 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Flickr30K-CFQ: A Compact and Fragmented Query Dataset for Text-image Retrieval
Mar 20, 2024
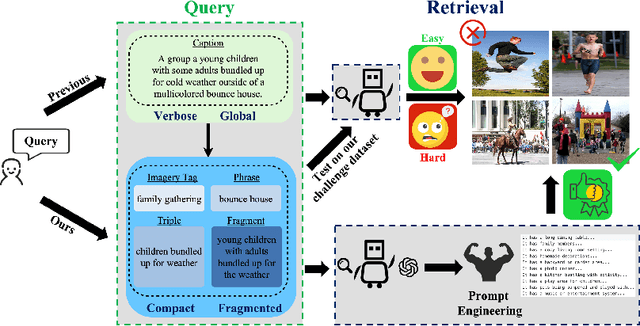

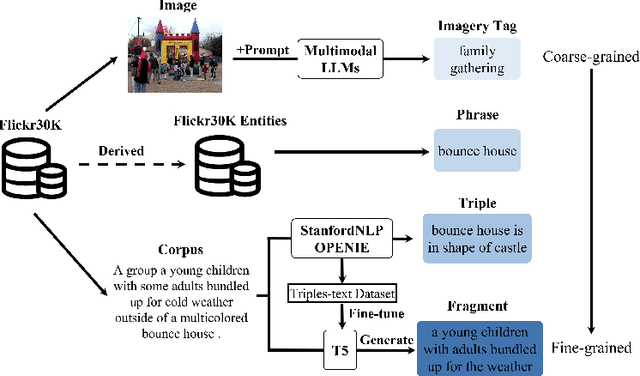

With the explosive growth of multi-modal information on the Internet, unimodal search cannot satisfy the requirement of Internet applications. Text-image retrieval research is needed to realize high-quality and efficient retrieval between different modalities. Existing text-image retrieval research is mostly based on general vision-language datasets (e.g. MS-COCO, Flickr30K), in which the query utterance is rigid and unnatural (i.e. verbosity and formality). To overcome the shortcoming, we construct a new Compact and Fragmented Query challenge dataset (named Flickr30K-CFQ) to model text-image retrieval task considering multiple query content and style, including compact and fine-grained entity-relation corpus. We propose a novel query-enhanced text-image retrieval method using prompt engineering based on LLM. Experiments show that our proposed Flickr30-CFQ reveals the insufficiency of existing vision-language datasets in realistic text-image tasks. Our LLM-based Query-enhanced method applied on different existing text-image retrieval models improves query understanding performance both on public dataset and our challenge set Flickr30-CFQ with over 0.9% and 2.4% respectively. Our project can be available anonymously in https://sites.google.com/view/Flickr30K-cfq.
Discover and Mitigate Multiple Biased Subgroups in Image Classifiers
Mar 20, 2024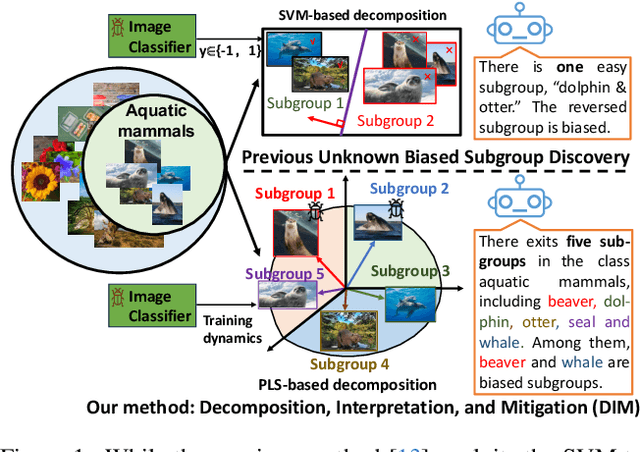

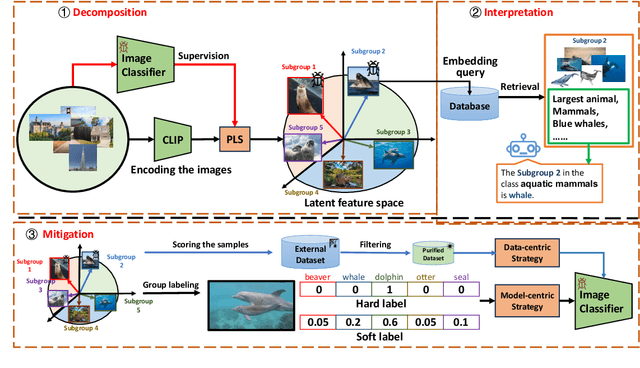
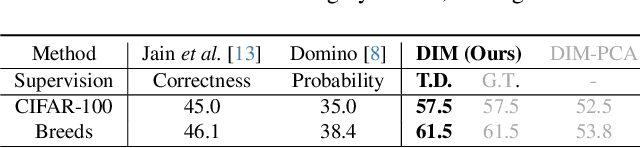
Machine learning models can perform well on in-distribution data but often fail on biased subgroups that are underrepresented in the training data, hindering the robustness of models for reliable applications. Such subgroups are typically unknown due to the absence of subgroup labels. Discovering biased subgroups is the key to understanding models' failure modes and further improving models' robustness. Most previous works of subgroup discovery make an implicit assumption that models only underperform on a single biased subgroup, which does not hold on in-the-wild data where multiple biased subgroups exist. In this work, we propose Decomposition, Interpretation, and Mitigation (DIM), a novel method to address a more challenging but also more practical problem of discovering multiple biased subgroups in image classifiers. Our approach decomposes the image features into multiple components that represent multiple subgroups. This decomposition is achieved via a bilinear dimension reduction method, Partial Least Square (PLS), guided by useful supervision from the image classifier. We further interpret the semantic meaning of each subgroup component by generating natural language descriptions using vision-language foundation models. Finally, DIM mitigates multiple biased subgroups simultaneously via two strategies, including the data- and model-centric strategies. Extensive experiments on CIFAR-100 and Breeds datasets demonstrate the effectiveness of DIM in discovering and mitigating multiple biased subgroups. Furthermore, DIM uncovers the failure modes of the classifier on Hard ImageNet, showcasing its broader applicability to understanding model bias in image classifiers. The code is available at https://github.com/ZhangAIPI/DIM.
Diffusion Deepfake
Apr 02, 2024Recent progress in generative AI, primarily through diffusion models, presents significant challenges for real-world deepfake detection. The increased realism in image details, diverse content, and widespread accessibility to the general public complicates the identification of these sophisticated deepfakes. Acknowledging the urgency to address the vulnerability of current deepfake detectors to this evolving threat, our paper introduces two extensive deepfake datasets generated by state-of-the-art diffusion models as other datasets are less diverse and low in quality. Our extensive experiments also showed that our dataset is more challenging compared to the other face deepfake datasets. Our strategic dataset creation not only challenge the deepfake detectors but also sets a new benchmark for more evaluation. Our comprehensive evaluation reveals the struggle of existing detection methods, often optimized for specific image domains and manipulations, to effectively adapt to the intricate nature of diffusion deepfakes, limiting their practical utility. To address this critical issue, we investigate the impact of enhancing training data diversity on representative detection methods. This involves expanding the diversity of both manipulation techniques and image domains. Our findings underscore that increasing training data diversity results in improved generalizability. Moreover, we propose a novel momentum difficulty boosting strategy to tackle the additional challenge posed by training data heterogeneity. This strategy dynamically assigns appropriate sample weights based on learning difficulty, enhancing the model's adaptability to both easy and challenging samples. Extensive experiments on both existing and newly proposed benchmarks demonstrate that our model optimization approach surpasses prior alternatives significantly.
Multispectral Image Restoration by Generalized Opponent Transformation Total Variation
Mar 19, 2024
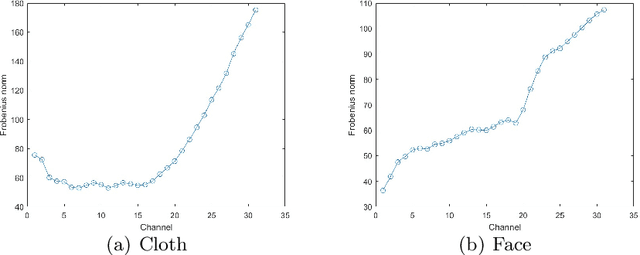
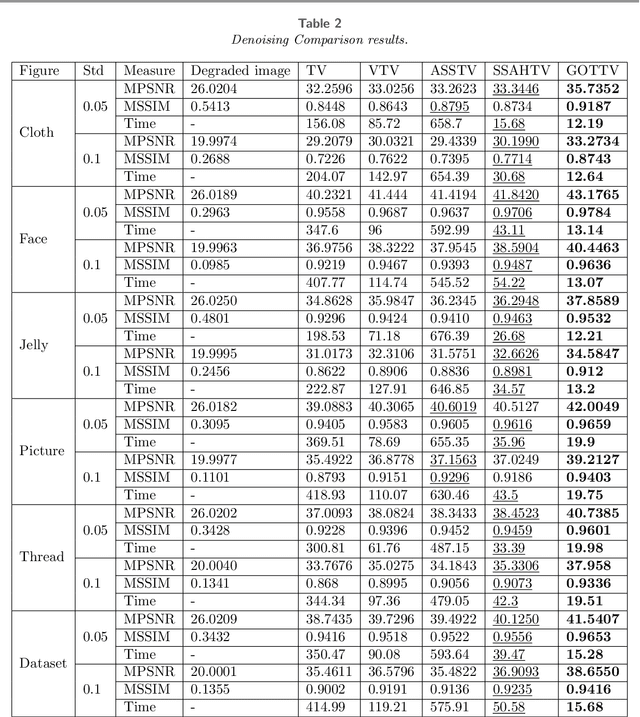
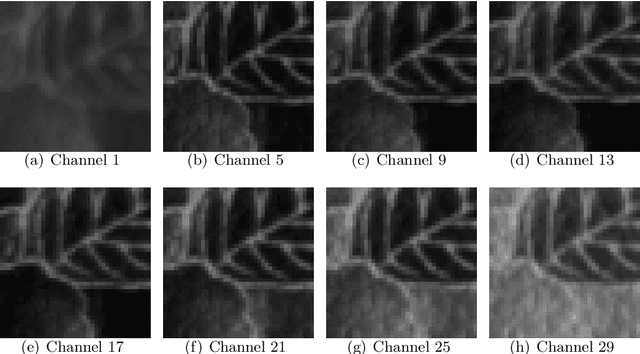
Multispectral images (MSI) contain light information in different wavelengths of objects, which convey spectral-spatial information and help improve the performance of various image processing tasks. Numerous techniques have been created to extend the application of total variation regularization in restoring multispectral images, for example, based on channel coupling and adaptive total variation regularization. The primary contribution of this paper is to propose and develop a new multispectral total variation regularization in a generalized opponent transformation domain instead of the original multispectral image domain. Here opponent transformations for multispectral images are generalized from a well-known opponent transformation for color images. We will explore the properties of generalized opponent transformation total variation (GOTTV) regularization and the corresponding optimization formula for multispectral image restoration. To evaluate the effectiveness of the new GOTTV method, we provide numerical examples that showcase its superior performance compared to existing multispectral image total variation methods, using criteria such as MPSNR and MSSIM.
Denoising Low-dose Images Using Deep Learning of Time Series Images
Mar 31, 2024Digital image devices have been widely applied in many fields, including scientific imaging, recognition of individuals, and remote sensing. As the application of these imaging technologies to autonomous driving and measurement, image noise generated when observation cannot be performed with a sufficient dose has become a major problem. Machine learning denoise technology is expected to be the solver of this problem, but there are the following problems. Here we report, artifacts generated by machine learning denoise in ultra-low dose observation using an in-situ observation video of an electron microscope as an example. And as a method to solve this problem, we propose a method to decompose a time series image into a 2D image of the spatial axis and time to perform machine learning denoise. Our method opens new avenues accurate and stable reconstruction of continuous high-resolution images from low-dose imaging in science, industry, and life.
Jailbreaking Prompt Attack: A Controllable Adversarial Attack against Diffusion Models
Apr 02, 2024The fast advance of the image generation community has attracted attention worldwide. The safety issue needs to be further scrutinized and studied. There have been a few works around this area mostly achieving a post-processing design, model-specific, or yielding suboptimal image quality generation. Despite that, in this article, we discover a black-box attack method that enjoys three merits. It enables (i)-attacks both directed and semantic-driven that theoretically and practically pose a hazard to this vast user community, (ii)-surprisingly surpasses the white-box attack in a black-box manner and (iii)-without requiring any post-processing effort. Core to our approach is inspired by the concept guidance intriguing property of Classifier-Free guidance (CFG) in T2I models, and we discover that conducting frustratingly simple guidance in the CLIP embedding space, coupled with the semantic loss and an additionally sensitive word list works very well. Moreover, our results expose and highlight the vulnerabilities in existing defense mechanisms.
Atom-Level Optical Chemical Structure Recognition with Limited Supervision
Apr 02, 2024Identifying the chemical structure from a graphical representation, or image, of a molecule is a challenging pattern recognition task that would greatly benefit drug development. Yet, existing methods for chemical structure recognition do not typically generalize well, and show diminished effectiveness when confronted with domains where data is sparse, or costly to generate, such as hand-drawn molecule images. To address this limitation, we propose a new chemical structure recognition tool that delivers state-of-the-art performance and can adapt to new domains with a limited number of data samples and supervision. Unlike previous approaches, our method provides atom-level localization, and can therefore segment the image into the different atoms and bonds. Our model is the first model to perform OCSR with atom-level entity detection with only SMILES supervision. Through rigorous and extensive benchmarking, we demonstrate the preeminence of our chemical structure recognition approach in terms of data efficiency, accuracy, and atom-level entity prediction.
ECoDepth: Effective Conditioning of Diffusion Models for Monocular Depth Estimation
Apr 01, 2024In the absence of parallax cues, a learning-based single image depth estimation (SIDE) model relies heavily on shading and contextual cues in the image. While this simplicity is attractive, it is necessary to train such models on large and varied datasets, which are difficult to capture. It has been shown that using embeddings from pre-trained foundational models, such as CLIP, improves zero shot transfer in several applications. Taking inspiration from this, in our paper we explore the use of global image priors generated from a pre-trained ViT model to provide more detailed contextual information. We argue that the embedding vector from a ViT model, pre-trained on a large dataset, captures greater relevant information for SIDE than the usual route of generating pseudo image captions, followed by CLIP based text embeddings. Based on this idea, we propose a new SIDE model using a diffusion backbone which is conditioned on ViT embeddings. Our proposed design establishes a new state-of-the-art (SOTA) for SIDE on NYUv2 dataset, achieving Abs Rel error of 0.059(14% improvement) compared to 0.069 by the current SOTA (VPD). And on KITTI dataset, achieving Sq Rel error of 0.139 (2% improvement) compared to 0.142 by the current SOTA (GEDepth). For zero-shot transfer with a model trained on NYUv2, we report mean relative improvement of (20%, 23%, 81%, 25%) over NeWCRFs on (Sun-RGBD, iBims1, DIODE, HyperSim) datasets, compared to (16%, 18%, 45%, 9%) by ZoeDepth. The project page is available at https://ecodepth-iitd.github.io
See, Imagine, Plan: Discovering and Hallucinating Tasks from a Single Image
Mar 24, 2024
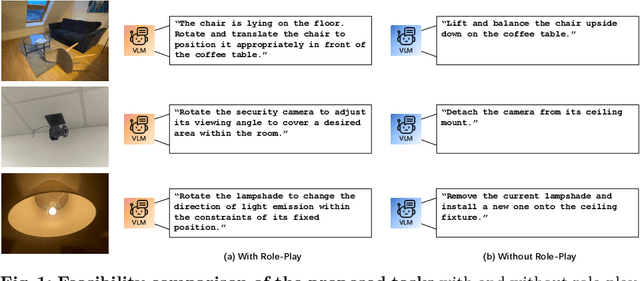
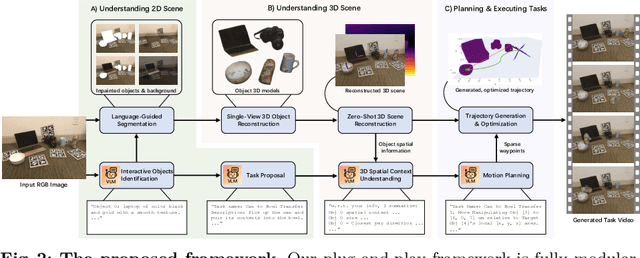
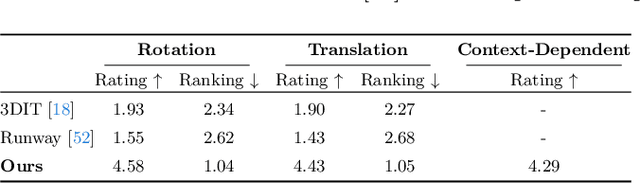
Humans can not only recognize and understand the world in its current state but also envision future scenarios that extend beyond immediate perception. To resemble this profound human capacity, we introduce zero-shot task hallucination -- given a single RGB image of any scene comprising unknown environments and objects, our model can identify potential tasks and imagine their execution in a vivid narrative, realized as a video. We develop a modular pipeline that progressively enhances scene decomposition, comprehension, and reconstruction, incorporating VLM for dynamic interaction and 3D motion planning for object trajectories. Our model can discover diverse tasks, with the generated task videos demonstrating realistic and compelling visual outcomes that are understandable by both machines and humans. Project Page: https://dannymcy.github.io/zeroshot_task_hallucination/
HySim: An Efficient Hybrid Similarity Measure for Patch Matching in Image Inpainting
Mar 21, 2024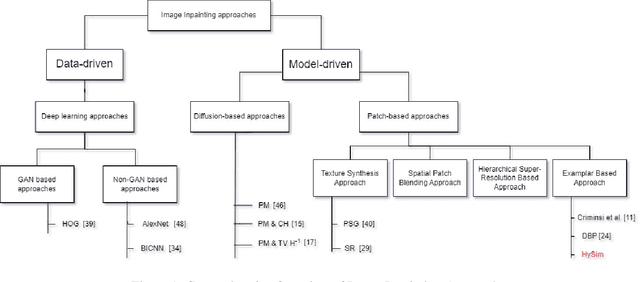
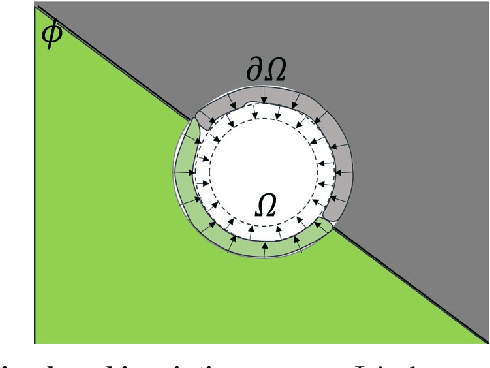
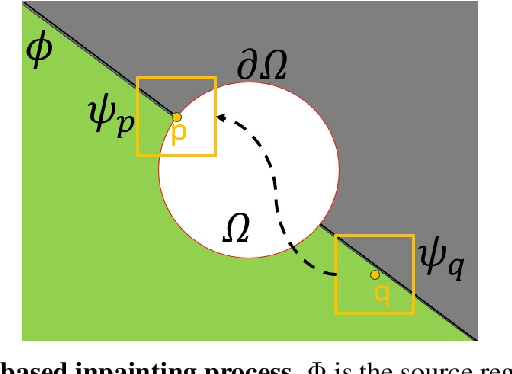
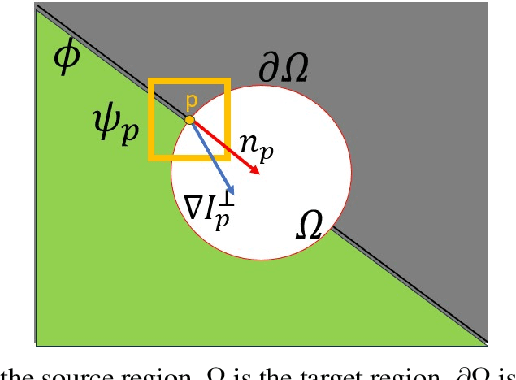
Inpainting, for filling missing image regions, is a crucial task in various applications, such as medical imaging and remote sensing. Trending data-driven approaches efficiency, for image inpainting, often requires extensive data preprocessing. In this sense, there is still a need for model-driven approaches in case of application constrained with data availability and quality, especially for those related for time series forecasting using image inpainting techniques. This paper proposes an improved modeldriven approach relying on patch-based techniques. Our approach deviates from the standard Sum of Squared Differences (SSD) similarity measure by introducing a Hybrid Similarity (HySim), which combines both strengths of Chebychev and Minkowski distances. This hybridization enhances patch selection, leading to high-quality inpainting results with reduced mismatch errors. Experimental results proved the effectiveness of our approach against other model-driven techniques, such as diffusion or patch-based approaches, showcasing its effectiveness in achieving visually pleasing restorations.