 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VIGC: Visual Instruction Generation and Correction
Sep 11, 2023
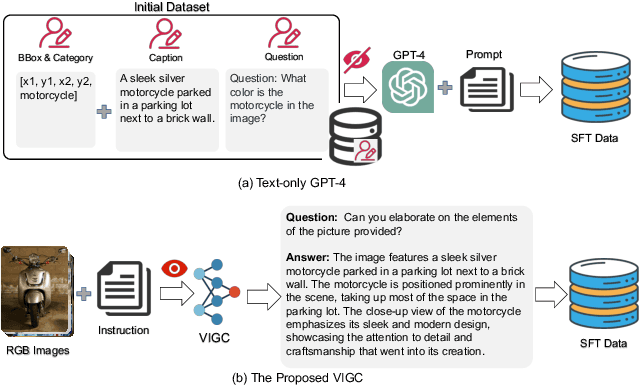
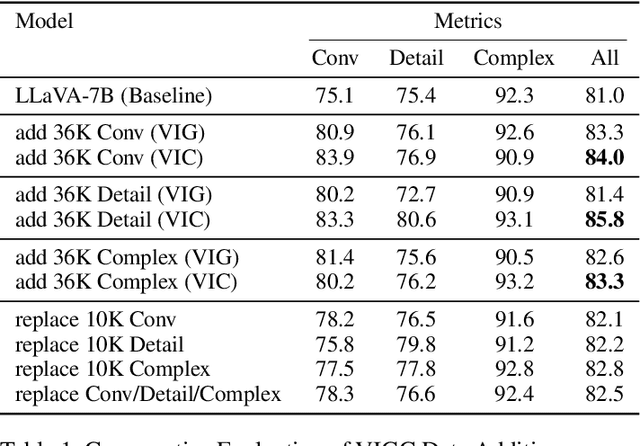
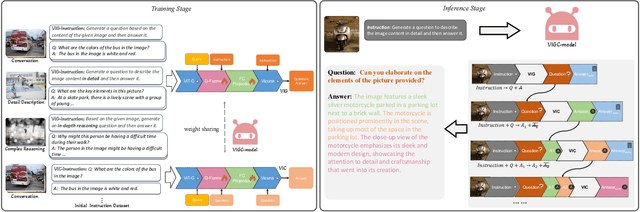

The integration of visual encoders and large language models (LLMs) has driven recent progress in multimodal large language models (MLLMs). However, the scarcity of high-quality instruction-tuning data for vision-language tasks remains a challenge. The current leading paradigm, such as LLaVA, relies on language-only GPT-4 to generate data, which requires pre-annotated image captions and detection bounding boxes, suffering from understanding image details. A practical solution to this problem would be to utilize the available multimodal large language models (MLLMs) to generate instruction data for vision-language tasks. However, it's worth noting that the currently accessible MLLMs are not as powerful as their LLM counterparts, as they tend to produce inadequate responses and generate false information. As a solution for addressing the current issue, this paper proposes the Visual Instruction Generation and Correction (VIGC) framework that enables multimodal large language models to generate instruction-tuning data and progressively enhance its quality on-the-fly. Specifically, Visual Instruction Generation (VIG) guides the vision-language model to generate diverse instruction-tuning data. To ensure generation quality, Visual Instruction Correction (VIC) adopts an iterative update mechanism to correct any inaccuracies in data produced by VIG, effectively reducing the risk of hallucination. Leveraging the diverse, high-quality data generated by VIGC, we finetune mainstream models and validate data quality based on various evaluations. Experimental results demonstrate that VIGC not only compensates for the shortcomings of language-only data generation methods, but also effectively enhances the benchmark performance. The models, datasets, and code are available at https://opendatalab.github.io/VIGC.
Sem-CS: Semantic CLIPStyler for Text-Based Image Style Transfer
Jul 12, 2023
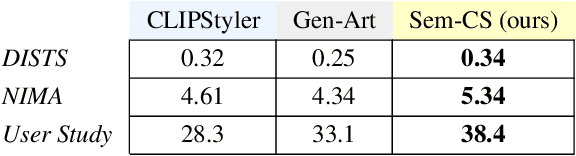
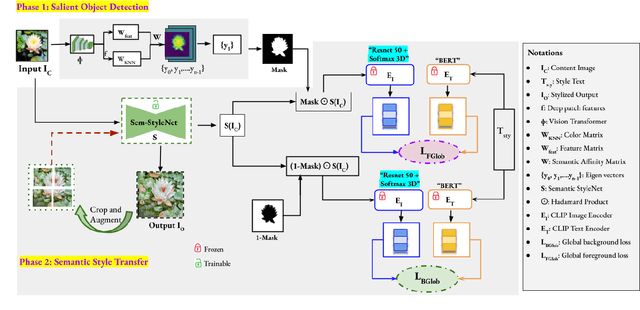
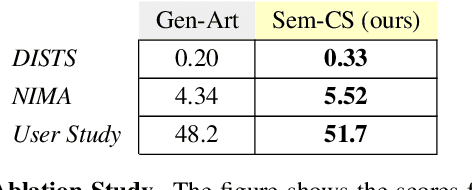
CLIPStyler demonstrated image style transfer with realistic textures using only a style text description (instead of requiring a reference style image). However, the ground semantics of objects in the style transfer output is lost due to style spill-over on salient and background objects (content mismatch) or over-stylization. To solve this, we propose Semantic CLIPStyler (Sem-CS), that performs semantic style transfer. Sem-CS first segments the content image into salient and non-salient objects and then transfers artistic style based on a given style text description. The semantic style transfer is achieved using global foreground loss (for salient objects) and global background loss (for non-salient objects). Our empirical results, including DISTS, NIMA and user study scores, show that our proposed framework yields superior qualitative and quantitative performance. Our code is available at github.com/chandagrover/sem-cs.
* 5 pages, 4 Figures, 2 Tables. arXiv admin note: substantial text overlap with arXiv:2303.06334
Parameter-Efficient Long-Tailed Recognition
Sep 18, 2023The "pre-training and fine-tuning" paradigm in addressing long-tailed recognition tasks has sparked significant interest since the emergence of large vision-language models like the contrastive language-image pre-training (CLIP). While previous studies have shown promise in adapting pre-trained models for these tasks, they often undesirably require extensive training epochs or additional training data to maintain good performance. In this paper, we propose PEL, a fine-tuning method that can effectively adapt pre-trained models to long-tailed recognition tasks in fewer than 20 epochs without the need for extra data. We first empirically find that commonly used fine-tuning methods, such as full fine-tuning and classifier fine-tuning, suffer from overfitting, resulting in performance deterioration on tail classes. To mitigate this issue, PEL introduces a small number of task-specific parameters by adopting the design of any existing parameter-efficient fine-tuning method. Additionally, to expedite convergence, PEL presents a novel semantic-aware classifier initialization technique derived from the CLIP textual encoder without adding any computational overhead. Our experimental results on four long-tailed datasets demonstrate that PEL consistently outperforms previous state-of-the-art approaches. The source code is available at https://github.com/shijxcs/PEL.
Face-Driven Zero-Shot Voice Conversion with Memory-based Face-Voice Alignment
Sep 18, 2023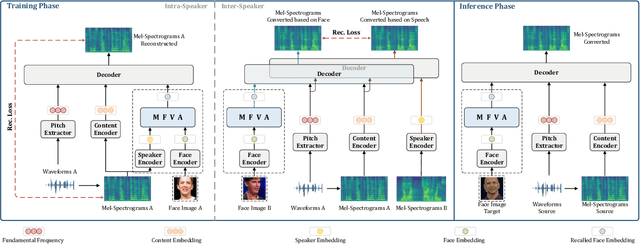
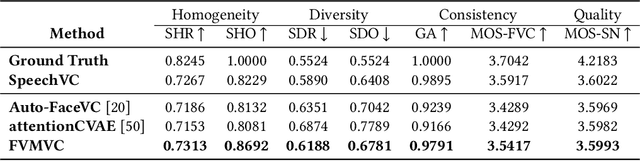
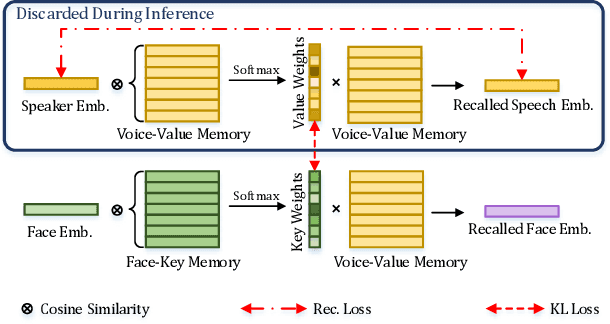
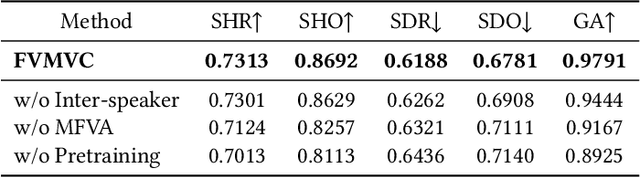
This paper presents a novel task, zero-shot voice conversion based on face images (zero-shot FaceVC), which aims at converting the voice characteristics of an utterance from any source speaker to a newly coming target speaker, solely relying on a single face image of the target speaker. To address this task, we propose a face-voice memory-based zero-shot FaceVC method. This method leverages a memory-based face-voice alignment module, in which slots act as the bridge to align these two modalities, allowing for the capture of voice characteristics from face images. A mixed supervision strategy is also introduced to mitigate the long-standing issue of the inconsistency between training and inference phases for voice conversion tasks. To obtain speaker-independent content-related representations, we transfer the knowledge from a pretrained zero-shot voice conversion model to our zero-shot FaceVC model. Considering the differences between FaceVC and traditional voice conversion tasks, systematic subjective and objective metrics are designed to thoroughly evaluate the homogeneity, diversity and consistency of voice characteristics controlled by face images. Through extensive experiments, we demonstrate the superiority of our proposed method on the zero-shot FaceVC task. Samples are presented on our demo website.
Can you text what is happening? Integrating pre-trained language encoders into trajectory prediction models for autonomous driving
Sep 13, 2023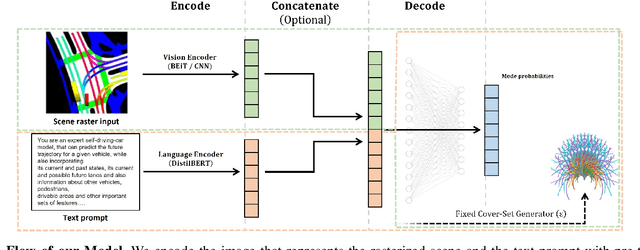

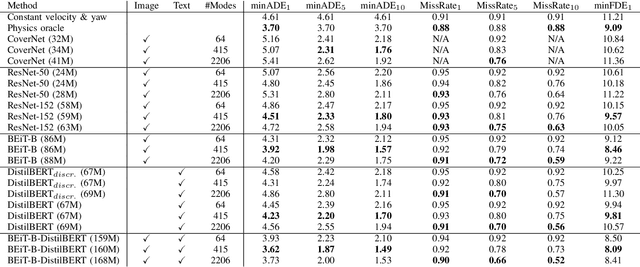
In autonomous driving tasks, scene understanding is the first step towards predicting the future behavior of the surrounding traffic participants. Yet, how to represent a given scene and extract its features are still open research questions. In this study, we propose a novel text-based representation of traffic scenes and process it with a pre-trained language encoder. First, we show that text-based representations, combined with classical rasterized image representations, lead to descriptive scene embeddings. Second, we benchmark our predictions on the nuScenes dataset and show significant improvements compared to baselines. Third, we show in an ablation study that a joint encoder of text and rasterized images outperforms the individual encoders confirming that both representations have their complementary strengths.
Feature Modulation Transformer: Cross-Refinement of Global Representation via High-Frequency Prior for Image Super-Resolution
Aug 12, 2023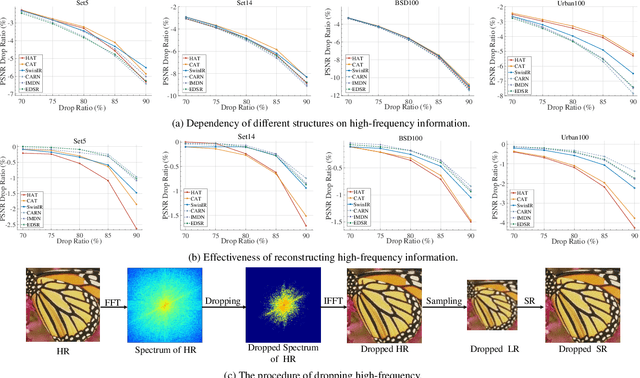
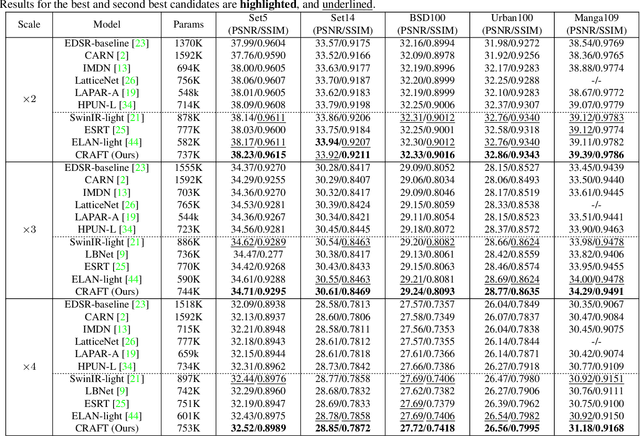
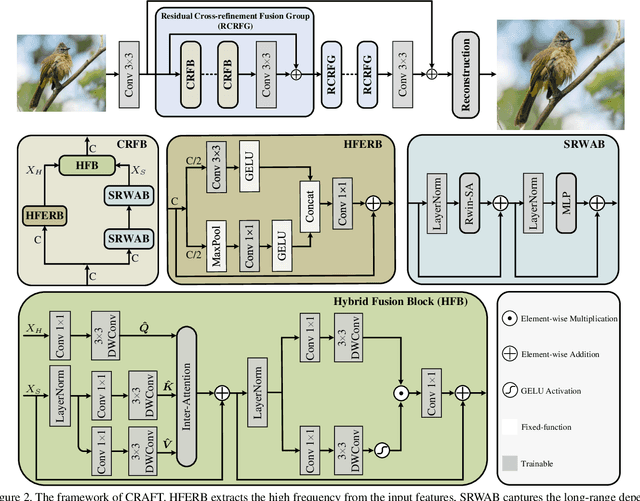
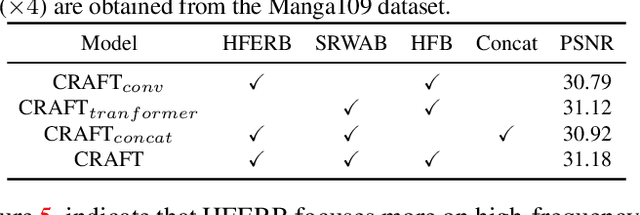
Transformer-based methods have exhibited remarkable potential in single image super-resolution (SISR) by effectively extracting long-range dependencies. However, most of the current research in this area has prioritized the design of transformer blocks to capture global information, while overlooking the importance of incorporating high-frequency priors, which we believe could be beneficial. In our study, we conducted a series of experiments and found that transformer structures are more adept at capturing low-frequency information, but have limited capacity in constructing high-frequency representations when compared to their convolutional counterparts. Our proposed solution, the cross-refinement adaptive feature modulation transformer (CRAFT), integrates the strengths of both convolutional and transformer structures. It comprises three key components: the high-frequency enhancement residual block (HFERB) for extracting high-frequency information, the shift rectangle window attention block (SRWAB) for capturing global information, and the hybrid fusion block (HFB) for refining the global representation. Our experiments on multiple datasets demonstrate that CRAFT outperforms state-of-the-art methods by up to 0.29dB while using fewer parameters. The source code will be made available at: https://github.com/AVC2-UESTC/CRAFT-SR.git.
A Novel Truncated Norm Regularization Method for Multi-channel Color Image Denoising
Jul 16, 2023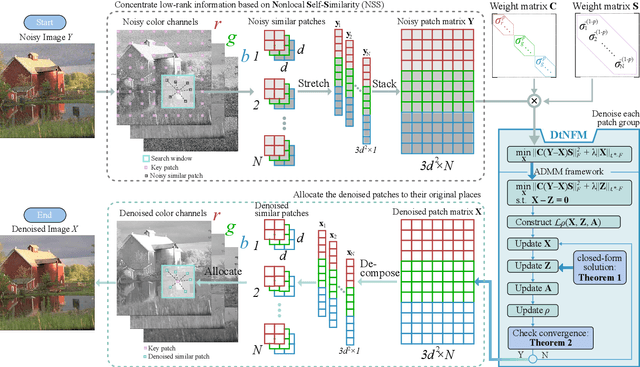
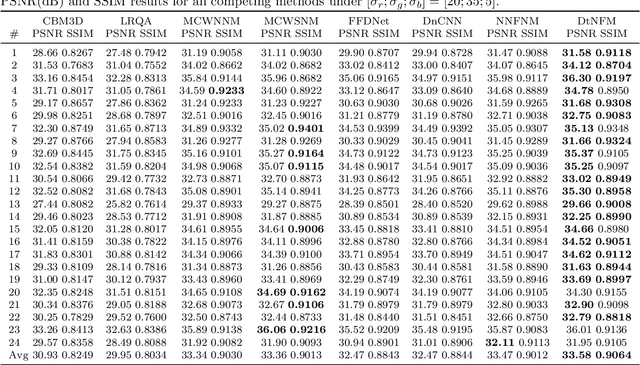
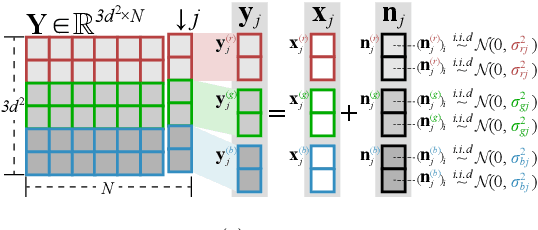
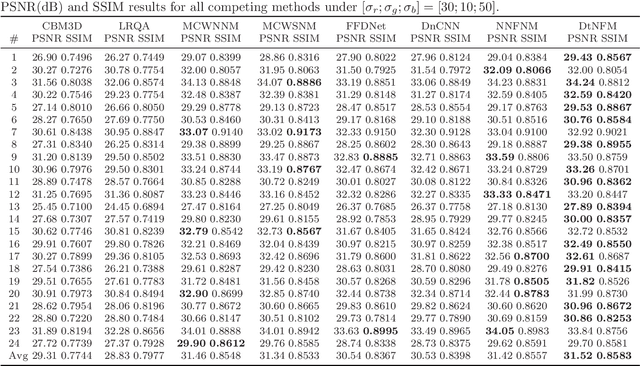
Due to the high flexibility and remarkable performance, low-rank approximation methods has been widely studied for color image denoising. However, those methods mostly ignore either the cross-channel difference or the spatial variation of noise, which limits their capacity in real world color image denoising. To overcome those drawbacks, this paper is proposed to denoise color images with a double-weighted truncated nuclear norm minus truncated Frobenius norm minimization (DtNFM) method. Through exploiting the nonlocal self-similarity of the noisy image, the similar structures are gathered and a series of similar patch matrices are constructed. For each group, the DtNFM model is conducted for estimating its denoised version. The denoised image would be obtained by concatenating all the denoised patch matrices. The proposed DtNFM model has two merits. First, it models and utilizes both the cross-channel difference and the spatial variation of noise. This provides sufficient flexibility for handling the complex distribution of noise in real world images. Second, the proposed DtNFM model provides a close approximation to the underlying clean matrix since it can treat different rank components flexibly. To solve the problem resulted from DtNFM model, an accurate and effective algorithm is proposed by exploiting the framework of the alternating direction method of multipliers (ADMM). The generated subproblems are discussed in detail. And their global optima can be easily obtained in closed-form. Rigorous mathematical derivation proves that the solution sequences generated by the algorithm converge to a single critical point. Extensive experiments on synthetic and real noise datasets demonstrate that the proposed method outperforms many state-of-the-art color image denoising methods.
Diffusion Models for Interferometric Satellite Aperture Radar
Aug 31, 2023Probabilistic Diffusion Models (PDMs) have recently emerged as a very promising class of generative models, achieving high performance in natural image generation. However, their performance relative to non-natural images, like radar-based satellite data, remains largely unknown. Generating large amounts of synthetic (and especially labelled) satellite data is crucial to implement deep-learning approaches for the processing and analysis of (interferometric) satellite aperture radar data. Here, we leverage PDMs to generate several radar-based satellite image datasets. We show that PDMs succeed in generating images with complex and realistic structures, but that sampling time remains an issue. Indeed, accelerated sampling strategies, which work well on simple image datasets like MNIST, fail on our radar datasets. We provide a simple and versatile open-source https://github.com/thomaskerdreux/PDM_SAR_InSAR_generation to train, sample and evaluate PDMs using any dataset on a single GPU.
Latent Painter
Sep 01, 2023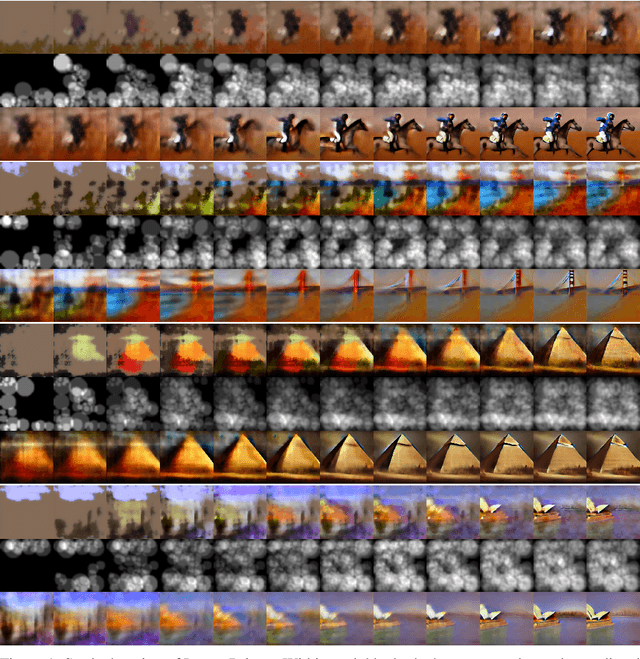



Latent diffusers revolutionized the generative AI and inspired creative art. When denoising the latent, the predicted original image at each step collectively animates the formation. However, the animation is limited by the denoising nature of the diffuser, and only renders a sharpening process. This work presents Latent Painter, which uses the latent as the canvas, and the diffuser predictions as the plan, to generate painting animation. Latent Painter also transits one generated image to another, which can happen between images from two different sets of checkpoints.
Do humans and Convolutional Neural Networks attend to similar areas during scene classification: Effects of task and image type
Jul 25, 2023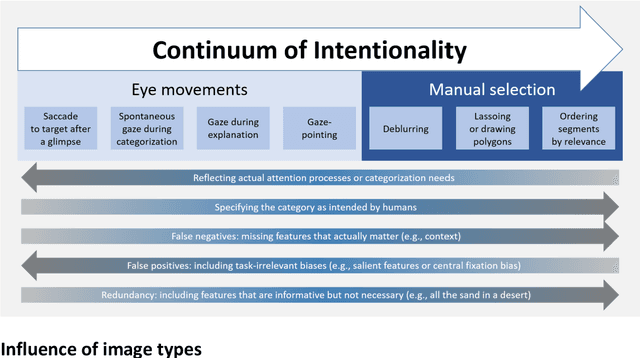
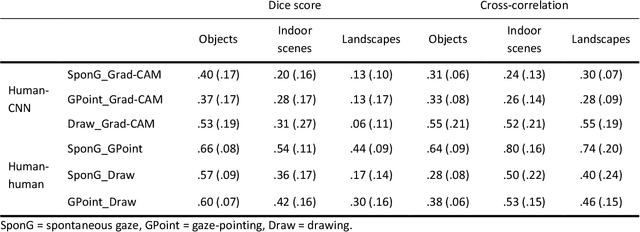

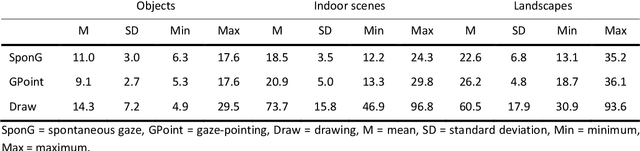
Deep Learning models like Convolutional Neural Networks (CNN) are powerful image classifiers, but what factors determine whether they attend to similar image areas as humans do? While previous studies have focused on technological factors, little is known about the role of factors that affect human attention. In the present study, we investigated how the tasks used to elicit human attention maps interact with image characteristics in modulating the similarity between humans and CNN. We varied the intentionality of human tasks, ranging from spontaneous gaze during categorization over intentional gaze-pointing up to manual area selection. Moreover, we varied the type of image to be categorized, using either singular, salient objects, indoor scenes consisting of object arrangements, or landscapes without distinct objects defining the category. The human attention maps generated in this way were compared to the CNN attention maps revealed by explainable artificial intelligence (Grad-CAM). The influence of human tasks strongly depended on image type: For objects, human manual selection produced maps that were most similar to CNN, while the specific eye movement task has little impact. For indoor scenes, spontaneous gaze produced the least similarity, while for landscapes, similarity was equally low across all human tasks. To better understand these results, we also compared the different human attention maps to each other. Our results highlight the importance of taking human factors into account when comparing the attention of humans and CNN.