 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OmniLRS: A Photorealistic Simulator for Lunar Robotics
Sep 16, 2023



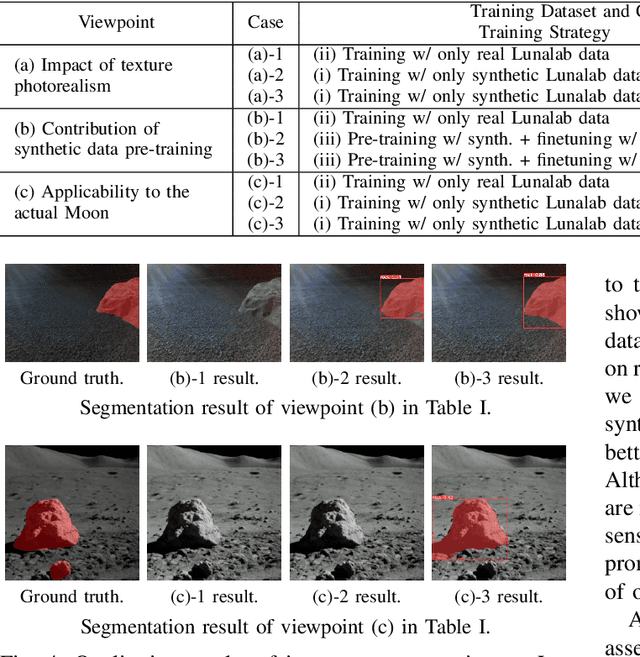
Developing algorithms for extra-terrestrial robotic exploration has always been challenging. Along with the complexity associated with these environments, one of the main issues remains the evaluation of said algorithms. With the regained interest in lunar exploration, there is also a demand for quality simulators that will enable the development of lunar robots. % In this paper, we explain how we built a Lunar simulator based on Isaac Sim, Nvidia's robotic simulator. In this paper, we propose Omniverse Lunar Robotic-Sim (OmniLRS) that is a photorealistic Lunar simulator based on Nvidia's robotic simulator. This simulation provides fast procedural environment generation, multi-robot capabilities, along with synthetic data pipeline for machine-learning applications. It comes with ROS1 and ROS2 bindings to control not only the robots, but also the environments. This work also performs sim-to-real rock instance segmentation to show the effectiveness of our simulator for image-based perception. Trained on our synthetic data, a yolov8 model achieves performance close to a model trained on real-world data, with 5% performance gap. When finetuned with real data, the model achieves 14% higher average precision than the model trained on real-world data, demonstrating our simulator's photorealism.% to realize sim-to-real. The code is fully open-source, accessible here: https://github.com/AntoineRichard/LunarSim, and comes with demonstrations.
PHE-SICH-CT-IDS: A Benchmark CT Image Dataset for Evaluation Semantic Segmentation, Object Detection and Radiomic Feature Extraction of Perihematomal Edema in Spontaneous Intracerebral Hemorrhage
Aug 21, 2023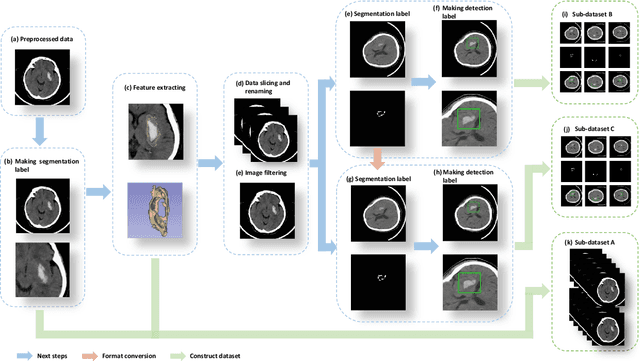
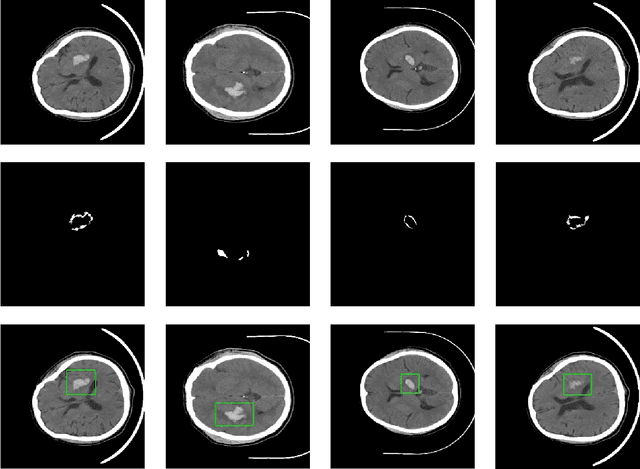
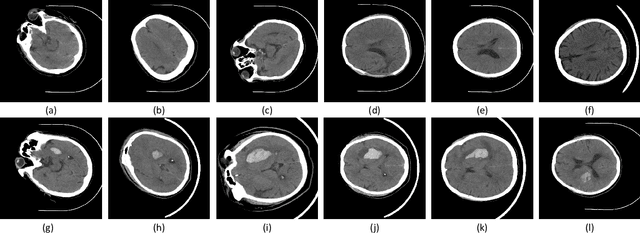
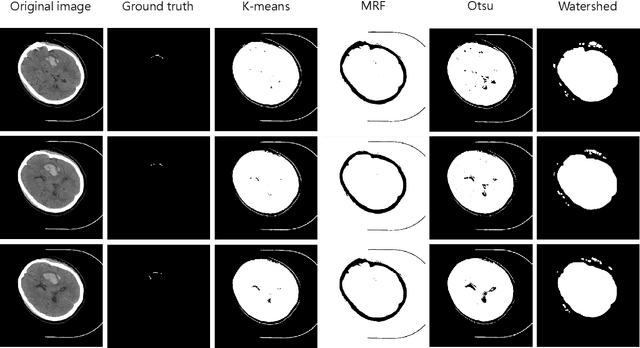
Intracerebral hemorrhage is one of the diseases with the highest mortality and poorest prognosis worldwide. Spontaneous intracerebral hemorrhage (SICH) typically presents acutely, prompt and expedited radiological examination is crucial for diagnosis, localization, and quantification of the hemorrhage. Early detection and accurate segmentation of perihematomal edema (PHE) play a critical role in guiding appropriate clinical intervention and enhancing patient prognosis. However, the progress and assessment of computer-aided diagnostic methods for PHE segmentation and detection face challenges due to the scarcity of publicly accessible brain CT image datasets. This study establishes a publicly available CT dataset named PHE-SICH-CT-IDS for perihematomal edema in spontaneous intracerebral hemorrhage. The dataset comprises 120 brain CT scans and 7,022 CT images, along with corresponding medical information of the patients. To demonstrate its effectiveness, classical algorithms for semantic segmentation, object detection, and radiomic feature extraction are evaluated. The experimental results confirm the suitability of PHE-SICH-CT-IDS for assessing the performance of segmentation, detection and radiomic feature extraction methods. To the best of our knowledge, this is the first publicly available dataset for PHE in SICH, comprising various data formats suitable for applications across diverse medical scenarios. We believe that PHE-SICH-CT-IDS will allure researchers to explore novel algorithms, providing valuable support for clinicians and patients in the clinical setting. PHE-SICH-CT-IDS is freely published for non-commercial purpose at: https://figshare.com/articles/dataset/PHE-SICH-CT-IDS/23957937.
Dynamic Spectrum Mixer for Visual Recognition
Sep 15, 2023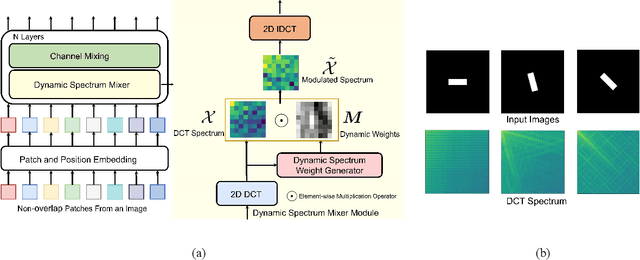
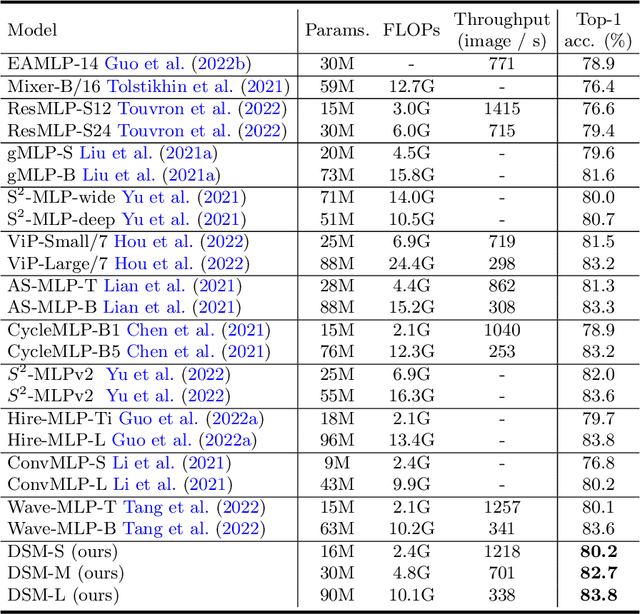
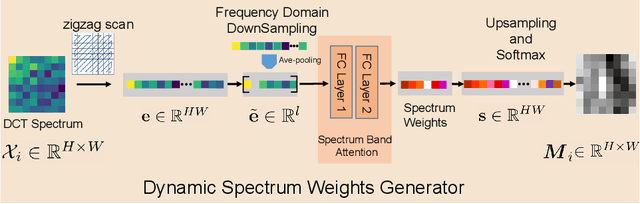
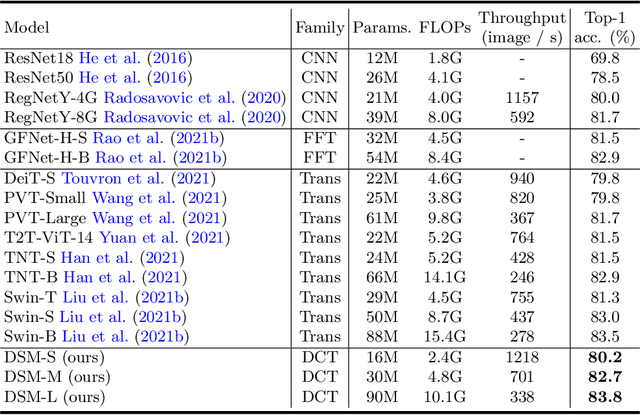
Recently, MLP-based vision backbones have achieved promising performance in several visual recognition tasks. However, the existing MLP-based methods directly aggregate tokens with static weights, leaving the adaptability to different images untouched. Moreover, Recent research demonstrates that MLP-Transformer is great at creating long-range dependencies but ineffective at catching high frequencies that primarily transmit local information, which prevents it from applying to the downstream dense prediction tasks, such as semantic segmentation. To address these challenges, we propose a content-adaptive yet computationally efficient structure, dubbed Dynamic Spectrum Mixer (DSM). The DSM represents token interactions in the frequency domain by employing the Discrete Cosine Transform, which can learn long-term spatial dependencies with log-linear complexity. Furthermore, a dynamic spectrum weight generation layer is proposed as the spectrum bands selector, which could emphasize the informative frequency bands while diminishing others. To this end, the technique can efficiently learn detailed features from visual input that contains both high- and low-frequency information. Extensive experiments show that DSM is a powerful and adaptable backbone for a range of visual recognition tasks. Particularly, DSM outperforms previous transformer-based and MLP-based models, on image classification, object detection, and semantic segmentation tasks, such as 83.8 \% top-1 accuracy on ImageNet, and 49.9 \% mIoU on ADE20K.
3D Arterial Segmentation via Single 2D Projections and Depth Supervision in Contrast-Enhanced CT Images
Sep 15, 2023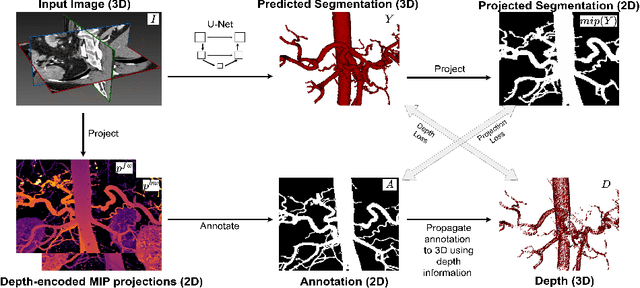
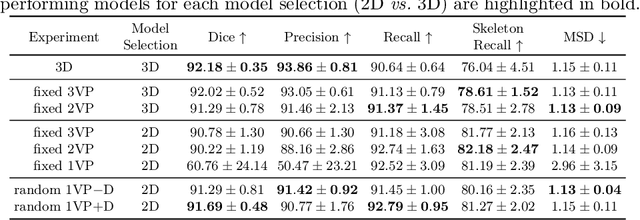
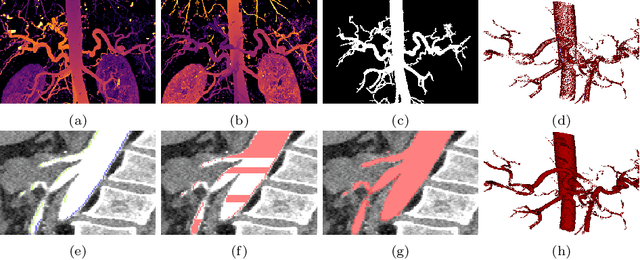
Automated segmentation of the blood vessels in 3D volumes is an essential step for the quantitative diagnosis and treatment of many vascular diseases. 3D vessel segmentation is being actively investigated in existing works, mostly in deep learning approaches. However, training 3D deep networks requires large amounts of manual 3D annotations from experts, which are laborious to obtain. This is especially the case for 3D vessel segmentation, as vessels are sparse yet spread out over many slices and disconnected when visualized in 2D slices. In this work, we propose a novel method to segment the 3D peripancreatic arteries solely from one annotated 2D projection per training image with depth supervision. We perform extensive experiments on the segmentation of peripancreatic arteries on 3D contrast-enhanced CT images and demonstrate how well we capture the rich depth information from 2D projections. We demonstrate that by annotating a single, randomly chosen projection for each training sample, we obtain comparable performance to annotating multiple 2D projections, thereby reducing the annotation effort. Furthermore, by mapping the 2D labels to the 3D space using depth information and incorporating this into training, we almost close the performance gap between 3D supervision and 2D supervision. Our code is available at: https://github.com/alinafdima/3Dseg-mip-depth.
Let's Roll: Synthetic Dataset Analysis for Pedestrian Detection Across Different Shutter Types
Sep 15, 2023Computer vision (CV) pipelines are typically evaluated on datasets processed by image signal processing (ISP) pipelines even though, for resource-constrained applications, an important research goal is to avoid as many ISP steps as possible. In particular, most CV datasets consist of global shutter (GS) images even though most cameras today use a rolling shutter (RS). This paper studies the impact of different shutter mechanisms on machine learning (ML) object detection models on a synthetic dataset that we generate using the advanced simulation capabilities of Unreal Engine 5 (UE5). In particular, we train and evaluate mainstream detection models with our synthetically-generated paired GS and RS datasets to ascertain whether there exists a significant difference in detection accuracy between these two shutter modalities, especially when capturing low-speed objects (e.g., pedestrians). The results of this emulation framework indicate the performance between them are remarkably congruent for coarse-grained detection (mean average precision (mAP) for IOU=0.5), but have significant differences for fine-grained measures of detection accuracy (mAP for IOU=0.5:0.95). This implies that ML pipelines might not need explicit correction for RS for many object detection applications, but mitigating RS effects in ISP-less ML pipelines that target fine-grained location of the objects may need additional research.
X-PDNet: Accurate Joint Plane Instance Segmentation and Monocular Depth Estimation with Cross-Task Distillation and Boundary Correction
Sep 15, 2023Segmentation of planar regions from a single RGB image is a particularly important task in the perception of complex scenes. To utilize both visual and geometric properties in images, recent approaches often formulate the problem as a joint estimation of planar instances and dense depth through feature fusion mechanisms and geometric constraint losses. Despite promising results, these methods do not consider cross-task feature distillation and perform poorly in boundary regions. To overcome these limitations, we propose X-PDNet, a framework for the multitask learning of plane instance segmentation and depth estimation with improvements in the following two aspects. Firstly, we construct the cross-task distillation design which promotes early information sharing between dual-tasks for specific task improvements. Secondly, we highlight the current limitations of using the ground truth boundary to develop boundary regression loss, and propose a novel method that exploits depth information to support precise boundary region segmentation. Finally, we manually annotate more than 3000 images from Stanford 2D-3D-Semantics dataset and make available for evaluation of plane instance segmentation. Through the experiments, our proposed methods prove the advantages, outperforming the baseline with large improvement margins in the quantitative results on the ScanNet and the Stanford 2D-3D-S dataset, demonstrating the effectiveness of our proposals.
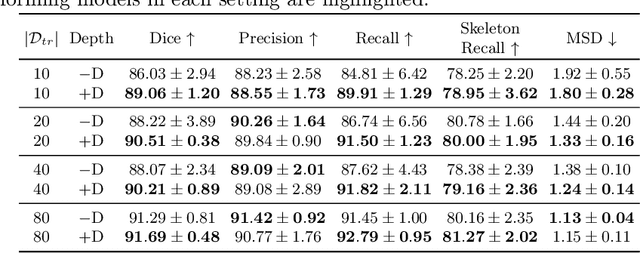
Robot Structure Prior Guided Temporal Attention for Camera-to-Robot Pose Estimation from Image Sequence
Jul 22, 2023
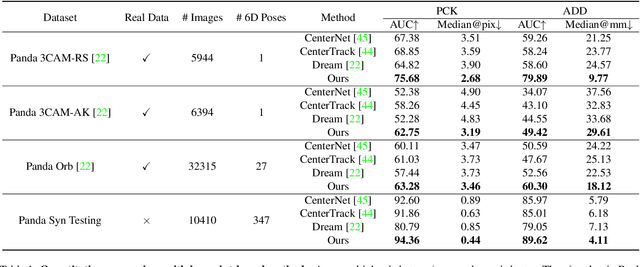
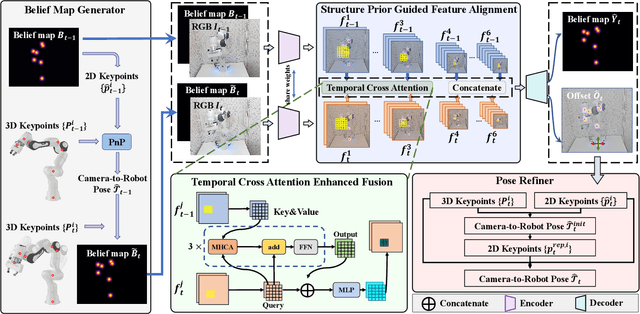
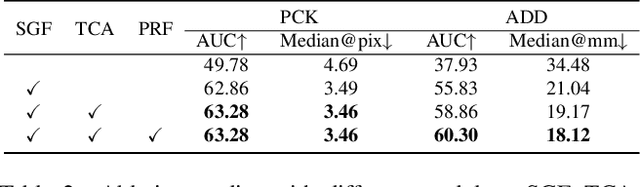
In this work, we tackle the problem of online camera-to-robot pose estimation from single-view successive frames of an image sequence, a crucial task for robots to interact with the world.
RecycleNet: Latent Feature Recycling Leads to Iterative Decision Refinement
Sep 14, 2023Despite the remarkable success of deep learning systems over the last decade, a key difference still remains between neural network and human decision-making: As humans, we cannot only form a decision on the spot, but also ponder, revisiting an initial guess from different angles, distilling relevant information, arriving at a better decision. Here, we propose RecycleNet, a latent feature recycling method, instilling the pondering capability for neural networks to refine initial decisions over a number of recycling steps, where outputs are fed back into earlier network layers in an iterative fashion. This approach makes minimal assumptions about the neural network architecture and thus can be implemented in a wide variety of contexts. Using medical image segmentation as the evaluation environment, we show that latent feature recycling enables the network to iteratively refine initial predictions even beyond the iterations seen during training, converging towards an improved decision. We evaluate this across a variety of segmentation benchmarks and show consistent improvements even compared with top-performing segmentation methods. This allows trading increased computation time for improved performance, which can be beneficial, especially for safety-critical applications.
Detecting Unknown Attacks in IoT Environments: An Open Set Classifier for Enhanced Network Intrusion Detection
Sep 14, 2023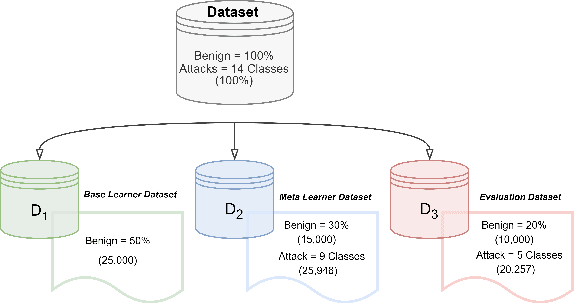
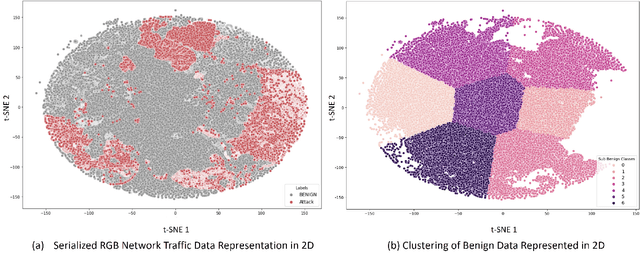
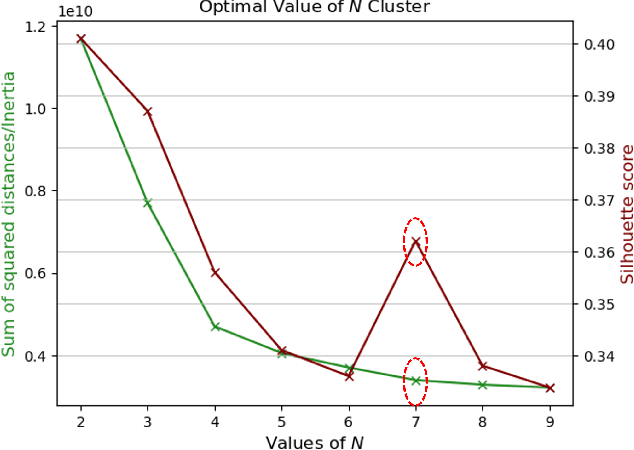
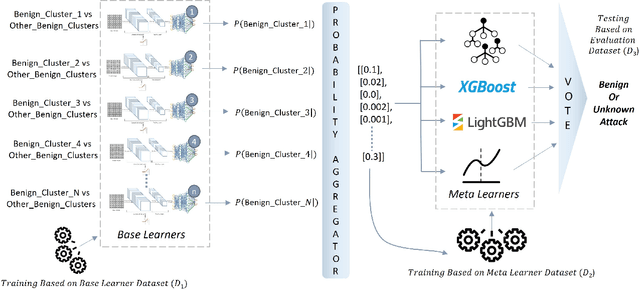
The widespread integration of Internet of Things (IoT) devices across all facets of life has ushered in an era of interconnectedness, creating new avenues for cybersecurity challenges and underscoring the need for robust intrusion detection systems. However, traditional security systems are designed with a closed-world perspective and often face challenges in dealing with the ever-evolving threat landscape, where new and unfamiliar attacks are constantly emerging. In this paper, we introduce a framework aimed at mitigating the open set recognition (OSR) problem in the realm of Network Intrusion Detection Systems (NIDS) tailored for IoT environments. Our framework capitalizes on image-based representations of packet-level data, extracting spatial and temporal patterns from network traffic. Additionally, we integrate stacking and sub-clustering techniques, enabling the identification of unknown attacks by effectively modeling the complex and diverse nature of benign behavior. The empirical results prominently underscore the framework's efficacy, boasting an impressive 88\% detection rate for previously unseen attacks when compared against existing approaches and recent advancements. Future work will perform extensive experimentation across various openness levels and attack scenarios, further strengthening the adaptability and performance of our proposed solution in safeguarding IoT environments.
Beta quantile regression for robust estimation of uncertainty in the presence of outliers
Sep 14, 2023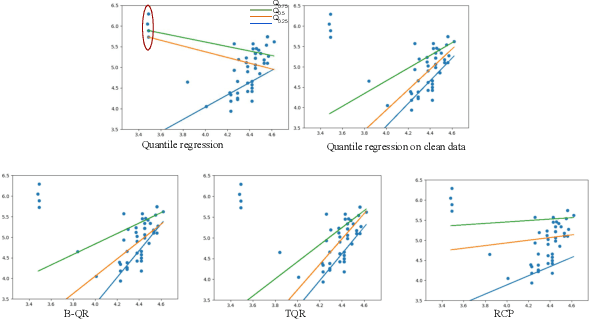
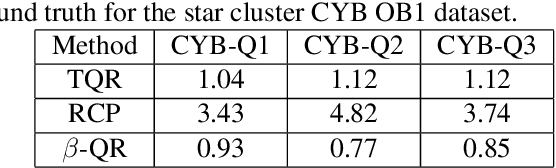
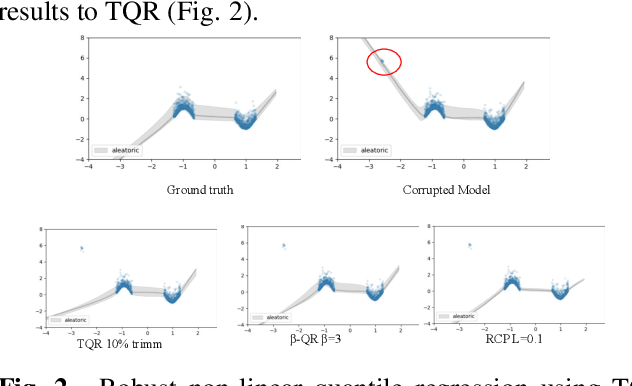
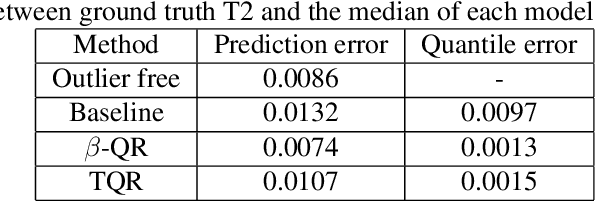
Quantile Regression (QR) can be used to estimate aleatoric uncertainty in deep neural networks and can generate prediction intervals. Quantifying uncertainty is particularly important in critical applications such as clinical diagnosis, where a realistic assessment of uncertainty is essential in determining disease status and planning the appropriate treatment. The most common application of quantile regression models is in cases where the parametric likelihood cannot be specified. Although quantile regression is quite robust to outlier response observations, it can be sensitive to outlier covariate observations (features). Outlier features can compromise the performance of deep learning regression problems such as style translation, image reconstruction, and deep anomaly detection, potentially leading to misleading conclusions. To address this problem, we propose a robust solution for quantile regression that incorporates concepts from robust divergence. We compare the performance of our proposed method with (i) least trimmed quantile regression and (ii) robust regression based on the regularization of case-specific parameters in a simple real dataset in the presence of outlier. These methods have not been applied in a deep learning framework. We also demonstrate the applicability of the proposed method by applying it to a medical imaging translation task using diffusion models.