 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures
Sep 17, 2023

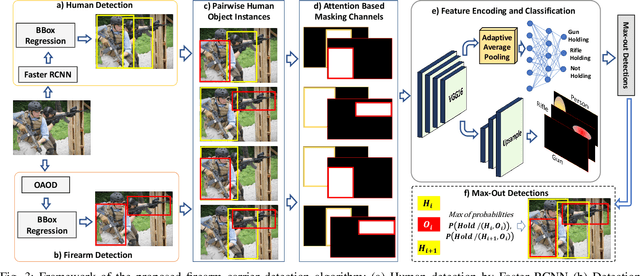
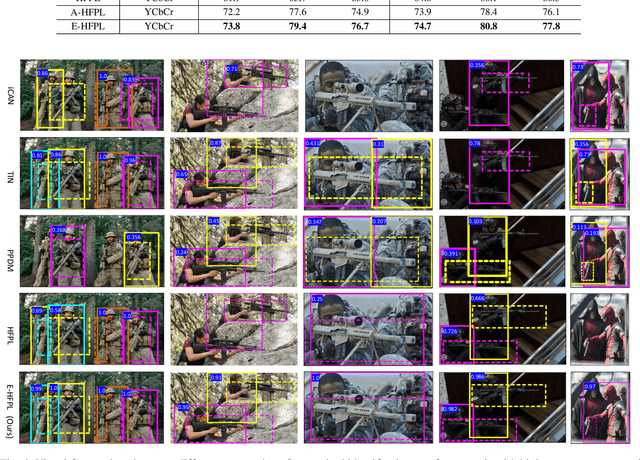

Detecting firearms and accurately localizing individuals carrying them in images or videos is of paramount importance in security, surveillance, and content customization. However, this task presents significant challenges in complex environments due to clutter and the diverse shapes of firearms. To address this problem, we propose a novel approach that leverages human-firearm interaction information, which provides valuable clues for localizing firearm carriers. Our approach incorporates an attention mechanism that effectively distinguishes humans and firearms from the background by focusing on relevant areas. Additionally, we introduce a saliency-driven locality-preserving constraint to learn essential features while preserving foreground information in the input image. By combining these components, our approach achieves exceptional results on a newly proposed dataset. To handle inputs of varying sizes, we pass paired human-firearm instances with attention masks as channels through a deep network for feature computation, utilizing an adaptive average pooling layer. We extensively evaluate our approach against existing methods in human-object interaction detection and achieve significant results (AP=77.8\%) compared to the baseline approach (AP=63.1\%). This demonstrates the effectiveness of leveraging attention mechanisms and saliency-driven locality preservation for accurate human-firearm interaction detection. Our findings contribute to advancing the fields of security and surveillance, enabling more efficient firearm localization and identification in diverse scenarios.
Balanced Face Dataset: Guiding StyleGAN to Generate Labeled Synthetic Face Image Dataset for Underrepresented Group
Aug 07, 2023
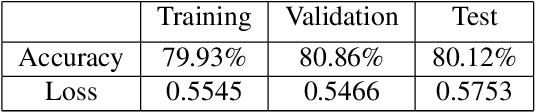
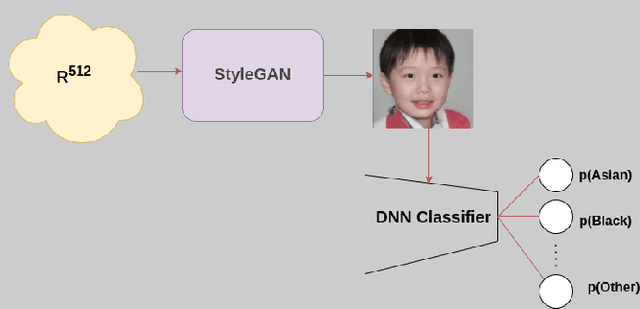

For a machine learning model to generalize effectively to unseen data within a particular problem domain, it is well-understood that the data needs to be of sufficient size and representative of real-world scenarios. Nonetheless, real-world datasets frequently have overrepresented and underrepresented groups. One solution to mitigate bias in machine learning is to leverage a diverse and representative dataset. Training a model on a dataset that covers all demographics is crucial to reducing bias in machine learning. However, collecting and labeling large-scale datasets has been challenging, prompting the use of synthetic data generation and active labeling to decrease the costs of manual labeling. The focus of this study was to generate a robust face image dataset using the StyleGAN model. In order to achieve a balanced distribution of the dataset among different demographic groups, a synthetic dataset was created by controlling the generation process of StyleGaN and annotated for different downstream tasks.
In-Style: Bridging Text and Uncurated Videos with Style Transfer for Text-Video Retrieval
Sep 16, 2023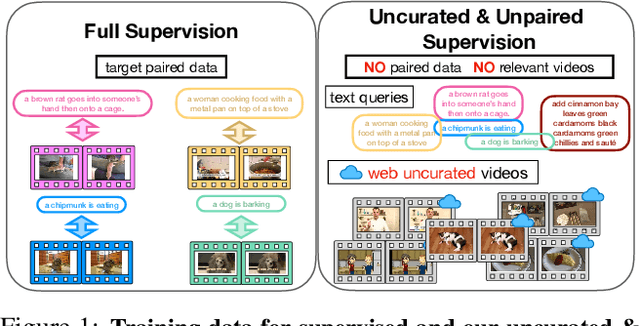

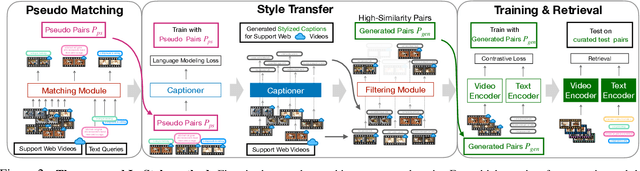
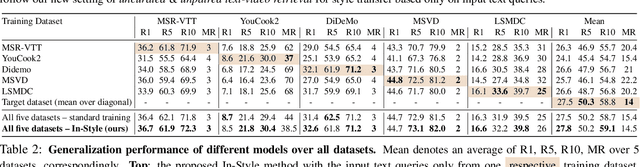
Large-scale noisy web image-text datasets have been proven to be efficient for learning robust vision-language models. However, when transferring them to the task of video retrieval, models still need to be fine-tuned on hand-curated paired text-video data to adapt to the diverse styles of video descriptions. To address this problem without the need for hand-annotated pairs, we propose a new setting, text-video retrieval with uncurated & unpaired data, that during training utilizes only text queries together with uncurated web videos without any paired text-video data. To this end, we propose an approach, In-Style, that learns the style of the text queries and transfers it to uncurated web videos. Moreover, to improve generalization, we show that one model can be trained with multiple text styles. To this end, we introduce a multi-style contrastive training procedure that improves the generalizability over several datasets simultaneously. We evaluate our model on retrieval performance over multiple datasets to demonstrate the advantages of our style transfer framework on the new task of uncurated & unpaired text-video retrieval and improve state-of-the-art performance on zero-shot text-video retrieval.
Semantics-aware LiDAR-Only Pseudo Point Cloud Generation for 3D Object Detection
Sep 16, 2023
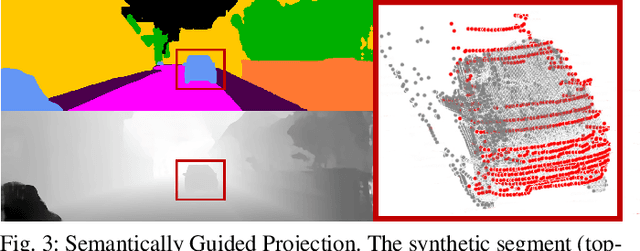

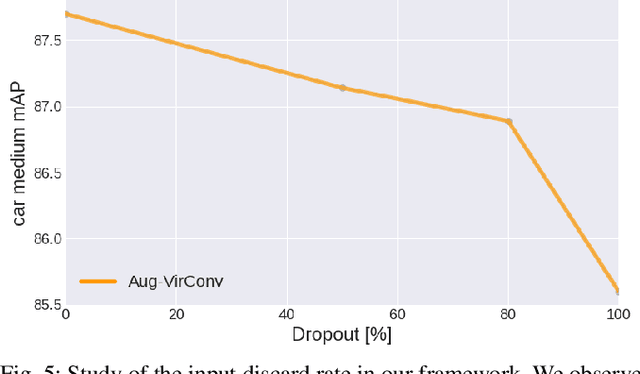
Although LiDAR sensors are crucial for autonomous systems due to providing precise depth information, they struggle with capturing fine object details, especially at a distance, due to sparse and non-uniform data. Recent advances introduced pseudo-LiDAR, i.e., synthetic dense point clouds, using additional modalities such as cameras to enhance 3D object detection. We present a novel LiDAR-only framework that augments raw scans with denser pseudo point clouds by solely relying on LiDAR sensors and scene semantics, omitting the need for cameras. Our framework first utilizes a segmentation model to extract scene semantics from raw point clouds, and then employs a multi-modal domain translator to generate synthetic image segments and depth cues without real cameras. This yields a dense pseudo point cloud enriched with semantic information. We also introduce a new semantically guided projection method, which enhances detection performance by retaining only relevant pseudo points. We applied our framework to different advanced 3D object detection methods and reported up to 2.9% performance upgrade. We also obtained comparable results on the KITTI 3D object detection dataset, in contrast to other state-of-the-art LiDAR-only detectors.
Learning Nuclei Representations with Masked Image Modelling
Jun 29, 2023Masked image modelling (MIM) is a powerful self-supervised representation learning paradigm, whose potential has not been widely demonstrated in medical image analysis. In this work, we show the capacity of MIM to capture rich semantic representations of Haemotoxylin & Eosin (H&E)-stained images at the nuclear level. Inspired by Bidirectional Encoder representation from Image Transformers (BEiT), we split the images into smaller patches and generate corresponding discrete visual tokens. In addition to the regular grid-based patches, typically used in visual Transformers, we introduce patches of individual cell nuclei. We propose positional encoding of the irregular distribution of these structures within an image. We pre-train the model in a self-supervised manner on H&E-stained whole-slide images of diffuse large B-cell lymphoma, where cell nuclei have been segmented. The pre-training objective is to recover the original discrete visual tokens of the masked image on the one hand, and to reconstruct the visual tokens of the masked object instances on the other. Coupling these two pre-training tasks allows us to build powerful, context-aware representations of nuclei. Our model generalizes well and can be fine-tuned on downstream classification tasks, achieving improved cell classification accuracy on PanNuke dataset by more than 5% compared to current instance segmentation methods.
AnyOKP: One-Shot and Instance-Aware Object Keypoint Extraction with Pretrained ViT
Sep 15, 2023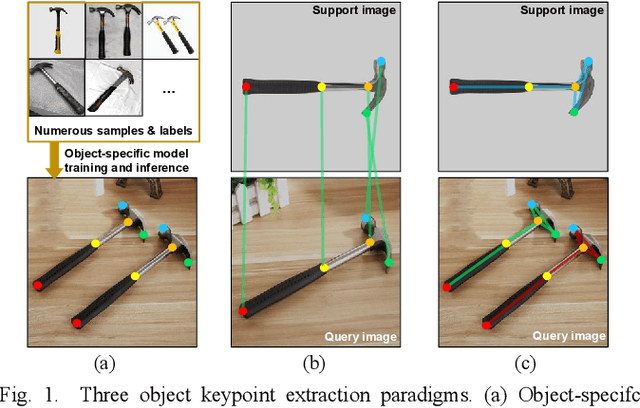
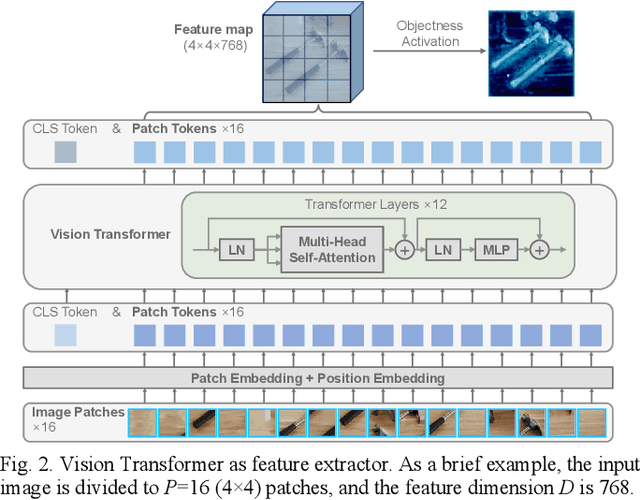
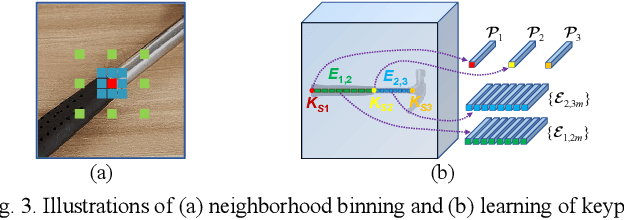
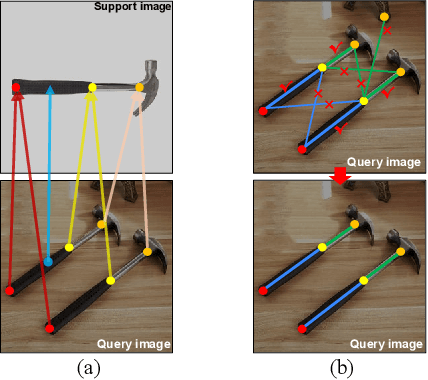
Towards flexible object-centric visual perception, we propose a one-shot instance-aware object keypoint (OKP) extraction approach, AnyOKP, which leverages the powerful representation ability of pretrained vision transformer (ViT), and can obtain keypoints on multiple object instances of arbitrary category after learning from a support image. An off-the-shelf petrained ViT is directly deployed for generalizable and transferable feature extraction, which is followed by training-free feature enhancement. The best-prototype pairs (BPPs) are searched for in support and query images based on appearance similarity, to yield instance-unaware candidate keypoints.Then, the entire graph with all candidate keypoints as vertices are divided to sub-graphs according to the feature distributions on the graph edges. Finally, each sub-graph represents an object instance. AnyOKP is evaluated on real object images collected with the cameras of a robot arm, a mobile robot, and a surgical robot, which not only demonstrates the cross-category flexibility and instance awareness, but also show remarkable robustness to domain shift and viewpoint change.
ShaDocFormer: A Shadow-attentive Threshold Detector with Cascaded Fusion Refiner for document shadow removal
Sep 14, 2023
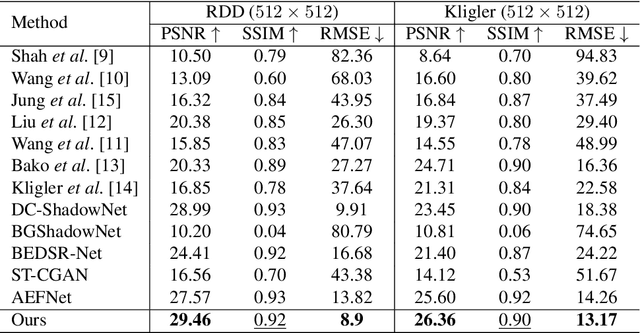
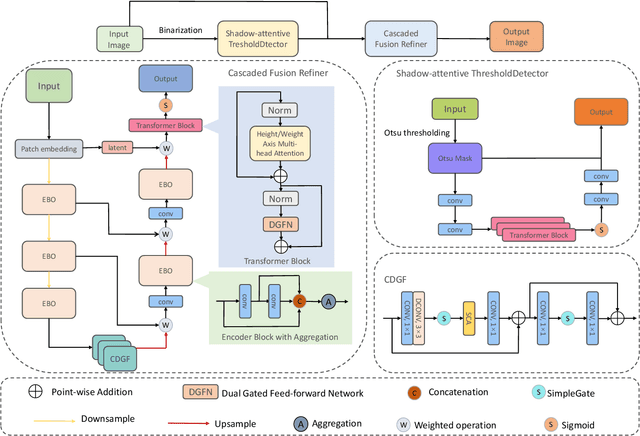
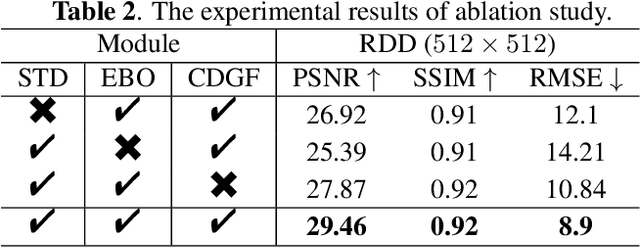
Document shadow is a common issue that arise when capturing documents using mobile devices, which significantly impacts the readability. Current methods encounter various challenges including inaccurate detection of shadow masks and estimation of illumination. In this paper, we propose ShaDocFormer, a Transformer-based architecture that integrates traditional methodologies and deep learning techniques to tackle the problem of document shadow removal. The ShaDocFormer architecture comprises two components: the Shadow-attentive Threshold Detector (STD) and the Cascaded Fusion Refiner (CFR). The STD module employs a traditional thresholding technique and leverages the attention mechanism of the Transformer to gather global information, thereby enabling precise detection of shadow masks. The cascaded and aggregative structure of the CFR module facilitates a coarse-to-fine restoration process for the entire image. As a result, ShaDocFormer excels in accurately detecting and capturing variations in both shadow and illumination, thereby enabling effective removal of shadows. Extensive experiments demonstrate that ShaDocFormer outperforms current state-of-the-art methods in both qualitative and quantitative measurements.
Identifying Interpretable Subspaces in Image Representations
Jul 20, 2023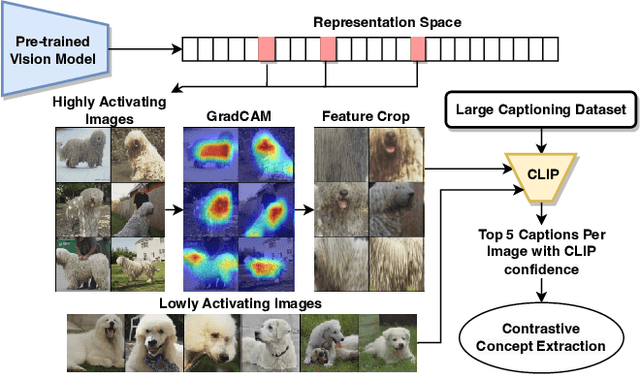
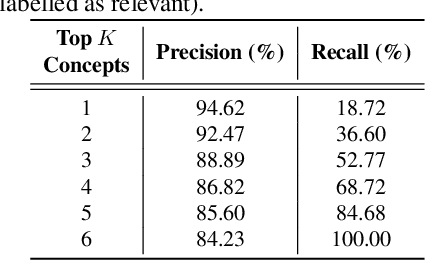
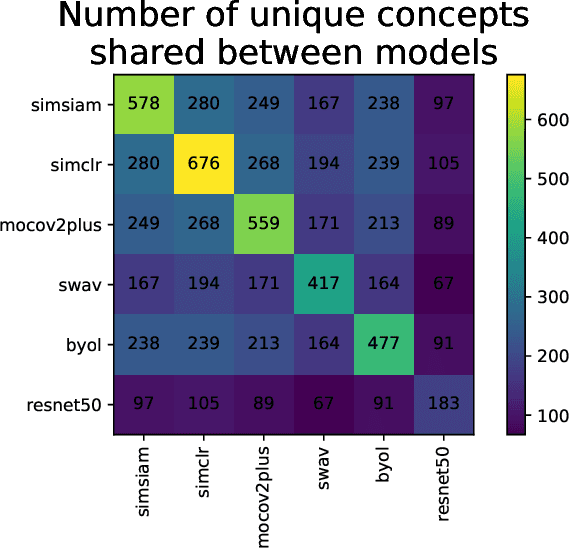

We propose Automatic Feature Explanation using Contrasting Concepts (FALCON), an interpretability framework to explain features of image representations. For a target feature, FALCON captions its highly activating cropped images using a large captioning dataset (like LAION-400m) and a pre-trained vision-language model like CLIP. Each word among the captions is scored and ranked leading to a small number of shared, human-understandable concepts that closely describe the target feature. FALCON also applies contrastive interpretation using lowly activating (counterfactual) images, to eliminate spurious concepts. Although many existing approaches interpret features independently, we observe in state-of-the-art self-supervised and supervised models, that less than 20% of the representation space can be explained by individual features. We show that features in larger spaces become more interpretable when studied in groups and can be explained with high-order scoring concepts through FALCON. We discuss how extracted concepts can be used to explain and debug failures in downstream tasks. Finally, we present a technique to transfer concepts from one (explainable) representation space to another unseen representation space by learning a simple linear transformation.
High-resolution 3D Maps of Left Atrial Displacements using an Unsupervised Image Registration Neural Network
Sep 05, 2023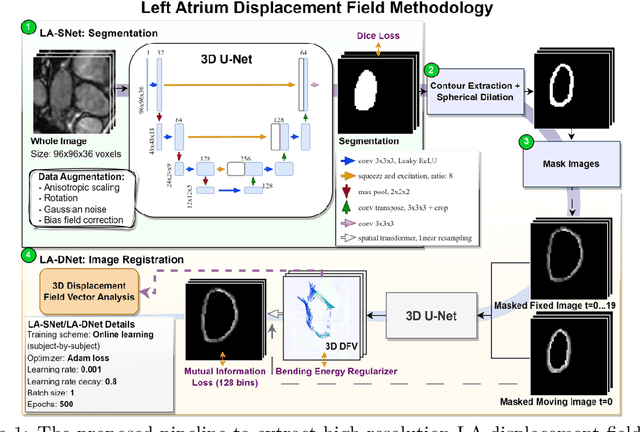
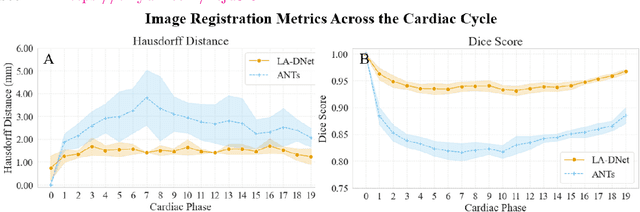
Functional analysis of the left atrium (LA) plays an increasingly important role in the prognosis and diagnosis of cardiovascular diseases. Echocardiography-based measurements of LA dimensions and strains are useful biomarkers, but they provide an incomplete picture of atrial deformations. High-resolution dynamic magnetic resonance images (Cine MRI) offer the opportunity to examine LA motion and deformation in 3D, at higher spatial resolution and with full LA coverage. However, there are no dedicated tools to automatically characterise LA motion in 3D. Thus, we propose a tool that automatically segments the LA and extracts the displacement fields across the cardiac cycle. The pipeline is able to accurately track the LA wall across the cardiac cycle with an average Hausdorff distance of $2.51 \pm 1.3~mm$ and Dice score of $0.96 \pm 0.02$.
High Fidelity Image Counterfactuals with Probabilistic Causal Models
Jul 18, 2023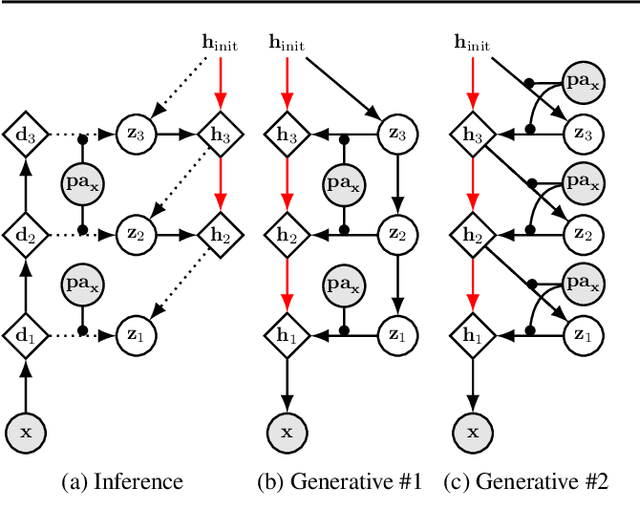
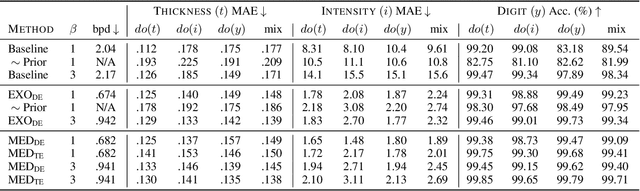
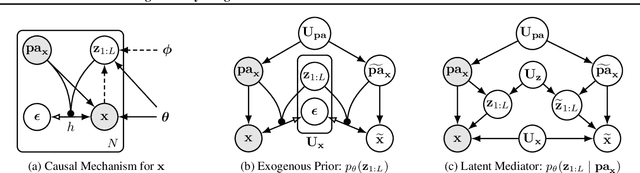
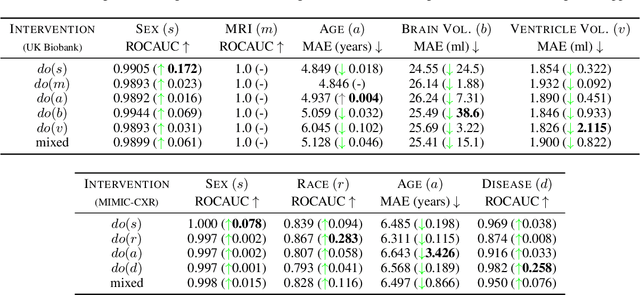
We present a general causal generative modelling framework for accurate estimation of high fidelity image counterfactuals with deep structural causal models. Estimation of interventional and counterfactual queries for high-dimensional structured variables, such as images, remains a challenging task. We leverage ideas from causal mediation analysis and advances in generative modelling to design new deep causal mechanisms for structured variables in causal models. Our experiments demonstrate that our proposed mechanisms are capable of accurate abduction and estimation of direct, indirect and total effects as measured by axiomatic soundness of counterfactuals.