 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Implicit Neural Feature Fusion Function for Multispectral and Hyperspectral Image Fusion
Jul 14, 2023
Multispectral and Hyperspectral Image Fusion (MHIF) is a practical task that aims to fuse a high-resolution multispectral image (HR-MSI) and a low-resolution hyperspectral image (LR-HSI) of the same scene to obtain a high-resolution hyperspectral image (HR-HSI). Benefiting from powerful inductive bias capability, CNN-based methods have achieved great success in the MHIF task. However, they lack certain interpretability and require convolution structures be stacked to enhance performance. Recently, Implicit Neural Representation (INR) has achieved good performance and interpretability in 2D tasks due to its ability to locally interpolate samples and utilize multimodal content such as pixels and coordinates. Although INR-based approaches show promise, they require extra construction of high-frequency information (\emph{e.g.,} positional encoding). In this paper, inspired by previous work of MHIF task, we realize that HR-MSI could serve as a high-frequency detail auxiliary input, leading us to propose a novel INR-based hyperspectral fusion function named Implicit Neural Feature Fusion Function (INF). As an elaborate structure, it solves the MHIF task and addresses deficiencies in the INR-based approaches. Specifically, our INF designs a Dual High-Frequency Fusion (DHFF) structure that obtains high-frequency information twice from HR-MSI and LR-HSI, then subtly fuses them with coordinate information. Moreover, the proposed INF incorporates a parameter-free method named INR with cosine similarity (INR-CS) that uses cosine similarity to generate local weights through feature vectors. Based on INF, we construct an Implicit Neural Fusion Network (INFN) that achieves state-of-the-art performance for MHIF tasks of two public datasets, \emph{i.e.,} CAVE and Harvard. The code will soon be made available on GitHub.
Feature Modulation Transformer: Cross-Refinement of Global Representation via High-Frequency Prior for Image Super-Resolution
Aug 09, 2023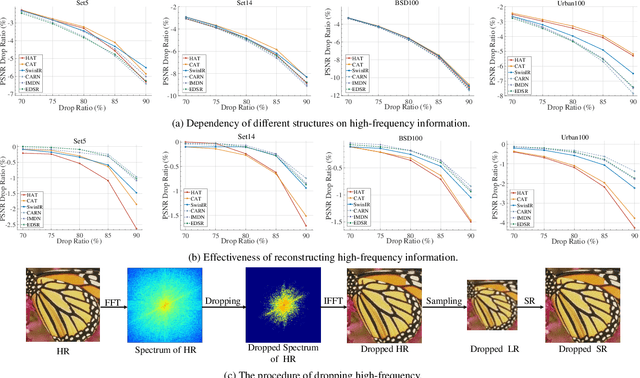
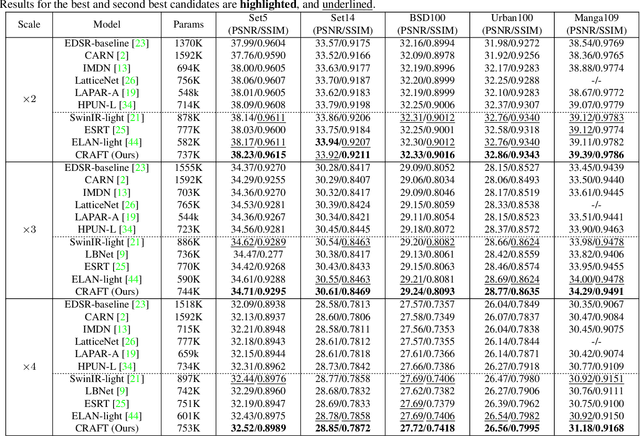
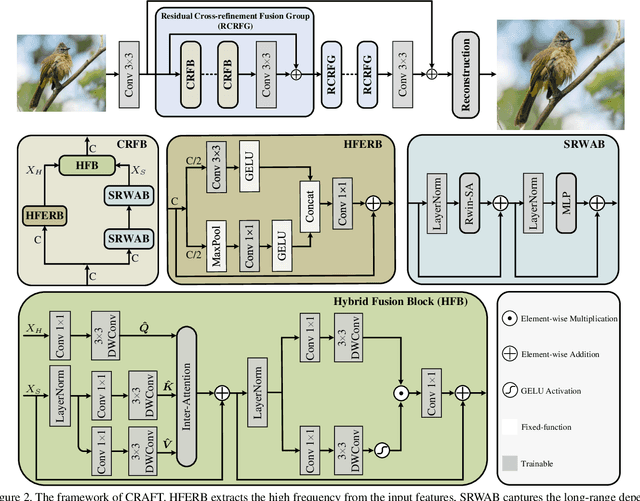
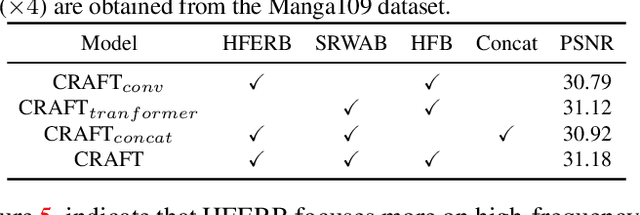
Transformer-based methods have exhibited remarkable potential in single image super-resolution (SISR) by effectively extracting long-range dependencies. However, most of the current research in this area has prioritized the design of transformer blocks to capture global information, while overlooking the importance of incorporating high-frequency priors, which we believe could be beneficial. In our study, we conducted a series of experiments and found that transformer structures are more adept at capturing low-frequency information, but have limited capacity in constructing high-frequency representations when compared to their convolutional counterparts. Our proposed solution, the cross-refinement adaptive feature modulation transformer (CRAFT), integrates the strengths of both convolutional and transformer structures. It comprises three key components: the high-frequency enhancement residual block (HFERB) for extracting high-frequency information, the shift rectangle window attention block (SRWAB) for capturing global information, and the hybrid fusion block (HFB) for refining the global representation. Our experiments on multiple datasets demonstrate that CRAFT outperforms state-of-the-art methods by up to 0.29dB while using fewer parameters. The source code will be made available at: https://github.com/AVC2-UESTC/CRAFT-SR.git.
Augmenting Chest X-ray Datasets with Non-Expert Annotations
Sep 05, 2023The advancement of machine learning algorithms in medical image analysis requires the expansion of training datasets. A popular and cost-effective approach is automated annotation extraction from free-text medical reports, primarily due to the high costs associated with expert clinicians annotating chest X-ray images. However, it has been shown that the resulting datasets are susceptible to biases and shortcuts. Another strategy to increase the size of a dataset is crowdsourcing, a widely adopted practice in general computer vision with some success in medical image analysis. In a similar vein to crowdsourcing, we enhance two publicly available chest X-ray datasets by incorporating non-expert annotations. However, instead of using diagnostic labels, we annotate shortcuts in the form of tubes. We collect 3.5k chest drain annotations for CXR14, and 1k annotations for 4 different tube types in PadChest. We train a chest drain detector with the non-expert annotations that generalizes well to expert labels. Moreover, we compare our annotations to those provided by experts and show "moderate" to "almost perfect" agreement. Finally, we present a pathology agreement study to raise awareness about ground truth annotations. We make our annotations and code available.
Towards Non-Parametric Models for Confidence Aware Image Prediction from Low Data using Gaussian Processes
Jul 20, 2023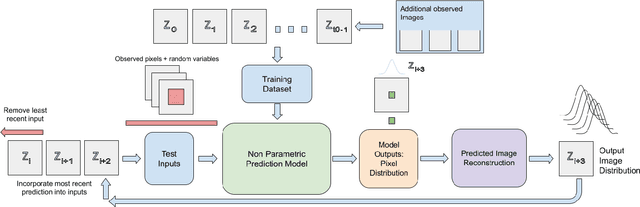
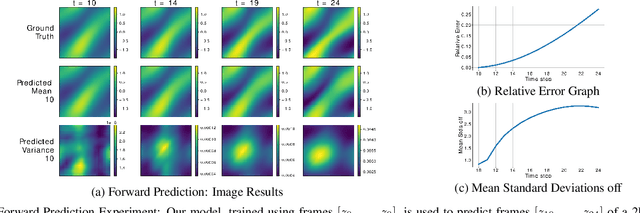

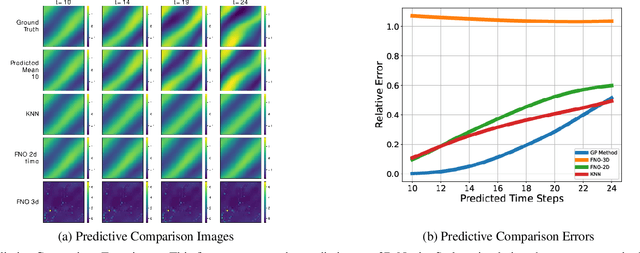
The ability to envision future states is crucial to informed decision making while interacting with dynamic environments. With cameras providing a prevalent and information rich sensing modality, the problem of predicting future states from image sequences has garnered a lot of attention. Current state of the art methods typically train large parametric models for their predictions. Though often able to predict with accuracy, these models rely on the availability of large training datasets to converge to useful solutions. In this paper we focus on the problem of predicting future images of an image sequence from very little training data. To approach this problem, we use non-parametric models to take a probabilistic approach to image prediction. We generate probability distributions over sequentially predicted images and propagate uncertainty through time to generate a confidence metric for our predictions. Gaussian Processes are used for their data efficiency and ability to readily incorporate new training data online. We showcase our method by successfully predicting future frames of a smooth fluid simulation environment.
Delving into Multimodal Prompting for Fine-grained Visual Classification
Sep 16, 2023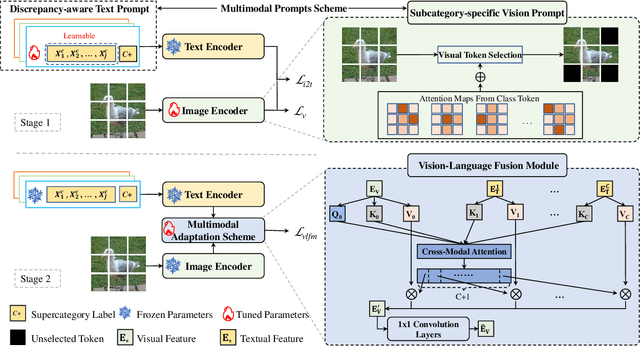
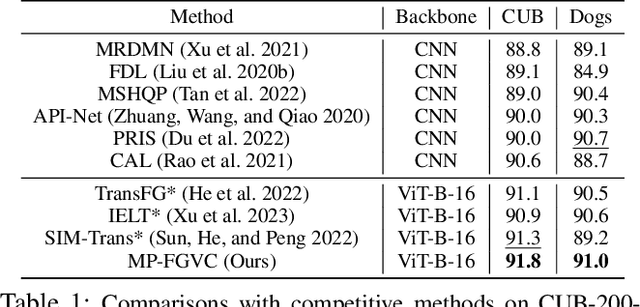
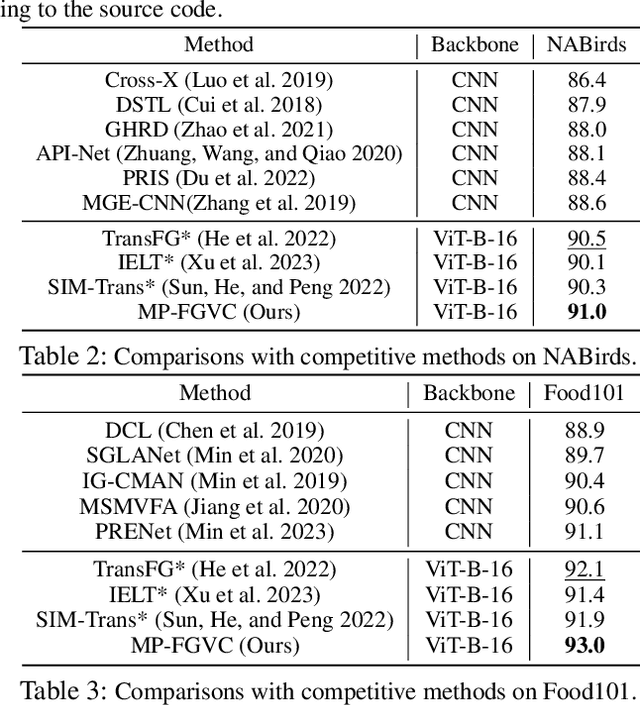
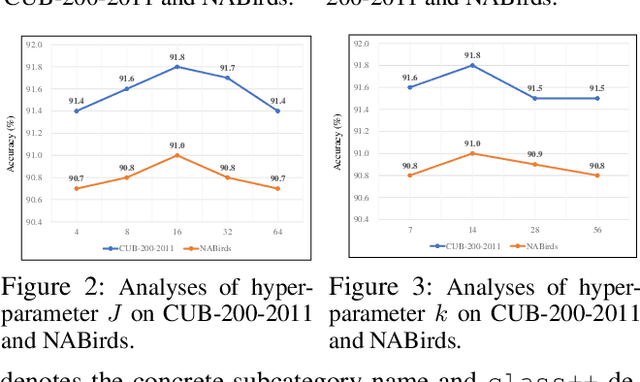
Fine-grained visual classification (FGVC) involves categorizing fine subdivisions within a broader category, which poses challenges due to subtle inter-class discrepancies and large intra-class variations. However, prevailing approaches primarily focus on uni-modal visual concepts. Recent advancements in pre-trained vision-language models have demonstrated remarkable performance in various high-level vision tasks, yet the applicability of such models to FGVC tasks remains uncertain. In this paper, we aim to fully exploit the capabilities of cross-modal description to tackle FGVC tasks and propose a novel multimodal prompting solution, denoted as MP-FGVC, based on the contrastive language-image pertaining (CLIP) model. Our MP-FGVC comprises a multimodal prompts scheme and a multimodal adaptation scheme. The former includes Subcategory-specific Vision Prompt (SsVP) and Discrepancy-aware Text Prompt (DaTP), which explicitly highlights the subcategory-specific discrepancies from the perspectives of both vision and language. The latter aligns the vision and text prompting elements in a common semantic space, facilitating cross-modal collaborative reasoning through a Vision-Language Fusion Module (VLFM) for further improvement on FGVC. Moreover, we tailor a two-stage optimization strategy for MP-FGVC to fully leverage the pre-trained CLIP model and expedite efficient adaptation for FGVC. Extensive experiments conducted on four FGVC datasets demonstrate the effectiveness of our MP-FGVC.
OmniLRS: A Photorealistic Simulator for Lunar Robotics
Sep 16, 2023


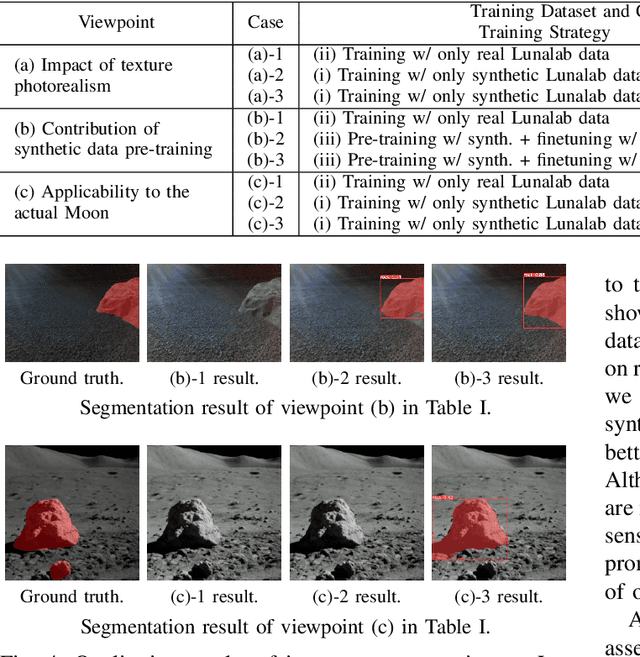
Developing algorithms for extra-terrestrial robotic exploration has always been challenging. Along with the complexity associated with these environments, one of the main issues remains the evaluation of said algorithms. With the regained interest in lunar exploration, there is also a demand for quality simulators that will enable the development of lunar robots. % In this paper, we explain how we built a Lunar simulator based on Isaac Sim, Nvidia's robotic simulator. In this paper, we propose Omniverse Lunar Robotic-Sim (OmniLRS) that is a photorealistic Lunar simulator based on Nvidia's robotic simulator. This simulation provides fast procedural environment generation, multi-robot capabilities, along with synthetic data pipeline for machine-learning applications. It comes with ROS1 and ROS2 bindings to control not only the robots, but also the environments. This work also performs sim-to-real rock instance segmentation to show the effectiveness of our simulator for image-based perception. Trained on our synthetic data, a yolov8 model achieves performance close to a model trained on real-world data, with 5% performance gap. When finetuned with real data, the model achieves 14% higher average precision than the model trained on real-world data, demonstrating our simulator's photorealism.% to realize sim-to-real. The code is fully open-source, accessible here: https://github.com/AntoineRichard/LunarSim, and comes with demonstrations.
Towards Robust Scene Text Image Super-resolution via Explicit Location Enhancement
Jul 19, 2023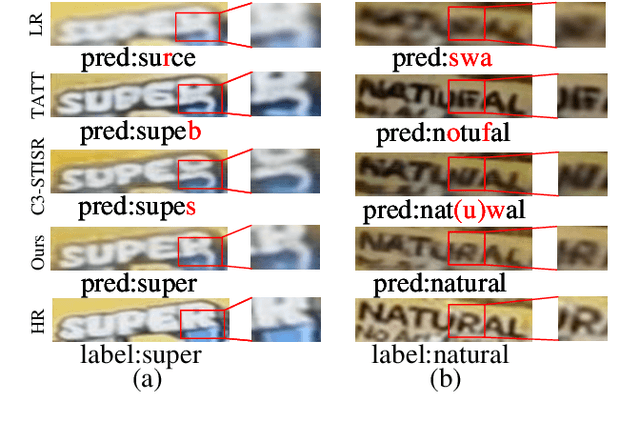

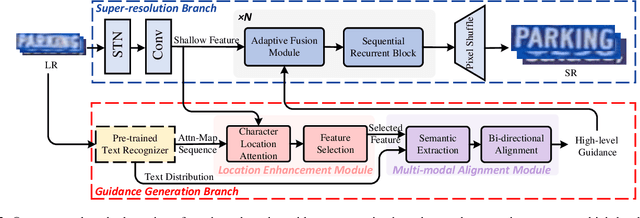

Scene text image super-resolution (STISR), aiming to improve image quality while boosting downstream scene text recognition accuracy, has recently achieved great success. However, most existing methods treat the foreground (character regions) and background (non-character regions) equally in the forward process, and neglect the disturbance from the complex background, thus limiting the performance. To address these issues, in this paper, we propose a novel method LEMMA that explicitly models character regions to produce high-level text-specific guidance for super-resolution. To model the location of characters effectively, we propose the location enhancement module to extract character region features based on the attention map sequence. Besides, we propose the multi-modal alignment module to perform bidirectional visual-semantic alignment to generate high-quality prior guidance, which is then incorporated into the super-resolution branch in an adaptive manner using the proposed adaptive fusion module. Experiments on TextZoom and four scene text recognition benchmarks demonstrate the superiority of our method over other state-of-the-art methods. Code is available at https://github.com/csguoh/LEMMA.
Frequency-mixed Single-source Domain Generalization for Medical Image Segmentation
Jul 18, 2023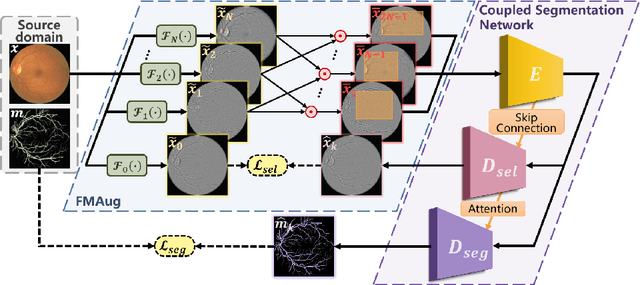
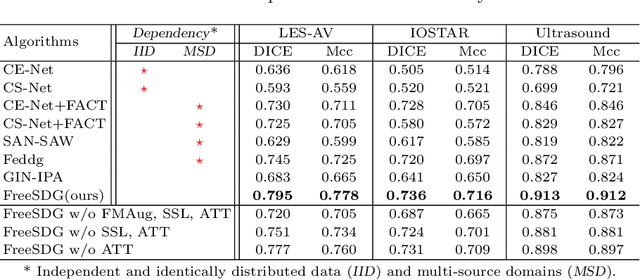
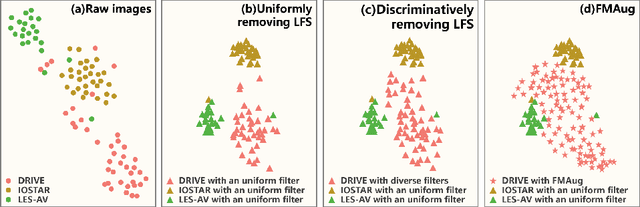
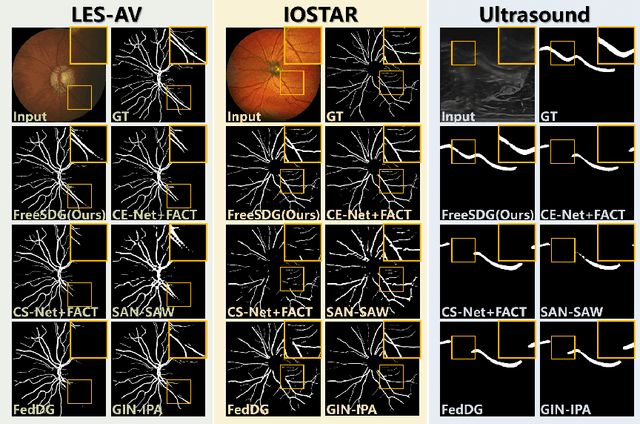
The annotation scarcity of medical image segmentation poses challenges in collecting sufficient training data for deep learning models. Specifically, models trained on limited data may not generalize well to other unseen data domains, resulting in a domain shift issue. Consequently, domain generalization (DG) is developed to boost the performance of segmentation models on unseen domains. However, the DG setup requires multiple source domains, which impedes the efficient deployment of segmentation algorithms in clinical scenarios. To address this challenge and improve the segmentation model's generalizability, we propose a novel approach called the Frequency-mixed Single-source Domain Generalization method (FreeSDG). By analyzing the frequency's effect on domain discrepancy, FreeSDG leverages a mixed frequency spectrum to augment the single-source domain. Additionally, self-supervision is constructed in the domain augmentation to learn robust context-aware representations for the segmentation task. Experimental results on five datasets of three modalities demonstrate the effectiveness of the proposed algorithm. FreeSDG outperforms state-of-the-art methods and significantly improves the segmentation model's generalizability. Therefore, FreeSDG provides a promising solution for enhancing the generalization of medical image segmentation models, especially when annotated data is scarce. The code is available at https://github.com/liamheng/Non-IID_Medical_Image_Segmentation.
Conditional 360-degree Image Synthesis for Immersive Indoor Scene Decoration
Jul 18, 2023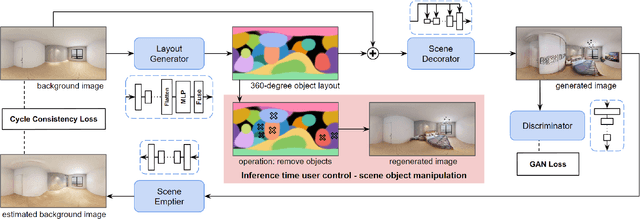
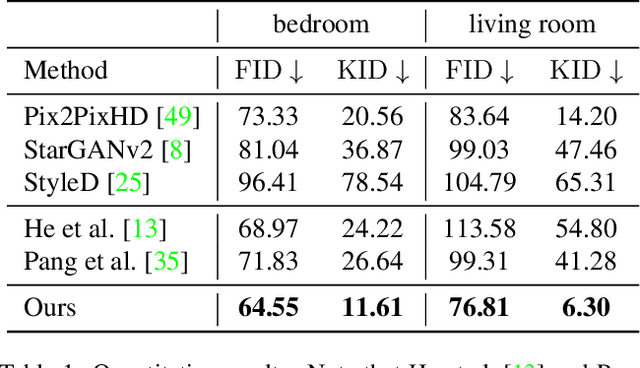
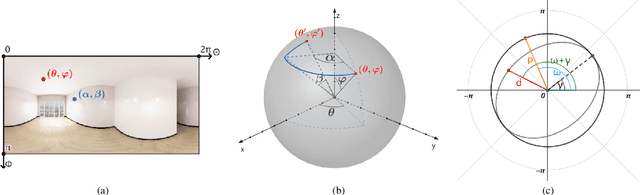
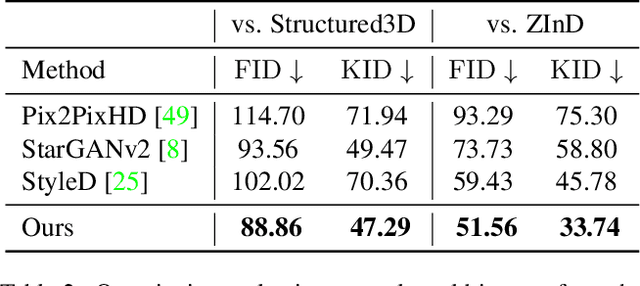
In this paper, we address the problem of conditional scene decoration for 360-degree images. Our method takes a 360-degree background photograph of an indoor scene and generates decorated images of the same scene in the panorama view. To do this, we develop a 360-aware object layout generator that learns latent object vectors in the 360-degree view to enable a variety of furniture arrangements for an input 360-degree background image. We use this object layout to condition a generative adversarial network to synthesize images of an input scene. To further reinforce the generation capability of our model, we develop a simple yet effective scene emptier that removes the generated furniture and produces an emptied scene for our model to learn a cyclic constraint. We train the model on the Structure3D dataset and show that our model can generate diverse decorations with controllable object layout. Our method achieves state-of-the-art performance on the Structure3D dataset and generalizes well to the Zillow indoor scene dataset. Our user study confirms the immersive experiences provided by the realistic image quality and furniture layout in our generation results. Our implementation will be made available.
Image-Processing Based Methods to Improve the Robustness of Robotic Gripping
Jul 11, 2023Image processing techniques have huge impact on most fields of robotics and industrial automation. Real time methods are usually employed in complex automation tasks, assisting with decision making or directly guiding robots and machinery, while post-processing is usually used for retrospective assessment of systems and processes. While artificial intelligence based image processing algorithms (usually neural networks) are more common nowadays, classical methods can also be used effectively even in modern applications. This paper focuses on optical flow based image processing, proving its efficiency by presenting optical flow based solutions for modern challenges in different fields of robotics such as robotic surgery and food industry automation. The main subject of the paper is a smart robotic gripper designed for automated robot cells in the meat industry, that is capable of slip detection and secure gripping of soft, slippery tissues with the help of the implemented optical flow based algorithm.