 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MRI Field-transfer Reconstruction with Limited Data: Regularization by Neural Style Transfer
Aug 21, 2023
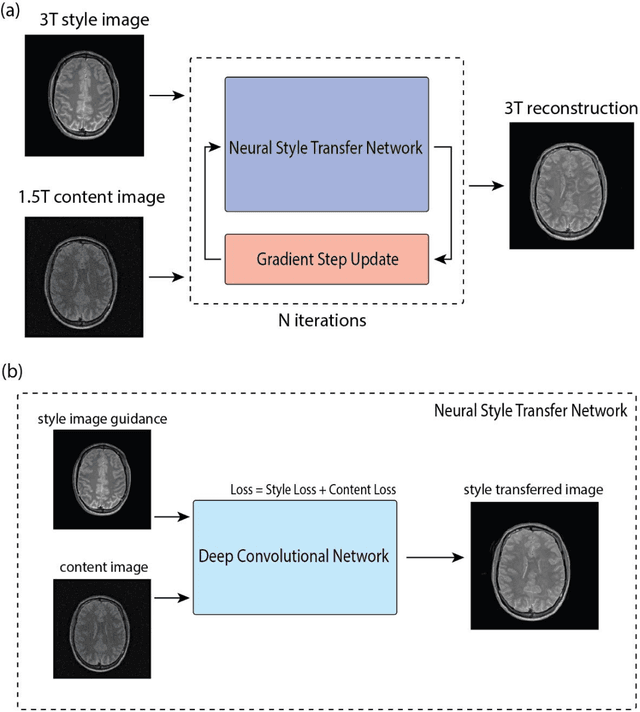
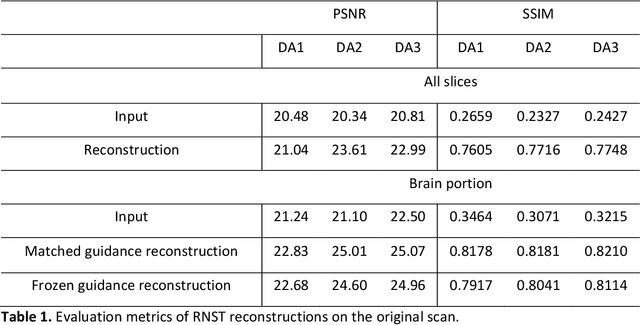
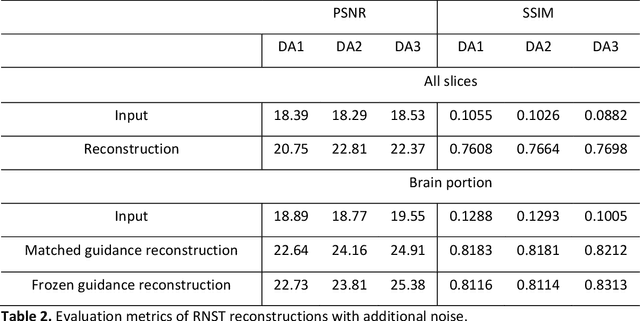
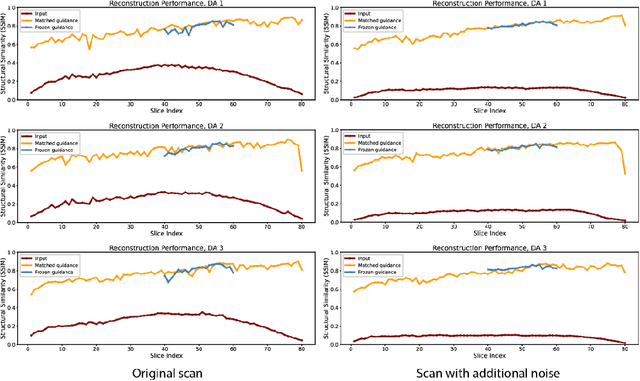
Recent works have demonstrated success in MRI reconstruction using deep learning-based models. However, most reported approaches require training on a task-specific, large-scale dataset. Regularization by denoising (RED) is a general pipeline which embeds a denoiser as a prior for image reconstruction. The potential of RED has been demonstrated for multiple image-related tasks such as denoising, deblurring and super-resolution. In this work, we propose a regularization by neural style transfer (RNST) method to further leverage the priors from the neural transfer and denoising engine. This enables RNST to reconstruct a high-quality image from a noisy low-quality image with different image styles and limited data. We validate RNST with clinical MRI scans from 1.5T and 3T and show that RNST can significantly boost image quality. Our results highlight the capability of the RNST framework for MRI reconstruction and the potential for reconstruction tasks with limited data.
Diffusion-based Adversarial Purification for Robust Deep MRI Reconstruction
Sep 11, 2023Deep learning (DL) methods have been extensively employed in magnetic resonance imaging (MRI) reconstruction, demonstrating remarkable performance improvements compared to traditional non-DL methods. However, recent studies have uncovered the susceptibility of these models to carefully engineered adversarial perturbations. In this paper, we tackle this issue by leveraging diffusion models. Specifically, we introduce a defense strategy that enhances the robustness of DL-based MRI reconstruction methods through the utilization of pre-trained diffusion models as adversarial purifiers. Unlike conventional state-of-the-art adversarial defense methods (e.g., adversarial training), our proposed approach eliminates the need to solve a minimax optimization problem to train the image reconstruction model from scratch, and only requires fine-tuning on purified adversarial examples. Our experimental findings underscore the effectiveness of our proposed technique when benchmarked against leading defense methodologies for MRI reconstruction such as adversarial training and randomized smoothing.
Correlated and Multi-frequency Diffusion Modeling for Highly Under-sampled MRI Reconstruction
Sep 02, 2023Most existing MRI reconstruction methods perform tar-geted reconstruction of the entire MR image without tak-ing specific tissue regions into consideration. This may fail to emphasize the reconstruction accuracy on im-portant tissues for diagnosis. In this study, leveraging a combination of the properties of k-space data and the diffusion process, our novel scheme focuses on mining the multi-frequency prior with different strategies to pre-serve fine texture details in the reconstructed image. In addition, a diffusion process can converge more quickly if its target distribution closely resembles the noise distri-bution in the process. This can be accomplished through various high-frequency prior extractors. The finding further solidifies the effectiveness of the score-based gen-erative model. On top of all the advantages, our method improves the accuracy of MRI reconstruction and accel-erates sampling process. Experimental results verify that the proposed method successfully obtains more accurate reconstruction and outperforms state-of-the-art methods.
ConvNeXt-ChARM: ConvNeXt-based Transform for Efficient Neural Image Compression
Jul 12, 2023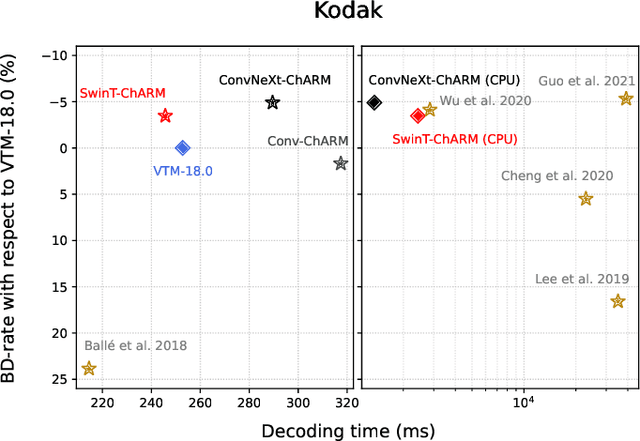
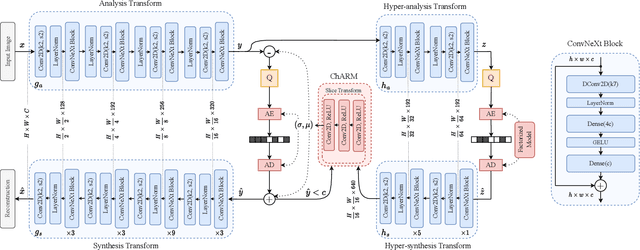
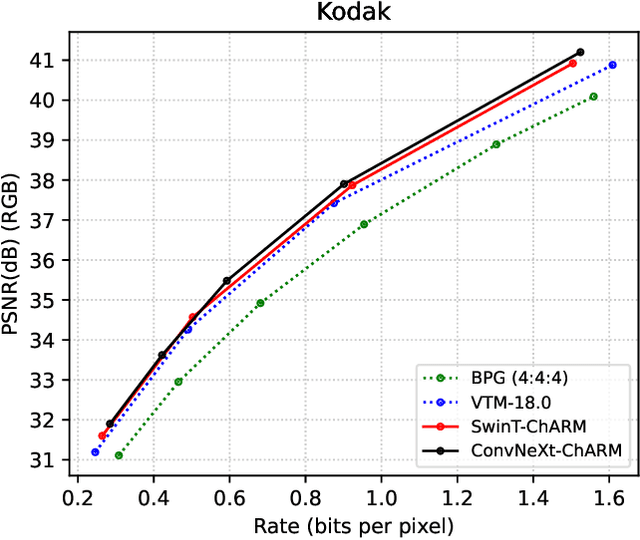
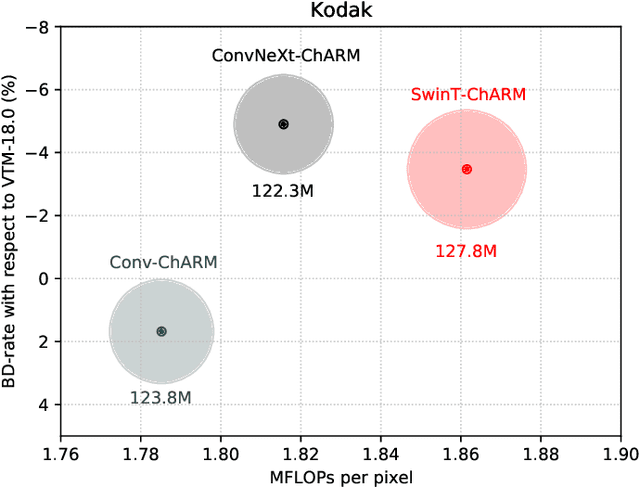
Over the last few years, neural image compression has gained wide attention from research and industry, yielding promising end-to-end deep neural codecs outperforming their conventional counterparts in rate-distortion performance. Despite significant advancement, current methods, including attention-based transform coding, still need to be improved in reducing the coding rate while preserving the reconstruction fidelity, especially in non-homogeneous textured image areas. Those models also require more parameters and a higher decoding time. To tackle the above challenges, we propose ConvNeXt-ChARM, an efficient ConvNeXt-based transform coding framework, paired with a compute-efficient channel-wise auto-regressive prior to capturing both global and local contexts from the hyper and quantized latent representations. The proposed architecture can be optimized end-to-end to fully exploit the context information and extract compact latent representation while reconstructing higher-quality images. Experimental results on four widely-used datasets showed that ConvNeXt-ChARM brings consistent and significant BD-rate (PSNR) reductions estimated on average to 5.24% and 1.22% over the versatile video coding (VVC) reference encoder (VTM-18.0) and the state-of-the-art learned image compression method SwinT-ChARM, respectively. Moreover, we provide model scaling studies to verify the computational efficiency of our approach and conduct several objective and subjective analyses to bring to the fore the performance gap between the next generation ConvNet, namely ConvNeXt, and Swin Transformer.
DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing
Jul 09, 2023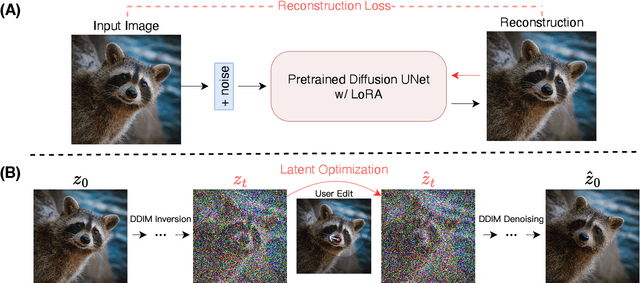


Precise and controllable image editing is a challenging task that has attracted significant attention. Recently, DragGAN enables an interactive point-based image editing framework and achieves impressive editing results with pixel-level precision. However, since this method is based on generative adversarial networks (GAN), its generality is upper-bounded by the capacity of the pre-trained GAN models. In this work, we extend such an editing framework to diffusion models and propose DragDiffusion. By leveraging large-scale pretrained diffusion models, we greatly improve the applicability of interactive point-based editing in real world scenarios. While most existing diffusion-based image editing methods work on text embeddings, DragDiffusion optimizes the diffusion latent to achieve precise spatial control. Although diffusion models generate images in an iterative manner, we empirically show that optimizing diffusion latent at one single step suffices to generate coherent results, enabling DragDiffusion to complete high-quality editing efficiently. Extensive experiments across a wide range of challenging cases (e.g., multi-objects, diverse object categories, various styles, etc.) demonstrate the versatility and generality of DragDiffusion. Code: https://github.com/Yujun-Shi/DragDiffusion.
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Jul 04, 2023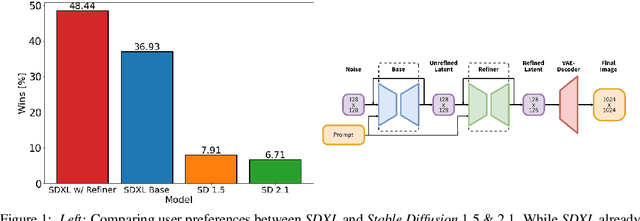

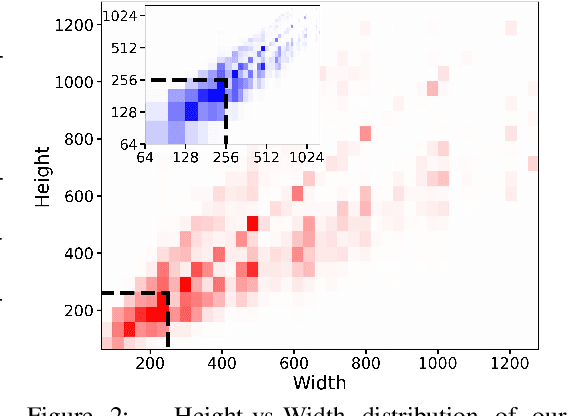
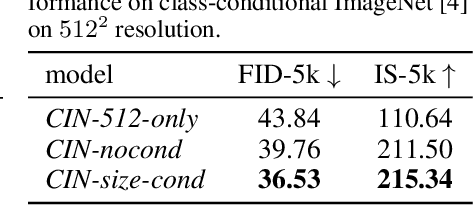
We present SDXL, a latent diffusion model for text-to-image synthesis. Compared to previous versions of Stable Diffusion, SDXL leverages a three times larger UNet backbone: The increase of model parameters is mainly due to more attention blocks and a larger cross-attention context as SDXL uses a second text encoder. We design multiple novel conditioning schemes and train SDXL on multiple aspect ratios. We also introduce a refinement model which is used to improve the visual fidelity of samples generated by SDXL using a post-hoc image-to-image technique. We demonstrate that SDXL shows drastically improved performance compared the previous versions of Stable Diffusion and achieves results competitive with those of black-box state-of-the-art image generators. In the spirit of promoting open research and fostering transparency in large model training and evaluation, we provide access to code and model weights at https://github.com/Stability-AI/generative-models
Virchow: A Million-Slide Digital Pathology Foundation Model
Sep 15, 2023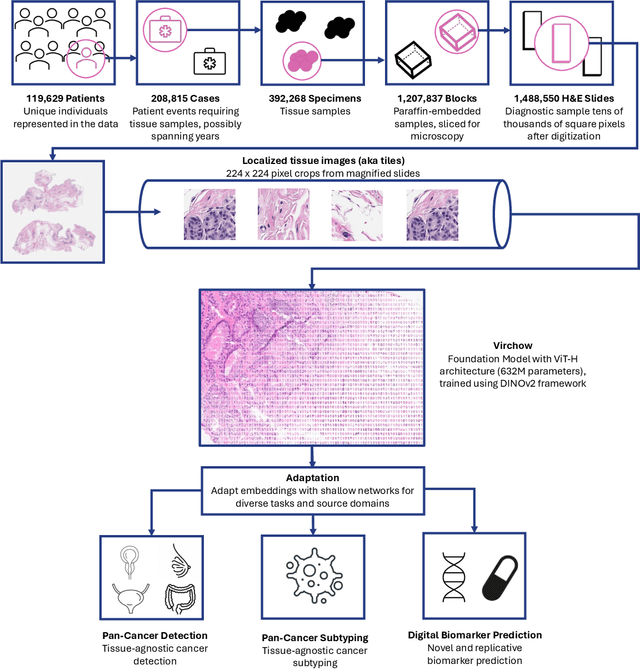
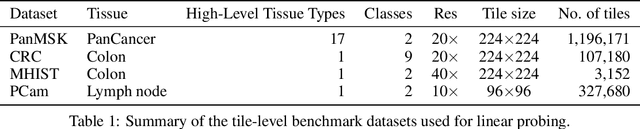
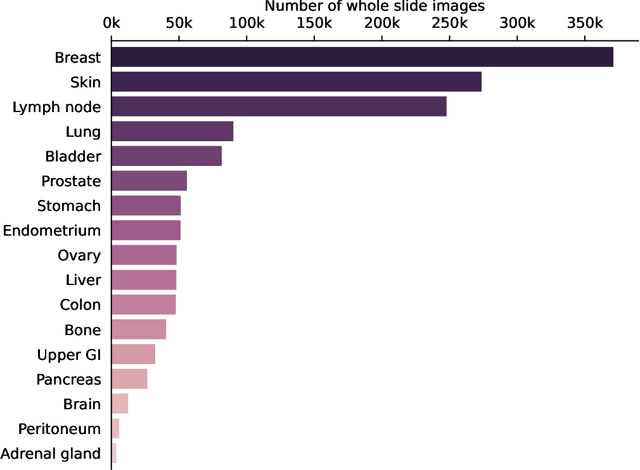
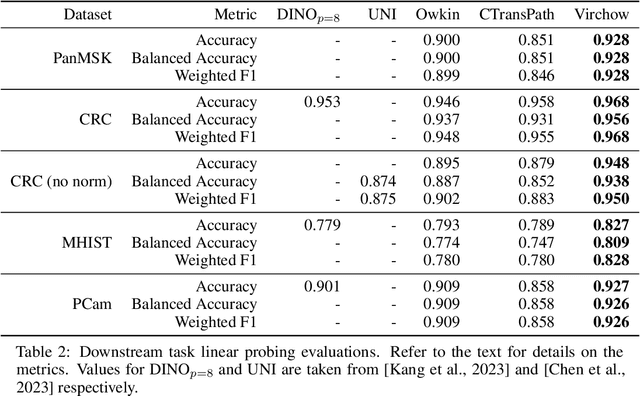
Computational pathology uses artificial intelligence to enable precision medicine and decision support systems through the analysis of whole slide images. It has the potential to revolutionize the diagnosis and treatment of cancer. However, a major challenge to this objective is that for many specific computational pathology tasks the amount of data is inadequate for development. To address this challenge, we created Virchow, a 632 million parameter deep neural network foundation model for computational pathology. Using self-supervised learning, Virchow is trained on 1.5 million hematoxylin and eosin stained whole slide images from diverse tissue groups, which is orders of magnitude more data than previous works. When evaluated on downstream tasks including tile-level pan-cancer detection and subtyping and slide-level biomarker prediction, Virchow outperforms state-of-the-art systems both on internal datasets drawn from the same population as the pretraining data as well as external public datasets. Virchow achieves 93% balanced accuracy for pancancer tile classification, and AUCs of 0.983 for colon microsatellite instability status prediction and 0.967 for breast CDH1 status prediction. The gains in performance highlight the importance of pretraining on massive pathology image datasets, suggesting pretraining on even larger datasets could continue improving performance for many high-impact applications where limited amounts of training data are available, such as drug outcome prediction.
Phase retrieval via non-rigid image registration
Jun 26, 2023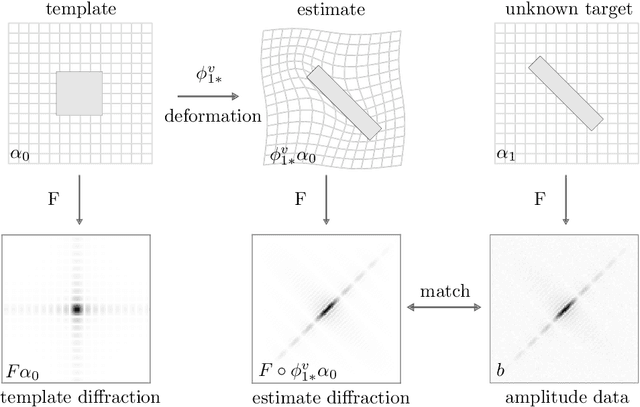
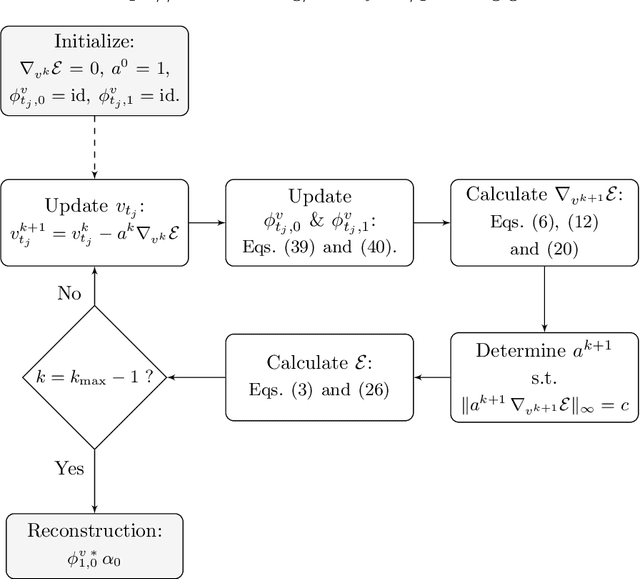
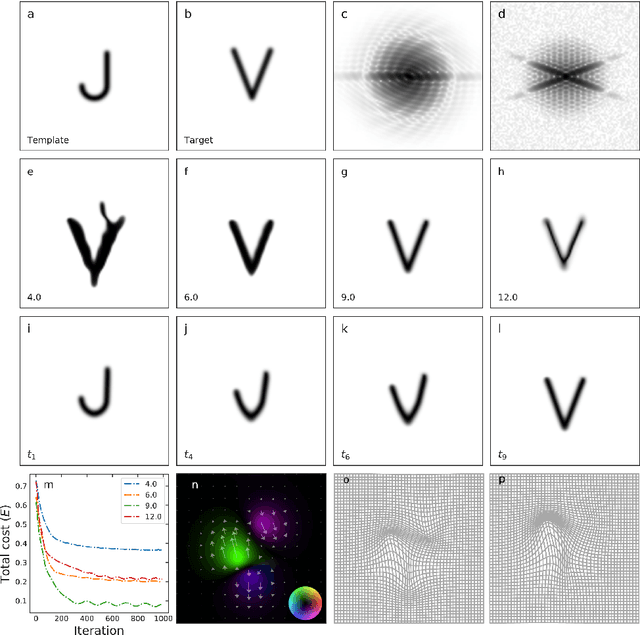
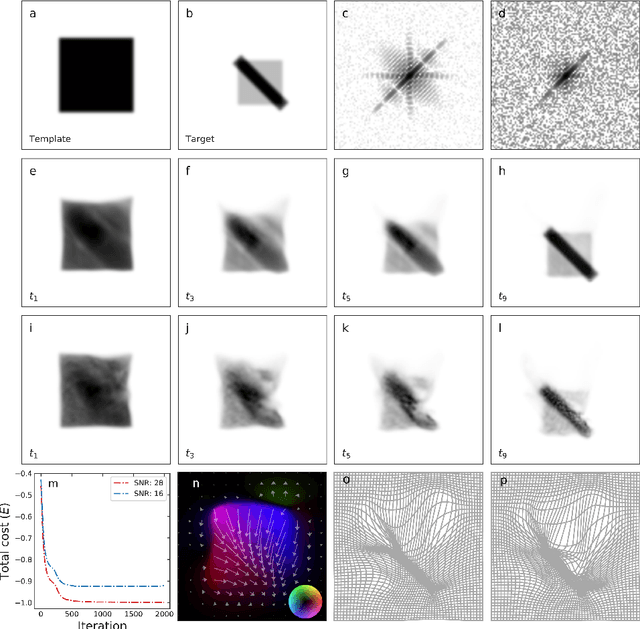
Phase retrieval is the numerical procedure of recovering a complex-valued signal from knowledge about its amplitude and some additional information. Here, an indirect registration procedure, based on the large deformation diffeomorphic metric mapping (LDDMM) formalism, is investigated as a phase retrieval method for coherent diffractive imaging. The method attempts to find a deformation which transforms an initial, template image to match an unknown target image by comparing the diffraction pattern to the data. The exterior calculus framework is used to treat different types of deformations in a unified and coordinate-free way. The algorithm performance with respect to measurement noise, image topology, and particular action are explored through numerical examples.
Any-Size-Diffusion: Toward Efficient Text-Driven Synthesis for Any-Size HD Images
Aug 31, 2023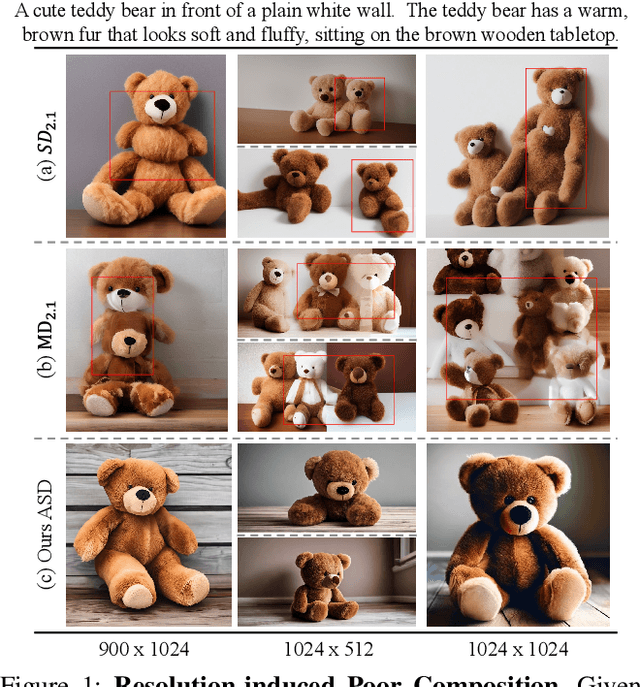
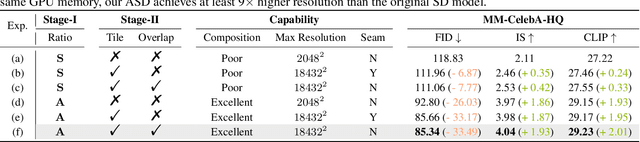
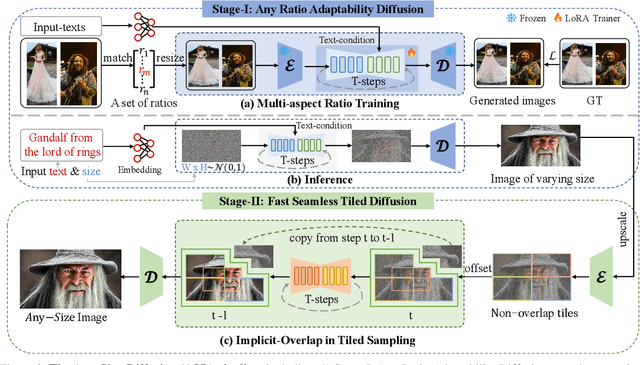
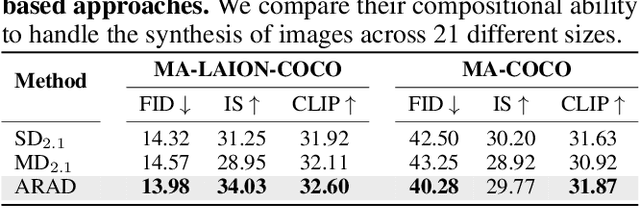
Stable diffusion, a generative model used in text-to-image synthesis, frequently encounters resolution-induced composition problems when generating images of varying sizes. This issue primarily stems from the model being trained on pairs of single-scale images and their corresponding text descriptions. Moreover, direct training on images of unlimited sizes is unfeasible, as it would require an immense number of text-image pairs and entail substantial computational expenses. To overcome these challenges, we propose a two-stage pipeline named Any-Size-Diffusion (ASD), designed to efficiently generate well-composed images of any size, while minimizing the need for high-memory GPU resources. Specifically, the initial stage, dubbed Any Ratio Adaptability Diffusion (ARAD), leverages a selected set of images with a restricted range of ratios to optimize the text-conditional diffusion model, thereby improving its ability to adjust composition to accommodate diverse image sizes. To support the creation of images at any desired size, we further introduce a technique called Fast Seamless Tiled Diffusion (FSTD) at the subsequent stage. This method allows for the rapid enlargement of the ASD output to any high-resolution size, avoiding seaming artifacts or memory overloads. Experimental results on the LAION-COCO and MM-CelebA-HQ benchmarks demonstrate that ASD can produce well-structured images of arbitrary sizes, cutting down the inference time by 2x compared to the traditional tiled algorithm.
Stroke Extraction of Chinese Character Based on Deep Structure Deformable Image Registration
Jul 10, 2023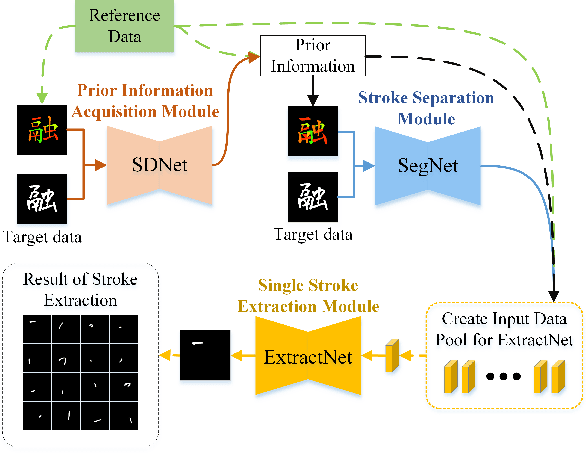
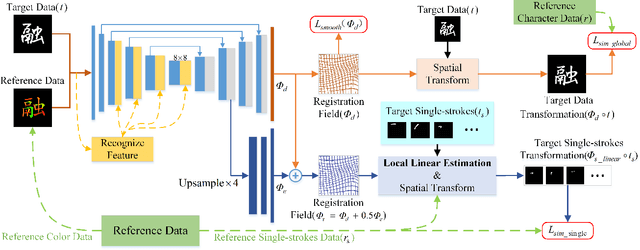
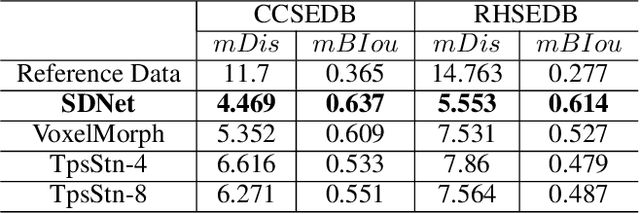
Stroke extraction of Chinese characters plays an important role in the field of character recognition and generation. The most existing character stroke extraction methods focus on image morphological features. These methods usually lead to errors of cross strokes extraction and stroke matching due to rarely using stroke semantics and prior information. In this paper, we propose a deep learning-based character stroke extraction method that takes semantic features and prior information of strokes into consideration. This method consists of three parts: image registration-based stroke registration that establishes the rough registration of the reference strokes and the target as prior information; image semantic segmentation-based stroke segmentation that preliminarily separates target strokes into seven categories; and high-precision extraction of single strokes. In the stroke registration, we propose a structure deformable image registration network to achieve structure-deformable transformation while maintaining the stable morphology of single strokes for character images with complex structures. In order to verify the effectiveness of the method, we construct two datasets respectively for calligraphy characters and regular handwriting characters. The experimental results show that our method strongly outperforms the baselines. Code is available at https://github.com/MengLi-l1/StrokeExtraction.
* 10 pages, 8 figures, published to AAAI-23 (oral)