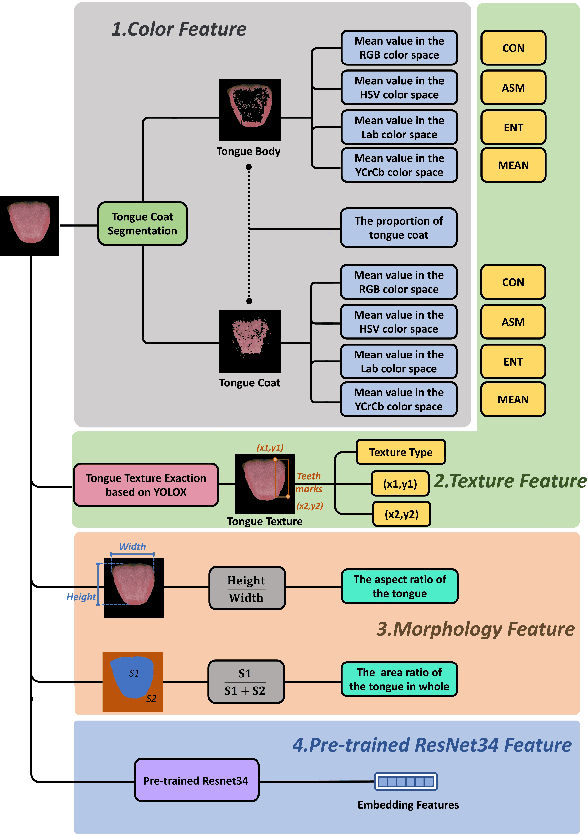
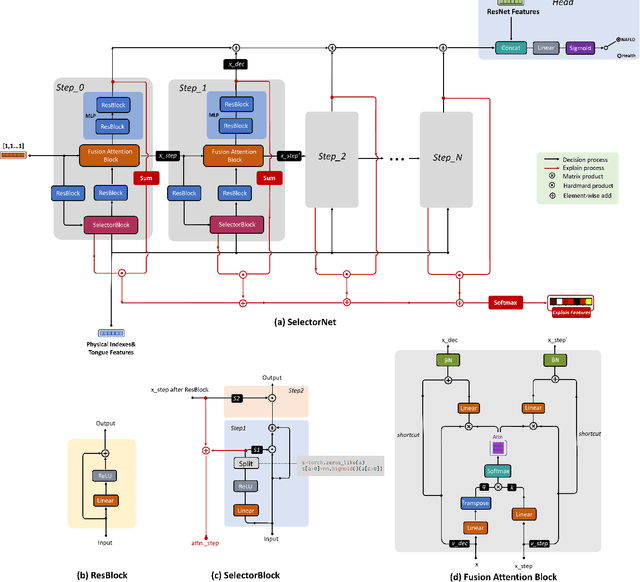

Non-alcoholic fatty liver disease (NAFLD) is a clinicopathological syndrome characterized by hepatic steatosis resulting from the exclusion of alcohol and other identifiable liver-damaging factors. It has emerged as a leading cause of chronic liver disease worldwide. Currently, the conventional methods for NAFLD detection are expensive and not suitable for users to perform daily diagnostics. To address this issue, this study proposes a non-invasive and interpretable NAFLD diagnostic method, the required user-provided indicators are only Gender, Age, Height, Weight, Waist Circumference, Hip Circumference, and tongue image. This method involves merging patients' physiological indicators with tongue features, which are then input into a fusion network named SelectorNet. SelectorNet combines attention mechanisms with feature selection mechanisms, enabling it to autonomously learn the ability to select important features. The experimental results show that the proposed method achieves an accuracy of 77.22\% using only non-invasive data, and it also provides compelling interpretability matrices. This study contributes to the early diagnosis of NAFLD and the intelligent advancement of TCM tongue diagnosis. The project in this paper is available at: https://github.com/cshan-github/SelectorNet.
Memory Efficient Optimizers with 4-bit States
Sep 06, 2023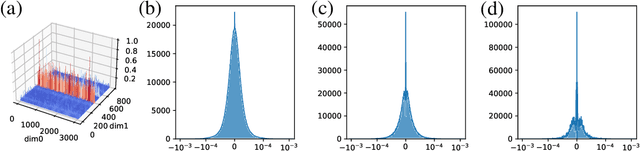
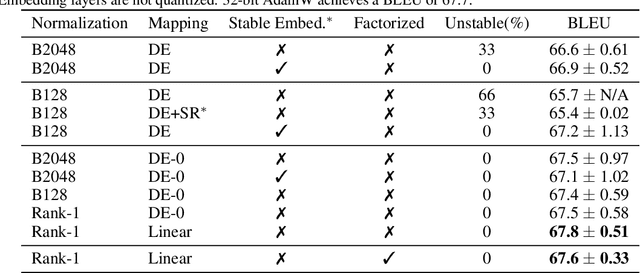
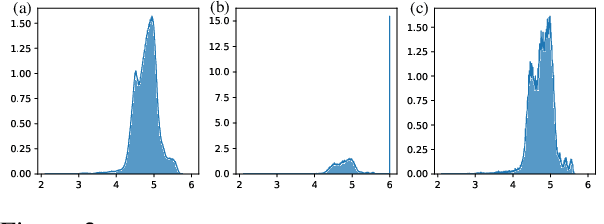
Optimizer states are a major source of memory consumption for training neural networks, limiting the maximum trainable model within given memory budget. Compressing the optimizer states from 32-bit floating points to lower bitwidth is promising to reduce the training memory footprint, while the current lowest achievable bitwidth is 8-bit. In this work, we push optimizer states bitwidth down to 4-bit through a detailed empirical analysis of first and second moments. Specifically, we find that moments have complicated outlier patterns, that current block-wise quantization cannot accurately approximate. We use a smaller block size and propose to utilize both row-wise and column-wise information for better quantization. We further identify a zero point problem of quantizing the second moment, and solve this problem with a linear quantizer that excludes the zero point. Our 4-bit optimizer is evaluated on a wide variety of benchmarks including natural language understanding, machine translation, image classification, and instruction tuning. On all the tasks our optimizers can achieve comparable accuracy with their full-precision counterparts, while enjoying better memory efficiency.
ProRes: Exploring Degradation-aware Visual Prompt for Universal Image Restoration
Jun 23, 2023
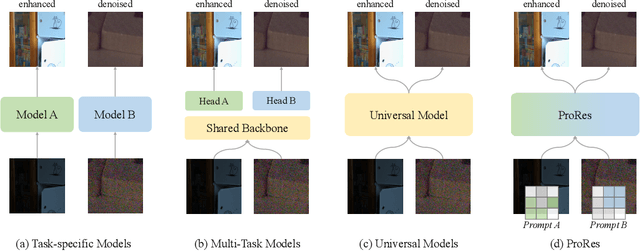
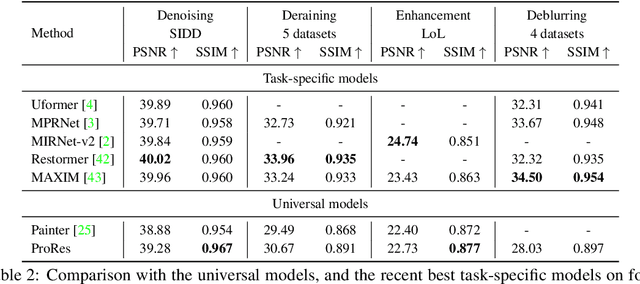
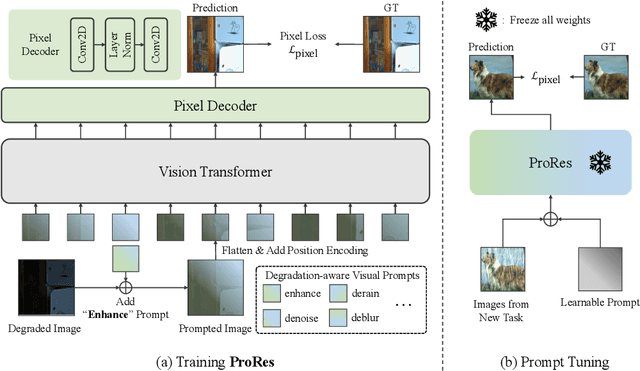
Image restoration aims to reconstruct degraded images, e.g., denoising or deblurring. Existing works focus on designing task-specific methods and there are inadequate attempts at universal methods. However, simply unifying multiple tasks into one universal architecture suffers from uncontrollable and undesired predictions. To address those issues, we explore prompt learning in universal architectures for image restoration tasks. In this paper, we present Degradation-aware Visual Prompts, which encode various types of image degradation, e.g., noise and blur, into unified visual prompts. These degradation-aware prompts provide control over image processing and allow weighted combinations for customized image restoration. We then leverage degradation-aware visual prompts to establish a controllable and universal model for image restoration, called ProRes, which is applicable to an extensive range of image restoration tasks. ProRes leverages the vanilla Vision Transformer (ViT) without any task-specific designs. Furthermore, the pre-trained ProRes can easily adapt to new tasks through efficient prompt tuning with only a few images. Without bells and whistles, ProRes achieves competitive performance compared to task-specific methods and experiments can demonstrate its ability for controllable restoration and adaptation for new tasks. The code and models will be released in \url{https://github.com/leonmakise/ProRes}.
Text-driven Editing of 3D Scenes without Retraining
Sep 10, 2023
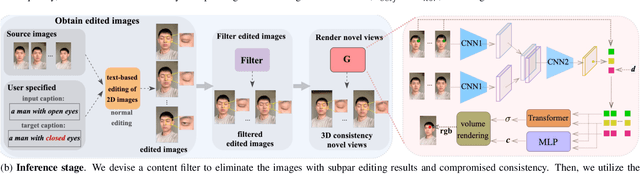
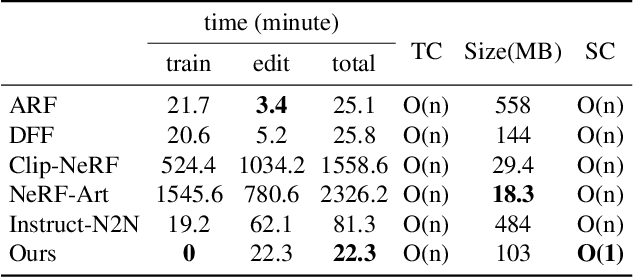

Numerous diffusion models have recently been applied to image synthesis and editing. However, editing 3D scenes is still in its early stages. It poses various challenges, such as the requirement to design specific methods for different editing types, retraining new models for various 3D scenes, and the absence of convenient human interaction during editing. To tackle these issues, we introduce a text-driven editing method, termed DN2N, which allows for the direct acquisition of a NeRF model with universal editing capabilities, eliminating the requirement for retraining. Our method employs off-the-shelf text-based editing models of 2D images to modify the 3D scene images, followed by a filtering process to discard poorly edited images that disrupt 3D consistency. We then consider the remaining inconsistency as a problem of removing noise perturbation, which can be solved by generating training data with similar perturbation characteristics for training. We further propose cross-view regularization terms to help the generalized NeRF model mitigate these perturbations. Our text-driven method allows users to edit a 3D scene with their desired description, which is more friendly, intuitive, and practical than prior works. Empirical results show that our method achieves multiple editing types, including but not limited to appearance editing, weather transition, material changing, and style transfer. Most importantly, our method generalizes well with editing abilities shared among a set of model parameters without requiring a customized editing model for some specific scenes, thus inferring novel views with editing effects directly from user input. The project website is available at http://sk-fun.fun/DN2N
LMBiS-Net: A Lightweight Multipath Bidirectional Skip Connection based CNN for Retinal Blood Vessel Segmentation
Sep 10, 2023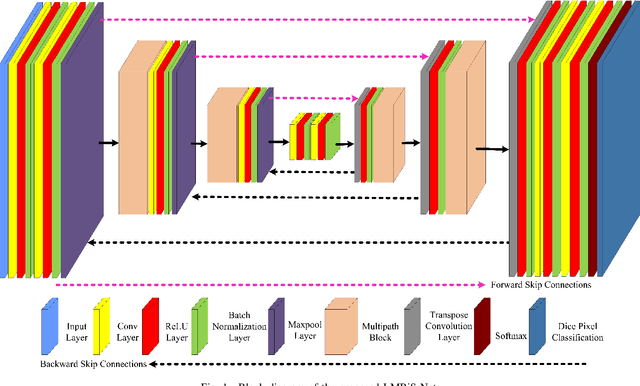
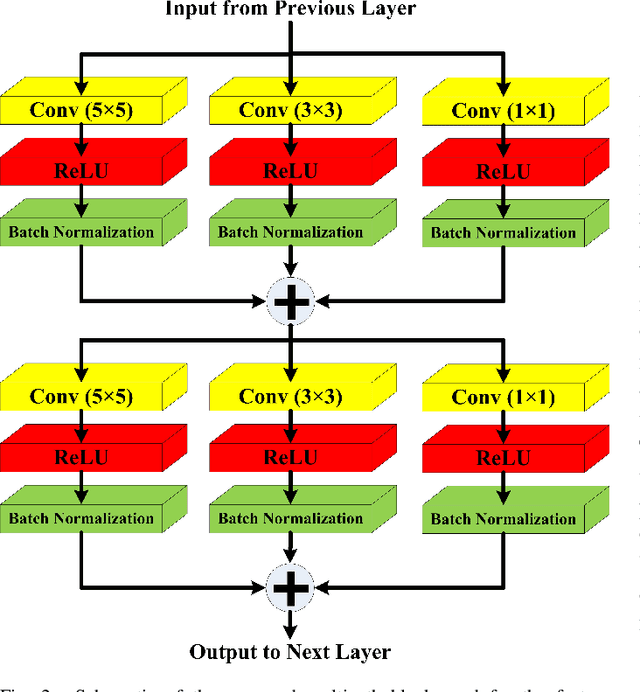
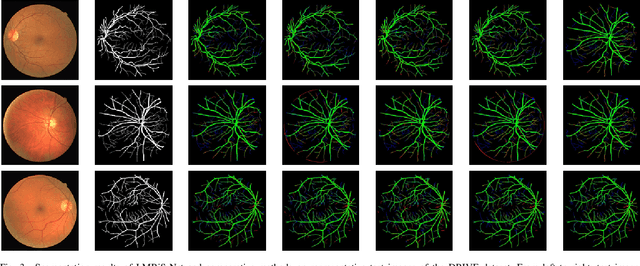
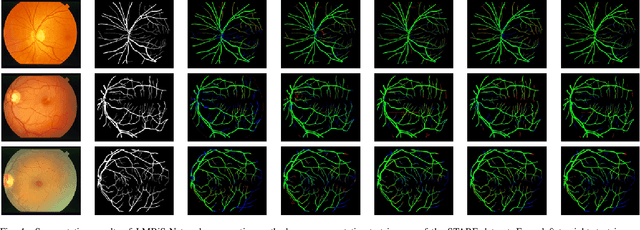
Blinding eye diseases are often correlated with altered retinal morphology, which can be clinically identified by segmenting retinal structures in fundus images. However, current methodologies often fall short in accurately segmenting delicate vessels. Although deep learning has shown promise in medical image segmentation, its reliance on repeated convolution and pooling operations can hinder the representation of edge information, ultimately limiting overall segmentation accuracy. In this paper, we propose a lightweight pixel-level CNN named LMBiS-Net for the segmentation of retinal vessels with an exceptionally low number of learnable parameters \textbf{(only 0.172 M)}. The network used multipath feature extraction blocks and incorporates bidirectional skip connections for the information flow between the encoder and decoder. Additionally, we have optimized the efficiency of the model by carefully selecting the number of filters to avoid filter overlap. This optimization significantly reduces training time and enhances computational efficiency. To assess the robustness and generalizability of LMBiS-Net, we performed comprehensive evaluations on various aspects of retinal images. Specifically, the model was subjected to rigorous tests to accurately segment retinal vessels, which play a vital role in ophthalmological diagnosis and treatment. By focusing on the retinal blood vessels, we were able to thoroughly analyze the performance and effectiveness of the LMBiS-Net model. The results of our tests demonstrate that LMBiS-Net is not only robust and generalizable but also capable of maintaining high levels of segmentation accuracy. These characteristics highlight the potential of LMBiS-Net as an efficient tool for high-speed and accurate segmentation of retinal images in various clinical applications.
Autonomous damage assessment of structural columns using low-cost micro aerial vehicles and multi-view computer vision
Aug 30, 2023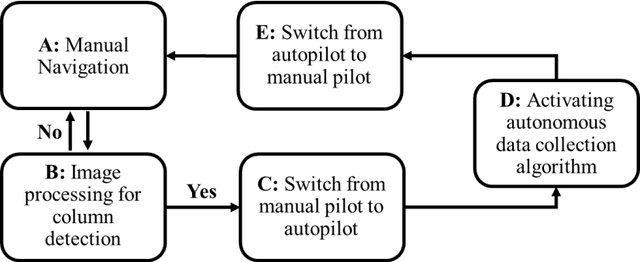
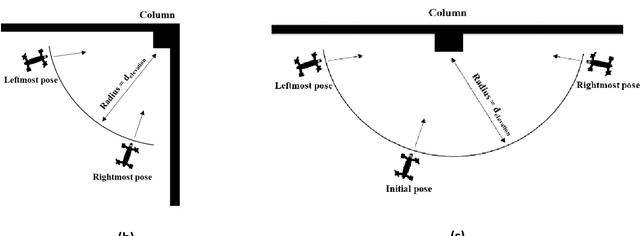

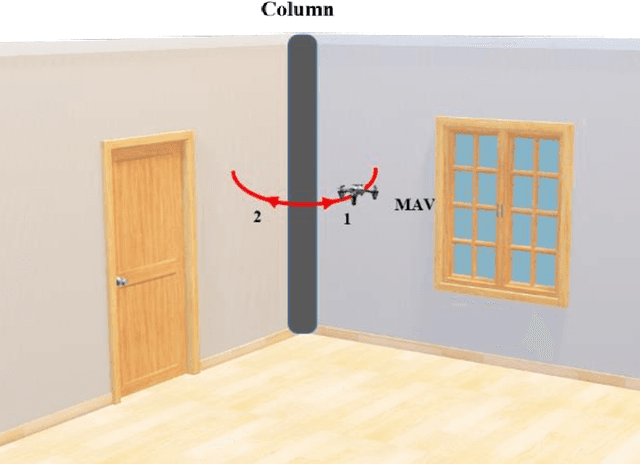
Structural columns are the crucial load-carrying components of buildings and bridges. Early detection of column damage is important for the assessment of the residual performance and the prevention of system-level collapse. This research proposes an innovative end-to-end micro aerial vehicles (MAVs)-based approach to automatically scan and inspect columns. First, an MAV-based automatic image collection method is proposed. The MAV is programmed to sense the structural columns and their surrounding environment. During the navigation, the MAV first detects and approaches the structural columns. Then, it starts to collect image data at multiple viewpoints around every detected column. Second, the collected images will be used to assess the damage types and damage locations. Third, the damage state of the structural column will be determined by fusing the evaluation outcomes from multiple camera views. In this study, reinforced concrete (RC) columns are selected to demonstrate the effectiveness of the approach. Experimental results indicate that the proposed MAV-based inspection approach can effectively collect images from multiple viewing angles, and accurately assess critical RC column damages. The approach improves the level of autonomy during the inspection. In addition, the evaluation outcomes are more comprehensive than the existing 2D vision methods. The concept of the proposed inspection approach can be extended to other structural columns such as bridge piers.
Cross-Modality Proposal-guided Feature Mining for Unregistered RGB-Thermal Pedestrian Detection
Aug 23, 2023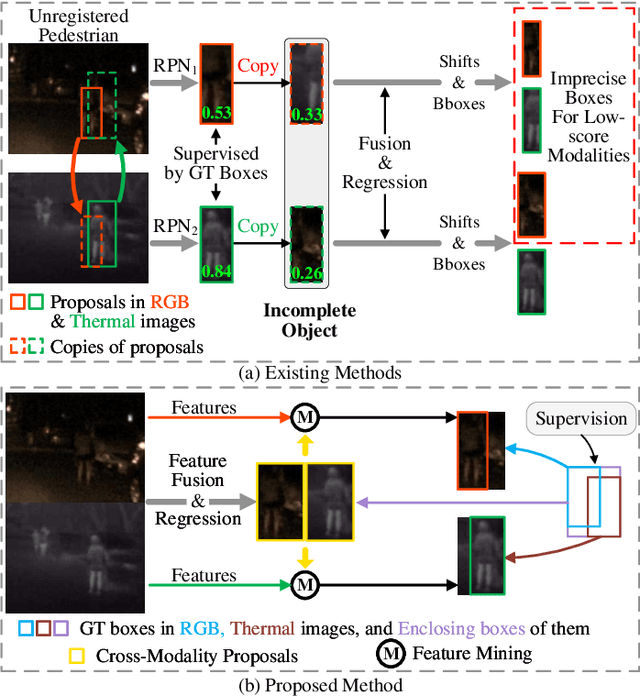
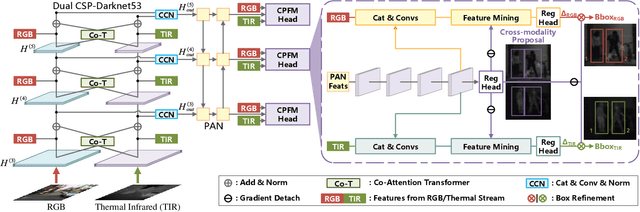
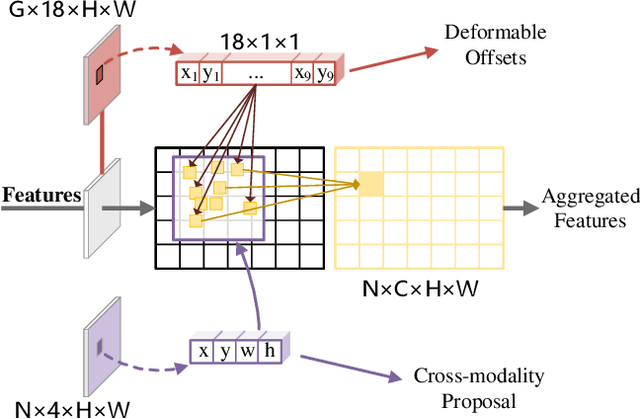
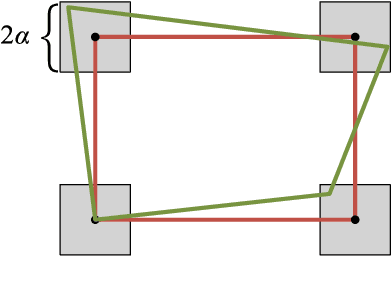
RGB-Thermal (RGB-T) pedestrian detection aims to locate the pedestrians in RGB-T image pairs to exploit the complementation between the two modalities for improving detection robustness in extreme conditions. Most existing algorithms assume that the RGB-T image pairs are well registered, while in the real world they are not aligned ideally due to parallax or different field-of-view of the cameras. The pedestrians in misaligned image pairs may locate at different positions in two images, which results in two challenges: 1) how to achieve inter-modality complementation using spatially misaligned RGB-T pedestrian patches, and 2) how to recognize the unpaired pedestrians at the boundary. To deal with these issues, we propose a new paradigm for unregistered RGB-T pedestrian detection, which predicts two separate pedestrian locations in the RGB and thermal images, respectively. Specifically, we propose a cross-modality proposal-guided feature mining (CPFM) mechanism to extract the two precise fusion features for representing the pedestrian in the two modalities, even if the RGB-T image pair is unaligned. It enables us to effectively exploit the complementation between the two modalities. With the CPFM mechanism, we build a two-stream dense detector; it predicts the two pedestrian locations in the two modalities based on the corresponding fusion feature mined by the CPFM mechanism. Besides, we design a data augmentation method, named Homography, to simulate the discrepancy in scales and views between images. We also investigate two non-maximum suppression (NMS) methods for post-processing. Favorable experimental results demonstrate the effectiveness and robustness of our method in dealing with unregistered pedestrians with different shifts.
Transfer Learning for Microstructure Segmentation with CS-UNet: A Hybrid Algorithm with Transformer and CNN Encoders
Aug 26, 2023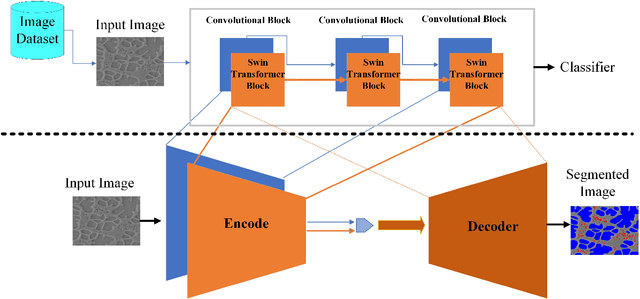

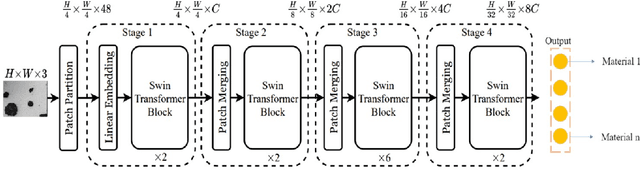
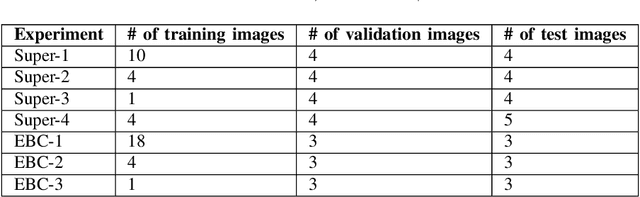
Transfer learning improves the performance of deep learning models by initializing them with parameters pre-trained on larger datasets. Intuitively, transfer learning is more effective when pre-training is on the in-domain datasets. A recent study by NASA has demonstrated that the microstructure segmentation with encoder-decoder algorithms benefits more from CNN encoders pre-trained on microscopy images than from those pre-trained on natural images. However, CNN models only capture the local spatial relations in images. In recent years, attention networks such as Transformers are increasingly used in image analysis to capture the long-range relations between pixels. In this study, we compare the segmentation performance of Transformer and CNN models pre-trained on microscopy images with those pre-trained on natural images. Our result partially confirms the NASA study that the segmentation performance of out-of-distribution images (taken under different imaging and sample conditions) is significantly improved when pre-training on microscopy images. However, the performance gain for one-shot and few-shot learning is more modest with Transformers. We also find that for image segmentation, the combination of pre-trained Transformers and CNN encoders are consistently better than pre-trained CNN encoders alone. Our dataset (of about 50,000 images) combines the public portion of the NASA dataset with additional images we collected. Even with much less training data, our pre-trained models have significantly better performance for image segmentation. This result suggests that Transformers and CNN complement each other and when pre-trained on microscopy images, they are more beneficial to the downstream tasks.
Masking Strategies for Background Bias Removal in Computer Vision Models
Aug 23, 2023
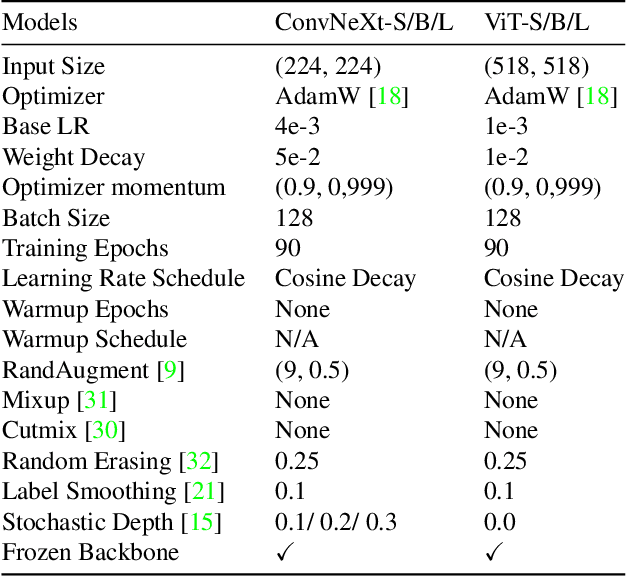
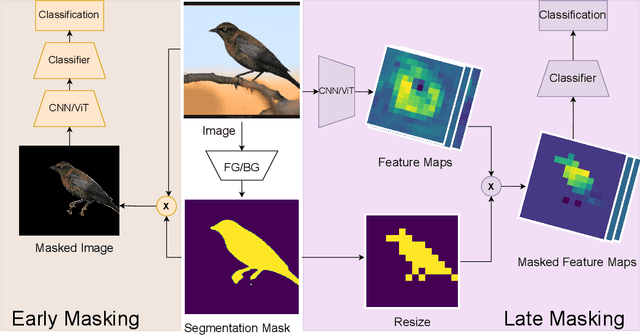
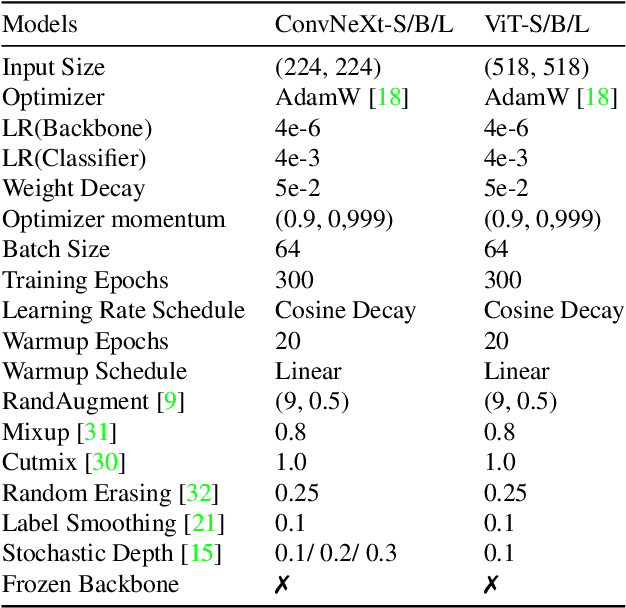
Models for fine-grained image classification tasks, where the difference between some classes can be extremely subtle and the number of samples per class tends to be low, are particularly prone to picking up background-related biases and demand robust methods to handle potential examples with out-of-distribution (OOD) backgrounds. To gain deeper insights into this critical problem, our research investigates the impact of background-induced bias on fine-grained image classification, evaluating standard backbone models such as Convolutional Neural Network (CNN) and Vision Transformers (ViT). We explore two masking strategies to mitigate background-induced bias: Early masking, which removes background information at the (input) image level, and late masking, which selectively masks high-level spatial features corresponding to the background. Extensive experiments assess the behavior of CNN and ViT models under different masking strategies, with a focus on their generalization to OOD backgrounds. The obtained findings demonstrate that both proposed strategies enhance OOD performance compared to the baseline models, with early masking consistently exhibiting the best OOD performance. Notably, a ViT variant employing GAP-Pooled Patch token-based classification combined with early masking achieves the highest OOD robustness.
Multimodal Foundation Models For Echocardiogram Interpretation
Aug 29, 2023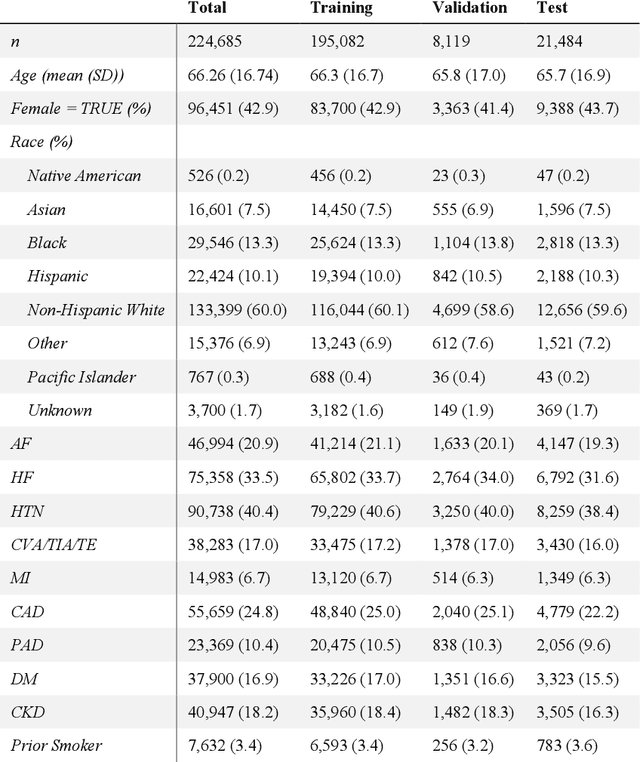
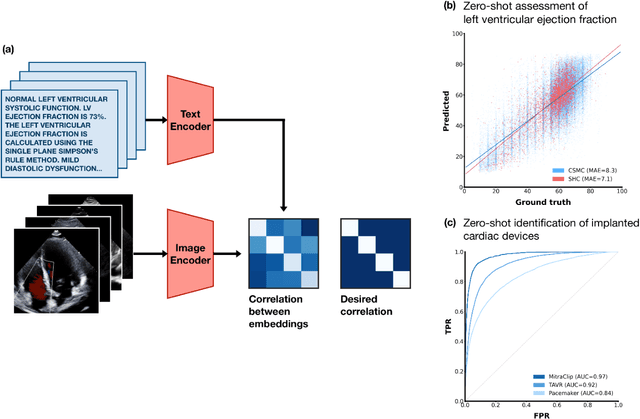
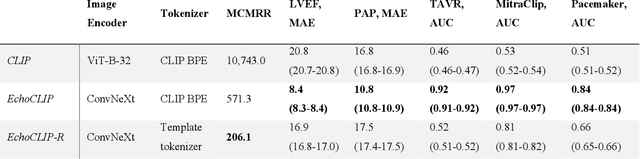
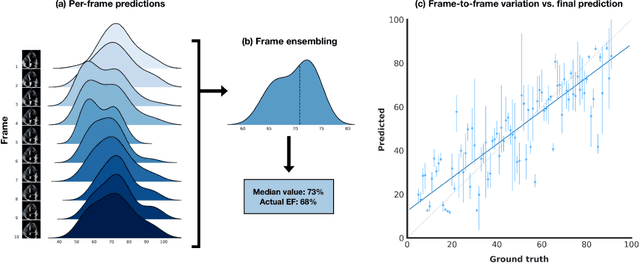
Multimodal deep learning foundation models can learn the relationship between images and text. In the context of medical imaging, mapping images to language concepts reflects the clinical task of diagnostic image interpretation, however current general-purpose foundation models do not perform well in this context because their training corpus have limited medical text and images. To address this challenge and account for the range of cardiac physiology, we leverage 1,032,975 cardiac ultrasound videos and corresponding expert interpretations to develop EchoCLIP, a multimodal foundation model for echocardiography. EchoCLIP displays strong zero-shot (not explicitly trained) performance in cardiac function assessment (external validation left ventricular ejection fraction mean absolute error (MAE) of 7.1%) and identification of implanted intracardiac devices (areas under the curve (AUC) between 0.84 and 0.98 for pacemakers and artificial heart valves). We also developed a long-context variant (EchoCLIP-R) with a custom echocardiography report text tokenizer which can accurately identify unique patients across multiple videos (AUC of 0.86), identify clinical changes such as orthotopic heart transplants (AUC of 0.79) or cardiac surgery (AUC 0.77), and enable robust image-to-text search (mean cross-modal retrieval rank in the top 1% of candidate text reports). These emergent capabilities can be used for preliminary assessment and summarization of echocardiographic findings.