 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ViLTA: Enhancing Vision-Language Pre-training through Textual Augmentation
Aug 31, 2023
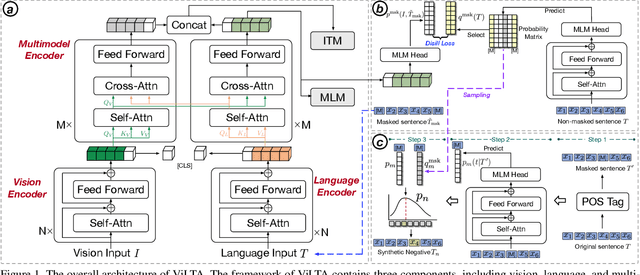
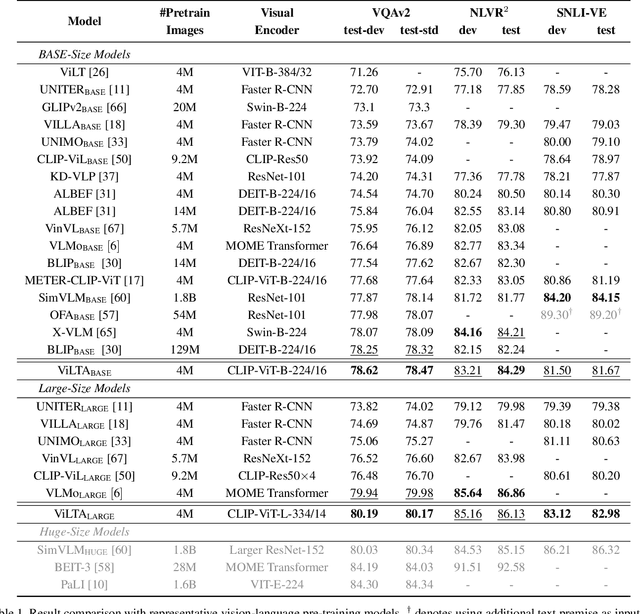
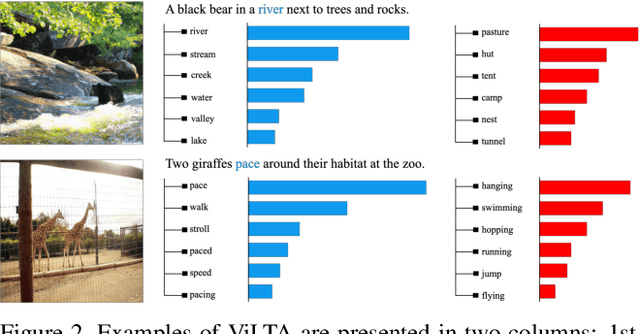
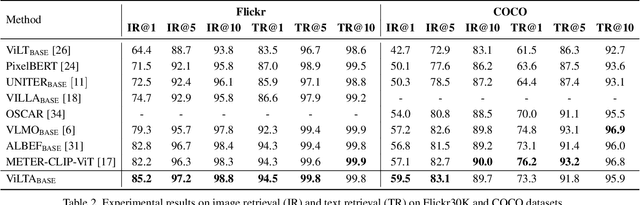
Vision-language pre-training (VLP) methods are blossoming recently, and its crucial goal is to jointly learn visual and textual features via a transformer-based architecture, demonstrating promising improvements on a variety of vision-language tasks. Prior arts usually focus on how to align visual and textual features, but strategies for improving the robustness of model and speeding up model convergence are left insufficiently explored. In this paper, we propose a novel method ViLTA, comprising of two components to further facilitate the model to learn fine-grained representations among image-text pairs. For Masked Language Modeling (MLM), we propose a cross-distillation method to generate soft labels to enhance the robustness of model, which alleviates the problem of treating synonyms of masked words as negative samples in one-hot labels. For Image-Text Matching (ITM), we leverage the current language encoder to synthesize hard negatives based on the context of language input, encouraging the model to learn high-quality representations by increasing the difficulty of the ITM task. By leveraging the above techniques, our ViLTA can achieve better performance on various vision-language tasks. Extensive experiments on benchmark datasets demonstrate that the effectiveness of ViLTA and its promising potential for vision-language pre-training.
Unsupervised CT Metal Artifact Reduction by Plugging Diffusion Priors in Dual Domains
Aug 31, 2023During the process of computed tomography (CT), metallic implants often cause disruptive artifacts in the reconstructed images, impeding accurate diagnosis. Several supervised deep learning-based approaches have been proposed for reducing metal artifacts (MAR). However, these methods heavily rely on training with simulated data, as obtaining paired metal artifact CT and clean CT data in clinical settings is challenging. This limitation can lead to decreased performance when applying these methods in clinical practice. Existing unsupervised MAR methods, whether based on learning or not, typically operate within a single domain, either in the image domain or the sinogram domain. In this paper, we propose an unsupervised MAR method based on the diffusion model, a generative model with a high capacity to represent data distributions. Specifically, we first train a diffusion model using CT images without metal artifacts. Subsequently, we iteratively utilize the priors embedded within the pre-trained diffusion model in both the sinogram and image domains to restore the degraded portions caused by metal artifacts. This dual-domain processing empowers our approach to outperform existing unsupervised MAR methods, including another MAR method based on the diffusion model, which we have qualitatively and quantitatively validated using synthetic datasets. Moreover, our method demonstrates superior visual results compared to both supervised and unsupervised methods on clinical datasets.
Sparkles: Unlocking Chats Across Multiple Images for Multimodal Instruction-Following Models
Aug 31, 2023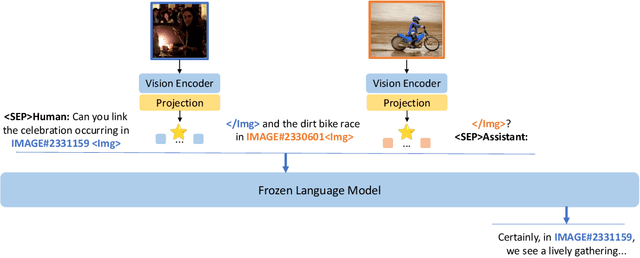


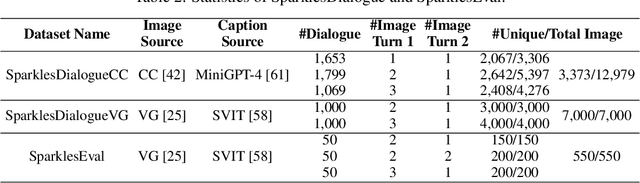
Large language models exhibit enhanced zero-shot performance on various tasks when fine-tuned with instruction-following data. Multimodal instruction-following models extend these capabilities by integrating both text and images. However, existing models such as MiniGPT-4 face challenges in maintaining dialogue coherence in scenarios involving multiple images. A primary reason is the lack of a specialized dataset for this critical application. To bridge these gaps, we present SparklesChat, a multimodal instruction-following model for open-ended dialogues across multiple images. To support the training, we introduce SparklesDialogue, the first machine-generated dialogue dataset tailored for word-level interleaved multi-image and text interactions. Furthermore, we construct SparklesEval, a GPT-assisted benchmark for quantitatively assessing a model's conversational competence across multiple images and dialogue turns. Our experiments validate the effectiveness of SparklesChat in understanding and reasoning across multiple images and dialogue turns. Specifically, SparklesChat outperformed MiniGPT-4 on established vision-and-language benchmarks, including the BISON binary image selection task and the NLVR2 visual reasoning task. Moreover, SparklesChat scored 8.56 out of 10 on SparklesEval, substantially exceeding MiniGPT-4's score of 3.91 and nearing GPT-4's score of 9.26. Qualitative evaluations further demonstrate SparklesChat's generality in handling real-world applications. All resources will be available at https://github.com/HYPJUDY/Sparkles.
CircleFormer: Circular Nuclei Detection in Whole Slide Images with Circle Queries and Attention
Aug 31, 2023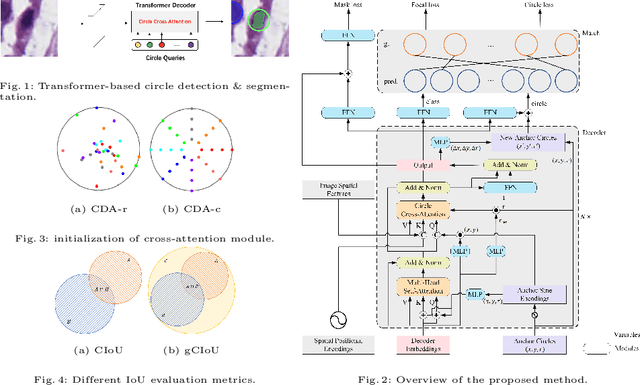
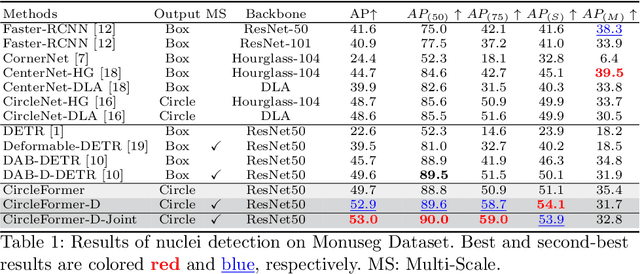
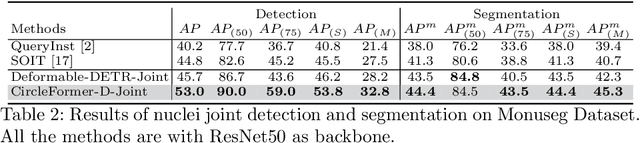
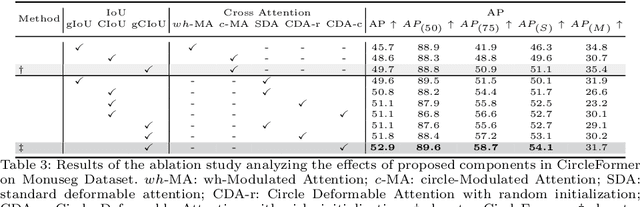
Both CNN-based and Transformer-based object detection with bounding box representation have been extensively studied in computer vision and medical image analysis, but circular object detection in medical images is still underexplored. Inspired by the recent anchor free CNN-based circular object detection method (CircleNet) for ball-shape glomeruli detection in renal pathology, in this paper, we present CircleFormer, a Transformer-based circular medical object detection with dynamic anchor circles. Specifically, queries with circle representation in Transformer decoder iteratively refine the circular object detection results, and a circle cross attention module is introduced to compute the similarity between circular queries and image features. A generalized circle IoU (gCIoU) is proposed to serve as a new regression loss of circular object detection as well. Moreover, our approach is easy to generalize to the segmentation task by adding a simple segmentation branch to CircleFormer. We evaluate our method in circular nuclei detection and segmentation on the public MoNuSeg dataset, and the experimental results show that our method achieves promising performance compared with the state-of-the-art approaches. The effectiveness of each component is validated via ablation studies as well. Our code is released at https://github.com/zhanghx-iim-ahu/CircleFormer.
Text + Sketch: Image Compression at Ultra Low Rates
Jul 04, 2023
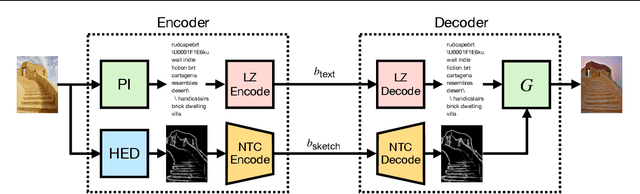
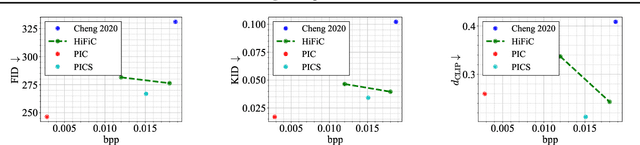
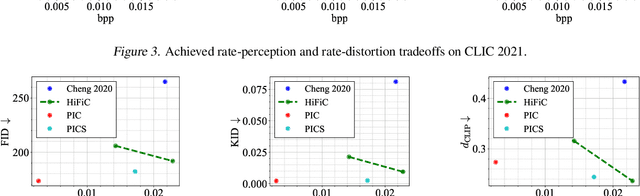
Recent advances in text-to-image generative models provide the ability to generate high-quality images from short text descriptions. These foundation models, when pre-trained on billion-scale datasets, are effective for various downstream tasks with little or no further training. A natural question to ask is how such models may be adapted for image compression. We investigate several techniques in which the pre-trained models can be directly used to implement compression schemes targeting novel low rate regimes. We show how text descriptions can be used in conjunction with side information to generate high-fidelity reconstructions that preserve both semantics and spatial structure of the original. We demonstrate that at very low bit-rates, our method can significantly improve upon learned compressors in terms of perceptual and semantic fidelity, despite no end-to-end training.
CHORUS: Learning Canonicalized 3D Human-Object Spatial Relations from Unbounded Synthesized Images
Sep 03, 2023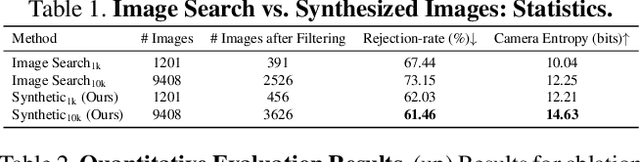

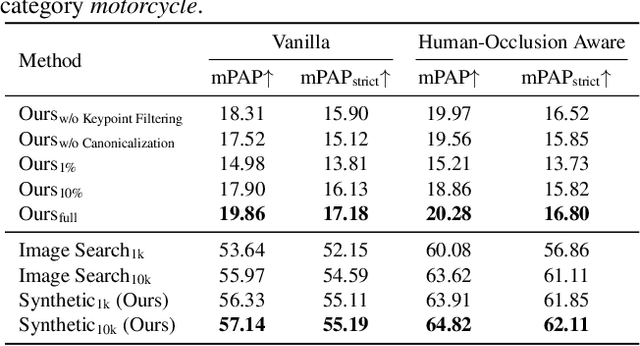
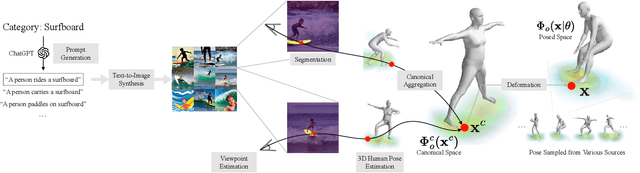
We present a method for teaching machines to understand and model the underlying spatial common sense of diverse human-object interactions in 3D in a self-supervised way. This is a challenging task, as there exist specific manifolds of the interactions that can be considered human-like and natural, but the human pose and the geometry of objects can vary even for similar interactions. Such diversity makes the annotating task of 3D interactions difficult and hard to scale, which limits the potential to reason about that in a supervised way. One way of learning the 3D spatial relationship between humans and objects during interaction is by showing multiple 2D images captured from different viewpoints when humans interact with the same type of objects. The core idea of our method is to leverage a generative model that produces high-quality 2D images from an arbitrary text prompt input as an "unbounded" data generator with effective controllability and view diversity. Despite its imperfection of the image quality over real images, we demonstrate that the synthesized images are sufficient to learn the 3D human-object spatial relations. We present multiple strategies to leverage the synthesized images, including (1) the first method to leverage a generative image model for 3D human-object spatial relation learning; (2) a framework to reason about the 3D spatial relations from inconsistent 2D cues in a self-supervised manner via 3D occupancy reasoning with pose canonicalization; (3) semantic clustering to disambiguate different types of interactions with the same object types; and (4) a novel metric to assess the quality of 3D spatial learning of interaction.
Make A Long Image Short: Adaptive Token Length for Vision Transformers
Jul 05, 2023The vision transformer is a model that breaks down each image into a sequence of tokens with a fixed length and processes them similarly to words in natural language processing. Although increasing the number of tokens typically results in better performance, it also leads to a considerable increase in computational cost. Motivated by the saying "A picture is worth a thousand words," we propose an innovative approach to accelerate the ViT model by shortening long images. Specifically, we introduce a method for adaptively assigning token length for each image at test time to accelerate inference speed. First, we train a Resizable-ViT (ReViT) model capable of processing input with diverse token lengths. Next, we extract token-length labels from ReViT that indicate the minimum number of tokens required to achieve accurate predictions. We then use these labels to train a lightweight Token-Length Assigner (TLA) that allocates the optimal token length for each image during inference. The TLA enables ReViT to process images with the minimum sufficient number of tokens, reducing token numbers in the ViT model and improving inference speed. Our approach is general and compatible with modern vision transformer architectures, significantly reducing computational costs. We verified the effectiveness of our methods on multiple representative ViT models on image classification and action recognition.
WaveMixSR: A Resource-efficient Neural Network for Image Super-resolution
Jul 01, 2023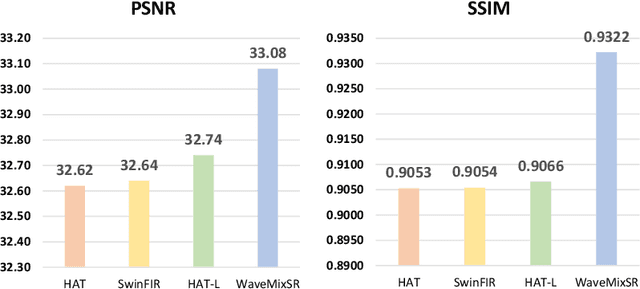
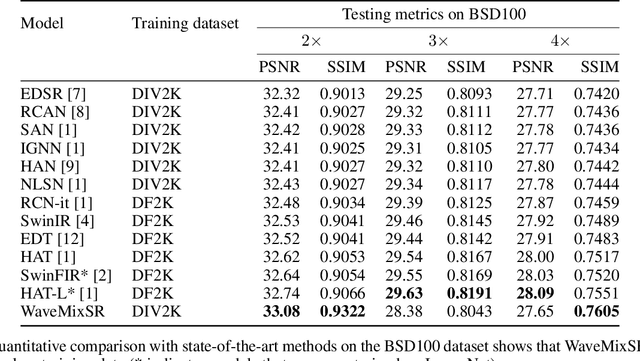
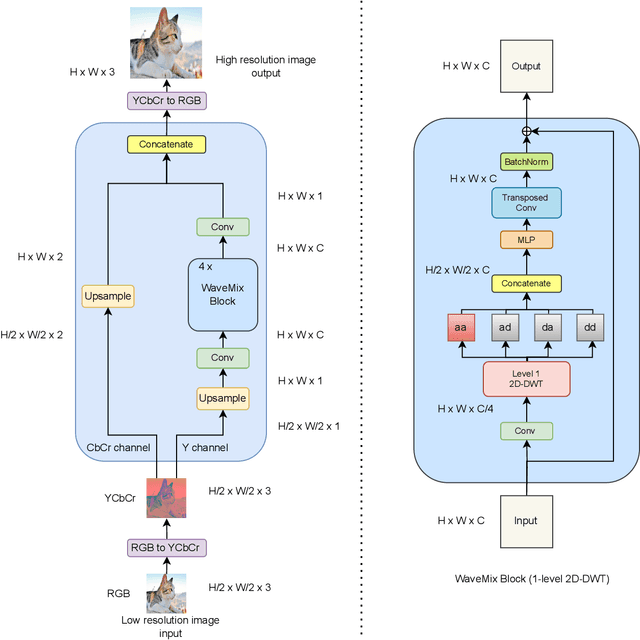

Image super-resolution research recently been dominated by transformer models which need higher computational resources than CNNs due to the quadratic complexity of self-attention. We propose a new neural network -- WaveMixSR -- for image super-resolution based on WaveMix architecture which uses a 2D-discrete wavelet transform for spatial token-mixing. Unlike transformer-based models, WaveMixSR does not unroll the image as a sequence of pixels/patches. It uses the inductive bias of convolutions along with the lossless token-mixing property of wavelet transform to achieve higher performance while requiring fewer resources and training data. We compare the performance of our network with other state-of-the-art methods for image super-resolution. Our experiments show that WaveMixSR achieves competitive performance in all datasets and reaches state-of-the-art performance in the BSD100 dataset on multiple super-resolution tasks. Our model is able to achieve this performance using less training data and computational resources while maintaining high parameter efficiency compared to current state-of-the-art models.
Retinex-based Image Denoising / Contrast Enhancement using Gradient Graph Laplacian Regularizer
Jul 05, 2023


Images captured in poorly lit conditions are often corrupted by acquisition noise. Leveraging recent advances in graph-based regularization, we propose a fast Retinex-based restoration scheme that denoises and contrast-enhances an image. Specifically, by Retinex theory we first assume that each image pixel is a multiplication of its reflectance and illumination components. We next assume that the reflectance and illumination components are piecewise constant (PWC) and continuous piecewise planar (PWP) signals, which can be recovered via graph Laplacian regularizer (GLR) and gradient graph Laplacian regularizer (GGLR) respectively. We formulate quadratic objectives regularized by GLR and GGLR, which are minimized alternately until convergence by solving linear systems -- with improved condition numbers via proposed preconditioners -- via conjugate gradient (CG) efficiently. Experimental results show that our algorithm achieves competitive visual image quality while reducing computation complexity noticeably.
A Theory of Topological Derivatives for Inverse Rendering of Geometry
Aug 19, 2023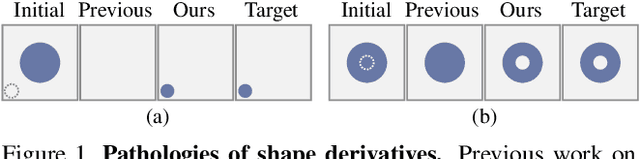
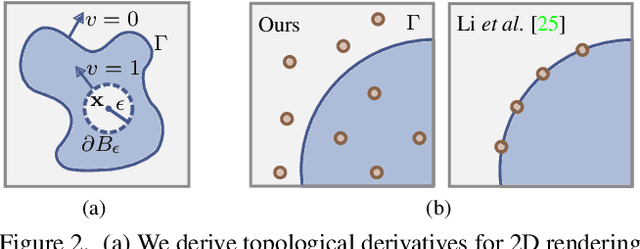
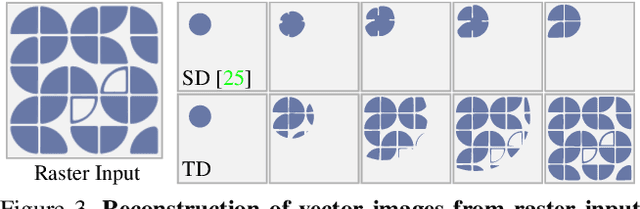

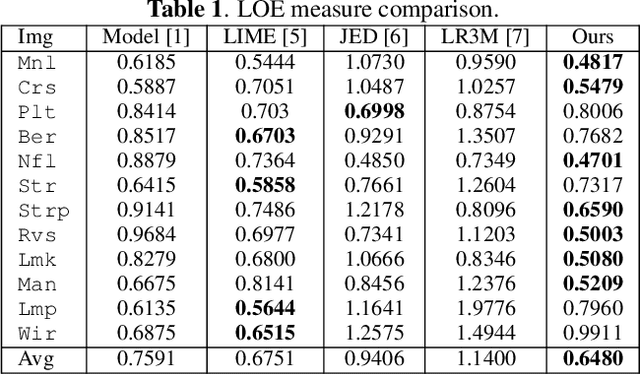
We introduce a theoretical framework for differentiable surface evolution that allows discrete topology changes through the use of topological derivatives for variational optimization of image functionals. While prior methods for inverse rendering of geometry rely on silhouette gradients for topology changes, such signals are sparse. In contrast, our theory derives topological derivatives that relate the introduction of vanishing holes and phases to changes in image intensity. As a result, we enable differentiable shape perturbations in the form of hole or phase nucleation. We validate the proposed theory with optimization of closed curves in 2D and surfaces in 3D to lend insights into limitations of current methods and enable improved applications such as image vectorization, vector-graphics generation from text prompts, single-image reconstruction of shape ambigrams and multi-view 3D reconstruction.