 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Adaptive Spatial-Temporal Local Feature Difference Method for Infrared Small-moving Target Detection
Sep 05, 2023
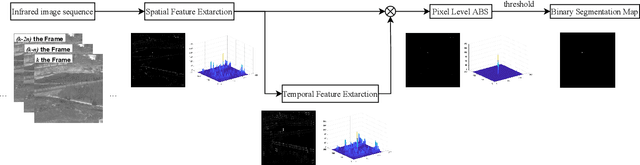

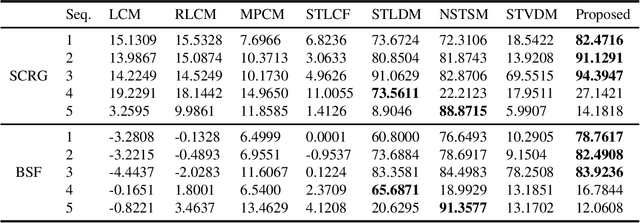
Detecting small moving targets accurately in infrared (IR) image sequences is a significant challenge. To address this problem, we propose a novel method called spatial-temporal local feature difference (STLFD) with adaptive background suppression (ABS). Our approach utilizes filters in the spatial and temporal domains and performs pixel-level ABS on the output to enhance the contrast between the target and the background. The proposed method comprises three steps. First, we obtain three temporal frame images based on the current frame image and extract two feature maps using the designed spatial domain and temporal domain filters. Next, we fuse the information of the spatial domain and temporal domain to produce the spatial-temporal feature maps and suppress noise using our pixel-level ABS module. Finally, we obtain the segmented binary map by applying a threshold. Our experimental results demonstrate that the proposed method outperforms existing state-of-the-art methods for infrared small-moving target detection.
Predicting masked tokens in stochastic locations improves masked image modeling
Jul 31, 2023
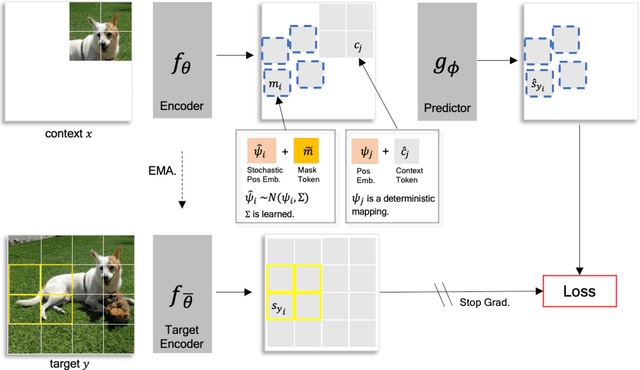
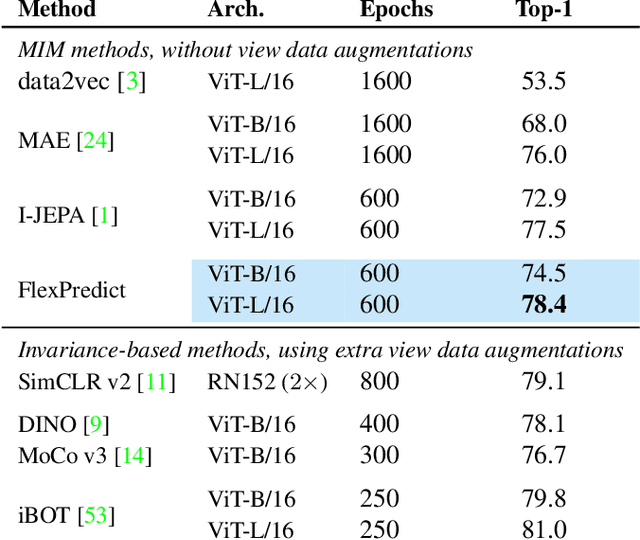
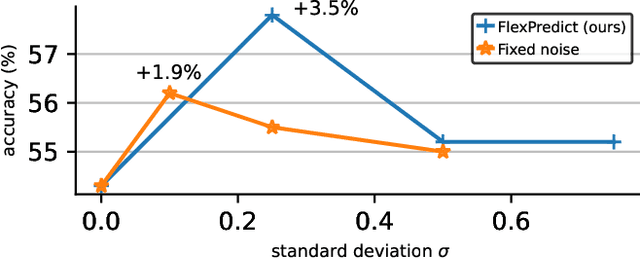
Self-supervised learning is a promising paradigm in deep learning that enables learning from unlabeled data by constructing pretext tasks that require learning useful representations. In natural language processing, the dominant pretext task has been masked language modeling (MLM), while in computer vision there exists an equivalent called Masked Image Modeling (MIM). However, MIM is challenging because it requires predicting semantic content in accurate locations. E.g, given an incomplete picture of a dog, we can guess that there is a tail, but we cannot determine its exact location. In this work, we propose FlexPredict, a stochastic model that addresses this challenge by incorporating location uncertainty into the model. Specifically, we condition the model on stochastic masked token positions to guide the model toward learning features that are more robust to location uncertainties. Our approach improves downstream performance on a range of tasks, e.g, compared to MIM baselines, FlexPredict boosts ImageNet linear probing by 1.6% with ViT-B and by 2.5% for semi-supervised video segmentation using ViT-L.
Focus the Discrepancy: Intra- and Inter-Correlation Learning for Image Anomaly Detection
Aug 06, 2023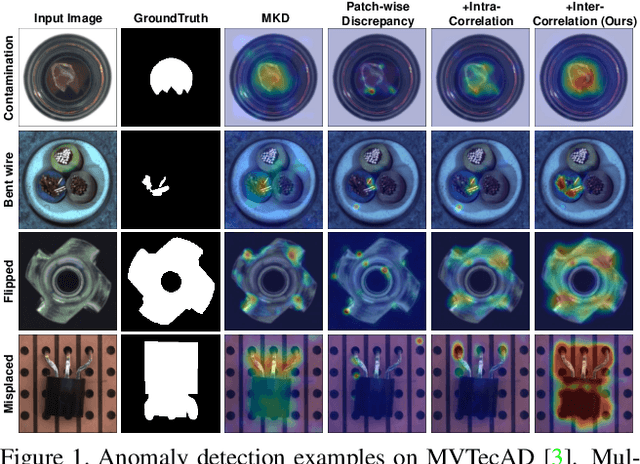
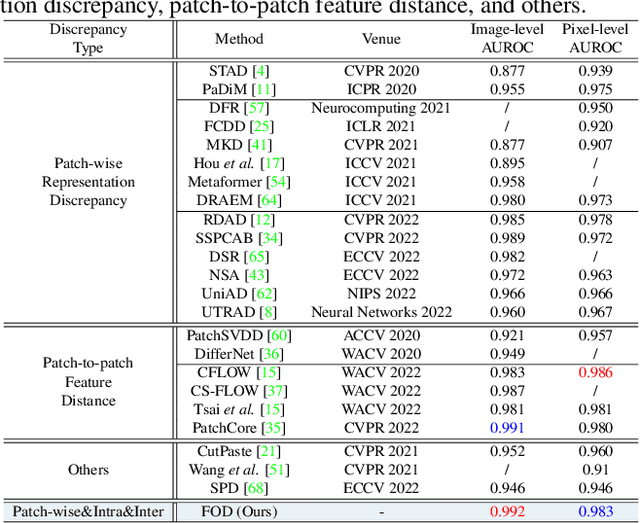
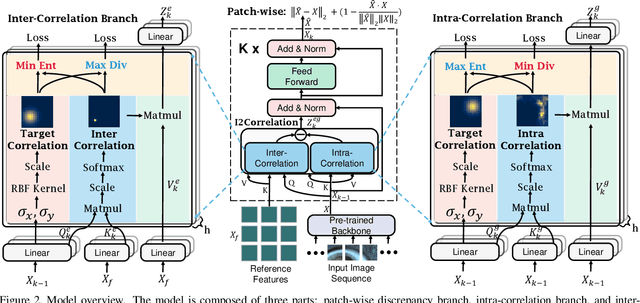
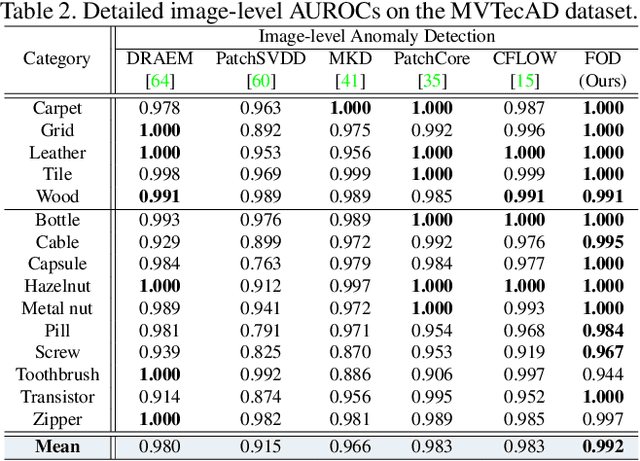
Humans recognize anomalies through two aspects: larger patch-wise representation discrepancies and weaker patch-to-normal-patch correlations. However, the previous AD methods didn't sufficiently combine the two complementary aspects to design AD models. To this end, we find that Transformer can ideally satisfy the two aspects as its great power in the unified modeling of patch-wise representations and patch-to-patch correlations. In this paper, we propose a novel AD framework: FOcus-the-Discrepancy (FOD), which can simultaneously spot the patch-wise, intra- and inter-discrepancies of anomalies. The major characteristic of our method is that we renovate the self-attention maps in transformers to Intra-Inter-Correlation (I2Correlation). The I2Correlation contains a two-branch structure to first explicitly establish intra- and inter-image correlations, and then fuses the features of two-branch to spotlight the abnormal patterns. To learn the intra- and inter-correlations adaptively, we propose the RBF-kernel-based target-correlations as learning targets for self-supervised learning. Besides, we introduce an entropy constraint strategy to solve the mode collapse issue in optimization and further amplify the normal-abnormal distinguishability. Extensive experiments on three unsupervised real-world AD benchmarks show the superior performance of our approach. Code will be available at https://github.com/xcyao00/FOD.
PatchCT: Aligning Patch Set and Label Set with Conditional Transport for Multi-Label Image Classification
Jul 18, 2023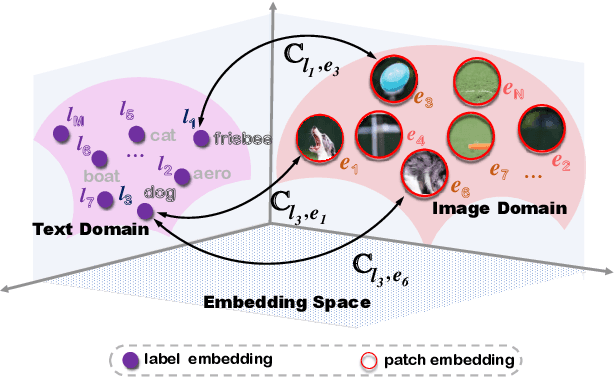
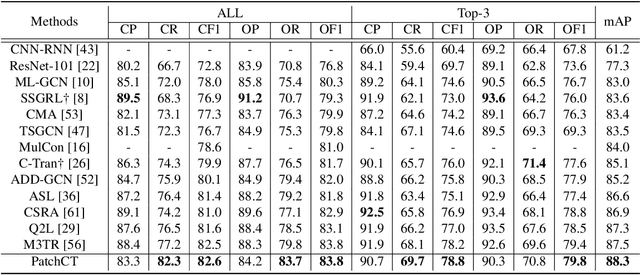
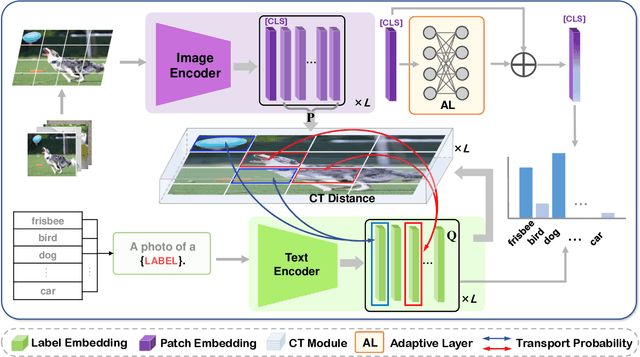
Multi-label image classification is a prediction task that aims to identify more than one label from a given image. This paper considers the semantic consistency of the latent space between the visual patch and linguistic label domains and introduces the conditional transport (CT) theory to bridge the acknowledged gap. While recent cross-modal attention-based studies have attempted to align such two representations and achieved impressive performance, they required carefully-designed alignment modules and extra complex operations in the attention computation. We find that by formulating the multi-label classification as a CT problem, we can exploit the interactions between the image and label efficiently by minimizing the bidirectional CT cost. Specifically, after feeding the images and textual labels into the modality-specific encoders, we view each image as a mixture of patch embeddings and a mixture of label embeddings, which capture the local region features and the class prototypes, respectively. CT is then employed to learn and align those two semantic sets by defining the forward and backward navigators. Importantly, the defined navigators in CT distance model the similarities between patches and labels, which provides an interpretable tool to visualize the learned prototypes. Extensive experiments on three public image benchmarks show that the proposed model consistently outperforms the previous methods. Our code is available at https://github.com/keepgoingjkg/PatchCT.
DRM-IR: Task-Adaptive Deep Unfolding Network for All-In-One Image Restoration
Jul 15, 2023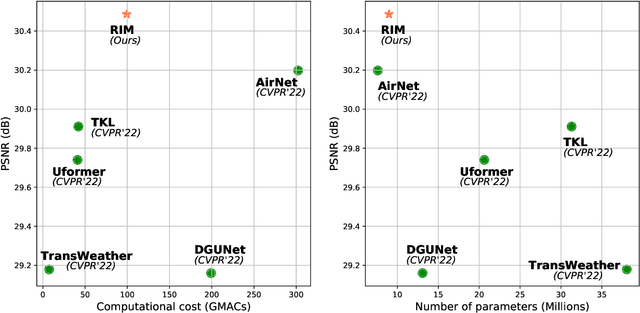
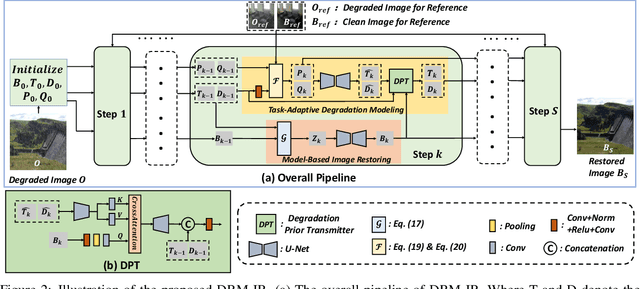
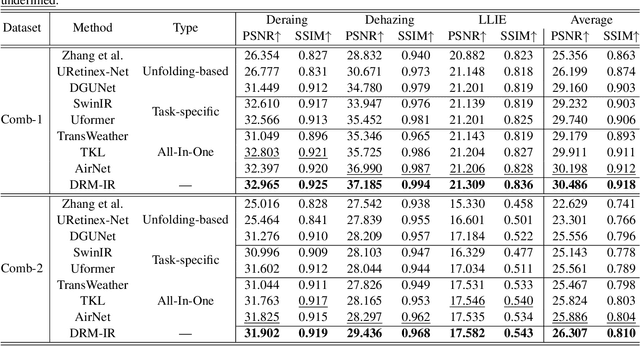
Existing All-In-One image restoration (IR) methods usually lack flexible modeling on various types of degradation, thus impeding the restoration performance. To achieve All-In-One IR with higher task dexterity, this work proposes an efficient Dynamic Reference Modeling paradigm (DRM-IR), which consists of task-adaptive degradation modeling and model-based image restoring. Specifically, these two subtasks are formalized as a pair of entangled reference-based maximum a posteriori (MAP) inferences, which are optimized synchronously in an unfolding-based manner. With the two cascaded subtasks, DRM-IR first dynamically models the task-specific degradation based on a reference image pair and further restores the image with the collected degradation statistics. Besides, to bridge the semantic gap between the reference and target degraded images, we further devise a Degradation Prior Transmitter (DPT) that restrains the instance-specific feature differences. DRM-IR explicitly provides superior flexibility for All-in-One IR while being interpretable. Extensive experiments on multiple benchmark datasets show that our DRM-IR achieves state-of-the-art in All-In-One IR.
Revisiting Latent Space of GAN Inversion for Real Image Editing
Jul 18, 2023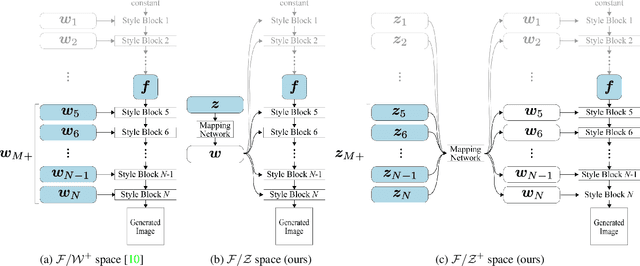


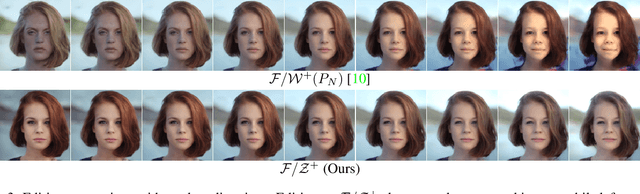
The exploration of the latent space in StyleGANs and GAN inversion exemplify impressive real-world image editing, yet the trade-off between reconstruction quality and editing quality remains an open problem. In this study, we revisit StyleGANs' hyperspherical prior $\mathcal{Z}$ and combine it with highly capable latent spaces to build combined spaces that faithfully invert real images while maintaining the quality of edited images. More specifically, we propose $\mathcal{F}/\mathcal{Z}^{+}$ space consisting of two subspaces: $\mathcal{F}$ space of an intermediate feature map of StyleGANs enabling faithful reconstruction and $\mathcal{Z}^{+}$ space of an extended StyleGAN prior supporting high editing quality. We project the real images into the proposed space to obtain the inverted codes, by which we then move along $\mathcal{Z}^{+}$, enabling semantic editing without sacrificing image quality. Comprehensive experiments show that $\mathcal{Z}^{+}$ can replace the most commonly-used $\mathcal{W}$, $\mathcal{W}^{+}$, and $\mathcal{S}$ spaces while preserving reconstruction quality, resulting in reduced distortion of edited images.
Active Learning for Semantic Segmentation with Multi-class Label Query
Sep 17, 2023This paper proposes a new active learning method for semantic segmentation. The core of our method lies in a new annotation query design. It samples informative local image regions (e.g., superpixels), and for each of such regions, asks an oracle for a multi-hot vector indicating all classes existing in the region. This multi-class labeling strategy is substantially more efficient than existing ones like segmentation, polygon, and even dominant class labeling in terms of annotation time per click. However, it introduces the class ambiguity issue in training since it assigns partial labels (i.e., a set of candidate classes) to individual pixels. We thus propose a new algorithm for learning semantic segmentation while disambiguating the partial labels in two stages. In the first stage, it trains a segmentation model directly with the partial labels through two new loss functions motivated by partial label learning and multiple instance learning. In the second stage, it disambiguates the partial labels by generating pixel-wise pseudo labels, which are used for supervised learning of the model. Equipped with a new acquisition function dedicated to the multi-class labeling, our method outperformed previous work on Cityscapes and PASCAL VOC 2012 while spending less annotation cost.
Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures
Sep 17, 2023
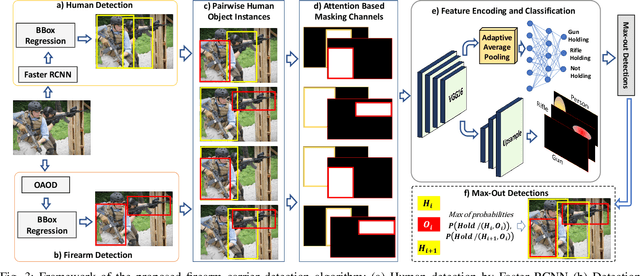
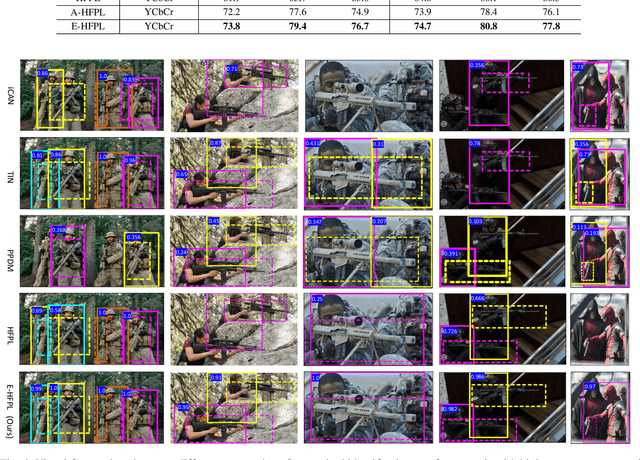

Detecting firearms and accurately localizing individuals carrying them in images or videos is of paramount importance in security, surveillance, and content customization. However, this task presents significant challenges in complex environments due to clutter and the diverse shapes of firearms. To address this problem, we propose a novel approach that leverages human-firearm interaction information, which provides valuable clues for localizing firearm carriers. Our approach incorporates an attention mechanism that effectively distinguishes humans and firearms from the background by focusing on relevant areas. Additionally, we introduce a saliency-driven locality-preserving constraint to learn essential features while preserving foreground information in the input image. By combining these components, our approach achieves exceptional results on a newly proposed dataset. To handle inputs of varying sizes, we pass paired human-firearm instances with attention masks as channels through a deep network for feature computation, utilizing an adaptive average pooling layer. We extensively evaluate our approach against existing methods in human-object interaction detection and achieve significant results (AP=77.8\%) compared to the baseline approach (AP=63.1\%). This demonstrates the effectiveness of leveraging attention mechanisms and saliency-driven locality preservation for accurate human-firearm interaction detection. Our findings contribute to advancing the fields of security and surveillance, enabling more efficient firearm localization and identification in diverse scenarios.
ICF-SRSR: Invertible scale-Conditional Function for Self-Supervised Real-world Single Image Super-Resolution
Jul 24, 2023
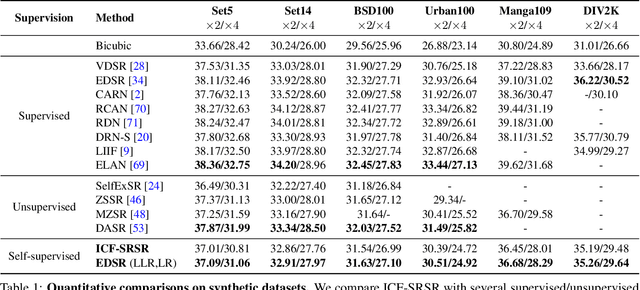
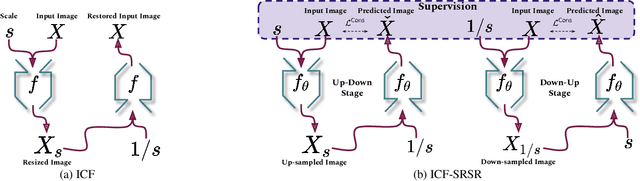
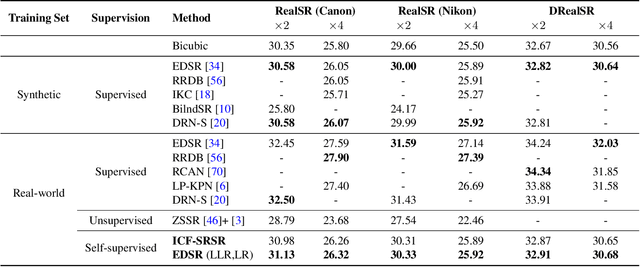
Single image super-resolution (SISR) is a challenging ill-posed problem that aims to up-sample a given low-resolution (LR) image to a high-resolution (HR) counterpart. Due to the difficulty in obtaining real LR-HR training pairs, recent approaches are trained on simulated LR images degraded by simplified down-sampling operators, e.g., bicubic. Such an approach can be problematic in practice because of the large gap between the synthesized and real-world LR images. To alleviate the issue, we propose a novel Invertible scale-Conditional Function (ICF), which can scale an input image and then restore the original input with different scale conditions. By leveraging the proposed ICF, we construct a novel self-supervised SISR framework (ICF-SRSR) to handle the real-world SR task without using any paired/unpaired training data. Furthermore, our ICF-SRSR can generate realistic and feasible LR-HR pairs, which can make existing supervised SISR networks more robust. Extensive experiments demonstrate the effectiveness of the proposed method in handling SISR in a fully self-supervised manner. Our ICF-SRSR demonstrates superior performance compared to the existing methods trained on synthetic paired images in real-world scenarios and exhibits comparable performance compared to state-of-the-art supervised/unsupervised methods on public benchmark datasets.
Analysing Gender Bias in Text-to-Image Models using Object Detection
Jul 16, 2023
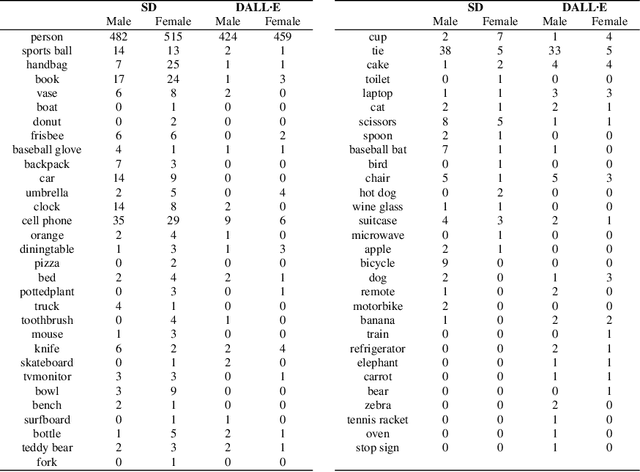
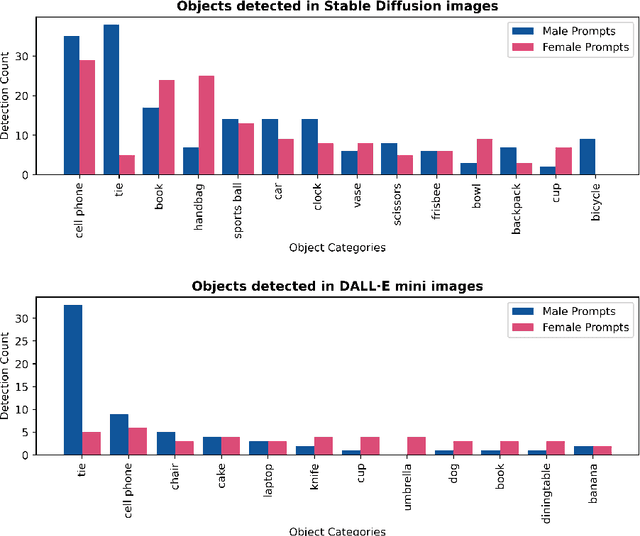
This work presents a novel strategy to measure bias in text-to-image models. Using paired prompts that specify gender and vaguely reference an object (e.g. "a man/woman holding an item") we can examine whether certain objects are associated with a certain gender. In analysing results from Stable Diffusion, we observed that male prompts generated objects such as ties, knives, trucks, baseball bats, and bicycles more frequently. On the other hand, female prompts were more likely to generate objects such as handbags, umbrellas, bowls, bottles, and cups. We hope that the method outlined here will be a useful tool for examining bias in text-to-image models.