 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
M3Dsynth: A dataset of medical 3D images with AI-generated local manipulations
Sep 14, 2023
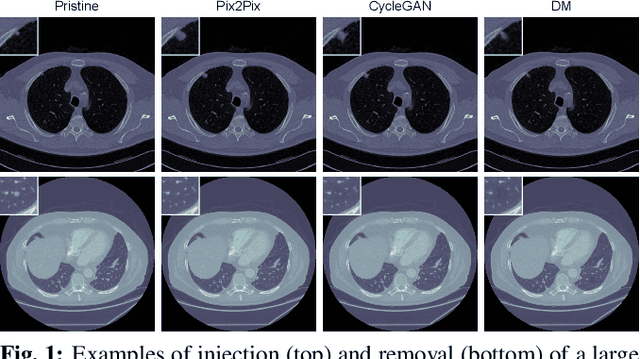
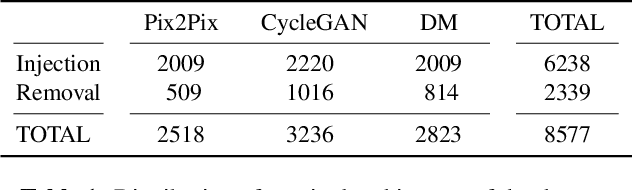
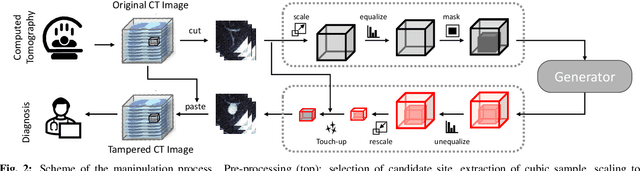
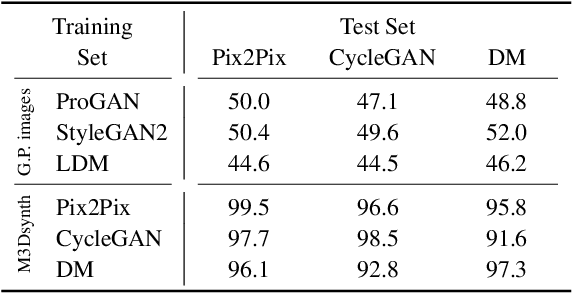
The ability to detect manipulated visual content is becoming increasingly important in many application fields, given the rapid advances in image synthesis methods. Of particular concern is the possibility of modifying the content of medical images, altering the resulting diagnoses. Despite its relevance, this issue has received limited attention from the research community. One reason is the lack of large and curated datasets to use for development and benchmarking purposes. Here, we investigate this issue and propose M3Dsynth, a large dataset of manipulated Computed Tomography (CT) lung images. We create manipulated images by injecting or removing lung cancer nodules in real CT scans, using three different methods based on Generative Adversarial Networks (GAN) or Diffusion Models (DM), for a total of 8,577 manipulated samples. Experiments show that these images easily fool automated diagnostic tools. We also tested several state-of-the-art forensic detectors and demonstrated that, once trained on the proposed dataset, they are able to accurately detect and localize manipulated synthetic content, including when training and test sets are not aligned, showing good generalization ability. Dataset and code will be publicly available at https://grip-unina.github.io/M3Dsynth/.
Padding Aware Neurons
Sep 14, 2023
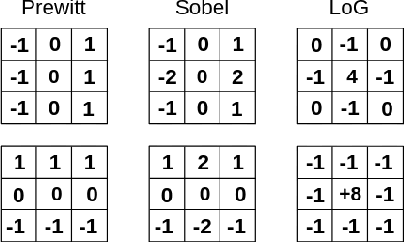

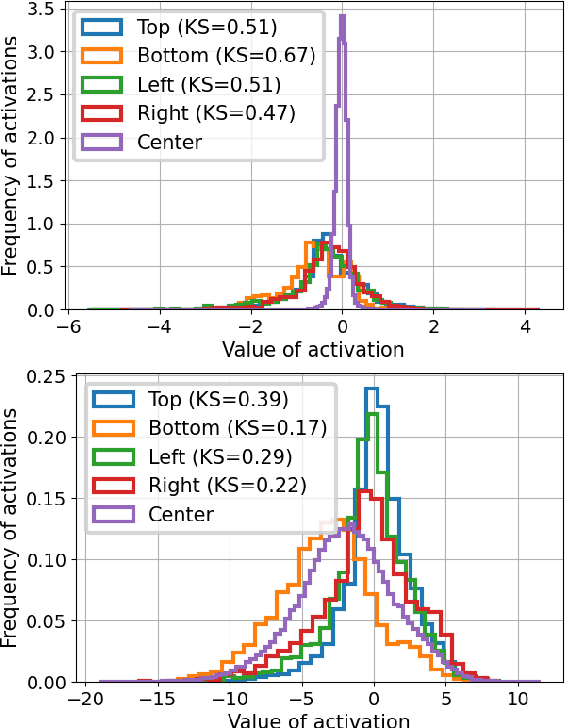
Convolutional layers are a fundamental component of most image-related models. These layers often implement by default a static padding policy (\eg zero padding), to control the scale of the internal representations, and to allow kernel activations centered on the border regions. In this work we identify Padding Aware Neurons (PANs), a type of filter that is found in most (if not all) convolutional models trained with static padding. PANs focus on the characterization and recognition of input border location, introducing a spatial inductive bias into the model (e.g., how close to the input's border a pattern typically is). We propose a method to identify PANs through their activations, and explore their presence in several popular pre-trained models, finding PANs on all models explored, from dozens to hundreds. We discuss and illustrate different types of PANs, their kernels and behaviour. To understand their relevance, we test their impact on model performance, and find padding and PANs to induce strong and characteristic biases in the data. Finally, we discuss whether or not PANs are desirable, as well as the potential side effects of their presence in the context of model performance, generalisation, efficiency and safety.
Ethnicity and Biometric Uniqueness: Iris Pattern Individuality in a West African Database
Sep 12, 2023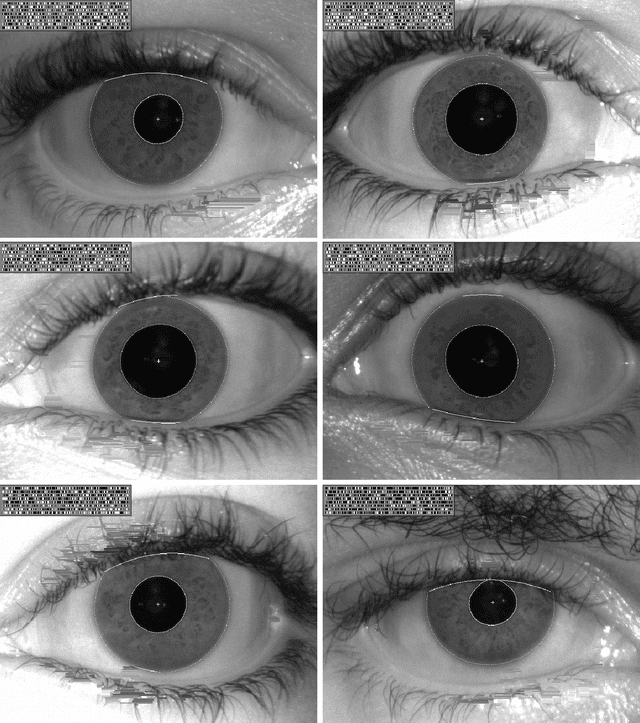
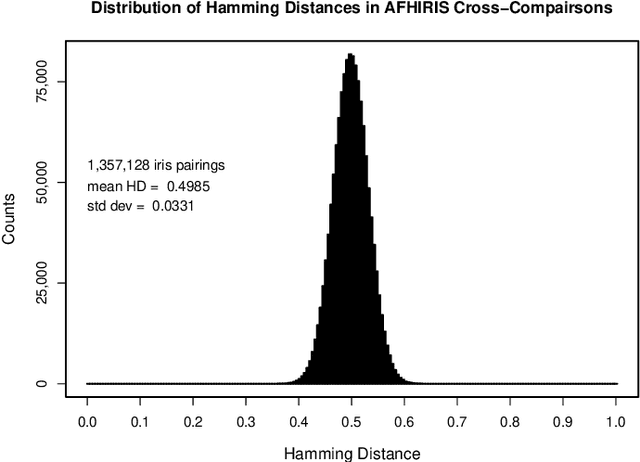
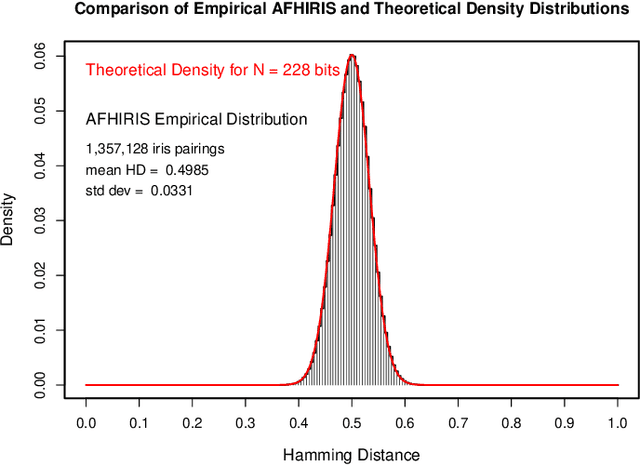
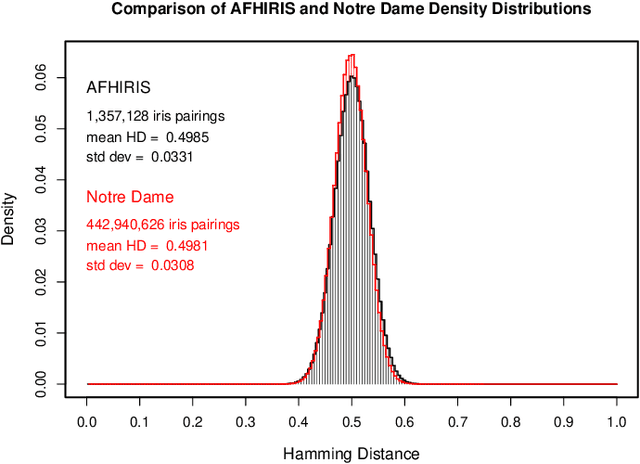
We conducted more than 1.3 million comparisons of iris patterns encoded from images collected at two Nigerian universities, which constitute the newly available African Human Iris (AFHIRIS) database. The purpose was to discover whether ethnic differences in iris structure and appearance such as the textural feature size, as contrasted with an all-Chinese image database or an American database in which only 1.53% were of African-American heritage, made a material difference for iris discrimination. We measured a reduction in entropy for the AFHIRIS database due to the coarser iris features created by the thick anterior layer of melanocytes, and we found stochastic parameters that accurately model the relevant empirical distributions. Quantile-Quantile analysis revealed that a very small change in operational decision thresholds for the African database would compensate for the reduced entropy and generate the same performance in terms of resistance to False Matches. We conclude that despite demographic difference, individuality can be robustly discerned by comparison of iris patterns in this West African population.
ATTA: Anomaly-aware Test-Time Adaptation for Out-of-Distribution Detection in Segmentation
Sep 12, 2023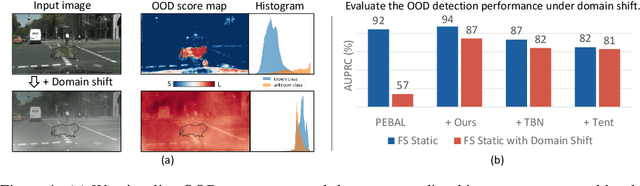

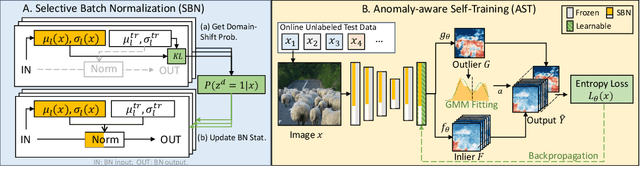
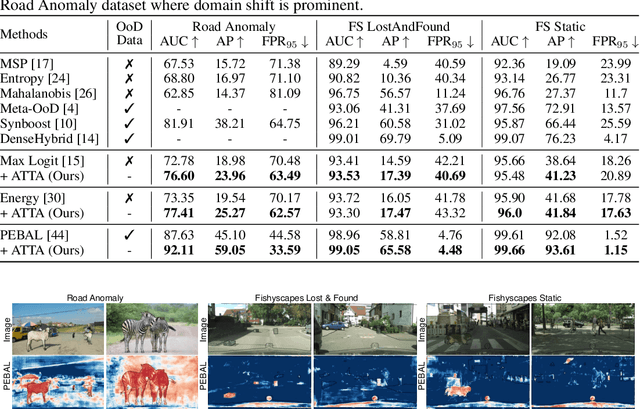
Recent advancements in dense out-of-distribution (OOD) detection have primarily focused on scenarios where the training and testing datasets share a similar domain, with the assumption that no domain shift exists between them. However, in real-world situations, domain shift often exits and significantly affects the accuracy of existing out-of-distribution (OOD) detection models. In this work, we propose a dual-level OOD detection framework to handle domain shift and semantic shift jointly. The first level distinguishes whether domain shift exists in the image by leveraging global low-level features, while the second level identifies pixels with semantic shift by utilizing dense high-level feature maps. In this way, we can selectively adapt the model to unseen domains as well as enhance model's capacity in detecting novel classes. We validate the efficacy of our proposed method on several OOD segmentation benchmarks, including those with significant domain shifts and those without, observing consistent performance improvements across various baseline models.
Towards a Holodeck-style Simulation Game
Sep 12, 2023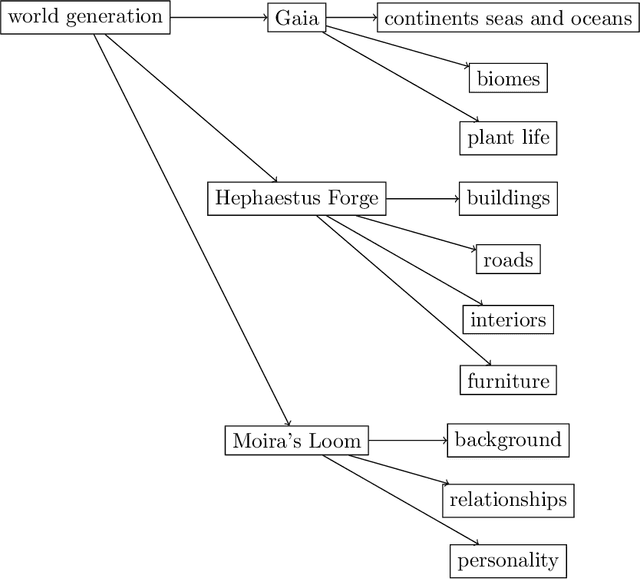
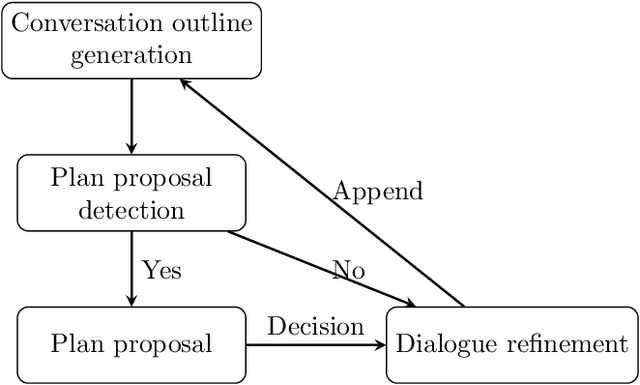


We introduce Infinitia, a simulation game system that uses generative image and language models at play time to reshape all aspects of the setting and NPCs based on a short description from the player, in a way similar to how settings are created on the fictional Holodeck. Building off the ideas of the Generative Agents paper, our system introduces gameplay elements, such as infinite generated fantasy worlds, controllability of NPC behavior, humorous dialogue, cost & time efficiency, collaboration between players and elements of non-determinism among in-game events. Infinitia is implemented in the Unity engine with a server-client architecture, facilitating the addition of exciting features by community developers in the future. Furthermore, it uses a multiplayer framework to allow humans to be present and interact in the simulation. The simulation will be available in open-alpha shortly at https://infinitia.ai/ and we are looking forward to building upon it with the community.
Efficient Pyramid Channel Attention Network for Pathological Myopia Detection
Sep 17, 2023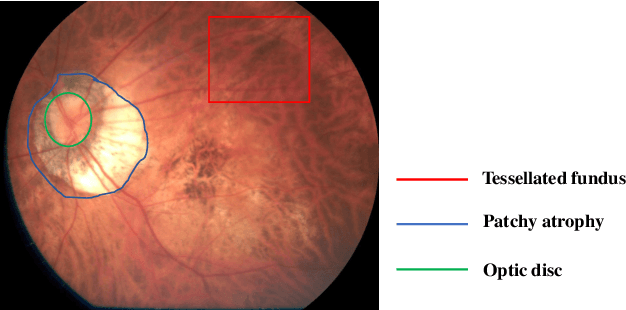
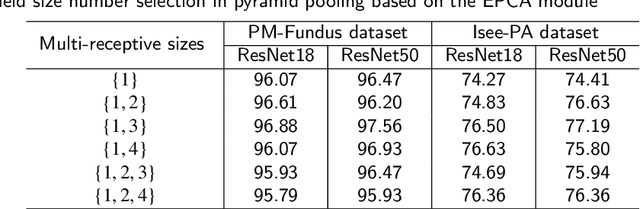
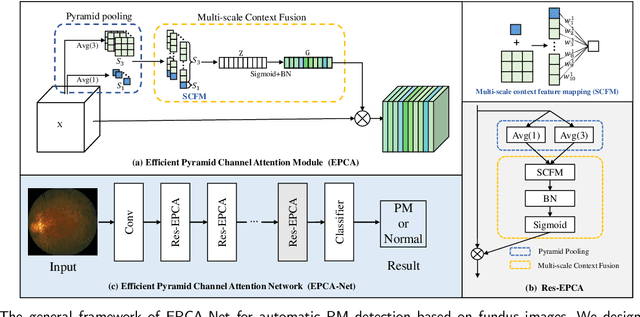
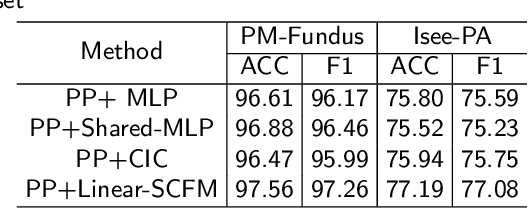
Pathological myopia (PM) is the leading ocular disease for impaired vision and blindness worldwide. The key to detecting PM as early as possible is to detect informative features in global and local lesion regions, such as fundus tessellation, atrophy and maculopathy. However, applying classical convolutional neural networks (CNNs) to efficiently highlight global and local lesion context information in feature maps is quite challenging. To tackle this issue, we aim to fully leverage the potential of global and local lesion information with attention module design. Based on this, we propose an efficient pyramid channel attention (EPCA) module, which dynamically explores the relative importance of global and local lesion context information in feature maps. Then we combine the EPCA module with the backbone network to construct EPCA-Net for automatic PM detection based on fundus images. In addition, we construct a PM dataset termed PM-fundus by collecting fundus images of PM from publicly available datasets (e.g., the PALM dataset and ODIR dataset). The comprehensive experiments are conducted on three datasets, demonstrating that our EPCA-Net outperforms state-of-the-art methods in detecting PM. Furthermore, motivated by the recent pretraining-and-finetuning paradigm, we attempt to adapt pre-trained natural image models for PM detection by freezing them and treating the EPCA module and other attention modules as the adapters. The results show that our method with the pretraining-and-finetuning paradigm achieves competitive performance through comparisons to part of methods with traditional fine-tuning methods with fewer tunable parameters.
Tree-Structured Shading Decomposition
Sep 13, 2023We study inferring a tree-structured representation from a single image for object shading. Prior work typically uses the parametric or measured representation to model shading, which is neither interpretable nor easily editable. We propose using the shade tree representation, which combines basic shading nodes and compositing methods to factorize object surface shading. The shade tree representation enables novice users who are unfamiliar with the physical shading process to edit object shading in an efficient and intuitive manner. A main challenge in inferring the shade tree is that the inference problem involves both the discrete tree structure and the continuous parameters of the tree nodes. We propose a hybrid approach to address this issue. We introduce an auto-regressive inference model to generate a rough estimation of the tree structure and node parameters, and then we fine-tune the inferred shade tree through an optimization algorithm. We show experiments on synthetic images, captured reflectance, real images, and non-realistic vector drawings, allowing downstream applications such as material editing, vectorized shading, and relighting. Project website: https://chen-geng.com/inv-shade-trees
Robot Structure Prior Guided Temporal Attention for Camera-to-Robot Pose Estimation from Image Sequence
Jul 22, 2023
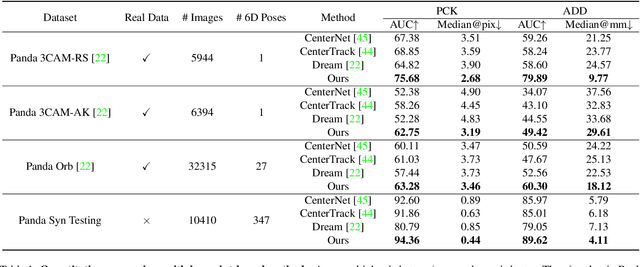
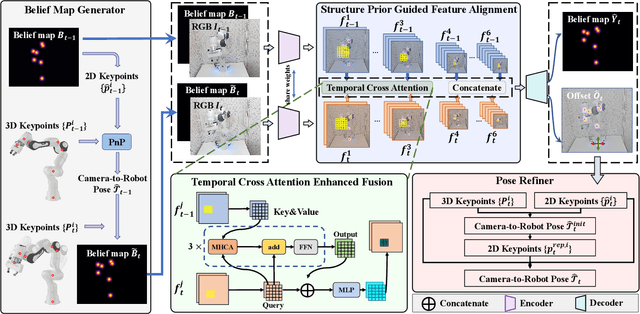
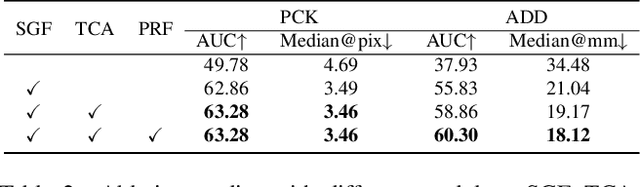
In this work, we tackle the problem of online camera-to-robot pose estimation from single-view successive frames of an image sequence, a crucial task for robots to interact with the world.
Constrained CycleGAN for Effective Generation of Ultrasound Sector Images of Improved Spatial Resolution
Sep 02, 2023Objective. A phased or a curvilinear array produces ultrasound (US) images with a sector field of view (FOV), which inherently exhibits spatially-varying image resolution with inferior quality in the far zone and towards the two sides azimuthally. Sector US images with improved spatial resolutions are favorable for accurate quantitative analysis of large and dynamic organs, such as the heart. Therefore, this study aims to translate US images with spatially-varying resolution to ones with less spatially-varying resolution. CycleGAN has been a prominent choice for unpaired medical image translation; however, it neither guarantees structural consistency nor preserves backscattering patterns between input and generated images for unpaired US images. Approach. To circumvent this limitation, we propose a constrained CycleGAN (CCycleGAN), which directly performs US image generation with unpaired images acquired by different ultrasound array probes. In addition to conventional adversarial and cycle-consistency losses of CycleGAN, CCycleGAN introduces an identical loss and a correlation coefficient loss based on intrinsic US backscattered signal properties to constrain structural consistency and backscattering patterns, respectively. Instead of post-processed B-mode images, CCycleGAN uses envelope data directly obtained from beamformed radio-frequency signals without any other non-linear postprocessing. Main Results. In vitro phantom results demonstrate that CCycleGAN successfully generates images with improved spatial resolution as well as higher peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) compared with benchmarks. Significance. CCycleGAN-generated US images of the in vivo human beating heart further facilitate higher quality heart wall motion estimation than benchmarks-generated ones, particularly in deep regions.
Adversarial Attacks on Image Classification Models: FGSM and Patch Attacks and their Impact
Jul 05, 2023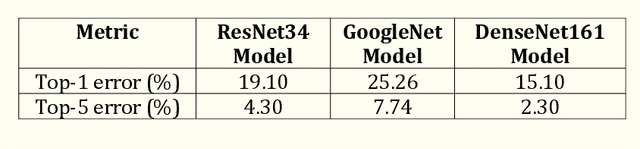

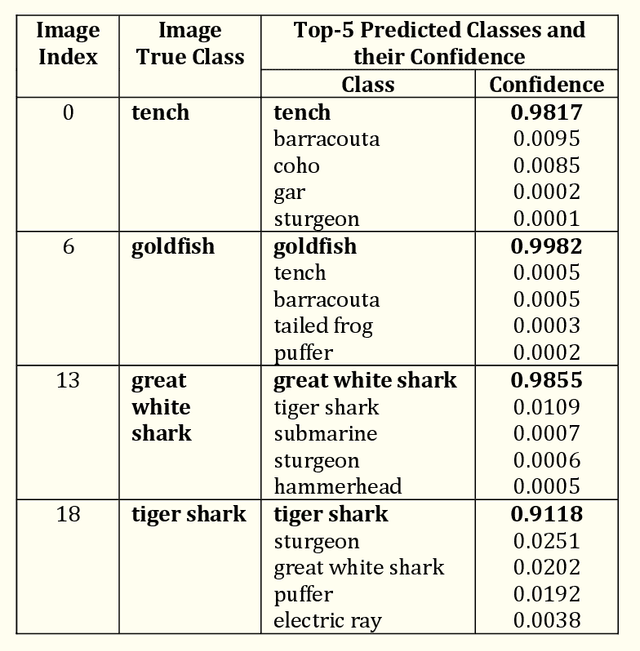
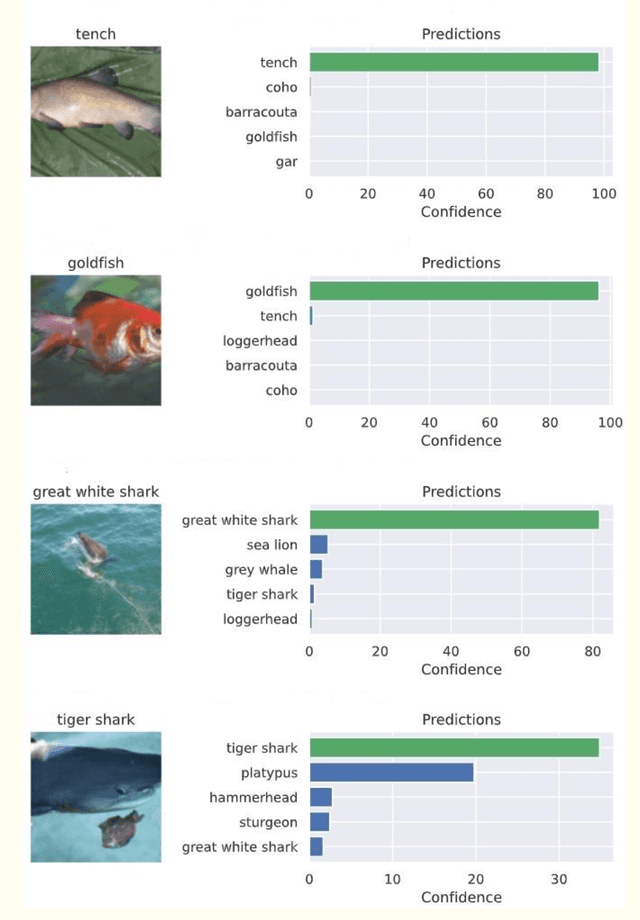
This chapter introduces the concept of adversarial attacks on image classification models built on convolutional neural networks (CNN). CNNs are very popular deep-learning models which are used in image classification tasks. However, very powerful and pre-trained CNN models working very accurately on image datasets for image classification tasks may perform disastrously when the networks are under adversarial attacks. In this work, two very well-known adversarial attacks are discussed and their impact on the performance of image classifiers is analyzed. These two adversarial attacks are the fast gradient sign method (FGSM) and adversarial patch attack. These attacks are launched on three powerful pre-trained image classifier architectures, ResNet-34, GoogleNet, and DenseNet-161. The classification accuracy of the models in the absence and presence of the two attacks are computed on images from the publicly accessible ImageNet dataset. The results are analyzed to evaluate the impact of the attacks on the image classification task.