 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Causality-Based Feature Importance Quantifying Methods:PN-FI, PS-FI and PNS-FI
Aug 28, 2023
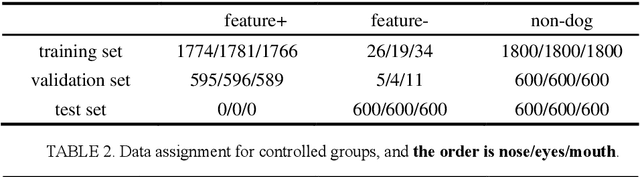
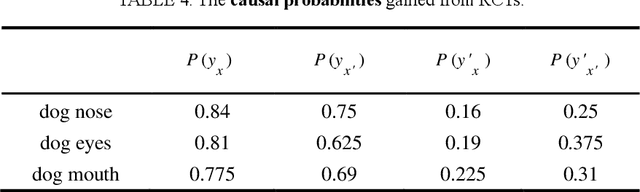
In current ML field models are getting larger and more complex, data we use are also getting larger in quantity and higher in dimension, so in order to train better models, save training time and computational resources, a good Feature Selection (FS) method in preprocessing stage is necessary. Feature importance (FI) is of great importance since it is the basis of feature selection. This paper creatively introduces the calculation of PNS(the probability of Necessity and Sufficiency) in Causality into quantifying feature importance and creates new FI measuring methods: PN-FI, which means how much importance a feature has in image recognition tasks, PS_FI that means how much importance a feature has in image generating tasks, and PNS_FI which measures both. The main body of this paper is three RCTs, with whose results we show how PS_FI, PN_FI and PNS_FI of three features: dog nose, dog eyes and dog mouth are calculated. The FI values are intervals with tight upper and lower bounds.
Video OWL-ViT: Temporally-consistent open-world localization in video
Aug 22, 2023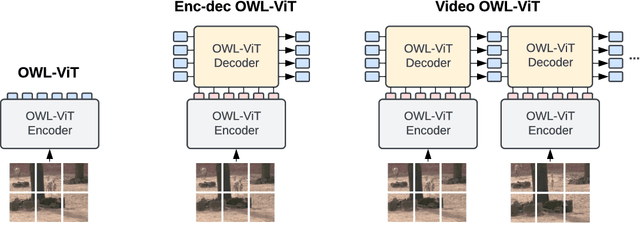
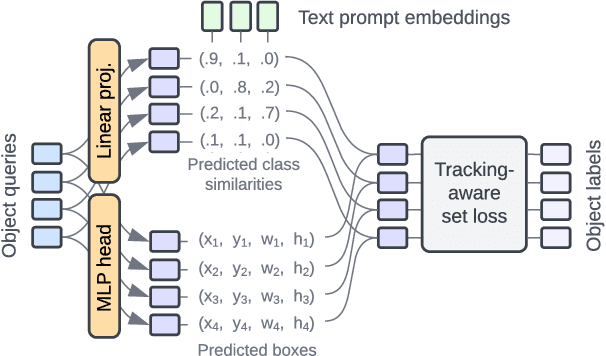
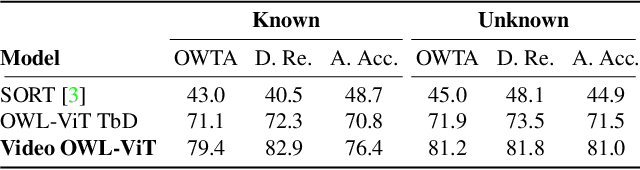

We present an architecture and a training recipe that adapts pre-trained open-world image models to localization in videos. Understanding the open visual world (without being constrained by fixed label spaces) is crucial for many real-world vision tasks. Contrastive pre-training on large image-text datasets has recently led to significant improvements for image-level tasks. For more structured tasks involving object localization applying pre-trained models is more challenging. This is particularly true for video tasks, where task-specific data is limited. We show successful transfer of open-world models by building on the OWL-ViT open-vocabulary detection model and adapting it to video by adding a transformer decoder. The decoder propagates object representations recurrently through time by using the output tokens for one frame as the object queries for the next. Our model is end-to-end trainable on video data and enjoys improved temporal consistency compared to tracking-by-detection baselines, while retaining the open-world capabilities of the backbone detector. We evaluate our model on the challenging TAO-OW benchmark and demonstrate that open-world capabilities, learned from large-scale image-text pre-training, can be transferred successfully to open-world localization across diverse videos.
Beyond Learned Metadata-based Raw Image Reconstruction
Jun 21, 2023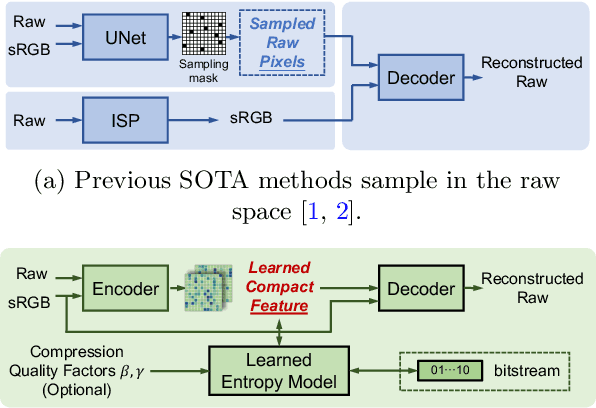
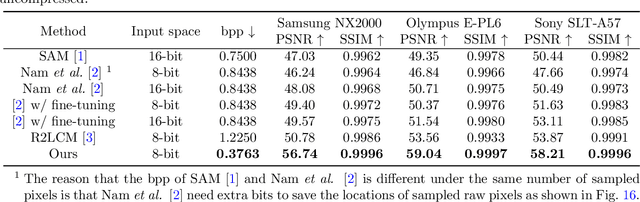
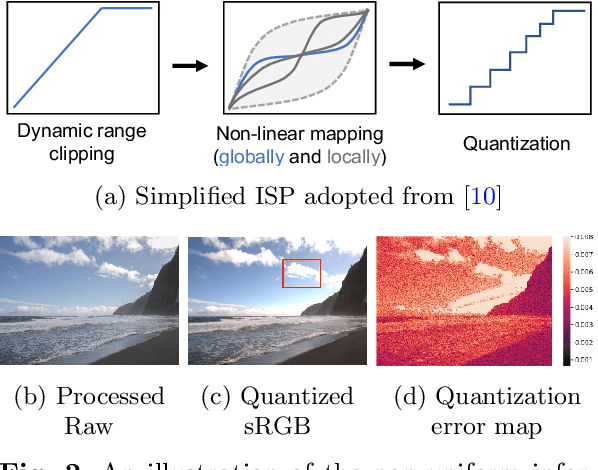
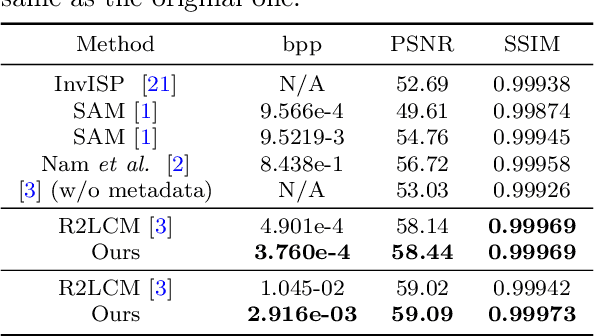
While raw images have distinct advantages over sRGB images, e.g., linearity and fine-grained quantization levels, they are not widely adopted by general users due to their substantial storage requirements. Very recent studies propose to compress raw images by designing sampling masks within the pixel space of the raw image. However, these approaches often leave space for pursuing more effective image representations and compact metadata. In this work, we propose a novel framework that learns a compact representation in the latent space, serving as metadata, in an end-to-end manner. Compared with lossy image compression, we analyze the intrinsic difference of the raw image reconstruction task caused by rich information from the sRGB image. Based on the analysis, a novel backbone design with asymmetric and hybrid spatial feature resolutions is proposed, which significantly improves the rate-distortion performance. Besides, we propose a novel design of the context model, which can better predict the order masks of encoding/decoding based on both the sRGB image and the masks of already processed features. Benefited from the better modeling of the correlation between order masks, the already processed information can be better utilized. Moreover, a novel sRGB-guided adaptive quantization precision strategy, which dynamically assigns varying levels of quantization precision to different regions, further enhances the representation ability of the model. Finally, based on the iterative properties of the proposed context model, we propose a novel strategy to achieve variable bit rates using a single model. This strategy allows for the continuous convergence of a wide range of bit rates. Extensive experimental results demonstrate that the proposed method can achieve better reconstruction quality with a smaller metadata size.
PoseSync: Robust pose based video synchronization
Aug 24, 2023Pose based video sychronization can have applications in multiple domains such as gameplay performance evaluation, choreography or guiding athletes. The subject's actions could be compared and evaluated against those performed by professionals side by side. In this paper, we propose an end to end pipeline for synchronizing videos based on pose. The first step crops the region where the person present in the image followed by pose detection on the cropped image. This is followed by application of Dynamic Time Warping(DTW) on angle/ distance measures between the pose keypoints leading to a scale and shift invariant pose matching pipeline.
Joint Hierarchical Priors and Adaptive Spatial Resolution for Efficient Neural Image Compression
Jul 12, 2023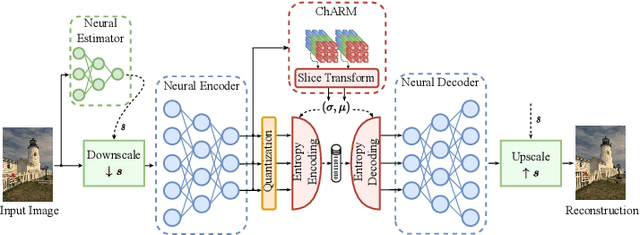
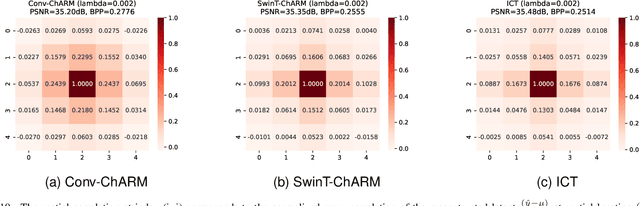

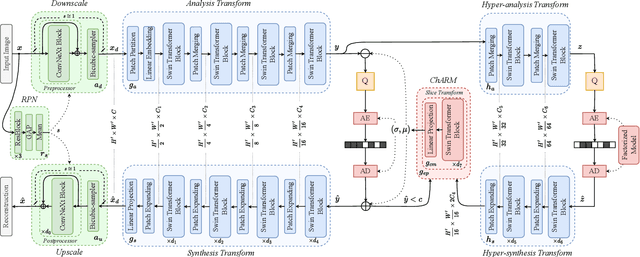
Recently, the performance of neural image compression (NIC) has steadily improved thanks to the last line of study, reaching or outperforming state-of-the-art conventional codecs. Despite significant progress, current NIC methods still rely on ConvNet-based entropy coding, limited in modeling long-range dependencies due to their local connectivity and the increasing number of architectural biases and priors, resulting in complex underperforming models with high decoding latency. Motivated by the efficiency investigation of the Tranformer-based transform coding framework, namely SwinT-ChARM, we propose to enhance the latter, as first, with a more straightforward yet effective Tranformer-based channel-wise auto-regressive prior model, resulting in an absolute image compression transformer (ICT). Through the proposed ICT, we can capture both global and local contexts from the latent representations and better parameterize the distribution of the quantized latents. Further, we leverage a learnable scaling module with a sandwich ConvNeXt-based pre-/post-processor to accurately extract more compact latent codes while reconstructing higher-quality images. Extensive experimental results on benchmark datasets showed that the proposed framework significantly improves the trade-off between coding efficiency and decoder complexity over the versatile video coding (VVC) reference encoder (VTM-18.0) and the neural codec SwinT-ChARM. Moreover, we provide model scaling studies to verify the computational efficiency of our approach and conduct several objective and subjective analyses to bring to the fore the performance gap between the adaptive image compression transformer (AICT) and the neural codec SwinT-ChARM.
Multi-modal Extreme Classification
Sep 10, 2023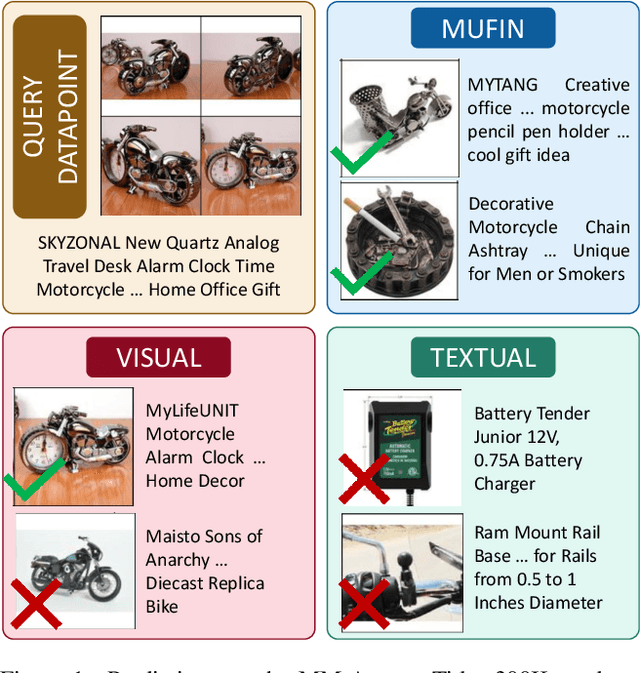

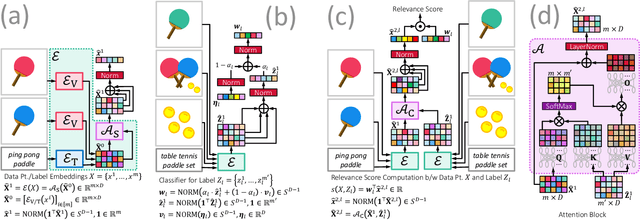
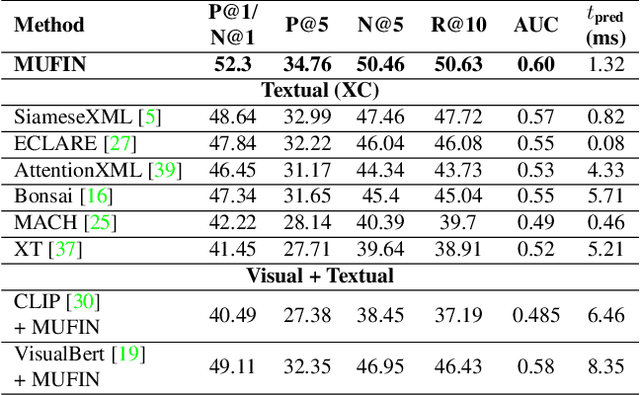
This paper develops the MUFIN technique for extreme classification (XC) tasks with millions of labels where datapoints and labels are endowed with visual and textual descriptors. Applications of MUFIN to product-to-product recommendation and bid query prediction over several millions of products are presented. Contemporary multi-modal methods frequently rely on purely embedding-based methods. On the other hand, XC methods utilize classifier architectures to offer superior accuracies than embedding only methods but mostly focus on text-based categorization tasks. MUFIN bridges this gap by reformulating multi-modal categorization as an XC problem with several millions of labels. This presents the twin challenges of developing multi-modal architectures that can offer embeddings sufficiently expressive to allow accurate categorization over millions of labels; and training and inference routines that scale logarithmically in the number of labels. MUFIN develops an architecture based on cross-modal attention and trains it in a modular fashion using pre-training and positive and negative mining. A novel product-to-product recommendation dataset MM-AmazonTitles-300K containing over 300K products was curated from publicly available amazon.com listings with each product endowed with a title and multiple images. On the all datasets MUFIN offered at least 3% higher accuracy than leading text-based, image-based and multi-modal techniques. Code for MUFIN is available at https://github.com/Extreme-classification/MUFIN
UX Heuristics and Checklist for Deep Learning powered Mobile Applications with Image Classification
Jul 05, 2023
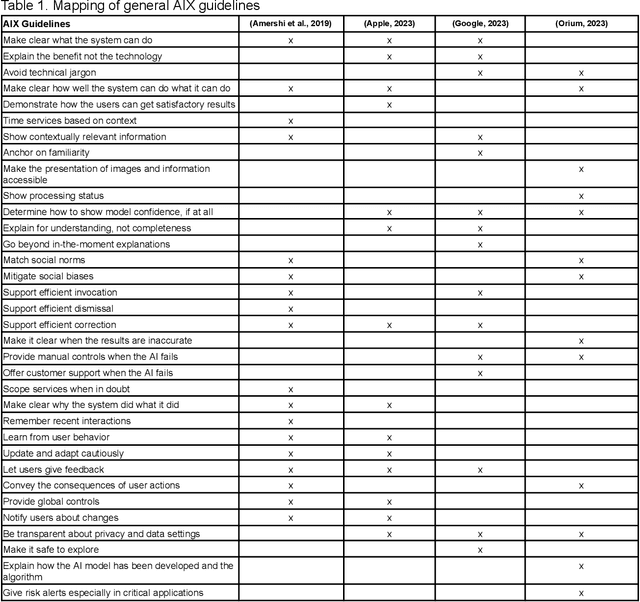
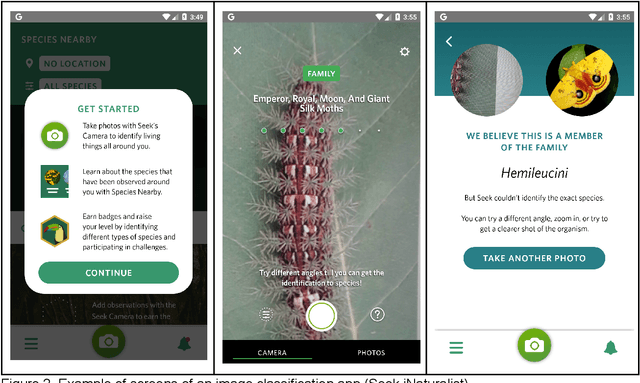
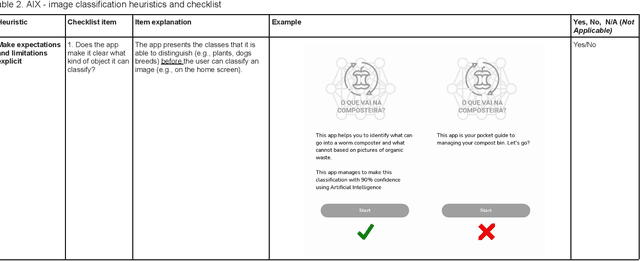
Advances in mobile applications providing image classification enabled by Deep Learning require innovative User Experience solutions in order to assure their adequate use by users. To aid the design process, usability heuristics are typically customized for a specific kind of application. Therefore, based on a literature review and analyzing existing mobile applications with image classification, we propose an initial set of AIX heuristics for Deep Learning powered mobile applications with image classification decomposed into a checklist. In order to facilitate the usage of the checklist we also developed an online course presenting the concepts and heuristics as well as a web-based tool in order to support an evaluation using these heuristics. These results of this research can be used to guide the design of the interfaces of such applications as well as support the conduction of heuristic evaluations supporting practitioners to develop image classification apps that people can understand, trust, and can engage with effectively.
Good-looking but Lacking Faithfulness: Understanding Local Explanation Methods through Trend-based Testing
Sep 09, 2023
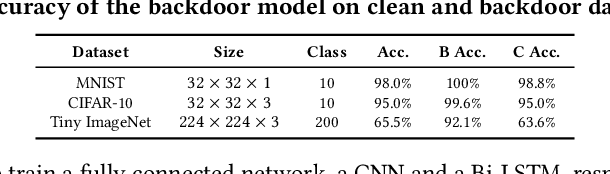


While enjoying the great achievements brought by deep learning (DL), people are also worried about the decision made by DL models, since the high degree of non-linearity of DL models makes the decision extremely difficult to understand. Consequently, attacks such as adversarial attacks are easy to carry out, but difficult to detect and explain, which has led to a boom in the research on local explanation methods for explaining model decisions. In this paper, we evaluate the faithfulness of explanation methods and find that traditional tests on faithfulness encounter the random dominance problem, \ie, the random selection performs the best, especially for complex data. To further solve this problem, we propose three trend-based faithfulness tests and empirically demonstrate that the new trend tests can better assess faithfulness than traditional tests on image, natural language and security tasks. We implement the assessment system and evaluate ten popular explanation methods. Benefiting from the trend tests, we successfully assess the explanation methods on complex data for the first time, bringing unprecedented discoveries and inspiring future research. Downstream tasks also greatly benefit from the tests. For example, model debugging equipped with faithful explanation methods performs much better for detecting and correcting accuracy and security problems.
Neural Semantic Surface Maps
Sep 09, 2023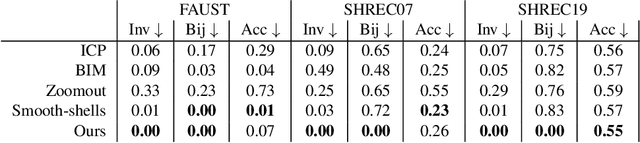
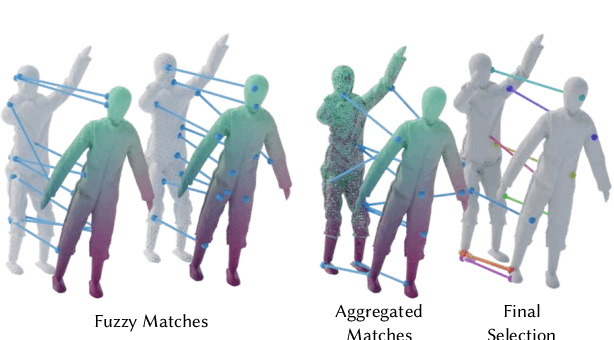
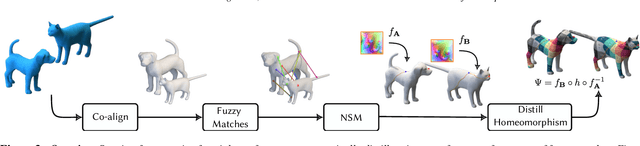
We present an automated technique for computing a map between two genus-zero shapes, which matches semantically corresponding regions to one another. Lack of annotated data prohibits direct inference of 3D semantic priors; instead, current State-of-the-art methods predominantly optimize geometric properties or require varying amounts of manual annotation. To overcome the lack of annotated training data, we distill semantic matches from pre-trained vision models: our method renders the pair of 3D shapes from multiple viewpoints; the resulting renders are then fed into an off-the-shelf image-matching method which leverages a pretrained visual model to produce feature points. This yields semantic correspondences, which can be projected back to the 3D shapes, producing a raw matching that is inaccurate and inconsistent between different viewpoints. These correspondences are refined and distilled into an inter-surface map by a dedicated optimization scheme, which promotes bijectivity and continuity of the output map. We illustrate that our approach can generate semantic surface-to-surface maps, eliminating manual annotations or any 3D training data requirement. Furthermore, it proves effective in scenarios with high semantic complexity, where objects are non-isometrically related, as well as in situations where they are nearly isometric.
A Machine Vision Method for Correction of Eccentric Error: Based on Adaptive Enhancement Algorithm
Sep 01, 2023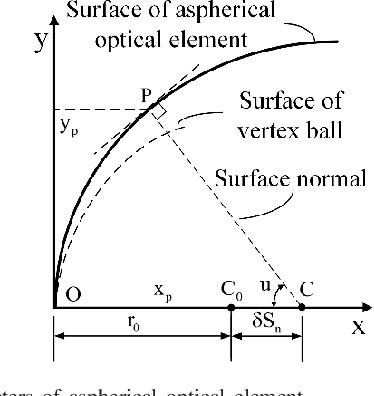

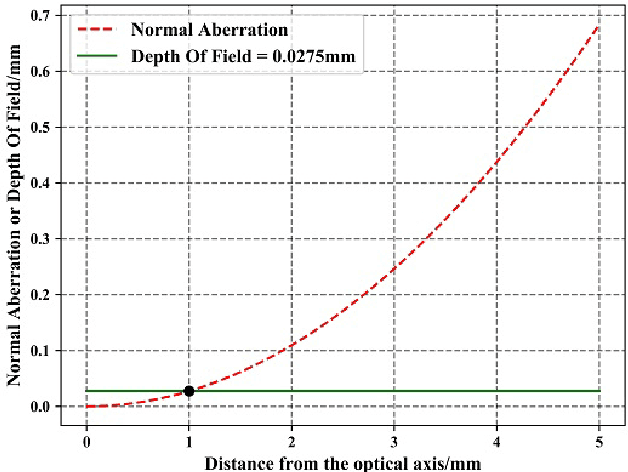

In the procedure of surface defects detection for large-aperture aspherical optical elements, it is of vital significance to adjust the optical axis of the element to be coaxial with the mechanical spin axis accurately. Therefore, a machine vision method for eccentric error correction is proposed in this paper. Focusing on the severe defocus blur of reference crosshair image caused by the imaging characteristic of the aspherical optical element, which may lead to the failure of correction, an Adaptive Enhancement Algorithm (AEA) is proposed to strengthen the crosshair image. AEA is consisted of existed Guided Filter Dark Channel Dehazing Algorithm (GFA) and proposed lightweight Multi-scale Densely Connected Network (MDC-Net). The enhancement effect of GFA is excellent but time-consuming, and the enhancement effect of MDC-Net is slightly inferior but strongly real-time. As AEA will be executed dozens of times during each correction procedure, its real-time performance is very important. Therefore, by setting the empirical threshold of definition evaluation function SMD2, GFA and MDC-Net are respectively applied to highly and slightly blurred crosshair images so as to ensure the enhancement effect while saving as much time as possible. AEA has certain robustness in time-consuming performance, which takes an average time of 0.2721s and 0.0963s to execute GFA and MDC-Net separately on ten 200pixels 200pixels Region of Interest (ROI) images with different degrees of blur. And the eccentricity error can be reduced to within 10um by our method.