 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ViLTA: Enhancing Vision-Language Pre-training through Textual Augmentation
Aug 31, 2023
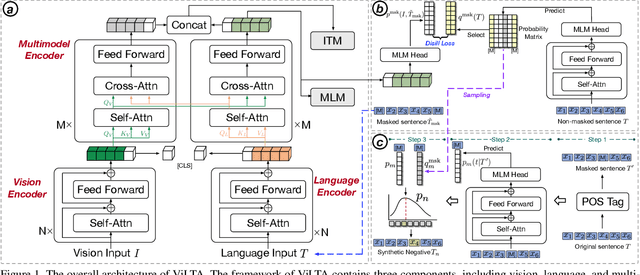
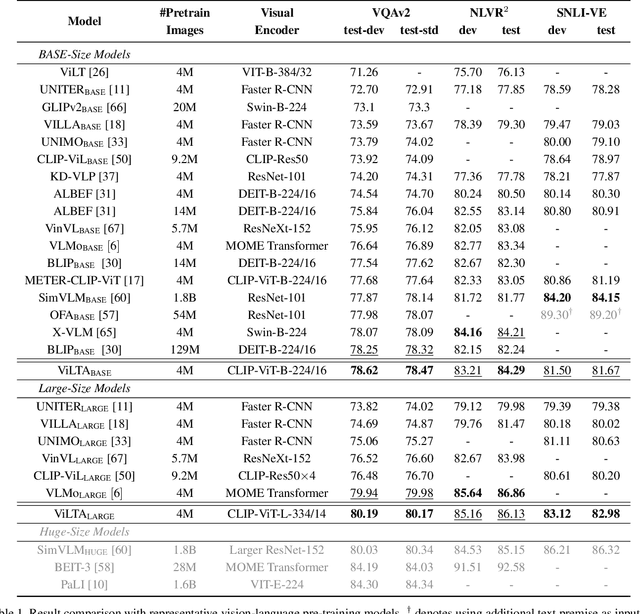
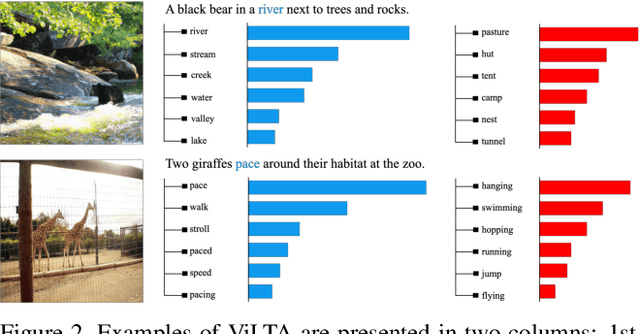
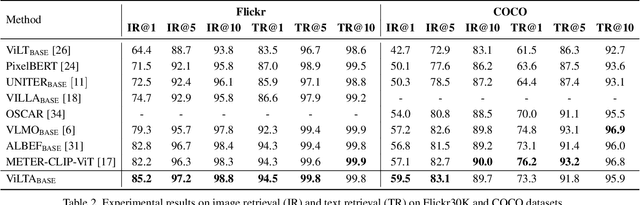
Vision-language pre-training (VLP) methods are blossoming recently, and its crucial goal is to jointly learn visual and textual features via a transformer-based architecture, demonstrating promising improvements on a variety of vision-language tasks. Prior arts usually focus on how to align visual and textual features, but strategies for improving the robustness of model and speeding up model convergence are left insufficiently explored. In this paper, we propose a novel method ViLTA, comprising of two components to further facilitate the model to learn fine-grained representations among image-text pairs. For Masked Language Modeling (MLM), we propose a cross-distillation method to generate soft labels to enhance the robustness of model, which alleviates the problem of treating synonyms of masked words as negative samples in one-hot labels. For Image-Text Matching (ITM), we leverage the current language encoder to synthesize hard negatives based on the context of language input, encouraging the model to learn high-quality representations by increasing the difficulty of the ITM task. By leveraging the above techniques, our ViLTA can achieve better performance on various vision-language tasks. Extensive experiments on benchmark datasets demonstrate that the effectiveness of ViLTA and its promising potential for vision-language pre-training.
Unsupervised CT Metal Artifact Reduction by Plugging Diffusion Priors in Dual Domains
Aug 31, 2023During the process of computed tomography (CT), metallic implants often cause disruptive artifacts in the reconstructed images, impeding accurate diagnosis. Several supervised deep learning-based approaches have been proposed for reducing metal artifacts (MAR). However, these methods heavily rely on training with simulated data, as obtaining paired metal artifact CT and clean CT data in clinical settings is challenging. This limitation can lead to decreased performance when applying these methods in clinical practice. Existing unsupervised MAR methods, whether based on learning or not, typically operate within a single domain, either in the image domain or the sinogram domain. In this paper, we propose an unsupervised MAR method based on the diffusion model, a generative model with a high capacity to represent data distributions. Specifically, we first train a diffusion model using CT images without metal artifacts. Subsequently, we iteratively utilize the priors embedded within the pre-trained diffusion model in both the sinogram and image domains to restore the degraded portions caused by metal artifacts. This dual-domain processing empowers our approach to outperform existing unsupervised MAR methods, including another MAR method based on the diffusion model, which we have qualitatively and quantitatively validated using synthetic datasets. Moreover, our method demonstrates superior visual results compared to both supervised and unsupervised methods on clinical datasets.
Sparkles: Unlocking Chats Across Multiple Images for Multimodal Instruction-Following Models
Aug 31, 2023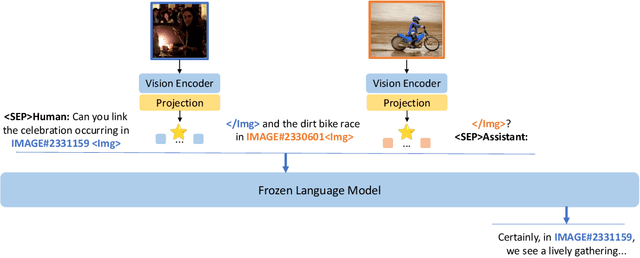


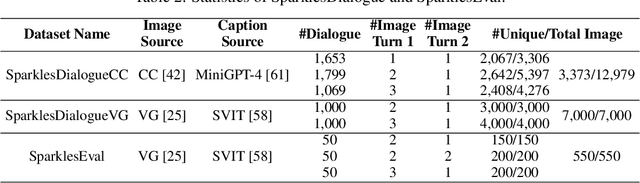
Large language models exhibit enhanced zero-shot performance on various tasks when fine-tuned with instruction-following data. Multimodal instruction-following models extend these capabilities by integrating both text and images. However, existing models such as MiniGPT-4 face challenges in maintaining dialogue coherence in scenarios involving multiple images. A primary reason is the lack of a specialized dataset for this critical application. To bridge these gaps, we present SparklesChat, a multimodal instruction-following model for open-ended dialogues across multiple images. To support the training, we introduce SparklesDialogue, the first machine-generated dialogue dataset tailored for word-level interleaved multi-image and text interactions. Furthermore, we construct SparklesEval, a GPT-assisted benchmark for quantitatively assessing a model's conversational competence across multiple images and dialogue turns. Our experiments validate the effectiveness of SparklesChat in understanding and reasoning across multiple images and dialogue turns. Specifically, SparklesChat outperformed MiniGPT-4 on established vision-and-language benchmarks, including the BISON binary image selection task and the NLVR2 visual reasoning task. Moreover, SparklesChat scored 8.56 out of 10 on SparklesEval, substantially exceeding MiniGPT-4's score of 3.91 and nearing GPT-4's score of 9.26. Qualitative evaluations further demonstrate SparklesChat's generality in handling real-world applications. All resources will be available at https://github.com/HYPJUDY/Sparkles.
CircleFormer: Circular Nuclei Detection in Whole Slide Images with Circle Queries and Attention
Aug 31, 2023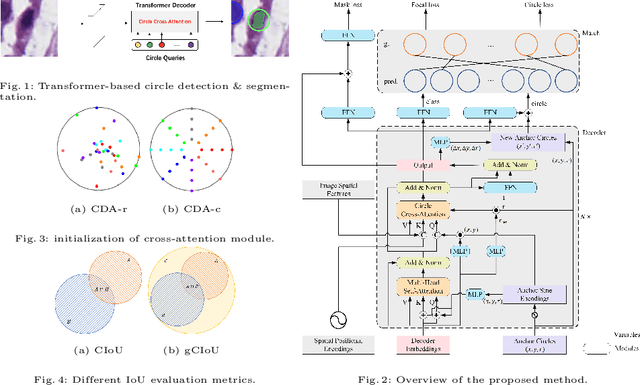
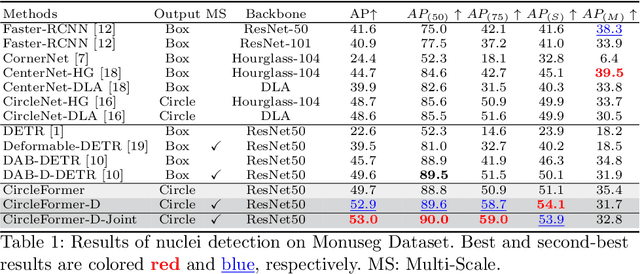
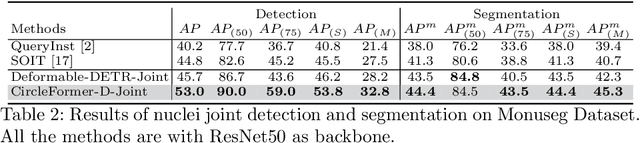
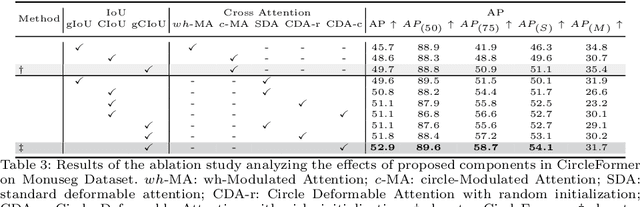
Both CNN-based and Transformer-based object detection with bounding box representation have been extensively studied in computer vision and medical image analysis, but circular object detection in medical images is still underexplored. Inspired by the recent anchor free CNN-based circular object detection method (CircleNet) for ball-shape glomeruli detection in renal pathology, in this paper, we present CircleFormer, a Transformer-based circular medical object detection with dynamic anchor circles. Specifically, queries with circle representation in Transformer decoder iteratively refine the circular object detection results, and a circle cross attention module is introduced to compute the similarity between circular queries and image features. A generalized circle IoU (gCIoU) is proposed to serve as a new regression loss of circular object detection as well. Moreover, our approach is easy to generalize to the segmentation task by adding a simple segmentation branch to CircleFormer. We evaluate our method in circular nuclei detection and segmentation on the public MoNuSeg dataset, and the experimental results show that our method achieves promising performance compared with the state-of-the-art approaches. The effectiveness of each component is validated via ablation studies as well. Our code is released at https://github.com/zhanghx-iim-ahu/CircleFormer.
Domain Transfer Through Image-to-Image Translation for Uncertainty-Aware Prostate Cancer Classification
Jul 02, 2023
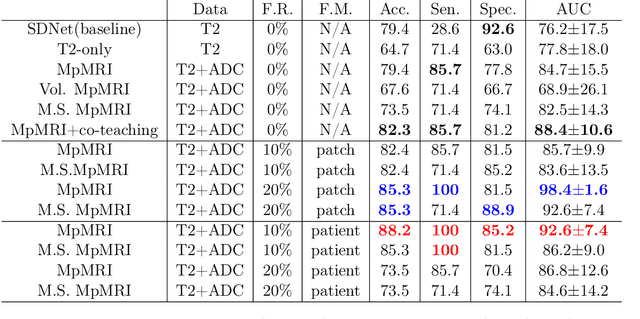
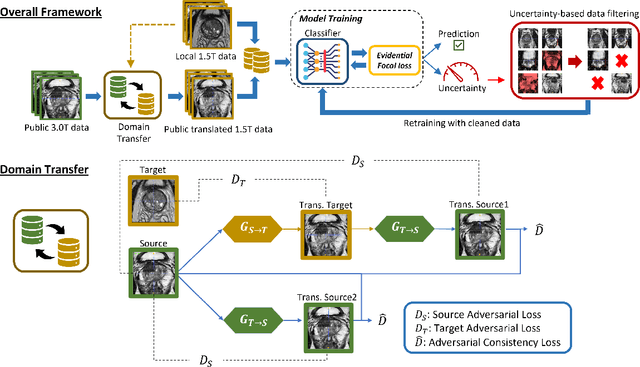

Prostate Cancer (PCa) is often diagnosed using High-resolution 3.0 Tesla(T) MRI, which has been widely established in clinics. However, there are still many medical centers that use 1.5T MRI units in the actual diagnostic process of PCa. In the past few years, deep learning-based models have been proven to be efficient on the PCa classification task and can be successfully used to support radiologists during the diagnostic process. However, training such models often requires a vast amount of data, and sometimes it is unobtainable in practice. Additionally, multi-source MRIs can pose challenges due to cross-domain distribution differences. In this paper, we have presented a novel approach for unpaired image-to-image translation of prostate mp-MRI for classifying clinically significant PCa, to be applied in data-constrained settings. First, we introduce domain transfer, a novel pipeline to translate unpaired 3.0T multi-parametric prostate MRIs to 1.5T, to increase the number of training data. Second, we estimate the uncertainty of our models through an evidential deep learning approach; and leverage the dataset filtering technique during the training process. Furthermore, we introduce a simple, yet efficient Evidential Focal Loss that incorporates the focal loss with evidential uncertainty to train our model. Our experiments demonstrate that the proposed method significantly improves the Area Under ROC Curve (AUC) by over 20% compared to the previous work (98.4% vs. 76.2%). We envision that providing prediction uncertainty to radiologists may help them focus more on uncertain cases and thus expedite the diagnostic process effectively. Our code is available at https://github.com/med-i-lab/DT_UE_PCa
Share Your Representation Only: Guaranteed Improvement of the Privacy-Utility Tradeoff in Federated Learning
Sep 11, 2023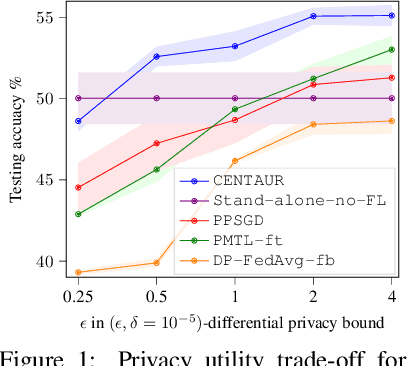


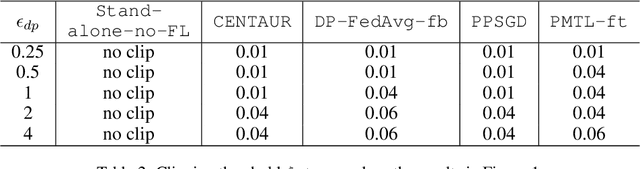
Repeated parameter sharing in federated learning causes significant information leakage about private data, thus defeating its main purpose: data privacy. Mitigating the risk of this information leakage, using state of the art differentially private algorithms, also does not come for free. Randomized mechanisms can prevent convergence of models on learning even the useful representation functions, especially if there is more disagreement between local models on the classification functions (due to data heterogeneity). In this paper, we consider a representation federated learning objective that encourages various parties to collaboratively refine the consensus part of the model, with differential privacy guarantees, while separately allowing sufficient freedom for local personalization (without releasing it). We prove that in the linear representation setting, while the objective is non-convex, our proposed new algorithm \DPFEDREP\ converges to a ball centered around the \emph{global optimal} solution at a linear rate, and the radius of the ball is proportional to the reciprocal of the privacy budget. With this novel utility analysis, we improve the SOTA utility-privacy trade-off for this problem by a factor of $\sqrt{d}$, where $d$ is the input dimension. We empirically evaluate our method with the image classification task on CIFAR10, CIFAR100, and EMNIST, and observe a significant performance improvement over the prior work under the same small privacy budget. The code can be found in this link: https://github.com/shenzebang/CENTAUR-Privacy-Federated-Representation-Learning.
UniSeg: A Unified Multi-Modal LiDAR Segmentation Network and the OpenPCSeg Codebase
Sep 11, 2023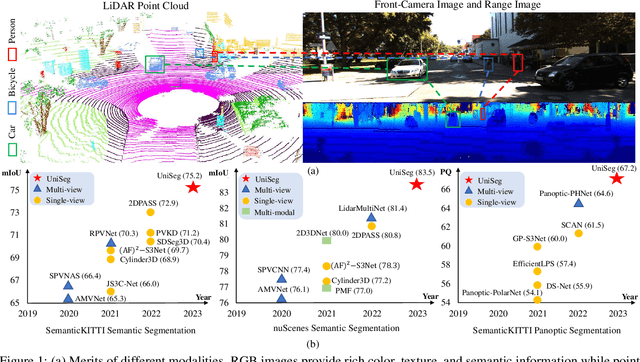

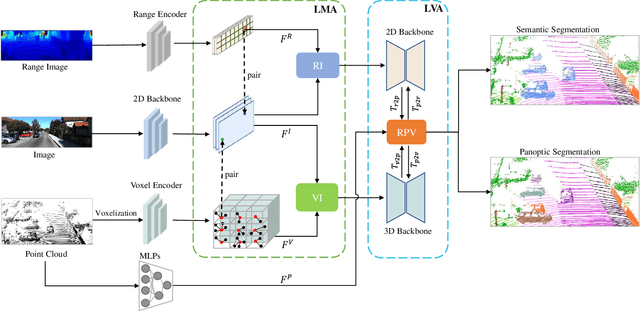
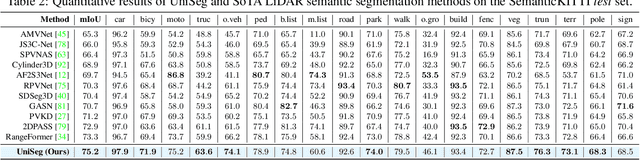
Point-, voxel-, and range-views are three representative forms of point clouds. All of them have accurate 3D measurements but lack color and texture information. RGB images are a natural complement to these point cloud views and fully utilizing the comprehensive information of them benefits more robust perceptions. In this paper, we present a unified multi-modal LiDAR segmentation network, termed UniSeg, which leverages the information of RGB images and three views of the point cloud, and accomplishes semantic segmentation and panoptic segmentation simultaneously. Specifically, we first design the Learnable cross-Modal Association (LMA) module to automatically fuse voxel-view and range-view features with image features, which fully utilize the rich semantic information of images and are robust to calibration errors. Then, the enhanced voxel-view and range-view features are transformed to the point space,where three views of point cloud features are further fused adaptively by the Learnable cross-View Association module (LVA). Notably, UniSeg achieves promising results in three public benchmarks, i.e., SemanticKITTI, nuScenes, and Waymo Open Dataset (WOD); it ranks 1st on two challenges of two benchmarks, including the LiDAR semantic segmentation challenge of nuScenes and panoptic segmentation challenges of SemanticKITTI. Besides, we construct the OpenPCSeg codebase, which is the largest and most comprehensive outdoor LiDAR segmentation codebase. It contains most of the popular outdoor LiDAR segmentation algorithms and provides reproducible implementations. The OpenPCSeg codebase will be made publicly available at https://github.com/PJLab-ADG/PCSeg.
Evaluating Similitude and Robustness of Deep Image Denoising Models via Adversarial Attack
Jun 28, 2023
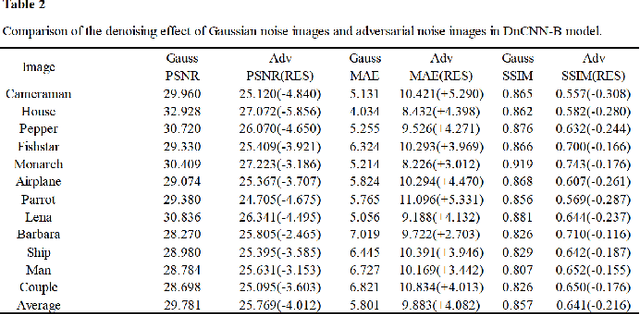

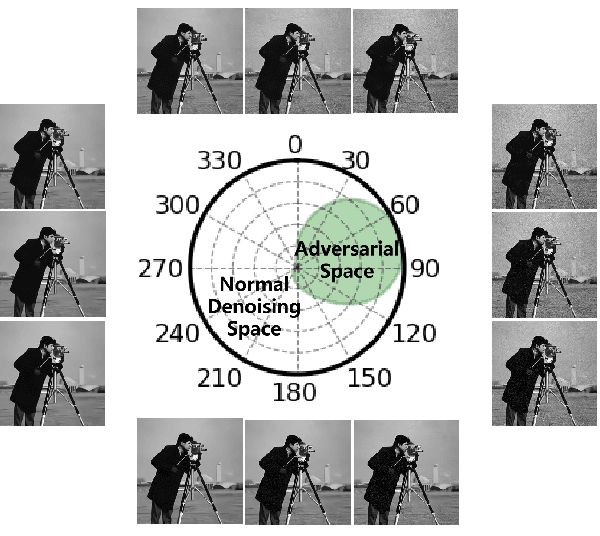
Deep neural networks (DNNs) have a wide range of applications in the field of image denoising, and they are superior to traditional image denoising. However, DNNs inevitably show vulnerability, which is the weak robustness in the face of adversarial attacks. In this paper, we find some similitudes between existing deep image denoising methods, as they are consistently fooled by adversarial attacks. First, denoising-PGD is proposed which is a denoising model full adversarial method. The current mainstream non-blind denoising models (DnCNN, FFDNet, ECNDNet, BRDNet), blind denoising models (DnCNN-B, Noise2Noise, RDDCNN-B, FAN), and plug-and-play (DPIR, CurvPnP) and unfolding denoising models (DeamNet) applied to grayscale and color images can be attacked by the same set of methods. Second, since the transferability of denoising-PGD is prominent in the image denoising task, we design experiments to explore the characteristic of the latent under the transferability. We correlate transferability with similitude and conclude that the deep image denoising models have high similitude. Third, we investigate the characteristic of the adversarial space and use adversarial training to complement the vulnerability of deep image denoising to adversarial attacks on image denoising. Finally, we constrain this adversarial attack method and propose the L2-denoising-PGD image denoising adversarial attack method that maintains the Gaussian distribution. Moreover, the model-driven image denoising BM3D shows some resistance in the face of adversarial attacks.
CHORUS: Learning Canonicalized 3D Human-Object Spatial Relations from Unbounded Synthesized Images
Sep 03, 2023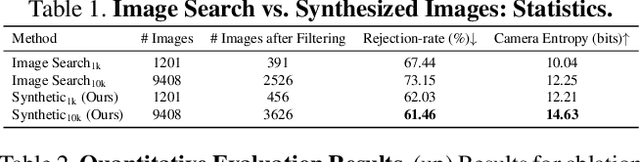

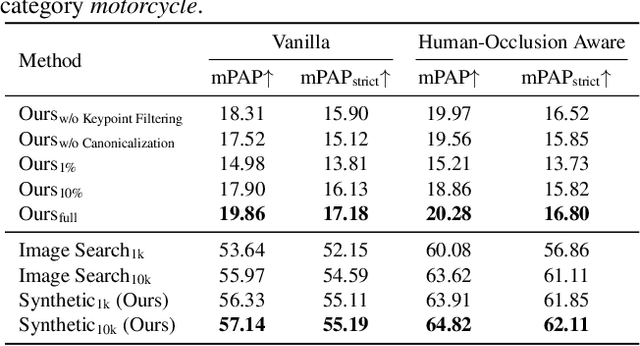
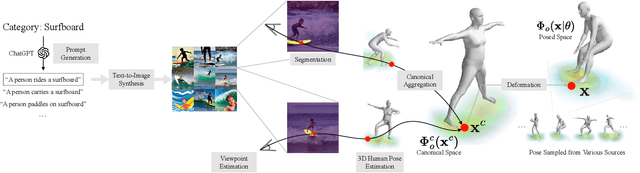
We present a method for teaching machines to understand and model the underlying spatial common sense of diverse human-object interactions in 3D in a self-supervised way. This is a challenging task, as there exist specific manifolds of the interactions that can be considered human-like and natural, but the human pose and the geometry of objects can vary even for similar interactions. Such diversity makes the annotating task of 3D interactions difficult and hard to scale, which limits the potential to reason about that in a supervised way. One way of learning the 3D spatial relationship between humans and objects during interaction is by showing multiple 2D images captured from different viewpoints when humans interact with the same type of objects. The core idea of our method is to leverage a generative model that produces high-quality 2D images from an arbitrary text prompt input as an "unbounded" data generator with effective controllability and view diversity. Despite its imperfection of the image quality over real images, we demonstrate that the synthesized images are sufficient to learn the 3D human-object spatial relations. We present multiple strategies to leverage the synthesized images, including (1) the first method to leverage a generative image model for 3D human-object spatial relation learning; (2) a framework to reason about the 3D spatial relations from inconsistent 2D cues in a self-supervised manner via 3D occupancy reasoning with pose canonicalization; (3) semantic clustering to disambiguate different types of interactions with the same object types; and (4) a novel metric to assess the quality of 3D spatial learning of interaction.
SGDiff: A Style Guided Diffusion Model for Fashion Synthesis
Aug 15, 2023This paper reports on the development of \textbf{a novel style guided diffusion model (SGDiff)} which overcomes certain weaknesses inherent in existing models for image synthesis. The proposed SGDiff combines image modality with a pretrained text-to-image diffusion model to facilitate creative fashion image synthesis. It addresses the limitations of text-to-image diffusion models by incorporating supplementary style guidance, substantially reducing training costs, and overcoming the difficulties of controlling synthesized styles with text-only inputs. This paper also introduces a new dataset -- SG-Fashion, specifically designed for fashion image synthesis applications, offering high-resolution images and an extensive range of garment categories. By means of comprehensive ablation study, we examine the application of classifier-free guidance to a variety of conditions and validate the effectiveness of the proposed model for generating fashion images of the desired categories, product attributes, and styles. The contributions of this paper include a novel classifier-free guidance method for multi-modal feature fusion, a comprehensive dataset for fashion image synthesis application, a thorough investigation on conditioned text-to-image synthesis, and valuable insights for future research in the text-to-image synthesis domain. The code and dataset are available at: \url{https://github.com/taited/SGDiff}.