 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Reconstructing Groups of People with Hypergraph Relational Reasoning
Aug 30, 2023
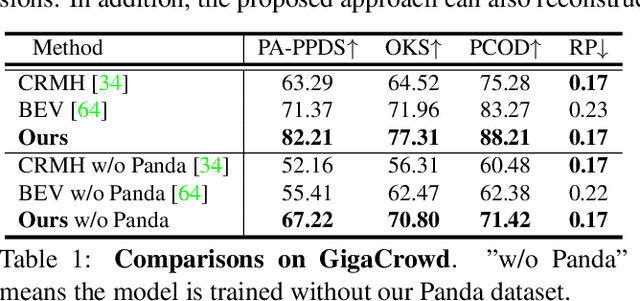

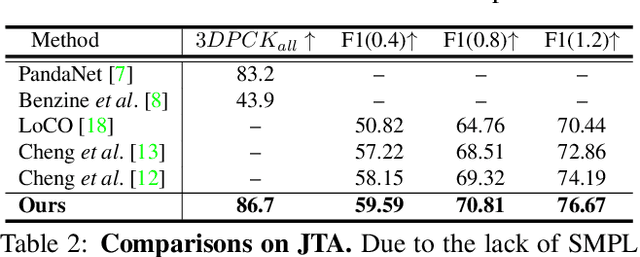
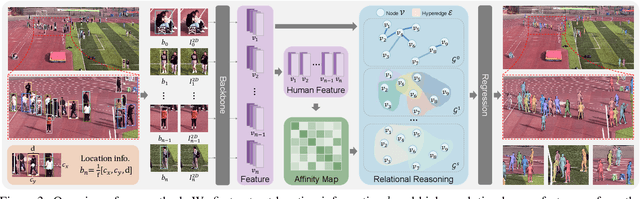
Due to the mutual occlusion, severe scale variation, and complex spatial distribution, the current multi-person mesh recovery methods cannot produce accurate absolute body poses and shapes in large-scale crowded scenes. To address the obstacles, we fully exploit crowd features for reconstructing groups of people from a monocular image. A novel hypergraph relational reasoning network is proposed to formulate the complex and high-order relation correlations among individuals and groups in the crowd. We first extract compact human features and location information from the original high-resolution image. By conducting the relational reasoning on the extracted individual features, the underlying crowd collectiveness and interaction relationship can provide additional group information for the reconstruction. Finally, the updated individual features and the localization information are used to regress human meshes in camera coordinates. To facilitate the network training, we further build pseudo ground-truth on two crowd datasets, which may also promote future research on pose estimation and human behavior understanding in crowded scenes. The experimental results show that our approach outperforms other baseline methods both in crowded and common scenarios. The code and datasets are publicly available at https://github.com/boycehbz/GroupRec.
Domain Transfer Through Image-to-Image Translation for Uncertainty-Aware Prostate Cancer Classification
Jul 02, 2023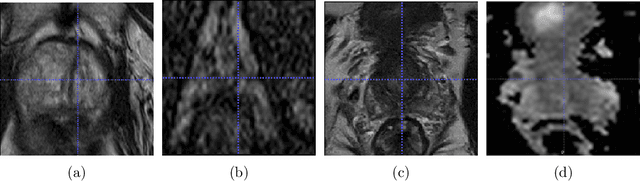
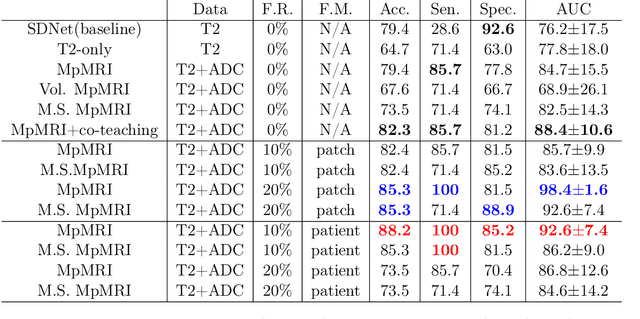
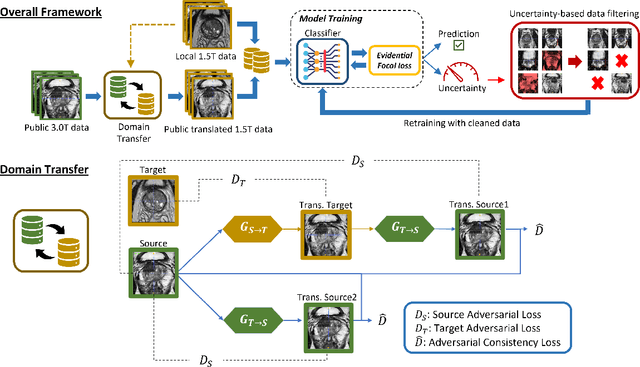

Prostate Cancer (PCa) is often diagnosed using High-resolution 3.0 Tesla(T) MRI, which has been widely established in clinics. However, there are still many medical centers that use 1.5T MRI units in the actual diagnostic process of PCa. In the past few years, deep learning-based models have been proven to be efficient on the PCa classification task and can be successfully used to support radiologists during the diagnostic process. However, training such models often requires a vast amount of data, and sometimes it is unobtainable in practice. Additionally, multi-source MRIs can pose challenges due to cross-domain distribution differences. In this paper, we have presented a novel approach for unpaired image-to-image translation of prostate mp-MRI for classifying clinically significant PCa, to be applied in data-constrained settings. First, we introduce domain transfer, a novel pipeline to translate unpaired 3.0T multi-parametric prostate MRIs to 1.5T, to increase the number of training data. Second, we estimate the uncertainty of our models through an evidential deep learning approach; and leverage the dataset filtering technique during the training process. Furthermore, we introduce a simple, yet efficient Evidential Focal Loss that incorporates the focal loss with evidential uncertainty to train our model. Our experiments demonstrate that the proposed method significantly improves the Area Under ROC Curve (AUC) by over 20% compared to the previous work (98.4% vs. 76.2%). We envision that providing prediction uncertainty to radiologists may help them focus more on uncertain cases and thus expedite the diagnostic process effectively. Our code is available at https://github.com/med-i-lab/DT_UE_PCa
BigVSAN: Enhancing GAN-based Neural Vocoders with Slicing Adversarial Network
Sep 06, 2023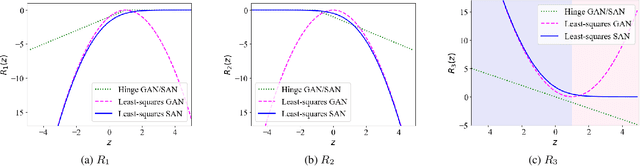

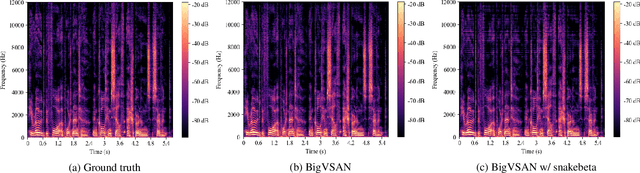
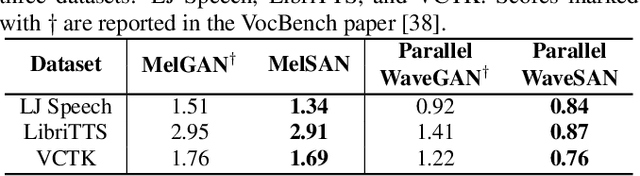
Generative adversarial network (GAN)-based vocoders have been intensively studied because they can synthesize high-fidelity audio waveforms faster than real-time. However, it has been reported that most GANs fail to obtain the optimal projection for discriminating between real and fake data in the feature space. In the literature, it has been demonstrated that slicing adversarial network (SAN), an improved GAN training framework that can find the optimal projection, is effective in the image generation task. In this paper, we investigate the effectiveness of SAN in the vocoding task. For this purpose, we propose a scheme to modify least-squares GAN, which most GAN-based vocoders adopt, so that their loss functions satisfy the requirements of SAN. Through our experiments, we demonstrate that SAN can improve the performance of GAN-based vocoders, including BigVGAN, with small modifications. Our code is available at https://github.com/sony/bigvsan.
Learning Modulated Transformation in GANs
Aug 29, 2023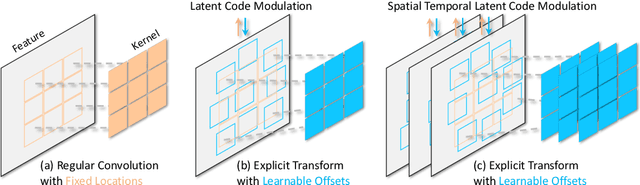
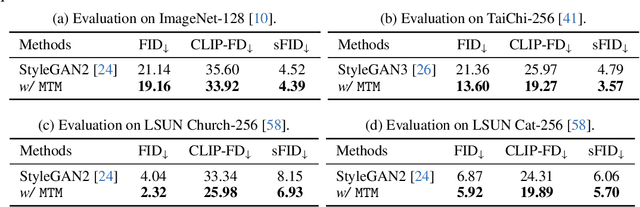


The success of style-based generators largely benefits from style modulation, which helps take care of the cross-instance variation within data. However, the instance-wise stochasticity is typically introduced via regular convolution, where kernels interact with features at some fixed locations, limiting its capacity for modeling geometric variation. To alleviate this problem, we equip the generator in generative adversarial networks (GANs) with a plug-and-play module, termed as modulated transformation module (MTM). This module predicts spatial offsets under the control of latent codes, based on which the convolution operation can be applied at variable locations for different instances, and hence offers the model an additional degree of freedom to handle geometry deformation. Extensive experiments suggest that our approach can be faithfully generalized to various generative tasks, including image generation, 3D-aware image synthesis, and video generation, and get compatible with state-of-the-art frameworks without any hyper-parameter tuning. It is noteworthy that, towards human generation on the challenging TaiChi dataset, we improve the FID of StyleGAN3 from 21.36 to 13.60, demonstrating the efficacy of learning modulated geometry transformation.
Reframing the Brain Age Prediction Problem to a More Interpretable and Quantitative Approach
Aug 23, 2023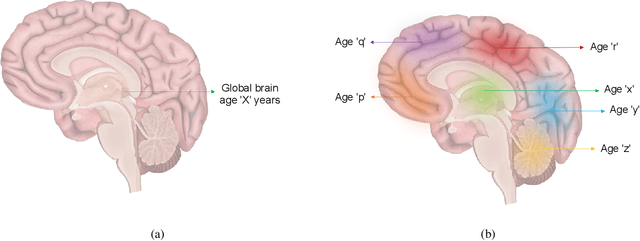

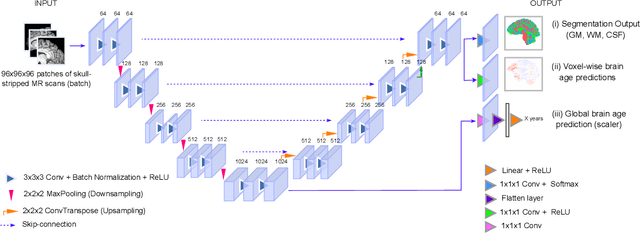
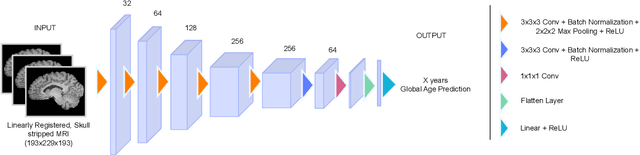
Deep learning models have achieved state-of-the-art results in estimating brain age, which is an important brain health biomarker, from magnetic resonance (MR) images. However, most of these models only provide a global age prediction, and rely on techniques, such as saliency maps to interpret their results. These saliency maps highlight regions in the input image that were significant for the model's predictions, but they are hard to be interpreted, and saliency map values are not directly comparable across different samples. In this work, we reframe the age prediction problem from MR images to an image-to-image regression problem where we estimate the brain age for each brain voxel in MR images. We compare voxel-wise age prediction models against global age prediction models and their corresponding saliency maps. The results indicate that voxel-wise age prediction models are more interpretable, since they provide spatial information about the brain aging process, and they benefit from being quantitative.
Causality-Based Feature Importance Quantifying Methods:PN-FI, PS-FI and PNS-FI
Aug 28, 2023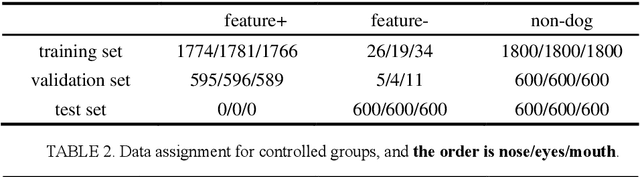
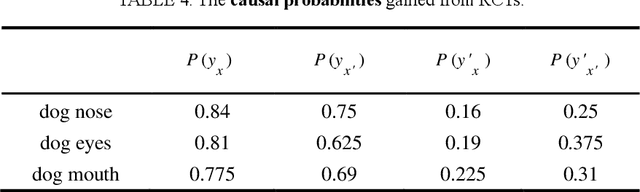
In current ML field models are getting larger and more complex, data we use are also getting larger in quantity and higher in dimension, so in order to train better models, save training time and computational resources, a good Feature Selection (FS) method in preprocessing stage is necessary. Feature importance (FI) is of great importance since it is the basis of feature selection. This paper creatively introduces the calculation of PNS(the probability of Necessity and Sufficiency) in Causality into quantifying feature importance and creates new FI measuring methods: PN-FI, which means how much importance a feature has in image recognition tasks, PS_FI that means how much importance a feature has in image generating tasks, and PNS_FI which measures both. The main body of this paper is three RCTs, with whose results we show how PS_FI, PN_FI and PNS_FI of three features: dog nose, dog eyes and dog mouth are calculated. The FI values are intervals with tight upper and lower bounds.
Fast Dust Sand Image Enhancement Based on Color Correction and New Membership Function
Jul 27, 2023Images captured in dusty environments suffering from poor visibility and quality. Enhancement of these images such as sand dust images plays a critical role in various atmospheric optics applications. In this work, proposed a new model based on Color Correction and new membership function to enhance san dust images. The proposed model consists of three phases: correction of color shift, removal of haze, and enhancement of contrast and brightness. The color shift is corrected using a new membership function to adjust the values of U and V in the YUV color space. The Adaptive Dark Channel Prior (A-DCP) is used for haze removal. The stretching contrast and improving image brightness are based on Contrast Limited Adaptive Histogram Equalization (CLAHE). The proposed model tests and evaluates through many real sand dust images. The experimental results show that the proposed solution is outperformed the current studies in terms of effectively removing the red and yellow cast and provides high quality and quantity dust images.
DHC: Dual-debiased Heterogeneous Co-training Framework for Class-imbalanced Semi-supervised Medical Image Segmentation
Jul 22, 2023The volume-wise labeling of 3D medical images is expertise-demanded and time-consuming; hence semi-supervised learning (SSL) is highly desirable for training with limited labeled data. Imbalanced class distribution is a severe problem that bottlenecks the real-world application of these methods but was not addressed much. Aiming to solve this issue, we present a novel Dual-debiased Heterogeneous Co-training (DHC) framework for semi-supervised 3D medical image segmentation. Specifically, we propose two loss weighting strategies, namely Distribution-aware Debiased Weighting (DistDW) and Difficulty-aware Debiased Weighting (DiffDW), which leverage the pseudo labels dynamically to guide the model to solve data and learning biases. The framework improves significantly by co-training these two diverse and accurate sub-models. We also introduce more representative benchmarks for class-imbalanced semi-supervised medical image segmentation, which can fully demonstrate the efficacy of the class-imbalance designs. Experiments show that our proposed framework brings significant improvements by using pseudo labels for debiasing and alleviating the class imbalance problem. More importantly, our method outperforms the state-of-the-art SSL methods, demonstrating the potential of our framework for the more challenging SSL setting. Code and models are available at: https://github.com/xmed-lab/DHC.
Processing Energy Modeling for Neural Network Based Image Compression
Jun 29, 2023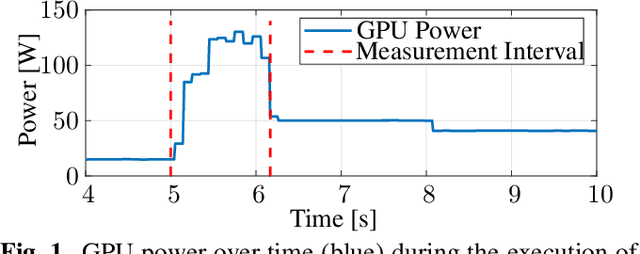
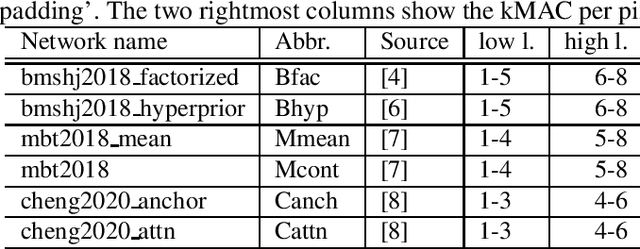
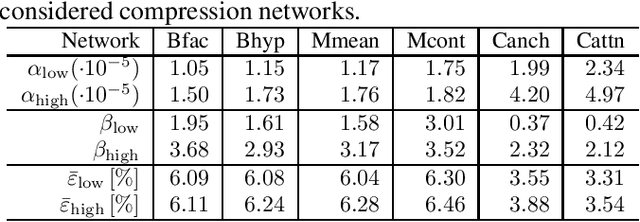
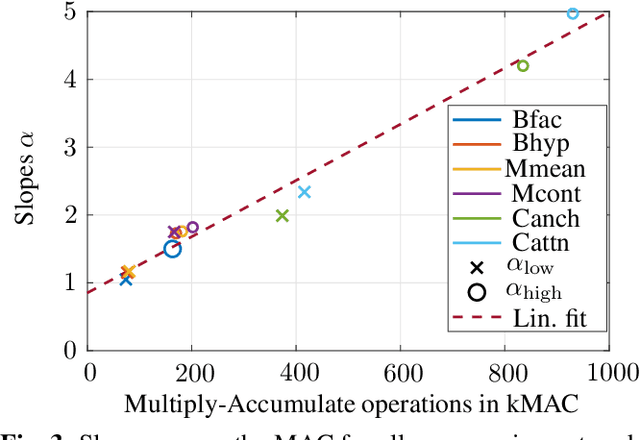
Nowadays, the compression performance of neural-networkbased image compression algorithms outperforms state-of-the-art compression approaches such as JPEG or HEIC-based image compression. Unfortunately, most neural-network based compression methods are executed on GPUs and consume a high amount of energy during execution. Therefore, this paper performs an in-depth analysis on the energy consumption of state-of-the-art neural-network based compression methods on a GPU and show that the energy consumption of compression networks can be estimated using the image size with mean estimation errors of less than 7%. Finally, using a correlation analysis, we find that the number of operations per pixel is the main driving force for energy consumption and deduce that the network layers up to the second downsampling step are consuming most energy.
Video OWL-ViT: Temporally-consistent open-world localization in video
Aug 22, 2023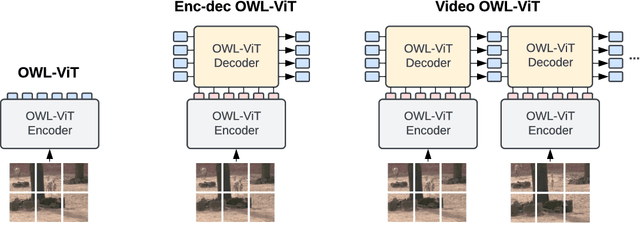
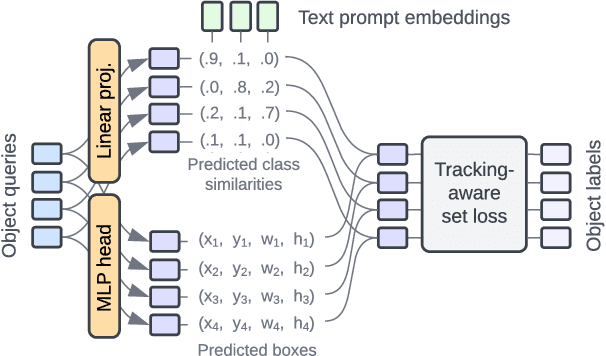
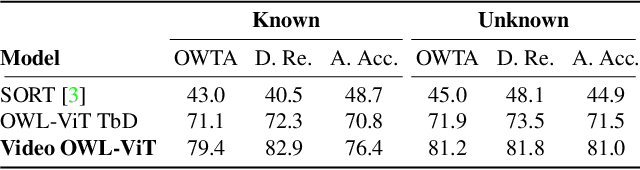

We present an architecture and a training recipe that adapts pre-trained open-world image models to localization in videos. Understanding the open visual world (without being constrained by fixed label spaces) is crucial for many real-world vision tasks. Contrastive pre-training on large image-text datasets has recently led to significant improvements for image-level tasks. For more structured tasks involving object localization applying pre-trained models is more challenging. This is particularly true for video tasks, where task-specific data is limited. We show successful transfer of open-world models by building on the OWL-ViT open-vocabulary detection model and adapting it to video by adding a transformer decoder. The decoder propagates object representations recurrently through time by using the output tokens for one frame as the object queries for the next. Our model is end-to-end trainable on video data and enjoys improved temporal consistency compared to tracking-by-detection baselines, while retaining the open-world capabilities of the backbone detector. We evaluate our model on the challenging TAO-OW benchmark and demonstrate that open-world capabilities, learned from large-scale image-text pre-training, can be transferred successfully to open-world localization across diverse videos.