 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Extreme Image Compression using Fine-tuned VQGAN Models
Jul 17, 2023




Recent advances in generative compression methods have demonstrated remarkable progress in enhancing the perceptual quality of compressed data, especially in scenarios with low bitrates. Nevertheless, their efficacy and applicability in achieving extreme compression ratios ($<0.1$ bpp) still remain constrained. In this work, we propose a simple yet effective coding framework by introducing vector quantization (VQ)-based generative models into the image compression domain. The main insight is that the codebook learned by the VQGAN model yields strong expressive capacity, facilitating efficient compression of continuous information in the latent space while maintaining reconstruction quality. Specifically, an image can be represented as VQ-indices by finding the nearest codeword, which can be encoded using lossless compression methods into bitstreams. We then propose clustering a pre-trained large-scale codebook into smaller codebooks using the K-means algorithm. This enables images to be represented as diverse ranges of VQ-indices maps, resulting in variable bitrates and different levels of reconstruction quality. Extensive qualitative and quantitative experiments on various datasets demonstrate that the proposed framework outperforms the state-of-the-art codecs in terms of perceptual quality-oriented metrics and human perception under extremely low bitrates.
ReCLIP: Refine Contrastive Language Image Pre-Training with Source Free Domain Adaptation
Aug 04, 2023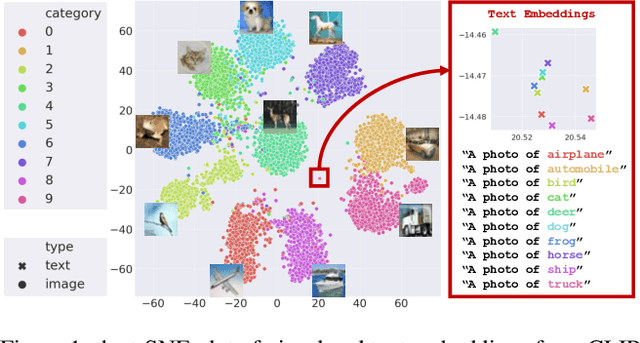
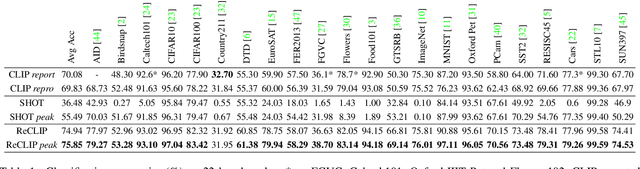
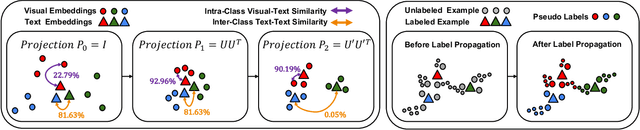
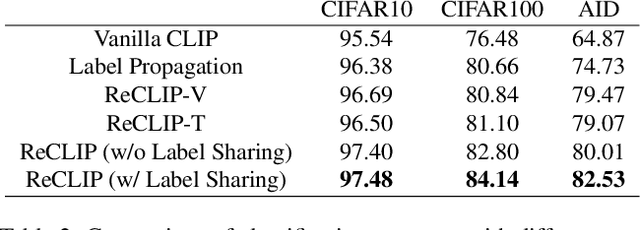
Large-scale Pre-Training Vision-Language Model such as CLIP has demonstrated outstanding performance in zero-shot classification, e.g. achieving 76.3% top-1 accuracy on ImageNet without seeing any example, which leads to potential benefits to many tasks that have no labeled data. However, while applying CLIP to a downstream target domain, the presence of visual and text domain gaps and cross-modality misalignment can greatly impact the model performance. To address such challenges, we propose ReCLIP, the first source-free domain adaptation method for vision-language models, which does not require any source data or target labeled data. ReCLIP first learns a projection space to mitigate the misaligned visual-text embeddings and learns pseudo labels, and then deploys cross-modality self-training with the pseudo labels, to update visual and text encoders, refine labels and reduce domain gaps and misalignments iteratively. With extensive experiments, we demonstrate ReCLIP reduces the average error rate of CLIP from 30.17% to 25.06% on 22 image classification benchmarks.
Timbre transfer using image-to-image denoising diffusion models
Jul 10, 2023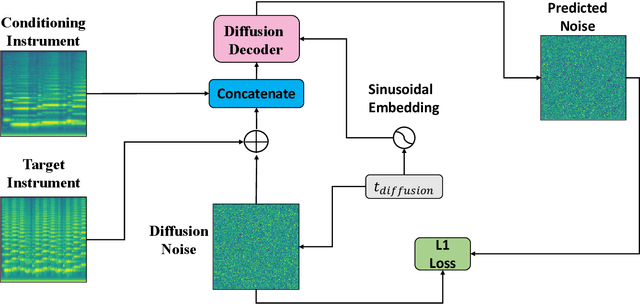
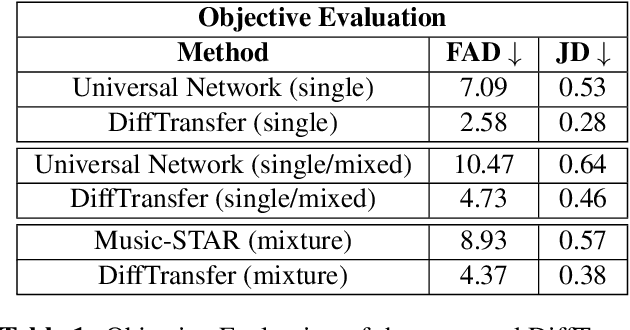
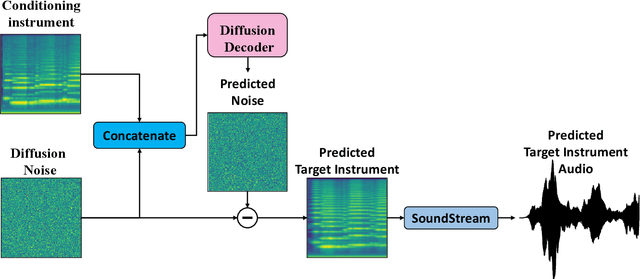
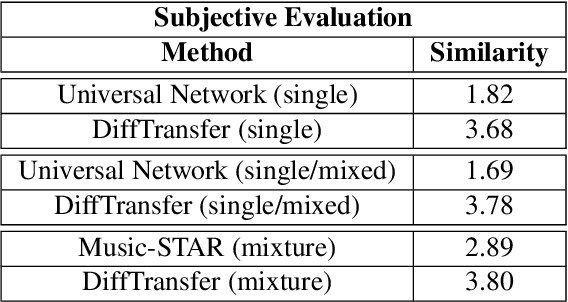
Timbre transfer techniques aim at converting the sound of a musical piece generated by one instrument into the same one as if it was played by another instrument, while maintaining as much as possible the content in terms of musical characteristics such as melody and dynamics. Following their recent breakthroughs in deep learning-based generation, we apply Denoising Diffusion Models (DDMs) to perform timbre transfer. Specifically, we apply the recently proposed Denoising Diffusion Implicit Models (DDIMs) that enable to accelerate the sampling procedure. Inspired by the recent application of DDMs to image translation problems we formulate the timbre transfer task similarly, by first converting the audio tracks into log mel spectrograms and by conditioning the generation of the desired timbre spectrogram through the input timbre spectrogram. We perform both one-to-one and many-to-many timbre transfer, by converting audio waveforms containing only single instruments and multiple instruments, respectively. We compare the proposed technique with existing state-of-the-art methods both through listening tests and objective measures in order to demonstrate the effectiveness of the proposed model.
Diffusion on the Probability Simplex
Sep 12, 2023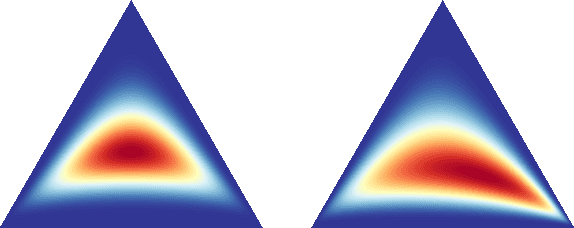
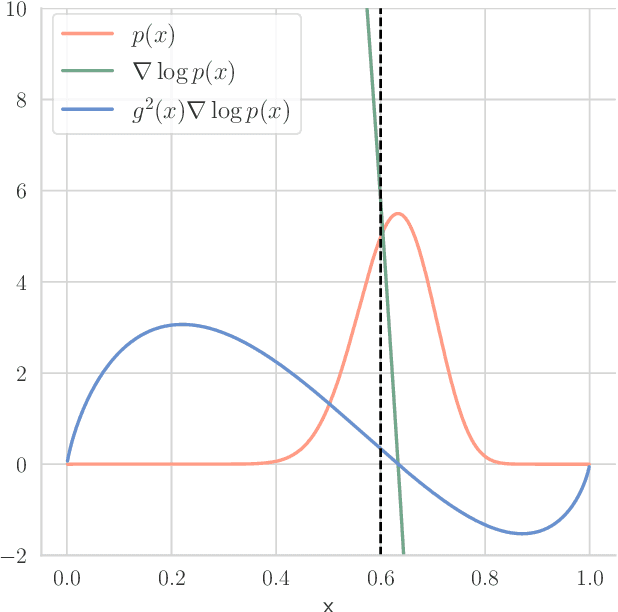

Diffusion models learn to reverse the progressive noising of a data distribution to create a generative model. However, the desired continuous nature of the noising process can be at odds with discrete data. To deal with this tension between continuous and discrete objects, we propose a method of performing diffusion on the probability simplex. Using the probability simplex naturally creates an interpretation where points correspond to categorical probability distributions. Our method uses the softmax function applied to an Ornstein-Unlenbeck Process, a well-known stochastic differential equation. We find that our methodology also naturally extends to include diffusion on the unit cube which has applications for bounded image generation.
Non-convex regularization based on shrinkage penalty function
Sep 08, 2023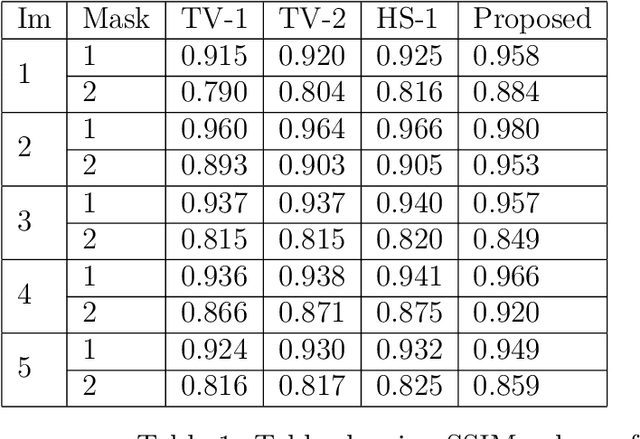

Total Variation regularization (TV) is a seminal approach for image recovery. TV involves the norm of the image's gradient, aggregated over all pixel locations. Therefore, TV leads to piece-wise constant solutions, resulting in what is known as the "staircase effect." To mitigate this effect, the Hessian Schatten norm regularization (HSN) employs second-order derivatives, represented by the pth norm of eigenvalues in the image hessian, summed across all pixels. HSN demonstrates superior structure-preserving properties compared to TV. However, HSN solutions tend to be overly smoothed. To address this, we introduce a non-convex shrinkage penalty applied to the Hessian's eigenvalues, deviating from the convex lp norm. It is important to note that the shrinkage penalty is not defined directly in closed form, but specified indirectly through its proximal operation. This makes constructing a provably convergent algorithm difficult as the singular values are also defined through a non-linear operation. However, we were able to derive a provably convergent algorithm using proximal operations. We prove the convergence by establishing that the proposed regularization adheres to restricted proximal regularity. The images recovered by this regularization were sharper than the convex counterparts.
Towards Practical Capture of High-Fidelity Relightable Avatars
Sep 08, 2023
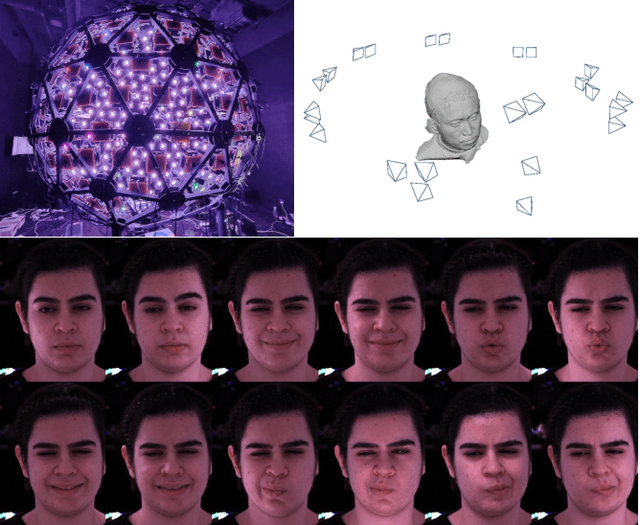
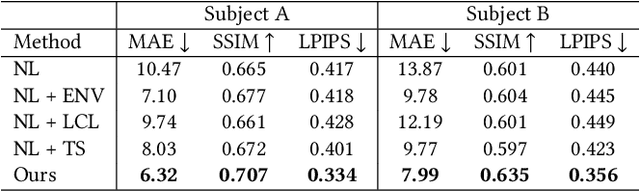
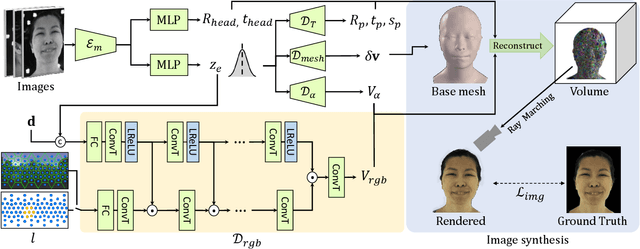
In this paper, we propose a novel framework, Tracking-free Relightable Avatar (TRAvatar), for capturing and reconstructing high-fidelity 3D avatars. Compared to previous methods, TRAvatar works in a more practical and efficient setting. Specifically, TRAvatar is trained with dynamic image sequences captured in a Light Stage under varying lighting conditions, enabling realistic relighting and real-time animation for avatars in diverse scenes. Additionally, TRAvatar allows for tracking-free avatar capture and obviates the need for accurate surface tracking under varying illumination conditions. Our contributions are two-fold: First, we propose a novel network architecture that explicitly builds on and ensures the satisfaction of the linear nature of lighting. Trained on simple group light captures, TRAvatar can predict the appearance in real-time with a single forward pass, achieving high-quality relighting effects under illuminations of arbitrary environment maps. Second, we jointly optimize the facial geometry and relightable appearance from scratch based on image sequences, where the tracking is implicitly learned. This tracking-free approach brings robustness for establishing temporal correspondences between frames under different lighting conditions. Extensive qualitative and quantitative experiments demonstrate that our framework achieves superior performance for photorealistic avatar animation and relighting.
Self-Supervised Super-Resolution Approach for Isotropic Reconstruction of 3D Electron Microscopy Images from Anisotropic Acquisition
Sep 19, 2023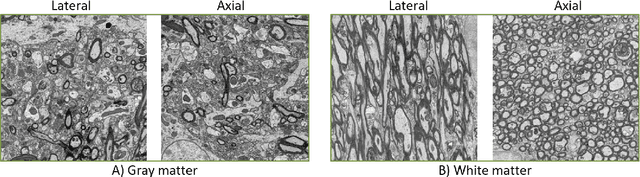
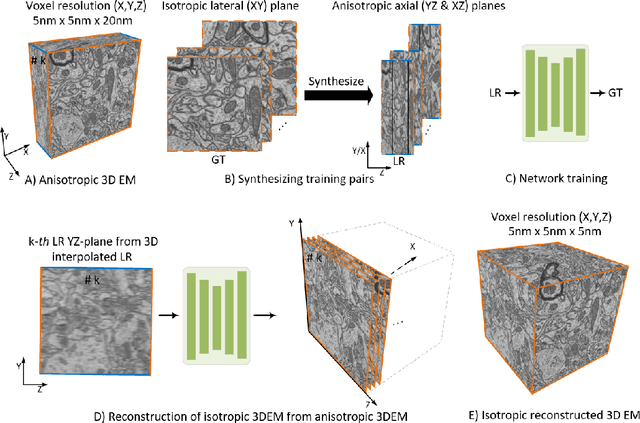
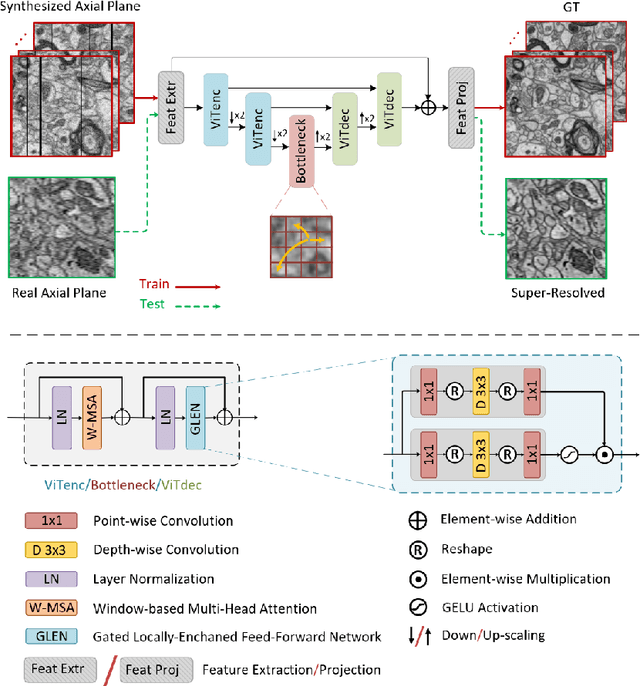

Three-dimensional electron microscopy (3DEM) is an essential technique to investigate volumetric tissue ultra-structure. Due to technical limitations and high imaging costs, samples are often imaged anisotropically, where resolution in the axial direction ($z$) is lower than in the lateral directions $(x,y)$. This anisotropy 3DEM can hamper subsequent analysis and visualization tasks. To overcome this limitation, we propose a novel deep-learning (DL)-based self-supervised super-resolution approach that computationally reconstructs isotropic 3DEM from the anisotropic acquisition. The proposed DL-based framework is built upon the U-shape architecture incorporating vision-transformer (ViT) blocks, enabling high-capability learning of local and global multi-scale image dependencies. To train the tailored network, we employ a self-supervised approach. Specifically, we generate pairs of anisotropic and isotropic training datasets from the given anisotropic 3DEM data. By feeding the given anisotropic 3DEM dataset in the trained network through our proposed framework, the isotropic 3DEM is obtained. Importantly, this isotropic reconstruction approach relies solely on the given anisotropic 3DEM dataset and does not require pairs of co-registered anisotropic and isotropic 3DEM training datasets. To evaluate the effectiveness of the proposed method, we conducted experiments using three 3DEM datasets acquired from brain. The experimental results demonstrated that our proposed framework could successfully reconstruct isotropic 3DEM from the anisotropic acquisition.
Ego3DPose: Capturing 3D Cues from Binocular Egocentric Views
Sep 21, 2023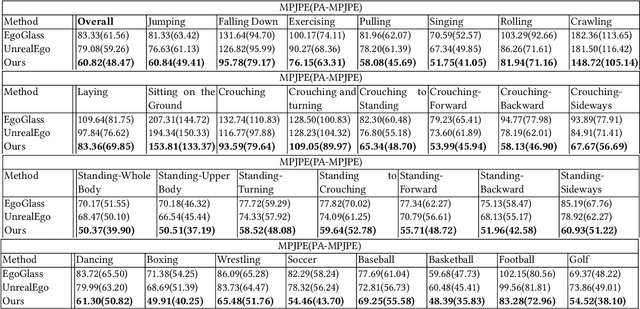
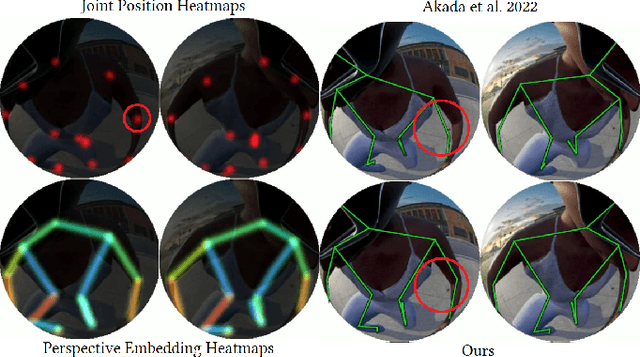
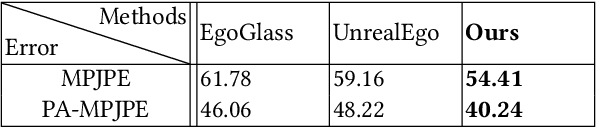
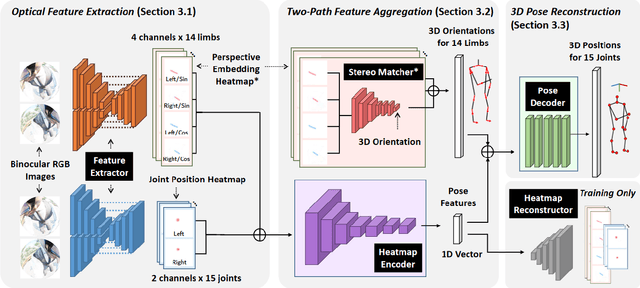
We present Ego3DPose, a highly accurate binocular egocentric 3D pose reconstruction system. The binocular egocentric setup offers practicality and usefulness in various applications, however, it remains largely under-explored. It has been suffering from low pose estimation accuracy due to viewing distortion, severe self-occlusion, and limited field-of-view of the joints in egocentric 2D images. Here, we notice that two important 3D cues, stereo correspondences, and perspective, contained in the egocentric binocular input are neglected. Current methods heavily rely on 2D image features, implicitly learning 3D information, which introduces biases towards commonly observed motions and leads to low overall accuracy. We observe that they not only fail in challenging occlusion cases but also in estimating visible joint positions. To address these challenges, we propose two novel approaches. First, we design a two-path network architecture with a path that estimates pose per limb independently with its binocular heatmaps. Without full-body information provided, it alleviates bias toward trained full-body distribution. Second, we leverage the egocentric view of body limbs, which exhibits strong perspective variance (e.g., a significantly large-size hand when it is close to the camera). We propose a new perspective-aware representation using trigonometry, enabling the network to estimate the 3D orientation of limbs. Finally, we develop an end-to-end pose reconstruction network that synergizes both techniques. Our comprehensive evaluations demonstrate that Ego3DPose outperforms state-of-the-art models by a pose estimation error (i.e., MPJPE) reduction of 23.1% in the UnrealEgo dataset. Our qualitative results highlight the superiority of our approach across a range of scenarios and challenges.
Sem-CS: Semantic CLIPStyler for Text-Based Image Style Transfer
Jul 12, 2023
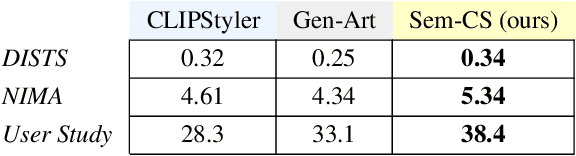
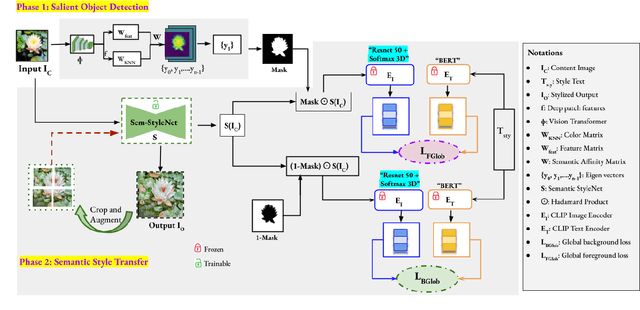
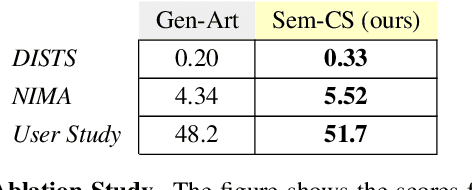
CLIPStyler demonstrated image style transfer with realistic textures using only a style text description (instead of requiring a reference style image). However, the ground semantics of objects in the style transfer output is lost due to style spill-over on salient and background objects (content mismatch) or over-stylization. To solve this, we propose Semantic CLIPStyler (Sem-CS), that performs semantic style transfer. Sem-CS first segments the content image into salient and non-salient objects and then transfers artistic style based on a given style text description. The semantic style transfer is achieved using global foreground loss (for salient objects) and global background loss (for non-salient objects). Our empirical results, including DISTS, NIMA and user study scores, show that our proposed framework yields superior qualitative and quantitative performance. Our code is available at github.com/chandagrover/sem-cs.
* 5 pages, 4 Figures, 2 Tables. arXiv admin note: substantial text overlap with arXiv:2303.06334
Tracking Anything with Decoupled Video Segmentation
Sep 07, 2023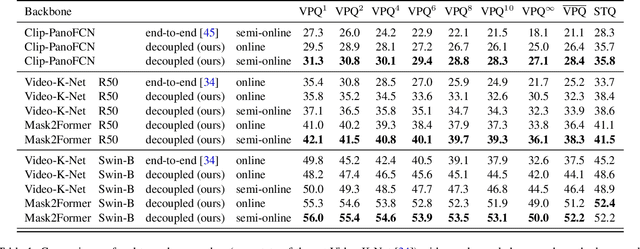
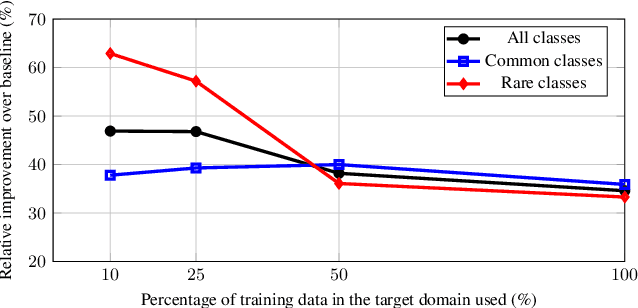
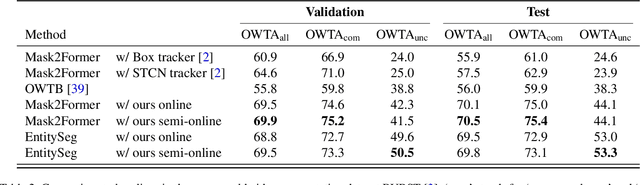
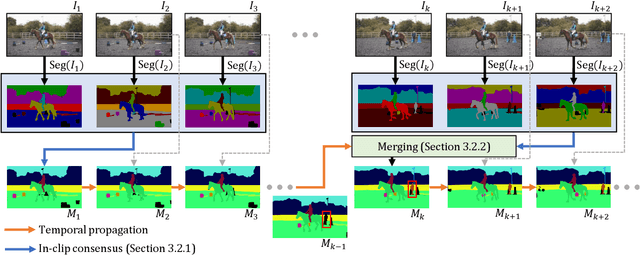
Training data for video segmentation are expensive to annotate. This impedes extensions of end-to-end algorithms to new video segmentation tasks, especially in large-vocabulary settings. To 'track anything' without training on video data for every individual task, we develop a decoupled video segmentation approach (DEVA), composed of task-specific image-level segmentation and class/task-agnostic bi-directional temporal propagation. Due to this design, we only need an image-level model for the target task (which is cheaper to train) and a universal temporal propagation model which is trained once and generalizes across tasks. To effectively combine these two modules, we use bi-directional propagation for (semi-)online fusion of segmentation hypotheses from different frames to generate a coherent segmentation. We show that this decoupled formulation compares favorably to end-to-end approaches in several data-scarce tasks including large-vocabulary video panoptic segmentation, open-world video segmentation, referring video segmentation, and unsupervised video object segmentation. Code is available at: https://hkchengrex.github.io/Tracking-Anything-with-DEVA