 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LEDITS: Real Image Editing with DDPM Inversion and Semantic Guidance
Jul 02, 2023

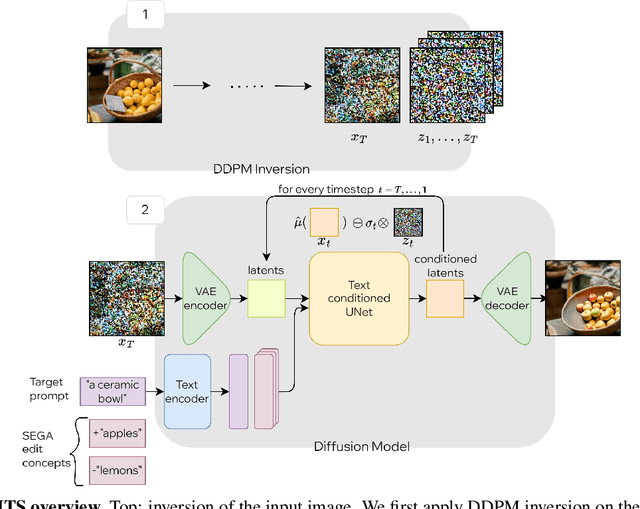

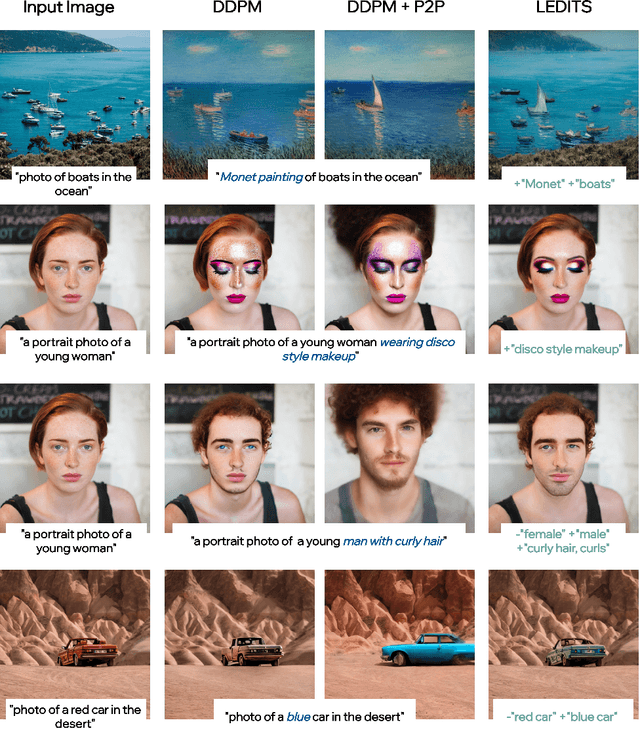
Recent large-scale text-guided diffusion models provide powerful image-generation capabilities. Currently, a significant effort is given to enable the modification of these images using text only as means to offer intuitive and versatile editing. However, editing proves to be difficult for these generative models due to the inherent nature of editing techniques, which involves preserving certain content from the original image. Conversely, in text-based models, even minor modifications to the text prompt frequently result in an entirely distinct result, making attaining one-shot generation that accurately corresponds to the users intent exceedingly challenging. In addition, to edit a real image using these state-of-the-art tools, one must first invert the image into the pre-trained models domain - adding another factor affecting the edit quality, as well as latency. In this exploratory report, we propose LEDITS - a combined lightweight approach for real-image editing, incorporating the Edit Friendly DDPM inversion technique with Semantic Guidance, thus extending Semantic Guidance to real image editing, while harnessing the editing capabilities of DDPM inversion as well. This approach achieves versatile edits, both subtle and extensive as well as alterations in composition and style, while requiring no optimization nor extensions to the architecture.
Impact of Visual Context on Noisy Multimodal NMT: An Empirical Study for English to Indian Languages
Aug 30, 2023
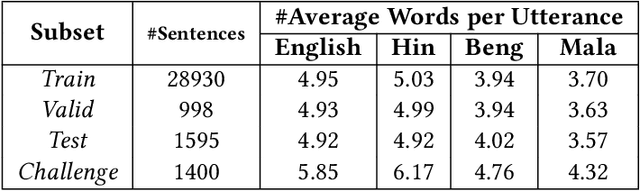
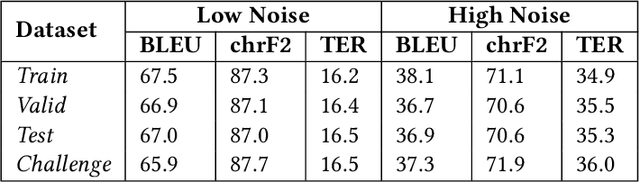
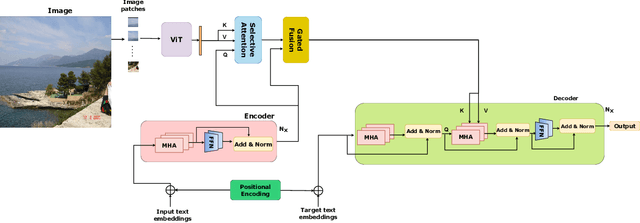
The study investigates the effectiveness of utilizing multimodal information in Neural Machine Translation (NMT). While prior research focused on using multimodal data in low-resource scenarios, this study examines how image features impact translation when added to a large-scale, pre-trained unimodal NMT system. Surprisingly, the study finds that images might be redundant in this context. Additionally, the research introduces synthetic noise to assess whether images help the model deal with textual noise. Multimodal models slightly outperform text-only models in noisy settings, even with random images. The study's experiments translate from English to Hindi, Bengali, and Malayalam, outperforming state-of-the-art benchmarks significantly. Interestingly, the effect of visual context varies with source text noise: no visual context works best for non-noisy translations, cropped image features are optimal for low noise, and full image features work better in high-noise scenarios. This sheds light on the role of visual context, especially in noisy settings, opening up a new research direction for Noisy Neural Machine Translation in multimodal setups. The research emphasizes the importance of combining visual and textual information for improved translation in various environments.
Towards Safe Self-Distillation of Internet-Scale Text-to-Image Diffusion Models
Jul 12, 2023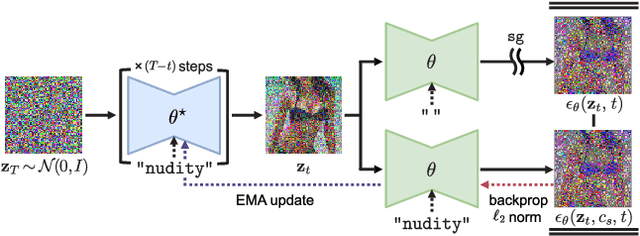
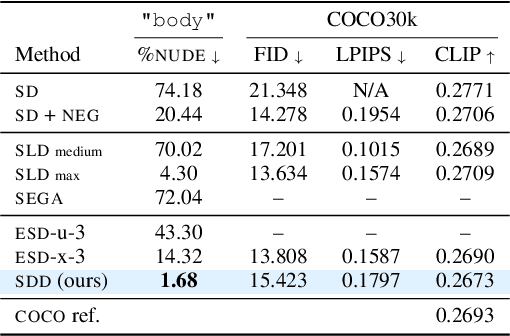
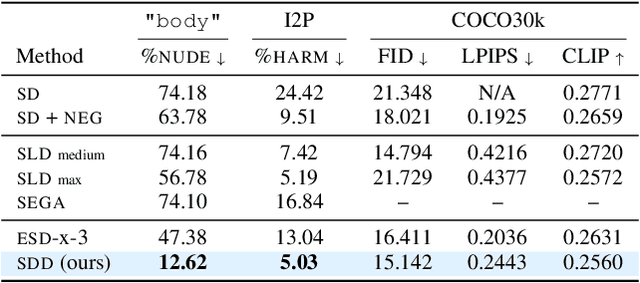

Large-scale image generation models, with impressive quality made possible by the vast amount of data available on the Internet, raise social concerns that these models may generate harmful or copyrighted content. The biases and harmfulness arise throughout the entire training process and are hard to completely remove, which have become significant hurdles to the safe deployment of these models. In this paper, we propose a method called SDD to prevent problematic content generation in text-to-image diffusion models. We self-distill the diffusion model to guide the noise estimate conditioned on the target removal concept to match the unconditional one. Compared to the previous methods, our method eliminates a much greater proportion of harmful content from the generated images without degrading the overall image quality. Furthermore, our method allows the removal of multiple concepts at once, whereas previous works are limited to removing a single concept at a time.
ICAR: Image-based Complementary Auto Reasoning
Aug 17, 2023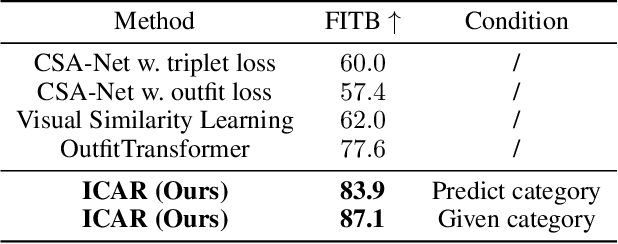
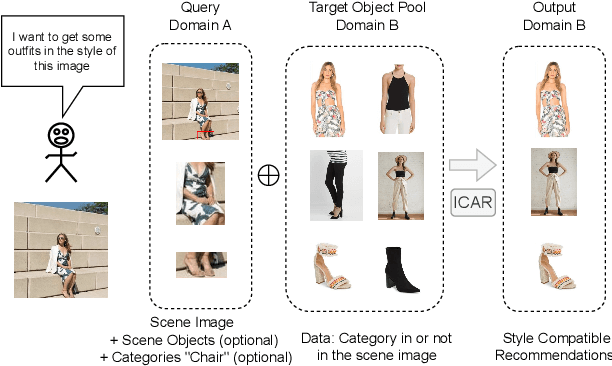
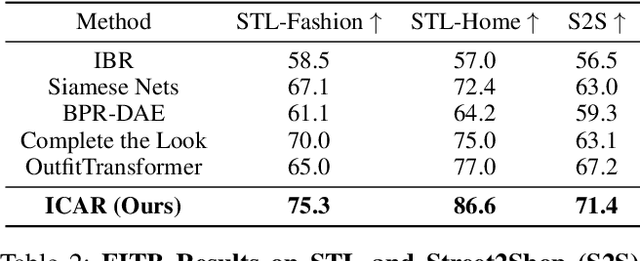
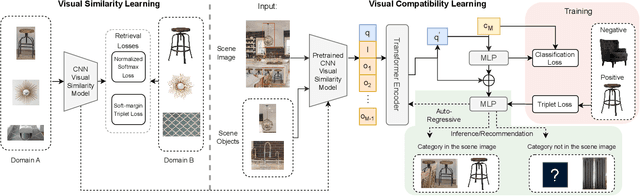
Scene-aware Complementary Item Retrieval (CIR) is a challenging task which requires to generate a set of compatible items across domains. Due to the subjectivity, it is difficult to set up a rigorous standard for both data collection and learning objectives. To address this challenging task, we propose a visual compatibility concept, composed of similarity (resembling in color, geometry, texture, and etc.) and complementarity (different items like table vs chair completing a group). Based on this notion, we propose a compatibility learning framework, a category-aware Flexible Bidirectional Transformer (FBT), for visual "scene-based set compatibility reasoning" with the cross-domain visual similarity input and auto-regressive complementary item generation. We introduce a "Flexible Bidirectional Transformer (FBT)" consisting of an encoder with flexible masking, a category prediction arm, and an auto-regressive visual embedding prediction arm. And the inputs for FBT are cross-domain visual similarity invariant embeddings, making this framework quite generalizable. Furthermore, our proposed FBT model learns the inter-object compatibility from a large set of scene images in a self-supervised way. Compared with the SOTA methods, this approach achieves up to 5.3% and 9.6% in FITB score and 22.3% and 31.8% SFID improvement on fashion and furniture, respectively.
CLIP-Guided StyleGAN Inversion for Text-Driven Real Image Editing
Jul 18, 2023
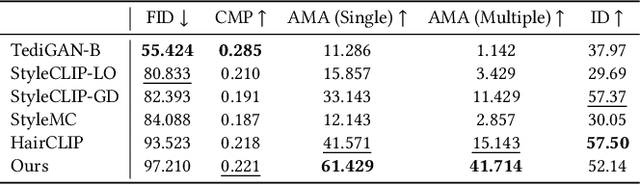

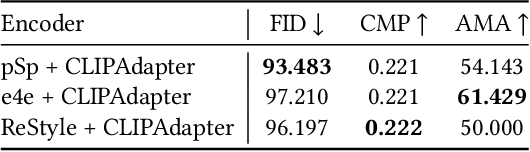
Researchers have recently begun exploring the use of StyleGAN-based models for real image editing. One particularly interesting application is using natural language descriptions to guide the editing process. Existing approaches for editing images using language either resort to instance-level latent code optimization or map predefined text prompts to some editing directions in the latent space. However, these approaches have inherent limitations. The former is not very efficient, while the latter often struggles to effectively handle multi-attribute changes. To address these weaknesses, we present CLIPInverter, a new text-driven image editing approach that is able to efficiently and reliably perform multi-attribute changes. The core of our method is the use of novel, lightweight text-conditioned adapter layers integrated into pretrained GAN-inversion networks. We demonstrate that by conditioning the initial inversion step on the CLIP embedding of the target description, we are able to obtain more successful edit directions. Additionally, we use a CLIP-guided refinement step to make corrections in the resulting residual latent codes, which further improves the alignment with the text prompt. Our method outperforms competing approaches in terms of manipulation accuracy and photo-realism on various domains including human faces, cats, and birds, as shown by our qualitative and quantitative results.
Semantic-Aware Dual Contrastive Learning for Multi-label Image Classification
Jul 19, 2023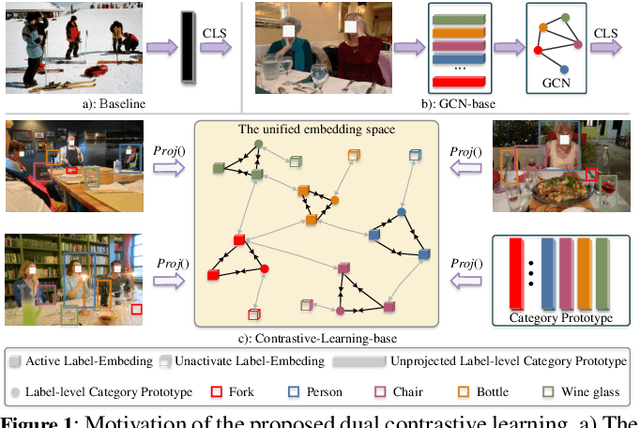
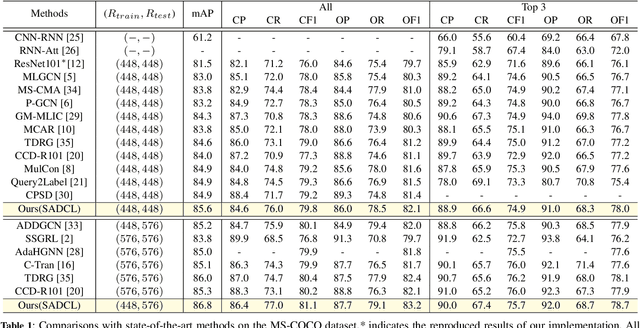
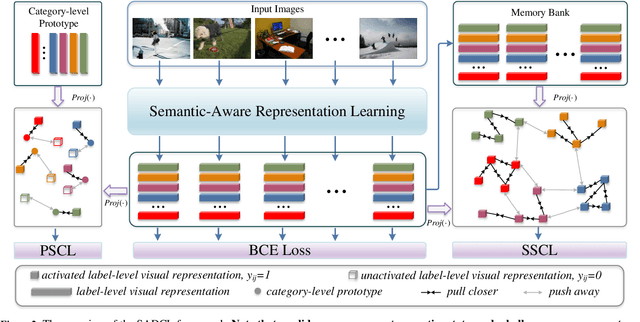
Extracting image semantics effectively and assigning corresponding labels to multiple objects or attributes for natural images is challenging due to the complex scene contents and confusing label dependencies. Recent works have focused on modeling label relationships with graph and understanding object regions using class activation maps (CAM). However, these methods ignore the complex intra- and inter-category relationships among specific semantic features, and CAM is prone to generate noisy information. To this end, we propose a novel semantic-aware dual contrastive learning framework that incorporates sample-to-sample contrastive learning (SSCL) as well as prototype-to-sample contrastive learning (PSCL). Specifically, we leverage semantic-aware representation learning to extract category-related local discriminative features and construct category prototypes. Then based on SSCL, label-level visual representations of the same category are aggregated together, and features belonging to distinct categories are separated. Meanwhile, we construct a novel PSCL module to narrow the distance between positive samples and category prototypes and push negative samples away from the corresponding category prototypes. Finally, the discriminative label-level features related to the image content are accurately captured by the joint training of the above three parts. Experiments on five challenging large-scale public datasets demonstrate that our proposed method is effective and outperforms the state-of-the-art methods. Code and supplementary materials are released on https://github.com/yu-gi-oh-leilei/SADCL.
MIM-OOD: Generative Masked Image Modelling for Out-of-Distribution Detection in Medical Images
Aug 02, 2023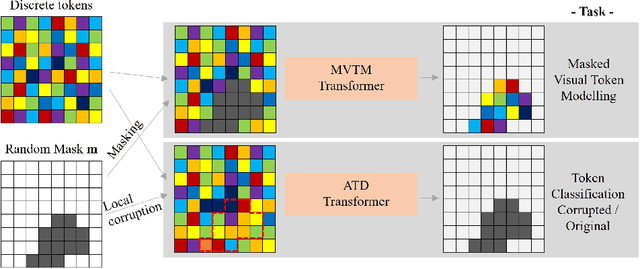

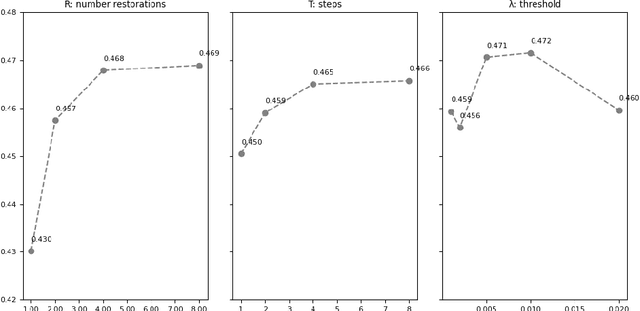
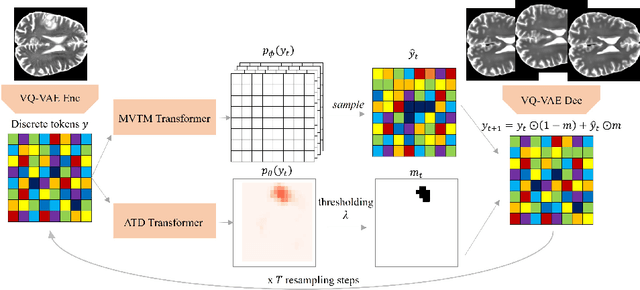
Unsupervised Out-of-Distribution (OOD) detection consists in identifying anomalous regions in images leveraging only models trained on images of healthy anatomy. An established approach is to tokenize images and model the distribution of tokens with Auto-Regressive (AR) models. AR models are used to 1) identify anomalous tokens and 2) in-paint anomalous representations with in-distribution tokens. However, AR models are slow at inference time and prone to error accumulation issues which negatively affect OOD detection performance. Our novel method, MIM-OOD, overcomes both speed and error accumulation issues by replacing the AR model with two task-specific networks: 1) a transformer optimized to identify anomalous tokens and 2) a transformer optimized to in-paint anomalous tokens using masked image modelling (MIM). Our experiments with brain MRI anomalies show that MIM-OOD substantially outperforms AR models (DICE 0.458 vs 0.301) while achieving a nearly 25x speedup (9.5s vs 244s).
Detect, Augment, Compose, and Adapt: Four Steps for Unsupervised Domain Adaptation in Object Detection
Aug 29, 2023

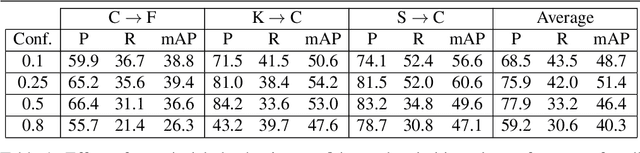

Unsupervised domain adaptation (UDA) plays a crucial role in object detection when adapting a source-trained detector to a target domain without annotated data. In this paper, we propose a novel and effective four-step UDA approach that leverages self-supervision and trains source and target data concurrently. We harness self-supervised learning to mitigate the lack of ground truth in the target domain. Our method consists of the following steps: (1) identify the region with the highest-confidence set of detections in each target image, which serve as our pseudo-labels; (2) crop the identified region and generate a collection of its augmented versions; (3) combine these latter into a composite image; (4) adapt the network to the target domain using the composed image. Through extensive experiments under cross-camera, cross-weather, and synthetic-to-real scenarios, our approach achieves state-of-the-art performance, improving upon the nearest competitor by more than 2% in terms of mean Average Precision (mAP). The code is available at https://github.com/MohamedTEV/DACA.
Adaptive conformal classification with noisy labels
Sep 10, 2023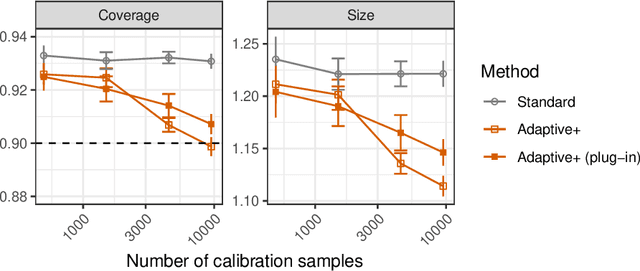
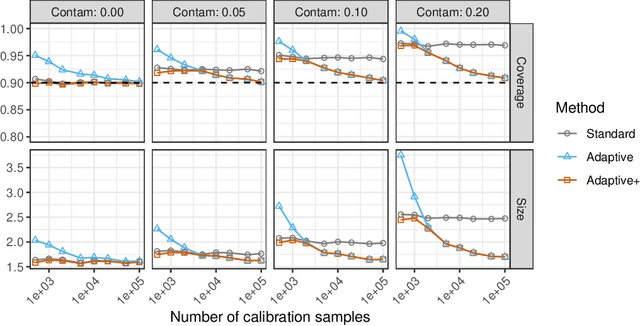
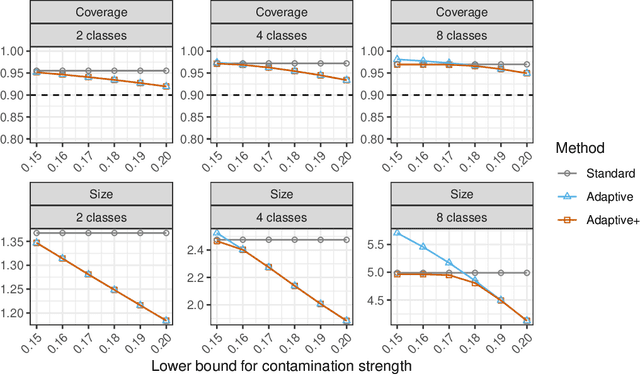
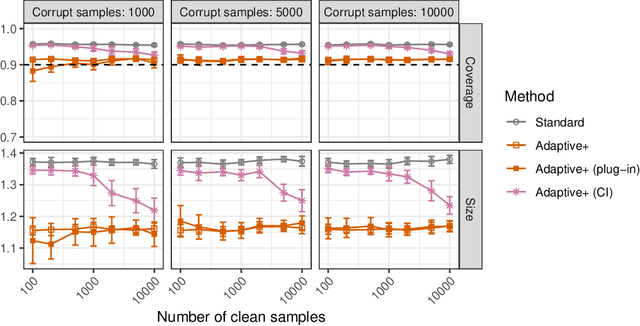
This paper develops novel conformal prediction methods for classification tasks that can automatically adapt to random label contamination in the calibration sample, enabling more informative prediction sets with stronger coverage guarantees compared to state-of-the-art approaches. This is made possible by a precise theoretical characterization of the effective coverage inflation (or deflation) suffered by standard conformal inferences in the presence of label contamination, which is then made actionable through new calibration algorithms. Our solution is flexible and can leverage different modeling assumptions about the label contamination process, while requiring no knowledge about the data distribution or the inner workings of the machine-learning classifier. The advantages of the proposed methods are demonstrated through extensive simulations and an application to object classification with the CIFAR-10H image data set.
MRI Field-transfer Reconstruction with Limited Data: Regularization by Neural Style Transfer
Aug 21, 2023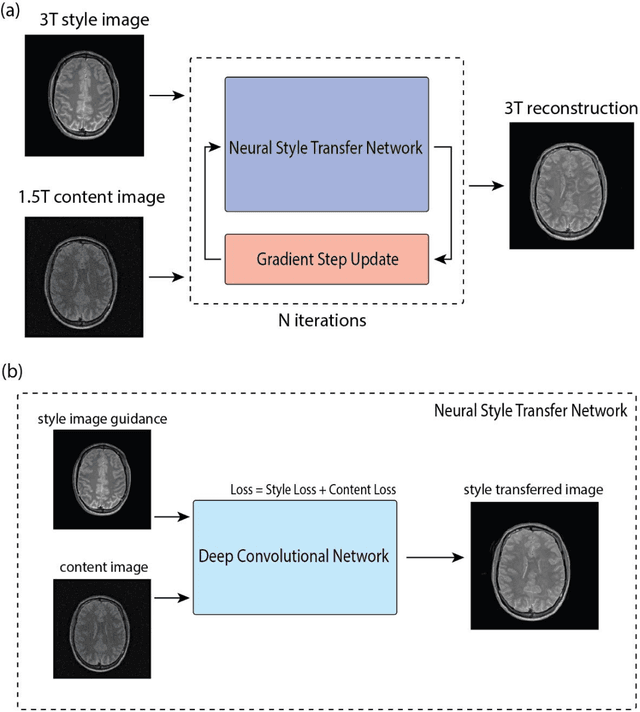
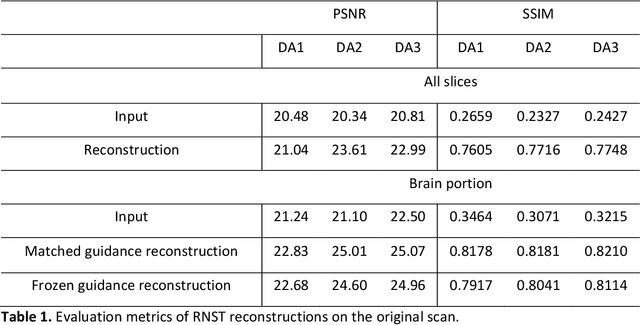
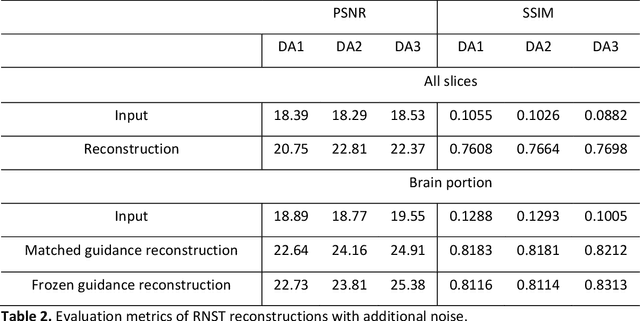
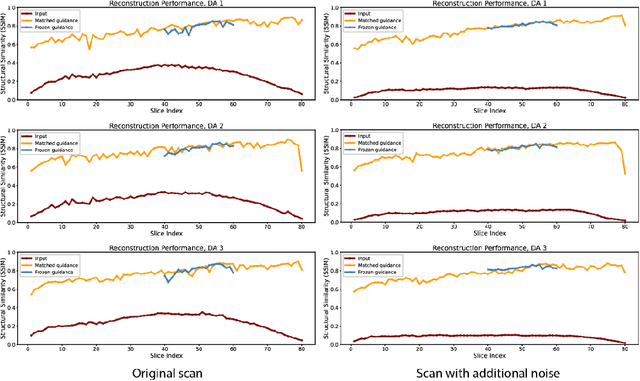
Recent works have demonstrated success in MRI reconstruction using deep learning-based models. However, most reported approaches require training on a task-specific, large-scale dataset. Regularization by denoising (RED) is a general pipeline which embeds a denoiser as a prior for image reconstruction. The potential of RED has been demonstrated for multiple image-related tasks such as denoising, deblurring and super-resolution. In this work, we propose a regularization by neural style transfer (RNST) method to further leverage the priors from the neural transfer and denoising engine. This enables RNST to reconstruct a high-quality image from a noisy low-quality image with different image styles and limited data. We validate RNST with clinical MRI scans from 1.5T and 3T and show that RNST can significantly boost image quality. Our results highlight the capability of the RNST framework for MRI reconstruction and the potential for reconstruction tasks with limited data.